
1. General
Reprint: Reading notes of Flink source code (19) - Implementation of flow table Join in Flink SQL
In the process of data analysis using SQL, association query is often used. In traditional OLTP and OLAP fields, the data set of association query is bounded, so it can rely on caching bounded data set for query. However, in Streaming SQL, for the case of Stream Join Stream, because both sides of the associated query are continuous and unbounded data streams, the implementation and optimization methods of Join operation in traditional data tables may not be fully applicable. In this article, we will introduce the challenges faced by dual stream Join and analyze the specific implementation mechanism of dual stream Join in Flink SQL.
2. Challenges of Shuangliu Join
In the traditional database or batch processing scenario, the data set of associated query is limited, so it can rely on the cache bounded data set and use methods such as nested loop join, sort merged join or Hash Join to perform matching query. However, in Streaming SQL, the associated query of two data streams mainly faces the following two problems: on the one hand, the data stream is infinite, and the cached data will bring high storage and query pressure to the long running task; On the other hand, there is inconsistency in the arrival time of messages in the data streams on both sides, which may lead to the lack of correlation results.
For the first problem mentioned above, in order to ensure the correctness of the correlation results, it is necessary to cache all the historical data in the data stream. With the continuous arrival of data in the two data streams, the overhead of caching historical data is increasing, and each newly arrived message will stimulate the query of historical data on the other side. In order to solve this problem, one method is to limit the associated data range to a specific time range through the time window, that is, Window Join (for time window, please refer to the previous article); Another method is to make a trade-off between storage overhead and association accuracy, and increase the limit of survival time on the cached historical data. This can avoid the unlimited growth of cached data, but it may reduce the accuracy accordingly.
The second problem mentioned above mainly aims at the external connection. Due to the uncertainty of the arrival time of the data on both sides, for a specific message, there may be no matching record at t1 and matching record at T2 (T2 > t1). For external connections, it is required to return NULL value when there is no association result. Therefore, in order to ensure the correctness of the association results, one way is to limit the associated data range through the time window, but this requires that the results are output at the end of the window, which will lead to output delay; The other way is to adopt the "undo correct" method, first output the NULL value, and then undo the output records when the subsequent associated records arrive, and correct them to the correct result of the association. Its disadvantage is that it will enlarge the number of output records.
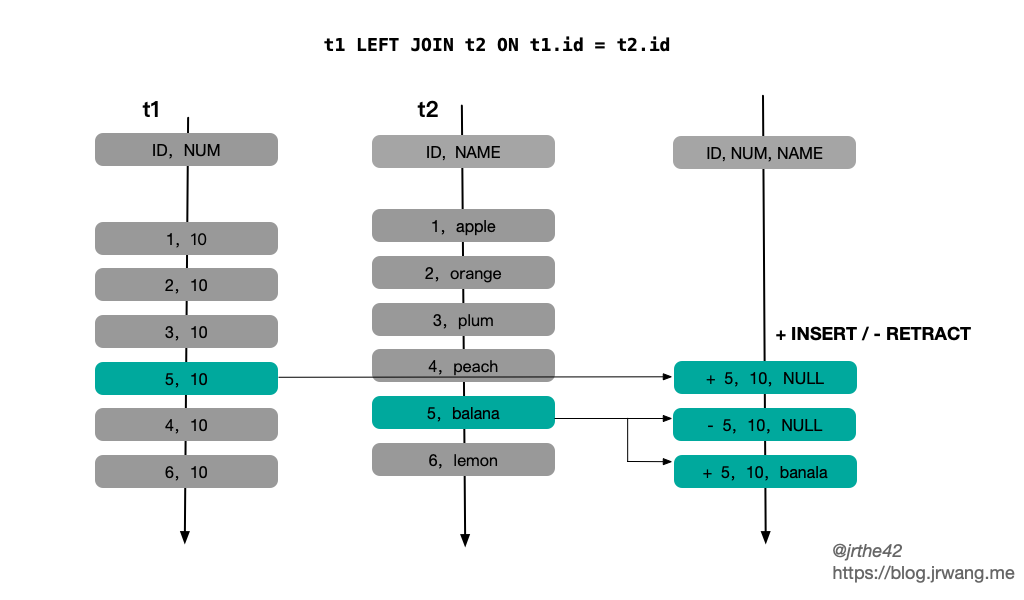
From the above analysis, it can be seen that the time window can partially solve the problems faced by Streaming Join by limiting the range of associated data in association query. Its basic idea is to divide the infinite data flow into limited time windows. However, time window association is not suitable for all situations. In many cases, the association query of two data streams cannot be limited to a specific time window; In addition, there is an output delay in time window correlation.
The follow-up part of this paper will introduce the implementation mechanism of ordinary dual stream Join in Flink SQL, and the implementation mechanism of Window Join will be analyzed in the follow-up articles.
3. Implementation mechanism of dual stream Join
Conversion of a Join statement
First, we take a simple Join statement as an example to track the transformation process of a Join statement.
