introduction
- In web development, function is the cornerstone. In addition to function, peacekeeping and protection are the top priority. Because during the operation of the website, the business may be abnormal due to the sudden traffic, and may also be maliciously attacked by others
- Therefore, our interface needs to limit the traffic. Commonly known as QPS, it is also a description of traffic
- For current limiting, most of them should be token bucket algorithm, because it can ensure more throughput. In addition to token bucket algorithm, there are its predecessor leaky bucket algorithm and simple counting algorithm
- Let's take a look at these four algorithms
Of course, as a reading benefit, Xiaobian carefully prepared a set of Redis related learning notes (including interview, brain map, handwritten pdf, etc.) as a benefit, which can be unconditionally sent to Java programmers who read this article. They can get what they need
The most complete Redis learning notes + real interview questions
Fixed time window algorithm
- Fixed time window algorithm can also be called simple counting algorithm. Many on the Internet separate counting algorithms. However, the author believes that the counting algorithm is an idea, and the fixed time window algorithm is one of his implementations
- Including the following sliding time window algorithm is also an implementation of the counting algorithm. Because if counting is not bound with time, it will lose the essence of current limiting. It becomes a refusal
advantage
- In case of flow overflow within a fixed time, the current limit can be made immediately. Each time window does not affect each other
- Ensure the stability of the system within the time unit. Upper limit of system throughput in guaranteed time unit
shortcoming
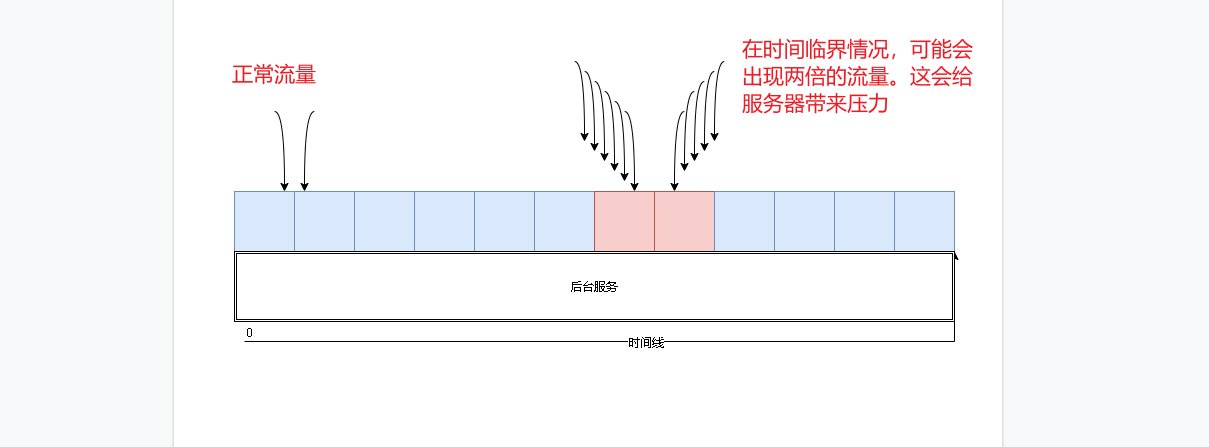
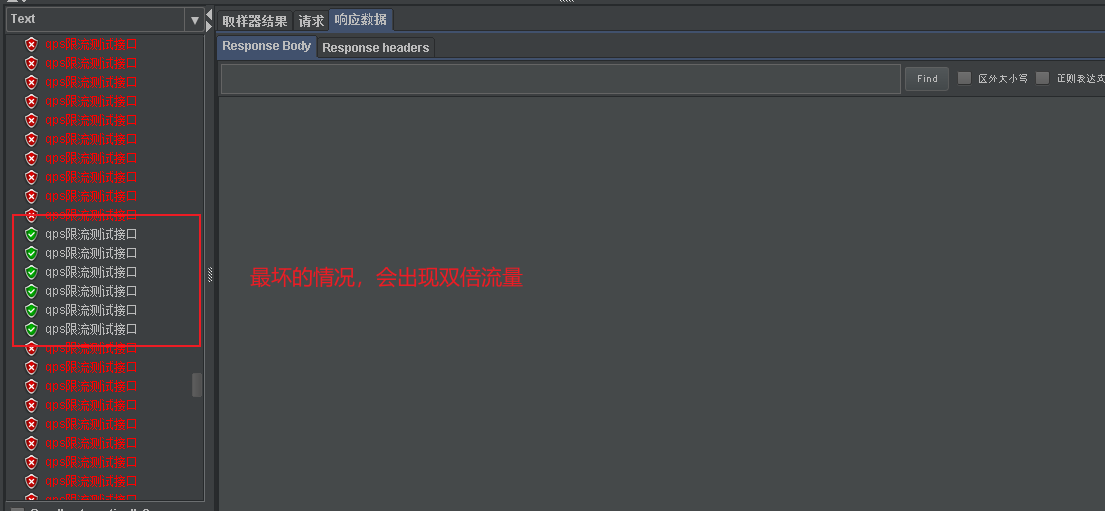
