Redis distributed lock
Redis is a single process and single thread mode. The queue mode is adopted to change concurrent access into serial access, and there is no competition between multiple clients for redis connection. In redis, SETNX command can be used to realize distributed locking.
If and only if the key does not exist, set the value of the key to value. If the given key already exists, SETNX will not take any action
SETNX is the abbreviation of "SET if Not eXists".
Return value: set successfully, return 1. Setting failed, return 0.
The process and matters of using SETNX to complete synchronous lock are as follows:
Use the SETNX command to obtain the lock. If 0 is returned (the key already exists and the lock already exists), the acquisition fails. Otherwise, the acquisition succeeds
In order to prevent exceptions in the program after obtaining the lock, causing other threads / processes to always return 0 when calling SETNX command and enter the deadlock state, it is necessary to set a "reasonable" expiration time for the key
Release the lock and delete the lock data with DEL command
There is an article about the principle of Setnx implementation:
redis setnx distributed lock
Distributed lock code implementation:
lua+redis distributed lock evolution code
Redlock
Common implementation
When it comes to Redis distributed locks, most people will think of: setnx+lua, or know set key value px milliseconds nx. The core implementation commands of the latter method are as follows:
- Acquire lock( unique_value Can be UUID Etc.)
SET resource_name unique_value NX PX 30000
- Release lock( lua In the script, be sure to compare value,Prevent accidental unlocking)
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
There are three key points in this implementation method (which is also where the interview probability is very high):
- set key value px milliseconds nx is used for the set command;
- value should be unique;
- When releasing the lock, verify the value value and do not unlock it by mistake;
In fact, the biggest disadvantage of this kind of trivial is that it only works on one Redis node when locking. Even if Redis ensures high availability through sentinel, if the master-slave switch occurs for some reason, the lock will be lost:
- Get the lock on the master node of Redis;
- However, the locked key has not been synchronized to the slave node;
- If the master fails, failover occurs, and the slave node is upgraded to the master node;
- The lock is lost.
Therefore, the official Redis station proposes an authoritative Redis based distributed locking method called Redlock, which is more secure than the original single node method. It guarantees the following features:
- Security feature: mutually exclusive access, that is, only one client can get the lock forever
- Avoid deadlock: in the end, the client may get the lock without deadlock, even if the client that originally locked a resource crashes or has a network partition
- Fault tolerance: as long as most Redis nodes survive, they can provide services normally
The redlock algorithm proposed by antirez is roughly as follows:
In the Redis distributed environment, we assume that there are n Redis master s. These nodes are completely independent of each other, and there is no master-slave replication or other cluster coordination mechanisms. We ensure that we will use the same method to obtain and release locks on N instances as in Redis single instance. Assuming that there are five Redis servers running on them at the same time, we need to ensure that they will not be down at the same time.
In order to get the lock, the client should do the following:
- Gets the current Unix time in milliseconds.
- Try to obtain locks from five instances in turn, using the same key and unique value (such as UUID). When requesting a lock from Redis, the client should set a network connection and response timeout, which should be less than the expiration time of the lock. For example, if your lock automatically expires for 10 seconds, the timeout should be between 5-50 milliseconds. This can prevent the client from waiting for the response result when the server-side Redis has hung up. If the server fails to respond within the specified time, the client should try to obtain the lock from another Redis instance as soon as possible.
- The client uses the current time to subtract the time of starting to acquire the lock (the time recorded in step 1) to get the time of acquiring the lock. The lock can only be obtained if and only if the lock is obtained from most Redis nodes (N/2+1, here are three nodes) and the use time is less than the lock expiration time.
- If the lock is obtained, the real effective time of the key is equal to the effective time minus the time used to obtain the lock (the result calculated in step 3).
- If the lock acquisition fails for some reason (the lock is not obtained in at least N/2+1 Redis instances or the lock acquisition time has exceeded the effective time), The client should unlock all Redis instances (even if some Redis instances are not locked successfully at all, to prevent some nodes from acquiring the lock, but the client does not get a response, so that the lock cannot be acquired again in the next period of time).
Redlock source code
redisson has encapsulated the redislock algorithm. Next, we will briefly introduce its usage and analyze the core source code (assuming five redis instances).
