Thank Enpei for the complete implementation of the project and open source the code for everyone to exchange and learn.
1, Project introduction
The final effect of this project is gesture control and mouse operation. As shown below
The project is implemented in python and calls opencv, mediapipe, python and other libraries. It consists of the following steps:
1. Use OpenCV to read camera video stream;
2. Identify the pixel coordinates of palm key points;
3. According to the identified palm key point information, the data structure is constructed in the form of graph;
4. Convolute the neural network training data with the GCN diagram provided by Pytorch and classify the gestures;
2, Knowledge disassembly
1,mediapipe
mediapipe is a common function library for deep learning launched by Google. It encapsulates common functions such as face detection, object detection, semantic segmentation and motion tracking, and supports Android, IOS, C + +, Python and other platforms and versions. Simple installation and convenient call.
The following shows how to use finger detection in the following python versions.
Installation Library:
pip install mediapipe
Call example:
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_hands = mp.solutions.hands
# For static images:
IMAGE_FILES = []
with mp_hands.Hands(
static_image_mode=True,
max_num_hands=2,
min_detection_confidence=0.5) as hands:
for idx, file in enumerate(IMAGE_FILES):
# Read an image, flip it around y-axis for correct handedness output (see
# above).
image = cv2.flip(cv2.imread(file), 1)
# Convert the BGR image to RGB before processing.
results = hands.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# Print handedness and draw hand landmarks on the image.
print('Handedness:', results.multi_handedness)
if not results.multi_hand_landmarks:
continue
image_height, image_width, _ = image.shape
annotated_image = image.copy()
for hand_landmarks in results.multi_hand_landmarks:
print('hand_landmarks:', hand_landmarks)
print(
f'Index finger tip coordinates: (',
f'{hand_landmarks.landmark[mp_hands.HandLandmark.INDEX_FINGER_TIP].x * image_width}, '
f'{hand_landmarks.landmark[mp_hands.HandLandmark.INDEX_FINGER_TIP].y * image_height})'
)
mp_drawing.draw_landmarks(
annotated_image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS,