- As shown in the figure, his biggest problem is the critical state. In the critical state, the worst case will be subject to twice the flow request
- In addition to the critical case, there is another case where the request threshold is consumed quickly in the early stage within a unit time window. Then the rest of the time will not be requested. In this way, the system will not be available for a period of time due to instantaneous traffic. This is unacceptable in highly available systems on the Internet.
realization
- Well, we have understood the principle, advantages and disadvantages. Now let's start to realize it
- First of all, when we implement this counting, redis is a very good choice. We implement redis here
controller
@RequestMapping(value = "/start",method = RequestMethod.GET)
public Map<String,Object> start(@RequestParam Map<String, Object> paramMap) {
return testService.startQps(paramMap);
}
service
@Override
public Map<String, Object> startQps(Map<String, Object> paramMap) {
//Go online according to the qps transmitted by the front end
Integer times = 100;
if (paramMap.containsKey("times")) {
times = Integer.valueOf(paramMap.get("times").toString());
}
String redisKey = "redisQps";
RedisAtomicInteger redisAtomicInteger = new RedisAtomicInteger(redisKey, redisTemplate.getConnectionFactory());
int no = redisAtomicInteger.getAndIncrement();
//Set fixed time window length 1S
if (no == 0) {
redisAtomicInteger.expire(1, TimeUnit.SECONDS);
}
//Judge whether it exceeds the limit. time=2 means qps=3
if (no > times) {
throw new RuntimeException("qps refuse request");
}
//Return success notification
Map<String, Object> map = new HashMap<>();
map.put("success", "success");
return map;
}
Result test
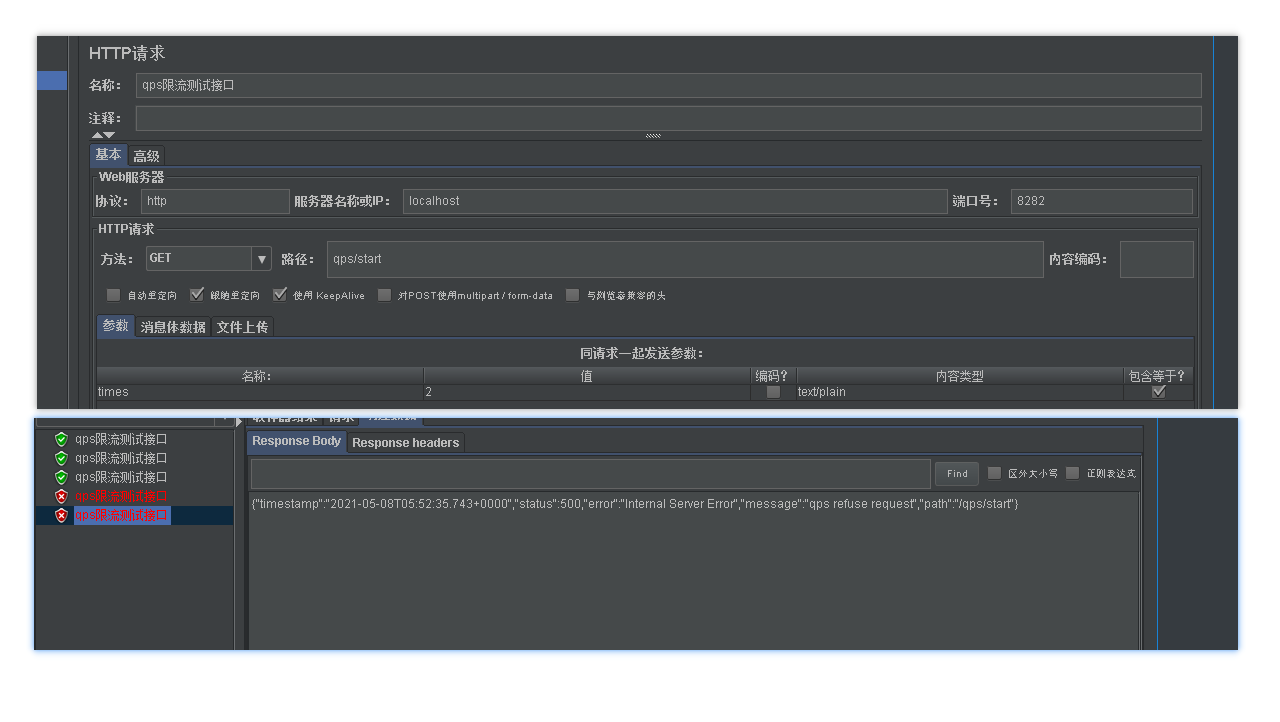
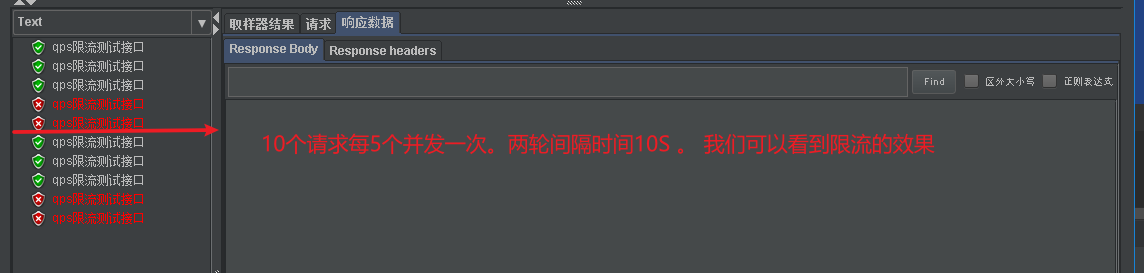
- When we set qps=3, we can see that after five concurrent entries, the first three access normally, and the last two fail. After a while, we are accessing concurrently, and the first three can be accessed normally. Indicates the next time window
