Welcome to WeChat official account: Xiamen micro think network.
Wechat (official website): https://www.xmws.cn/
During holidays, people who return home and go out to play in the first and second tier cities are almost faced with a problem: grab train tickets!
Although tickets can be booked in most cases, I believe everyone has a deep understanding of the scene that there is no ticket at the moment of ticket release.
Especially during the Spring Festival, we not only use 12306, but also consider "Zhixing" and other ticket grabbing software. Hundreds of millions of people across the country are grabbing tickets during this period.
"12306 service" bears QPS that can't be surpassed by any second kill system in the world. Millions of concurrency can't be more normal!
The author specially studied the server architecture of "12306" and learned many highlights in its system design. Here, I share and simulate an example: how to provide normal and stable services when 1 million people rob 10000 train tickets at the same time.
Github code address:
https://github.com/GuoZhaoran/spikeSystem
01
Large scale high concurrency system architecture
The highly concurrent system architecture will adopt distributed cluster deployment. The upper layer of the service has layer by layer load balancing, and provides various disaster recovery means (double fire machine room, node fault tolerance, server disaster recovery, etc.) to ensure the high availability of the system. The traffic will also be balanced to different servers according to different load capacities and configuration strategies.
Below is a simple diagram:
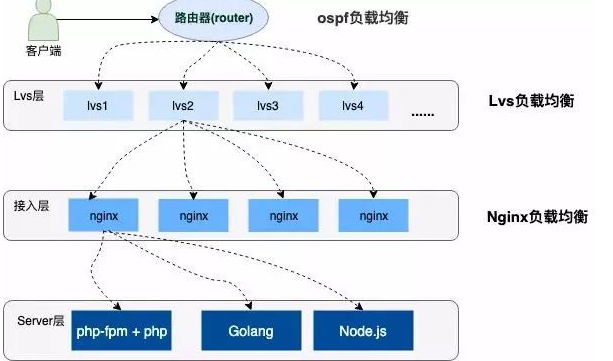
02
Introduction to load balancing
The above figure describes that the user requests to the server has experienced three layers of load balancing. The following briefly introduces these three kinds of load balancing.
① OSPF (open shortest link first) is an internal gateway protocol (IGP)
OSPF establishes the link state database by announcing the state of the network interface between routers and generates the shortest path tree. OSPF will automatically calculate the Cost value on the routing interface, but it can also manually specify the Cost value of the interface. The manually specified value takes precedence over the automatically calculated value.
The Cost calculated by OSPF is also inversely proportional to the interface bandwidth. The higher the bandwidth, the smaller the Cost value. The path that reaches the same Cost value of the target can perform load balancing, and up to 6 links can perform load balancing at the same time.
②LVS (Linux Virtual Server)
It is a kind of Cluster technology, which adopts IP load balancing technology and content-based request distribution technology.
The scheduler has a good throughput, transfers requests to different servers evenly, and automatically shields the failure of the server, so as to form a group of servers into a high-performance and highly available virtual server.
③Nginx
You must be familiar with it. It is a very high-performance HTTP proxy / reverse proxy server, which is often used for load balancing in service development.
There are three main ways for Nginx to achieve load balancing:
-
polling
-
Weighted polling
-
IP # Hash # polling
Next, we will do a special configuration and test for the weighted polling of Nginx.
Demonstration of Nginx weighted polling
Nginx realizes load balancing through the Upstream module. The configuration of weighted polling can add a weight value to relevant services. During configuration, the corresponding load may be set according to the performance and load capacity of the server.
The following is a weighted polling load configuration. I will monitor ports 3001-3004 locally and configure the weights of 1, 2, 3 and 4 respectively:
#Configure load balancing upstream load_ rule { server 127.0.0.1:3001 weight=1; server 127.0.0.1:3002 weight=2; server 127.0.0.1:3003 weight=3; server 127.0.0.1:3004 weight=4; } ... server { listen 80; server_name load_balance.com www.load_balance.com; location / { proxy_pass http://load_rule ; }}
I configured www.load in the local / etc/hosts directory_ balance. Com.
