If you were given a huge file containing 100 million lines of data, and you could convert the data into the production database within one week, how would you operate?
The above problem is that little black brother received a real business demand some time ago and migrated the historical data of an old system to the new production system through offline files.
Since the bosses have finalized the launch time of the new system, little black brother is only allowed one week to import the historical data into the production system.
Due to the tight time and huge amount of data, little black brother came up with the following solutions in the design process:
- Split file
- Multithreaded import
Split file
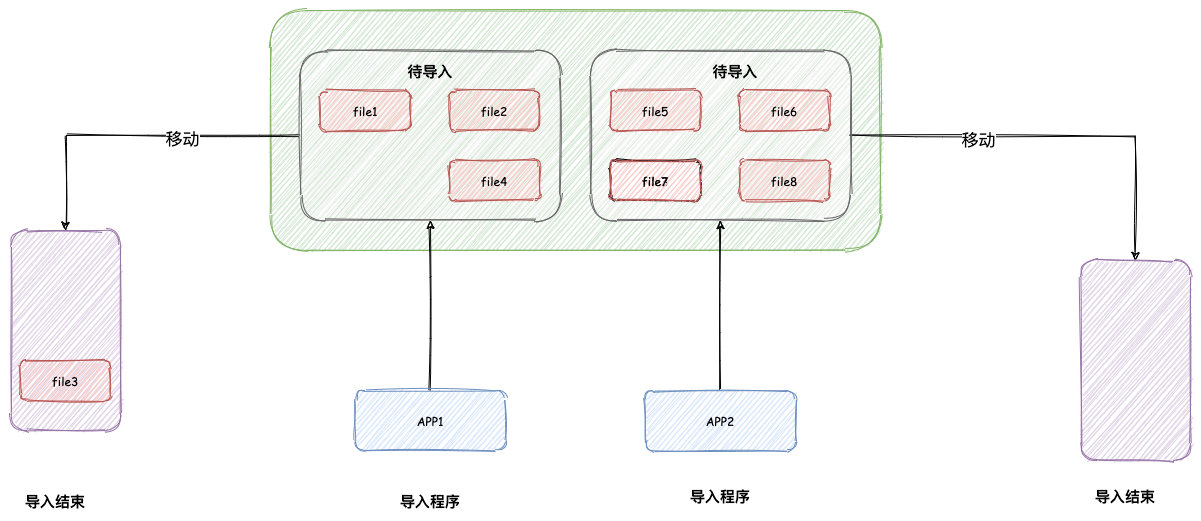
First, we can write a small program, or use the split command "split" to split the large file into small files.
-- Split a large file into several small files, 100000 lines each split -l 100000 largeFile.txt -d -a 4 smallFile_
There are two main reasons why we choose to split large files first:
First, if the program reads this large file directly, it is assumed that the program suddenly stops halfway through the reading, which will directly lose the progress of file reading and need to start reading again.
After the file is split, once the small file is read, we can move the small file to a specified folder.
In this way, even if the application is down and restarted, we only need to read the remaining files when we re read.
Second, a file can only be read by one application, which limits the speed of import.
After file splitting, we can use multi node deployment to expand horizontally. Each node reads a part of the file, which can double the import speed.
Multithreaded import
After we split the file, we need to read the contents of the file and import it.
Before splitting, set each small file to contain 10w rows of data. For fear of reading 10w data into the application at once, which will lead to excessive heap memory occupation and frequent Full GC, the following adopts the method of streaming reading to read data line by line.
Of course, if the file is small after splitting, or the heap memory setting of the application is large, we can directly load the file into the application memory for processing. This is relatively simple.
The code read line by line is as follows:
File file = ...