- POM dependency
<!-- https://mvnrepository.com/artifact/org.redisson/redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.3.2</version>
</dependency>
usage
First, let's take a look at the distributed lock usage implemented by the redlock algorithm encapsulated by redistribution. It is very simple and is a little similar to reentrant lock:
Example 1:
Config config = new Config();
config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389")
.setMasterName("masterName")
.setPassword("password").setDatabase(0);
RedissonClient redissonClient = Redisson.create(config);
// You can also getFairLock(), getReadWriteLock()
RLock redLock = redissonClient.getLock("REDLOCK_KEY");
boolean isLock;
try {
isLock = redLock.tryLock();
// If you can't get the lock within 500ms, it is considered that obtaining the lock failed. 10000ms, i.e. 10s, is the lock failure time.
isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS);
if (isLock) {
//TODO if get lock success, do something;
}
} catch (Exception e) {
} finally {
// In any case, unlock it in the end
redLock.unlock();
}
Example 2:
@RequestMapping("/redlock")
public String redlock() {
String lockKey = "product_001";
//Here, you need to instantiate the redisson client connections of different redis instances. Here is only the pseudo code, which is simplified by using a redisson client
RLock lock1 = redisson.getLock(lockKey);
RLock lock2 = redisson.getLock(lockKey);
RLock lock3 = redisson.getLock(lockKey);
/**
* RedissonRedLock is built based on multiple RLock objects (the core difference is here)
*/
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
try {
/**
* waitTimeout The maximum waiting time for trying to acquire a lock. If it exceeds this value, it is considered that acquiring a lock has failed
* leaseTime The holding time of the lock. After this time, the lock will automatically expire (the value should be set to be greater than the business processing time to ensure that the business can be processed within the lock validity period)
*/
boolean res = redLock.tryLock(10, 30, TimeUnit.SECONDS);
if (res) {
//Successfully obtain the lock and process the business here
}
} catch (Exception e) {
throw new RuntimeException("lock fail");
} finally {
//In any case, unlock it in the end
redLock.unlock();
}
return "end";
}
Unique ID:
A very important point in implementing distributed locks is that the value of set should be unique. How does the value of reisson ensure the uniqueness of value? The answer is UUID+threadId. The entry is redissonclient Getlock ("REDLOCK_KEY"), the source code is in redisson Java and redissonlock In Java:
protected final UUID id = UUID.randomUUID();
String getLockName(long threadId) {
return id + ":" + threadId;
}
Acquire lock:
The code to obtain the lock is redlock Trylock() or redlock Trylock (500, 10000, timeunit. Milliseconds). The final core source code of both is the following code, but the default lease time of the former is LOCK_EXPIRATION_INTERVAL_SECONDS, i.e. 30s:
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
// Commands sent to 5 redis instances when acquiring locks
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
// First, the KEY of the distributed lock cannot exist. If it does not exist, execute the hset command (hset REDLOCK_KEY uuid+threadId 1) and set the expiration time (also the lease time of the lock) through pexpire
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// If the KEY of the distributed lock already exists and the value also matches, indicating that it is the lock held by the current thread, the number of reentries is increased by 1, and the expiration time is set
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// Gets the number of milliseconds that the KEY of the distributed lock expires
"return redis.call('pttl', KEYS[1]);",
// These three parameters correspond to KEYS[1], ARGV[1] and ARGV[2] respectively
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
In the command to obtain the lock,
- **KEYS[1] * * is collections Singletonlist (getname()), which represents the key of the distributed lock, namely REDLOCK_KEY;
- **ARGV[1] * * is the internalLockLeaseTime, that is, the lease time of the lock, which is 30s by default;
- **ARGV[2] * * is getLockName(threadId), which is the unique value of set when obtaining lock, that is UUID+threadId:
Release lock
The code for releasing the lock is redlock Unlock (), the core source code is as follows:
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
// Execute the following commands to all five redis instances
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// If the distributed lock KEY does not exist, a message is issued to the channel
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end;" +
// If the distributed lock exists, but the value does not match, which indicates that the lock has been occupied, it is returned directly
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
// If the current thread holds the distributed lock, the number of reentries will be reduced by 1
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
// If the number of re-entry times minus 1 is greater than 0, it indicates that the distributed lock has been re-entered, so only the expiration time is set and cannot be deleted
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
// If the value of re-entry times minus 1 is 0, it means that the distributed lock has been obtained only once, then delete the KEY and publish the unlocking message
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
// These five parameters correspond to KEYS[1], KEYS[2], ARGV[1], ARGV[2] and ARGV[3] respectively
Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));
}
For the implementation of Redlock algorithm, we can use Redisson Redlock in Redisson. For details, please refer to the article of the boss: mp.weixin.qq.com/s/8uhYult2h...