Next, use the go language to open four HTTP port listening services. The following is the Go program listening on port 3001. For others, you only need to modify the port:
package main
import ( "net/http" "os" "strings")
func main() { http.HandleFunc("/buy/ticket", handleReq) http.ListenAndServe(":3001", nil)}
//Process the request function and write the response result information into the log according to the request func handlereq (W http. Responsewriter, R * http. Request) {failedmsg: = "handle in port:" writelog (failedmsg, ". / stat.log")}
//Write log func writelog (MSG string, logpath string) {FD,: = OS. OpenFile (logpath, OS. O_rdwr|os. O_create|os. O_append, 0644) defer FD. Close() content: = strings. Join ([] string{MSG, "\ R \ n"}, "3001") buf: = [] byte (content) FD Write(buf)}I wrote the requested port log information to/ stat.log file, and then use AB pressure measurement tool for pressure measurement:
ab -n 1000 -c 100 http://www.load_balance.com/buy/ticket
According to the statistics in the log, ports 3001-3004 get the requests of 100, 200, 300 and 400} respectively.
This is in good agreement with the weight proportion I configured in Nginx, and the traffic after load is very uniform and random.
For specific implementation, you can refer to the implementation source code of the Upstream module of Nginx. Here is an article "load balancing of the Upstream mechanism in Nginx":
https://www.kancloud.cn/digest/understandingnginx/202607
03
Model selection of spike buying system
Back to the question we first mentioned: how can the train ticket second kill system provide normal and stable services under high concurrency?
From the above introduction, we know that the second kill traffic of users is evenly distributed to different servers through layers of load balancing. Even so, the QPS borne by single machines in the cluster is very high. How to optimize the single machine performance to the extreme?
To solve this problem, we need to understand one thing: usually, the booking system has to deal with three basic stages: order generation, inventory deduction and user payment.
What our system needs to do is to ensure that the train ticket orders are not oversold and many are sold. Each sold ticket must be paid to be effective, and the system must bear high concurrency.
How can the order of these three stages be more reasonable? Let's analyze:
Reduce inventory under order

When the user's concurrent request reaches the server, first create an order, then deduct the inventory and wait for the user to pay.
This order is the first solution that most of us will think of. In this case, it can also ensure that the order will not be oversold, because the inventory will be reduced after the order is created. This is an atomic operation.
But there are also some problems:
-
In the case of extreme concurrency, the details of any memory operation are crucial and affect the performance. In particular, the logic of creating an order generally needs to be stored in the disk database, and the pressure on the database can be imagined.
-
If users place orders maliciously and only place orders without payment, the inventory will be reduced and many orders will be sold less. Although the server can limit the number of IP and users' purchase orders, this is not a good method.
Payment minus inventory

If you wait for the user to pay the order and reduce the inventory, the first feeling is that you won't sell less. However, this is a big taboo of concurrent architecture, because in the case of extreme concurrency, users may create many orders.
When the inventory is reduced to zero, many users find that the orders they grab can't be paid, which is the so-called "oversold". Concurrent operation of Database disk IO cannot be avoided.
Withholding inventory
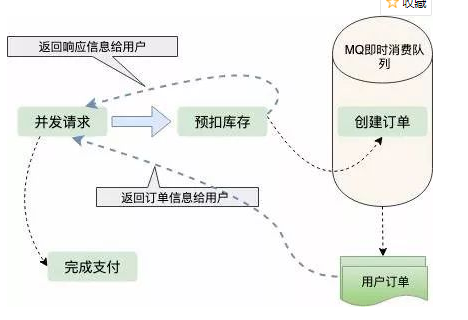
From the consideration of the above two schemes, we can draw a conclusion: as long as you create an order, you should operate database IO frequently.
