This article is only for technical learning. Welcome to reprint it. Please indicate the source
Because my friend needs scenic spot data to participate in mathematical modeling, and I just know a little, so I helped him write crawler code. Some crawler methods were found on the Internet, but when obtaining the scenic spot ID, it was found that Ctrip's Request Payload parameter has changed, resulting in some original parameters, such as page turning request Fetch and scenic spot ID:viewid, which are no longer available. After analysis, it was found that poiID was used as a new parameter, so I wrote the crawler again for the new interface parameter, At the same time, it summarizes the page turning data realized by ajax. If there is any error, please forgive and point out!
PS: the original interface parameters of Ctrip can still be used normally or crawled normally. Just can't find those excuse parameters
If anyone knows the reason, or find a way to viewid, please don't hesitate to comment
Analysis process
The preface mentioned that Ctrip's Request Payload parameter has changed, so it is necessary to re analyze the interface parameters and return results.
Here is a brief mention of why you need to obtain comment data through the interface:
There are two ways to jump the number of pages
Because there are too many comments, all web pages are mostly displayed in the form of pages, and users can jump by clicking the corresponding number of pages
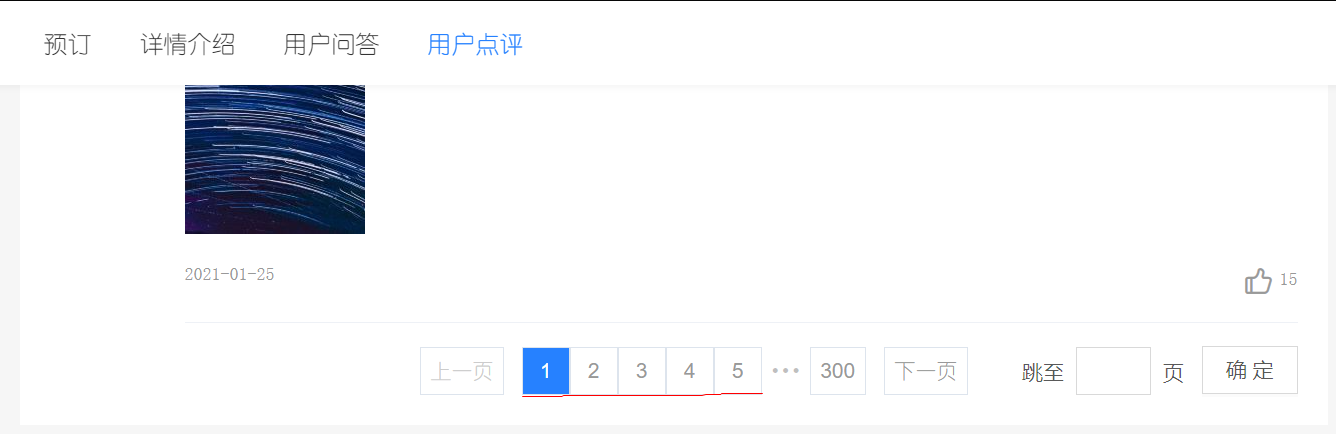
At present, there are two ways to realize the number of jump pages:
The first is through website parameters, such as Douban. This is the common way of crawling Douban movie top250.