-- table A('a1, 'a2, 'a3)
-- table B('b1, 'b2, 'b3)
SELECT a1, b1 FROM A JOIN B ON a1 = b1 and a2 > b2
After parsing, the above SQL statement is converted into the following logical plan:
LogicalProject(a1=[$0], b1=[$3]) +- LogicalJoin(condition=[AND(=($0, $3), >($1, $4))], joinType=[inner]) :- LogicalTableScan(table=[[A, source: [TestTableSource(a1, a2, a3)]]]) +- LogicalTableScan(table=[[B, source: [TestTableSource(b1, b2, b3)]]])
This logical plan is first converted to the RelNode inside Flink SQL, that is:
FlinkLogicalCalc(select=[a1, b1])
+- FlinkLogicalJoin(condition=[AND(=($0, $2), >($1, $3))], joinType=[inner])
:- FlinkLogicalCalc(select=[a1, a2])
: +- FlinkLogicalTableSourceScan(table=[[A, source: [TestTableSource(a1, a2, a3)]]], fields=[a1, a2, a3])
+- FlinkLogicalCalc(select=[b1, b2])
+- FlinkLogicalTableSourceScan(table=[[B, source: [TestTableSource(b1, b2, b3)]]], fields=[b1, b2, b3])
After that, after a series of optimization rules, it is optimized into the final execution plan, as follows:
Calc(select=[a1, b1])
+- Join(joinType=[InnerJoin], where=[AND(=(a1, b1), >(a2, b2))], select=[a1, a2, b1, b2], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey])
:- Exchange(distribution=[hash[a1]])
: +- Calc(select=[a1, a2])
: +- TableSourceScan(table=[[A, source: [TestTableSource(a1, a2, a3)]]], fields=[a1, a2, a3])
+- Exchange(distribution=[hash[b1]])
+- Calc(select=[b1, b2])
+- TableSourceScan(table=[[B, source: [TestTableSource(b1, b2, b3)]]], fields=[b1, b2, b3])
At this point, the optimization phase of the logical plan ends and enters the generation phase of the physical plan.
Flink SQL will generate a TwoInputTransformation transformation for the StreamExecJoin operation. The internal operator is StreamingJoinOperator, which is used to match the associated records in the two data streams; Generate a PartitionTransformation for the streamexexexchange operation, which is used to determine that the records output by the upstream operator are forwarded to the partitions of the downstream operator.
4. Two important transformation rules
In the process of logical plan optimization, there are two important rules to pay attention to: StreamExecJoinRule and flinkeexpandconversionrule.
As the name suggests, StreamExecJoinRule is mainly used to convert FlinkLogicalJoin to StreamExecJoin. However, this transformation is conditional, that is, the association condition of FlinkLogicalJoin does not include a time window. First, let's look at the matching conditions of this rule:
class StreamExecJoinRule
extends RelOptRule(
operand(classOf[FlinkLogicalJoin],
operand(classOf[FlinkLogicalRel], any()),
operand(classOf[FlinkLogicalRel], any())),
"StreamExecJoinRule") {
override def matches(call: RelOptRuleCall): Boolean = {
val join: FlinkLogicalJoin = call.rel(0)
//Whether the association result needs to project data from the right table. SEMI JOIN and ANTI JOIN do not need to select the data of the right table
if (!join.getJoinType.projectsRight) {
// SEMI/ANTI JOIN is always converted to StreamExecJoin
return true
}
val left: FlinkLogicalRel = call.rel(1).asInstanceOf[FlinkLogicalRel]
val right: FlinkLogicalRel = call.rel(2).asInstanceOf[FlinkLogicalRel]
val tableConfig = call.getPlanner.getContext.unwrap(classOf[FlinkContext]).getTableConfig
val joinRowType = join.getRowType
//Left table does not support temporary table
if (left.isInstanceOf[FlinkLogicalSnapshot]) {
throw new TableException(
"Temporal table join only support apply FOR SYSTEM_TIME AS OF on the right table.")
}
//Temporary table join is not supported
if (right.isInstanceOf[FlinkLogicalSnapshot] ||
TemporalJoinUtil.containsTemporalJoinCondition(join.getCondition)) {
return false
}
//Extract 1) time window boundary 2) other conditions from the correlation conditions
val (windowBounds, remainingPreds) = WindowJoinUtil.extractWindowBoundsFromPredicate(
join.getCondition,
join.getLeft.getRowType.getFieldCount,
joinRowType,
join.getCluster.getRexBuilder,
tableConfig)
//If there is a window, it does not apply to the rule
if (windowBounds.isDefined) {
return false
}
//Common association conditions cannot access time attributes
// remaining predicate must not access time attributes
val remainingPredsAccessTime = remainingPreds.isDefined &&
WindowJoinUtil.accessesTimeAttribute(remainingPreds.get, joinRowType)
//The RowTime property cannot appear in the association condition of a normal join
//@see https://stackoverflow.com/questions/57181771/flink-rowtime-attributes-must-not-be-in-the-input-rows-of-a-regular-join
val rowTimeAttrInOutput = joinRowType.getFieldList
.exists(f => FlinkTypeFactory.isRowtimeIndicatorType(f.getType))
if (rowTimeAttrInOutput) {
throw new TableException(
"Rowtime attributes must not be in the input rows of a regular join. " +
"As a workaround you can cast the time attributes of input tables to TIMESTAMP before.")
