One of the data structures commonly used in HashMap work. The underlying data structure is composed of array + linked list + red black tree, as shown in the figure below
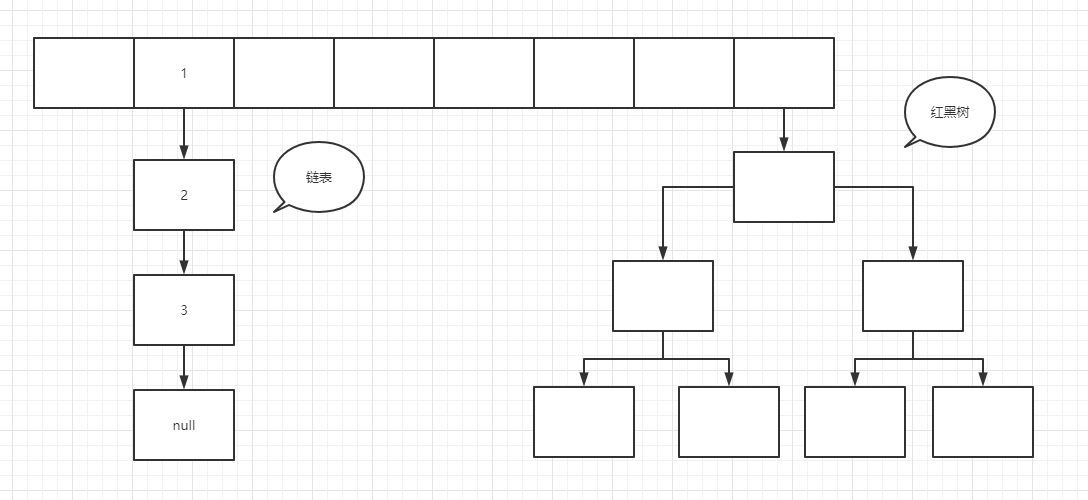
After knowing the data structure of HashMap, you will have some doubts. Why are there some linked lists, some red and black trees, and some have only one node? How do the linked lists and red and black trees convert? Let's clear the clouds from 0 to 1!
First, let's take a look at some properties of HashMap
/**
* The default table size is the default initialization array length
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* table Maximum length
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* Default load factor size
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Tree threshold
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* Tree degradation is called the threshold of linked list
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* Another parameter of treelization. Treelization is allowed only when the number of all elements in the hash table exceeds 64
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* HashMap Array in
*/
transient Node<K,V>[] table;
/**
* Number of elements in the current hash table
*/
transient int size;
//For the internal class in HashMap, pay attention to its four properties
static class Node<K,V> implements Map.Entry<K,V> {
//hash value
final int hash;
//Incoming key
final K key;
//Value passed in
V value;
//Because it is a linked list, the information pointing to the next Node is also a Node node
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
//There are other ways not to show
}
Then look at the initialization method of HashMap
/**
* Pass in an initial length and load factor
*/
public HashMap(int initialCapacity, float loadFactor) {
//In fact, I did some verification
//capacity must be greater than 0, and the maximum value is MAX_CAP
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//loadFactor must be greater than 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* initialCapacity :Pass in an initial length. The default loadFactor is 0.75
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Nothing is transmitted. The default length is 16 and the load factor is 0.75
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
/**
* Pass in a Map and re assign the Map to the new Map
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
It is not difficult to see that HashMap has four constructors, the most important of which is the first constructor, most of which are parameter verification, but pay attention to the method of tableSizeFor(initialCapacity)
//Function: returns a number greater than or equal to the current value cap, and this number must be to the power of 2
static final int tableSizeFor(int cap) {
int n = cap;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
This method is very important. What we get is the power of the current incoming initial size up to 2. For example, if I pass in a 14, then 16 will be returned through this method and 32 will be returned through 31. Why do we have to take the power of 2 here? It plays a great role. We will explain in detail when we find the subscript array to which the data is stored.