Is there a scheme that does not require direct operation of database IO, that is, withholding inventory. First deduct the inventory to ensure that it is not oversold, and then generate user orders asynchronously. In this way, the response speed to users will be much faster; So how to guarantee a lot of sales? What if the user gets the order and doesn't pay?
We all know that now orders have a validity period. For example, if users don't pay within five minutes, the order will become invalid. Once the order becomes invalid, new inventory will be added. This is also the scheme adopted by many online retail enterprises to ensure the sale of many goods.
Orders are generated asynchronously and are generally processed in real-time consumption queues such as MQ and Kafka. When the number of orders is relatively small, orders are generated very quickly and users hardly need to queue.
The art of inventory deduction
From the above analysis, it is obvious that the scheme of withholding inventory is the most reasonable. We further analyze the details of inventory deduction. There is still a lot of room for optimization. Where is the inventory? How to ensure high and issued, correct inventory deduction, and rapid response to user requests?
In the case of low concurrency of single machine, we usually realize inventory deduction as follows:
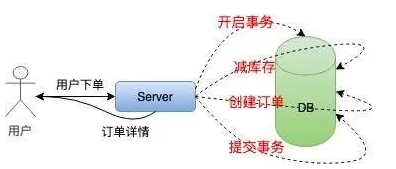
In order to ensure the atomicity of inventory deduction and order generation, it is necessary to adopt transaction processing, then take inventory judgment, reduce inventory, and finally submit the transaction. The whole process has a lot of IO, which blocks the operation of the database.
This method is not suitable for high concurrency seckill system at all. Next, we optimize the single machine inventory deduction scheme: local inventory deduction.
We allocate a certain amount of inventory to the local machine, directly reduce the inventory in memory, and then create orders asynchronously according to the previous logic.
The improved stand-alone system is as follows:
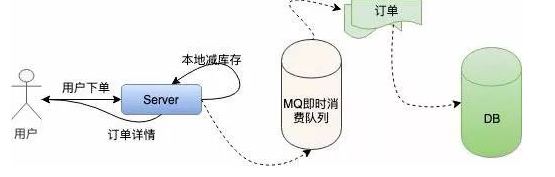
This avoids frequent IO operations on the database and only performs operations in memory, which greatly improves the anti concurrency ability of a single machine.
However, with millions of user requests, a single machine cannot resist it anyway. Although Nginx uses the Epoll model to process network requests, the problem of c10k has long been solved in the industry.
However, under Linux system, all resources are files, and so are network requests. A large number of file descriptors will make the operating system lose response instantly.
We mentioned the weighted equalization strategy of Nginx above. We might as well assume that the amount of user requests of 100W is evenly balanced to 100 servers, so that the amount of concurrency borne by a single machine is much smaller.
Then we stock 100 train tickets locally for each machine, and the total inventory on 100) servers is still 10000, which ensures that the inventory orders are not oversold. The following is the cluster architecture we describe:
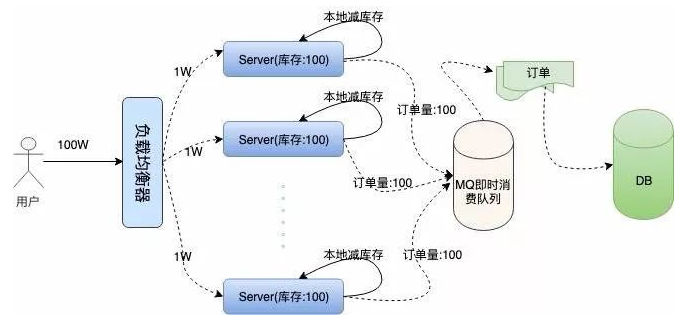
Problems come one after another. In the case of high concurrency, we can't guarantee the high availability of the system. If two or three machines on these 100} servers are down because they can't carry the concurrent traffic or for other reasons. Then the orders on these servers cannot be sold, which leads to less sales of orders.
To solve this problem, we need to manage the total order volume uniformly. This is the next fault-tolerant scheme. The server should not only reduce inventory locally, but also reduce inventory remotely.