}
// joins require an equality condition
// or a conjunctive predicate with at least one equality condition
// and disable outer joins with non-equality predicates(see FLINK-5520)
// And do not accept a FlinkLogicalTemporalTableSourceScan as right input
!remainingPredsAccessTime
}
}
Its basic logic is that in ordinary dual stream Join, Temporal Table, time window and access to time attributes are not supported. One thing to note here is that in an ordinary dual stream Join, Flink cannot ensure that the association results are submitted in chronological order, which will destroy the order of time attributes. Therefore, in an ordinary dual stream Join, the association conditions do not support time attributes.
StreamExecJoinRule will convert FlinkLogicalJoin to StreamexecJoin, but accordingly, the two inputs of FlinkLogicalJoin need to be transformed first. Here, the trait of FlinkRelDistribution will be pushed down to the input operator.
FlinkRelDistribution is used to determine the partition information that the result of the upstream operator is forwarded to the downstream operator. For example, if there is an equivalent Association condition in the association condition, the hash partition will be carried out according to the corresponding association key to ensure that the records of the same key are forwarded to the same Task, that is, FlinkRelDistribution hash; If there is no equivalent condition in the association condition, all records can only be forwarded to the same Task, that is, FlinkRelDistribution SINGLETON.
class StreamExecJoinRule{
override def onMatch(call: RelOptRuleCall): Unit = {
val join: FlinkLogicalJoin = call.rel(0)
val left = join.getLeft
val right = join.getRight
//Determine FlinkRelDistribution according to whether there is equivalent correlation condition
def toHashTraitByColumns(
columns: util.Collection[_ <: Number],
inputTraitSets: RelTraitSet): RelTraitSet = {
val distribution = if (columns.isEmpty) {
FlinkRelDistribution.SINGLETON
} else {
FlinkRelDistribution.hash(columns)
}
inputTraitSets
.replace(FlinkConventions.STREAM_PHYSICAL)
.replace(distribution)
}
val joinInfo = join.analyzeCondition()
val (leftRequiredTrait, rightRequiredTrait) = (
toHashTraitByColumns(joinInfo.leftKeys, left.getTraitSet),
toHashTraitByColumns(joinInfo.rightKeys, right.getTraitSet))
val providedTraitSet = join.getTraitSet.replace(FlinkConventions.STREAM_PHYSICAL)
//Transform input
val newLeft: RelNode = RelOptRule.convert(left, leftRequiredTrait)
val newRight: RelNode = RelOptRule.convert(right, rightRequiredTrait)
//Generate StreamExecJoin
val newJoin = new StreamExecJoin(
join.getCluster,
providedTraitSet,
newLeft,
newRight,
join.getCondition,
join.getJoinType)
call.transformTo(newJoin)
}
}
The matching transformation rules for FlinkRelDistribution are in flinkrexpandconversionrule. The function of flinkeexpandconversionrule is to handle two kinds of trait s: RelDistribution and relcolligation, in which RelDistribution describes the physical distribution of data and relcolligation describes the sorting (usually applied in ORDER BY statement in Batch mode).
In the flinkrexpandconversionrule, a streamexexexchange will be generated for the transformation of the target trail containing FlinkRelDistribution:
class FlinkExpandConversionRule(flinkConvention: Convention)
extends RelOptRule(
operand(classOf[AbstractConverter],
operand(classOf[RelNode], any)),
"FlinkExpandConversionRule") {
override def matches(call: RelOptRuleCall): Boolean = {
// from trait and to trait are inconsistent
val toTraitSet = call.rel(0).asInstanceOf[AbstractConverter].getTraitSet
val fromTraitSet = call.rel(1).asInstanceOf[RelNode].getTraitSet
toTraitSet.contains(flinkConvention) &&
fromTraitSet.contains(flinkConvention) &&
!fromTraitSet.satisfies(toTraitSet)
}
override def onMatch(call: RelOptRuleCall): Unit = {
val converter: AbstractConverter = call.rel(0)
val child: RelNode = call.rel(1)
val toTraitSet = converter.getTraitSet
// try to satisfy required trait by itself.
satisfyTraitsBySelf(child, toTraitSet, call)
// try to push down required traits to children.
