Hello, guys, the first two blog cases basically introduced the basic process of crawler. This blog began to put a heavy bomb, and the difficulty coefficient increased a little (difficulty 1: involving secondary page crawling, difficulty 2: crawling a total of 16 fields). The main content of this article: Take Shijiazhuang City as an example, crawl the relevant field information on the details page of the second-hand housing community of anjuke.com, and crawl the information on the home page of the second-hand housing community, which will not be introduced here, because it is different from the previous blog( Python crawls 58 houses on sale in the same city )The steps of the crawler are basically the same. Interested partners can have a look. All right, no more nonsense, let's start~
First of all, let's open the official website of anjuke and set up two screening conditions: Shijiazhuang city and second-hand housing community (this is selected according to the interests of our partners). We can see that there are 11688 selected communities, 25 on each page, so there are about 468 pages of data. If we crawl all the community data, it will take more time, This article mainly focuses on explaining the process, so here, we mainly crawl the relevant field data of the detail page of the first 500 communities. Now let's take a look at what fields can be crawled on the detail page of second-hand housing communities?
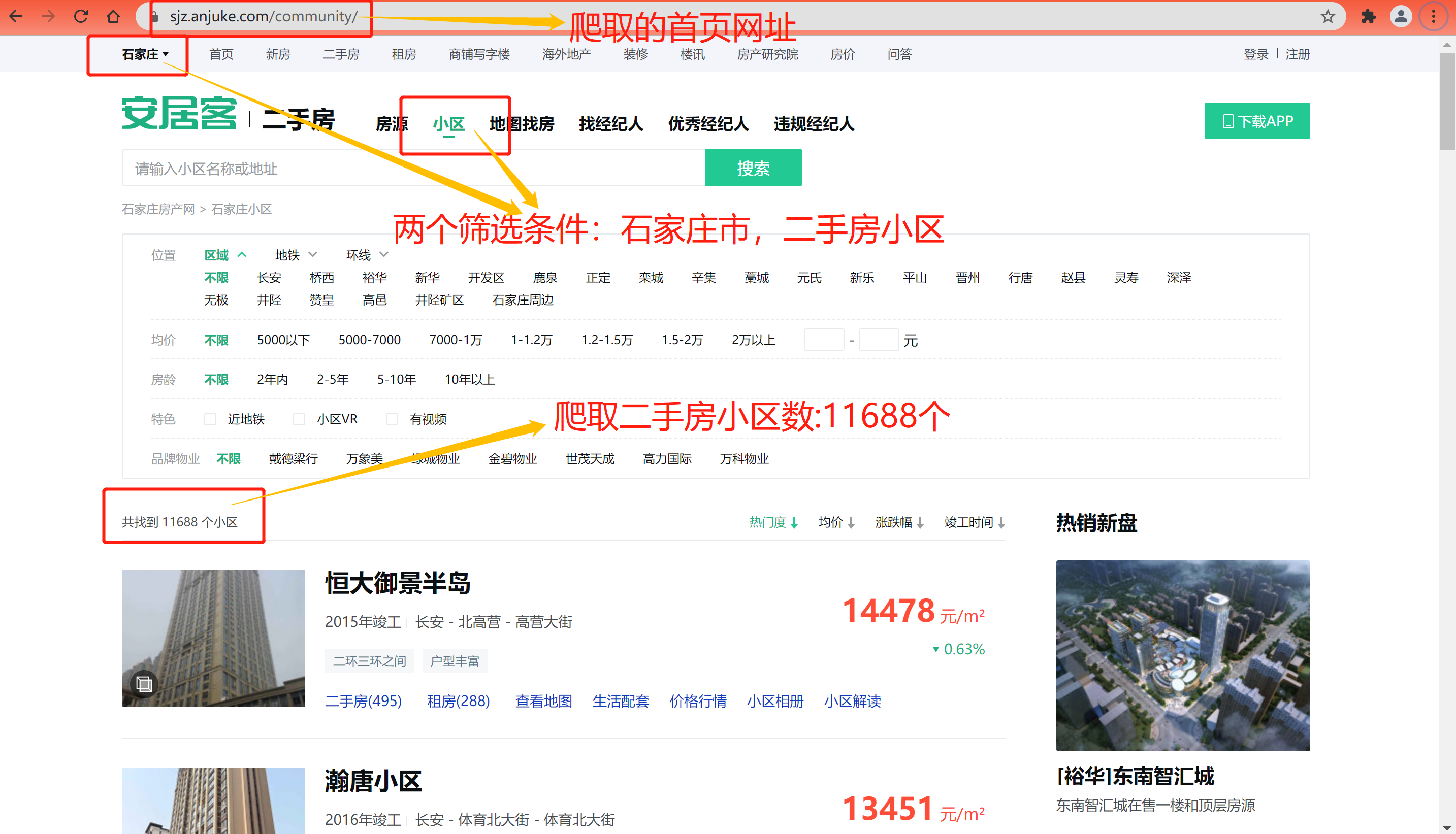
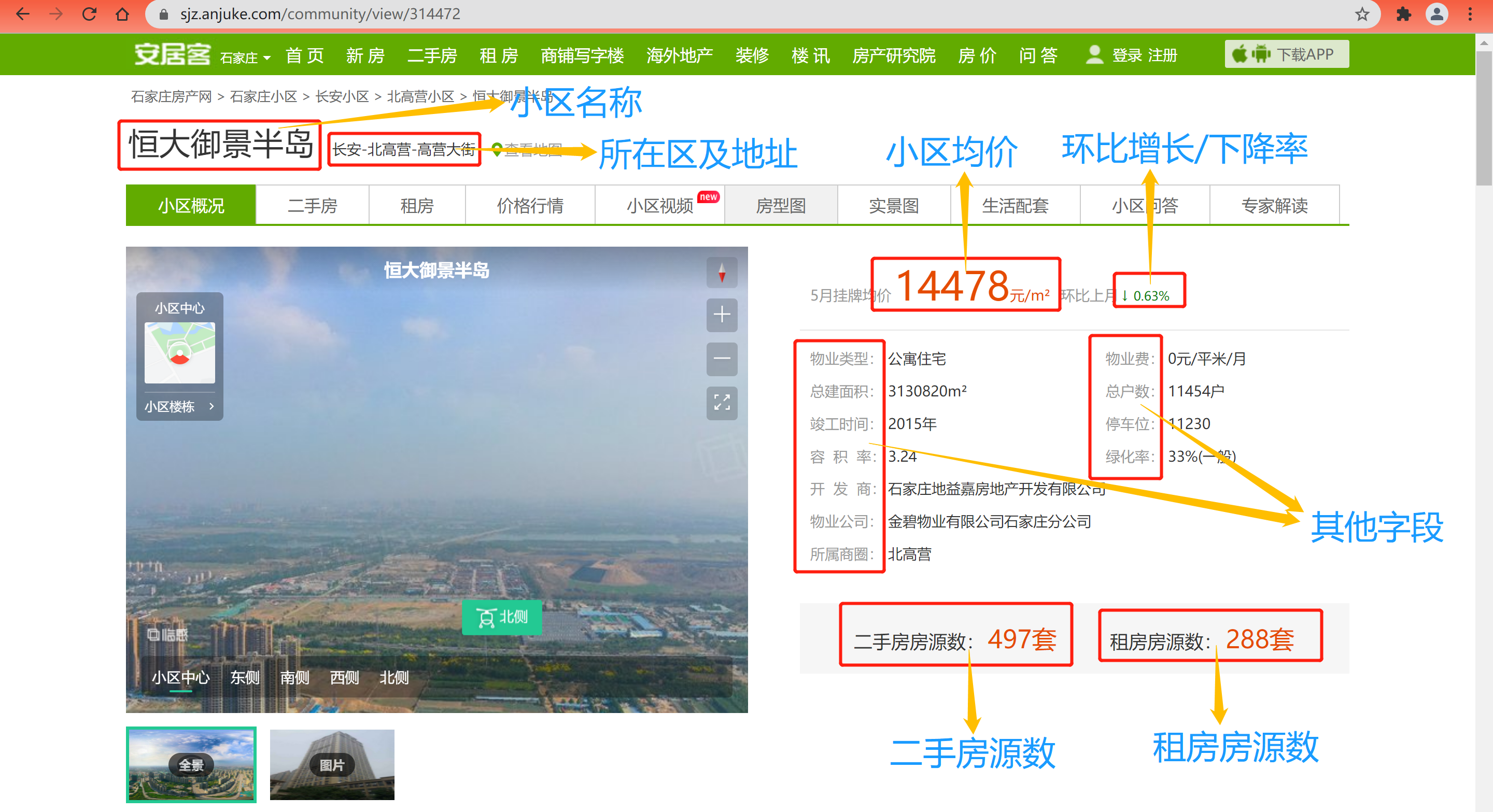
Taking Evergrande Yujing Peninsula, the first second-hand housing community on the home page, as an example, we open the community details page as shown in the figure below. From the figure, we can see that there are many field information. This time, our task is to crawl these relevant fields, mainly including: community name, location and address, average price of the community, number of second-hand houses, number of rental houses, property type, property fee, total construction area Total number of households, completion time, parking space, plot ratio, greening rate, developer, property company and business district, there are 16 fields in total.
It is also mentioned at the beginning of the article that compared with the previous two crawler cases, the difficulty of this crawler case should be increased. The difficulty is mainly concentrated in two aspects: one is secondary page crawling, and the other is that there are many crawling fields. But don't panic, steady, in fact, it's not difficult. Here, I will briefly describe the general crawling process, and the little partners will understand how to crawl. General process: first crawl the URL of each cell detail page according to the URL of the cell list page, then traverse the URL of each cell detail page, and crawl the relevant field information of its detail page in turn during the cycle. Basically, it is the logic of loop set loop! If you still don't understand, you may be surprised to see the code directly later!
1. Get the URL of Shijiazhuang second-hand housing community of anjuke.com
As for how to get the URL, here is no more introduction. Just put the results directly. If you have just started to contact a small partner, you can see my first two basic cases of crawler blog.