With the remote unified inventory reduction operation, we can allocate some redundant "Buffer inventory" for each machine according to the machine load to prevent machine downtime.
Let's make a specific analysis in combination with the following architecture diagram:
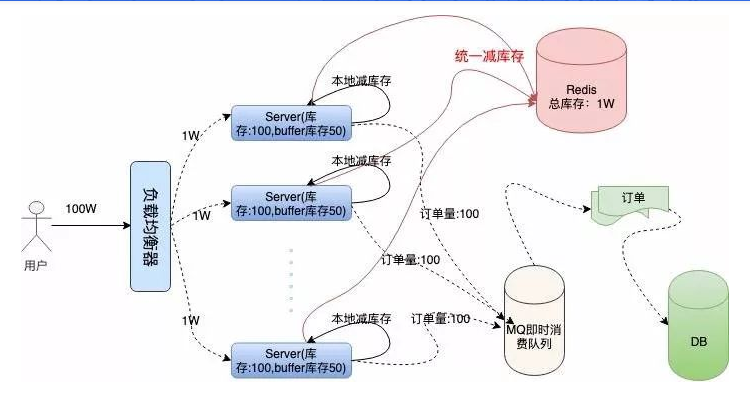
We use Redis to store unified inventory. Because Redis has very high performance, it is known that single machine QPS can resist 10W concurrency.
After the local inventory reduction, if there is a local order, we will ask Redis to reduce the inventory remotely. After the local inventory reduction and remote inventory reduction are successful, the prompt of successful ticket grabbing will be returned to the user, which can also effectively ensure that the order will not be oversold.
When one of the machines is down, because there are reserved Buffer tickets on each machine, the remaining tickets on the down machine can still be made up on other machines, ensuring a lot of sales.
How appropriate is the setting of Buffer spare ticket? Theoretically, the more Buffer is set, the more machines the system will tolerate downtime. However, too large Buffer setting will also have a certain impact on Redis.
Although the anti concurrency ability of Redis in memory database is very high, the request will still go through a network IO. In fact, the number of requests for Redis in the process of ticket grabbing is the total amount of local inventory and Buffer inventory.
Because when the local inventory is insufficient, the system will directly return the user's "sold out" information prompt, so the logic of unified inventory deduction will not be followed.
To a certain extent, it also avoids the huge amount of network requests from pushing Redis across. Therefore, the architect needs to carefully consider the load capacity of the system to set the Buffer value.
04
Code demonstration
Go language is originally designed for concurrency. I will use go language to show you the specific process of single machine ticket grabbing.
Initialization work
The Init function in the Go package is executed before the Main function. Some preparatory work is mainly done at this stage.
The preparations for our system include: initializing the local inventory, initializing the Hash key value of the remote Redis storage unified inventory, and initializing the Redis connection pool.
In addition, you also need to initialize an Int type Chan with a size of 1 in order to realize the function of distributed lock.
You can also directly use read-write locks or Redis and other methods to avoid resource competition, but using Channel is more efficient. This is the philosophy of Go language: do not communicate through shared memory, but share memory through communication.