try (LineIterator iterator = IOUtils.lineIterator(new FileInputStream(file), "UTF-8")) {
while (iterator.hasNext()) {
String line=iterator.nextLine();
convertToDB(line);
}
}
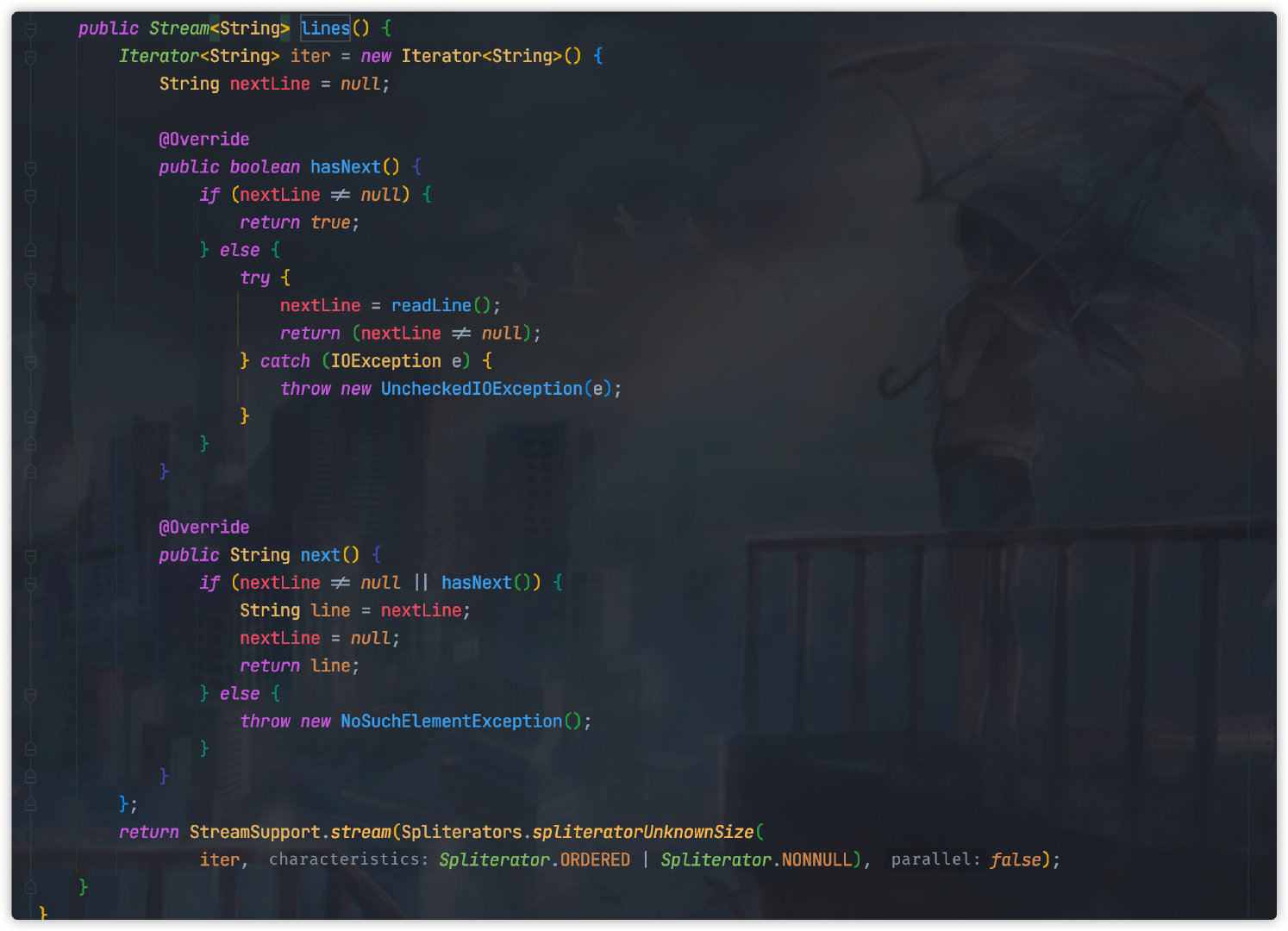
The above code uses the "LineIterator" class in "commons IO". The underlying class uses "BufferedReader" to read the contents of the file. It encapsulates it into an iterator pattern, so that we can easily read iteratively.
If jdk1 is currently used 8. The above operation is simpler. We can directly use the JDK native class "Stream Files" to convert the file into "Stream" mode for reading. The code is as follows:
Files.lines(Paths.get("File path"), Charset.defaultCharset()).forEach(line -> {
convertToDB(line);
});
In fact, take a closer look at the underlying source code of #Files#lines. In fact, the principle is similar to that of # LineIterator above, which is also encapsulated into iterator mode.
Problems in the introduction of multithreading
The above read code is not difficult to write, but there is an efficiency problem, mainly because only a single thread can continue to operate the next line after importing the data of the previous line.
In order to speed up the import, let's add several threads to import concurrently.
