Reprint notes: http://www.cnblogs.com/tolimit/
summary
Recently, I was looking at memory recycling. The synchronization of memory recycling is very complex. Then I thought that the synchronization relationship in the process of page migration without memory defragmentation is so complex. I looked at the source code of page migration with curiosity. Fortunately, it is not complex and easy to understand, Here we will talk about how to synchronize in the process of page migration. But first of all, friends who may not have seen it need to look at linux memory source code analysis - memory defragmentation (I), because it will involve some knowledge.
In fact, one sentence can summarize how to synchronize during page migration, that is: I'm going to start page migration on this page. All your processes accessing this page will join the waiting queue for me, and I'll wake you up when I finish processing.
If you need to be more detailed, it is that a page will be migrated in memory defragmentation. First, the old page will be locked (set the PG_locked flag of the page), and then a new page entry data will be created. The page entry data belongs to swap type, and the page entry data maps to the old page, Then write the page entry data into all process page entries mapped to the old page, copy the old page data and parameters to the new page, and then create a new page entry data. The page entry data is the conventional page entry data, and the page entry data maps to the new page, Then write the page entry data to all previous process page entries that map the old page, release the lock and wake up the waiting process.
The whole process can be illustrated with one diagram:
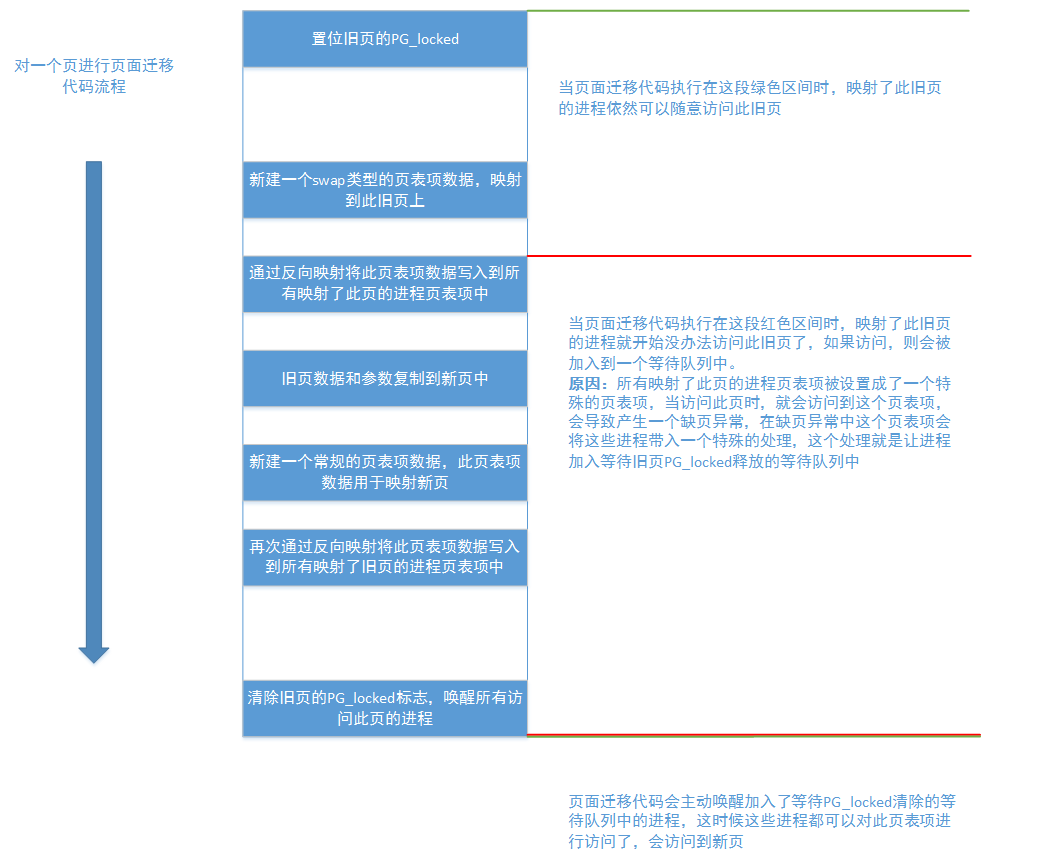
Here, let's briefly talk about the page entry data of swap type. We know that an important data stored in the page entry is the intra page offset. Another important flag bit is that the page is not in memory. When we write an anonymous page to the swap partition, the page frame occupied by the anonymous page in memory will be released. In this way, The process mapping this anonymous page cannot access the anonymous page on the disk. The kernel needs to provide some means for these processes to know that this anonymous page is not in memory, and then try to put this anonymous page in memory. The means provided by the kernel is to modify the process page table item mapped to this page into a special page table item. When the process accesses this page, this special page table item will cause a page missing exception. In the page missing exception, this special page table item will lead to the corresponding processing place. This special page table item is a page table item of swap type. There are two types of page table items of swap type. One is that it indicates that the page is not in memory, and the page table item offset is the index of the page slot of the swap partition where the anonymous page is located. This swap type page table entry can correctly lead the missing page exception and replace the anonymous page that should be replaced into memory. The other is the page table item of the page migration type we need to use. It indicates that the page is not in memory, and the offset of the page table item is the page frame number of the old page. Similarly, this page table item will lead the page missing exception, and add the process with the current page missing exception to the waiting PG of the old page_ Locked is cleared in the waiting queue.