Redis library uses rediso, and the following is the code implementation:
...//The localSpike package structure defines the package localSpike
type LocalSpike struct { LocalInStock int64 LocalSalesVolume int64}...//remoteSpike's definition of hash structure and redis connection pool package remoteSpike / / remote order storage key type remotespikekeys struct {spikeorderhashkey string / / second kill order hash structure key totalinventorykey string in redis / / total order inventory key quantityoforderkey string in hash structure / / existing order quantity key in hash structure}
//Initialize redis connection pool func newpool() * redis Pool { return &redis.Pool{ MaxIdle: 10000, MaxActive: 12000, // max number of connections Dial: func() (redis.Conn, error) { c, err := redis.Dial("tcp", ":6379") if err != nil { panic(err.Error()) } return c, err }, }}... func init() { localSpike = localSpike2.LocalSpike{ LocalInStock: 150, LocalSalesVolume: 0, } remoteSpike = remoteSpike2. RemoteSpikeKeys{ SpikeOrderHashKey: "ticket_hash_key", TotalInventoryKey: "ticket_total_nums", QuantityOfOrderKey: "ticket_sold_nums", } redisPool = remoteSpike2. NewPool() done = make(chan int, 1) done <- 1}Local inventory deduction and unified inventory deduction
The logic of local inventory deduction is very simple. The user requests to add the sales volume, then compares whether the sales volume is greater than the local inventory, and returns the Bool value:
package localSpike//Deduct inventory locally, return bool value func (spike * localspike) localderivationstock() bool{spike. Localsalesvolume = spike. Localsalesvolume + 1 return spike. Localsalesvolume < spike. Localinstock}
Note that the operation of shared data LocalSalesVolume here is realized by using locks, but because local inventory deduction and unified inventory deduction are atomic operations, Channel is used at the top layer, which will be discussed later.
Redis is a unified inventory deduction operation. Because redis is a single thread, we need to take data from it, write data and calculate some column steps. We need to cooperate with Lua script packaging commands to ensure the atomicity of the operation:
package remoteSpike......const LuaScript = ` local ticket_key = KEYS[1] local ticket_total_key = ARGV[1] local ticket_sold_key = ARGV[2] local ticket_total_nums = tonumber(redis.call('HGET', ticket_key, ticket_total_key)) local ticket_sold_nums = tonumber(redis.call('HGET', ticket_key, ticket_sold_key)) -- Check whether there are any remaining tickets,Increase order quantity,Return result value if(ticket_total_nums >= ticket_sold_nums) then return redis.call('HINCRBY', ticket_key, ticket_sold_key, 1) end return 0`//Remote unified inventory deduction func (remotespikekeys * remotespikekeys) remotedeductionstock (conn redis. Conn) bool {Lua: = redis. Newscript (1, luascript) result, err: = redis. Int (Lua. Do (Conn, remotespikekeys. Spikeorderhashkey, remotespikekeys. Totalinventorykey, remotespikekeys. Quantityoforderkey)) if err! = nil {return false} return result != 0}We use the Hash structure to store the information of total inventory and total sales volume. When the user requests, we judge whether the total sales volume is greater than the inventory, and then return the relevant Bool value.
Before starting the service, we need to initialize the initial inventory information of Redis:
hmset ticket_hash_key "ticket_total_nums" 10000 "ticket_sold_nums" 0
Respond to user information
We start an HTTP service and listen on one port:
package main...func main() { http.HandleFunc("/buy/ticket", handleReq) http.ListenAndServe(":3005", nil)}We have finished all the initialization work above. Next, the logic of handleReq is very clear. Judge whether the ticket is successfully robbed and return the user information.
package main//Processing request functions, Write the response result information to the log according to the request func handlereq (W http. Responsewriter, R * http. Request) {redisconn: = redispool. Get() logmsg: = "< - done / / global read-write lock if localspike. Localdeductionstock() & & remotespike. Remotedeductionstock (redisconn) {util. Respjason (W, 1," ticket grabbing succeeded ", Nil) logmsg = logmsg+ "result:1,localSales:" + strconv. Formatint (localspike. Localsalesvolume, 10)} else {util. Respjason (W, - 1, "sold out", Nil) logmsg = logmsg + "result: 0, localsales:" + strconv.formatint (localspike. Localsalesvolume, 10)} done < - 1
//Write the ticket grabbing status into the log writeLog(LogMsg, "./stat.log")}
func writeLog(msg string, logPath string) { fd, _ := os.OpenFile(logPath, os.O_RDWR|os.O_CREATE|os.O_APPEND, 0644) defer fd.Close() content := strings.Join([]string{msg, "\r\n"}, "") buf := []byte(content) fd.Write(buf)}
As mentioned earlier, we should consider the race condition when deducting inventory. Here, we use Channel to avoid concurrent reading and writing, so as to ensure the efficient sequential execution of requests. We write the return information of the interface to/ stat.log file is convenient for pressure measurement statistics.
