preface
Hello, guys, I'm amu! A programmer who likes to share technical points through actual project practice!
Have you ever encountered the scene of being ridiculed by the interviewer; Before, there was a junior who just graduated from primary school (Internet cafe in University, temporary cramming after graduation) who was interviewed in a large company in Shanghai magic capital. On the second side, he mainly asked about the relevant knowledge points of redis, and the answer was stumbling. Therefore, I took one of the knowledge points (friends nearby) to share and discuss with my friends. If there is anything wrong, you are welcome to correct and criticize and make common progress~~~
Interviewer's main test site
- Test site 1: what is the Geohash of the interviewer's test site? The amount of knowledge storage has not been used, but we can't help but know
- Test site 2: the principle and algorithm of the interviewer's test site # test the basic skills of the algorithm
- Test site 3: the interviewer's basic command of redis's geohash
- Test site 4: the interviewer's ideas and plans for the implementation of the test site # investigate the thinking ability
- Test site 5: the actual project application and actual combat experience of the interviewer's test site
When you see that the interviewer wants to test your knowledge; During the interview, your mind is turning rapidly, combining a series of data scenarios to prepare for the challenge.
Introduction to Geohash concept
geohash is a kind of geographic location coding. It is used to query the nearby POI(POI is the abbreviation of "Point of Interest", which can be translated into "Point of Interest" in Chinese. In GIS, a POI can be a house, a shop, a mailbox, a bus stop, etc.), which is also an algorithm idea.
The earth is regarded as a two-dimensional plan, and then the plane is recursively cut into smaller modules. Then the spatial longitude and latitude data are encoded to generate a binary string, and then it is converted into a string through base32. Finally, we query the nearby target elements by comparing the similarity of geohash values.
What functions can Geohash achieve?
- Map navigation; Gaode map, baidu map, Tencent map
- Function of nearby people; One person near wechat, one person near wechat
Geohash algorithm principle
Seriously, when I want to explain the principle and algorithm, I am also very tangled. After all, the algorithm is not my strength, and Baidu is the same; And they are all summarized by great gods, and they dare not belittle themselves. Therefore, we still stand on the shoulders of our predecessors to understand the geohash principle and algorithm.
"People nearby" is often referred to as lbs (location-based services). It focuses on users' current geographic location data and provides users with accurate value-added services.
The core idea of "people nearby" is as follows:
① Search for nearby users with "yourself" as the center
② Calculate the distance between others and me based on your current geographical location
③ Sort by the distance between "yourself" and others, and filter out the users or stores closest to me
Then we follow our previous operation mode: when we search for people nearby, we will put the user information of the whole site into a list, and then traverse all nodes to check which node is within our scope; The time complexity becomes n*m(n search times, m user data). Who can withstand it? That is, it can't withstand all redis once the amount of data comes up, and the search efficiency is very low.
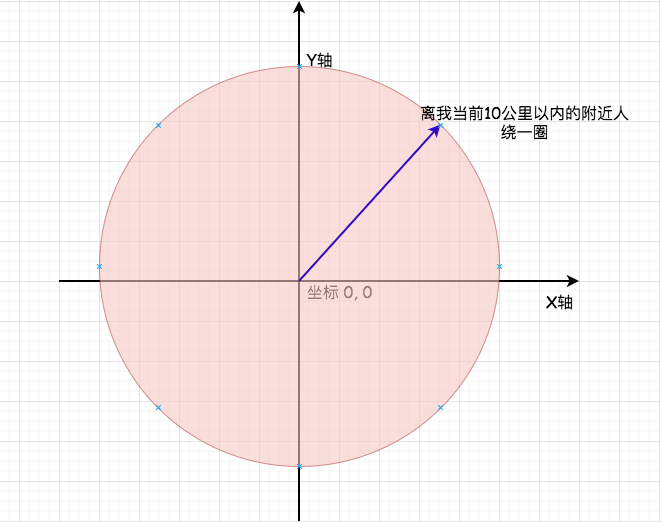
You can see from the above that in fact, you take your own coordinates as a center; Hey, then we need to find a nearby partner within 10 kilometers around us:
X axis: we can regard it as latitude, and the range of the left half is - 180 ° ~ ~ 0 °; The right half is 0 ° ~ ~ 180 ° Y axis: we can regard it as longitude, and the range of the upper half is 0 ° ~ ~ 90 °; The lower half is the - 90 ° ~ ~ 0 ° origin: we regard it as the (0,0) position; It's like our own position
For example
If we are now located in Guangzhou byte beating Co., Ltd. (No. 6, Zhujiang East Road, Tianhe District, Guangzhou), the longitude and latitude are 113.326059 (longitude) and 23.117596 (latitude)
The essence of geohash is to divide the longitude and latitude into corresponding intervals. The finer the division is, the finer it is until it approaches a critical value. Then the more layers the division is, the more accurate the accuracy is.