# Home page URL
url = 'https://sjz.anjuke.com/community/p1'
# Multi page crawling: for the convenience of crawling, take the first 500 communities as an example, 25 per page, a total of 20 pages
for i in range(20):
url = 'https://sjz.anjuke.com/community/p{}'.format(i)2. Analyze the html code of the web page and view the location of the web page where each field information is located
Here, the html codes of two pages are involved. One is the cell list page and the other is the details page of each cell. Let's take a look at them respectively:
(1) Cell list page html code:
On the cell list page, we only need to obtain two aspects: one is the URL of each cell details page, and the other is the average price of each cell;
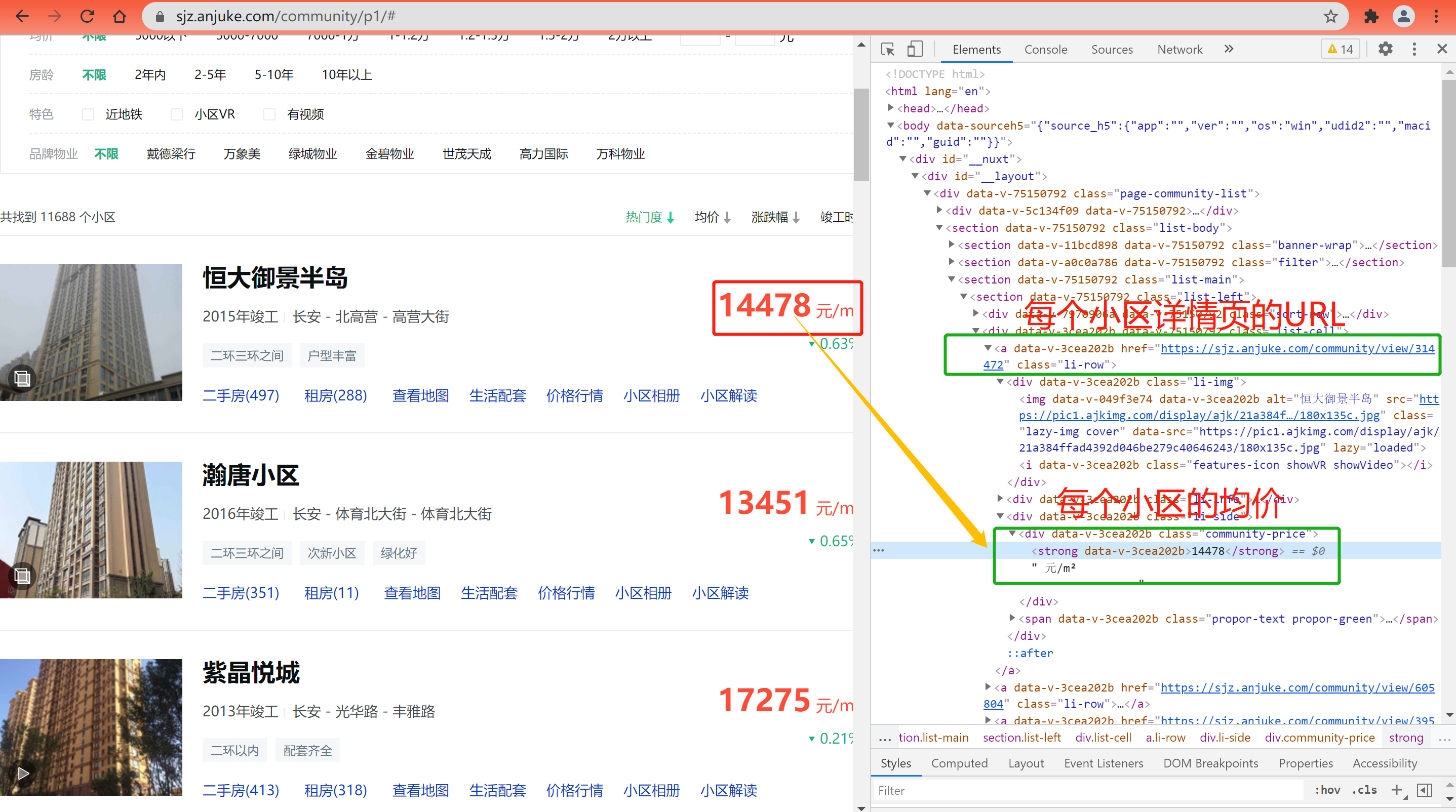
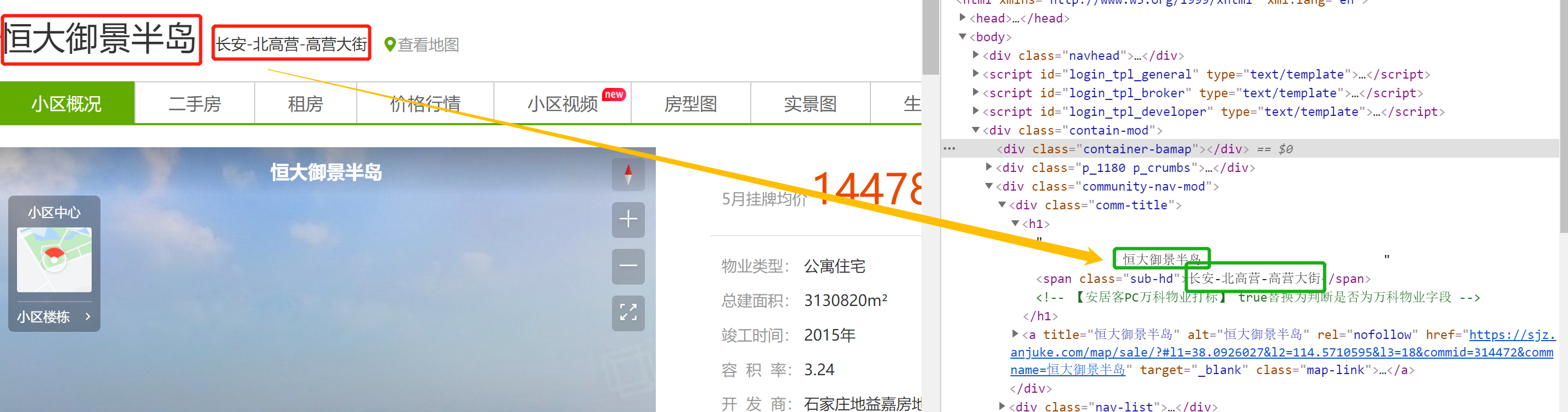
(2) Cell details page html code:
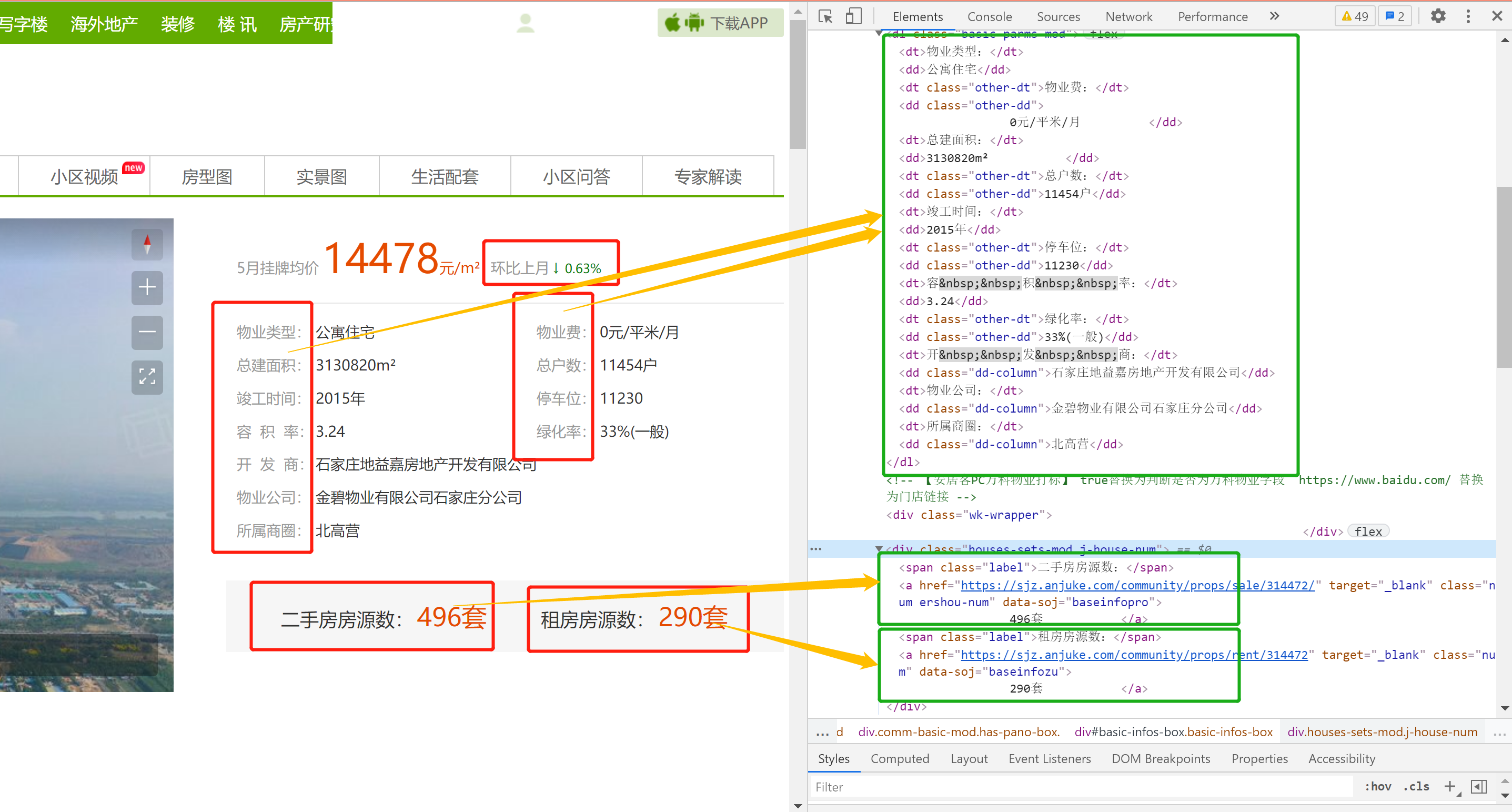
3. Use Xpath to parse the web page and obtain the value of the corresponding field
(1) Cell list page:
# URL of each cell details page:
link = html.xpath('.//div[@class="list-cell"]/a/@href')
# Average price of community:
price = html.xpath('.//div[@class="list-cell"]/a/div[3]/div/strong/text()')(2) Cell details page:
dict_result = {'Community name':'-','Price':'-','Cell address':'-','Property type':'-','Property fee': '-','Total construction area': '-','Total households': '-','Construction age': '-','Parking space': '-','Plot ratio': '-','Greening rate': '-','Developers': '-','Property company': '-','Business district': '-','Number of second-hand houses':'-','Number of rental houses':'-'}
dict_result['Community name'] = html.xpath('.//div[@class="comm-title"]/h1/text()')
dict_result['Cell address'] = html.xpath('.//div[@class="comm-title"]/h1/span/text()')
dict_result['Property type'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[1]/text()')
dict_result['Property fee'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[2]/text()')
dict_result['Total construction area'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[3]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[3]/text()')
dict_result['Total households'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[4]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[4]/text()')
dict_result['Construction age'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[5]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[5]/text()')
dict_result['Parking space'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[6]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[6]/text()')
dict_result['Plot ratio'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[7]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[7]/text()')
dict_result['Greening rate'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[8]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[8]/text()')
dict_result['Developers'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[9]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[9]/text()')
dict_result['Property company'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[10]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[10]/text()')