mp_drawing_styles.get_default_hand_landmarks_style(),
mp_drawing_styles.get_default_hand_connections_style())
cv2.imwrite(
'/tmp/annotated_image' + str(idx) + '.png', cv2.flip(annotated_image, 1))
# Draw hand world landmarks.
if not results.multi_hand_world_landmarks:
continue
for hand_world_landmarks in results.multi_hand_world_landmarks:
mp_drawing.plot_landmarks(
hand_world_landmarks, mp_hands.HAND_CONNECTIONS, azimuth=5)
# For webcam input:
cap = cv2.VideoCapture(0)
with mp_hands.Hands(
model_complexity=0,
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as hands:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
# To improve performance, optionally mark the image as not writeable to
# pass by reference.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = hands.process(image)
# Draw the hand annotations on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS,
mp_drawing_styles.get_default_hand_landmarks_style(),
mp_drawing_styles.get_default_hand_connections_style())
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Hands', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()effect: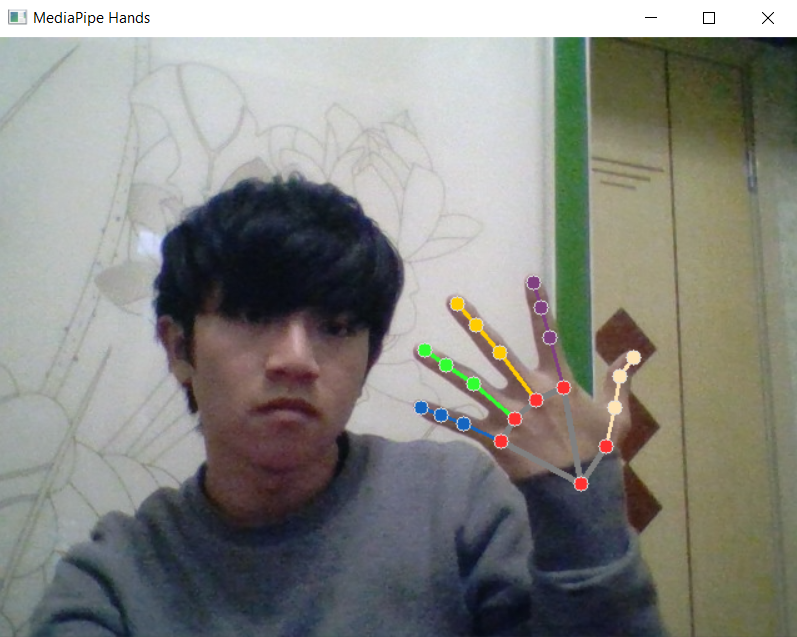
2. Graph neural network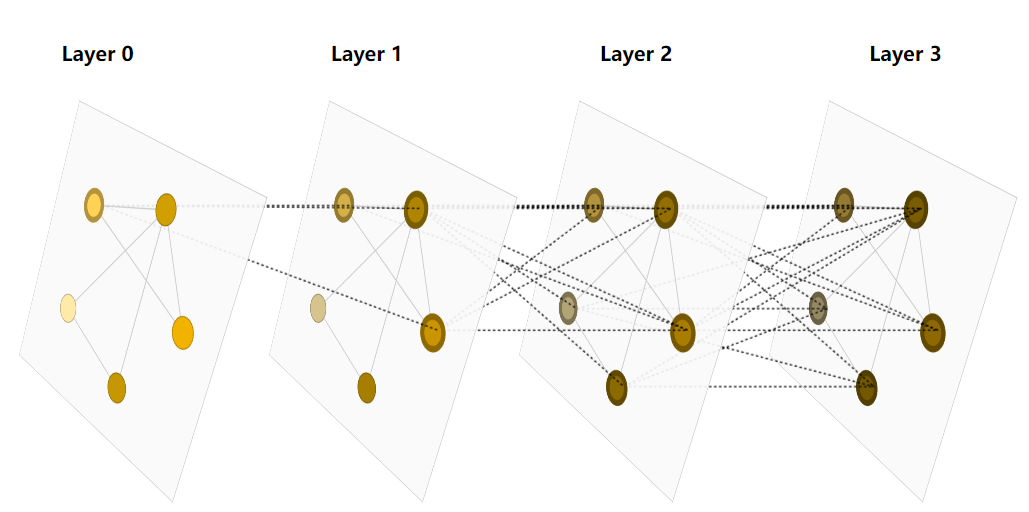
What is a graph
As shown in the figure, the graph is composed of vertices and edges. Graph represents the relationship (edge) between entities (vertices).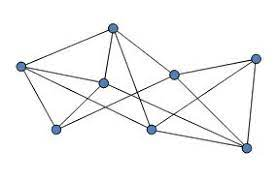
How does the computer represent the diagram
In computer representation, vertex, node and graph are represented by embedding vectors.
Here we can see that the idea of graph neural network is also to represent the points, edges and graphs of graphs with vectors. What we need to care about is how to use these vectors in data processing, and whether we can learn the values of these vectors through data.
In addition, in the classification of graphs, there are mainly directed graphs and undirected graphs.
In short, you and I are all friends, which is called undirected. You like me, but I don't like you. It's called directed.

How are other data represented as graphs
After introducing the data structure of graph and its representation method, we naturally have a question, that is, how to use graph to represent the information such as picture and text?
