When query time word segmentation and storage time word segmentation are not set in es Library
1, Index with default settings
Picture:
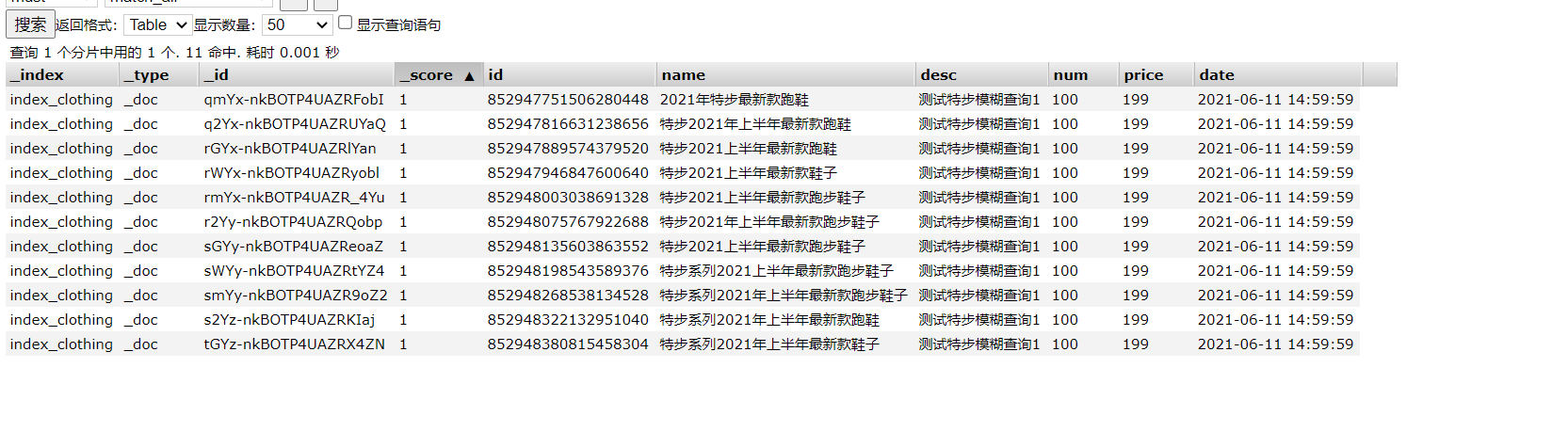
1. When querying es using MatchQueryBuilder
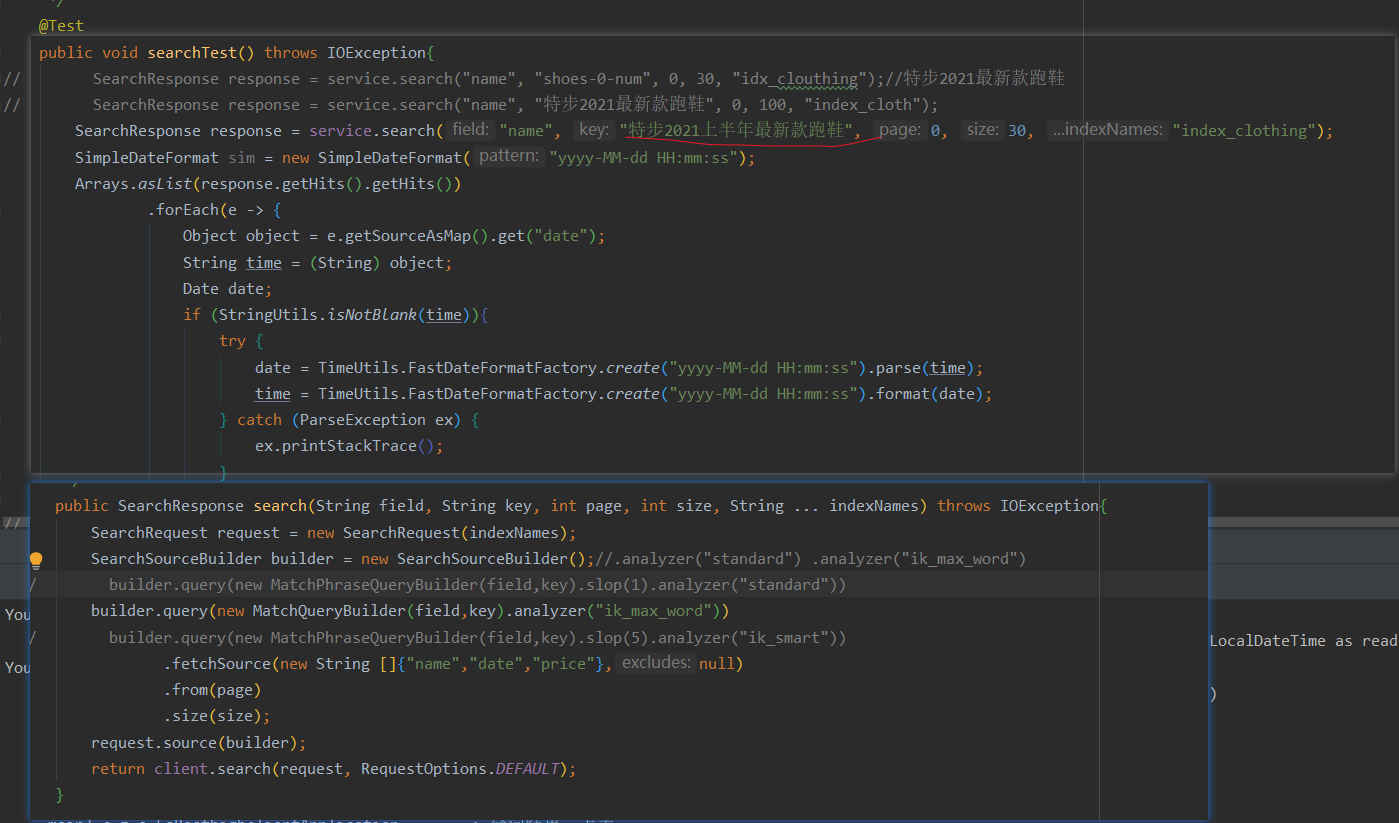
@Test
public void searchTest() throws IOException{
// SearchResponse response = service.search("name", "shoes-0-num", 0, 30, "idx_clouthing");// Tebu 2021 latest running shoes
// SearchResponse response = service.search("name", "Tebu 2021 latest running shoes", 0, 100, "index_cloth");
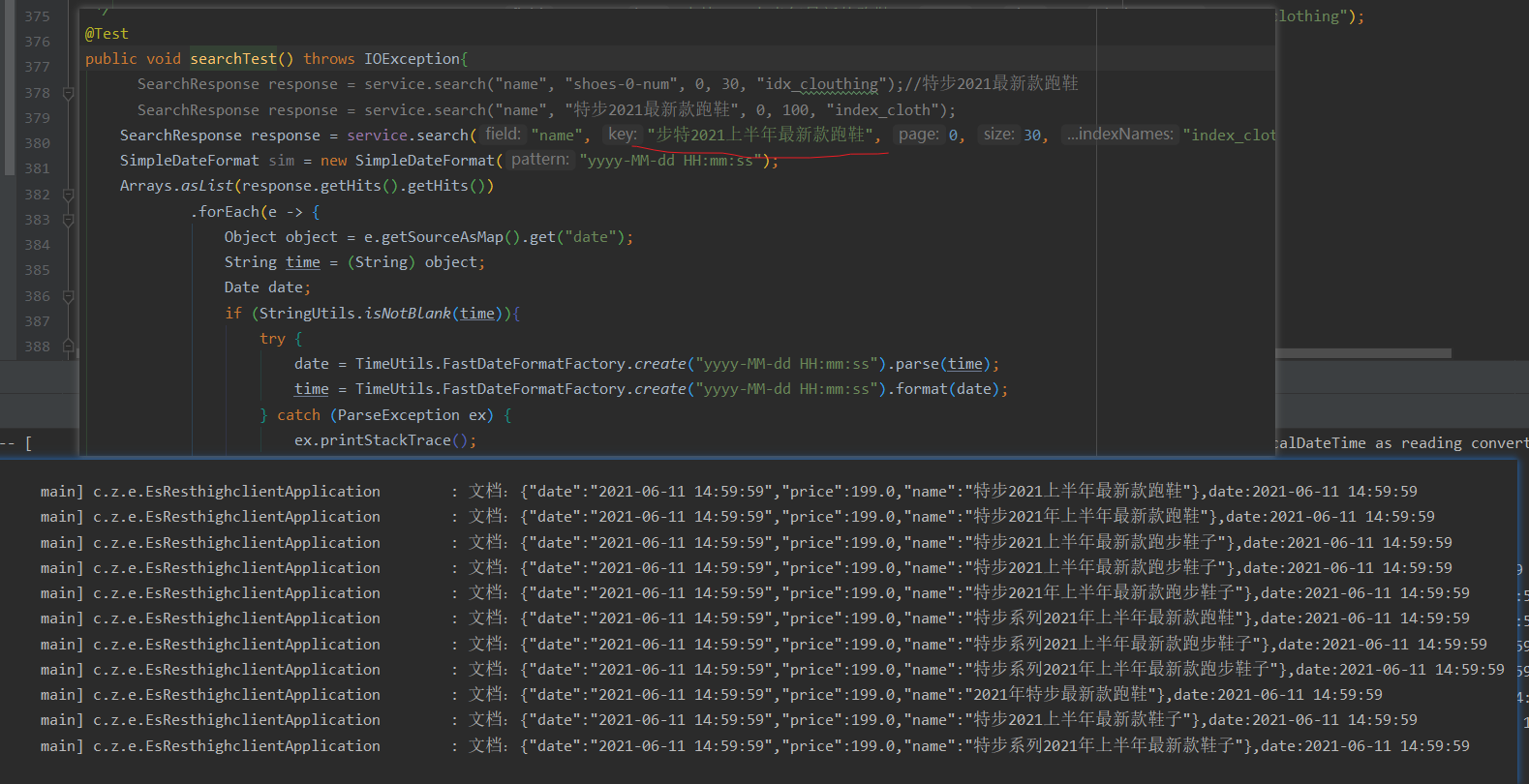
SearchResponse response = service.search("name", "Tebu's latest running shoes in the first half of 2021", 0, 30, "index_clothing");
SimpleDateFormat sim = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Arrays.asList(response.getHits().getHits())
.forEach(e -> {
Object object = e.getSourceAsMap().get("date");
String time = (String) object;
Date date;
if (StringUtils.isNotBlank(time)){
try {
date = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").parse(time);
time = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").format(date);
} catch (ParseException ex) {
ex.printStackTrace();
}
}
// DateTime dateTime = new DateTime(object);
// long millis = dateTime.getMillis();
// Date date = new Date(millis);
// String format = sim.format(date);
log.info("file:{},date:{}",e.getSourceAsString(),time);
});
}
- Use standard default word segmentation for query
The result is:
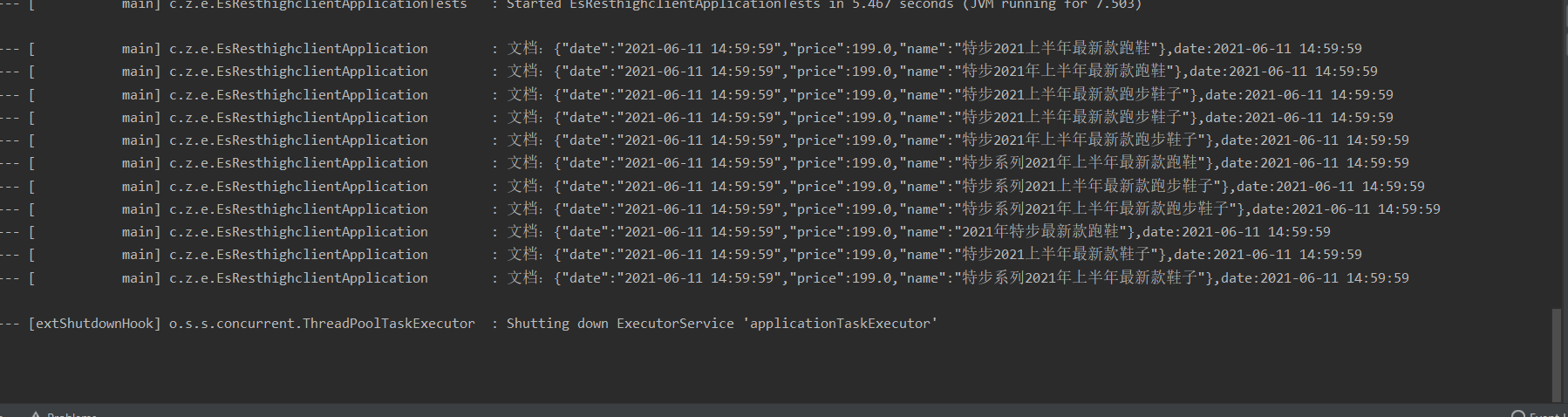
From here, you can see that all the queries are back, and then query the word segmentation results of the conditions to be queried under the default word segmentation
@Test
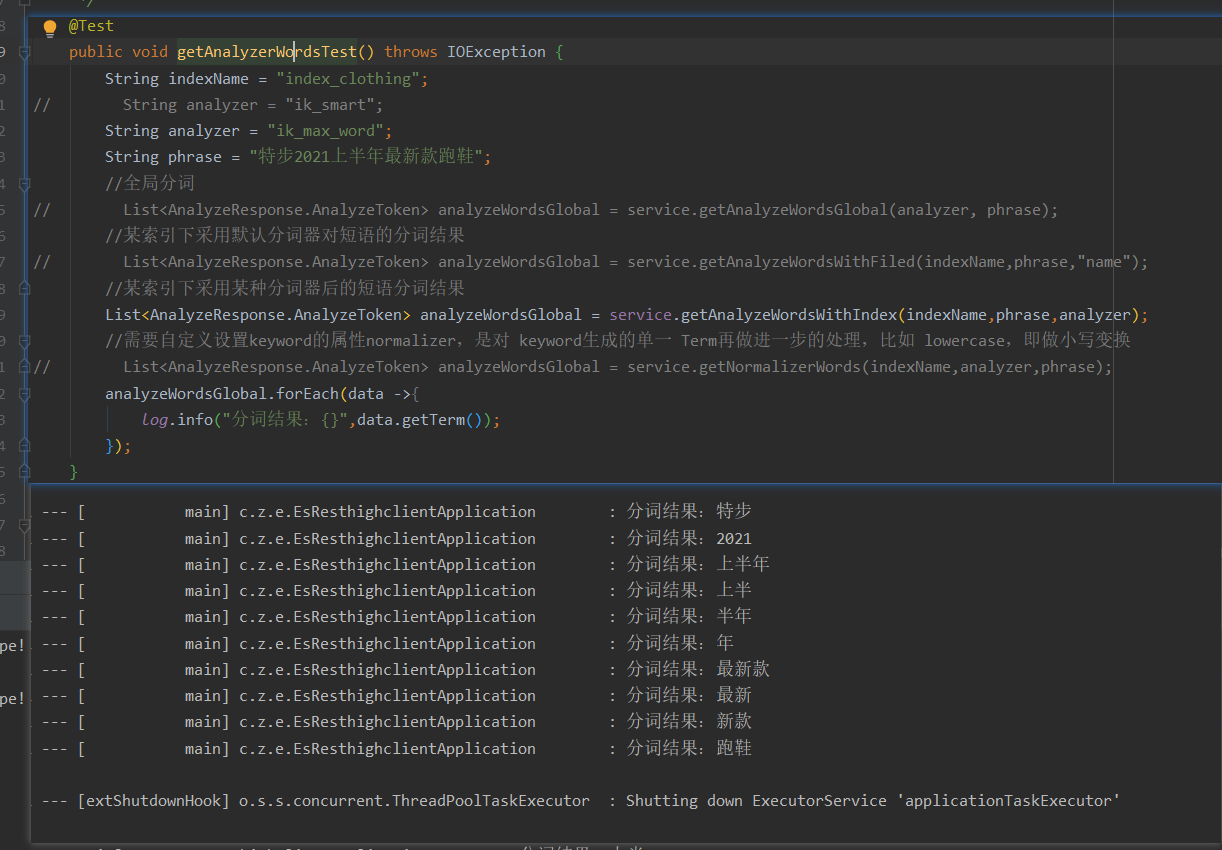
public void getAnalyzerWordsTest() throws IOException {
String indexName = "index_clothing";
// String analyzer = "ik_smart";
String analyzer = "standard";
String phrase = "Tebu's latest running shoes in the first half of 2021";
//Global word segmentation
// List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getAnalyzeWordsGlobal(analyzer, phrase);
//The result of phrase segmentation using the default participator in an index
// List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getAnalyzeWordsWithFiled(indexName,phrase,"name");