dict_result['Business district'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[11]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[11]/text()')
dict_result['Number of second-hand houses'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[1]/text()')
dict_result['Number of rental houses'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[2]/text()')4. Home page crawling - 25 cell details page data
In general, I will first consider crawling the content of the home page. When all the field information of the home page content is crawling without error, I will add a cycle to crawl multiple pages of content. If you have a foundation, you can skip this chapter and see the complete code for crawling all the data at last( 5. Complete code analysis during multi page crawling);
(1) Import packages and create file objects
## Import related packages
from lxml import etree
import requests
from fake_useragent import UserAgent
import random
import time
import csv
import re
## Create file object
f = open('Anjuke.com Shijiazhuang second-hand housing information.csv', 'w', encoding='utf-8-sig', newline="") # Create file object
csv_write = csv.DictWriter(f, fieldnames=['Community name', 'Price', 'Cell address', 'Property type','Property fee','Total construction area','Total households', 'Construction age','Parking space','Plot ratio','Greening rate','Developers','Property company','Business district','Number of second-hand houses','Number of rental houses'])
csv_write.writeheader() # Write file header(2) Set reverse crawl
## Set request header parameters: user agent, cookie, referer
ua = UserAgent()
headers = {
# Randomly generate user agent
"user-agent": ua.random,
# Cookies are different when different users visit at different times. See another blog for access methods according to their own web pages
"cookie": "sessid=C7103713-BE7D-9BEF-CFB5-6048A637E2DF; aQQ_ajkguid=263AC301-A02C-088D-AE4E-59D4B4D4726A; ctid=28; twe=2; id58=e87rkGCpsF6WHADop0A3Ag==; wmda_uuid=1231c40ad548840be4be3d965bc424de; wmda_new_uuid=1; wmda_session_id_6289197098934=1621733471115-664b82b6-8742-1591; wmda_visited_projects=%3B6289197098934; obtain_by=2; 58tj_uuid=8b1e1b8f-3890-47f7-ba3a-7fc4469ca8c1; new_session=1; init_refer=http%253A%252F%252Flocalhost%253A8888%252F; new_uv=1; _ga=GA1.2.1526033348.1621734712; _gid=GA1.2.876089249.1621734712; als=0; xxzl_cid=7be33aacf08c4431a744d39ca848819a; xzuid=717fc82c-ccb6-4394-9505-36f7da91c8c6",
# Set where to jump from
"referer": "https://sjz.anjuke.com/community/p1/",
}
## Randomly obtain an IP from the proxy IP pool. For example, the ProxyPool project must be running
def get_proxy():
try:
PROXY_POOL_URL = 'http://localhost:5555/random'
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
except ConnectionError:
return None(3) Parsing first level page functions:
It mainly crawls the URL of each cell detail page in the cell list and the average price of each cell;
## Parsing first level page function
def get_link(url):
text = requests.get(url=url, headers=headers, proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
link = html.xpath('.//div[@class="list-cell"]/a/@href')