Now the construction work has been completed, but the HashMap is still an empty shell. The table in it is not initialized. The first initialization is the first put. See the code below
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//tab: hash table referencing the current hashMap
//p: Represents the element of the current hash table
//n: Represents the length of the hash table array
//i: Indicates the route addressing result
Node<K,V>[] tab; Node<K,V> p; int n, i;
//Delay initialization logic. When putVal is called for the first time, it will initialize the hash table that consumes the most memory in the hashMap object
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//The simplest case: the bucket bit found by addressing is just null. At this time, just throw in the current K-V = > node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//e: If it is not null, a key element consistent with the key value to be inserted is found
//k: Represents a temporary key
Node<K,V> e; K k;
//Indicates that the element in the bucket is exactly the same as the key of the element you are currently inserting, indicating that subsequent replacement operations are required
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//The red black tree is not explained here. The insertion node of the red black tree is essentially similar to the linked list, but its flipping is very complex
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//In the case of the linked list, and the header element of the linked list is inconsistent with the key we want to insert.
for (int binCount = 0; ; ++binCount) {
//If the condition holds, it means that the iteration has reached the last element, and a node consistent with the key you want to insert has not been found
//Note that it needs to be added to the end of the current linked list
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//If the condition is true, it indicates that the length of the current linked list has reached the treelization standard and needs to be treelized
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//Tree operation
treeifyBin(tab, hash);
break;
}
//If the condition holds, it means that the node element with the same key is found and needs to be replaced
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//e is not equal to null. If the condition holds, it indicates that a data completely consistent with the element key you inserted has been found and needs to be replaced
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//The number of times that the element of mod is not modified in the Hash list structure, and the count of value represents the number of times that the element of mod is not modified
++modCount;
//Insert a new element and the size will increase automatically. If the value after the increase is greater than the capacity expansion threshold, the capacity expansion will be triggered.
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
When put ting the first time, the table must be null, then you will enter the resize() method. As we all know, this is a capacity expansion method, but in fact, hashmap1 8. Another function of the resizing method is to initialize the table. See the following code
final Node<K,V>[] resize() {
//oldTab: refers to the hash table before capacity expansion
Node<K,V>[] oldTab = table;
//oldCap: indicates the length of the table array before capacity expansion
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//oldThr: indicates the capacity expansion threshold before capacity expansion and the threshold triggering this capacity expansion
int oldThr = threshold;
//newCap: size of table array after capacity expansion
//newThr: after capacity expansion, the condition for capacity expansion will be triggered again next time
int newCap, newThr = 0;
//If the condition holds, the hash table in hashMap has been initialized. This is a normal expansion
if (oldCap > 0) {
//After the size of the table array before capacity expansion has reached the maximum threshold, the capacity will not be expanded, and the capacity expansion condition is set to the maximum value of int.
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//oldCap is shifted by one bit to the left to double the value and assigned to newCap. newCap is less than the maximum limit of the array and the threshold before capacity expansion is > = 16
//In this case, the threshold of the next expansion is equal to doubling the current threshold
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//oldCap == 0, indicating that the hash table in hashMap is null, that is, Map map=new HashMap(); For the constructed map, the default length is 16 and the expansion threshold is 12
//1.new HashMap(initCap, loadFactor);
//2.new HashMap(initCap);
//3.new HashMap(map); And the map has data
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//oldCap == 0,oldThr == 0
//new HashMap();
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;//16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//12
}
//When the newThr is zero, calculate a newThr through newCap and loadFactor
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//Create a longer and larger array
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//Note: before this hashMap expansion, the table is not null and will not be entered during initialization. Because the old array is null, the method of entering and changing must be capacity expansion
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
//Current node
Node<K,V> e;
//It indicates that there is data in the current bucket, but it is unknown whether the data is a single data, a linked list or a red black tree
if ((e = oldTab[j]) != null) {
//It is convenient for JVM to reclaim memory during GC
oldTab[j] = null;
//The first case: there is only one element in the current bucket and no collision has occurred. In this case, directly calculate the position of the current element in the new array, and then
//Just throw it in
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//The second case: the current node has been treelized. We won't talk about it in this issue, but in the next issue, we will talk about red black tree
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//The third case: the bucket position has formed a linked list
//Low linked list: the subscript position of the array stored after capacity expansion, which is consistent with the subscript position of the current array.