The principle is: mark the left interval with 0; The right section is marked with 1.
For example, we use code to realize the binary generated by the above latitude and longitude dichotomy:
/**
* @desc The binary code of longitude and latitude is found by using recursive idea
* @param float $place Longitude or latitude
* @param string $binary_array bit value obtained by each recursion
* @param int $max_separate_num Total number of recursions
* @param array $section Interval value
* @param int $num Recursion times
* @return array
*/
public function binary($place = 0, $binary_array = [], $max_recursion_num = 20, $section = [], $num = 1)
{
if (!$section) return $binary_array;
// Get intermediate value
$count = ($section['max'] - $section['min']) / 2;
// Left half interval
$left = [
'min' => $section['min'],
'max' => $section['min'] + $count
];
// Right half interval
$right = [
'min' => $section['min'] + $count,
'max' => $section['max']
];
// If the longitude and latitude value of a given point is greater than the minimum value on the right, it belongs to the right half interval and is 1, otherwise it is the left half interval 0
array_push($binary_array, $place > $right['min'] ? 1 : 0);
// If the number of recursions has reached the maximum, the result set is returned directly
if ($max_recursion_num <= $num) return $binary_array;
// Next time we recurse, we need to pass in the latitude and longitude interval value
$section = $place > $right['min'] ? $right : $left;
// Continue the recursive processing for itself until the result appears
return $this->binary($place, $binary_array, $max_recursion_num, $section, $num + 1);
}
// Instantiate and call the method
require_once './Geohash.php';
$geohash = new Geohash();
echo json_encode($geohash->binary(23.117596,[],$geohash->baseLengthGetNums(4, 1), $geohash->interval[0],1));
//Result set
[1,0,1,0,0,0,0,0,1,1]-> Binary 101000 00011 is this very clear
//If you can't understand it for a long time, print out the range value:
[{"min":-90,"max":90},{"min":0,"max":90},{"min":0,"max":45},{"min":22.5,"max":45},{"min":22.5,"max":33.75},{"min":22.5,"max":28.125},{"min":22.5,"max":25.3125},{"min":22.5,"max":23.90625},{"min":22.5,"max":23.203125},{"min":22.8515625,"max":23.203125}]
Is it clearer from the script implementation above? Then I'm using lua language to show you that the principles are basically the same:
local cjson = require("cjson")
-- Define latitude and longitude range
local interval = {
{ min = -90, max = 90 },
{ min = -180, max = 180 }
}
--- @desc The binary code of longitude and latitude is found by using recursive idea
--- @param place string Longitude or latitude
--- @param binary_array table I get it every time I recurse bit value
--- @param max_separate_num number Total number of recursions
--- @param section table Interval value
--- @param num number Recursion times
function binary(place, binary_array, max_recursion_num, section, num)
-- body
place = tonumber(place) or 0
binary_array = binary_array and binary_array or {}
max_recursion_num = tonumber(max_recursion_num) or 20
section = section and section or {}
num = tonumber(num) or 1
if not next(section) then
return binary_array
end
print(cjson.encode(section))
-- Get intermediate value
local count = (section["max"] - section["min"]) / 2
-- Left half interval
local left = {
min = section["min"],
max = section["min"] + count
}
-- Right half interval
local right = {
min = section["min"] + count,
max = section["max"]
}
-- If the longitude and latitude value of a given point is greater than the minimum value on the right, it belongs to the right half interval and is 1, otherwise it is the left half interval 0
binary_array[#binary_array+1] = place > right["min"] and 1 or 0
-- If the number of recursions has reached the maximum, the result set is returned directly