Sliding time window algorithm
- Aiming at the disadvantage of fixed time window - double flow at the critical value. Our sliding time window is generated.
- In fact, it is easy to understand that for a fixed time window, the time window statistics are changed from the original fixed interval to a more detailed unit.
- In our fixed time window demonstration above, the time unit we set is 1S. For 1S, we split 1S into time stamps.
- Fixed time window means that the statistical unit moves backward with the passage of time. Sliding time window is what we think. Imagine a time unit to fix time according to the idea of relativity, and our abstract time unit moves by itself. The abstract time unit is smaller than the actual time unit.
- Readers can understand it by looking at the following dynamic diagram.

advantage
- In essence, it is the improvement of the fixed time window algorithm. So the disadvantage of fixed time window is its advantage.
- The interior abstracts a sliding time window to reduce the time. The problem of boundary is even smaller. Customer perception is weaker.
shortcoming
- Whether fixed time window algorithm or sliding time window algorithm, they are optimized based on counter algorithm, but their current limiting strategy is too rough.
- Why is it rude? They are allowed to release normally without flow restriction. Once the current limit is reached, it will be rejected directly. In this way, we will lose part of the request. This is not very friendly for a product
realization
-
Sliding the time window is to refine the time. We implemented it through redis#setnx. Here we can't unify the records through him. We should add smaller time units to store them in a collection summary. Then, the current limit is calculated according to the total amount of the set. The Zset data structure of redis meets our needs.