Page migration
Next, we can go directly to the source code, because the previous articles have also analyzed a lot. In this article, we only talk about the processing of the kernel when a page starts page migration. We can directly start from__ unmap_ and_ From the move() function, this function has passed in the descriptors of the page frame to be moved and the page frame to be moved from the superior function, and provides the memory defragmentation mode. The memory defragmentation mode here will hardly have a substantive impact on our analysis, but here are some differences:
- The move mode is asynchronous and no attempt will be made to move the page_ Movable and MIGRATE_CMA type page box
- Light synchronization mode: blocking operation will be carried out (for example, if the device is busy, it will wait for a while, and if the lock is busy, it will block until the lock is obtained), but it will not block the path waiting for the completion of page writeback. It will directly skip the page being written back, and the page trying to move is MIGRATE_RECLAIMABLE,MIGRATE_MOVABLE and MIGRATE_CMA type page box
- Synchronization mode: Based on the light synchronization mode, it will block the page and wait for the page to write back, and then process the page. If necessary, the dirty file page will also be written back, and the page will be moved after the write back is completed (depending on the file system)
The page box to be moved must be MIGRATE_RECLAIMABLE,MIGRATE_MOVABLE and migrate_ One of CMA types (file page and anonymous page), and the page box to be moved in must be a free page box, and it is closer to the end of the zone than the page box to be moved.
static int __unmap_and_move(struct page *page, struct page *newpage,
int force, enum migrate_mode mode)
{
int rc = -EAGAIN;
int remap_swapcache = 1;
struct anon_vma *anon_vma = NULL;
/* Obtaining this page lock (PG_locked flag) is the key and the guarantee of synchronization in the whole recycling process
* When we unmap all processes that map this page, we will give them a special page table entry
* When these processes access this page again, they will enter the page missing exception due to accessing this special page table item, and then wait for the lock of this page to be released in the page missing exception
* When the lock of this page is released, the page migration has been completed, and the page table entries of these processes have been mapped to the new page before releasing the lock. At this time, these processes waiting for the lock of this page can be awakened
* The next time these processes access the table entry of this page, they will access the new page
*/
if (!trylock_page(page)) {
/* Asynchronous must get the lock at this time, otherwise it will return, because there is a lock below_ Page (page) obtains the lock, which may lead to blocking and waiting */
if (!force || mode == MIGRATE_ASYNC)
goto out;
if (current->flags & PF_MEMALLOC)
goto out;
/* In the case of synchronization and light synchronization, it is possible to block here in order to get the lock */
lock_page(page);
}
/* This page is being written back to disk */
if (PageWriteback(page)) {
/* Both asynchronous and light synchronous modes do not wait */
if (mode != MIGRATE_SYNC) {
rc = -EBUSY;
goto out_unlock;
}
if (!force)
goto out_unlock;
/* In synchronous mode, wait for this page to write back */
wait_on_page_writeback(page);
}
/* Anonymous pages and not used in ksm */
if (PageAnon(page) && !PageKsm(page)) {
/* Gets the anon pointed to by the anonymous page_ VMA, NULL if it is a file page */
anon_vma = page_get_anon_vma(page);
if (anon_vma) {
/*
* This page is anonymous and will not be processed
*/
} else if (PageSwapCache(page)) {
/* This page is an anonymous page that has been added to the swapcache and has been unmapped (it's here because the anon_vma is empty, which indicates that unmapping has been performed). Now there is no process mapping this page */
remap_swapcache = 0;
} else {
goto out_unlock;
}
}
/* balloon Pages used */
if (unlikely(isolated_balloon_page(page))) {
rc = balloon_page_migrate(newpage, page, mode);
goto out_unlock;
}
/* page->mapping If it is empty, there are two cases
* 1.This page is an anonymous page that has been added to the swapcache and unmap ped. Now there is no process mapping this page
* 2.For some special pages, page - > mapping is empty, but page - > private points to a buffer_head linked list (pages used by log buffer?)
*/
if (!page->mapping) {
VM_BUG_ON_PAGE(PageAnon(page), page);
/* page->private With buffer_head */
if (page_has_private(page)) {
/* Release all buffers on this page_ Head, after which this page will be recycled */
try_to_free_buffers(page);
goto out_unlock;
}
goto skip_unmap;
}
/* Establish migration ptes or remove ptes */
/* umap This page will create an SWP for migration for the process mapping this page_ entry_ t. This swp_entry_t refers to this page
* This swp_entry_t replaces the page table entry that maps this page
* Then the page descriptor of this page_ mapcount -- indicates that a process mapped reversely to cancels the mapping
*/
try_to_unmap(page, TTU_MIGRATION|TTU_IGNORE_MLOCK|TTU_IGNORE_ACCESS);
skip_unmap:
/* Copying the contents of the page to the newpage will remap the newpage to the pte of the process to which the page belongs */
if (!page_mapped(page))
rc = move_to_new_page(newpage, page, remap_swapcache, mode);
/* When in move_ to_ new_ Remove in page()_ migration_ Only when ptes() fails will it be executed here
* Here is to remap all the process page table entries mapped to the old page to the old page, that is, this memory migration failed.
*/
if (rc && remap_swapcache)
remove_migration_ptes(page, page);
/* Drop an anon_vma reference if we took one */
if (anon_vma)
put_anon_vma(anon_vma);
out_unlock:
/* Release the lock of this page (PG_locked cleared)
* After unmap, all processes accessing this page will block here and wait for the lock to be released
* After the release here, all processes accessing this page will be awakened
*/
unlock_page(page);
out:
return rc;
}
The two locks before and after this code are the focus of synchronization during page migration. You can also see from the code that this lock must be obtained before you can continue page migration. When in asynchronous mode, if the lock is not obtained, it will jump out directly and cancel the processing of this page. In light synchronization and synchronization mode, you won't die if you don't get this lock. For this function, there are only two main function entries, one try_to_unmap(), one is move_to_new_page().