//Phrase segmentation results after using a word splitter in an index
List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getAnalyzeWordsWithIndex(indexName,phrase,analyzer);
//The attribute normalizer of keyword needs to be customized to further process the single Term generated by keyword, such as lowercase, that is, lowercase transformation
// List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getNormalizerWords(indexName,analyzer,phrase);
analyzeWordsGlobal.forEach(data ->{
log.info("Word segmentation result:{}",data.getTerm());
});
}
Word segmentation code of query criteria
/**
* Returns the result of a phrase in an index under a word splitter
* @param indexName Index name
* @param phrase Participle of phrase
* @param analyzer Word breaker type
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getAnalyzeWordsWithIndex(String indexName, String phrase, String analyzer) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withIndexAnalyzer(indexName,analyzer,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
/**
* Returns the word segmentation result of a phrase in an index under a field
* @param indexName Index name
* @param phrase Phrase to participle
* @param field Word segmentation field
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getAnalyzeWordsWithFiled(String indexName, String phrase, String field) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withField(indexName,field,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
/**
* Returns the word segmentation result of a phrase under a word splitter type under all indexes
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getAnalyzeWordsGlobal(String analyzer, String ... phrase) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withGlobalAnalyzer(analyzer,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
/**
* Returns the word segmentation result of a phrase under a Normalizer type under an index
* @param indexName Index name
* @param analyzer Word breaker type
* @param phrase Phrase to participle
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getNormalizerWords(String indexName, String analyzer,String ... phrase) throws IOException {