-
Why choose zset? Because there is a weight in the zset of redis besides the value. It will be sorted according to this weight. If we take our time unit and timestamp as our weight, we only need to follow a timestamp range when obtaining statistics.
-
Because the elements in zset are unique, our values are generated by id generators such as uuid or snowflake algorithm
controller
@RequestMapping(value = "/startList",method = RequestMethod.GET)
public Map<String,Object> startList(@RequestParam Map<String, Object> paramMap) {
return testService.startList(paramMap);
}
service
String redisKey = "qpsZset";
Integer times = 100;
if (paramMap.containsKey("times")) {
times = Integer.valueOf(paramMap.get("times").toString());
}
long currentTimeMillis = System.currentTimeMillis();
long interMills = inter * 1000L;
Long count = redisTemplate.opsForZSet().count(redisKey, currentTimeMillis - interMills, currentTimeMillis);
if (count > times) {
throw new RuntimeException("qps refuse request");
}
redisTemplate.opsForZSet().add(redisKey, UUID.randomUUID().toString(), currentTimeMillis);
Map<String, Object> map = new HashMap<>();
map.put("success", "success");
return map;
Result test
- Same concurrency as fixed time window. Why is there a critical situation above. Because in the code, the time unit interval is larger than the fixed time interval. The above shows that the fixed time window time unit is the worst case of 1S. The sliding interval should be shorter. And when I set it to 10S, there was no bad situation
- This shows the advantages of sliding over fixed. If we adjust it smaller, there should be no critical problems, but in the final analysis, it can't avoid the critical problems
Leaky bucket algorithm
- Although sliding time window can avoid the critical value problem to a great extent, it can not be avoided all the time
- In addition, the time algorithm has a fatal problem. It cannot face a sudden large amount of traffic, because it directly rejects other additional traffic after reaching the current limit
- To solve this problem, we continue to optimize our current limiting algorithm. Leaky bucket algorithm came into being
advantage
- More flexible in the face of current limit, no more rude rejection.
- Increased the acceptability of the interface
- Ensure the stability of obscene service reception. Uniform distribution
shortcoming
- I think there are no shortcomings. If you have to pick a bone in an egg, I can only say that the capacity of the leaky bucket is a short board
realization
controller
@RequestMapping(value = "/startLoutong",method = RequestMethod.GET)
public Map<String,Object> startLoutong(@RequestParam Map<String, Object> paramMap) {
return testService.startLoutong(paramMap);
}
service
- In the service, we simulate the bucket effect through the list function of redis. The code here is laboratory. In real use, we also need to consider the problem of concurrency
@Override
public Map<String, Object> startLoutong(Map<String, Object> paramMap) {
String redisKey = "qpsList";
Integer times = 100;
if (paramMap.containsKey("times")) {
times = Integer.valueOf(paramMap.get("times").toString());
}
Long size = redisTemplate.opsForList().size(redisKey);
if (size >= times) {
throw new RuntimeException("qps refuse request");
}
Long aLong = redisTemplate.opsForList().rightPush(redisKey, paramMap);
if (aLong > times) {
//To prevent concurrent scenarios. You should also verify after adding here. Even so, this code has problems in high concurrency. Here's how it works
redisTemplate.opsForList().trim(redisKey, 0, times-1);
throw new RuntimeException("qps refuse request");
}
Map<String, Object> map = new HashMap<>();
map.put("success", "success");
return map;
}
Downstream consumption
@Component
public class SchedulerTask {
@Autowired
RedisTemplate redisTemplate;
private String redisKey="qpsList";
@Scheduled(cron="*/1 * * * * ?")