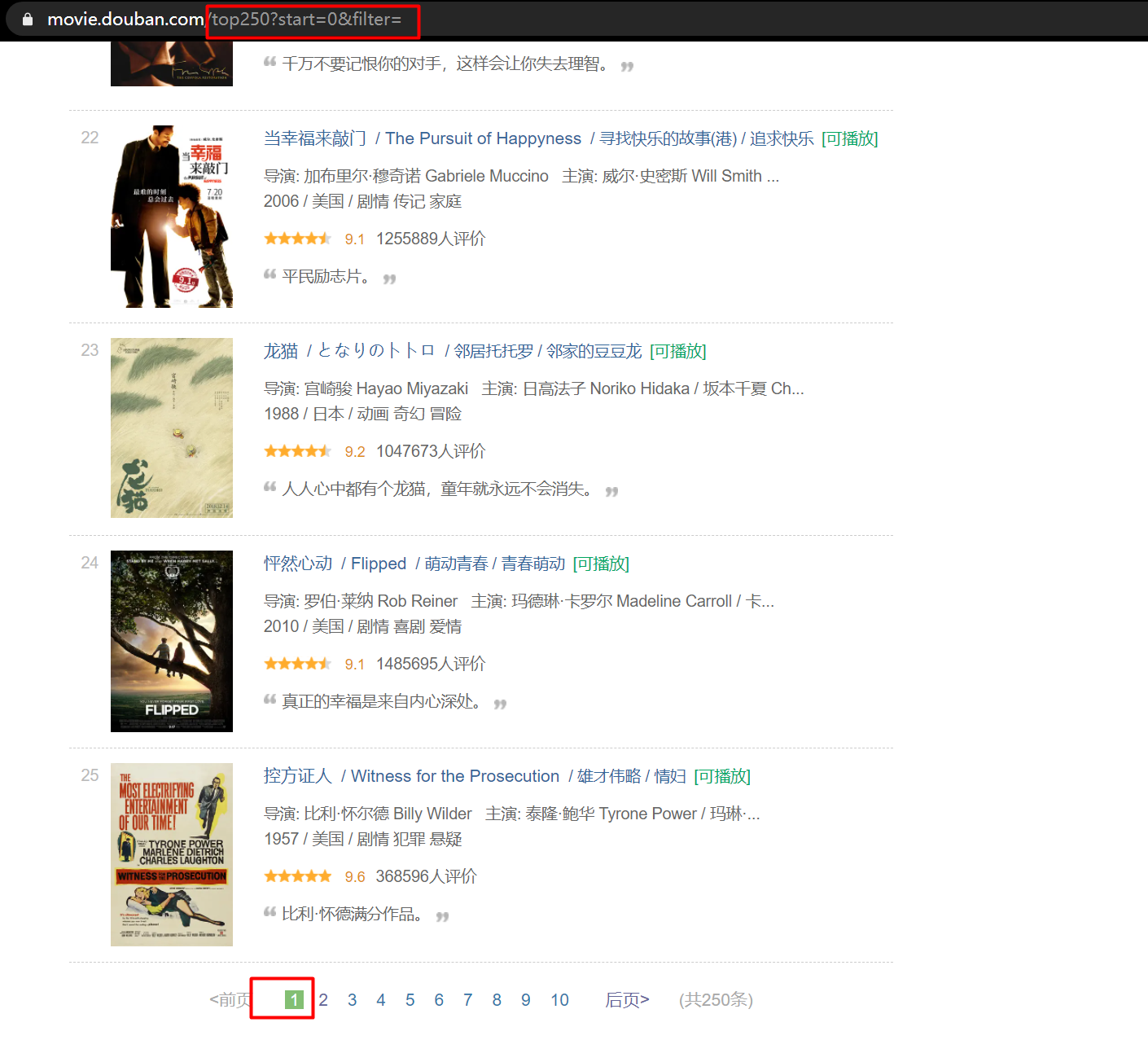
We enter https://movie.douban.com/top250 , view page data.