//normalizer is an attribute of keyword, which can further process the single Term generated by keyword, such as lowercase transformation. The usage method is similar to that of the custom word splitter, which needs to be customized
AnalyzeRequest request = AnalyzeRequest.withNormalizer(indexName,analyzer,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
The first two are probably used,
The following is the result of the default word splitter:
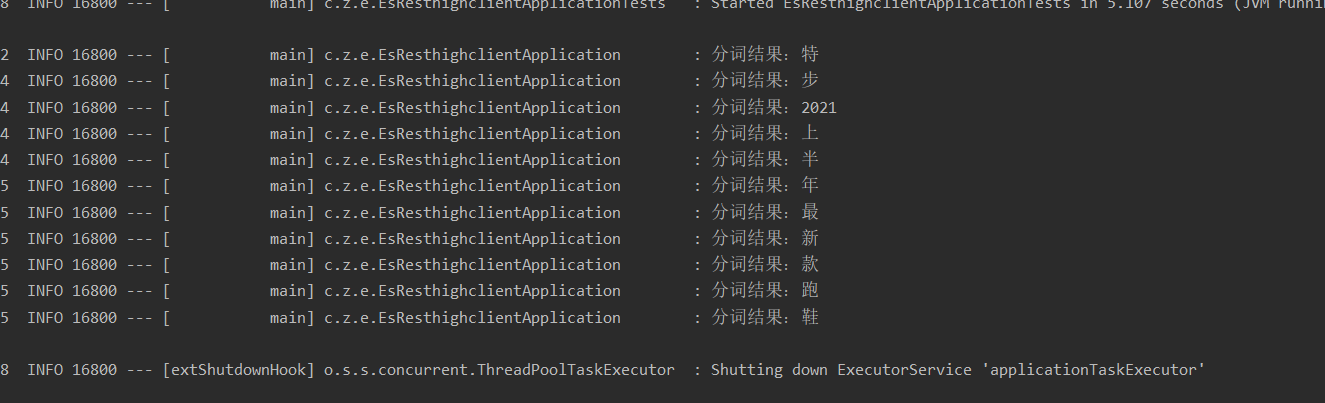
It can be seen that it is basically divided according to the number of Chinese, and the order of Chinese in the phrase seems to have no effect on the result
kibana can also be used here to query the word segmentation effect of keywords
kibana statement:
POST /index_clothing/_analyze
{
"field": "name",
"text": "2021 Tebu's latest running shoes in the first half of the year"
}
Field Description:
filed: the field in the benchmarking test index. By default, the same participle as this field is used
text: keyword content requiring word segmentation
You can also customize which word breaker "analyzer" is used for this field: "ik_smart"
Word segmentation result:
{
"tokens" : [
{
"token" : "2021",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "special",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "step",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "upper",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "half",
"start_offset" : 7,
"end_offset" : 8,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "year",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "most",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "new",
"start_offset" : 10,
"end_offset" : 11,
"type" : "<IDEOGRAPHIC>",
"position" : 7
},
{
"token" : "paragraph",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 8
},
{
"token" : "run",
"start_offset" : 12,
"end_offset" : 13,
"type" : "<IDEOGRAPHIC>",
"position" : 9
},
{
"token" : "shoes",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 10
}
]
}
Note here: there is position in the word segmentation result, which should be the position of the word after word segmentation, start_offset and end_offset is the starting position difference. The size of the following slop parameters should be related to this, but it cannot work under standard.