Node<K,V> loHead = null, loTail = null;
//High order linked list: the following table position of the array stored after capacity expansion is the subscript position of the current array + the length of the array before capacity expansion
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//hash-> .... 1 1111
//hash-> .... 0 1111
// 0b 10000
/** Hash is used here & the length of the old array is not - 1, so as to distinguish the high and low order. For ex amp le, binary 10000 of 16 uses this number & upper hash
* No matter what the value of hahs is, the result is only 1 and 0. If you subtract 1, the binary of 16 is 1111. You can't distinguish between high and low */
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
/** This is mainly to form a linked list structure. It is worth noting that the 1.7 and 1.8 versions of hashmap often use temporary variables during capacity expansion
* To host node nodes, so loTail Next = e should be the next of the node object referred to by the temporary variable pointer loTail
* */
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
/** It is also part of the split linked list */
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
It can be seen here that if nothing is transmitted when constructing HashMap map=new HashMap(), the oldThr must not be assigned. By default, the initial capacity of HashMap is 16 and the expansion threshold is 12.
If the initial capacity HashMap = new HashMap (16) is passed in, the threshold expansion threshold will be calculated according to the loadFactor loading factor. Finally, a new Node array will be created and assigned to the old array, and Node < K, V > [] newtab = (Node < K, V > []) new Node [newcap] will be returned. Because the old array is empty for the first time, it will not enter the data transfer method of capacity expansion. OK, Now that the initialization is completed and the table is returned, continue with the put method. Pay attention to the put code fragment above. Before put, if ((P = tab [i = (n - 1) & hash]) = = null) note that n is assigned as the length of the array n = (tab = resize()) Length previously mentioned why the length of HashMap must be the power of 2. Assuming that the length n is 16 and converted to binary, that is 00010000, then the binary bit 0000 11111 of (n-1) assumes that the hash of our key is 0101 0101
(n - 1) & hash==0000 1111&0101 0101 Ignore hash How&This value must be<=0000 1111(that is n-1)
n-1 is just the maximum value of the array length, so the subscript put in will never exceed the array length, and the underlying calculation of the computer is through binary calculation, so & the operation efficiency is faster tab [i = (n - 1) & hash]) this operation is called addressing, that is to find the corresponding array subscript, and then start storing data to table. Put is divided into four cases:
1.It is obtained that the current subscript node has not stored data, that is to say table[i]==null,In this case, you can put the data directly 2.It is obtained that the current subscript node has data (only the current one), if hash,key(Value and address) are equal, overwriting the old value for so long 3.If the current subscript node has data (forming a linked list), you need to traverse the linked list and insert it to the end. After inserting, you need to judge whether the current linked list reaches the treelization threshold (treelization threshold is 8). When the linked list node reaches the treelization threshold, The linked list will be turned into a red black tree (you can refer to other blogs for turning into a red black tree, mainly because the turning of the red black tree is complex, but the idea of inserting data remains the same) 4.Get the data of the current subscript node(It's already a red and black tree),Then you need to traverse the red black tree, and then insert it (the red black tree refers to other blogs. If necessary, I will consider a red black tree blog)
Finally, it will judge whether the size of the current HashMap exceeds the threshold expansion threshold. If it exceeds the threshold, the resize() method will be triggered. If it does not exceed that long, the element will be returned and put succeeds.