Picture: we can map each pixel to the node of the graph, and the adjacent pixels are connected by edges. The matrix in the middle is the adjacency matrix. Each blue pixel represents an edge in the graph. It will be used in the representation of neural network compatibility graph later.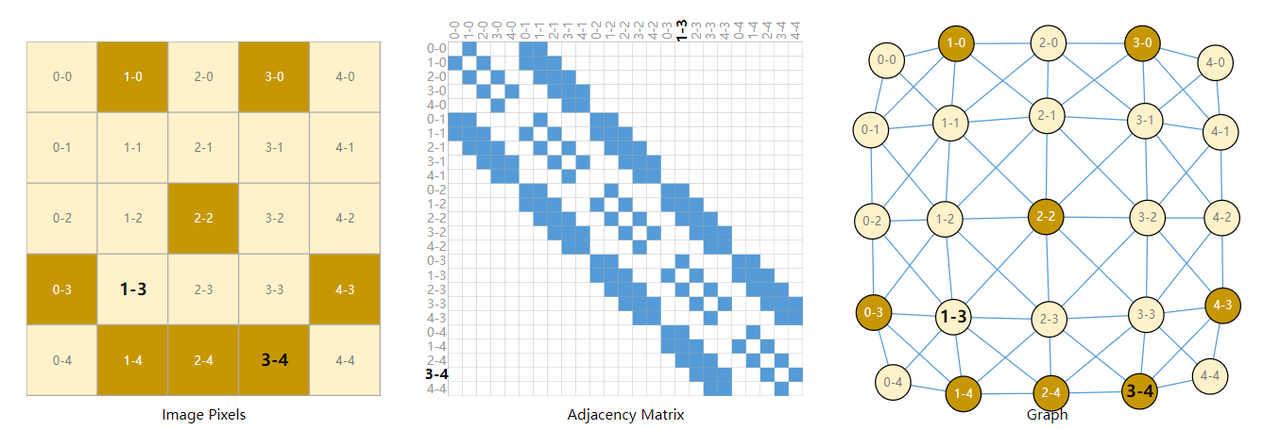
Text: the idea is actually simpler. Each word is used as a node, and the flow direction of the sentence can be represented by a directed edge.
Similarly, in fact, molecules, social relations, article citations and so on are easy to be represented by graphs. It can be seen that graphs are widely used.
What problems can be solved with a diagram
The first is the problem of graph level. Example: in the following figure, the types of graphs are classified according to the number of rings.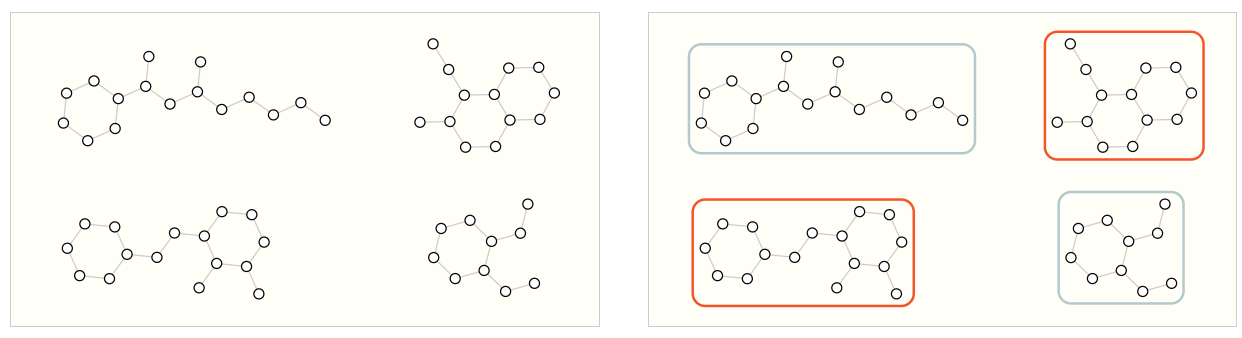
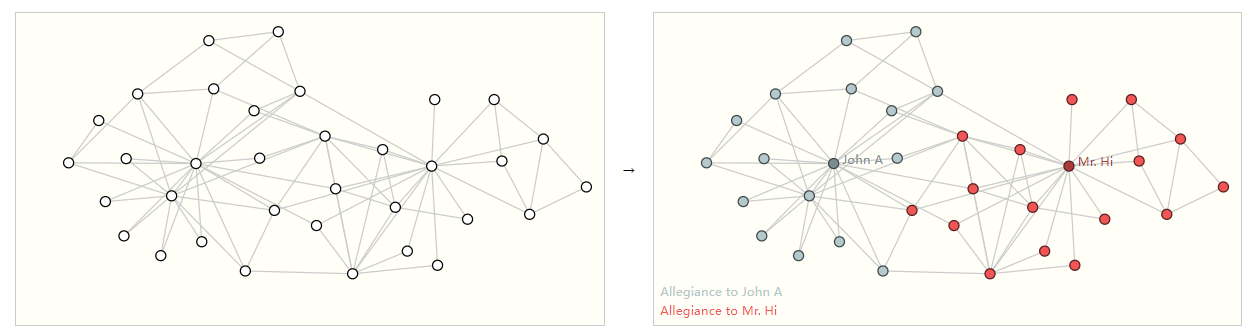
The second is the problem at the point level. For example, in the following figure, all points are divided into two categories according to a certain standard.