satisfyTraitsByInput(child, toTraitSet, call)
}
private def satisfyTraitsBySelf(
node: RelNode,
requiredTraits: RelTraitSet,
call: RelOptRuleCall): Unit = {
var transformedNode = node
val definedTraitDefs = call.getPlanner.getRelTraitDefs
// Handling FlinkRelDistribution
if (definedTraitDefs.contains(FlinkRelDistributionTraitDef.INSTANCE)) {
val toDistribution = requiredTraits.getTrait(FlinkRelDistributionTraitDef.INSTANCE)
transformedNode = satisfyDistribution(flinkConvention, transformedNode, toDistribution)
}
if (definedTraitDefs.contains(RelCollationTraitDef.INSTANCE)) {
val toCollation = requiredTraits.getTrait(RelCollationTraitDef.INSTANCE)
transformedNode = satisfyCollation(flinkConvention, transformedNode, toCollation)
}
checkSatisfyRequiredTrait(transformedNode, requiredTraits)
call.transformTo(transformedNode)
}
}
object FlinkExpandConversionRule {
def satisfyDistribution(
flinkConvention: Convention,
node: RelNode,
requiredDistribution: FlinkRelDistribution): RelNode = {
val fromTraitSet = node.getTraitSet
val fromDistribution = fromTraitSet.getTrait(FlinkRelDistributionTraitDef.INSTANCE)
if (!fromDistribution.satisfies(requiredDistribution)) {
requiredDistribution.getType match {
case SINGLETON | HASH_DISTRIBUTED | RANGE_DISTRIBUTED |
BROADCAST_DISTRIBUTED | RANDOM_DISTRIBUTED =>
flinkConvention match {
case FlinkConventions.BATCH_PHYSICAL =>
// replace collation with empty since distribution destroy collation
......
new BatchExecExchange(node.getCluster, traitSet, node, requiredDistribution)
case FlinkConventions.STREAM_PHYSICAL =>
val updateAsRetraction = fromTraitSet.getTrait(UpdateAsRetractionTraitDef.INSTANCE)
val accMode = fromTraitSet.getTrait(AccModeTraitDef.INSTANCE)
// replace collation with empty since distribution destroy collation
val traitSet = fromTraitSet
.replace(requiredDistribution)
.replace(flinkConvention)
.replace(RelCollations.EMPTY)
.replace(updateAsRetraction)
.replace(accMode)
// Generate streamexexexchange
new StreamExecExchange(node.getCluster, traitSet, node, requiredDistribution)
case _ => throw new TableException(s"Unsupported convention: $flinkConvention")
}
case _ => throw new TableException(s"Unsupported type: ${requiredDistribution.getType}")
}
} else {
node
}
}
}
5. Physical execution plan
After getting the final logical execution plan, you need to convert it into a physical execution plan, that is, generate the Transformation operator inside Flink.
First, the input of StreamExecJoin is two streamexexchange nodes. Streamexexchange will generate a PartitionTransformation operator to determine the distribution of upstream data to downstream. According to reldistribution For different types, the StreamPartitioner of PartitionTransformation will choose to use GlobalPartitioner (corresponding to RelDistribution.Type.SINGLETON) or KeyGroupStreamPartitioner (corresponding to RelDistribution.Type.HASH_DISTRIBUTED).
class StreamExecExchange {
//Generate physical execution plan
override protected def translateToPlanInternal(
planner: StreamPlanner): Transformation[BaseRow] = {
val inputTransform = getInputNodes.get(0).translateToPlan(planner)
.asInstanceOf[Transformation[BaseRow]]
val inputTypeInfo = inputTransform.getOutputType.asInstanceOf[BaseRowTypeInfo]
val outputTypeInfo = BaseRowTypeInfo.of(
FlinkTypeFactory.toLogicalRowType(getRowType))
relDistribution.getType match {
// If the distribution is SINGLETON (there is no equivalent correlation condition), all records are forwarded to the same partition
case RelDistribution.Type.SINGLETON =>
val partitioner = new GlobalPartitioner[BaseRow]
val transformation = new PartitionTransformation(
inputTransform,
partitioner.asInstanceOf[StreamPartitioner[BaseRow]])
transformation.setOutputType(outputTypeInfo)
transformation.setParallelism(1)
transformation
case RelDistribution.Type.HASH_DISTRIBUTED =>
val selector = KeySelectorUtil.getBaseRowSelector(
relDistribution.getKeys.map(_.toInt).toArray, inputTypeInfo)
// If the distribution is HASH (there is equivalent correlation condition), partition according to HASH
val partitioner = new KeyGroupStreamPartitioner(selector,
DEFAULT_LOWER_BOUND_MAX_PARALLELISM)
val transformation = new PartitionTransformation(
inputTransform,
partitioner.asInstanceOf[StreamPartitioner[BaseRow]])
transformation.setOutputType(outputTypeInfo)
transformation.setParallelism(ExecutionConfig.PARALLELISM_DEFAULT)
transformation
case _ =>
throw new UnsupportedOperationException(
s"not support RelDistribution: ${relDistribution.getType} now!")