price = html.xpath('.//div[@class="list-cell"]/a/div[3]/div/strong/text()')
#print(link)
#print(price)
return zip(link, price)(4) Analyze the secondary page function, that is, the cell details page
## Parsing secondary page functions
def parse_message(url, price):
dict_result = {'Community name': '-','Price': '-','Cell address': '-','Property type': '-',
'Property fee': '-','Total construction area': '-','Total households': '-','Construction age': '-',
'Parking space': '-','Plot ratio': '-','Greening rate': '-','Developers': '-',
'Property company': '-','Business district': '-','Number of second-hand houses':'-','Number of rental houses':'-'}
text = requests.get(url=url, headers=headers,proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
dict_result['Community name'] = html.xpath('.//div[@class="comm-title"]/h1/text()')
dict_result['Cell address'] = html.xpath('.//div[@class="comm-title"]/h1/span/text()')
dict_result['Property type'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[1]/text()')
dict_result['Property fee'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[2]/text()')
dict_result['Total construction area'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[3]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[3]/text()')
dict_result['Total households'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[4]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[4]/text()')
dict_result['Construction age'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[5]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[5]/text()')
dict_result['Parking space'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[6]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[6]/text()')
dict_result['Plot ratio'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[7]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[7]/text()')
dict_result['Greening rate'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[8]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[8]/text()')
dict_result['Developers'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[9]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[9]/text()')
dict_result['Property company'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[10]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[10]/text()')
dict_result['Business district'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[11]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[11]/text()')
dict_result['Number of second-hand houses'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[1]/text()')
dict_result['Number of rental houses'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[2]/text()')
# Simply preprocess the crawled data
for key,value in dict_result.items():
value = list(map(lambda item: re.sub('\s+', '', item), value)) # Remove line breaks and tabs
dict_result[key] = list(filter(None, value)) # Remove the empty element generated in the previous step
if len(dict_result[key]) == 0:
dict_result[key] = ''
else:
dict_result[key] = dict_result[key][0]
dict_result['Price'] = price
return dict_result(5) Save data to file save_csv() function
## Read data into csv file
def save_csv(result):