Multithreading, we will naturally use thread pool. The relevant code is modified as follows:
File file = ...;
ExecutorService executorService = new ThreadPoolExecutor(
5,
10,
60,
TimeUnit.MINUTES,
// Number of files, assuming that the file contains 10W lines
new ArrayBlockingQueue<>(10*10000),
// Provided by guava
new ThreadFactoryBuilder().setNameFormat("test-%d").build());
try (LineIterator iterator = IOUtils.lineIterator(new FileInputStream(file), "UTF-8")) {
while (iterator.hasNext()) {
String line = iterator.nextLine();
executorService.submit(() -> {
convertToDB(line);
});
}
}
In the above code, each line of content read will be directly handed over to the thread pool for execution.
We know that the principle of thread pool is as follows:
- If the number of core threads is not full, a thread will be created to execute the task directly.
- If the number of core threads is full, the task will be put into the queue.
- If the queue is full, another thread will be created to execute the task.
- If the maximum number of threads is full and the queue is full, a reject policy is executed.
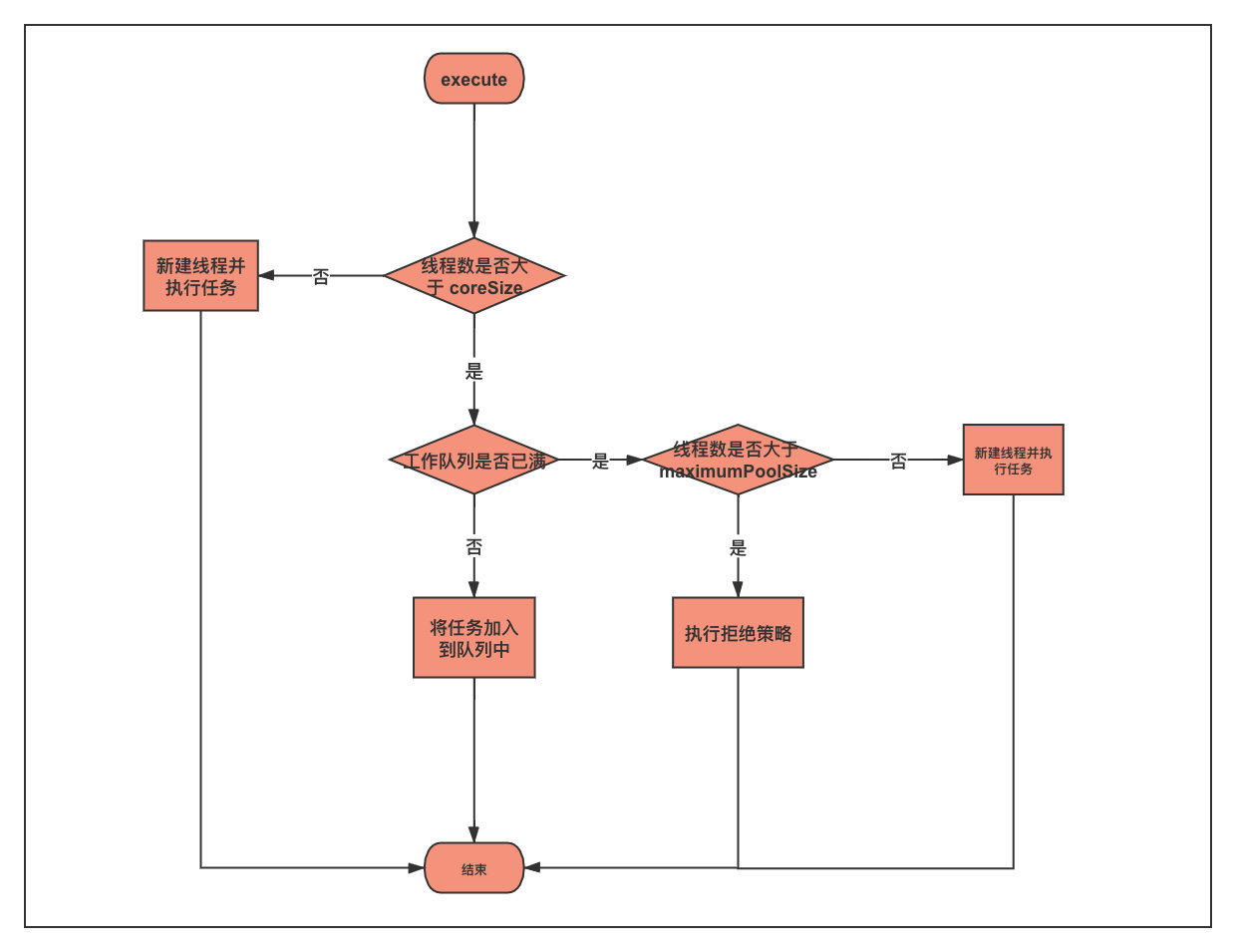
Since the number of core threads set by our thread pool is 5, the maximum number of core threads is reached soon, and subsequent tasks can only be added to the queue.