Generally speaking, under the default word segmentation method, the order of query keywords has nothing to do with the results. As long as the word segmentation in the field to be queried contains a word after the word segmentation of the keyword, it can be queried,
So this method seems to be a little inconsistent with the actual needs!
-
Using ik_max_word segmentation for query,
It will segment words according to the most fine-grained Chinese, and the results are as follows
Query criteria and results:
result:
The result is no different from the first one,
After changing the phrase order, the result is no difference -
Using ik_smart word splitter for query,
It will segment Chinese words according to common phrase combinations, and can customize phrase phrases in ik plug-ins, such as' old fellow 'and' 666 ', which are not traditional Chinese phrases. ik participles need to install their own configuration.
Query phrase segmentation results:
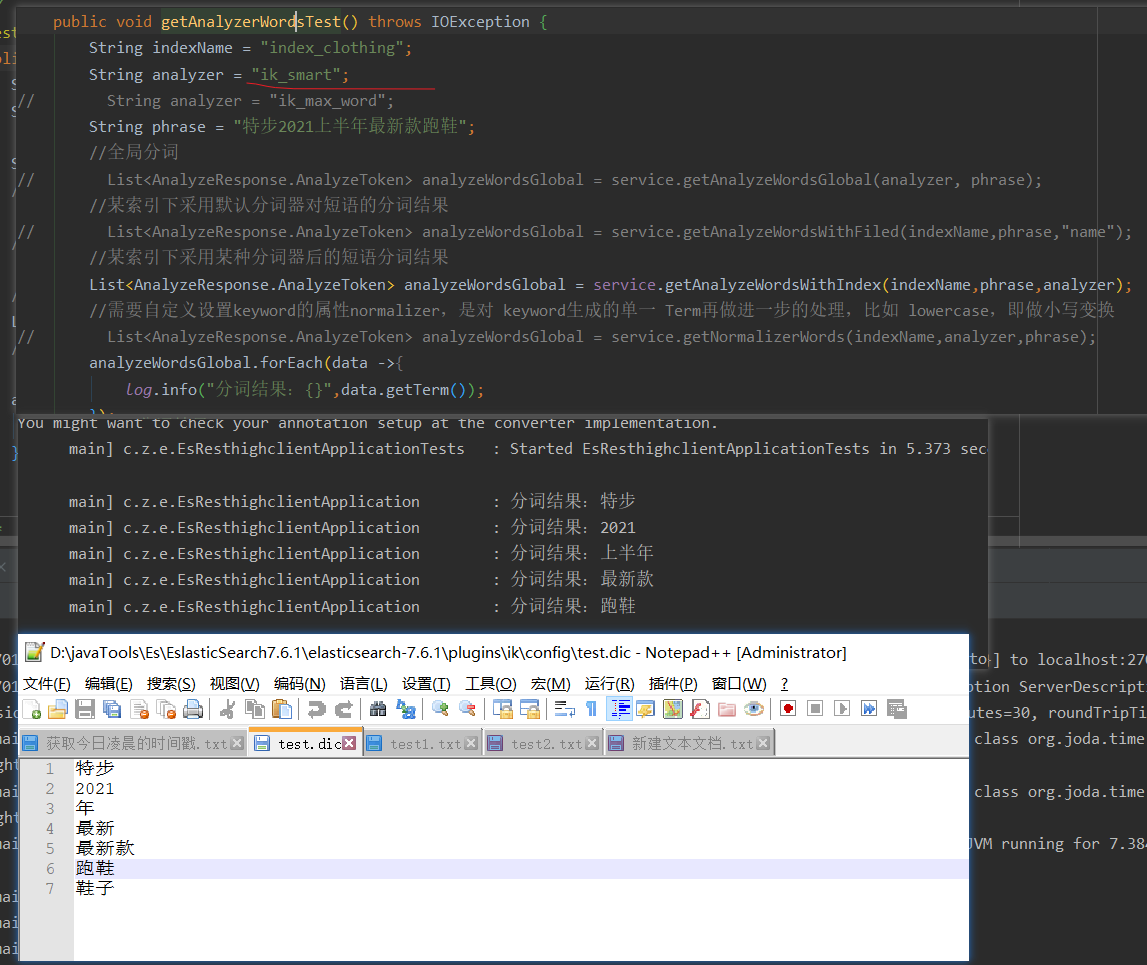
Test DIC file is my custom dictionary
Query results:
It seems that the results are the same.
It can be seen from here that the three word segmentation results under MatchQueryBuilder are similar
2. When querying es using MatchPhraseQueryBuilder
-
Use standard to query es
The phrase and word segmentation here are the same, so it's not in the map. Just paste the query results directly.
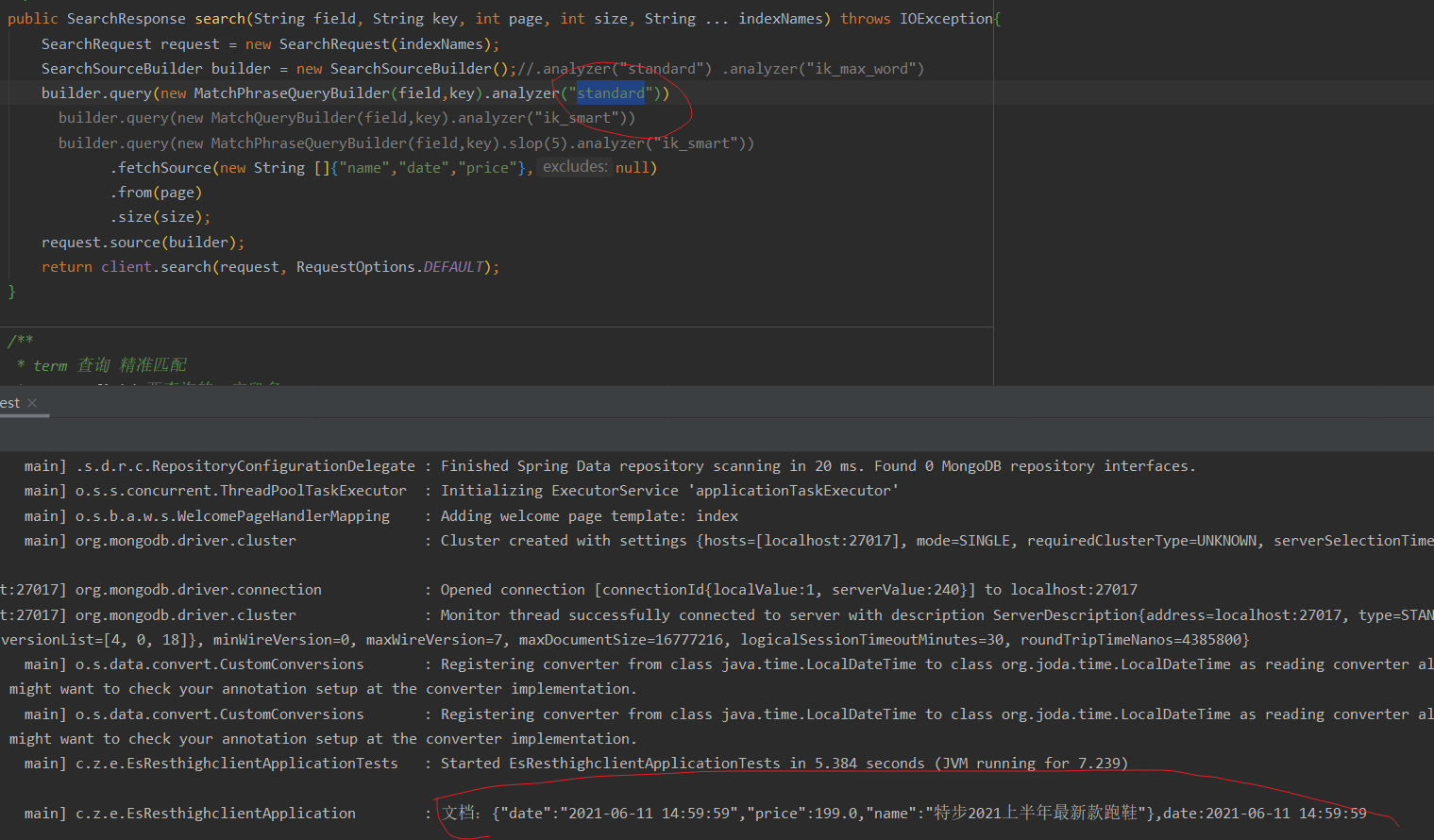
After changing the phrase order, the query, such as "the latest running shoes of Bute in the first half of 2021", found no results
However, when the slop parameter is set, 8 pieces of data can be queried, as shown in the figure:
effect:
match_ The function of phrase must be in the matched document
It includes "the latest running shoes in the first half of 2021" and the sequence interval must be consistent with the input content
What if I want the document to contain "the latest running shoes in the first half of 2021", but there are some words between them? For example, "Tebu's latest running shoes in the first half of 2021" needs to be controlled by parameters. This parameter is slop, and the value of slop means
In the phrase you enter, each term is allowed to be separated by several terms.