try_ to_ The unmap() function is to reverse map this page and process each process page table that maps this page. Pay attention to TTU_ The migration flag indicates that the reverse mapping is for page migration, not TTU_IGNORE_MLOCK flag also means that memory defragmentation can be performed on mlock page frames in memory. As mentioned before, in try_ to_ In the unmap() function, the main work is to generate a swap type page entry data, set this page entry data as the data used for page migration, and then write this page entry data into each process page entry that maps the page to be moved. Let's enter this function to see:
int try_to_unmap(struct page *page, enum ttu_flags flags)
{
int ret;
/* Reverse mapping control structure */
struct rmap_walk_control rwc = {
/* unmap the page table to which a vma belongs
* Each time a vma is acquired, this function will be called for this vma. The first thing in the function is to judge whether the acquired vma is mapped to this page
*/
.rmap_one = try_to_unmap_one,
.arg = (void *)flags,
/* This function is executed after unmap ping a vma */
.done = page_not_mapped,
.file_nonlinear = try_to_unmap_nonlinear,
/* For the entire anon_ The red black tree of VMA is locked with read and write semaphores. The lock is AON_ rwsem of VMA */
.anon_lock = page_lock_anon_vma_read,
};
VM_BUG_ON_PAGE(!PageHuge(page) && PageTransHuge(page), page);
if ((flags & TTU_MIGRATION) && !PageKsm(page) && PageAnon(page))
rwc.invalid_vma = invalid_migration_vma;
/* It will traverse all Vmas mapped to this page. See reverse mapping for details */
ret = rmap_walk(page, &rwc);
/* No vma requires this page to be locked in memory, and page - >_ Mapcount is - 1, which means that no process has mapped this page */
if (ret != SWAP_MLOCK && !page_mapped(page))
ret = SWAP_SUCCESS;
return ret;
}
For the principle of reverse mapping, see linux memory source code analysis - memory recycling (anonymous page reverse mapping), which will not be described in detail here. Talk about this function. This function has one of the most important function pointers, rmap_one, it points to try_to_unmap_one() function, which will be called every time a vma is accessed. Whether the vma maps this page or not, the reverse mapping process is rmap_ In the walk, we don't watch it here. We mainly watch try_to_unmap_one() function:
/*
* unmap vma and page - > on this page_ Mapcount -- the page here may be a file page or an anonymous page
* page: Target page
* vma: Obtained vma
* address: page Linear address in the process address space to which the vma belongs
*/
static int try_to_unmap_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
struct mm_struct *mm = vma->vm_mm;
pte_t *pte;
pte_t pteval;
spinlock_t *ptl;
int ret = SWAP_AGAIN;
enum ttu_flags flags = (enum ttu_flags)arg;
/* First check whether this vma maps this page. If so, return the page table entry of this page in this process address space */
/* Check whether the page is mapped to the mm address space
* address Page is the linear address of the process address space to which the vma belongs. The method of obtaining is: address = vma - > VM_ pgoff + page->pgoff << PAGE_ SHIFT;
* Obtain the page table entry corresponding to this process address space through the linear address address, and then compare the page frame number mapped by the page table entry with the page frame number of page to know whether the page table entry maps this page
* The page table will be locked
*/
pte = page_check_address(page, mm, address, &ptl, 0);
/* pte If it is empty, it means that the page is not mapped to the process address space to which this mm belongs, and it jumps to out */
if (!pte)
goto out;
/* If flags does not require vma of mlock to be ignored */
if (!(flags & TTU_IGNORE_MLOCK)) {
/* If this vma requires that all pages in it be locked in memory, skip to out_mlock */
if (vma->vm_flags & VM_LOCKED)
goto out_mlock;
/* flags If the mlock release mode for vma is marked, skip to out_unmap, because this function only unmap vma */
if (flags & TTU_MUNLOCK)
goto out_unmap;
}
/* Ignore Accessed in page table entries */
if (!(flags & TTU_IGNORE_ACCESS)) {
/* Clear the Accessed flag of page table entries */
if (ptep_clear_flush_young_notify(vma, address, pte)) {
/* Clearing failed. Check whether it is 0 after clearing */
ret = SWAP_FAIL;
goto out_unmap;
}
}
/* Nuke the page table entry. */
/* Null function */
flush_cache_page(vma, address, page_to_pfn(page));
/* Get the contents of page table items, save them to pteval, and then empty the page table items */
pteval = ptep_clear_flush(vma, address, pte);
/* Move the dirty bit to the physical page now the pte is gone. */
/* If the page table entry marks this page as dirty */
if (pte_dirty(pteval))
/* Set PG of page descriptor_ Dirty tag */
set_page_dirty(page);
/* Update high watermark before we lower rss */
/* The maximum number of page frames owned by the update process */
update_hiwater_rss(mm);
/* This page is marked as "bad page". This page is used by the kernel to correct some errors. Is it used for boundary checking? */
if (PageHWPoison(page) && !(flags & TTU_IGNORE_HWPOISON)) {
/* Non large page */
if (!PageHuge(page)) {
/* If it is an anonymous page, mm of MM_ANONPAGES-- */
if (PageAnon(page))
dec_mm_counter(mm, MM_ANONPAGES);
else
/* If this page is a file page, mm is MM_FILEPAGES-- */
dec_mm_counter(mm, MM_FILEPAGES);
}
/* Set the new content of page table item as swp_entry_to_pte(make_hwpoison_entry(page)) */
set_pte_at(mm, address, pte,
