Python crawler framework's Scrapy detailed explanation and single page crawling tutorial portal:

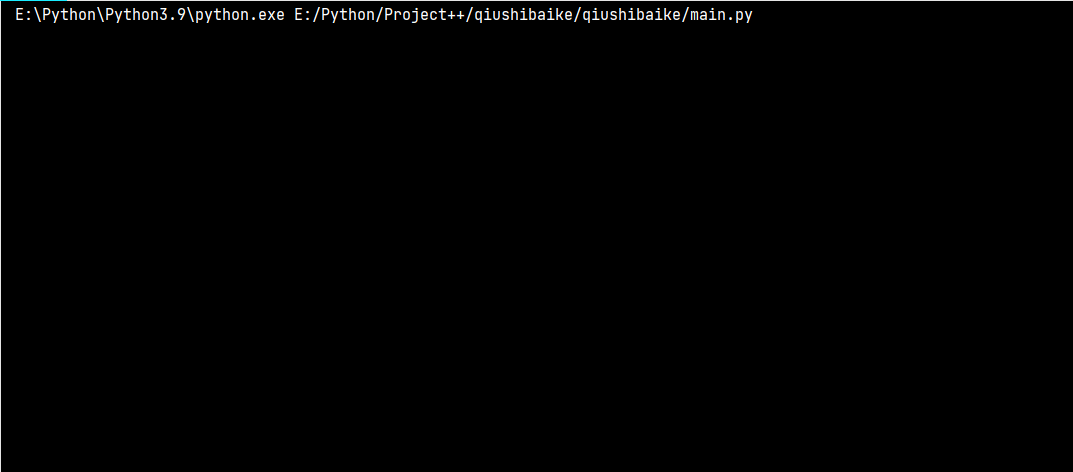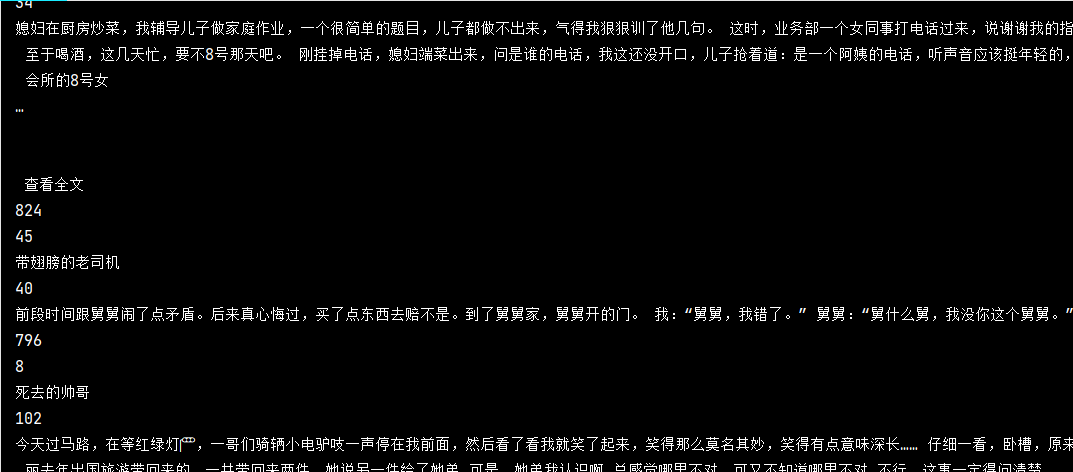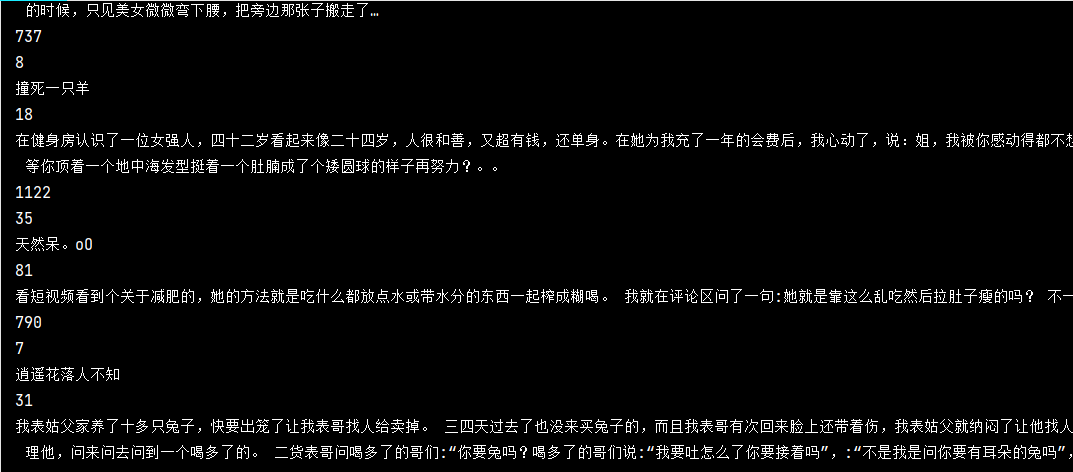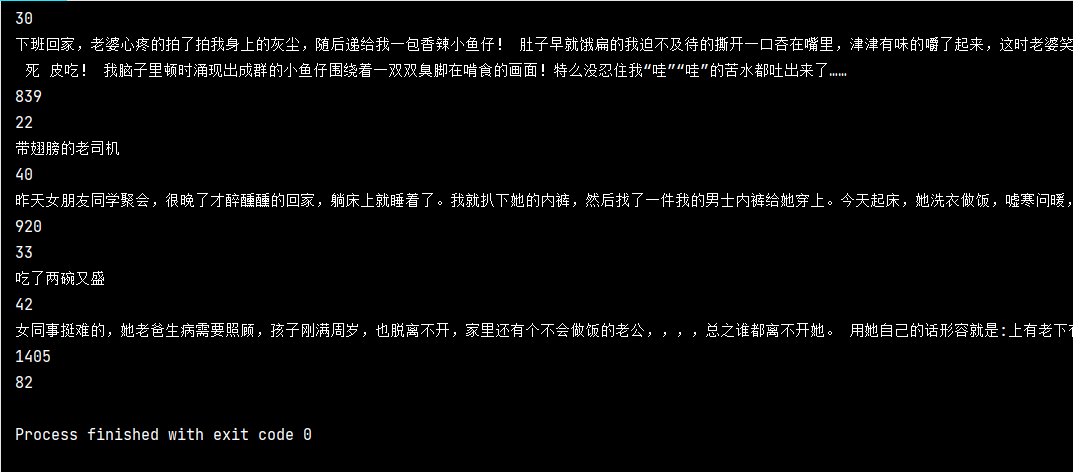
Today, let's directly look at the actual combat and climb all the passages in the embarrassing encyclopedia. First, let's take a look at the results we have obtained:
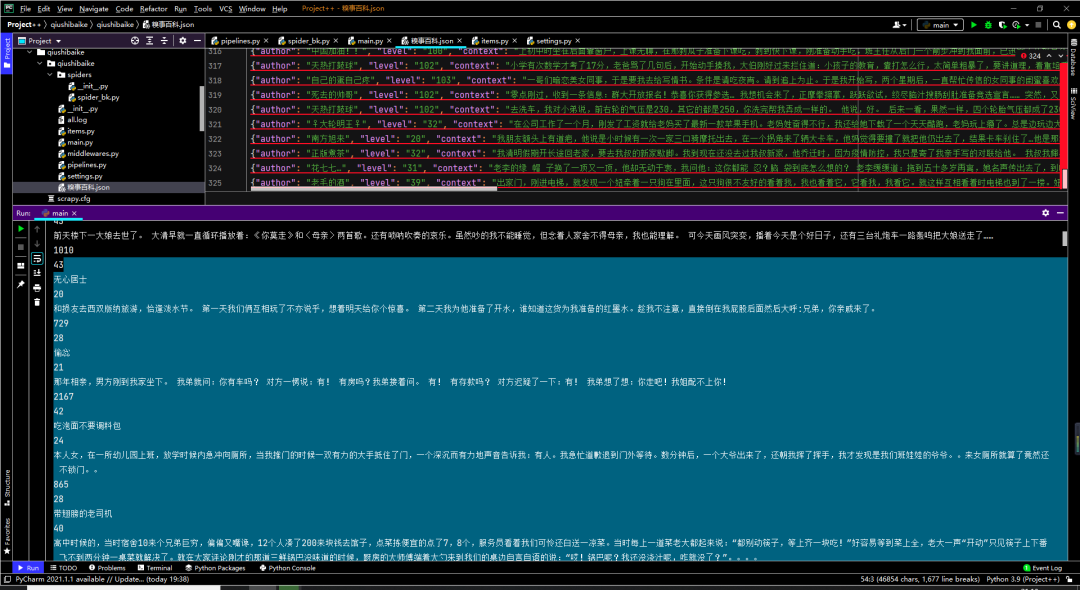
Console
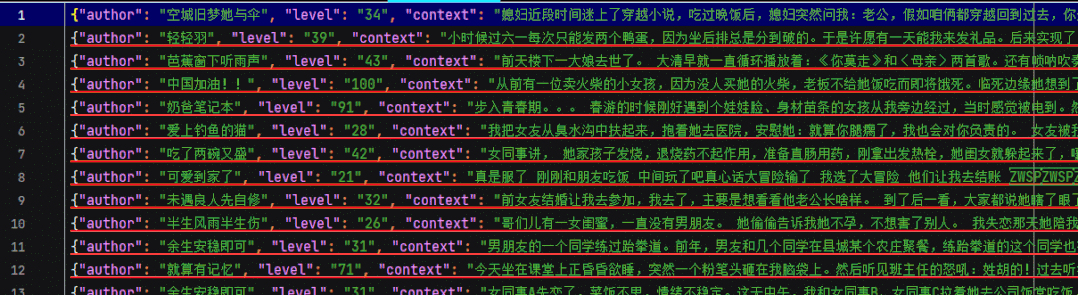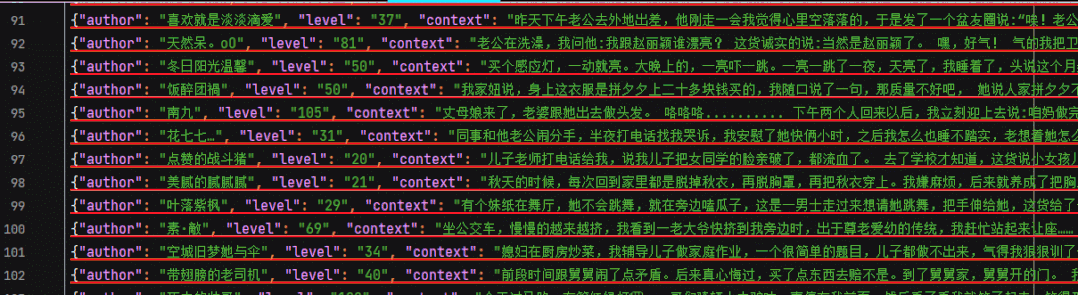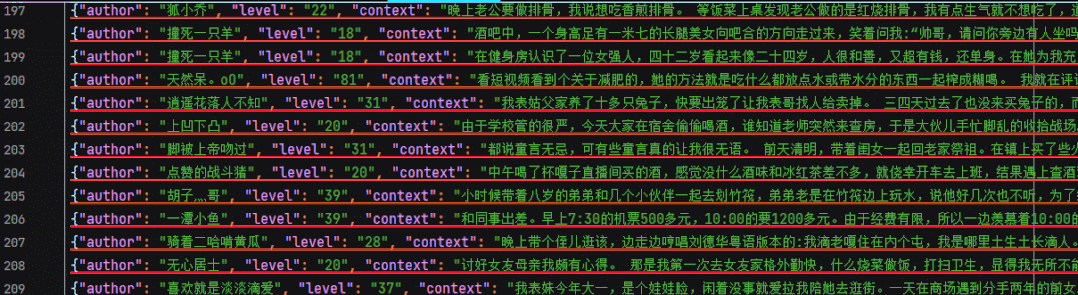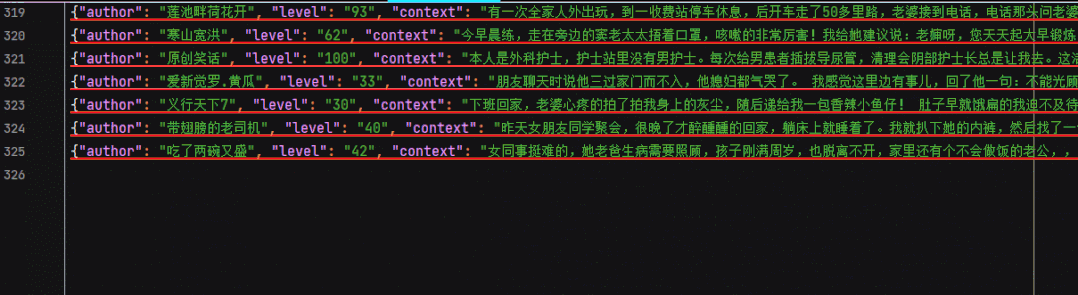
json file
1. Determine the goal: open the embarrassing Encyclopedia - under the paragraph column. We have five target data for this trip. Author's name, author level, paragraph content, number of likes and comments.
Home page link:
https://www.qiushibaike.com/text/
2. Establish the project. We use commands
scrapy startproject qiushibaike
3. Then we use the command
scrapy genspider spider_bk www.qiushibaike.com/text/
Build a spider_ The python file of bk.py is used to realize the specific crawler.