Read write lock
The advantage of the read-write lock is that it can help the customer read the latest data. The write lock is an exclusive lock, while the read lock is a shared lock. If the write lock always exists, the read data must wait until the write data is completed, so as to ensure the consistency of the data
Read / write lock code:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public Redisson redisson() {
// This is stand-alone mode
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}
}
@RequestMapping("/get_stock")
public String getStock(@RequestParam("clientId") Long clientId) throws InterruptedException {
String lockKey = "product_stock_101";
RReadWriteLock readWriteLock = redisson.getReadWriteLock(lockKey);
RLock rLock = readWriteLock.readLock();
rLock.lock();
System.out.println("Acquire read lock successfully: client=" + clientId);
String stock = stringRedisTemplate.opsForValue().get("stock");
if (StringUtils.isEmpty(stock)) {
System.out.println("The query database inventory is 10...");
Thread.sleep(5000);
stringRedisTemplate.opsForValue().set("stock", "10");
}
rLock.unlock();
System.out.println("Successful release of read lock: client=" + clientId);
return "end";
}
@RequestMapping("/update_stock")
public String updateStock(@RequestParam("clientId") Long clientId) throws InterruptedException {
String lockKey = "product_stock_101";
RReadWriteLock readWriteLock = redisson.getReadWriteLock(lockKey);
RLock writeLock = readWriteLock.writeLock();
writeLock.lock();
System.out.println("Successfully obtained write lock: client=" + clientId);
System.out.println("Modify the database inventory of item 101 to 6...");
stringRedisTemplate.delete("stock");
Thread.sleep(5000);
writeLock.unlock();
System.out.println("Successful release of write lock: client=" + clientId);
return "end";
}
Cache design
Cache penetration
Cache penetration refers to querying a data that does not exist at all, and neither the cache layer nor the storage layer will hit. Generally, for the sake of fault tolerance, if the data cannot be found from the storage layer, it will not be written to the cache layer.
Cache penetration will cause nonexistent data to be queried in the storage layer every request, losing the significance of cache protection for back-end storage.
Example: for system A, suppose there are 5000 requests per second, of which 4000 are malicious attacks by hackers.
The 4000 attacks sent by hackers can't be found in the cache. Every time you go to the database, you can't find them.
Assuming that the database id starts from 1, the request IDS sent by hackers are all negative. In this way, there will be no requests in the cache. Each time, the request will "treat the cache as nothing" and query the database directly. The cache penetration of this malicious attack scenario will directly kill the database.
There are two basic reasons for cache penetration:
First, there is a problem with its own business code or data.
Second, some malicious attacks and crawlers cause a large number of empty hits.
Solution to cache penetration problem:
1. Cache empty objects
String get(String key) {
// Get data from cache
String cacheValue = cache.get(key);
// Cache is empty
if (StringUtils.isBlank(cacheValue)) {
// Get from storage
String storageValue = storage.get(key);
cache.set(key, storageValue);
// If the stored data is empty, you need to set an expiration time (300 seconds)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// Cache is not empty
return cacheValue;
}
}
2. Bloom filter
For malicious attacks, the cache penetration caused by requesting a large amount of non-existent data from the server can also be filtered first with the bloom filter. For non-existent data, the bloom filter can generally be filtered out to prevent the request from being sent to the back end. When the bloom filter says that a value exists, the value may not exist; When it says it doesn't exist, it certainly doesn't exist.
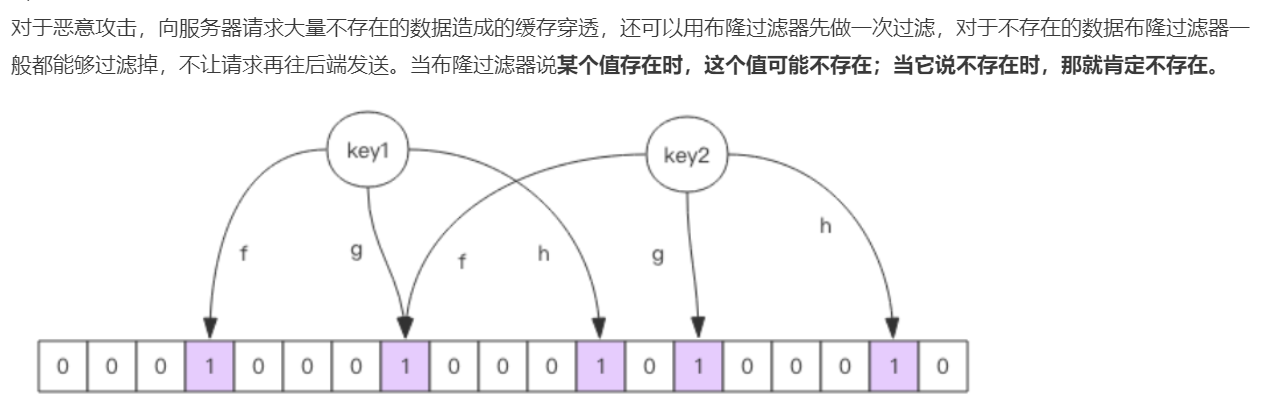
Bloom filter is a large set of bits and several different unbiased hash functions. Unbiased means that the hash value of an element can be calculated evenly.
