Hello, everyone. I'm spicy~
As the title shows, we must have been bombed by President Wang's melon these two days. There have been several rounds of hot searches on the microblog. I also eat with relish. It's rare to see President Wang eat flat in front of girls. In addition, I chatted with a friend about the problems encountered in the collection of microblog comments. I wrote this article with emotion. Without much to say, let's go directly to the theme.
Climb target
Website: [microblog]( https://m.weibo.cn/detai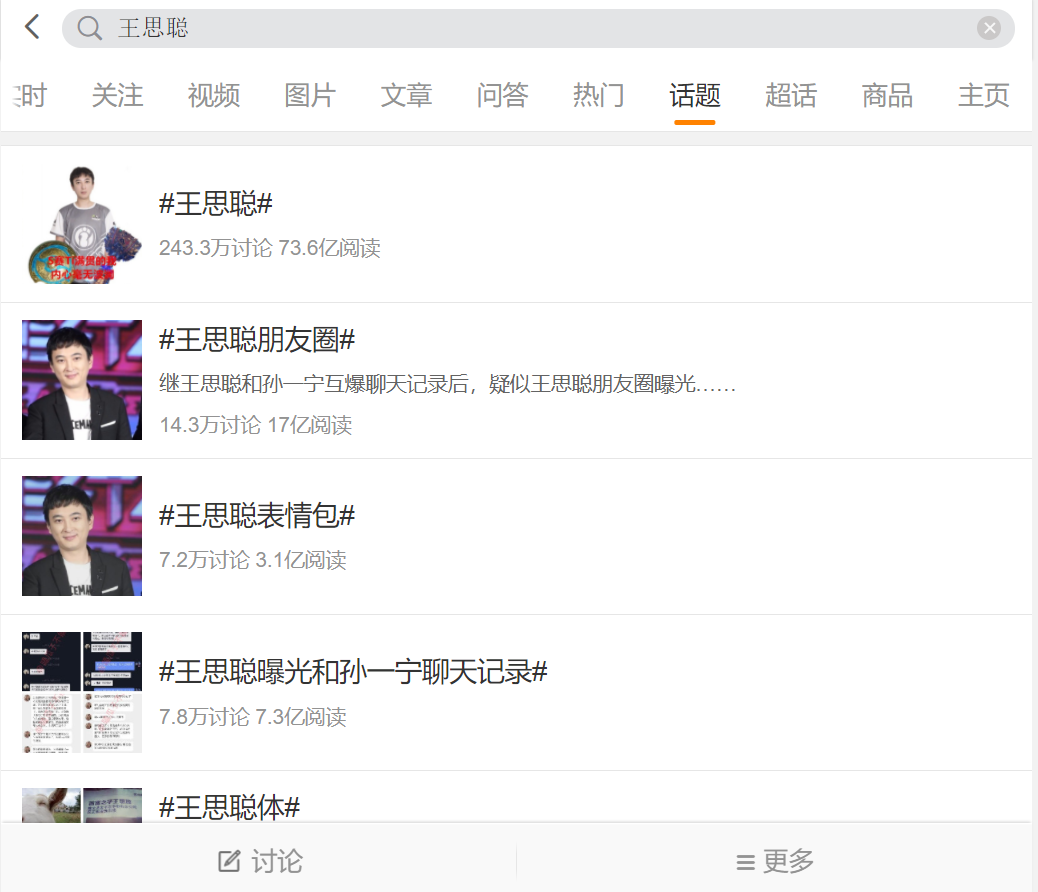
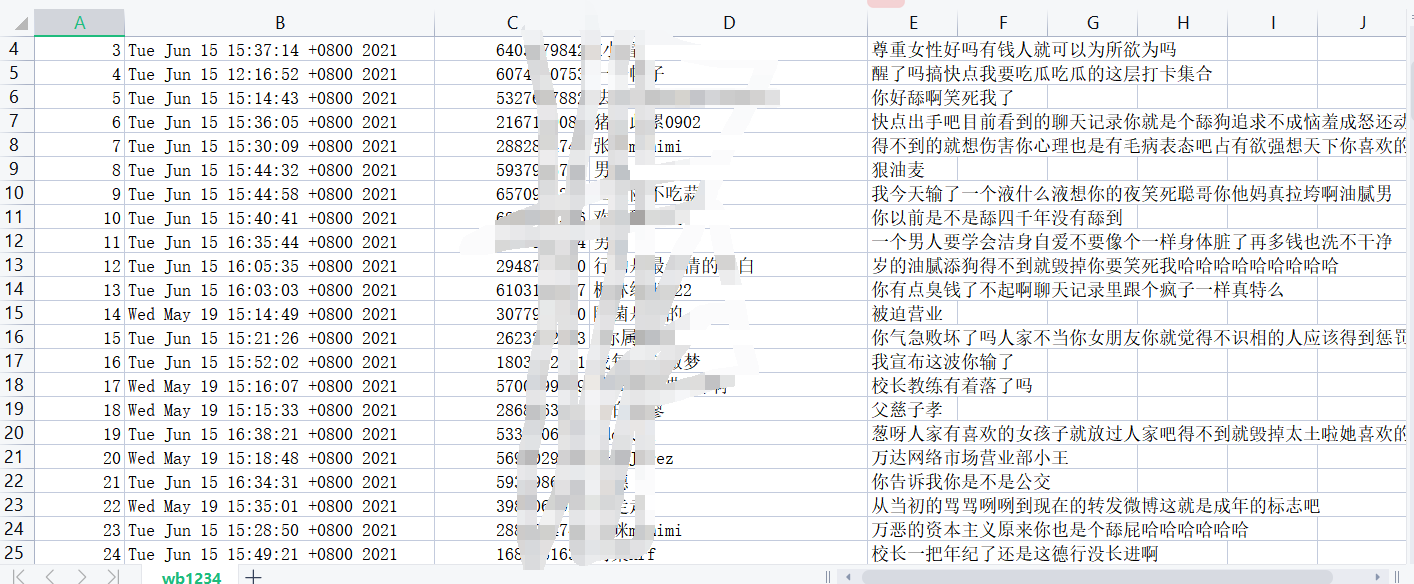
Effect display
Tool use
Development environment: win10, python3 seven
Development tools: pycharm, Chrome
Toolkit: requests, re, csv