4. Next, let's implement our entity class items Py file. The data we want to obtain are as follows.
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class QiushibaikeItem(scrapy.Item): # define the fields for your item here like: #Author author = scrapy.Field() #Author level level = scrapy.Field() #Content context = scrapy.Field() #Number of people who agree star = scrapy.Field() #Number of comments comment = scrapy.Field()
5. Let's start with the spider in the crawler file_ Bk.py realizes the acquisition of single page data.
import scrapy
from qiushibaike.items import QiushibaikeItem
class SpiderBkSpider(scrapy.Spider):
name = 'spider_bk'
allowed_domains = ['www.qiushibaike.com/text/page/1/']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
#Instantiation method
item = QiushibaikeItem()
#Get all div s of the current page
divs = response.xpath("//div[@class='col1 old-style-col1']/div")
for div in divs:
item['author'] = div.xpath('./div[@class="author clearfix"]/a/h2/text()').get().strip() #Author
item['level'] = div.xpath('./div[@class="author clearfix"]/div/text()').get() #Author level
content = div.xpath(".//div[@class='content']//text()").getall()
content = " ".join(content).strip() #Content
item['context'] = content
item['star'] = div.xpath('./div/span/i/text()').get() #Number of people who agree
item['comment'] = div.xpath('./div/span/a/i/text()').get() #Number of comments
yield item
6. We save the acquired data into pipelines Py's embarrassing encyclopedia In the json file, in order to make it easy to see the data, we print out the data before saving.
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class QiushibaikePipeline:
def process_item(self, item, spider):
print(item['author'])
print(item['level'])
print(item['context'])
print(item['star'])
print(item['comment'])
#Save file locally
with open('./Embarrassing Encyclopedia.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)
return item
7. We create another main method to print the data on the console. This avoids the trouble of writing commands on the command line every time.
from scrapy import cmdline
cmdline.execute('scrapy crawl spider_bk -s LOG_FILE=all.log'.split())
8. Next, let's go to setting Open the following settings in py:
from fake_useragent import UserAgent
BOT_NAME = 'qiushibaike'
SPIDER_MODULES = ['qiushibaike.spiders']
NEWSPIDER_MODULE = 'qiushibaike.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': str(UserAgent().random),
}
ITEM_PIPELINES = {
'qiushibaike.pipelines.QiushibaikePipeline': 300,
}
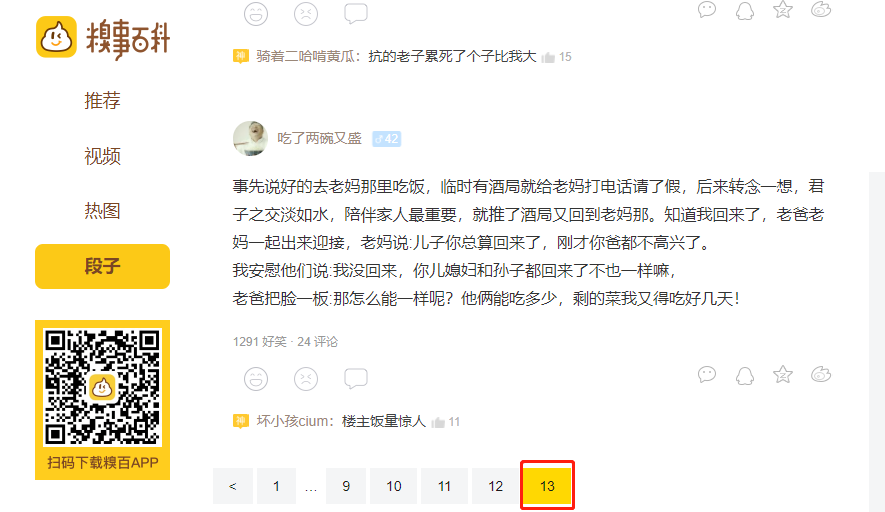
9. In the last step, we write the main method to print single page data to the console.

You can see that the single page data has been successfully obtained. We can see that the embarrassing Encyclopedia has 13 pages in total, and our goal is to have all the data on these 13 pages.
10. We are in the crawler file spider_ Add a loop to BK to get all the data.
def start_requests(self):
#Get page turning URL
for page in range(1, 13 + 1):
url = 'https://www.qiushibaike.com/text/page/{}/'.format(str(page)) # extract page turning links
yield scrapy.Request(url, callback=self.parse)
Execute the main method again, and all 325 pieces of data on page 13 have been obtained locally.