private void process(){
//Two for one-time consumption
System.out.println("Consuming......");
redisTemplate.opsForList().trim(redisKey, 2, -1);
}
}
test
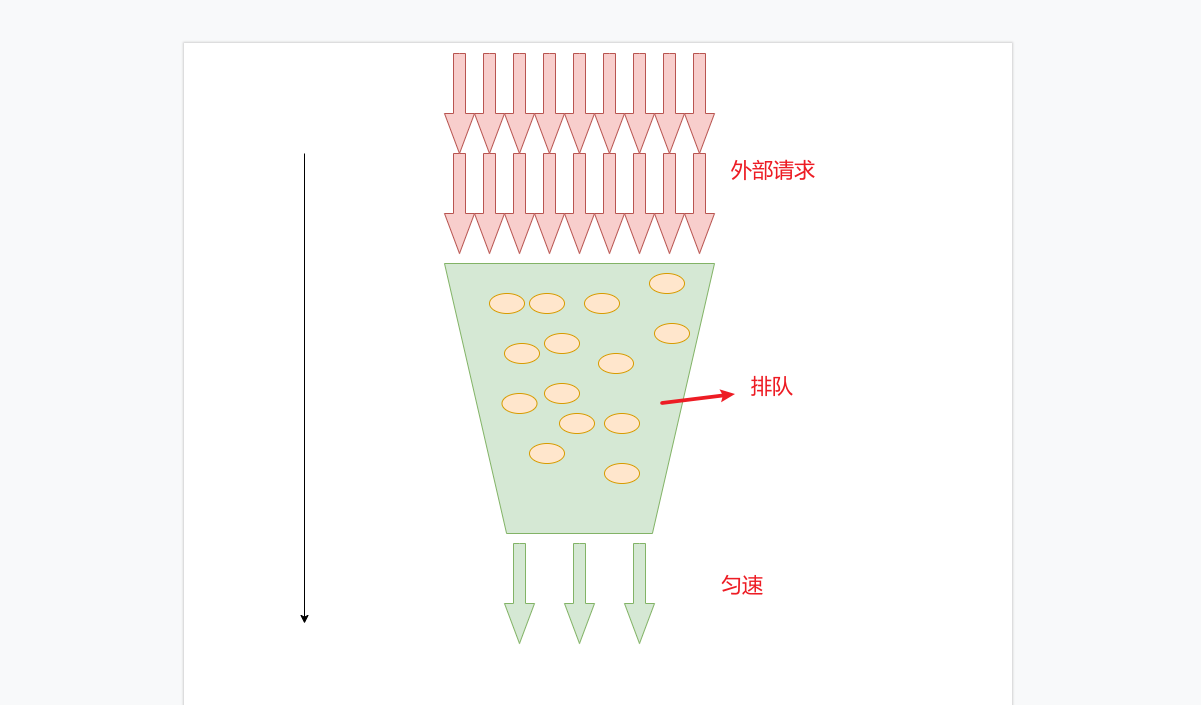
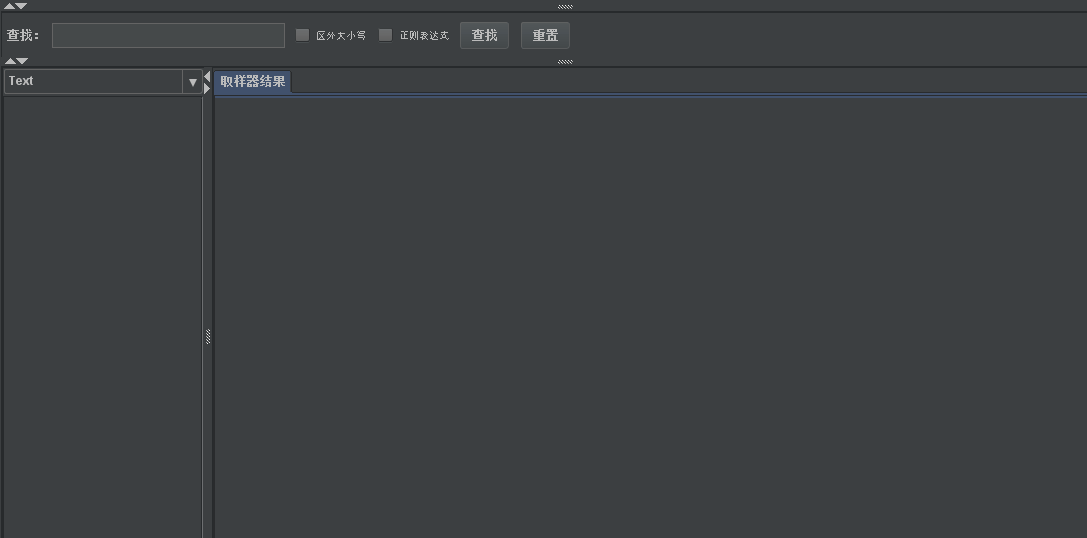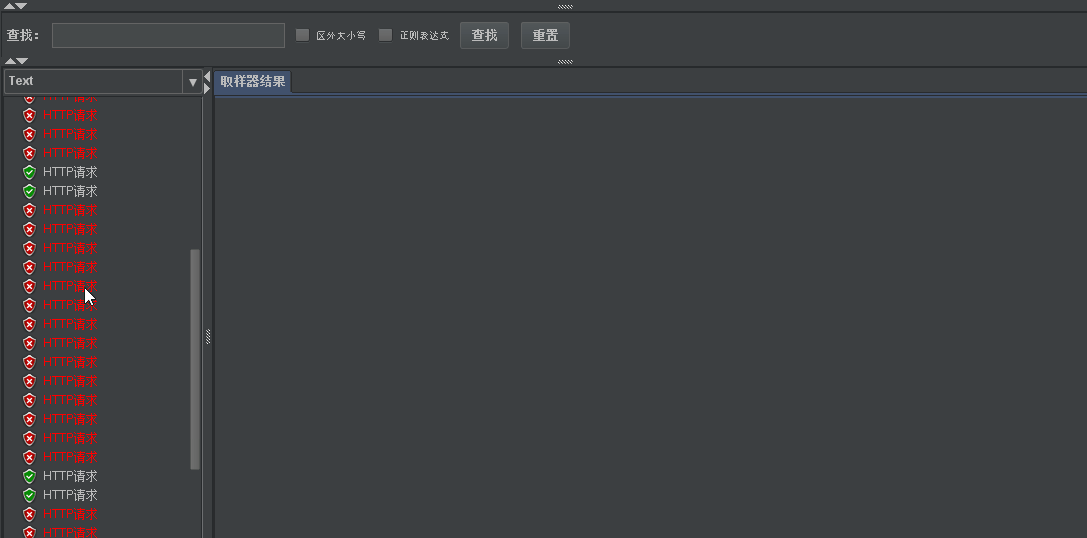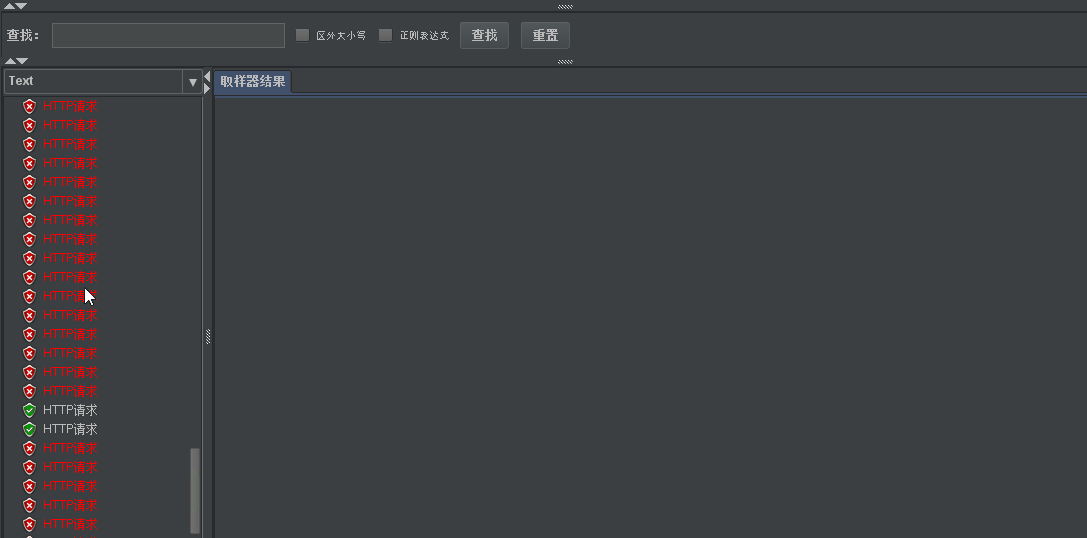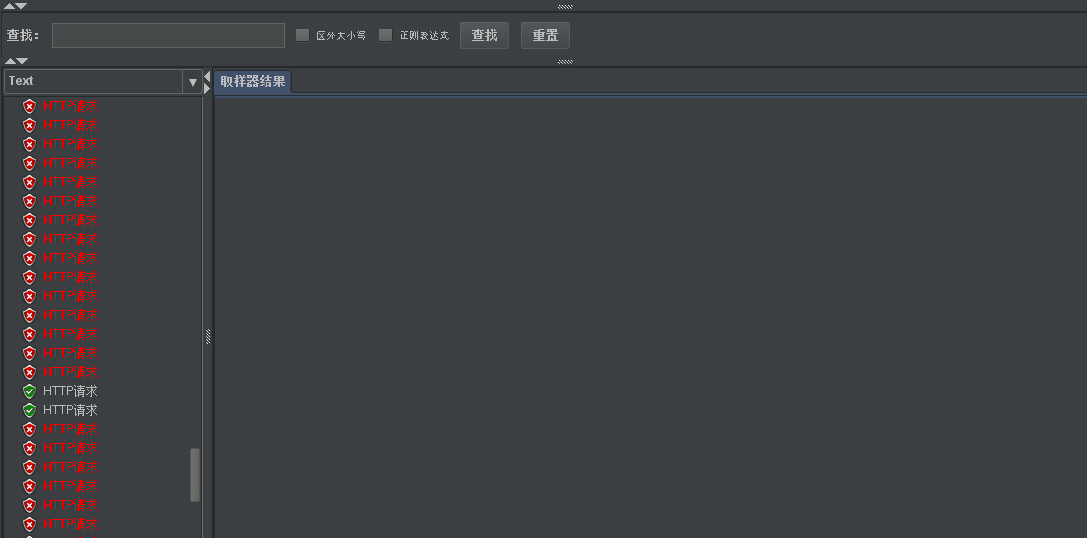
- We still have 10 accesses through 50 concurrent loops. We can find that high throughput can be achieved only at the beginning. After the barrel is full. When the downstream droplet rate is slower than the upstream request rate. Access can only be received at a constant speed downstream.
- His problems are also obvious. For the lack of time window, the leakage bucket is insufficient, but it is still insufficient. The problem of request overflow cannot be completely avoided.