In order to prevent subsequent tasks from being rejected by the thread pool, we can adopt the following scheme:
- Set the queue capacity to be large, including all lines of the entire file
- Set the maximum number of threads to be large, and the number is greater than the number of all lines
The above two schemes have the same problem. The first is to load all the contents of the file into memory, which will occupy too much memory.
The second way is to create too many threads, which will also occupy too much memory.
Once too much memory is occupied and the GC cannot be cleaned up, it may cause frequent "Full GC" or even "OOM", resulting in too slow program import speed.
To solve this problem, we can use the following two solutions:
- CountDownLatch batch execution
- Extended thread pool
CountDownLatch batch execution
The CountDownLatch provided by JDK allows the main thread to wait for the execution of all child threads before continuing.
Using this feature, we can transform the code imported by multithreading. The main logic is as follows:
try (LineIterator iterator = IOUtils.lineIterator(new FileInputStream(file), "UTF-8")) {
// Stores the number of rows executed per task
List<String> lines = Lists.newArrayList();
// Store asynchronous tasks
List<ConvertTask> tasks = Lists.newArrayList();
while (iterator.hasNext()) {
String line = iterator.nextLine();
lines.add(line);
// Sets the number of rows executed per thread
if (lines.size() == 1000) {
// Create a new asynchronous task. Note that you need to create a List here
tasks.add(new ConvertTask(Lists.newArrayList(lines)));
lines.clear();
}
if (tasks.size() == 10) {
asyncBatchExecuteTask(tasks);
}
}
// File reading ended, but there may still be content that has not been
tasks.add(new ConvertTask(Lists.newArrayList(lines)));
// Do it again for the last time
asyncBatchExecuteTask(tasks);
}
In this code, each asynchronous task will import 1000 rows of data. After accumulating 10 asynchronous tasks, it will call asyncBatchExecuteTask to execute asynchronously using the thread pool.
/**
* Batch execution of tasks
*
* @param tasks
*/
private static void asyncBatchExecuteTask(List<ConvertTask> tasks) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(tasks.size());
for (ConvertTask task : tasks) {
task.setCountDownLatch(countDownLatch);
executorService.submit(task);
}
// The main thread waits for the asynchronous thread countDownLatch to finish executing
countDownLatch.await();
// Empty and add task again
tasks.clear();
}
The batchcountexecute method will be called asynchronously in the main thread, and then the batchcountexecute method will end.
ConvertTask asynchronous task logic is as follows:
/**
* Asynchronous task
* After the data import is completed, be sure to call countdownlatch countDown()
* Otherwise, the main route will be blocked,
*/
private static class ConvertTask implements Runnable {
private CountDownLatch countDownLatch;
private List<String> lines;
public ConvertTask(List<String> lines) {
this.lines = lines;
}
public void setCountDownLatch(CountDownLatch countDownLatch) {
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {
for (String line : lines) {
convertToDB(line);
}
} finally {
countDownLatch.countDown();
}
}
}
The ConvertTask task task class logic is very simple, traversing all rows and importing them into the database. After importing all data, call #countDownLatch#countDown.
Once the execution of all asynchronous threads is completed, call #countDownLatch#countDown, and the main thread will wake up and continue to read the file.
Although this method solves the above problems, it needs to accumulate a certain number of tasks each time to start executing all tasks asynchronously.
In addition, the next batch of tasks can only be started after the execution of all tasks. The time consumed by batch execution is equal to that consumed by the slowest asynchronous task.
In this way, there is a certain idle time in the thread pool. Is there any way to squeeze the thread pool and keep it working?
Extended thread pool
Back to the initial problem, file reading and importing is actually a producer consumer consumption model.
The main thread, as the producer, constantly reads the file and then puts it in the queue.
Asynchronous threads, as consumers, constantly read content from the queue and import it into the database.
Once the queue is full, the producer should block until the consumer consumes the task.
In fact, what we use thread pool is also a producer consumer consumption model, which also uses blocking queue.
Then why does the thread pool not block when the queue is full?
This is because the {offer} method is used inside the thread pool. This method will not block when the queue is full, but directly return.