swp_entry_to_pte(make_hwpoison_entry(page)));
} else if (pte_unused(pteval)) {
/* This happens in some architectures, and X86 will not call this judgment */
if (PageAnon(page))
dec_mm_counter(mm, MM_ANONPAGES);
else
dec_mm_counter(mm, MM_FILEPAGES);
} else if (PageAnon(page)) {
/* This page is anonymous */
/* Get the contents saved in page - > private and call try_ to_ Before unmap (), this page will be added to the swap cache, and then an SWP with the offset of the swap page slot will be allocated_ entry_ t */
swp_entry_t entry = { .val = page_private(page) };
pte_t swp_pte;
/* This is basically the case for memory recycling, because the page has been moved to swapcache before calling here
* For memory defragmentation,
*/
if (PageSwapCache(page)) {
/* Check whether the entry is valid
* And the corresponding page slot of entry is added in swap_ info_ Swap of struct_ Map, which indicates how many process references the page of this page slot has
*/
if (swap_duplicate(entry) < 0) {
/* Failed to check. Write back the contents of the original page table item */
set_pte_at(mm, address, pte, pteval);
/* The return value is SWAP_FAIL */
ret = SWAP_FAIL;
goto out_unmap;
}
/* entry Valid and swap_ The value of the target page slot in the map is also + + */
/* In this if case, the mm of the process to which the vma belongs is not added to the mmlist of all processes (init_mm.mmlist) */
if (list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
if (list_empty(&mm->mmlist))
list_add(&mm->mmlist, &init_mm.mmlist);
spin_unlock(&mmlist_lock);
}
/* Reduce anonymous page statistics for this mm */
dec_mm_counter(mm, MM_ANONPAGES);
/* Increase the number of page table items marked with pages in swap in the page table of this mm */
inc_mm_counter(mm, MM_SWAPENTS);
} else if (IS_ENABLED(CONFIG_MIGRATION)) {
/* This is the page migration of anonymous pages (used in memory defragmentation) */
/* If the flags are not marked, you are performing page migration this time */
BUG_ON(!(flags & TTU_MIGRATION));
/* Create an SWP for page migration for this anonymous page_ entry_ t. This swp_entry_t points to this anonymous page */
entry = make_migration_entry(page, pte_write(pteval));
}
/*
* There are two cases of this entry: the SWP saved in page - > private with the page slot offset in swap as the data_ entry_ t
* The other is an SWP used for migration_ entry_ t
*/
/* Turn entry into a page entry */
swp_pte = swp_entry_to_pte(entry);
/* Page table entries have a bit for_ PAGE_SOFT_DIRTY for kmemcheck */
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
/* The configured new page table item swp_pte is written to the page table entry */
set_pte_at(mm, address, pte, swp_pte);
/* If the page table entry indicates that the mapping is a file, it is a bug. Because anonymous pages are processed here, it mainly checks the contents in page table items_ PAGE_FILE bit */
BUG_ON(pte_file(*pte));
} else if (IS_ENABLED(CONFIG_MIGRATION) &&
(flags & TTU_MIGRATION)) {
/* This call is to migrate the file page, which will create an SWP for the process mapping this file page_ entry_ t. This swp_entry_t points to this file page */
/* Establish migration entry for a file page */
swp_entry_t entry;
/* Establish an SWP for migration_ entry_ t. For file page migration */
entry = make_migration_entry(page, pte_write(pteval));
/* Write the pte page table entry of this page table into the page table entry converted to */
set_pte_at(mm, address, pte, swp_entry_to_pte(entry));
} else
/* This page is a file page. Only the file page count of this mm --, the file page does not need to set the page table item, but only needs to empty the page table item */
dec_mm_counter(mm, MM_FILEPAGES);
/* If it is an anonymous page, the above code has modified the page table entry of the anonymous page corresponding to this process */
/* The page descriptor of this page_ Mapcount -- operation, when_ When mapcount is - 1, it means that there is no page table item mapping on this page */
page_remove_rmap(page);
/* Each process has unmap ped this page. Page - > of this page_ Count -- and judge whether it is 0. If it is 0, the page will be released. Generally, it will not be 0 here */
page_cache_release(page);
out_unmap:
pte_unmap_unlock(pte, ptl);
if (ret != SWAP_FAIL && !(flags & TTU_MUNLOCK))
mmu_notifier_invalidate_page(mm, address);
out:
return ret;
out_mlock:
pte_unmap_unlock(pte, ptl);
if (down_read_trylock(&vma->vm_mm->mmap_sem)) {
if (vma->vm_flags & VM_LOCKED) {
mlock_vma_page(page);
ret = SWAP_MLOCK;
}
up_read(&vma->vm_mm->mmap_sem);
}
return ret;
}
This function is very long because it has written in all possible reverse mapping unmap operations, such as memory recycling and page migration. It should be noted that the first thing to do in the beginning of this function is to determine whether this vma maps this page through page_check_address(), and the judgment condition is also very simple. Subtract the virtual page frame number saved by page - > index from the virtual page frame number at the beginning of the vma to get an offset in page. Add this offset to the starting linear address of the vma to get the linear address of the page in the process address space, and then find the corresponding page table item through the linear address, Whether the physical page frame number mapped in the page table item is consistent with the physical page frame number of this page, which indicates that this vma maps this page. In fact, the code involved in our page migration is not much, as follows:
......