}
}
}
For StreamExecJoin, a TwoInputTransformation will be generated for it, and its internal conversion code is as follows:
class StreamExecJoin {
override protected def translateToPlanInternal(
planner: StreamPlanner): Transformation[BaseRow] = {
val tableConfig = planner.getTableConfig
val returnType = BaseRowTypeInfo.of(FlinkTypeFactory.toLogicalRowType(getRowType))
// Transform the upstream input
val leftTransform = getInputNodes.get(0).translateToPlan(planner)
.asInstanceOf[Transformation[BaseRow]]
val rightTransform = getInputNodes.get(1).translateToPlan(planner)
.asInstanceOf[Transformation[BaseRow]]
val leftType = leftTransform.getOutputType.asInstanceOf[BaseRowTypeInfo]
val rightType = rightTransform.getOutputType.asInstanceOf[BaseRowTypeInfo]
// Get the Join Key, that is, the equivalent Association condition
val (leftJoinKey, rightJoinKey) =
JoinUtil.checkAndGetJoinKeys(keyPairs, getLeft, getRight, allowEmptyKey = true)
// Generate the code of KeySelector to extract the Join Key
// If there is no equivalent Association condition, the null binaryrowkeyselector is returned and the Join Key is empty
val leftSelect = KeySelectorUtil.getBaseRowSelector(leftJoinKey, leftType)
val rightSelect = KeySelectorUtil.getBaseRowSelector(rightJoinKey, rightType)
// Analyze whether UniqueKey exists on the input side of the Join and whether the Join key contains UniqueKey
// The storage and search methods of the status will be optimized according to UniqueKey
val leftInputSpec = analyzeJoinInput(left)
val rightInputSpec = analyzeJoinInput(right)
// Generate code for comparing Association conditions. Here, only non equivalent Association conditions are processed. The equivalent Association conditions are implicitly completed through the state
val generatedCondition = JoinUtil.generateConditionFunction(
tableConfig,
cluster.getRexBuilder,
getJoinInfo,
leftType.toRowType,
rightType.toRowType)
//Status save time
val minRetentionTime = tableConfig.getMinIdleStateRetentionTime
//Internal operator
val operator = if (joinType == JoinRelType.ANTI || joinType == JoinRelType.SEMI) {
new StreamingSemiAntiJoinOperator(
joinType == JoinRelType.ANTI,
leftType,
rightType,
generatedCondition,
leftInputSpec,
rightInputSpec,
filterNulls,
minRetentionTime)
} else {
val leftIsOuter = joinType == JoinRelType.LEFT || joinType == JoinRelType.FULL
val rightIsOuter = joinType == JoinRelType.RIGHT || joinType == JoinRelType.FULL
new StreamingJoinOperator(
leftType,
rightType,
generatedCondition,
leftInputSpec,
rightInputSpec,
leftIsOuter,
rightIsOuter,
filterNulls,
minRetentionTime)
}
//Transform
val ret = new TwoInputTransformation[BaseRow, BaseRow, BaseRow](
leftTransform,
rightTransform,
getRelDetailedDescription,
operator,
returnType,
leftTransform.getParallelism)
// The input has a reldistribution Type. Singleton (no equivalent correlation condition), then the parallelism of the Join operator is set to 1
if (inputsContainSingleton()) {
ret.setParallelism(1)
ret.setMaxParallelism(1)
}
// set KeyType and Selector for state
// Set the KeySelector of the state. The state is KeyedState
ret.setStateKeySelectors(leftSelect, rightSelect)
ret.setStateKeyType(leftSelect.getProducedType)
ret
}
}
In the process of converting StreamExecJoin into TwoInputTransformation, we will first analyze the characteristics of the two upstream inputs, including whether there is an association key (corresponding to the equivalent Association condition) and whether there is a Unique Key (Unique Key, which can be used to ensure that the upstream output is unique. Refer to the reading notes of Flink source code (18) - flows and dynamic tables in Flink SQL), Whether the associated key contains a Unique Key, etc. Depending on the Join type, the internal operator of TwoInputTransformation is StreamingJoinOperator or StreamingSemiAntiJoinOperator (for SEMI/ANTI Join). The StreamingJoinOperator uses KeyedState internally, so the KeySelector of the state is set as the correlation key.
6. Optimization of state storage
In the case of dual stream Join, in order to ensure the correctness of the association results, the history record needs to be saved in the state. With the continuous arrival of data in the data stream, the overhead of caching historical data is increasing. To this end, Flink SQL supports limiting the state saving time by configuring the state TTL on the one hand, and optimizes the state storage structure on the other hand.
According to the characteristics of the input side in JoinInputSideSpec (whether it contains a unique key and whether the associated key contains a unique key), Flink SQL designs several different state storage structures, namely JoinKeyContainsUniqueKey, InputSideHasUniqueKey and InputSideHasNoUniqueKey, as follows:
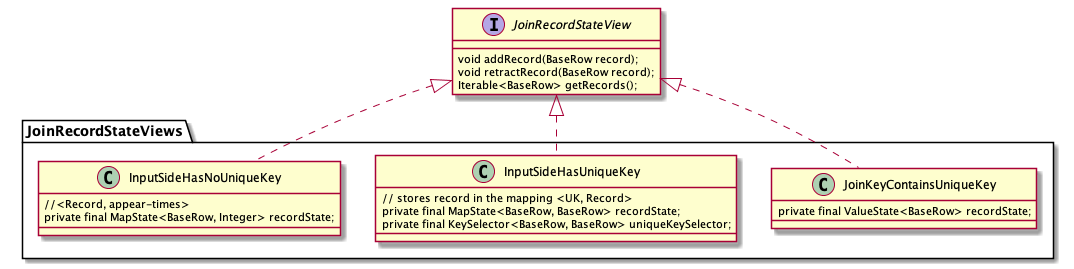
The JoinRecordStateView interface is implemented for the above different state stores. The three methods provided are as follows: adding a record to the state, withdrawing a record, and querying associated records:
public interface JoinRecordStateView {
/**
* Add a new record to the state view.