if max_recursion_num <= num then
return binary_array
end
-- Next time we recurse, we need to pass in the latitude and longitude interval value
local _section = place > right["min"] and right or left
return binary(place, binary_array, max_recursion_num, _section, num + 1)
end
local res = binary(113.326059, {}, _base_length_get_nums(4, 1), interval[2], 1)
print(cjson.encode(res))
//Print results
{"max":180,"min":-180}
{"max":180,"min":0}
{"max":180,"min":90}
{"max":135,"min":90}
{"max":135,"min":112.5}
{"max":123.75,"min":112.5}
{"max":118.125,"min":112.5}
{"max":115.3125,"min":112.5}
{"max":113.90625,"min":112.5}
{"max":113.90625,"min":113.203125}
[1,1,0,1,0,0,0,0,1,0]
We can actually type and execute it manually. Smart friends should see a function PHP ($geohash - > baselengthgetnums) and a private method in lua (_base_length_get_nums). What is this used for? Through the method annotation, we can see that it roughly means our two-tier number:
--- @desc Obtain the number of two layers of longitude and latitude according to the specified coding length
--- @param int $length Coding accuracy
--- @param int $type Type 0-Latitude; one-longitude
--- @return mixed
local function _base_length_get_nums(length, typ)
-- The first way is to write dead
local list = { {2, 3}, {5, 5}, {7, 8}, {10, 10}, {12, 13}, {15, 15}, {17, 18}, {20, 20}, {22, 23}, {25, 25}, {27, 28}, {30, 30} }
-- The second is the combination of latitude digits calculated by law list
local cycle_num = 12
local list_res = {}
local lat, lng = 0, 0
for i = 1, 12, 1 do
lat = i % 2 == 0 and lat + 3 or lat + 2
lng = i % 2 == 0 and lng + 2 or lng + 3
list_res[#list_res + 1] = {lat, lng}
end
return list[length][typ]
end
🤡 Do you still have questions? My God, where does this list variable come from? Does it feel strange? Let's take a look at the following table showing GeoHash Base32 coding length and accuracy:
Overall calculation method: latitude The scope of is:-90° To 90° longitude The scope is:-180° To 180° Perimeter of earth reference sphere: 40075016.68 rice
| Geohash length | Lat digit | Lng digit | Lat error | Lng error | km error |
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ±2.8 | ±5.6 | ±630 |
| 3 | 7 | 8 | ±0.7 | ±0.7 | ±78 |
| 4 | 10 | 10 | ±0.087 | ±0.18 | ±20 |
| 5 | 12 | 13 | ±0.022 | ±0.022 | ±2.4 |
| 6 | 15 | 15 | ±0.0027 | ±0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
| 8 | 20 | 20 | ±0.000086 | ±0.000172 | ±0.01911 |
| 9 | 22 | 23 | ±0.000021 | ±0.000021 | ±0.00478 |
| 10 | 25 | 25 | ±0.00000268 | ±0.00000536 | ±0.0005871 |
| 11 | 27 | 28 | ±0.00000067 | ±00000067 | ±0.0001492 |
| 12 | 30 | 30 | ±0.00000008 | ±00000017 | ±0.0000186 |
At equal latitudes:
- Every 0.00001 degrees of longitude, the distance difference is about 1m;
- Every 0.0001 degrees, the distance difference is about 10m;
- Every 0.001 degrees, the distance difference is about 100m;
- Every 0.01 degrees, the distance difference is about 1000m;
- Every 0.1 degrees, the distance difference is about 10000 meters.
With equal longitude:
- The latitude is every 0.00001 degrees, and the distance difference is about 1.1m;
- The distance difference is about 11 meters every 0.0001 degrees;
- Every 0.001 degrees, the distance difference is about 111 meters;
- The distance difference is about 1113 meters every 0.01 degrees;
- The distance difference is about 11132 meters every 0.1 degrees.
Now it is clear at a glance. It is stipulated that the maximum length of Geohash is 12 layers, and each layer corresponds to the number of digits. oh So it's like this. Is it super simple. What do we do when we get the longitude and latitude code? It must be coded:
Combination code:
Through the above calculation, the code generated by latitude is 10100 00011 and the code generated by longitude is 11010 00010. The even bit is used for longitude and the odd bit is used for latitude. The two strings are combined to generate a new string: 11100 110000000 01101. Is it a little confused again? How is it combined? The following figure shows you its combination process:
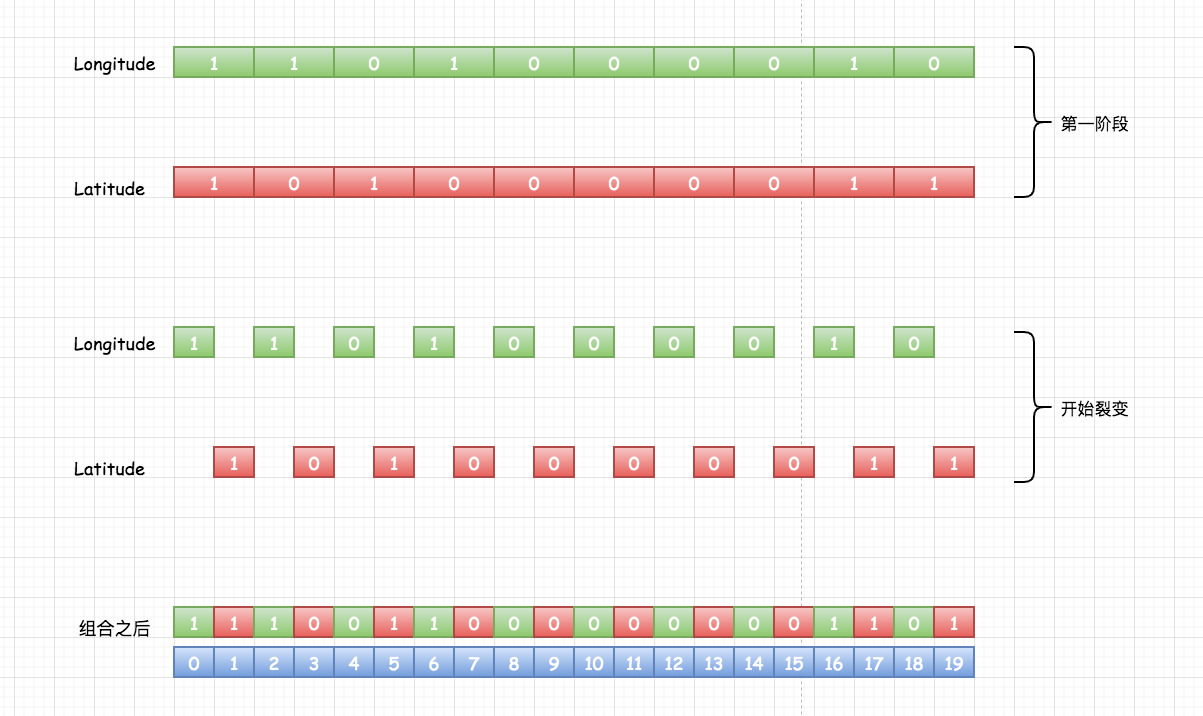
The combination is so simple; Some little friends may be a little confused about reading many articles in it. They will be a little confused about how to combine odd and even cross combinations; But it looks so simple!
Code implementation code combination
/**
* @desc Coding combination
* @param $latitude_str latitude
* @param $longitude_str longitude
* @return string
*/
public function combination($latitude_str, $longitude_str)
{
$result = '';
//Number as even position
for ($i = 0; $i < strlen($longitude_str); $i++) {
// Splice longitude as even position
$result .= $longitude_str{$i};
// Splice string if dimension exists
if (isset($latitude_str{$i})) $result .= $latitude_str{$i};
}
return $result;
}
// Result set
var_dump($geohash->combination('1010000011', '1101000010'));
11100110000000001101
function combination(latitude_arr, longitude_arr)
local result = ''
for i = 1, #longitude_arr do
result = result..longitude_arr[i]
if latitude_arr[i] then
result = result..latitude_arr[i]
end
end
return result
end
//Result set
print(cjson.encode(combination({1,0,1,0,0,0,0,0,1,1}, {1,1,0,1,0,0,0,0,1,0})))
11100110000000001101
Really, by this time, the work of converting longitude and latitude to GeoHash string has been half completed. Is it easy to catch up with super invincible~
Base32 algorithm: use the 32 letters of 0-9 and b-z (excluding a, i, l, o) to encode base32. First, convert 11100 110000000 01101 into decimal system, and the corresponding code corresponding to decimal system can be combined into string. I believe that those who have studied programming must have used base64 coding for encryption and decryption, but I'm not sure whether to study how to encrypt and decrypt. The difference between base32 and base64 is that the binary sequence corresponding to base32 is 5 bits and the binary sequence corresponding to base64 is 6 bits.
Some guys will ask why they want to remove it(a, i, l, o)These four letters? If you have any questions, please deduct 1 below!!!!!
- Characters that are easily confused, such as: [1, I (uppercase I), l (lowercase L)], [0,O]; When actually coding, you will read it wrong
- Remove vowels to prevent password leakage and increase reliability
Codes are combined into decimal and converted into strings
Principle: split and convert the combined binary sequence every 5 bits; For example:
11100 = 2^4+2^3+2^2 = 16+8+4 = 28 That is, correspondence w character string; Look at the corresponding Wikipedia dictionary below
| Decimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base32 encoding | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g | h |
| Decimal | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base32 encoding | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
Is it more clear? Just follow the right one; If there is no code at the end of the text, it will be decoded (the following code will not be written):
/**
* @desc Convert the binary string to decimal and then to the corresponding encoding
* @param $str
* @return string
*/
public function encode($str = '')
{
$string = '';
// Split string by 5 bits
$array = str_split($str, 5);
if (!$array) return $string;
foreach ($array as $va) {
//Binary to decimal
$decimal = bindec($va);
$string .= $this->base_32[$decimal];
}
return $string;
}
// The result set is ws0e
var_dump($geohash->encode('11100110000000001101'));
Note: in the process of converting longitude and latitude into binary sequence, the more times of conversion, the finer the precision and the smaller the scope of identification.