Analysis of project ideas
Find articles that need to eat melons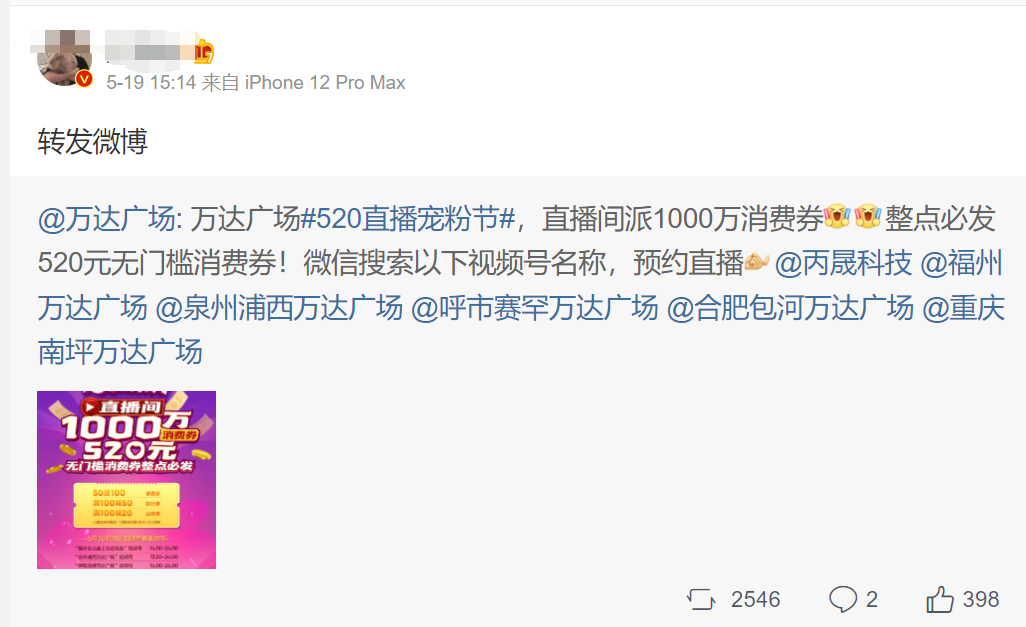
The request header needs to carry the basic configuration data
headers = {
"referer": "",
"cookie":"",
"user-agent": ""
}Find the comment data dynamically submitted by the article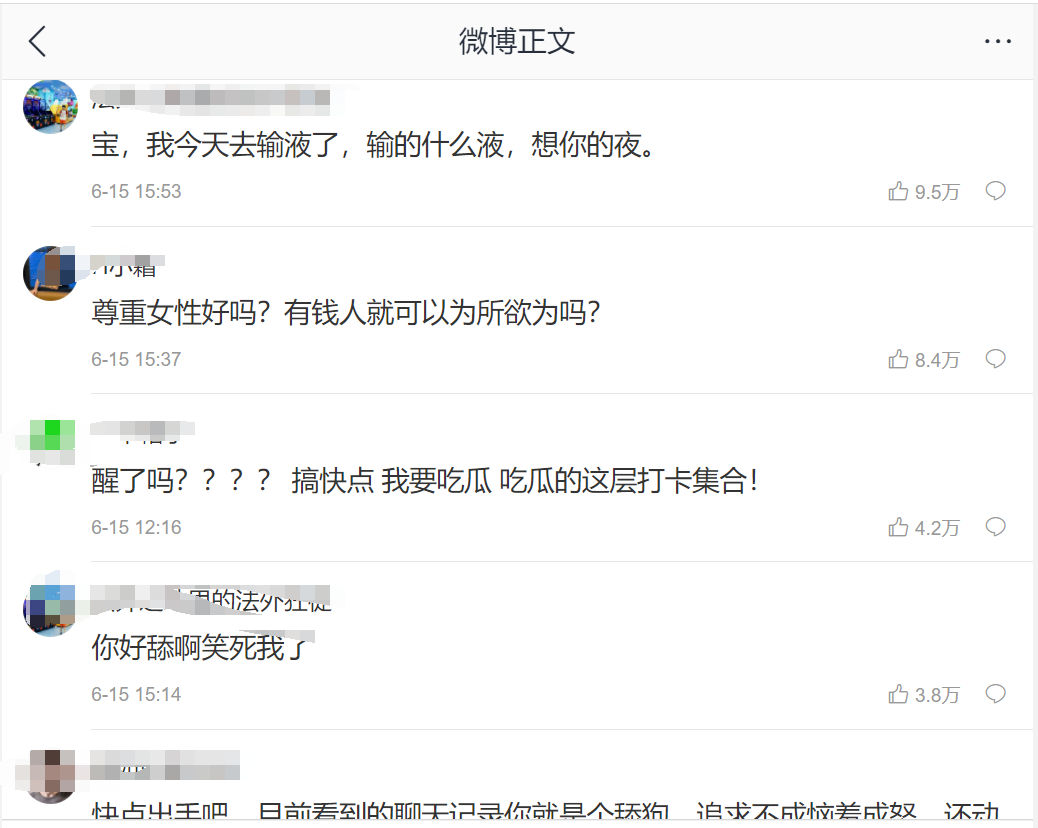
Find the corresponding comment data information through the packet capture tool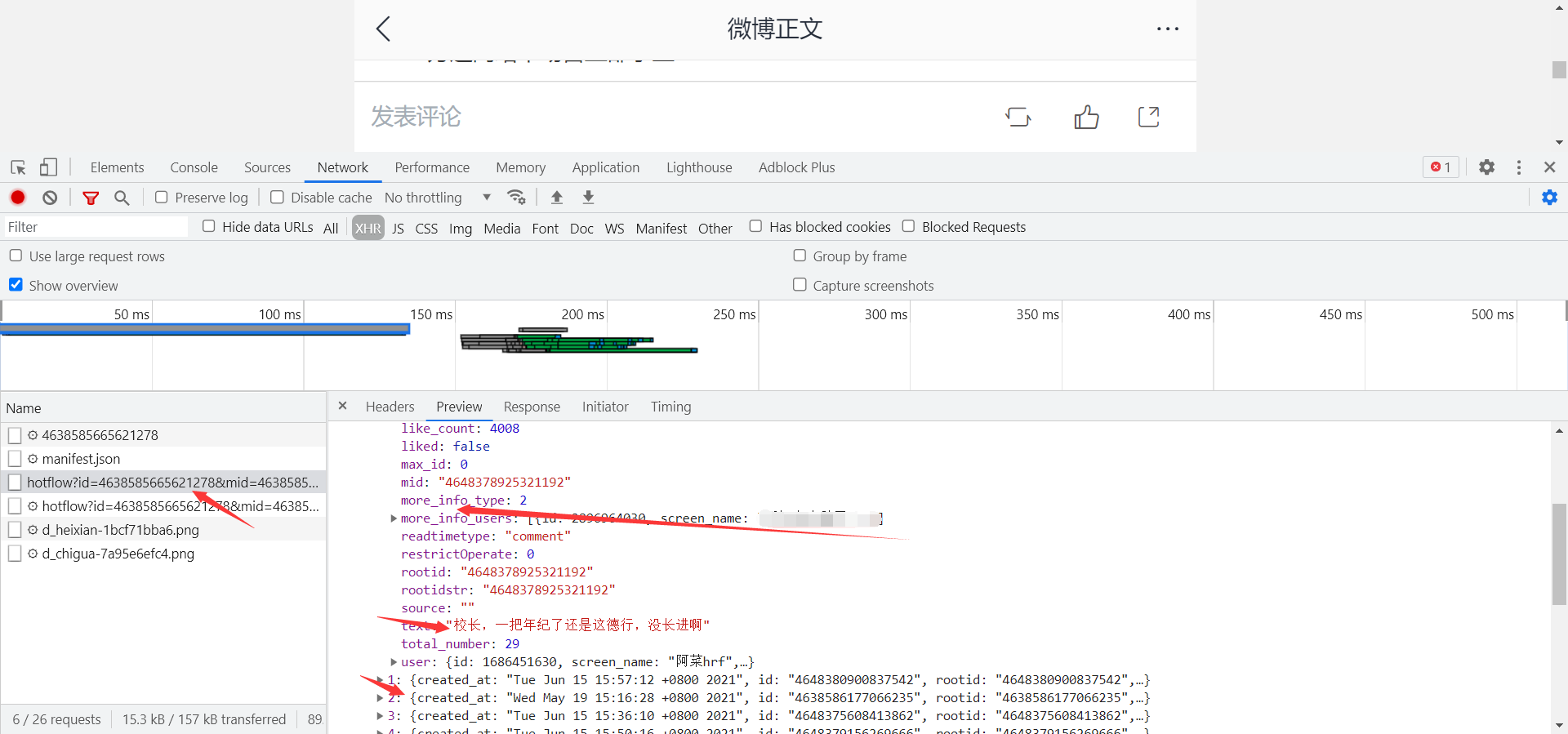
The url of Weibo will have an article ID, and mid is also an article ID, max_ ID is the max in each json data_ ID is irregular. https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4638585665621278&max_id=1190535179743975&max_id_type=0
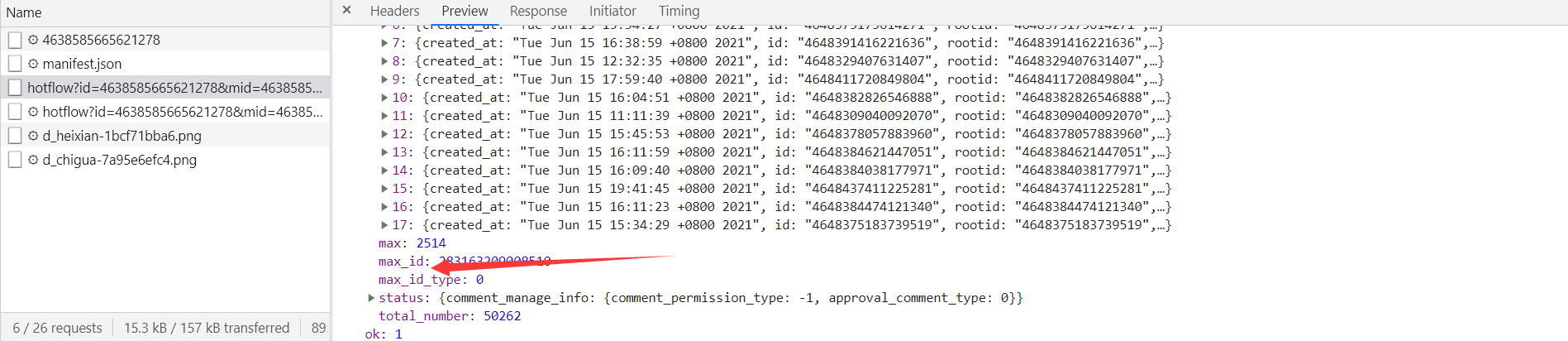