first page:
Page 2:
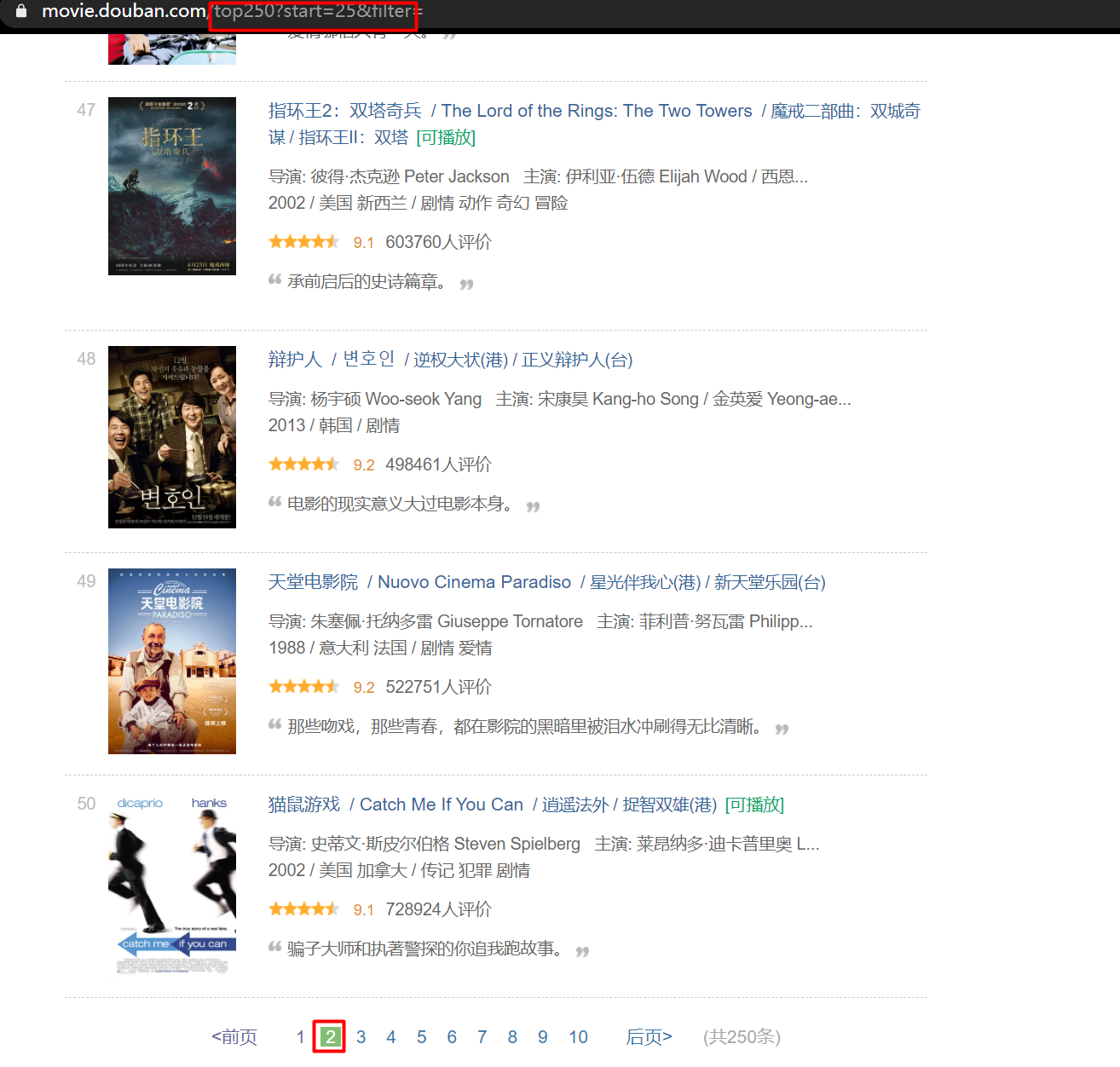
It can be seen that this page jumps to different pages through the change of the URL parameter "start =".
It is easy to get the data when the number of pages is different.