OK, let's see the resize() code block. Let's see how the expansion method transfers elements:
Before entering the capacity expansion method, we said that either initialization or capacity expansion of HashMap is required. Here we assume that capacity expansion is required
First of all, the old array oldTab must not be empty, so the oldCap, that is, the array length must be > 0, and then enter the if (oldCap > 0) {} code block. First, judge whether the length of the old array exceeds maximum_ The maximum length of capability exceeds that directly assigned to integer MAX_ The maximum value of value is 2147483647. Otherwise, double the length of the array, recalculate the expansion threshold and assign it to the new threshold. Finally, the data transfer, hashmap1 8. Data transfer is divided into high-order and low-order. The linked list and red black tree will be split to achieve the effect of data dispersion. Make full use of the space of HashMap, reduce the length of linked list and red black tree, and speed up the query efficiency. The following is the effect diagram before and after capacity expansion
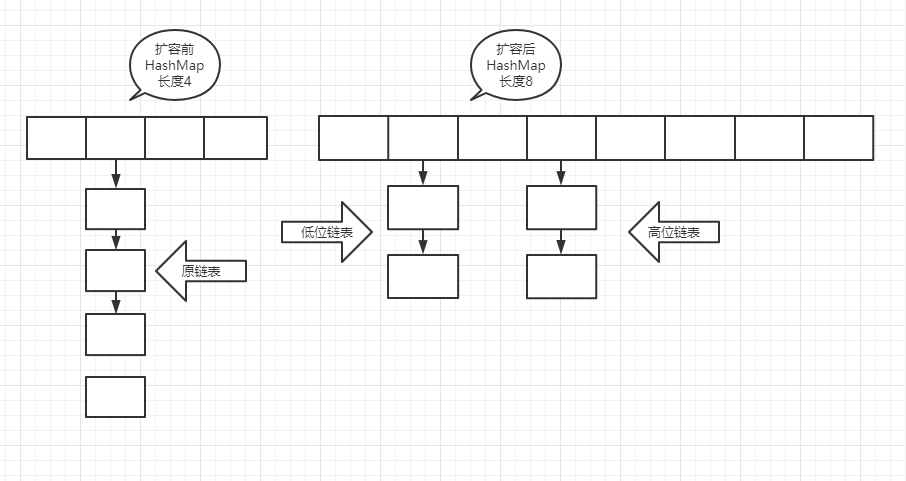
In fact, the idea of data transfer is not difficult. Combined with the above resize() method code block, it can be seen that traversing the old array is also divided into four cases, which is similar to put. It should be noted that in either case, the subscript position of the elements stored in the new array will be recalculated
1.Traverse to the current node null If the current node has no elements, skip 2.Traversing to the current node, there is only one element, that is, it does not occur hash If there is a collision, the subscript of the current element in the new array is recalculated newTab[e.hash & (newCap - 1)] = e 3.If the current node is a linked list, it will traverse the linked list, as mentioned above HashMap It is divided into high-order and low-order. Take a closer look at the code block above me. Here I take a screenshot. The high-order and low-order are passed(e.hash & oldCap) == 0 To judge, eh, what's the difference between here and before put The index of the array is similar to that of the array tab[i = (n - 1) & hash],Yes, that's right. See the figure below for the specific explanation

4.If the current node is traversed to be a red black tree, it is also traversed to split the red black tree, And after the split red black tree reaches the degradation threshold of 6, it will be converted from red black tree to linked list (the reason why we don't talk about red black tree here is that the turnover of red black tree is not easy to express. In the actual interview, we can't tell the interviewer how to turn it. We just need to know his executive thinking. If we have to, we can go to the red black tree blog)
At this point, the data transfer is completed, hashmap1 8 uses the tail interpolation method, which will not reverse the order of elements after capacity expansion, nor produce a ring linked list, so it will not lead to dead lock during get, but this does not mean jdk1 The HashMap thread of 8 is safe. It also has concurrent modification exception concurrent modificationexception
In fact, HashMap is almost the same here. Its get and remove methods are very simple. I won't repeat them here. Let's briefly talk about the idea of get! The old rule is to look at the following code first
final Node<K,V> getNode(int hash, Object key) {
//tab: hash table referencing the current hashMap
//first: header element in bucket
//e: Temporary node element
//n: table array length
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//The first case: the located bucket element is the data we want to get
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//It indicates that there is more than one element in the current bucket, which may be a linked list or a red black tree
if ((e = first.next) != null) {
//The second case: the bucket is upgraded to a red black tree
if (first instanceof TreeNode)//In the next issue
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//The third case: the bucket position forms a linked list
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Here are still four cases. As before put, the subscript of the element is obtained through hash
1.The obtained element is the current element and is returned directly 2.The obtained element is a linked list. Traverse the linked list for comparison key,Until the comparison is successful, it will return; if not, it will return null 3.Get the red black tree. Traverse the red black tree and compare key,Until the comparison is successful, it will return; if not, it will return null 4.Nothing returned null
remove is the same. Please check it yourself
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
//tab: references the hash table in the current hashMap
//p: Current node element
//n: Indicates the length of the hash table array
//index: indicates the addressing result
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
//It indicates that there is data in the bucket of the route, which needs to be searched and deleted
//node: found results
//e: Next element of the current Node
Node<K,V> node = null, e; K k; V v;
//The first case: the element in the current bucket is the element you want to delete
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
//Note: the current bucket is either a linked list or a red black tree
if (p instanceof TreeNode)//Judge whether the current bucket is upgraded to red black tree
//The second case
//The red black tree search operation will be discussed in the next issue
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//The third case
//Linked list
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//If the node is not empty, the data to be deleted is found according to the key
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//The first case: node is a tree node, indicating that the tree node needs to be removed
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//The second case: if the bucket element is the search result, the next element of the element will be placed in the bucket
else if (node == p)
tab[index] = node.next;
else
//The third case: set the next element of the current element p as the next element to be deleted.