*/
void addRecord(BaseRow record) throws Exception;
/**
* Retract the record from the state view.
*/
void retractRecord(BaseRow record) throws Exception;
/**
* Gets all the records under the current context (i.e. join key).
*/
Iterable<BaseRow> getRecords() throws Exception;
}
The current state of the joinstream is the record used by the joinstream operator. In different cases, the structure and access overhead of different state storage are as follows:
| State Structure | Update Row | Query by JK | Note | |
|---|---|---|---|---|
| JoinKeyContainsUniqueKey | <JK,ValueState<Record>> | O(1) | O(1) | |
| InputSideHasUniqueKey | <JK,MapState<UK,Record>> | O(2) | O(N) | N = size of MapState |
| InputSideHasNoUniqueKey | <JK,MapState<Record, appear-times>> | O(2) | O(N) | N = size of MapState |
The contents in the above table are not difficult to understand. According to the characteristics of Join Key and Unique Key, the state structure is divided into three cases:
- If the Join Key contains a Unique Key, a Join Key will only correspond to one record, so the state storage selects ValueState
- If there is a Unique Key in the input, but the Join Key does not contain a Unique Key, a Join Key may correspond to multiple records, but the unique keys of these records must be different. Therefore, select MapState, where key is the Unique Key and value is the corresponding record
- If there is no Unique Key in the input, the status can only be ListState or MapState. Considering the efficiency of update and retract, choose to use MapState, directly use the record itself as the Key, and value is the number of occurrences of the record
Another special case is that there is no Join Key (Cartesian product), which is actually a special case of InputSideHasNoUniqueKey. All the recorded join keys are binaryrowutil EMPTY_ ROW.
In terms of final performance
JoinkKeyContainsUniqueKey > InputSideHasUniqueKey > InputSideHasNoUniqueKey.
If it is an external connection, the state of the external connection side needs to implement the OuterJoinRecordStateView interface. Its specific implementation can also be divided into three cases, as follows:
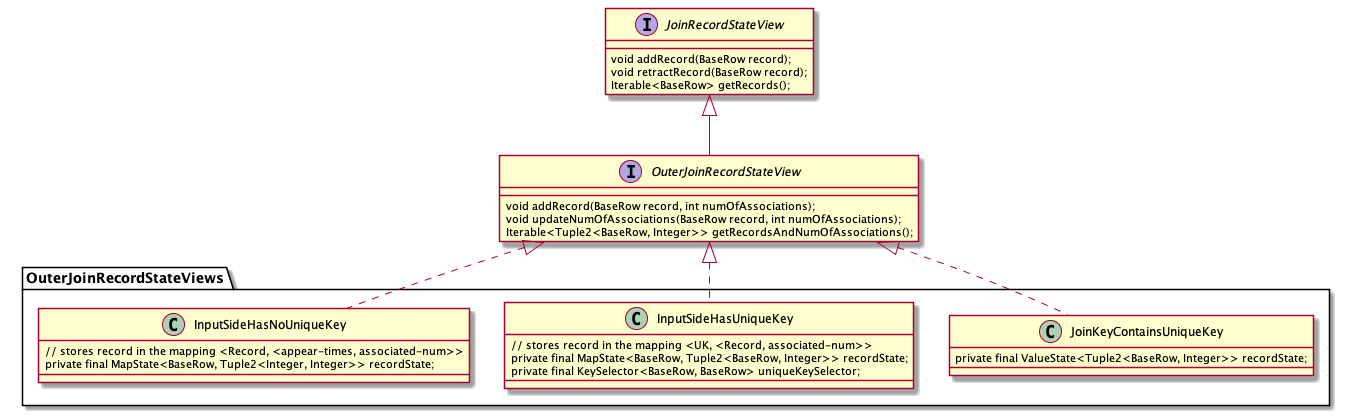
OuterJoinRecordStateView is an extension of JoinRecordStateView. In addition to storing the record itself in the state, it also stores the number of records associated with the record on the other side. The reason why the number of associated records should be stored in the state is mainly to facilitate the processing and withdrawal of the results filled with NULL values in the Outer Join. The specific logic of association will be further described below. In addition, the storage structures of OuterJoinRecordStateView and JoinRecordStateView are consistent.