The third is the problem at the side level. For example, in the following figure, if each vertex is given meaning (such as player, audience and referee), judge the meaning represented by the edge of each day.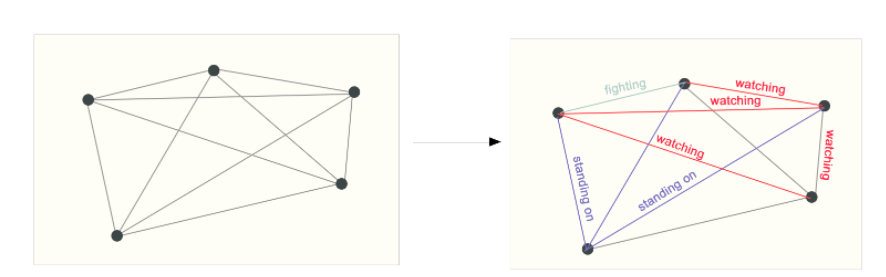
What are the difficulties in using map in deep learning
As we all know, neural network is very friendly to vector compatibility. As mentioned above, edges, vertices and graphs can be represented by embedding vectors, so there is no problem. The fatal thing is the connection. Although we also mentioned that it can be expressed by adjacency matrix, this is obviously OK. The problem is that it will be too sparse and not friendly to storage and operation. Moreover, for the same connection relationship, due to the different order of points, there will be many forms of adjacency matrix, but they essentially represent the same connection. This means that the neural network should make the same response to many different adjacency matrix inputs. It's scary to think about it.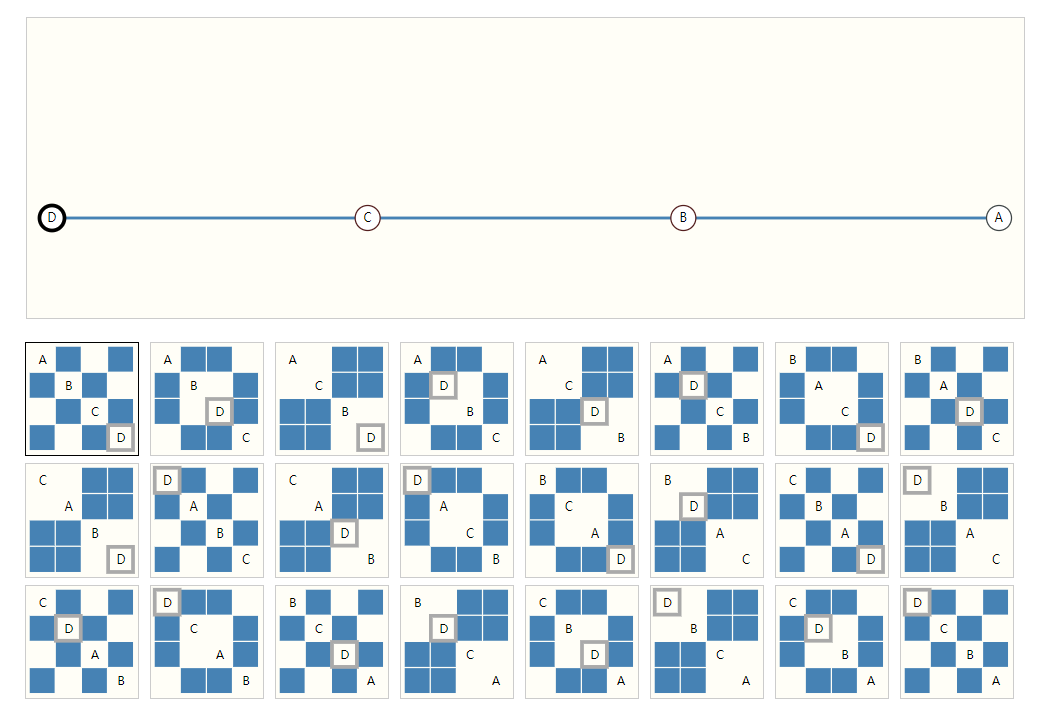
In fact, after a little analysis, it is not difficult for us to find that the information essence of adjacency description is which two points are connected.