Geohash combat series
- Query of nearby people based on mysql
- Query of nearby people based on mysql + GeoHash
- Query of nearby people based on redis + GeoHash
- Query of nearby people based on mongoDB
- Implement the query of nearby people based on es search engine (say the next scheme)
Query of nearby people based on mysql
Create a table reported by the user's geographical location to store the longitude and latitude attributes:
CREATE TABLE `user_place` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `user_id` int(10) DEFAULT NULL DEFAULT '0' COMMENT 'user id', `longitude` double DEFAULT NULL DEFAULT '' COMMENT 'longitude', `latitude` double DEFAULT NULL DEFAULT ''COMMENT 'latitude', `create_time` int(10) DEFAULT NULL DEFAULT '0' COMMENT 'Creation time', PRIMARY KEY (`id`), KEY `idx_longe_lat` (`longitude`,`latitude`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
① The first scheme: query the nearby people who meet the requirements, and then calculate the distance (used in internship)
SELECT * FROM `user_place` WHERE (longitude BETWEEN minlng(Minimum longitude) AND maxlng(Maximum longitude)) AND (latitude BETWEEN minlat(Minimum latitude) AND maxlat(Maximum latitude)) After querying the result set, calculate the distance by latitude and longitude
② The second scheme: directly calculate the results through complex sql statements (used in internship)
// Current longitude and latitude coordinates $latitude = 23.117596 $longitude = 113.326059 //A series of complex calculations use the trigonometric function ASIN function in mysql: anti sinusoidal value; POWER function: used to calculate the y POWER of x. Other partners Baidu check sine and cosine fields = "user_id,ROUND(6378.138*2*ASIN(SQRT(POW(SIN(($latitude*PI()/180-latitude*PI()/180)/2),2)+COS($latitude*PI()/180)*COS(latitude*PI()/180)*POW(SIN(($longitude*PI()/180-longitude*PI()/180)/2),2)))*1000,2) AS distance"; selecet fields from `user_place` having distance <= 10 order by distance asc limit 10
③ Scheme 3: four built-in functions of mysql
1,ST_GeoHash(longitude, latitude, max_length -- generate geohash value
mysql> SELECT ST_GeoHash(116.336506,39.978729,10);
+-------------------------------------+
| ST_GeoHash(116.336506,39.978729,10) |
+-------------------------------------+
| wx4ermcsvp |
+-------------------------------------+
1 row in set (0.00 sec)
2,ST_LongFromGeoHash() -- from geohash Value returns longitude
mysql> SELECT ST_LongFromGeoHash('wx4ermcsvp');
+----------------------------------+
| ST_LongFromGeoHash('wx4ermcsvp') |
+----------------------------------+
| 116.33651 |
+----------------------------------+
1 row in set (0.00 sec)
3,ST_LatFromGeoHash() -- from geohash Value returns the latitude
mysql> SELECT ST_LatFromGeoHash('wx4ermcsvp');
+---------------------------------+
| ST_LatFromGeoHash('wx4ermcsvp') |
+---------------------------------+
| 39.97873 |
+---------------------------------+
1 row in set (0.00 sec)
4,ST_PointFromGeoHash() -- take geohash Convert value to point value
mysql> SELECT ST_AsText(ST_PointFromGeoHash('wx4ermcsvp',0));
+------------------------------------------------+
| ST_AsText(ST_PointFromGeoHash('wx4ermcsvp',0)) |
+------------------------------------------------+
| POINT(116.33651 39.97873) |
+------------------------------------------------+
1 row in set (0.00 sec)
In fact, the specific usage is almost the same. Partners can check the relevant information! Not a lot
Note: implement "people nearby" only based on mysql; Advantages: simple, one table can store longitude and latitude; Disadvantages: it can be used when the amount of data is relatively small. At the same time, it can cooperate with redis to cache the query result set, and the effect is ok; However, when the amount of data is large, we can see that a lot of calculation is needed to calculate the distance between two points, which has a great impact on the performance. (not recommended)
Query of nearby people based on mysql + GeoHash
① Design ideas
In the original table where the user's latitude and longitude are stored: the geohash string corresponding to the calculated latitude and longitude is stored in the table; When storing, we need to specify the length of the string.
Then we don't need to use longitude and latitude to query. We can do this: select * from xx where geohash like 'geohash%' for fuzzy query. The query result set calculates the distance through longitude and latitude; Then filter the specified distance. For example, if it is within 1000m, it is people nearby.