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
At this point, the general idea and underlying structure of HashMap are almost finished. Let's talk about hashmap1 7 formation of ring linked list
I've been puzzled here before, but it's good to figure out one thing. I can definitely say here is the most detailed ring linked list formation process in the whole network. The old rule is to look at the following code first (the following is the data transfer code of jdk1.7!!!)
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//Traverse the old array
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {//Ignore this if code block and leave it alone
e.hash = null == e.key ? 0 : hash(e.key);
}
//Evaluate the subscript in the new array
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
It's very similar to the temporary variable of K 8 more, many people here will misunderstand, such as e = next; In this operation, the pointer of next actually points to e.next, so e=e.next is equivalent to tracing the assignment operation of temporary variables to a specific node rather than temporary variables. In the case of forming a ring linked list, suppose that two threads enter the transfer method at the same time, and thread b executes to entry < K, V > next = e.next; A thread grabs the CPU for execution. See the figure below
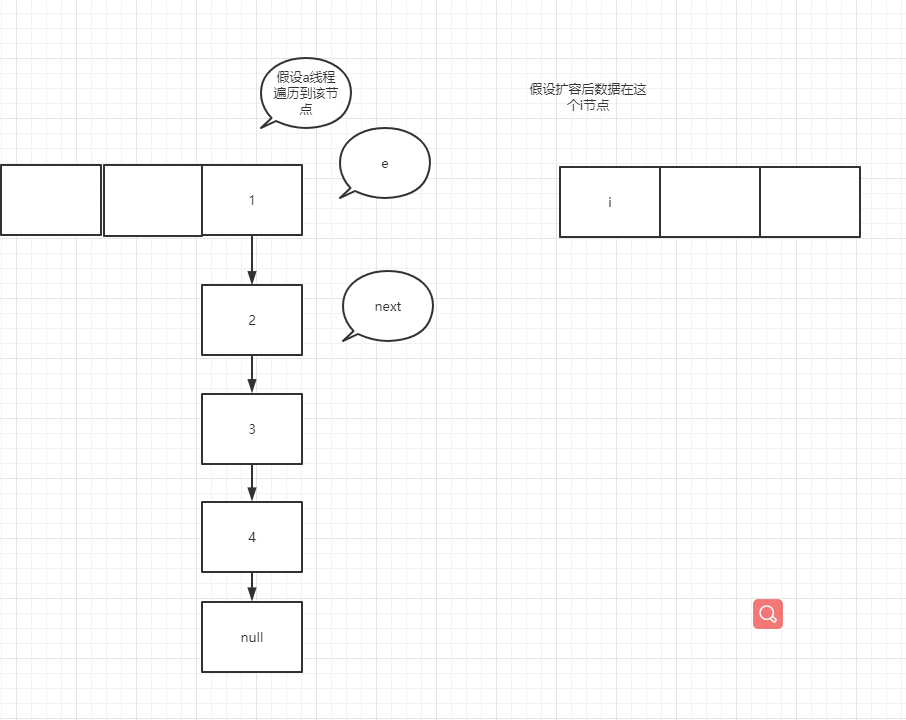
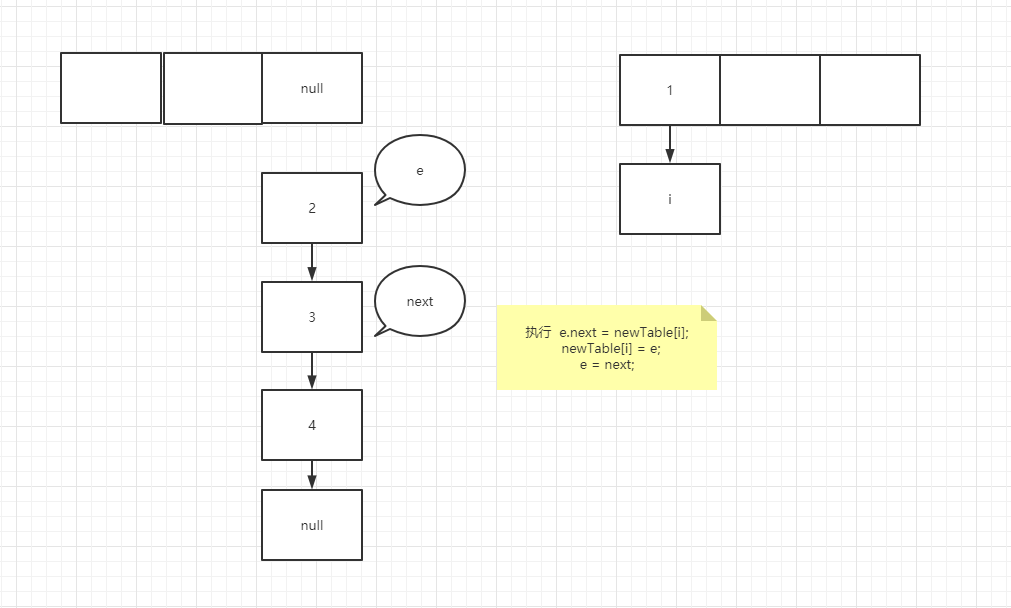
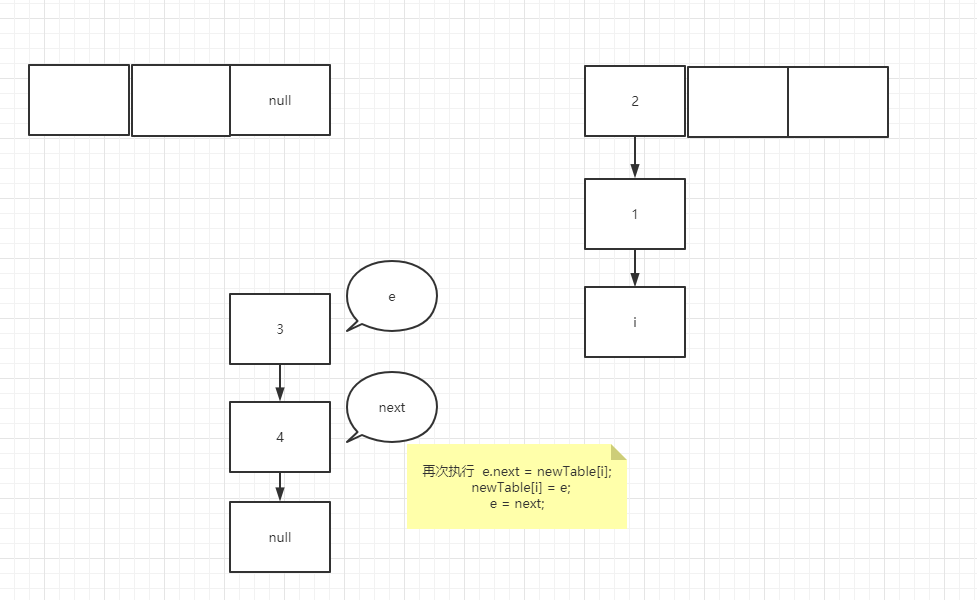
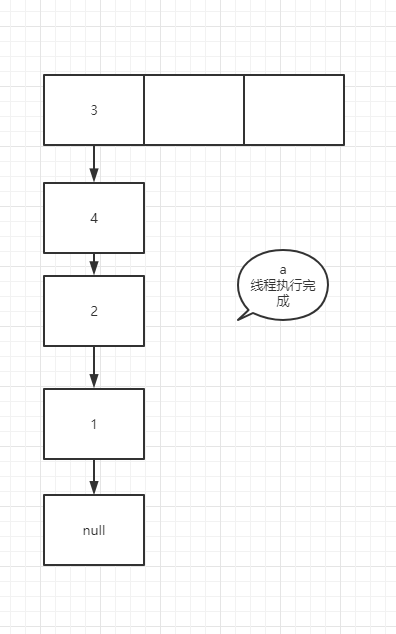