Take out the current max_id, you will get the request interface of the next page
Simple source code analysis
import csv
import re
import requests
import time
start_url = "https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4638585661278&max_id_type=0"
next_url = "https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4638585661278&max_id={}&max_id_type=0"
continue_url = start_url
headers = {
"referer": "",
"cookie": "",
"user-agent": ""
}
count = 0
def csv_data(fileheader):
with open("wb1234.csv", "a", newline="")as f:
write = csv.writer(f)
write.writerow(fileheader)
def get_data(start_url):
print(start_url)
response = requests.get(start_url, headers=headers).json()
print(response)
max_id = response['data']['max_id']
print(max_id)
content_list = response.get("data").get('data')
for item in content_list:
global count
count += 1
create_time = item['created_at']
text = "".join(re.findall('[\u4e00-\u9fa5]', item["text"]))
user_id = item.get("user")["id"]
user_name = item.get("user")["screen_name"]
# print([count, create_time, user_id, user_name, text])
csv_data([count, create_time, user_id, user_name, text])
global next_url
continue_url = next_url.format(max_id)
print(continue_url)
time.sleep(2)
get_data(continue_url)
if __name__ == "__main__":
fileheader = ["id", "Comment time", "user id", "user_name", "Comment content"]
csv_data(fileheader)
get_data(start_url)
PS: don't take any part or make any evaluation. I hope you can learn technology while eating melons. If it's helpful to you, remember to give spicy strips for three times. Finally, I wish everyone a smooth relationship. Those who don't get off the order will get off the order as soon as possible, and those who get off the order will get married as soon as possible.
How to get the source code:
① More than 3000 Python e-books
② Python development environment installation tutorial
③ Python 400 set self-study video
④ Common vocabulary of software development
⑤ Python learning Roadmap
⑥ Project source code case sharing
If you can use it, you can take it directly. In my QQ technical exchange group, group number: 739021630 (pure technical exchange and resource sharing, advertising is not allowed) take it by yourself
Click here to receive