② Code implementation
-- Add field first geohash alter table `user` add `geohash` varchar(64) NOT NULL DEFAULT NULL COMMENT 'Longitude latitude correspondence geohash Code value', -- Add again geohash General index of alter table `user` add index idx_geohash ( `geohash` ) -- query sql select * from `user` where `geohash` like 'geohash%' order by id asc limit 100
③ Problem analysis
Everyone knows that geohash algorithm divides the map into several rectangular blocks, and then encodes the rectangular blocks to get the geohash string. Is this the case? This person is very close to me, but we are not in the same rectangular block. Is it that I can't find this person when I search? It's not blood loss (in case it's a beautiful sister)
④ Solution
During the search, we can calculate the geohash codes of 8 nearby blocks according to the current code, and then get them all, and then filter and compare them one by one; In this way, I found the girl to add friends!
⑤ Realize again
-- For example, there are eight values geohash1,geohash2,geohash3,geohash4,geohash5,geohash6,geohash7,geohash8 -- query sql select * from `user` where `geohash` regexp 'geohash1|geohash2|geohash3|geohash4' order by id asc limit 100
Then calculate the distance from the query result set and filter out the nearby people who are greater than the specified distance.
Query of nearby people based on redis + GeoHash
① Design ideas
1. Find select instruction operation:
1,geopos Instruction: geopos key member [member ...] Get specified key Returns the location of all specified names(Longitude and latitude);Time complexity O(log(n)),n Is the number of elements in the sort set
matters needing attention:
① geopos The command returns an array, each of which consists of two elements: the first is the longitude of the location, and the second is the latitude of the location.
② If the given element does not exist, the corresponding array item is nil(Don't be mistaken for an empty array).
2,geodist Instruction: geodist key member1 member2 [m|km|ft|mi] Obtain the distance between two given positions; Time complexity O(log(n)),n Is the number of elements in the sort set
matters needing attention:
① member1 and member2 Name two geographic locations, such as users id identification.
② [m|km|ft|mi]Tail parameters:
m : Meter, default unit
km : Kilometer
mi : mile
ft : foot
③ The calculated distance will be returned in the form of double precision floating-point number; If the location does not exist, return nil.
3,georadius Instruction: georadius key longitude latitude radius [m|km|ft|mi] [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
Obtain the set of geographical locations within the specified range according to the longitude and latitude coordinates given by the user; Time complexity: O(n+log(m)),n Is the number of elements in the bounding box of the circular area, which is bounded by the center and radius, m Is the number of items in the index.
matters needing attention:
① Centered on a given latitude and longitude
② [m|km|ft|mi]Unit description
m : Meter, default unit
km : Kilometer
mi : mile
ft : foot
③ withdist: While returning the location element, the distance between the location element and the center is also returned.
④ withcoord: The longitude and dimension of the location element are also returned.
⑤ withhash: Returns the signed position of the original element in the form of 52 bits geohash Coded ordered set score. This option is mainly used for low-level application or debugging, and has little effect in practice.
⑥ count Limit the number of records returned.
⑦ asc: The search results are sorted from near to far.
⑧ desc: The search results are sorted from far to near.
4,georadiusbymember Instruction: georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
Get the element data within the specified range. The center point is determined by the given location element, rather than using longitude and latitude to determine the center point. Time complexity: O(n+log(m)),n Is the number of elements in the bounding box of the circular area, which is bounded by the center and radius, m Is the number of items in the index.
The precautions are the same as above georadius Instruction!!!
5,geohash Instruction: geohash key member [member ...] Gets the location of one or more location elements geohash Value; Time complexity O(log(n)),n Is the number of elements in the sort set
matters needing attention:
① The command returns an array format. If the position does not exist, it returns nil
② The value of the array result set corresponds to the given position one by one. In other words, the subscript is consistent
2. Add insert instruction:
geoadd Instruction: geoadd key longitude latitude member [longitude latitude member ...] Add the coordinates of the geographical location; Time complexity O(log(n)),n Is the number of elements in the sort set. matters needing attention: ① The type of data actually stored is zset,member yes zset of value,score It is calculated according to longitude and latitude geohash ② geohash It's 52 bit The formula used to calculate the distance is Haversine ③ geoadd The added coordinates will have a little error because geohash One dimensional mapping of two-dimensional coordinates is lossy
Do you think it's a little strange that the time complexity of this redis command is O(log(n)), what does this mean? Then let's do some popular science together:
① O(1)Resolution: O(1)It is the lowest space-time complexity, that is, time-consuming/Space consumption has nothing to do with the size of input data. No matter how many times the input data is increased, it takes time/Space consumption remains unchanged. ② O(n)Resolution: For example, the time complexity is O(n),It means that the amount of data increases several times and the time consumption also increases several times. For example, the common traversal algorithm. To find the largest number in an array, you have to n All variables are scanned once, and the number of operations is n,So what is the complexity of the algorithm O(n). ③ O(n^2)Resolution: Such as time complexity O(n^2),It means that the amount of data increases n Times, the time consumption increases n This is a higher time complexity than linearity. Bubble sorting, for example, is typical O(n^2)Algorithm, right n Number sorting, scanning required n×n Times. Arrange an array with bubble sorting, for n For an array of variables, the positions of variables need to be exchanged several times, so the complexity of the algorithm is O(). ③ O(logn)Resolution: such as O(logn),When the data increases n Times, the time consumption increases logn Times (here) log It is based on 2. For example, when the data is increased by 256 times, the time consumption is only increased by 8 times, which is lower than the linear time complexity),Binary search is O(logn)The algorithm eliminates half of the possibility every time it is found, and the target can be found as long as it is found 8 times in 256 data. ④ O(nlogn)Resolution: O(nlogn)Similarly, it is n multiply logn,When the data increases 256 times, the time consumption increases 256 times*8=2048 Times. This complexity is higher than linearity and lower than square. Merge sort is O(nlogn)Time complexity.