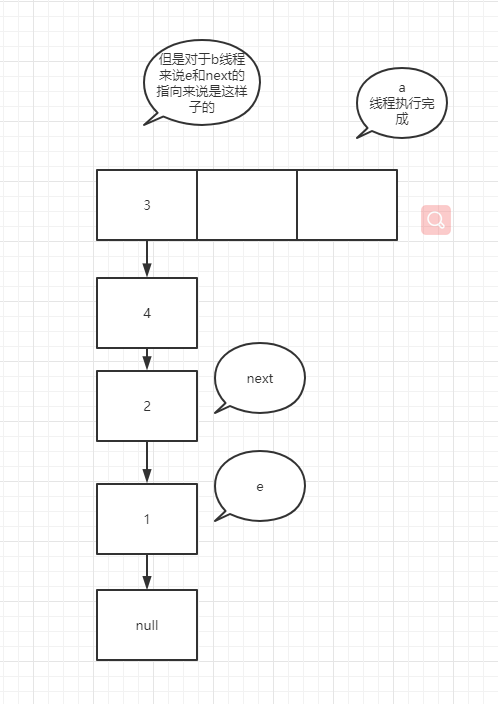
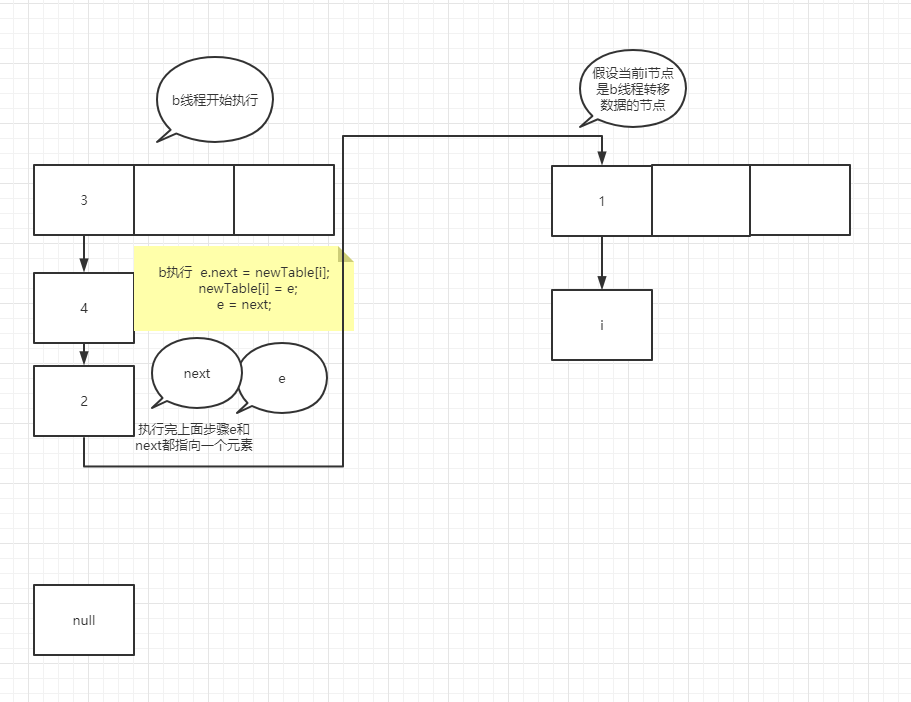
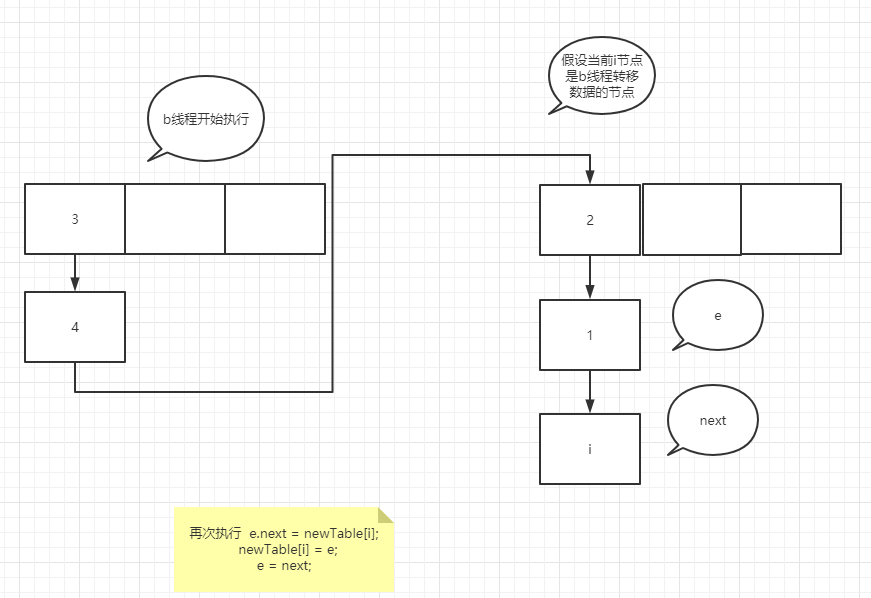
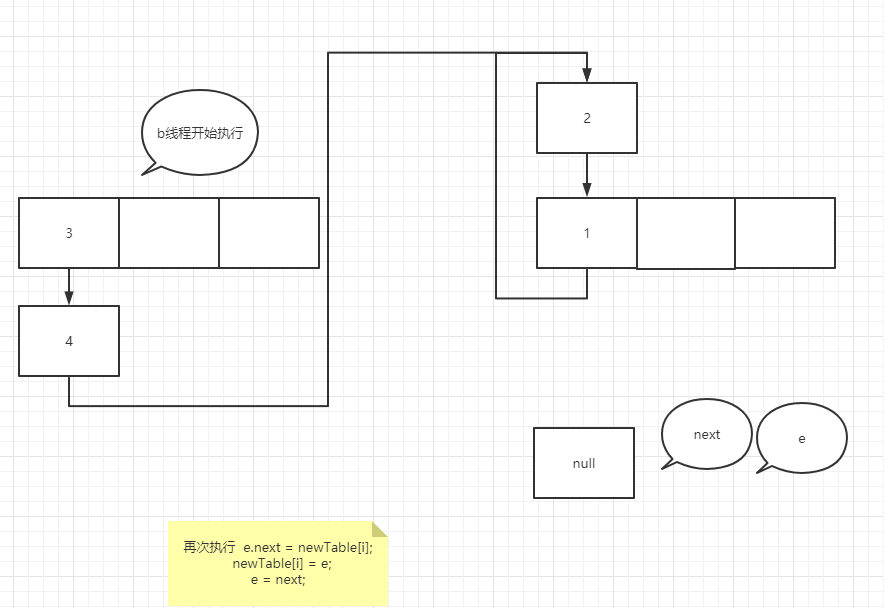
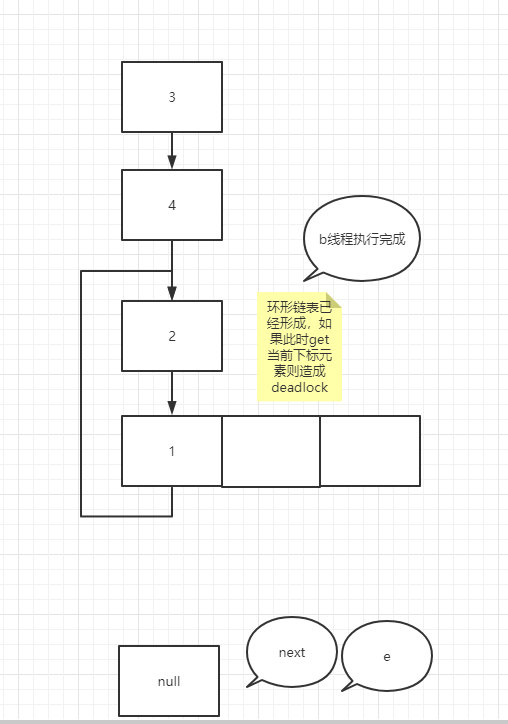
You can try it yourself. It's not difficult to understand that if the node assignment operation is a temporary variable such as next, the assignment is the real node pointed to by the pointer rather than the next node
Finally, complete HashMap Please add a group to obtain the notes of the Chinese version: 552583683