7. Association processing logic
The main logic in StreamingJoinOperator is actually two steps:
- Update the status of this side when the data arrives
- When the data arrives, query the status of the other side according to the Join Key
In Streaming SQL, there are two types of messages, ACCUMULATE and RETRACT, which need to be considered separately in the Join. If the reached message is a record of type ACCUMULATE, the pseudo code of the corresponding processing logic is as follows:
//record is ACC
if input side is outer //This side is outer join
if no matched row on the other side //There is no matching record on the other side
send +[record + null]
state.add(record, 0) // 0 means there is no associated record on the other side
else // other.size > 0
if other side is outer
if (associated rows in matched rows == 0)
//There is no matching record on the other side, so the previous [null + other] needs to be withdrawn
send -[null + other]
else
skip
endif
otherState.update(other, old + 1) //Associated record on the other side + 1
endif
send +[record, other]s //Send as many records as there are matches on the other side
state.add(record, other.size) //Update status
endif
else //This side is not an outer join
state.add(record)
if no matched row on the other side //There is no matching record on the other side
skip //No output required
else // other.size > 0
if other size is outer
if (associated rows in matched rows == 0)
send -[null + other]
else
skip
endif
otherState.update(other, old + 1) //Associated record on the other side + 1
endif
send +[record + other]s //Send as many records as there are matches on the other side
endif
endif
The case of Inner Join is relatively simple. Here we need to pay attention to the processing of Outer Join. Outer Join requires that the result filled with NULL value be output when there is no matching record, but when there is a matching record on the other side, the sent NULL value filling record needs to be withdrawn and corrected to the normal association result. Therefore, the number of associated records will be saved in OuterJoinRecordStateView. If the number of associated records is 0, it indicates that records filled with NULL values have been sent before. Then withdrawal operation is required to avoid recalculating the number of associated records each time.