for row in result: # A cell data is stored in a dictionary
csv_write.writerow(row)(6) Only the main function when crawling the home page
#Main function
C = 1
k = 1 # Number of crawling listings
print("************************Page 1 start crawling************************")
# First page URL
url = 'https://sjz.anjuke.com/community/p1'
# Parse the first level page function, which returns the URL and average price of the detail page
link = get_link(url)
list_result = [] # Store dictionary data in the list
for j in link:
try:
# Parse the secondary page function and pass in two parameters: the URL of the detail page and the average price
result = parse_message(j[0], j[1])
list_result.append(result)
print("Crawled{}Data bar".format(k))
k = k + 1 # Control the number of cells crawled
time.sleep(round(random.randint(5, 10), C)) # Set sleep interval
except Exception as err:
print("-----------------------------")
print(err)
# Save data to file
save_csv(list_result)
print("************************Page 1 successfully crawled************************")5. Multi page crawling - complete code analysis
Since the code is long, you must read it patiently. If you are just starting to learn crawler, you can first look at Part 4 above. After learning to crawl home page data, it will be much easier to crawl multi page data;
## Import related packages
from lxml import etree
import requests
from fake_useragent import UserAgent
import random
import time
import csv
import re
## Create file object
f = open('Anjuke.com Shijiazhuang second-hand housing information.csv', 'w', encoding='utf-8-sig', newline="") # Create file object
csv_write = csv.DictWriter(f, fieldnames=['Community name', 'Price', 'Cell address', 'Property type','Property fee','Total construction area','Total households', 'Construction age','Parking space','Plot ratio','Greening rate','Developers','Property company','Business district','Number of second-hand houses','Number of rental houses'])
csv_write.writeheader() # Write file header
## Set request header parameters: user agent, cookie, referer
ua = UserAgent()
headers = {
# Randomly generate user agent
"user-agent": ua.random,
# Cookies are different when different users visit at different times. See another blog for access methods according to their own web pages
"cookie": "sessid=C7103713-BE7D-9BEF-CFB5-6048A637E2DF; aQQ_ajkguid=263AC301-A02C-088D-AE4E-59D4B4D4726A; ctid=28; twe=2; id58=e87rkGCpsF6WHADop0A3Ag==; wmda_uuid=1231c40ad548840be4be3d965bc424de; wmda_new_uuid=1; wmda_session_id_6289197098934=1621733471115-664b82b6-8742-1591; wmda_visited_projects=%3B6289197098934; obtain_by=2; 58tj_uuid=8b1e1b8f-3890-47f7-ba3a-7fc4469ca8c1; new_session=1; init_refer=http%253A%252F%252Flocalhost%253A8888%252F; new_uv=1; _ga=GA1.2.1526033348.1621734712; _gid=GA1.2.876089249.1621734712; als=0; xxzl_cid=7be33aacf08c4431a744d39ca848819a; xzuid=717fc82c-ccb6-4394-9505-36f7da91c8c6",
# Set where to jump from
"referer": "https://sjz.anjuke.com/community/p1/",
}
## Randomly obtain an IP from the proxy IP pool. For example, the ProxyPool project must be running
def get_proxy():
try:
PROXY_POOL_URL = 'http://localhost:5555/random'
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
except ConnectionError:
return None
## Parsing first level page function
def get_link(url):
text = requests.get(url=url, headers=headers, proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
link = html.xpath('.//div[@class="list-cell"]/a/@href')
price = html.xpath('.//div[@class="list-cell"]/a/div[3]/div/strong/text()')
#print(link)
#print(price)
return zip(link, price)
## Parsing secondary page functions
def parse_message(url, price):
dict_result = {'Community name': '-','Price': '-','Cell address': '-','Property type': '-',
'Property fee': '-','Total construction area': '-','Total households': '-','Construction age': '-',
'Parking space': '-','Plot ratio': '-','Greening rate': '-','Developers': '-',
'Property company': '-','Business district': '-','Number of second-hand houses':'-','Number of rental houses':'-'}
text = requests.get(url=url, headers=headers,proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
dict_result['Community name'] = html.xpath('.//div[@class="comm-title"]/h1/text()')
dict_result['Cell address'] = html.xpath('.//div[@class="comm-title"]/h1/span/text()')
dict_result['Property type'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[1]/text()')
dict_result['Property fee'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[2]/text()')
dict_result['Total construction area'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[3]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[3]/text()')
dict_result['Total households'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[4]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[4]/text()')
dict_result['Construction age'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[5]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[5]/text()')
dict_result['Parking space'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[6]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[6]/text()')
dict_result['Plot ratio'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[7]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[7]/text()')
dict_result['Greening rate'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[8]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[8]/text()')
dict_result['Developers'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[9]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[9]/text()')
dict_result['Property company'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[10]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[10]/text()')
dict_result['Business district'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[11]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[11]/text()')
dict_result['Number of second-hand houses'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[1]/text()')
dict_result['Number of rental houses'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[2]/text()')
# Simply preprocess the crawled data
for key,value in dict_result.items():
value = list(map(lambda item: re.sub('\s+', '', item), value)) # Remove line breaks and tabs