Single machine service pressure test
When the service is started, we use AB pressure test tool to test:
ab -n 10000 -c 100 http://127.0.0.1:3005/buy/ticket
The following is the pressure measurement information of my local low configuration Mac:
-
According to the indicators, my single machine can handle 4000 + requests per second. The normal server is multi-core configuration, and there is no problem processing 1W + requests at all.
This is ApacheBench, Version 2.3 <$revision: 1826891="">Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 127.0.0.1 (be patient)Completed 1000 requestsCompleted 2000 requestsCompleted 3000 requestsCompleted 4000 requestsCompleted 5000 requestsCompleted 6000 requestsCompleted 7000 requestsCompleted 8000 requestsCompleted 9000 requestsCompleted 10000 requestsFinished 10000 requests Server Software:Server Hostname: 127.0.0.1Server Port: 3005 Document Path: /buy/ticketDocument Length: 29 bytes Concurrency Level: 100Time taken for tests: 2.339 secondsComplete requests: 10000Failed requests: 0Total transferred: 1370000 bytesHTML transferred: 290000 bytesRequests per second: 4275.96 [#/sec] (mean)Time per request: 23.387 [ms] (mean)Time per request: 0.234 [ms] (mean, across all concurrent requests)Transfer rate: 572.08 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median maxConnect: 0 8 14.7 6 223Processing: 2 15 17.6 11 232Waiting: 1 11 13.5 8 225Total: 7 23 22.8 18 239 Percentage of the requests served within a certain time (ms) 50% 18 66% 24 75% 26 80% 28 90% 33 95% 39 98% 45 99% 54 100% 239 (longest request)
In addition, it is found that the requests are normal, the traffic is uniform, and Redis is also normal during the whole service process
//stat.log...result:1,localSales:145result:1,localSales:146result:1,localSales:147result:1,localSales:148result:1,localSales:149result:1,localSales:150result:0,localSales:151result:0,localSales:152result:0,localSales:153result:0,localSales:154result:0,localSales:156...
05
Summary review
Overall, the second kill system is very complex. Here we just briefly introduce some strategies to simulate how to optimize a single machine to high performance, how to avoid a single point of failure in a cluster, and how to ensure that orders are not oversold and not oversold
The complete order system also has a task to view the order progress. Each server has a task to synchronize the remaining tickets and inventory information from the total inventory to the user regularly. In addition, the user does not pay within the order validity period, releases the order, replenishes the inventory, and so on.
We have realized the core logic of high concurrency ticket grabbing. It can be said that the system design is very ingenious and skillfully avoids the operation of DB database IO.
For the high concurrent requests of Redis network IO, almost all calculations are completed in memory, which effectively ensures that there is no oversold and many sales, and can tolerate the downtime of some machines.
***
① Load balancing, divide and conquer
Through load balancing, different traffic is divided into different machines. Each machine handles its own requests and gives full play to its performance.
In this way, the whole system can withstand high concurrency. Just like a team working, everyone gives full play to their own value, and the growth of the team is naturally great.
② Rational use of concurrency and asynchrony
Since the Epoll network architecture model solved the c10k problem, asynchrony has been more and more accepted by server developers. What can be done asynchronously can be done asynchronously, which can achieve unexpected results in function disassembly.
This is in Nginx and node Both JS and Redis can reflect the Epoll model they use to process network requests. Practice shows that single thread can still play a powerful role.
The server has entered the multi-core era. Go language, which is born for concurrency, perfectly gives play to the multi-core advantage of the server. Many tasks that can be processed concurrently can be solved by concurrency. For example, when go processes HTTP requests, each request will be executed in a Goroutine.
In short, how to reasonably squeeze the CPU and make it play its due value is the direction we always need to explore and learn.