} else if (IS_ENABLED(CONFIG_MIGRATION)) {
/* This is the page migration of anonymous pages (used in memory defragmentation) */
/* If the flags are not marked, you are performing page migration this time */
BUG_ON(!(flags & TTU_MIGRATION));
/* Create an SWP for page migration for this anonymous page_ entry_ t. This swp_entry_t points to this anonymous page */
entry = make_migration_entry(page, pte_write(pteval));
}
/*
* There are two cases of this entry: the SWP saved in page - > private with the page slot offset in swap as the data_ entry_ t
* The other is an SWP used for migration_ entry_ t
*/
/* Turn entry into a page entry */
swp_pte = swp_entry_to_pte(entry);
/* Page table entries have a bit for_ PAGE_SOFT_DIRTY for kmemcheck */
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
/* The configured new page table item swp_pte is written to the page table entry */
set_pte_at(mm, address, pte, swp_pte);
/* If the page table entry indicates that the mapping is a file, it is a bug. Because anonymous pages are processed here, it mainly checks the contents in page table items_ PAGE_FILE bit */
BUG_ON(pte_file(*pte));
} else if (IS_ENABLED(CONFIG_MIGRATION) &&
(flags & TTU_MIGRATION)) {
/* This call is to migrate the file page, which will create an SWP for the process mapping this file page_ entry_ t. This swp_entry_t points to this file page */
/* Establish migration entry for a file page */
swp_entry_t entry;
/* Establish an SWP for migration_ entry_ t. For file page migration */
entry = make_migration_entry(page, pte_write(pteval));
/* Write the pte page table entry of this page table into the page table entry converted to */
set_pte_at(mm, address, pte, swp_entry_to_pte(entry));
} else
/* This page is a file page. Only the file page count of this mm --, the file page does not need to set the page table item, but only needs to empty the page table item */
dec_mm_counter(mm, MM_FILEPAGES);
/* If it is an anonymous page, the above code has modified the page table entry of the anonymous page corresponding to this process */
/* The page descriptor of this page_ Mapcount -- operation, when_ When mapcount is - 1, it means that there is no page table item mapping on this page */
page_remove_rmap(page);
/* Each process has unmap ped this page. Page - > of this page_ Count -- and judge whether it is 0. If it is 0, the page will be released. Generally, it will not be 0 here */
page_cache_release(page);
out_unmap:
pte_unmap_unlock(pte, ptl);
if (ret != SWAP_FAIL && !(flags & TTU_MUNLOCK))
mmu_notifier_invalidate_page(mm, address);
out:
return ret;
out_mlock:
pte_unmap_unlock(pte, ptl);
if (down_read_trylock(&vma->vm_mm->mmap_sem)) {
if (vma->vm_flags & VM_LOCKED) {
mlock_vma_page(page);
ret = SWAP_MLOCK;
}
up_read(&vma->vm_mm->mmap_sem);
}
return ret;
}
The code here includes the page migration of file pages and anonymous pages. Here is through make_migration_entry() generates the swap type page table entry for page migration mentioned earlier, and then through set_pte_at() is written to the page table entry corresponding to the process. After processing here, no process can access the data in this old page. When the process tries to access this page box at this time, it will be added to the PG waiting to eliminate this page_ Locked in the waiting queue. Note here: a swap type page table item used for migration is generated according to the process page table item mapping this old page, that is, some flags in the process page table item will be saved in the swap type page table item. And both file pages and non file pages will generate a page table entry of swap type used in migration. In the process of memory recycling, this swap type page table entry will also be used, but it is not of migration type and will only be used for non file pages.
OK, at this time, all processes cannot access the old page. The following work is to create a new page and move the data parameters of the old page to the new page. This work is carried out by move_ to_ new_ The page () function is used to do this. After calling move_to_new_page() will be passed before page ()_ Mapped (page) determines whether the old page has a process mapped to it. If not, we can directly look at move_to_new_page() function:
static int move_to_new_page(struct page *newpage, struct page *page,
int remap_swapcache, enum migrate_mode mode)
{
struct address_space *mapping;
int rc;
/* Lock the new page, which should be 100% locked successfully, because this page is new and is not used by any process or module */
if (!trylock_page(newpage))
BUG();
/* Prepare mapping for the new page.*/
/* index, mapping and PG of old pages_ The swapbacked flag is copied to a new page
* It is of great significance for copying index and mapping
* Through index and mapping, you can reverse map the new page. When the new page is configured, you can reverse map the new page, find the processes that map the old page, and then map their corresponding page table entries to the new page
*/
newpage->index = page->index;
newpage->mapping = page->mapping;
if (PageSwapBacked(page))
SetPageSwapBacked(newpage);
/* Get mapping of old pages */
mapping = page_mapping(page);
/* If mapping is empty, the default migrate is executed_ page()
* Note that the process mapping this page has already unmap ped this page, and the page table entry corresponding to the process is set to point to the SWP of page (not newpage)_ entry_ t
*/
if (!mapping)
/* Anonymous pages that are not added to swapcache will be migrated here */
rc = migrate_page(mapping, newpage, page, mode);
else if (mapping->a_ops->migratepage)
/* File pages and anonymous pages added to swapcache will all be here
* For anonymous pages, swap is called_ aops->migrate_page() function, which is actually the above migrate function_ Page() function
* Depending on the file system, dirty file pages may be written back here. Only synchronous mode can write back
*/
rc = mapping->a_ops->migratepage(mapping,
newpage, page, mode);
else
/* When the file system where the file page is located does not support the migratepage() function, this default function will be called, which will write back the dirty file page, which can only be performed in the synchronization mode */
rc = fallback_migrate_page(mapping, newpage, page, mode);
if (rc != MIGRATEPAGE_SUCCESS) {
newpage->mapping = NULL;
} else {
mem_cgroup_migrate(page, newpage, false);
/* This remap_swapcache defaults to 1
* The work done here is to map all the page table items previously mapped to the old page to the new page, and the reverse mapping will be used
*/
if (remap_swapcache)
remove_migration_ptes(page, newpage);
page->mapping = NULL;
}
/* Release PG of newpage_ Locked flag */
unlock_page(newpage);
return rc;
}
There are two important functions here. One is migrate corresponding to the file system_ The page () function, one of which is remove_migration_ptes() function, for migrate_ The essence of the page () function is to copy the parameters and data of the old page to the new page, and remove_ migration_ As like as two peas, the PTEs () function is a reverse mapping of the new page (the new page has been copied from the old page, the new reverse mapping effect is exactly the same as the reverse mapping effect of the old page), and then all the process page items modified to swap type are reset to the page table items that map the new page.