② Advantages and disadvantages
- Advantages: high efficiency, simple implementation and support sorting.
- Disadvantages: there are errors in the results; If precision is required, it needs to be screened again manually; In a large number of cases, the cache needs to be decoupled. If it is a cluster environment, the cache key should not be too large, otherwise there will be problems in cluster migration; Therefore, for redis, the cache should be carefully decoupled and split into multiple small keys
③ Code implementation
/**
* @desc You can add multiple user geographical locations. You can test and modify the methods
* @param int $user_id
* @param int $latitude
* @param int $longitude
* @return int
*/
public function insert($user_id = 0, $latitude = 0, $longitude = 0)
{
$result = $this->redis->geoAdd($this->key, $longitude, $latitude, $user_id);
return $result;
}
/**
* @desc Search nearby result set
* @param int $distance
* @param int $latitude
* @param int $longitude
* @return mixed
*/
public function searchNearby($distance = 300, $latitude = 0, $longitude = 0)
{
$result = $this->redis->georadius(
$this->key,
$longitude,
$latitude,
$distance,
'mi',
['WITHDIST','count' => 10,'DESC']
);
return $result;
}
// Call get result set
$res = new GeoRedis();
var_dump($res->searchNearby(300, 21.306,-157.858));
array(2) {
[0]=>
array(2) {
[0]=>
string(4) "1001" //User id
[1]=>
string(8) "104.5615" //distance
}
[1]=>
array(2) {
[0]=>
string(4) "1002"
[1]=>
string(8) "104.5615"
}
}
So is there a small partner who asked: what can I do if I want to page? In fact, the answer has been given above. Use the "STOREDIST" in the geordiusbmember command to store the ordered data into a zset set. After paging, you can directly get the data from the zset set:
localhost:6379> zrange user:nearby 0 10 withscores 1) "1001" 2) "1184565520453603" 3) "1002" 4) "1184565520453603" 5) "1003" 6) "1231646528010636" 7) "1004" 8) "1231732998886639" 9) "1005" 10) "1235058932387089"
However, there are some deficiencies, that is, we can't query directly according to the filter criteria, but manually filter after the query is found; For example, we need to check the friends near the 18-year-old beautiful girl;
① Or store a copy of data according to the refinement of search conditions
② Or filter after query
Query of nearby people based on mongoDB
① Design ideas
At present, Amu has a similar live broadcast project, and the home page recommendation has the function of a nearby friend; It is based on MongoDB to realize the function of nearby friends. It is mainly through its two geospatial indexes 2d and 2dsphere, which are built based on geohash.
2dsphere index support: Star surface point, line, surface, multipoint, multiline, polygon and geometric set; Create 2dsphere index syntax:
-- Create index
db.coll.createIndex({'location':'2dsphere'})
-- Spatial query syntax
① Position intersection db.coll.map.find({'location':{'$geoIntersects':{'$geometry':area}})
② Location contains db.coll.map.find({'location':{'$within':{'$geometry':area}})
③ Position proximity db.coll.map.find({'location':{'$near':{'$geometry':area}})
2d index supports planar geometry and some spherical queries; Support spherical query, but not very friendly, more suitable for plane query; Create 2d index syntax:
-- Precision of index creation bits To specify, bits The larger the, the higher the precision of the index
db.coll.createIndex({'location':"2d"}, {"bits":30})
-- Query syntax
① Location contains db.coll.map.find({'location':{'$within':[[10,10],[20,20]]})
② Rectangular inclusion db.coll.map.find({'location':{'$within':{'$box':[[10,10],[20,20]]}})
③ Center contains db.coll.map.find({'location':{'$within':{'$center':[[20,20],5]}})
④ Polygon inclusion db.coll.map.find({'location':{'$within':{'$polygon':[[20,20],[10,10],[10,18],[13,21]]}})
⑤ Position proximity db.coll.map.find({'location':{'$near':[10,20]})
② Code implementation
1. Create a database and insert several pieces of data; collection is named user (equivalent to the table name in mysql). Three fields user_id, user id,user_name and location are longitude and latitude data.