dict_result[key] = list(filter(None, value)) # Remove the empty element generated in the previous step
if len(dict_result[key]) == 0:
dict_result[key] = ''
else:
dict_result[key] = dict_result[key][0]
dict_result['Price'] = price
return dict_result
## Read data into csv file
def save_csv(result):
for row in result:
csv_write.writerow(row)
## Main code
C = 1
k = 1 # Number of crawling listings
# Multi page crawling. Due to time constraints, only the detailed data of the first 500 cells are crawled, and subsequent interested partners can crawl by themselves
for i in range(1,21): #There are 25 communities on each page, and the first 500 are 20 pages
print("************************" + "The first%s Page start crawling" % i + "************************")
url = 'https://sjz.anjuke.com/community/p{}'.format(i)
# Parse the first level page function, which returns the URL and average price of the detail page
link = get_link(url)
list_result = [] # Define a list to store the dictionary data of each cell
for j in link:
try:
# Parse the secondary page function and pass in two parameters: the URL of the detail page and the average price
result = parse_message(j[0], j[1])
list_result.append(result) # Store dictionary data in the list
print("Crawled{}Data bar".format(k))
k = k + 1 # Control the number of cells crawled
time.sleep(round(random.randint(1,3), C)) # Set the sleep interval and control the two-level page access time
except Exception as err:
print("-----------------------------")
print(err)
# Save data to file
save_csv(list_result)
time.sleep(random.randint(1,3)) # Set the sleep interval and control the first level page access time
print("************************" + "The first%s Page crawling succeeded" % i + "************************")6. Data finally crawled
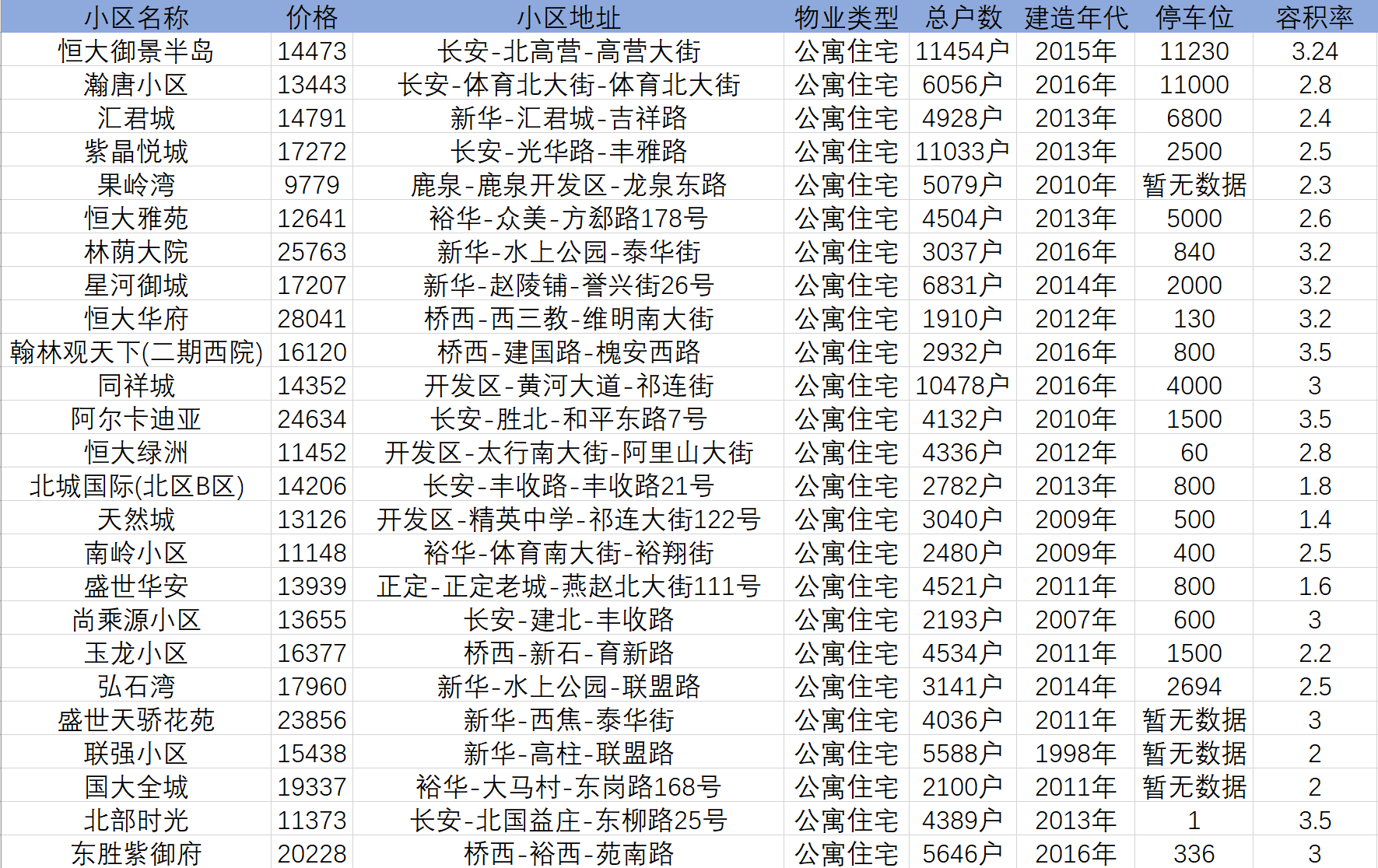
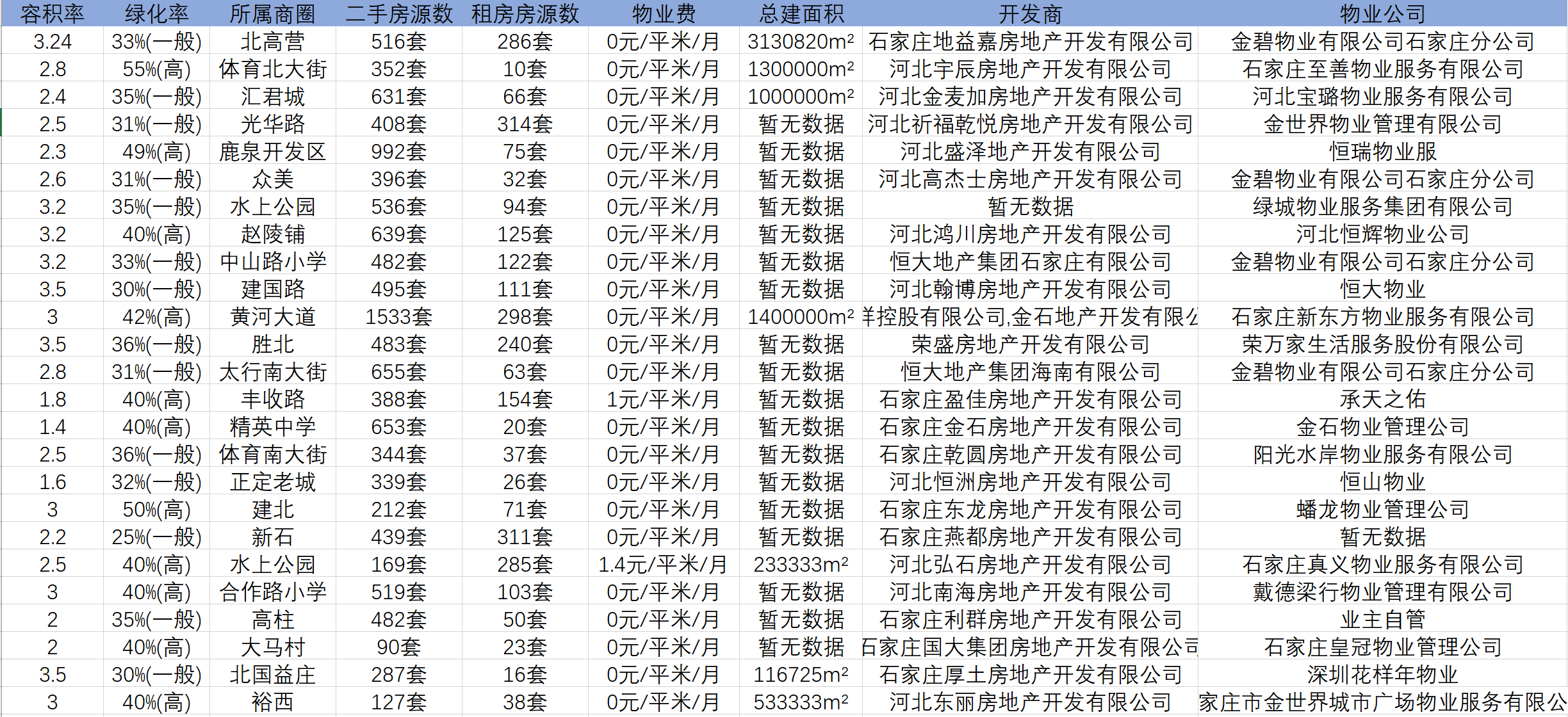
Well, the third crawler case is almost over. This paper mainly uses Xpath to crawl the relevant data on the details page of second-hand housing community in Shijiazhuang. Compared with the first two cases, the difficulty of this case has increased by one level. The difficulty is mainly reflected in two aspects: one is related to the crawling of secondary pages, You need to obtain the URL of the secondary page from the primary page; The other is that there are many fields to crawl. You need to constantly try to check whether the corresponding fields can be crawled successfully. Generally speaking, although the difficulty has increased, as long as the partners can keep reading, I believe there will be no small harvest! When I was a little white student, my first feeling was that reptiles could still play like this. It was still very interesting! As for the follow-up blog plan, I have crawled Baidu map POI data, public comments, etc. in the process of learning before. This may be what I want to summarize in the next step. If my friends are interested, they can pay attention to Bo. Hey hey!
If there is a place where the introduction is not very comprehensive, you are welcome to leave a message in the comment area, and I will continue to improve it!
It's all here. Are you sure you don't leave anything, hee hee~