Linux kernel development / Architect interview questions, learning materials, teaching videos and learning Roadmap Get here
Linux Kernel Learning: https://ke.qq.com/course/3485817?flowToken=1036460
Let's look at migrate first_ Page (), only the migrate of the anonymous page is taken here_ The page() function is described because it is relatively clear and easy to understand:
/* Anonymous pages not added to swapcache and those added to swapcache will be migrated here */
int migrate_page(struct address_space *mapping,
struct page *newpage, struct page *page,
enum migrate_mode mode)
{
int rc;
/* None of the pages have been added to the swapcache, let alone being written back */
BUG_ON(PageWriteback(page)); /* Writeback must be complete */
/* The main work of this function is if the old page is added to address_ In the base tree of space, replace the slot of the old page with a new page, and add address to the new page_ In the base tree of space
* And the PG of the old anonymous page will be synchronized_ Swapcache flag and private pointer content to new page
* Page - > for old pages_ Count -- (remove from base tree)
* Page - > is displayed for the new page_ Count + + (add to base tree)
*/
rc = migrate_page_move_mapping(mapping, newpage, page, NULL, mode, 0);
if (rc != MIGRATEPAGE_SUCCESS)
return rc;
/* A newpage that copies the contents of a page
* Then copy some flags
*/
migrate_page_copy(newpage, page);
return MIGRATEPAGE_SUCCESS;
}
There are two more functions, migrate_page_move_mapping() and migrate_page_copy(), first look at the first one, migrate_ page_ move_ The function of mapping () is to put the old page in address_ Replace the data in the base tree node of space with a new page:
/* The main work of this function is if the old page is added to address_ In the base tree of space, replace the slot of the old page with a new page, and add address to the new page_ In the base tree of space
* And the PG of the old anonymous page will be synchronized_ Swapcache flag and private pointer content to new page
* For anonymous pages not added to swapcache, head = NULL, extra_count = 0
*/
int migrate_page_move_mapping(struct address_space *mapping,
struct page *newpage, struct page *page,
struct buffer_head *head, enum migrate_mode mode,
int extra_count)
{
int expected_count = 1 + extra_count;
void **pslot;
/* Here, we mainly judge the old anonymous pages that are not added to the swapcache
* For old anonymous pages that are not added to the swapcache, as long as page - >_ If count is 1, migration can be performed directly
* page->_count It means that only the isolation function is + +, and this page is not referenced elsewhere
* page->_count If it is 1, directly return MIGRATEPAGE_SUCCESS
*/
if (!mapping) {
/* Anonymous page without mapping */
if (page_count(page) != expected_count)
return -EAGAIN;
return MIGRATEPAGE_SUCCESS;
}
/* The following is the case when page - > mapping is not empty */
/* Lock the base tree in mapping */
spin_lock_irq(&mapping->tree_lock);
/* Get the slot in the base tree where this old page is located */
pslot = radix_tree_lookup_slot(&mapping->page_tree,
page_index(page));
/* Add address for_ Old pages in the base tree of space
* Judge page - >_ Is count 2 + page_has_private(page)
* If correct, go to the next step
* If not, the old page may be mapped by a process
*/
expected_count += 1 + page_has_private(page);
if (page_count(page) != expected_count ||
radix_tree_deref_slot_protected(pslot, &mapping->tree_lock) != page) {
spin_unlock_irq(&mapping->tree_lock);
return -EAGAIN;
}
/* Judge again here, and only judge page - > here_ Is count 2 + page_has_private(page)
* If so, keep going
* If not, the old page may be mapped by a process
*/
if (!page_freeze_refs(page, expected_count)) {
spin_unlock_irq(&mapping->tree_lock);
return -EAGAIN;
}
if (mode == MIGRATE_ASYNC && head &&
!buffer_migrate_lock_buffers(head, mode)) {
page_unfreeze_refs(page, expected_count);
spin_unlock_irq(&mapping->tree_lock);
return -EAGAIN;
}
/* If you get here, the above code comes to the conclusion that page is the address pointed to by page - > mapping_ In the base tree of space, and no process maps this page
* Therefore, the following is to replace the slot where the old page data is located with the new page data
*/
/* New page - >_ Count + +, because the new page will replace the slot where the old page is located later */
get_page(newpage);
/* If it is an anonymous page, this anonymous page must have been added to swapcache */
if (PageSwapCache(page)) {
/* Set the new page in the swapcache. The old page will be replaced later, and the new page will be added to the swapcache */
SetPageSwapCache(newpage);
/* Copy the address pointed to by the private of the old page to the private of the new page
* For the pages added to the swap cache, this item saves the SWP indexed by the page slot of the swap partition_ entry_ t
* Note here the SWP that writes the process page table entry when unmap during memory defragmentation_ entry_ The difference of T is that SWP is written to the process page table entry during memory defragmentation_ entry_ T refers to the old page
*/
set_page_private(newpage, page_private(page));
}
/* Replace the slot of the old page with the new page data */
radix_tree_replace_slot(pslot, newpage);
/* Set page - > of old page_ Count is expected_count - 1
* This - 1 is because this old page is already from address_ Out of the base tree of space
*/
page_unfreeze_refs(page, expected_count - 1);
/* Note that the anonymous pages added to the swapcache are also counted as Nr_ FILE_ Number of pages */
__dec_zone_page_state(page, NR_FILE_PAGES);
__inc_zone_page_state(newpage, NR_FILE_PAGES);
if (!PageSwapCache(page) && PageSwapBacked(page)) {
__dec_zone_page_state(page, NR_SHMEM);
__inc_zone_page_state(newpage, NR_SHMEM);
}
spin_unlock_irq(&mapping->tree_lock);
return MIGRATEPAGE_SUCCESS;
}
And migrate_page_copy() is very simple. Copy the data of the old page to the new page through memcpy(), and then copy some parameters of the old page to the page descriptor of the new page:
/* A newpage that copies the contents of a page
* Then copy some flags
*/
void migrate_page_copy(struct page *newpage, struct page *page)
{
int cpupid;
if (PageHuge(page) || PageTransHuge(page))
/* Large page call */
copy_huge_page(newpage, page);
else
/* Ordinary page call is mainly to permanently map the linear address assigned to two page cores, and then do memcpy to copy the contents of the old page to the new page
* For 64 bit machines, there is no need to use permanent mapping and memcpy directly
*/
copy_highpage(newpage, page);
/* Copy of page flag */
if (PageError(page))
SetPageError(newpage);
if (PageReferenced(page))
SetPageReferenced(newpage);
if (PageUptodate(page))
SetPageUptodate(newpage);
if (TestClearPageActive(page)) {
VM_BUG_ON_PAGE(PageUnevictable(page), page);
SetPageActive(newpage);
} else if (TestClearPageUnevictable(page))
SetPageUnevictable(newpage);
if (PageChecked(page))
SetPageChecked(newpage);
if (PageMappedToDisk(page))
SetPageMappedToDisk(newpage);
/* If the page is marked with a dirty page */
if (PageDirty(page)) {
/* Clear the dirty page flag of old pages */
clear_page_dirty_for_io(page);
/* Set the dirty page flag for new pages */
if (PageSwapBacked(page))
SetPageDirty(newpage);
else
__set_page_dirty_nobuffers(newpage);
}
/* Or copy some flags */
cpupid = page_cpupid_xchg_last(page, -1);
page_cpupid_xchg_last(newpage, cpupid);
/* Here is also a copy of some signs
* Mainly PG_ Mllocked and ksm stable_node
*/
mlock_migrate_page(newpage, page);
ksm_migrate_page(newpage, page);
/* Clear several flags of the old page, which have been assigned to the new page before */
ClearPageSwapCache(page);
ClearPagePrivate(page);
set_page_private(page, 0);
/*
* If any waiters have accumulated on the new page then
* wake them up.
*/
/* This is mainly used to wake up those waiting for a new page */
if (PageWriteback(newpage))
end_page_writeback(newpage);
}
Well, here, in fact, the whole new page has been set, but because of the relationship between page table items, no process can access the new page. The last processing process is to re set the page table items of those processes to map to the new page. This work is the move listed in the front_ to_ new_ Remove () in page_ migration_ Ptes() function, in remove_ migration_ In ptes(), there is also a reverse mapping:
static void remove_migration_ptes(struct page *old, struct page *new)
{
/* Reverse mapping control structure */
struct rmap_walk_control rwc = {
/* This function is called every time a vma is acquired */
.rmap_one = remove_migration_pte,
/* rmap_one The last parameter of is the old page box */
.arg = old,
.file_nonlinear = remove_linear_migration_ptes_from_nonlinear,
};
/* Reverse mapping traversal vma function */
rmap_walk(new, &rwc);
}
Just look at remove here_ migration_ Pte() function, which is not difficult. Look at it directly:
static int remove_migration_pte(struct page *new, struct vm_area_struct *vma,
unsigned long addr, void *old)
{
struct mm_struct *mm = vma->vm_mm;
swp_entry_t entry;
pmd_t *pmd;
pte_t *ptep, pte;
spinlock_t *ptl;
/* The new page is a large page (the size of the new page is the same as that of the old page, which means that the old page is also a large page) */
if (unlikely(PageHuge(new))) {
ptep = huge_pte_offset(mm, addr);
if (!ptep)
goto out;
ptl = huge_pte_lockptr(hstate_vma(vma), mm, ptep);
} else {
/* The new page is a normal 4k page */
/* This addr is the linear address corresponding to new and old in the process address space. New and old will have the same linear address because new is copied from old */
/* Get the page middle directory entry corresponding to the linear address addr */
pmd = mm_find_pmd(mm, addr);
if (!pmd)
goto out;
/* Obtain the corresponding page table entry pointer according to the page middle directory entry and addr */
ptep = pte_offset_map(pmd, addr);
/* Gets the lock of the directory entry in the middle of the page */
ptl = pte_lockptr(mm, pmd);
}
/* Lock */
spin_lock(ptl);
/* Get page table item content */
pte = *ptep;
/* If the page table item content is not a page table item content of swap type (the page migration page table item belongs to a page table item of swap type), prepare to jump out */
if (!is_swap_pte(pte))
goto unlock;
/* Convert memory to SWP according to page table entry_ entry_ T type */
entry = pte_to_swp_entry(pte);
/* If this entry is not an entry of page migration type, or the page pointed to by this entry is not an old page, it indicates a problem and is ready to jump out */
if (!is_migration_entry(entry) ||
migration_entry_to_page(entry) != old)
goto unlock;
/* Page of new page - >_ count++ */
get_page(new);
/* Create a new page table item content according to the new page */
pte = pte_mkold(mk_pte(new, vma->vm_page_prot));
/* This seems to have something to do with numa. Don't pay attention to it first. It's harmless */
if (pte_swp_soft_dirty(*ptep))
pte = pte_mksoft_dirty(pte);
/* Recheck VMA as permissions can change since migration started */
/* If the obtained entry is marked with a mapping page, it can be written */
if (is_write_migration_entry(entry))
/* Add a writable flag to the page table item of the new page */
pte = maybe_mkwrite(pte, vma);
#ifdef CONFIG_HUGETLB_PAGE
/* Don't look at the big page first */
if (PageHuge(new)) {
pte = pte_mkhuge(pte);
pte = arch_make_huge_pte(pte, vma, new, 0);
}
#endif
flush_dcache_page(new);
/* Write the content of the set page table item of the new page into the corresponding page table item. Here, this page table item originally mapped to the old page, but now it has mapped to the new page */
set_pte_at(mm, addr, ptep, pte);
/* Big page, don't read it first */
if (PageHuge(new)) {
if (PageAnon(new))
hugepage_add_anon_rmap(new, vma, addr);
else
page_dup_rmap(new);
/* For anonymous pages */
} else if (PageAnon(new))
/* Mainly for page - >_ Count + +, because there is one more process mapping this page */
page_add_anon_rmap(new, vma, addr);
else
/* For the file page, it is also for page - >_ Count + +, because there is one more process mapping this page */
page_add_file_rmap(new);
/* No need to invalidate - it was non-present before */
/* Refresh tlb */
update_mmu_cache(vma, addr, ptep);
unlock:
/* Release lock */
pte_unmap_unlock(ptep, ptl);
out:
return SWAP_AGAIN;
}
OK, I've gone through the whole process here, but we found that there is no process of releasing the old page frame in the whole process. In fact, the function of the old page frame release process at the beginning__ unmap_and_move() because this old page is isolated from lru. So after it has been migrated to a new page, its page - >_ Count is 1. When lru is put back from the isolated state, this page - >_ Count –, and the system will find page - > in this page box_ If the count is 0, it will be released directly to the partner system.
Finally, let's take a brief look at the path taken in page missing interruption when the process sets the page migration page table item of swap type. Because the previous path is too long, I mainly list the following path, and the previous path is: do_ page_ fault() -> __ do_ page_ fault() -> handle_ mm_ fault() -> __ handle_ mm_ fault() -> handle_ pte_ fault() -> do_swap_page(); Finally to do_swap_page() to see how to handle it. Here is only a part of the code:
static int do_swap_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
spinlock_t *ptl;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
int locked;
int exclusive = 0;
int ret = 0;
if (!pte_unmap_same(mm, pmd, page_table, orig_pte))
goto out;
entry = pte_to_swp_entry(orig_pte);
/* This entry is not a swap type entry, but this page entry is a swap type page entry */
if (unlikely(non_swap_entry(entry))) {
/* Is the entry of the page migration type */
if (is_migration_entry(entry)) {
/* Enter processing */
migration_entry_wait(mm, pmd, address);
} else if (is_hwpoison_entry(entry)) {
ret = VM_FAULT_HWPOISON;
} else {
print_bad_pte(vma, address, orig_pte, NULL);
ret = VM_FAULT_SIGBUS;
}
goto out;
}
.......
Well, there will be migration in the end_ entry_ Wait() function:
void migration_entry_wait(struct mm_struct *mm, pmd_t *pmd,
unsigned long address)
{
/* Acquire a lock (not a lock) */
spinlock_t *ptl = pte_lockptr(mm, pmd);
/* Get the corresponding page table item with page missing exception */
pte_t *ptep = pte_offset_map(pmd, address);
/* handle */
__migration_entry_wait(mm, ptep, ptl);
}
Look down__ migration_entry_wait():
static void __migration_entry_wait(struct mm_struct *mm, pte_t *ptep,
spinlock_t *ptl)
{
pte_t pte;
swp_entry_t entry;
struct page *page;
/* Lock */
spin_lock(ptl);
/* Page table item content corresponding to page table item */
pte = *ptep;
/* If it is not the page table item content of the corresponding swap type, it is an error
* Note that the page table item content of page migration belongs to swap type
* However, the entry type of page migration is not a swap type
*/
if (!is_swap_pte(pte))
goto out;
/* Page table item content is converted to swp_entry_t */
entry = pte_to_swp_entry(pte);
/* If it is not the entry type of page migration, an error occurs */
if (!is_migration_entry(entry))
goto out;
/* entry The specified page descriptor. This page is the old page, that is, the page to be moved */
page = migration_entry_to_page(entry);
/* Page - > of this page_ count++ */
if (!get_page_unless_zero(page))
goto out;
/* Release lock */
pte_unmap_unlock(ptep, ptl);
/* If PG on this page_ If locked is set, it will join the waiting queue of this page and wait for this bit to be cleared */
wait_on_page_locked(page);
/* After a period of blocking, here PG_locked is cleared, page - >_ count-- */
put_page(page);
return;
out:
pte_unmap_unlock(ptep, ptl);
}
See the wait behind_ on_ page_ locked(page):
static inline void wait_on_page_locked(struct page *page)
{
if (PageLocked(page))
wait_on_page_bit(page, PG_locked);
}
Now we know why the page table item of page migration type needs to take the old page as the page table item offset, so as to facilitate obtaining the page descriptor of the old page and adding it to the waiting PG_locked is cleared in the waiting queue.
Finally, summarize the process:
-
Set PG of old page_ locked
-
Reverse map the old page and process each process page table item that maps this page
- Generate a swap type page table item for migration based on the process page table item of the old page (both file pages and non file pages will be allocated). Here, the process page table item of the old page needs to be used, which is equivalent to saving some flags in the process page table item of the old page into this swap type page table item
- Write the page table entry of swap type used by this migration to the process page table entry that maps this page.
-
Call the migration function to realize migration, copy the page descriptor data and intra page data of the old page to the new page, and handle pages in different states differently
- Not added to address_ Pages in space are copied directly using the default migration function
- Add to address_ Pages in space do not use the default migration function, but use address_ The migration function in space mainly updates the old page in address_space to point to a new page
-
Reverse map the new page and remap the process page table item previously modified as the swap page table item of the portable type to the new page. Since the data in the page descriptor of the new page is consistent with the old page, reverse mapping can be carried out. Then, through the linear address of the page in different process vma, the corresponding page table item can be found, and then judge whether the page table item is a page table item of portable swap type and points to the old page (it is not mapped to the old page here), You can determine whether the vma of this process has mapped old pages before migration.
-
Clear PG of old pages_ Locked flag
-
On the upper layer, the old page will be released.