When adding a key to the bloom filter, multiple hash functions will be used to hash the key to obtain an integer index value, and then modulo the length of the bit array to obtain a position. Each hash function will calculate a different position. Then set these positions of the digit group to 1 to complete the add operation.
When you ask the bloom filter whether a key exists, just like add, you will calculate several positions of the hash to see whether these positions in the bit group are all 1. As long as one bit is 0, it means that the key in the bloom filter does not exist. If they are all 1, this does not mean that the key must exist, but it is very likely to exist, because these bits are set to 1, which may be caused by the existence of other keys. If the digit group is sparse, the probability will be large. If the digit group is crowded, the probability will be reduced.
This method is applicable to the application scenarios with low data hit, relatively fixed data and low real-time performance (usually with large data sets). The code maintenance is complex, but the cache space takes up little.
Summary: bloom filter introduces K (k > 1) K (k > 1) independent Hash functions to ensure that the process of element duplication is completed under a given space and misjudgment rate. Its advantage is that the space efficiency and query time are far higher than those of general algorithms, while its disadvantage is that it has a certain misrecognition rate and deletion difficulty. The core idea of Bloom filter algorithm is to use multiple different Hash functions to solve the "conflict". There is a conflict (collision) problem in Hash. The values of two URL s obtained by using the same Hash may be the same. In order to reduce conflicts, we can introduce several more hashes. If we conclude that an element is not in the set through one of the Hash values, then the element must not be in the set. Only when all Hash functions tell us that the element is in the collection can we determine that the element exists in the collection. This is the basic idea of Bloom filter. Bloom filter is generally used to determine whether an element exists in a collection with a large amount of data.
Bloom filter code used in redis
redisson can be used to implement bloom filter and introduce dependency:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.6.5</version> </dependency>
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
//Construct Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//Initialize bloom filter: it is estimated that the element is 100000000L and the error rate is 3%. The size of the underlying bit array will be calculated according to these two parameters
bloomFilter.tryInit(100000000L,0.03);
//Insert 123 into the bloom filter
bloomFilter.add("123");
//Determine whether the following numbers are in the bloom filter
System.out.println(bloomFilter.contains("xxx"));//false
System.out.println(bloomFilter.contains("123"));//true
}
}
To use bloom filter, you need to put all data into bloom filter in advance, and put it into bloom filter when adding data
//Initialize bloom filter
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//Initialize bloom filter: the expected element is 100000000L, and the error rate is 3%
bloomFilter.tryInit(100000000L,0.03);
//Store all data into bloom filter
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) {
// Judge whether the key exists from the level cache of Bloom filter
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "";
}
// Get data from cache
String cacheValue = cache.get(key);
// Cache is empty
if (StringUtils.isBlank(cacheValue)) {
// Get from storage
String storageValue = storage.get(key);
cache.set(key, storageValue);
// If the stored data is empty, you need to set an expiration time (300 seconds)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// Cache is not empty
return cacheValue;
}
}
Cache failure (breakdown)
The failure of mass cache at the same time may lead to a large number of requests penetrating the cache to the database at the same time, which may cause the database to be under excessive pressure or even hang up. In this case, when we increase the cache in batch, we'd better set the cache expiration time of this batch of data to different times in a time period.
Example pseudocode:
String get(String key) {
// Get data from cache
String cacheValue = cache.get(key);
// Cache is empty
if (StringUtils.isBlank(cacheValue)) {
// Get from storage
String storageValue = storage.get(key);
cache.set(key, storageValue);
//Set an expiration time (a random number between 300 and 600)
int expireTime = new Random().nextInt(300) + 300;
if (storageValue == null) {
cache.expire(key, expireTime);
}
return storageValue;
} else {
// Cache is not empty
return cacheValue;
}
}
Cache avalanche
For system A, assuming 5000 requests per second in the peak period every day, the cache could have carried 4000 requests per second in the peak period, but the cache machine unexpectedly went down completely. The cache hangs. At this time, all 5000 requests in one second fall into the database. The database will not be able to carry them. It will call the police and then hang up. At this time, if no special scheme is adopted to deal with the fault, the DBA is very anxious and restarts the database, but the database is immediately killed by new traffic.
The cache fails in a period of time, and a large number of cache penetrations occur. All queries fall on the database, resulting in a cache avalanche.
The solutions of cache avalanche are as follows:
- In advance: redis is highly available, master-slave + sentinel, and redis cluster to avoid total collapse.
- In fact: local ehcache + for example, use Sentinel or Hystrix current limiting and degrading components to avoid MySQL being killed.
- Afterwards: redis is persistent. Once restarted, it will automatically load data from the disk and quickly recover cached data.