self-introduction
xdm well, I'm a jump table, an ordered data structure. There is an array in each of my nodes. I maintain multiple pointers that can point to other nodes, so I can quickly access these nodes. That's why I'm a jump table.
My average time complexity is O(logN). At worst, it is O(N). In most cases, I can compare with the efficiency of balanced tree, but my implementation is much simpler than him.
What are the usage scenarios in redis
I am one of the underlying implementations of ordered collections in redis, but there is no free lunch in the world. It is conditional for him to use me as the underlying implementation. When there are many elements or the members of an ordered set are long strings, it will be applicable to me to implement it. My usage scenarios in redis are relatively few. There are only two places where I am used, one is this ordered collection, and the other is used as an internal data structure in cluster nodes.
My realization
I look like this:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
You can see that my structure first has two pointers, a header and a tail, pointing to my head node and tail node respectively. There is also a length to record the number of my nodes. Level records the maximum height of all my nodes. My header node is a very special node. It does not store data. It only stores the pointer to the next node of the same level and the corresponding span.
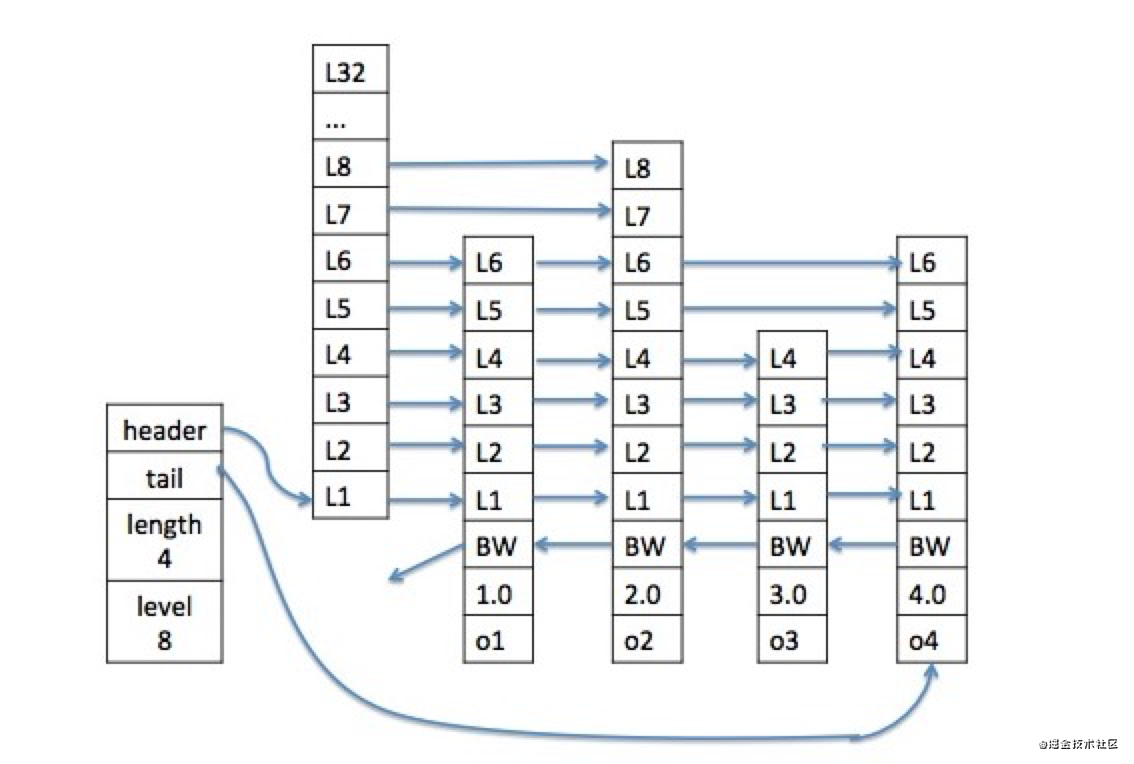
Let's talk about my node. It looks like this:
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
- ele is our key value stored
- Score is the score of our ordered set, and the sorting is based on this field
- backward is a pointer to the previous node, which is convenient for us to find from back to front
- level array, we can see that there is a forward pointer in its structure, which is the pointer to the next node (refer to the above figure), and a span refers to the span (there are several nodes between the node pointed to by this pointer and the current node)
If you feel that your learning efficiency is low and you lack correct guidance, you can join the technology circle with rich resources and strong learning atmosphere to learn and communicate together!
[Java architecture group]
There are many technological giants from the front line in the group, as well as code farmers struggling in small factories or outsourcing companies. We are committed to building an equal and high-quality JAVA Communication circle, which may not make everyone's technology advance by leaps and bounds in the short term, but in the long run, vision, pattern and long-term development direction are the most important.
Don't you look at the source code?
I have many operations, such as zslcreate, zslfree, zslinsert, zsldelete and so on. Let me talk about my operation first
Implementation of zslInsert! xdm goes through the code first.
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
In fact, we can see the logic of this part:
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
The logic of this place is to find the position where our inserted node should be. This logic is a little around. It is the level array of the original node. First find a score that is less than the score of the current node to be inserted from back to front, then execute the code in while from this node, and finally find our x. the node we want to insert is behind our x.
xdm can focus on understanding that the insertion process is still very interesting (if you have doubts, you can discuss it in the comment area. We will return to the next section). Through this insertion method, we can also find that the jump table in redis is an ascending storage structure.
xdm through the source code, we can find out how to sort the jump table when the scores are the same?
Sdscmp (x - > level [i]. Forward - > ele, ELE) < 0) is to compare their sds objects, and the code is posted to xdm
int sdscmp(const sds s1, const sds s2) {
size_t l1, l2, minlen;
int cmp;
l1 = sdslen(s1);
l2 = sdslen(s2);
minlen = (l1 < l2) ? l1 : l2;
cmp = memcmp(s1,s2,minlen);
if (cmp == 0) return l1>l2? 1: (l1<l2? -1: 0);
return cmp;
}
Another concept is that the floor height of the jump table is between 1-64 (32 before 3.2). There is a picture and a truth
 , jump
, jump
Finally, xdm codeword is not easy. If you have some help after reading it, give it a praise ~ I'm going to have an infusion, miss your night!
last
Share with you an immortal document of Java high concurrency core programming compiled by front-line development Daniel, which mainly contains knowledge points: multithreading, thread pool, built-in lock, JMM, CAS, JUC, high concurrency design mode, Java asynchronous callback, completable future class, etc.
Document address: A divine article explains java multithreading, lock, JMM, JUC and high concurrency design pattern clearly
Code words are not easy. If you think this article is useful to you, please give me one button three times! Pay attention to the author, there will be more dry goods to share in the future, please continue to pay attention!