- Request overflow itself is a catastrophic problem. All algorithms have not solved this problem at present. Just slowing down the problems he brought
Token Bucket
-
Token bucket and leaky bucket are the same. It just changed the direction of the bucket.
-
The outflow speed of the leaky bucket is constant. If the flow increases suddenly, we can only refuse to enter the pool
-
However, the token bucket is to put the token into the bucket. We know that under normal circumstances, the token is a string of characters. When the bucket is full, the token will be refused to enter the pool. However, in the face of high traffic, the normal plus our timeout time will leave enough time to produce and consume tokens. In this way, the request will not be rejected as much as possible
-
Finally, whether the token bucket cannot get the token and is rejected, or the water in the leaky bucket overflows, a small part of the flow is sacrificed to ensure the normal use of most of the flow
public Map<String, Object> startLingpaitong(Map<String, Object> paramMap) {
String redisKey = "lingpaitong";
String token = redisTemplate.opsForList().leftPop(redisKey).toString();
//Whether the tampering is legal and needs to be verified
if (StringUtils.isEmpty(token)) {
throw new RuntimeException("Token bucket reject");
}
Map<String, Object> map = new HashMap<>();
map.put("success", "success");
return map;
}
@Scheduled(cron="*/1 * * * * ?")
private void process(){
//One time production of two
System.out.println("Consuming......");
for (int i = 0; i < 2; i++) {
redisTemplate.opsForList().rightPush(redisKey, i);
}
}