If the received record is a RETRACT message, the pseudo code of the corresponding processing logic is as follows:
//record is RETRACT
state.retract(record)
if no matched rows on the other side //There is no associated record on the other side
if input side is outer
send -[record + null]
endif
else //There is an associated record on the other side
send -[record, other]s //To recall a sent associated record
if other side is outer
if the matched num in the matched rows == 0, this should never happen!
if the matched num in the matched rows == 1, send +[null + other]
if the matched num in the matched rows > 1, skip
otherState.update(other, old - 1) //Number of records associated on the other side - 1
endif
endif
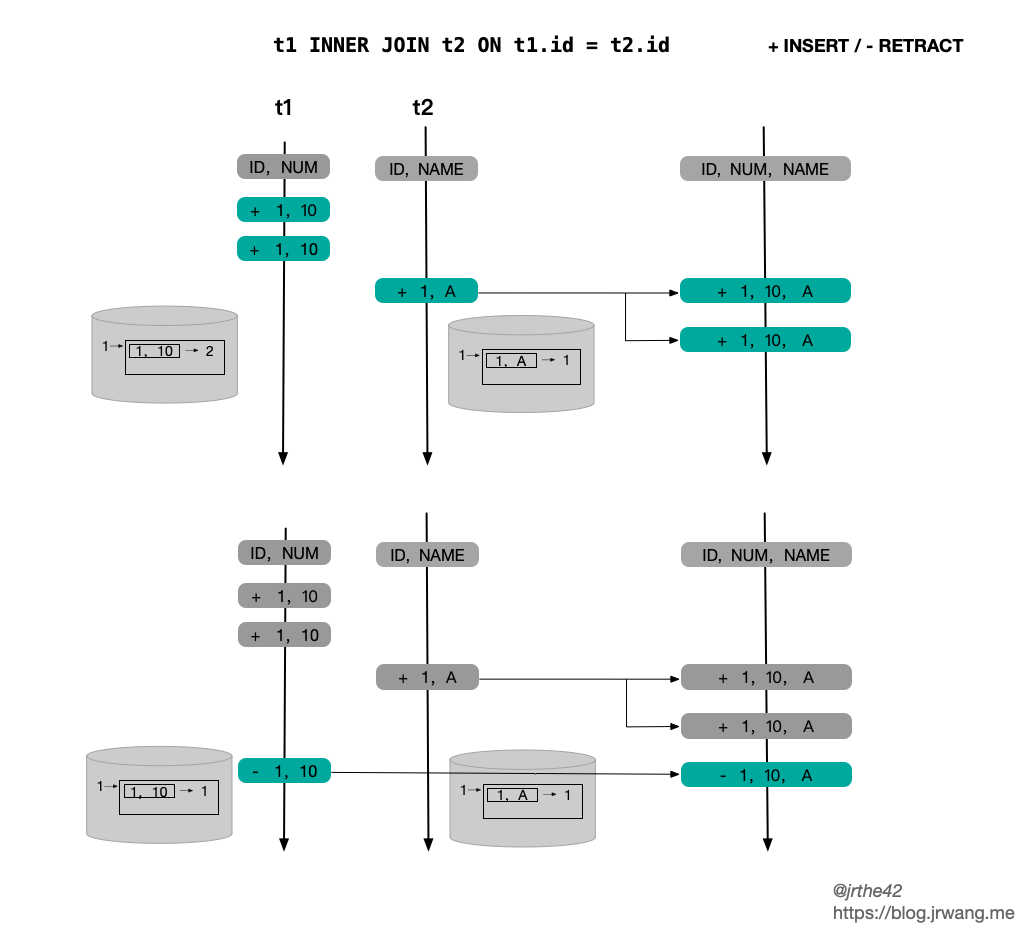
The following figure gives a simple example of an inner join. The States on both sides are InputSideHasNoUniqueKey, and the upper and lower parts correspond to ACCMULATE and RETRACT respectively:
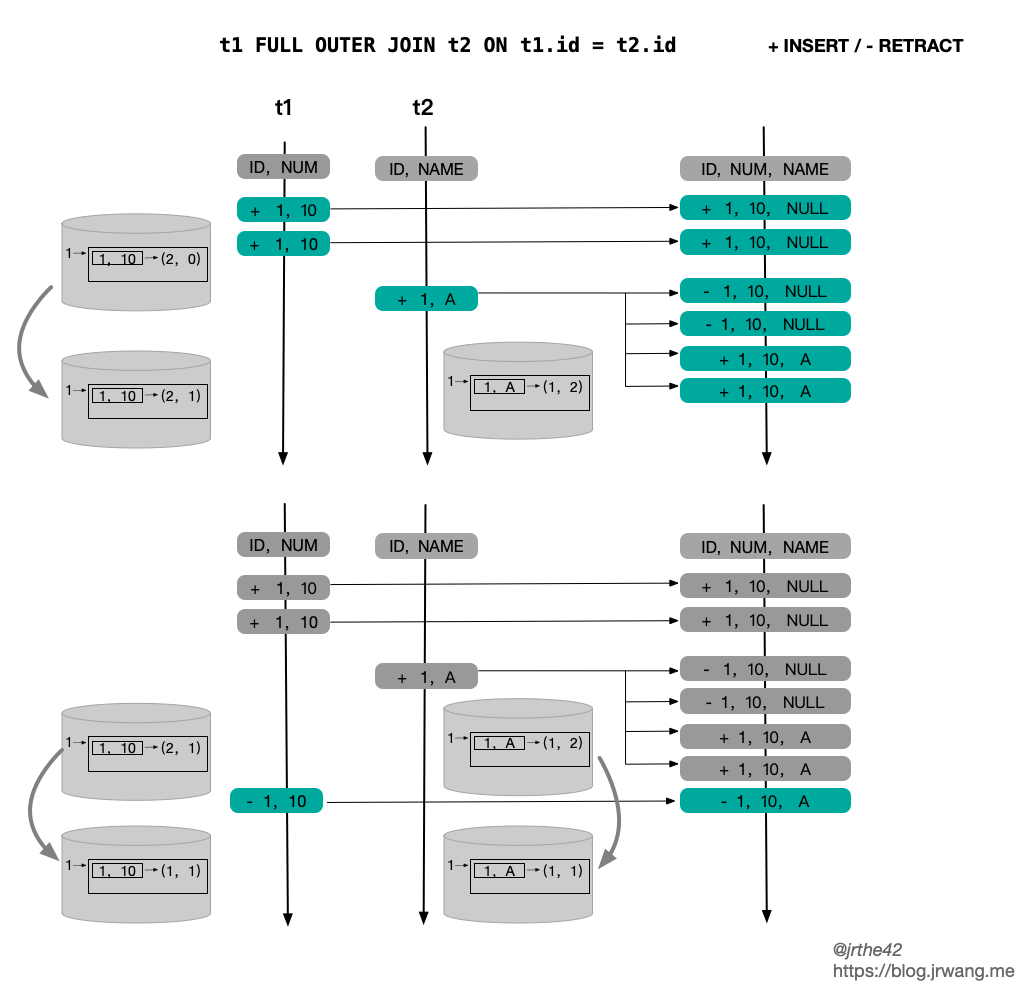
The following figure shows the situation of Full outer join:
8.SEMI/ANTI JOIN
Flink SQL supports SEMI JOIN (SEMI JOIN) and ANTI JOIN (ANTI JOIN) in addition to ordinary Join. The difference between SEMI/ANTI Join and ordinary Join is that there is no need to obtain data from the right table. A simple example is as follows:
-- SEMI JON SELECT * FROM l WHERE a IN (SELECT d FROM r) -- ANTI JOIN SELECT * FROM l WHERE a NOT IN (SELECT d FROM r)
SEMI/ANTI Join is finally transformed into StreamingSemiAntiJoinOperator operator, and the state storage on the left and right sides uses OuterJoinRecordStateView and JoinRecordStateView respectively. The logic of StreamingSemiAntiJoinOperator and StreamingJoinOperator are very similar, but they are simpler because they do not need to splice the data of the right table, so they will not be introduced further here.
9. Summary
This paper analyzes the challenges faced by dual stream Join in Streaming SQL, and introduces the specific implementation mechanism of dual stream Join in Flink SQL. Flink SQL limits the infinite growth of states under infinite data flow based on the state lifetime, and makes full use of the unique key feature to optimize the storage form of states; In addition, Flink ensures the correctness of association results based on ACC/RETRACT mechanism.