db.user.insertMany([
{'user_id':1001, 'user_name':'Amu 1', loc:[122.431, 37.773]},
{'user_id':1002, 'user_name':'Amu 2', location:[157.858, 21.315]},
{'user_id':1003, 'user_name':'Amu 3', location:[155.331, 21.798]},
{'user_id':1004, 'user_name':'Amu 4', location:[157.331,22.798]},
{'user_id':1005, 'user_name':'Amu 5', location:[151.331, 25.798]},
{'user_id':1006, 'user_name':'Amu 6', location:[147.942428, 28.67652]},
])
2. Because we store data in the form of points on a two-dimensional plane, if we want to query LBS, we still choose to set the 2d index:
db.coll.createIndex({'location':"2d"}, {"bits":30})
3. Query according to your current coordinate longitude and latitude
db.user.aggregate({
$geoNear:{
near: [157.858, 21.306], // Current self coordinates
spherical: true, // Calculate spherical distance
distanceMultiplier: 6378137, // The radius of the earth, in meters, is 6378137 by default
maxDistance: 300/6378137, // Within 300m of filtering condition, radian is required
distanceField: "distance" // Distance field alias
}
})
4. Check whether there is qualified data in the result set. If there is data, the distance field name distance just set will be added, indicating the distance between two points:
//The current result set is a simulation result, because mongo is not installed in docker on the local computer
{ "_id" : ObjectId("4e96b3c91b8d4ce765381e58"), 'user_id':1001, 'user_name':'Amu 1', "location" : [ 122.431, 37.773 ], "distance" : 5.10295397457355 }
{ "_id" : ObjectId("4e96b5c91b8d4ce765381e51"), 'user_id':1002, 'user_name':'Amu 2', "location" : [ 157.858, 21.315 ], "distance" : 255.81213803417531 }
So here, do you know something about mongo storing longitude and latitude, and then querying people nearby to obtain the distance; In fact, the performance is still very good, but when the pressure is high, the mongo connection timeout will occur. We can make a cluster for mongo; Basically, it is relatively stable.
Realizing the query of nearby people based on es search engine
① Design ideas
In fact, most search engines like es/sphinx/solr can support querying people nearby because of their high efficiency, fast query speed and accurate result set; Therefore, it is recommended to use this.
GET api/query/search/
{
"query": {
"geo_distance": {
"distance": "1km",
"location": {
"lat": 21.306,
"lon": 157.858
}
}
}
}
The general process is as follows: ① the user requests to query the nearby friends; ② the server receives the request, and then requests the data of the upstream search engine group through api(http or rpc); ③ the search group obtains the request parameters, analyzes and queries the corresponding relationship chain; ④ returns it to the caller efficiently
Support paging query and query schemes with more conditions; Superior performance and pagination; Especially in the case of large amount of data, its performance is more friendly. This is how the company handled it before amu, similar to personalized recommendation; Search from millions of products through user preferences. The whole process is the server requesting the search group interface. The search groups are basically Java developers. sorl searches the elastic search engine excessively, and uses k8s to deploy es clusters; good!!!
Warehouse code address: https://github.com/woshiamu/amu/tree/master/redis
🐣 summary
Wow, I'm very convinced to see the little friends here. I spent three days thinking about painting and conceiving the written articles; To be honest, writing this article is very stressful; First, the underlying algorithm principle, and then need to be verified by practice. The network is full of copies, so I want to take a different route; Since everyone has read so many articles related to geohash, the principles and algorithms should be ok; If I go to talk and write again, wouldn't it be a bit self humiliating; So I decided to think about a problem from different angles; And the thinking it triggered.
This paper mainly combines practical projects and past experience through practice; Show the use of geohash in different scenarios, how to choose between large and small quantities, etc? When sorting out the articles, I also analyze the questions that the boys will encounter. It is estimated that many articles do not have these questions, because they are all the same. What a mu wants to do is to simplify and complicate. He who can practice with his hands will never just watch but not practice!
Motto: no matter what you do, as long as you stick to it, you will see the difference!
Finally, welcome to my official account, "I am ammu", and will update the knowledge and learning notes from time to time. I also welcome direct official account or personal mail or email to contact me. We can learn together and make progress together.
Well, I'm a mu, a migrant worker who doesn't want to be eliminated at the age of 30 ⛽ ️ ⛽ ️ ⛽ ️ . It's not easy to think that the words written by "a Mu" are a little material: 👍 Pay attention, 💖 Share it. I'll see you next time.