The general function is that 2021 and the first half of the year do not need to be next to each other. If the position after word segmentation in the first half of the year is within 20 units than that after word segmentation in 2021, it can still be queried normally (of course, the parameter numbers in this can be defined by themselves and used according to their appropriate size. If you want to know more, you can go to google). In the case of standard word splitter, There is no problem changing the order of two words. The result is the same
-
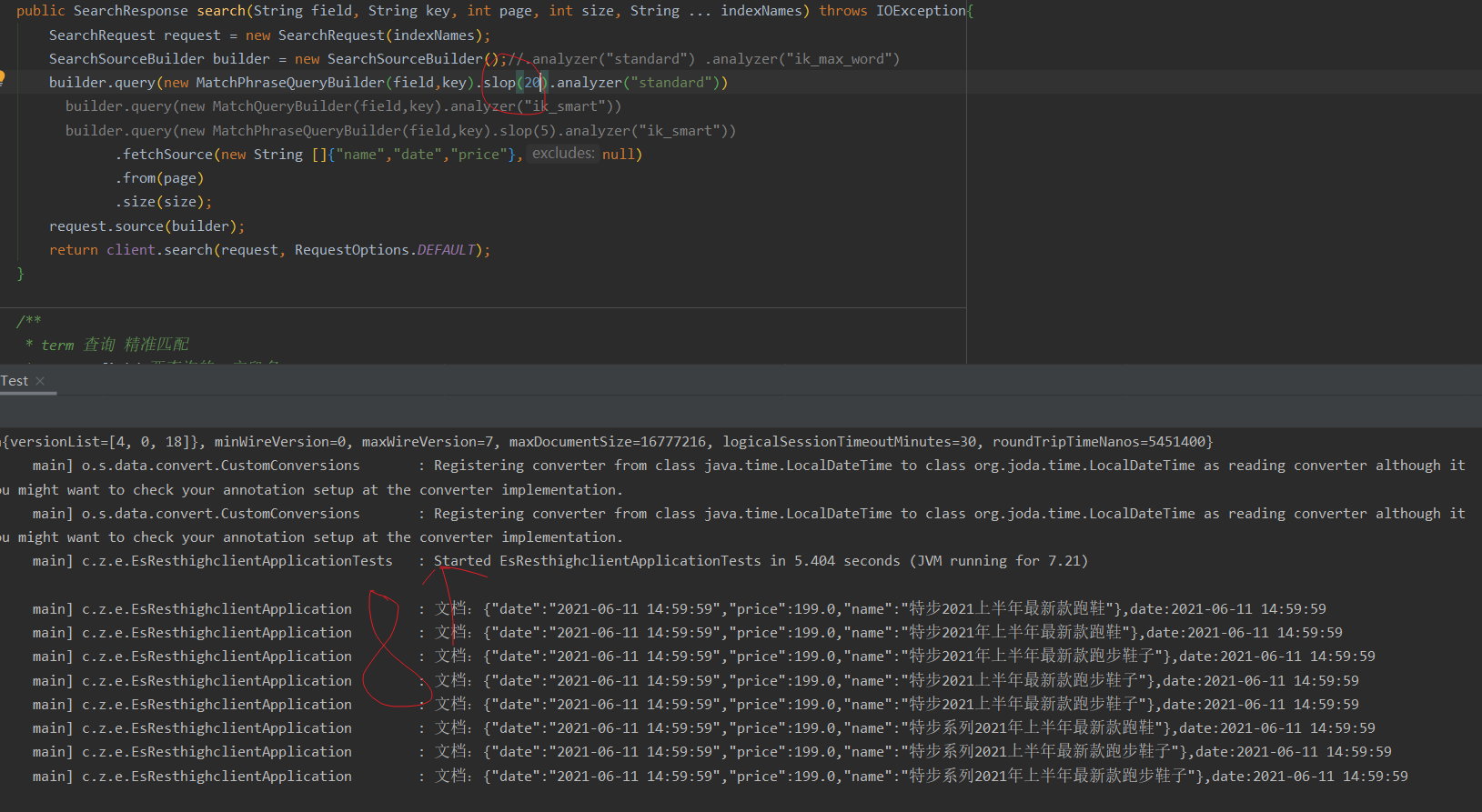
Using ik_max_word query es
Query results:
After adding the slop parameter, the query result is still not found, and the order of changing the query phrase is still not found -
Using ik_smart query es
Query result: null
After adding the slop parameter, it is null
There is no es database with query word segmentation index and word segmentation configuration during storage. From the above test results,
Data can be found after adding slop parameter in standard word segmentation mode, but ik_max_word and ik_ Why did smart add the slop method but failed to query the data? Personally, I think it is because the index is segmented according to the standard default method, but because I configured the ik word splitter and Chinese user-defined dictionary, the keyword segmentation during query does not index the result word after its own segmentation,
The comparison between the index of the field with default word segmentation and the word segmentation of query keywords is as follows:

Therefore, the default word segmentation method plus the slop parameter can be used to query, because their word segmentation results are the same. For the latter two word segmentation methods, some word segmentation results cannot be found after the field word segmentation. When the MatchPhraseQueryBuilder queries, the query phrase word segmentation results must be in the order of the field itself,
Therefore, according to the general actual situation, it is good to use MatchPhraseQueryBuilder plus the default word breaker
The index database is established after setting the configuration of query time word segmentation and storage field time word segmentation
1, When the es database searches for some fields, the keywords are ik segmented and the fields are stored in the es. The index is set after the index configuration
kibana command when I index:
PUT /index_cloth
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1,
"max_result_window" : 100000000
},
"analysis": {
"analyzer": {
"default": {
"type": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "keyword",
"ignore_above" : 32
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"price": {
"type": "float"
},
"num": {
"type": "integer"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
Index information after establishment:
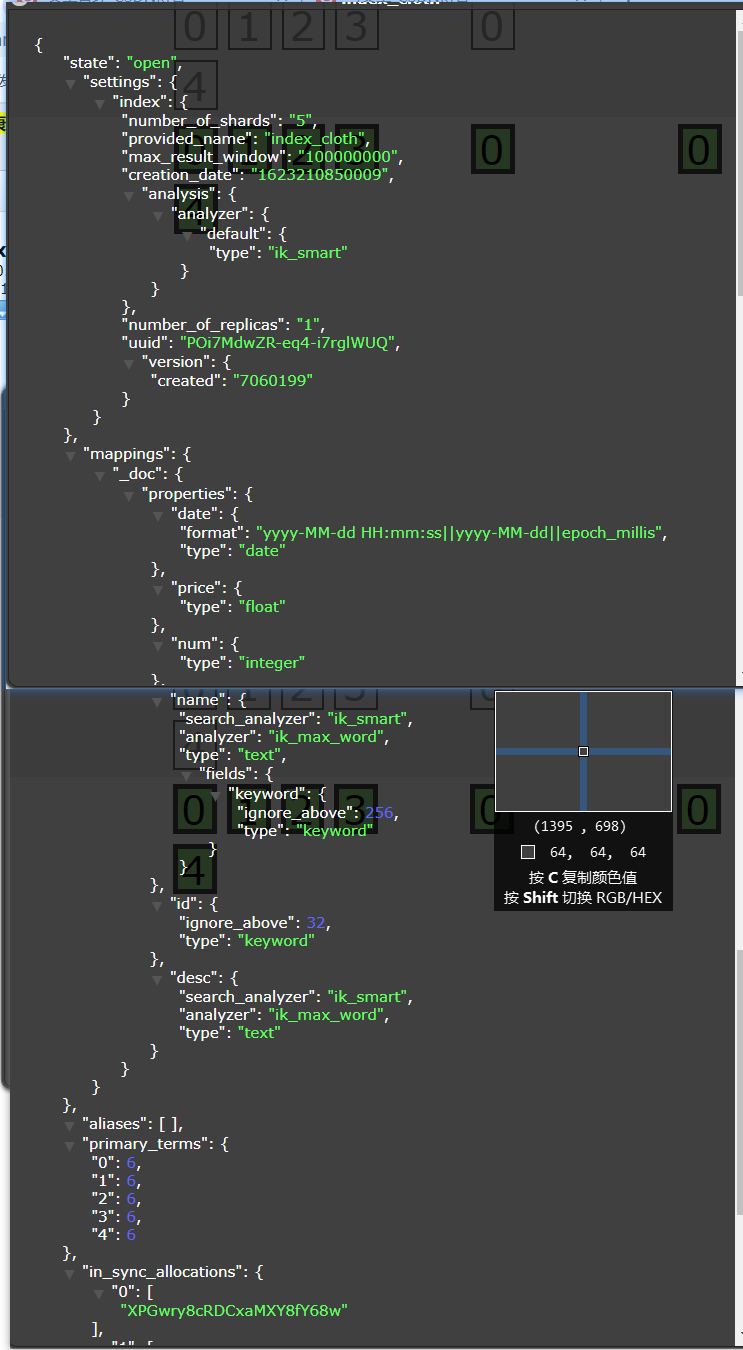
Index information code:
{
"state": "open",
"settings": {
"index": {
"number_of_shards": "5",
"provided_name": "index_cloth",
"max_result_window": "100000000",
"creation_date": "1623210850009",
"analysis": {
"analyzer": {
"default": {
"type": "ik_smart"
}
}
},
"number_of_replicas": "1",
"uuid": "POi7MdwZR-eq4-i7rglWUQ",
"version": {
"created": "7060199"
}
}
},
"mappings": {
"_doc": {
"properties": {
"date": {
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
"type": "date"
},
"price": {
"type": "float"
},
"num": {
"type": "integer"
},
"name": {
"search_analyzer": "ik_smart",
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"id": {
"ignore_above": 32,
"type": "keyword"
},
"desc": {
"search_analyzer": "ik_smart",
"analyzer": "ik_max_word",
"type": "text"
}
}
}
},
"aliases": [ ],
"primary_terms": {
"0": 6,
"1": 6,
"2": 6,
"3": 6,
"4": 6
},
"in_sync_allocations": {
"0": [
"XPGwry8cRDCxaMXY8fY68w"
],
"1": [
"NdRuwJVzSlWI8xOyRgSO8A"
],
"2": [
"jYgFnX7NRR2fy0QWxwCe8g"
],
"3": [
"zJGltD4YRBe5-bzq48-_SQ"
],
"4": [
"cINi0SkqQhGhhNFnL7aMIA"
]
}
}
Picture:
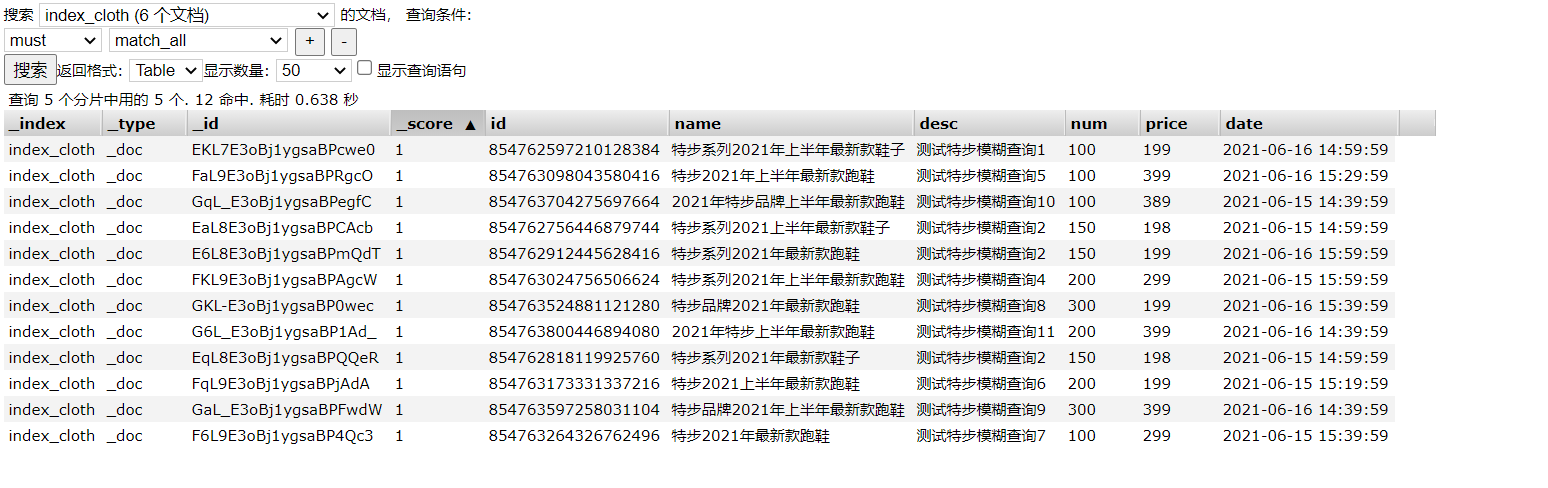
12 pieces of data in total
1. When querying es using MatchQueryBuilder
@Test
public void searchTest() throws IOException{
// SearchResponse response = service.search("name", "shoes-0-num", 0, 30, "idx_clouthing");// Tebu 2021 latest running shoes
// SearchResponse response = service.search("name", "Tebu 2021 latest running shoes", 0, 100, "index_cloth");
SearchResponse response = service.search("name", "Tebu's latest running shoes in the first half of 2021", 0, 30, "index_cloth");
SimpleDateFormat sim = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Arrays.asList(response.getHits().getHits())
.forEach(e -> {
Object object = e.getSourceAsMap().get("date");
String time = (String) object;
Date date;
if (StringUtils.isNotBlank(time)){
try {
date = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").parse(time);
time = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").format(date);
} catch (ParseException ex) {
ex.printStackTrace();
}
}
// DateTime dateTime = new DateTime(object);
// long millis = dateTime.getMillis();
// Date date = new Date(millis);
// String format = sim.format(date);
log.info("file:{},date:{}",e.getSourceAsString(),time);
});
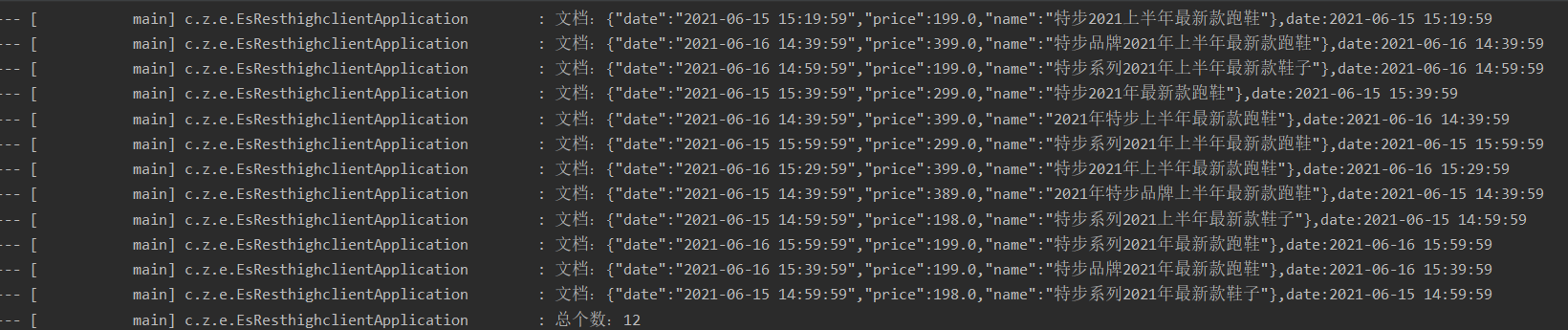
log.info("Total number:{}",response.getHits().getTotalHits().value);
}
- Use standard default word segmentation for query
The result is:
You can see from here that all the queries are back. Then query the word segmentation results of the conditions to be queried under the default word segmentation. It is found that
The keyword segmentation result here is the same as that of the library without index configuration.
Results of standard query criteria - conclusion:
It is consistent with the query result of the default configured index library, and the order of Chinese in the phrase seems to have no impact on the result. As long as the query keyword contains a word in the field text, it can be queried, which is too wide,
So this method does not meet the actual needs!
-
Using ik_max_word segmentation for query,
It will segment words according to the most fine-grained Chinese, and the results are as follows
The result of word segmentation is the same as that of setting word segmentation method without configuration storage, and there is no change
Query results:
Like the standard above, changing the order of phrases and a few words have no effect on the results. -
Using ik_smart word splitter for query,
It will segment Chinese words according to common phrase combinations, and can customize phrase phrases in ik plug-ins, such as' old fellow 'and' 666 ', which are not traditional Chinese phrases. ik participles need to install their own configuration.
The query phrase segmentation result is consistent with the query result,
It can be seen from here that the three word segmentation results under MatchQueryBuilder are similar, which is similar to the query results of the index library without setting the query word segmentation method
2. When querying es using MatchPhraseQueryBuilder
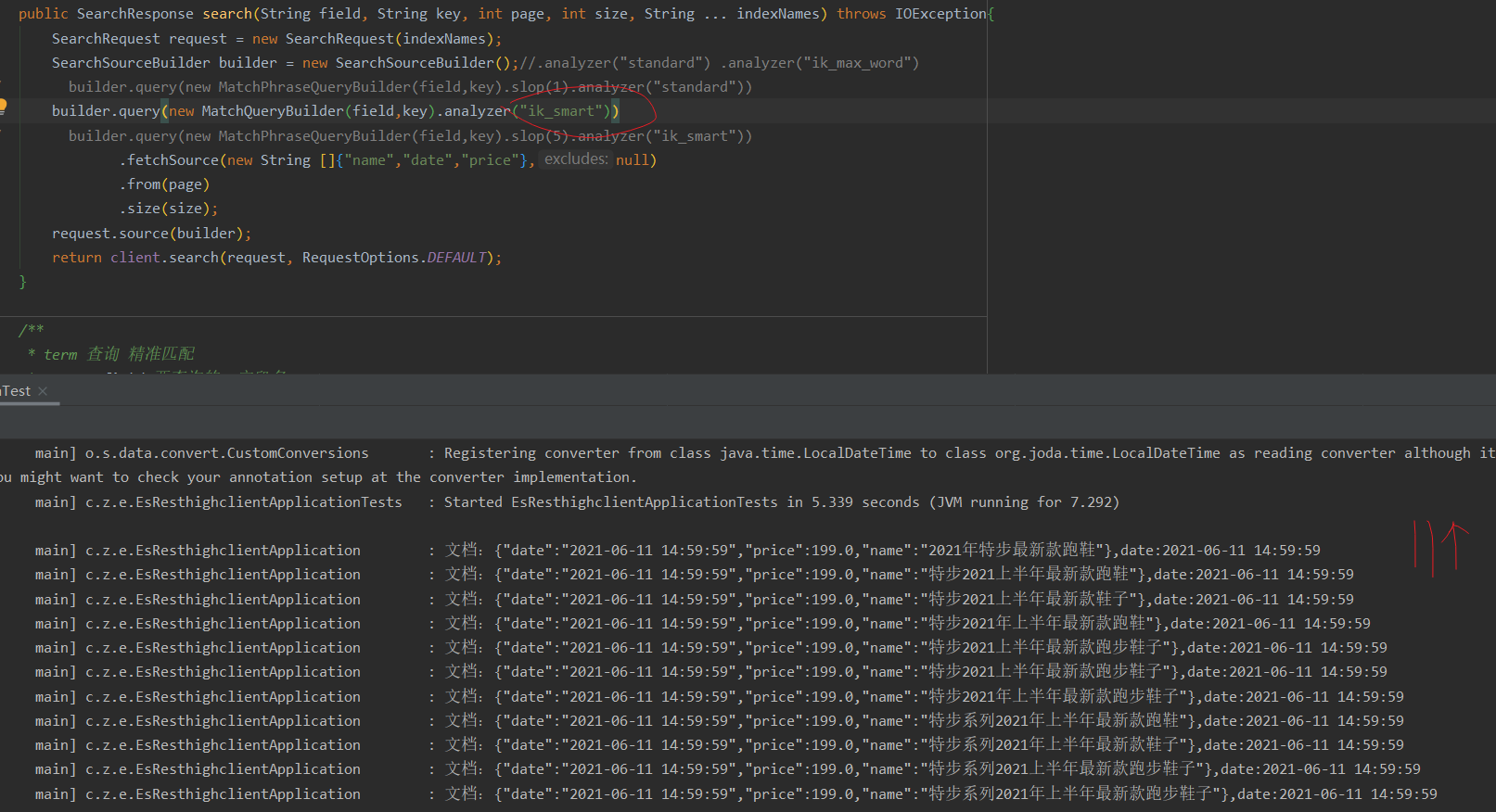
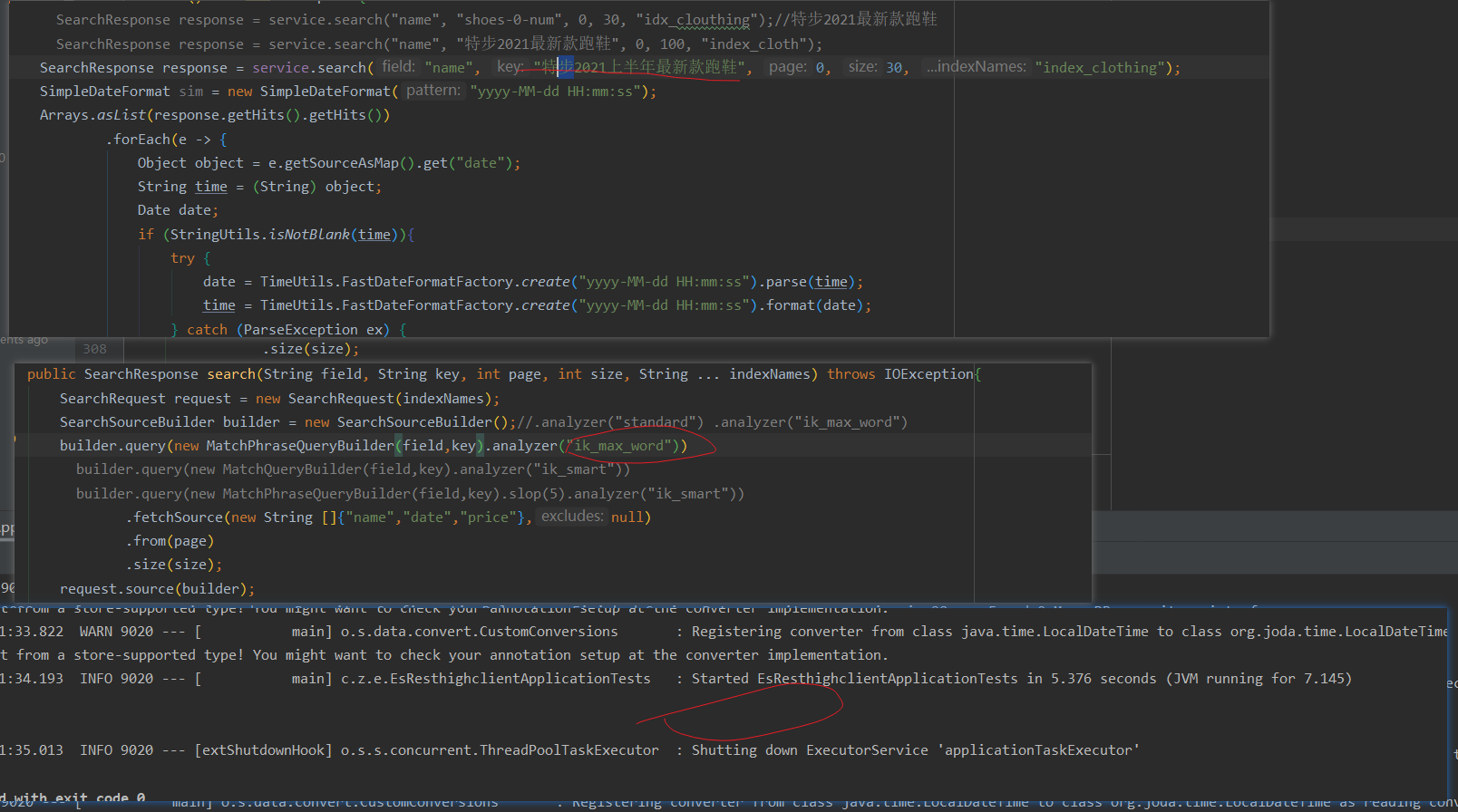
- Use standard to query es
Query statement:
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();//.analyzer("standard") .analyzer("ik_max_word")