We can use a tuple to describe an edge, and the tuple sequence can be sorted according to the sequence of edges to represent the connection relationship without redundancy. In addition, this representation has the advantage of disorder. If the order of the point is disturbed, it is necessary to adjust the ordinal number of the corresponding edge in the adjacency matrix.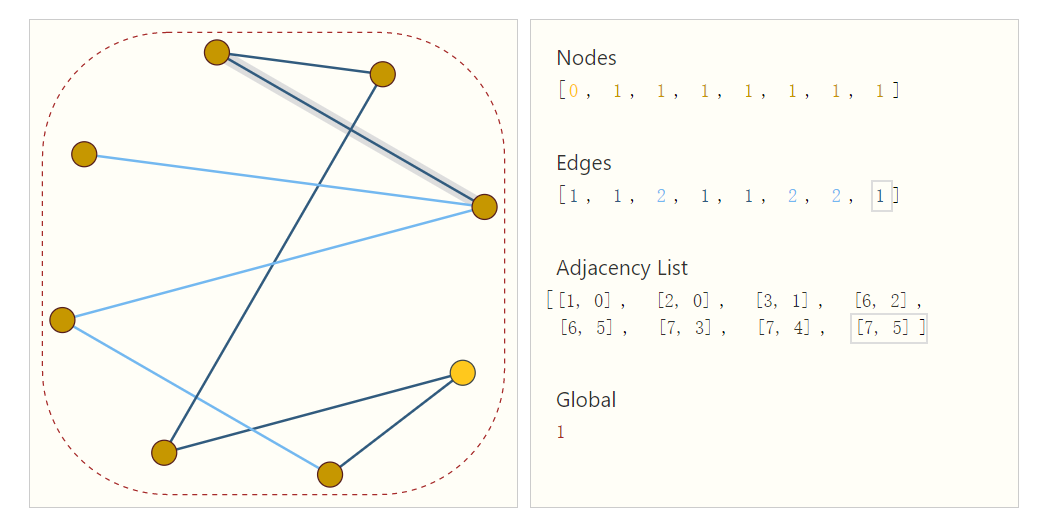
To get to the point, what is graph neural network
The definition may not be easy to understand. It only needs to have a concept. It is a neural network and has the following two characteristics.
1. The input is a graph, and the output is also a graph.
2. Make a series of transformations on the edge and vertex vectors, but the connection relationship will not change.
Take the simplest example. Input the edges, vertices and embedding vectors of the graph on the left into the three MLP s respectively, and update to obtain new edges, vertices and vectors of the graph, but the connection relationship of the graph does not change with their updating. This is the simplest GNN.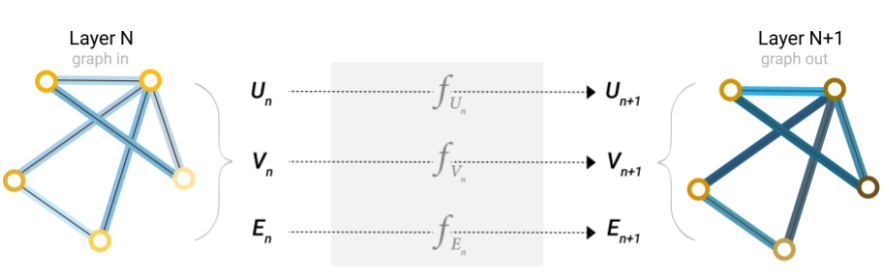
Now let's look at a specific problem. For example, I want to classify a point in the above figure. Assuming that the embedding vector of these points is known, the problem is simple. Just input a neural network directly for classification. This is no different from the traditional neural network.
What about the embedding vector of the false point? We can use the weighted sum of the vector of the edge connected to the point and the global vector to determine. (convergence layer) if the vector dimension of the edge is inconsistent with the dimension of the point, projection can be made. Similarly, there are only vertices and no edges.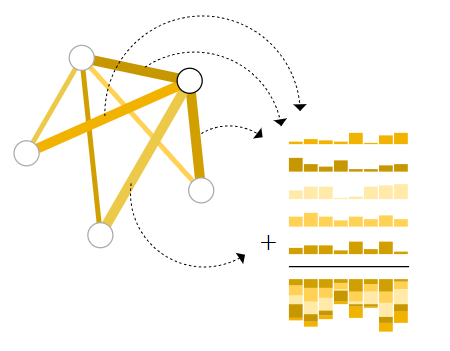
With the operation of aggregation, we can process the information of points and edges through neural network, and complete it through aggregation. But careful friends have found that this does not make full use of the information of a graph. How can we input all the information of vertices and edges of a graph.