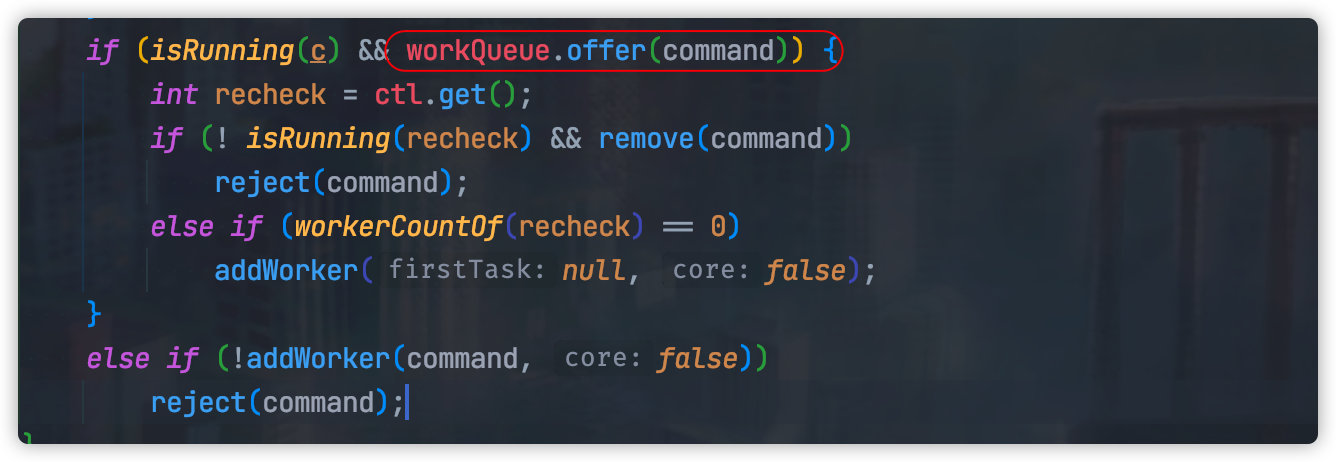
Is there any way to block the main thread to add tasks when the thread pool queue is full?
In fact, we can customize the thread pool rejection policy. When the queue is full, we call {BlockingQueue Put , to achieve producer blocking.
RejectedExecutionHandler rejectedExecutionHandler = new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
try {
executor.getQueue().put(r);
} catch (InterruptedException e) {
// should not be interrupted
}
}
}
};
In this way, once the thread pool is full, the main thread will be blocked.
After using this method, we can directly use the multi-threaded imported code mentioned above.
ExecutorService executorService = new ThreadPoolExecutor(
5,
10,
60,
TimeUnit.MINUTES,
new ArrayBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("test-%d").build(),
(r, executor) -> {
if (!executor.isShutdown()) {
try {
// The main thread will be blocked
executor.getQueue().put(r);
} catch (InterruptedException e) {
// should not be interrupted
}
}
});
File file = new File("File path");
try (LineIterator iterator = IOUtils.lineIterator(new FileInputStream(file), "UTF-8")) {
while (iterator.hasNext()) {
String line = iterator.nextLine();
executorService.submit(() -> convertToDB(line));
}
}
Summary
For a very large file, we can split the file into multiple files, and then deploy multiple applications to improve the reading speed.
In addition, we can also use multithreading to import concurrently in the reading process, but we need to note that subsequent tasks will be rejected after the thread pool is full.
We can expand the thread pool and customize the rejection policy to block the reading main thread.
last
Many programmers are immersed in the CRUD of business code all day. There is no large amount of data concurrency in the business and lack practical experience. They only stay in understanding concurrency and can't be proficient, so they always pass by big manufacturers.
I share the notes and mind map of this set of concurrency system hidden in my pocket, and the combination of theoretical knowledge and project practice. I think you can quickly master concurrent programming as long as you are willing to take the time to learn these carefully.
Whether it is to check and make up deficiencies or in-depth learning, it can have very good results. If you need help, remember to point out praise and support
, subsequent tasks will be rejected.
We can expand the thread pool and customize the rejection policy to block the reading main thread.
last
Many programmers are immersed in the CRUD of business code all day. There is no large amount of data concurrency in the business and lack practical experience. They only stay in understanding concurrency and can't be proficient, so they always pass by big manufacturers.
I share the notes and mind map of this set of concurrency system hidden in my pocket, and the combination of theoretical knowledge and project practice. I think you can quickly master concurrent programming as long as you are willing to take the time to learn these carefully.
Whether it is to check and make up deficiencies or in-depth learning, it can have very good results. If you need help, remember to point out praise and support
It's not easy to sort out. Friends who feel helpful can help praise, share and support Xiaobian~