👉 Write in front 👈
The origin of this article is that when I searched the Python interview questions of major websites, I found that some of the interview questions in most articles are too basic (not installed by the author) 🍺 Ha), if you don't believe it, look below.
 |
|---|
Others are even more powerful. I don't know where to copy. They often open 110 Python interview questions..
Then the author sorted out some valuable topics on CSDN, Github and other platforms. Some of the topics were adapted according to my own experience. At the same time, use ☆ to indicate the difficulty of the topic. If the content is wrong, please leave a message under the comment area. Thank you very much!!
1. How to output a Fibonacci sequence within 100 in Python?
Difficulty: ★★☆☆☆
>>> a, b = 0, 1 >>> while b < 100: print(b, end=' ') a, b = b, a + b 1 1 2 3 5 8 13 21 34 55 89
2. What is a lambda function? What are the benefits of it?
Difficulty: ★★☆☆☆
lambda function is a function that can receive any number of parameters (including optional parameters) and return a single expression value. lambda functions cannot contain commands. They cannot contain more than one expression.
3. Please briefly describe the difference between is and = = in Python.
Difficulty: ★★☆☆☆
An object in Python contains three elements: id, type, and value. Is compares the IDs of two objects== The value of two objects is compared.
4. Please briefly describe the meaning of * args and * * kwargs in function(*args, **kwargs)?
Difficulty: ★★☆☆☆
*Args and * * kwargs are mainly used for function defined parameters. Python language allows an indefinite number of parameters to be passed to a function, where * args represents a variable parameter list of non key value pairs and * * kwargs represents an indefinite number of key value pair parameter lists. Note: * args and * * kwargs can be in the function definition at the same time, but * args must precede * * kwargs.
5. Please briefly describe the object-oriented__ new__ And__ init__ The difference between.
Difficulty: ★★★☆☆
(1) __ new__ There must be at least one parameter cls, which represents the current class. This parameter is automatically recognized by the Python interpreter when instantiating.
(2) __ new__ Return the generated instance, and you can return the parent class (through super (current class name, cls))__ new__ Out of the instance, or directly the object__ new__ Examples are given. This is implemented by programming__ new__ Pay special attention when.
(3) __ init__ There is a parameter self, which is this__ new__ Returned instance__ init__ In__ new__ Some other initialization actions can be completed on the basis of__ init__ No return value is required.
(4) If__ new__ An instance of the current class is created and will be called automatically__ init__ , Through the call in the return statement__ new__ The first parameter of the function is cls to ensure that it is the current class instance. If it is the class name of other classes, the instances of other classes are actually created and returned, and the current class or other classes will not be called__ init__ Function.
6. When a python subclass inherits from multiple parent classes, if multiple parent classes have methods with the same name, which method will the subclass inherit from?
Difficulty: ★☆☆☆☆
The methods of subclasses in Python language to inherit the parent class are determined according to the sequence of the inherited parent classes. For example, subclass A inherits from parent classes B and C, and there are methods with the same name in B and C, then the Test() method in A actually inherits from the Test() method in B.
7. Judge whether two strings are isomorphic.
Difficulty: ★★☆☆☆
String isomorphism means that all characters in string s can be replaced by all characters in t. While preserving the character order, all characters that appear must be replaced with another character. Two characters in s cannot be mapped to the same character in T, but characters can be mapped to themselves. Try to determine whether the given strings S and T are isomorphic.
For example:
s = "paper"
t = "title"
Output True
s = "add"
t = "apple"
Output False
>>> s = 'app' >>> t = 'add' >>> len(set(s)) == len(set(t)) == len(set(zip(s, t))) True
8. please write regular expressions matching the Chinese mainland mobile phone number and ending not 4 and 7.
Difficulty: ★★☆☆☆
>>> import re
>>> tel = '15674899231'
>>> "Effective" if (re.match(r"1\d{9}[0-3,5-6,8-9]", tel) != None) else "invalid"
'Effective'
9. Use recurrence formula to convert matrix [[1,2], [3,4], [5,6]] into one-dimensional vector.
Difficulty: ★☆☆☆☆
>>> a = [[1, 2], [3, 4], [5, 6]] >>> [j for i in a for j in i] [1, 2, 3, 4, 5, 6]
10. Write Python program and print asterisk pyramid.
Difficulty: ★★☆☆☆
Write a Python program as short as possible to print the asterisk pyramid. For example, when n=5, the following pyramid graphics are output:
* *** ***** ******* *********
>>> n = 5
>>> for i in range(1, n + 1):
print(' '*(n-(i-1))+'*'*(2*i-1))
*
***
*****
*******
*********
11. Method of generating random integers, random decimals and decimals between 0 and 1.
Difficulty: ★★☆☆☆
>>> import random
>>> import numpy as np
>>> print('Positive integer:', random.randint(1, 10))
Positive integer: 2
>>> print('5 Random decimals:', np.random.randn(5))
5 Random decimals: [ 0.76768263 -0.3587897 0.04880354 -0.02443411 0.73785606]
>>> print('0-1 Random decimal:', random.random())
0-1 Random decimal: 0.24387235868905555
12. List [1, 2, 3, 4, 5], use the map() function to output [1, 4, 9, 16, 25], and then obtain the number greater than 10 through the list derivation.
Difficulty: ★★☆☆☆
>>> lst = [1, 2, 3, 4, 5] >>> map(lambda x: x**2, lst) <map object at 0x000002B37C9D88B0> >>> [n for n in res if n > 10] [16, 25]
13. De duplicate the string and sort the output from large to small.
Difficulty: ★★☆☆☆
>>> s = 'aabcddeff' >>> set_s = set(list(s)) >>> list_s = sorted(list(set_s), reverse=True) >>> ''.join(list_s) 'fedcba'
14. The dictionary is sorted from large to small according to the key; Sort values from large to small.
Difficulty: ★★☆☆☆
dic = {'a': 2, 'b': 1, 'c': 3, 'd': 0}
lst1 = sorted(dic.items(), key=lambda x: x[0], reverse=False)
# [('a', 2), ('b', 1), ('c', 3), ('d', 0)]
lst2 = sorted(dic.items(), key=lambda x: x[1], reverse=False)
# [('d', 0), ('b', 1), ('a', 2), ('c', 3)]
res_dic1 = {key: value for key, value in lst1}
res_dic2 = {key: value for key, value in lst2}
print('In descending order:', res_dic1)
print('In descending order of value:', res_dic2)
# Descending by key: {a ': 2,' B ': 1,' C ': 3,'d': 0}
# In descending order of values: {d ': 0,' B ': 1,' a ': 2,' C ': 3}
15. Count the number of occurrences of each letter in the string, and obtain the two letters with the most occurrences and their occurrences.
Difficulty: ★★★☆☆
>>> from collections import Counter
>>> s = 'aaaabbbccd'
>>> Counter(s).most_common(2)
[('a', 4), ('b', 3)]
16. The filter method obtains the multiple of 3 in 1 - 10.
Difficulty: ★★☆☆☆
>>> list(filter(lambda x: x % 3 == 0, list(range(1, 10)))) [3, 6, 9]
17. What types are a = (1), b = (1), c = ('1') respectively.
Difficulty: ★★☆☆☆
>>> type((1))
<class 'int'>
>>> type((1,))
<class 'tuple'>
>>> type(('1'))
<class 'str'>
18.x = 'abc', y = 'def', z = ['d ',' e ',' f '], write the results of x.join (y) and x.join (z).
Difficulty: ★★☆☆☆
>>> x = 'abc' >>> y = 'def' >>> z = list(y) >>> x.join(y) 'dabceabcf' >>> x.join(z) 'dabceabcf'
19.s = 'Jingxiang language 100 points, Jingxiang mathematics 100 points', replace the first "Jingxiang" with "fat tiger".
Difficulty: ★★☆☆☆
>>> s = 'Jingxiang Chinese 100 points, Jingxiang math 100 points'
>>> s.replace('Jingxiang', 'Fat tiger', 1)
'Fat tiger language 100 points, Jingxiang math 100 points'
20. Write down several common exceptions and their meanings.
Difficulty: ★★★☆☆
- IOError: input / output exception
- AttributeError: an attempt was made to access an attribute that an object does not have
- ImportError: unable to import module or package / object
- Indentation error: Code indentation error
- IndexError: subscript index out of bounds
- KeyError: an attempt was made to access a key that does not exist in the mapping
- Syntax error: Python syntax error
- NameErrir: object not declared / initialized (no properties)
- TabError: mixed use of Tab and space
- ValueError: invalid parameter passed in
- Overflow error: numeric operation exceeds the maximum limit
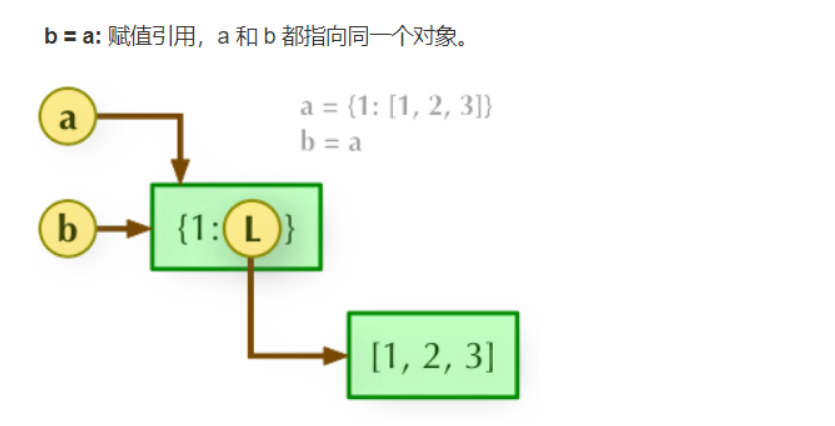
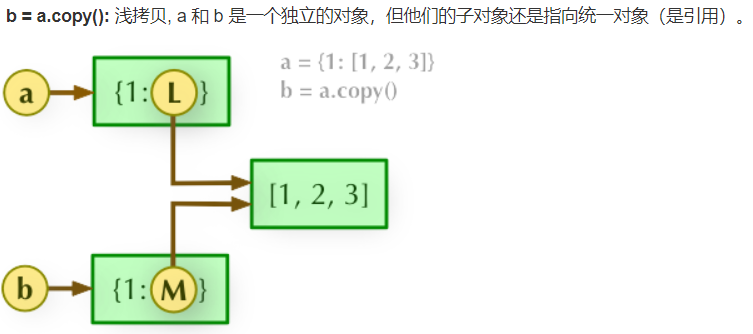
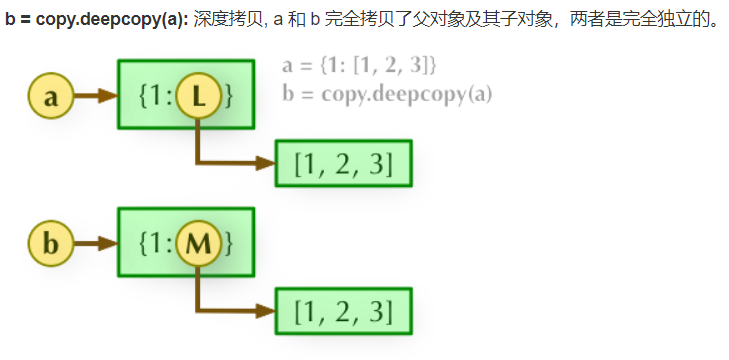
21. Explain the difference between direct assignment, shallow copy and deep copy?
Difficulty: ★★★★★
(1) Direct assignment, just passing the reference of the object. If the original list changes, the assigned object will make the same change.
(2) For shallow copy, there is no copy sub object, so if the original data sub object changes, the copied sub object will also change.
(3) Deep copy includes the copy of sub objects in the object, so the change of the original object will not cause the change of any sub elements of deep copy berry. The two are completely independent.
Here is an example:
import copy
primary_list = [1,2,3,[1,2]]
list1 = primary_list
list2 = primary_list.copy()
list3 = copy.deepcopy(primary_list)
# --Direct assignment--
list1.append('a')
list1[3].append('b')
print(primary_list,'address:',id(primary_list))
print(list1,'address:',id(list1))
# [1, 2, 3, [1, 2, 'b'], 'a'] address: 238116701856
# [1, 2, 3, [1, 2, 'b'], 'a'] address: 238116701856
# --Shallow copy--
list2.append('a')
list2[3].append('b')
print(primary_list,'address:',id(primary_list))
print(list2,'address:',id(list2))
# [1, 2, 3, [1, 2, 'b']] address: 2693332999552
# [1, 2, 3, [1, 2, 'b'], 'a'] address: 2693332999680
# --Deep copy--
list3.append('a')
list3[3].append('b')
print(primary_list,'address:',id(primary_list))
print(list3,'address:',id(list3))
# [1, 2, 3, [1, 2]] address: 262776888384
# [1, 2, 3, [1, 2, 'b'], 'a'] address: 26277688448
 |
|---|
 |
 |
22. Use lambda function to sort lst = [-1, -5, 2, -3, 1, 4, -4, 3, -2, 5]. The sorting result should be positive (from small to large) and negative (from large to small), such as [1, 2, 3, 4, 5, - 1, - 2, - 3, - 4, 5].
Difficulty: ★★★☆☆
>>> lst = [-1, -5, 2, -3, 1, 4, -4, 3, -2, 5] >>> lst.sort(key=lambda x: (x < 0, abs(x))) # lst = sorted(lst, key=lambda x: (x < 0, abs(x))) >>> lst [1, 2, 3, 4, 5, -1, -2, -3, -4, -5]
23. Sort the [{age ': 18,' class': 2}, {age ': 21,' class': 1}, {age ': 19,' class': 2}, {age ': 19,' class': 1}] list by age and class.
Difficulty: ★★★☆☆
>>> lst = [{'age': 18, 'class': 2}, {'age': 21, 'class': 1}, {'age': 19, 'class': 2}, {'age': 19, 'class': 1}]
>>> lst.sort(key=lambda x: (x['age'], x['class']))
>>> lst
[{'age': 18, 'class': 2}, {'age': 19, 'class': 1}, {'age': 19, 'class': 2}, {'age': 21, 'class': 1}]
24. What are the mutable and immutable types in Python and how are they different?
Difficulty: ★★☆☆☆
(1) Variable types include list, dict; Immutable types are str, int, tuple.
(2) When modifying, the variable type passes the address in memory, that is, directly modifying the value in memory without opening up new memory.
(3) When the immutable type is changed, it does not change the value in the original memory address, but opens up a new memory, copies the value in the original address, and operates on the value in the newly opened memory.
25. Write the way you know how to combine two dictionaries into a new dictionary.
Difficulty: ★★★★★
# Example:
dict1 = {'name': 'Jingxiang', 'age': 18}
dict2 = {'name': 'Jingxiang', 'sex': 'female'}
# After merger
res = {'name': 'Jingxiang', 'age': 18, 'sex': 'female'}
1. Update
dict1.update(dict2)
2. Dictionary derivation
res = {k: v for dic in [dict1, dict2] for k, v in dic.items()}
3. Element splicing
res = dict(list(dict1.items()) + list(dict2.items()))
4.itertools.chain
chain() can link a list, such as lists / tuples / iterables; Returns the iterables object.
from itertools import chain res = dict(chain(dict1.items(), dict2.items()))
5.collections.ChainMap
collections.ChainMap can combine multiple dictionaries or maps into a single mapping structure logically
from collections import ChainMap res = dict(ChainMap(dict2, dict1))
6. Dictionary splitting
In Python 3 In 5 +, the dictionary can be split in the following way:
res = {**dict1, **dict2}
26. Read the contents of the file into the list by line
Difficulty: ★★☆☆☆
with open('somefile.txt') as f:
content = [line.strip() for line in f] # Remove the leading and trailing white space characters
27. Usage of Python built-in functions any() and all().
Difficulty: ★★☆☆☆
(1) The any(iterable) function accepts an iteratable object iterable as a parameter. If any element in iterable is True, it returns True; otherwise, it returns false. False if iterable is empty.
(2) The all(iterable) function accepts an iteratable object iterable as a parameter. If all elements in iterable are True, it returns True; otherwise, it returns False. Returns True if iterable is empty.
28. Talk about the garbage collection mechanism in Python
Difficulty: ★★★★★
Python GC mainly uses reference counting to track and recycle garbage. On the basis of reference counting, the possible circular reference problem of container objects is solved by "mark and sweep", and the garbage collection efficiency is improved by "generation collection" exchanging space for time.
1. Reference count
PyObject is a necessary content of each object, where ob_refcnt is the reference count. When an object has a new reference, its ob_refcnt will increase. When the object referencing it is deleted, its ob_refcnt will decrease, and when the reference count is 0, the object's life is over. advantage:
- simple
- Real time disadvantages:
- Maintaining reference counts consumes resources
- Circular reference
2. Mark clear mechanism
The basic idea is to allocate on demand first. When there is no free memory, start from the references on the register and program stack, traverse the graph composed of objects as nodes and references as edges, mark all accessible objects, and then clean the memory space to release all unmarked objects.
3. Generation technology
The overall idea of generational recycling is to divide all memory blocks in the system into different sets according to their survival time, and each set becomes a "generation". The garbage collection frequency decreases with the increase of the survival time of the "generation". The survival time is usually measured by several garbage recycling. Python defines three generations of object collections by default. The larger the index number, the longer the object lives.
For example: when some memory blocks M are still alive after three times of garbage collection, we will divide the memory block M into A set A, and the newly allocated memory will be divided into set B. When garbage collection starts, in most cases, only collection B is garbage collected, while collection A is garbage collected after A long time, which reduces the memory required by the garbage collection mechanism and naturally improves the efficiency. In this process, some memory blocks in set B will be transferred to set A due to their long survival time. Of course, there are also some garbage in set A, and the collection of these garbage will be delayed due to this generational mechanism.
29. What is the difference between match() and search() in Python's re module?
Difficulty: ★★★☆☆
(1) match(pattern, string[, flags]) in the re module to check whether the beginning of the string matches the pattern.
(2) In the re module, research(pattern, string[, flags]) searches for the first matching value of pattern in string.
import re
print(re.match('super', 'superstition').span())
# (0, 5)
print(re.match('super', 'insuperable'))
# None
print(re.search('super', 'superstition').span())
# (0, 5)
print(re.search('super', 'insuperable').span())
# (2, 7)
30. When reading files, you will use read(), readline() or readlines() to briefly describe their respective functions.
Difficulty: ★★★☆☆
read() reads the entire file at a time. It is usually used to put the contents of the file into a string variable. If you want to output line by line, you can use readline(). This method will load the contents of the file into memory, so it will consume memory resources for reading large files. At this time, you can use the readlines method to generate a producer from the file handle and then read it.
31. Explain what a closure is?
Difficulty: ★★☆☆☆
Define another function inside the function, and the function uses the variables of the outer function, then this function and some variables used are called closures.
32. Conditions for stopping recursive functions
Difficulty: ★★☆☆☆
The termination condition of recursion is generally defined inside the recursive function. Before recursive call, make a condition judgment. According to the judgment result, choose whether to continue calling itself or return to return to terminate recursion.
Conditions for termination:
-
Determine whether the number of recursions reaches a certain limit.
-
Judge whether the result of the operation reaches a certain range, etc.
33. What is the difference between (g.*d) and (g.*?d) when Python regular matches "good study, day, day up"?
Difficulty: ★★★☆☆
-
(. *) is greedy matching
-
(.*?) It's a lazy match
>>> import re
>>> s = 'good good study, day day up!'
>>> print('Greedy model: ', re.findall('g.*d', s))
Greedy model: ['good good study, day d']
>>> print('Lazy mode: ', re.findall('g.*?d', s))
Lazy mode: ['good', 'good']
34. Briefly describe interpretive and compiled programming languages?
Difficulty: ★★★☆☆
Compiled language: use a special compiler to compile the high-level language source code into machine code that can be executed by the hardware of the platform at one time, and package it into the format of executable program recognized by the platform.
Features: before the program written in compiled language is executed, a special compilation process is needed to compile the source code into machine language files
Execution mode: source code - > compile (compile once) - > object code - > execute (execute multiple times) - > output
Interpretive language: use a special interpreter to interpret the source program line by line into the machine code of a specific platform and execute it immediately.
Features: the interpretive language does not need to be compiled in advance. It directly interprets the source code into machine code and executes it immediately. Therefore, as long as a platform provides a corresponding interpreter, the program can be run.
Execution mode: source code - > interpreter (interpretation is required for each execution) - > output
Difference: the compiled language has fast program execution speed and low system requirements under the same conditions. Therefore, it is adopted when developing operating system, large application program and database system. C/C + +, Pascal/Object Pascal (Delphi) and other compiled languages. The interpreted language needs to interpret the source code as machine code and execute it every time, which is inefficient, Some programs such as web script, server script and auxiliary development interface that do not require high speed and have certain requirements for the compatibility between different system platforms usually use explanatory languages, such as Java, JavaScript, VBScript, Perl, Python, Ruby, MATLAB and so on.
35. What is the difference between xrange and range?
Difficulty: ★★☆☆☆
In Python 2, there are two ways to get numbers in a certain range: range(), which returns a list, and xrange(), which returns an iterator.
In Python 3, range() returns the iterator and xrange() no longer exists.
36. Briefly describe the keywords yield and yield from.
Difficulty: ★★★★★
When the yield keyword appears in a function, the function is a generator.
After the function is converted to generator, it will be executed every time next() is called. If the yield statement returns, it will continue to execute from the last returned yield statement when it is executed again.
yield from iterable
for item in iterable:
Syntax of yield item.
Note that the yield from must be followed by an iteratable object
Use of yield
>>> def func():
for i in range(5):
yield i
>>> func()
<generator object func at 0x0000021812746040>
>>> f = func()
>>> next(f)
0
>>> next(f)
1
>>> next(f)
2
>>> next(f)
3
>>> next(f)
4
>>> next(f)
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
next(f)
StopIteration
Use of yield from
>>> def func1():
yield range(5)
>>> def func2():
yield from range(5)
>>> def func3():
for i in range(5):
yield i
# func1() returns an iteratable object directly
>>> for i in func1():
print(i)
range(0, 5)
# func2() returns the value after iteration
>>> for i in func2():
print(i)
0
1
2
3
4
# func3() returns the value after iteration
>>> for i in func3():
print(i)
0
1
2
3
4
37. What are the help() and dir() functions in Python for?
Difficulty: ★★★☆☆
The help() function is a built-in function used to view a detailed description of the purpose of a function or module.
>>> help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
The dir() function is also a Python built-in function. When the dir() function does not take parameters, it returns a list of variables, methods and defined types in the current range; With parameters, the list of properties and methods of the parameters is returned.
>>> list1 = [1,2] >>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'list1'] >>> dir(list1) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
38. How to implement threads in Python?
Difficulty: ★★★★★
Python has a multithreading package threading, which can be used to improve the performance of your code. But Python has a construct called Global Interpreter Lock (GIL). Gil ensures that only one 'thread' can execute at any time.
The thread obtains the GIL, does some work, and then passes the GIL to the next thread. This happens very quickly, so to the human eye, it may look like your threads executing in parallel, but they actually just take turns using the same CPU core. Therefore, the existence of GIL makes multithreading in Python unable to really take advantage of multi-core to improve performance.
For IO intensive operations, GIL will be released when waiting for the operating system to return; Another example is that the crawler can use multithreading to speed up the response time of the waiting server! However, for CPU intensive operations, it can only be accelerated through Multiprocess.
39. What is a monkey patch in Python?
Difficulty: ★★★★★
Monkey patch is a very Python usage, that is, functions can be assigned values and other operations like variables in Python. We can dynamically replace modules at runtime, commonly known as monkey patch! We passed on MyClass Func is re assigned, which dynamically changes the output result.
>>> class MyClass:
def func(self):
print("enter func()")
>>> def monkey_func(self):
print('enter monkey_func()')
>>> obj = MyClass()
>>> obj.func()
enter func()
>>> MyClass.func = monkey_func
>>> new_obj = MyClass()
>>> obj.func()
enter monkey_func()
40. How to disrupt the elements of a list by local operation?
Difficulty: ★★☆☆☆
Use the shuffle() function imported from the random module
>>> from random import shuffle >>> lst = [1, 2, 3, 4, 5] >>> shuffle(lst) >>> lst [4, 3, 1, 2, 5]
41. Change the string 'love' to 'live'.
Difficulty: ★★☆☆☆
>>> s = 'love'
# Method 1: convert str to list
>>> list_s = list(s)
>>> list_s[1] = 'i'
>>> ''.join(list_s)
'live'
# Method 2: use replace()
>>> s.replace('o', 'i')
'live'
# Method 3 string splicing
>>> s[:1] + 'i' + s[2:]
'live'
42. Write the result of the following code.
Difficulty: ★★☆☆☆
>>> def func(): pass >>> type(func())
The running result of the above code is < class' NoneType '> because it is func(), that is, the type of return value. Because there is no return value, it is NoneType. The result of type(func) is < class' function >.
43. Is the transfer method of function call parameters in Python value transfer or reference transfer?
Difficulty: ★★★☆☆
Python parameter passing includes: location parameter, default parameter, variable parameter and keyword parameter.
Whether the value transfer of a function is value transfer or reference transfer depends on the situation:
-
Immutable parameter: it is value passing. Immutable objects such as integers and strings are passed by copy, because you can't change immutable objects in place anyway.
-
Variable parameter: it refers to the transfer of references. For example, objects such as lists and dictionaries are passed by reference. It is very similar to the transfer of arrays with pointers in C language. Variable objects can be changed within functions.
44. An existing DataFrame dataset contains the names and scores of students. First, a new column of "evaluation" should be added to record the passing status of students. If the score is less than 60, it will be "failed", otherwise it will be "passed".
Use map, lambda anonymous functions, and ternary expressions to filter students who meet the conditions.
Difficulty: ★★★☆☆
>>> df = pd.DataFrame({'full name': ['Zhang San', 'Li Si', 'Wang Wu', 'Zhao Liu'], 'fraction': [50, 70, 80, 90]})
>>> df
Name score
0 Zhang San 50
1 Li Si 70
2 Wang WU80
3 Zhao liu90
>>> df['evaluate'] = df['fraction'].map(lambda x: 'pass' if x >= 60 else 'fail,')
>>> df
Name score evaluation
0 Zhang San failed at 50
1 Li Si passed 70
2 Wang WU80 passed
3 Zhao liu90 passed
45. Now, in order to obtain more detailed information, the "evaluation" column needs to be divided into failure below 60, pass from 60 to 80 and excellent above 80.
Use pandas Cut() divides the "evaluation" column into sections.
Difficulty: ★★★☆☆
>>> df['evaluate'] = pd.cut(df['fraction'], [0, 60, 80, 100], labels=['fail,', 'pass', 'excellent']) >>> df Name score evaluation 0 Zhang San failed at 50 1 Li Si passed 70 2 Wang WU80 passed 3 Zhao liu90 excellent
Key reference links
BAT_interviews/Python interview questions and answers md
What is the difference between compiled and interpreted languages?
Collaborative process keywords yield and yield from
8 carefully sorted Python interview questions! Is it difficult for you
kenwoodjw/python_interview_question
👉 PDF acquisition method 👈
The PDF has been generated. If necessary, you can leave an email or private letter. I will send it when I see it.
 |
|---|
This is all the content of this article, if it feels good. ❤ Point a praise before you go!!! ❤

In the follow-up, I will continue to share "Mysql true · selected interview questions". If you are interested, you can pay attention and don't get lost ~.