Smart, you may have thought of it. Didn't you just talk about convergence? This is the way to make full use of the information of each vertex and edge. Before entering the neural network, the aggregation operation is carried out first. Each vertex and edge is updated several times with adjacent vertices and edges, and the new vertices and edges are input into the neural network. Yes, the specific process is shown in the figure. This process is also called information transmission.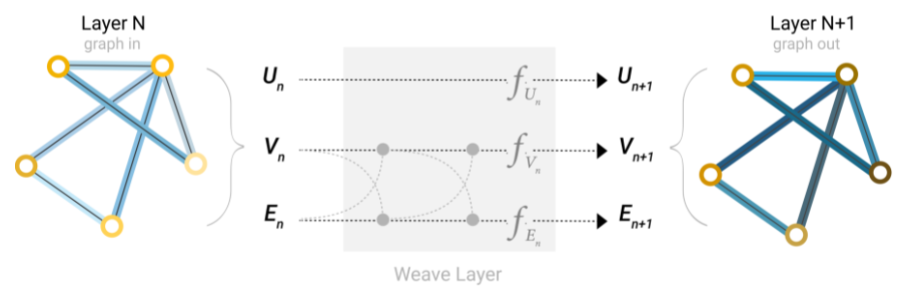
At this time, there is another problem, that is, when the picture is large, it takes a long time to transmit the information of distant points. Because of this, a global vector U is proposed to represent the average attribute of the whole graph.
So far, the basic principle of graph neural network is introduced clearly.
GCN is actually about designing a K-layer convergence network in the process of convergence. Each convergence takes N steps outward, and the field of view of each point is K*N. In fact, it is equivalent to taking out the adjacency matrix for multiplication.
It can be seen that the flexibility of graph neural network is very high, and basically all data can be represented as graphs. But it also brings its problems. It is very difficult to optimize this sparse architecture, and the graph is still a dynamic architecture.
3, Actual combat drill
Get the hand frame with mediapipe, and then use InterHand to accurately identify the joint points of the hand
 https://github.com/facebookresearch/InterHand2.6M/releases/tag/v1.0
https://github.com/facebookresearch/InterHand2.6M/releases/tag/v1.0# For more questions, please contact us by private letter. thujiang000
# Enter a hand picture and return to 3D coordinates
class HandPose:
def __init__(self):
cfg.set_args('0')
cudnn.benchmark = True
# joint set information is in annotations/skeleton.txt
self.joint_num = 21 # single hand
self.joint_type = {'right': np.arange(0,self.joint_num), 'left': np.arange(self.joint_num,self.joint_num*2)}
# snapshot load
model_path = './snapshot_19.pth.tar'
assert osp.exists(model_path), 'Cannot find self.hand_pose_model at ' + model_path
print('Load checkpoint from {}'.format(model_path))
self.hand_pose_model = get_model('test', self.joint_num)
self.hand_pose_model = DataParallel(self.hand_pose_model).cuda()
ckpt = torch.load(model_path)
self.hand_pose_model.load_state_dict(ckpt['network'], strict=False)
self.hand_pose_model.eval()
# prepare input image
self.transform = transforms.ToTensor()
def get3Dpoint(self,x_t_l, y_t_l, cam_w, cam_h,original_img):
bbox = [x_t_l, y_t_l, cam_w, cam_h] # xmin, ymin, width, height
original_img_height, original_img_width = original_img.shape[:2]
bbox = process_bbox(bbox, (original_img_height, original_img_width, original_img_height))
img, trans, inv_trans = generate_patch_image(original_img, bbox, False, 1.0, 0.0, cfg.input_img_shape)
img = self.transform(img.astype(np.float32))/255
img = img.cuda()[None,:,:,:]
# forward
inputs = {'img': img}
targets = {}
meta_info = {}
with torch.no_grad():
out = self.hand_pose_model(inputs, targets, meta_info, 'test')
img = img[0].cpu().numpy().transpose(1,2,0) # cfg.input_img_shape[1], cfg.input_img_shape[0], 3
joint_coord = out['joint_coord'][0].cpu().numpy() # x,y pixel, z root-relative discretized depth
rel_root_depth = out['rel_root_depth'][0].cpu().numpy() # discretized depth
hand_type = out['hand_type'][0].cpu().numpy() # handedness probability