builder.query(new MatchPhraseQueryBuilder(field,key))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
// builder.query(new MatchQueryBuilder(field,key).analyzer("ik_smart"))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
.fetchSource(new String []{"name","date","price"},null)
.from(page)
.size(size);
request.source(builder);
return client.search(request, RequestOptions.DEFAULT);
The phrase and word segmentation here are the same, so it's not in the map. Just paste the query results directly.

Conclusion: no results are found. After changing the phrase order, query, such as "the latest running shoes of Bute in the first half of 2021", no results are found
, when the slop parameter is set, the query still cannot be found. From here, it can be proved that after setting the field word segmentation method as "ik_max_word", the data cannot be found by querying the word segmentation in standard mode
- Using ik_max_word query es
Query statement:
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();//.analyzer("standard") .analyzer("ik_max_word")
builder.query(new MatchPhraseQueryBuilder(field,key).analyzer("ik_max_word"))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
// builder.query(new MatchQueryBuilder(field,key).analyzer("ik_smart"))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
.fetchSource(new String []{"name","date","price"},null)
.from(page)
.size(size);
request.source(builder);
return client.search(request, RequestOptions.DEFAULT);
Query results:

join slop After the parameter, the result is:

Change the order of query statement Keywords:
SearchResponse response = service.search("name", "2021 Tebu's latest running shoes in the first half of the year", 0, 30, "index_cloth");
The result is 0. plus slop After the parameter, the result is: It is consistent with the above result
- Using ik_smart query es
SearchResponse response = service.search("name", "Tebu's latest running shoes in the first half of 2021", 0, 30, "index_cloth");
Query results: 0 queries were found, and the order of keywords in the query statement was changed: Results and adoption ik_max_word The query method is not consistent,
The result of adding the slop parameter is that there are 6 pieces of data, and the order of the keyword of the query statement is changed. The result of adding the slop parameter is also consistent, and there are 6 pieces of data
The resulting pictures are all the following: