Introduction to LEFT SEMI JOIN
The main use scenario of SEMI JOIN (equivalent to LEFT SEMI JOIN) is to solve EXISTS IN. LEFT SEMI JOIN is a more efficient implementation of IN/EXISTS sub query. Although LEFT SEMI JOIN contains LEFT, its implementation effect is equivalent to INNER JOIN, but the JOIN result only takes the columns in the original LEFT table.
Optimization example
Instance table preparation:
CREATE TABLE test.user1( `id` bigint ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile LOCATION '/big-data/test/user1'; CREATE TABLE test.user2( `id` bigint, `role` string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile LOCATION '/big-data/test/user2';
Instance data preparation:
insert into test.user1 values(-1); insert into test.user1 values(1); insert into test.user2 values(-1,'C1'); insert into test.user2 values(1,'C1'); insert into test.user2 values(1,'C2');
Data test:
JOIN
--join of select There can be t1((left table),t2(Right table) fields of two tables SELECT t1.id, t2.role FROM test.user1 t1 JOIN test.user2 t2 ON t1.id=t2.id;
result:
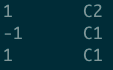
left semi join
--left semi join of select Only allowed in results t1(Left table) fields of the table
SELECT
t1.id
FROM test.user1 t1
LEFT SEMI JOIN test.user2 t2
ON t1.id=t2.id;
--Equivalent to
SELECT
t1.id
FROM test.user1 t1
WHERE id IN (
SELECT
id
FROM test.user2
);
--Equivalent to
SELECT
t1.id
FROM test.user1 t1
WHERE EXISTS (
SELECT 1
FROM test.user2 t2
WHERE t1.id=t2.id
);
result:

Exception:
In this way, if the result involves the fields in the right table of the query, an error will be reported:
SELECT t1.id, t2.role FROM test.user1 t1 LEFT SEMI JOIN test.user2 t2 ON t1.id=t2.id;
result:

Connection between join on and left semi join
They are all a kind of hive join. join on belongs to common join(shuffle join/reduce join), while left semi join belongs to a variant of map join(broadcast join). From the name, we can see that their implementation principles are different.
The difference between join on and left semi join
(1) Left Semi Join, also known as semi join, is a method borrowed from distributed database. Its motivation is: for reduce side join, the amount of data transmission across machines is very large, which has become a bottleneck of the join operation. If the data that will not participate in the join operation can be filtered at the map side, the network IO can be greatly saved and the execution efficiency can be improved.
Implementation method: select a small table, assuming File1, extract its key participating in the join and save it to File3, which is generally small and can be put into memory. In the map phase, use the DistributedCache to copy File3 to each TaskTracker, and then filter out the records corresponding to the keys in File2 that are not in File3. The work of the remaining reduce phase is the same as that of the reduce side join.
left semi join is to pass only the join key of the table to the map stage. If the key is small enough, execute the map join. If not, execute the common join. For the principle of common join (shuffle join/reduce join), please refer to ref at the end of the article.
(2) The right table in the left semi join clause can only be filtered in the ON clause, but not in the WHERE clause, SELECT clause or other places.
(3) There are differences in the treatment of duplicate keys in the right table: because the left semi join is in(keySet), when encountering duplicate records in the right table, the left table will skip, while the join on will traverse all the time. The final result in the left semi join is that this will lead to differences in performance and join results.
(4) The result of the last select in the left semi join can only appear in the left table, because only the join key in the right table is involved in the association calculation, while the join on defaults to the whole relationship model.
Here is an example diagram on the Internet for explanation:
For example, the following tables A and B perform A join or left semi join, and then select all fields. The difference between the results is as follows: (the column with the Blue Cross does not actually exist in the left semi join, because the last selected result can only appear in the left table.)
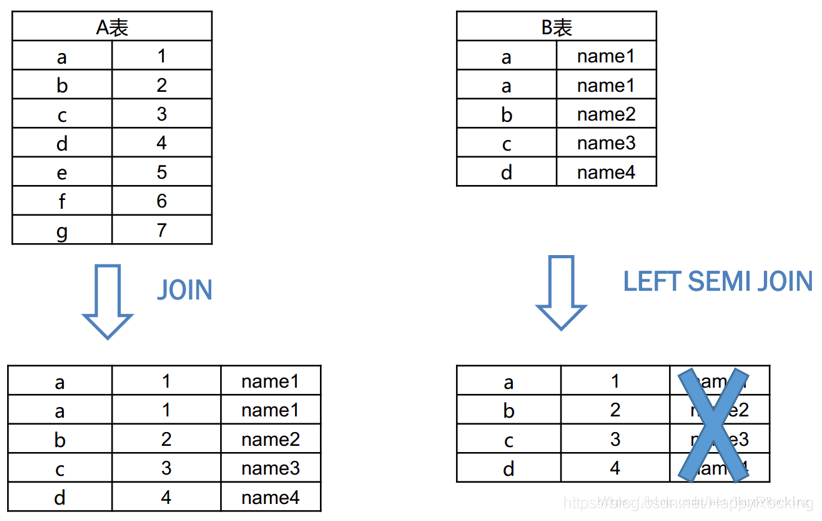
Write at the end
In most cases, JOIN ON and left semi on are equivalent. When there are duplicate data records in the right table, the results are different. Therefore, it is best to understand the principles of these two methods and whether they are consistent with the data effect we want.