# restore joint coord to original image space and continuous depth space
joint_coord[:,0] = joint_coord[:,0] / cfg.output_hm_shape[2] * cfg.input_img_shape[1]
joint_coord[:,1] = joint_coord[:,1] / cfg.output_hm_shape[1] * cfg.input_img_shape[0]
joint_coord[:,:2] = np.dot(inv_trans, np.concatenate((joint_coord[:,:2], np.ones_like(joint_coord[:,:1])),1).transpose(1,0)).transpose(1,0)
joint_coord[:,2] = (joint_coord[:,2]/cfg.output_hm_shape[0] * 2 - 1) * (cfg.bbox_3d_size/2)
# restore right hand-relative left hand depth to continuous depth space
rel_root_depth = (rel_root_depth/cfg.output_root_hm_shape * 2 - 1) * (cfg.bbox_3d_size_root/2)
# right hand root depth == 0, left hand root depth == rel_root_depth
joint_coord[self.joint_type['left'],2] += rel_root_depth
# 3D node information
return joint_coordAfter extracting the three-dimensional joint points, we can construct the map of the hand. Think about it. Our task is to classify different graphs. The direction and length of edges are the characteristics of graphs. Based on the characteristics of features, we can try to construct this graph with edges. Note that the fingers are undirected and should be handled.
Firstly, a two-layer graph convolution neural network is constructed
class GCN(nn.Module): def __init__(self, in_feats, h_feats, num_classes): super(GCN, self).__init__() self.conv1 = GraphConv(in_feats, h_feats) self.conv2 = GraphConv(h_feats, num_classes) def forward(self, g, in_feat): h = self.conv1(g, in_feat) h = F.relu(h) h = self.conv2(g, h) g.ndata['h'] = h return dgl.mean_nodes(g, 'h')
u. v is the starting point and ending point of the graph respectively.
Then, according to the relative coordinates of each point to the center coordinates of the palm, it is input into the original drawing.
# Structural drawings and features
u,v = torch.tensor([[0,0,0,0,0,4,3,2,8,7,6,12,11,10,16,15,14,20,19,18,0,21,21,21,21,21,25,24,23,29,28,27,33,32,31,37,36,35,41,40,39],
[4,8,12,16,20,3,2,1,7,6,5,11,10,9,15,14,13,19,18,17,21,25,29,33,37,41,24,23,22,28,27,26,32,31,30,36,35,34,40,39,38]])
g = dgl.graph((u,v))
# Undirected processing
bg = dgl.to_bidirected(g)
# Calculate relative coordinates
x_y_z_column = self.relativeMiddleCor(x_list, y_list,z_list)
# Add feature
bg.ndata['feat'] =torch.tensor( x_y_z_column ) # x. Y, Z coordinates
# test model
device = torch.device("cuda:0")
# device = torch.device("cpu")
bg = bg.to(device)
self.modelGCN = self.modelGCN.to(device)
pred = self.modelGCN(bg, bg.ndata['feat'].float())
pred_type =pred.argmax(1).item()Full project code address:
Note during operation:
1. When collecting training data, run demo Handrecognize. Py file getTrainningData(task_type = '6'). Parameter task_ The value of type is 0 ~ 6, and up to seven gestures can be recognized.
2. When running, assuming that five gestures are collected, the output layer of the corresponding hand part class should be changed to 5.
self.modelGCN = GCN(3, 16, 5)
self.modelGCN.load_state_dict(torch.load('./saveModel/handsModel.pth'))
self.modelGCN.eval()
self.handPose = HandPose()
self.mp_hands = mp.solutions.hands3. If gpu acceleration is required, dgl needs to install gpu version. nvcc --version check your cuda version and go to Deep Graph Library https://www.dgl.ai/pages/start.html Find the corresponding installation instructions.
https://www.dgl.ai/pages/start.html Find the corresponding installation instructions.
If you encounter difficulties in operation, please leave a message.