The second is Ctrip, which dynamically loads comment data through ajax technology
first page:
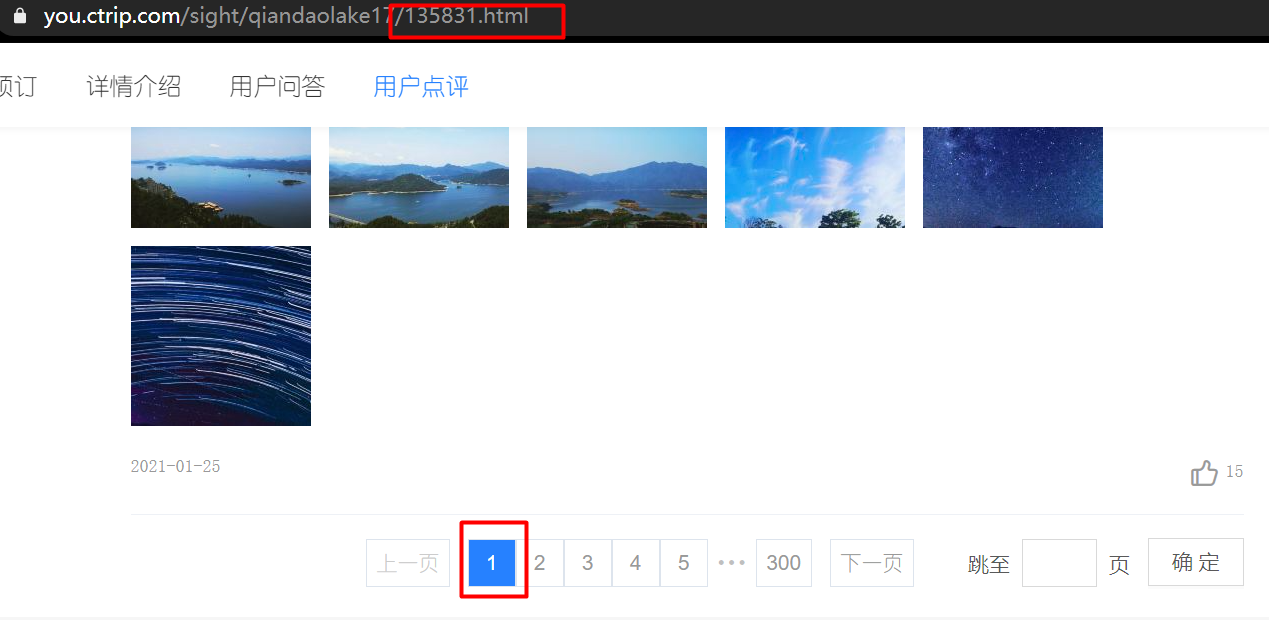
Page 2:
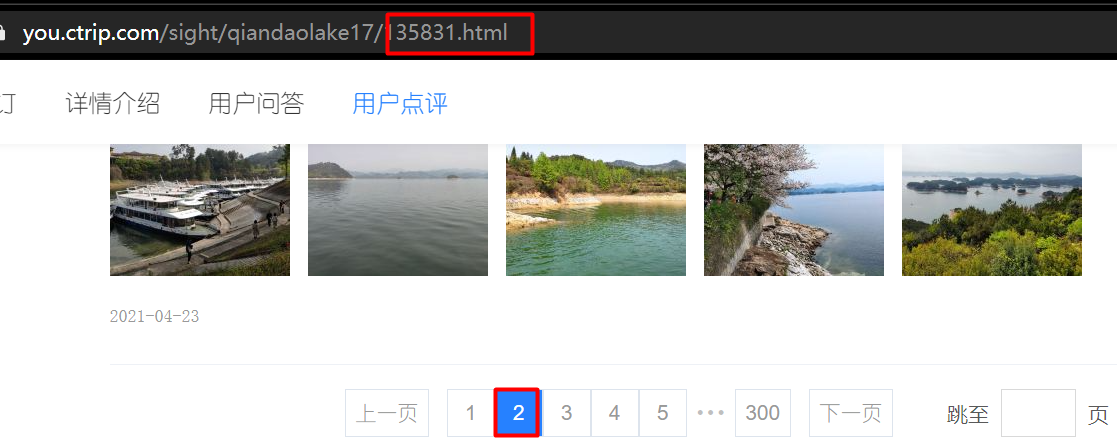
You can see that the website has not changed, but the data has been loaded in.
For this method, we need to check its calling interface and use fixed parameters to obtain the return data, which is relatively more difficult to obtain.
To get back to business, this paper will not repeat the above two methods, but only analyze the comment data of Ctrip scenic spots
Analysis comment data request interface
We press' F12 'on the Ctrip scenic spot review page to enter the element detection, and click' Network 'to view the Network resources. Because what we need is the request data when the number of comment pages changes. In order to prevent other data interference, we first clear all the data, and then click the second page to load the data. We can see that all Network request resources are sniffed at this time. When the data no longer changes, stop listening, and you will see all the data on the second page of the request for comment.
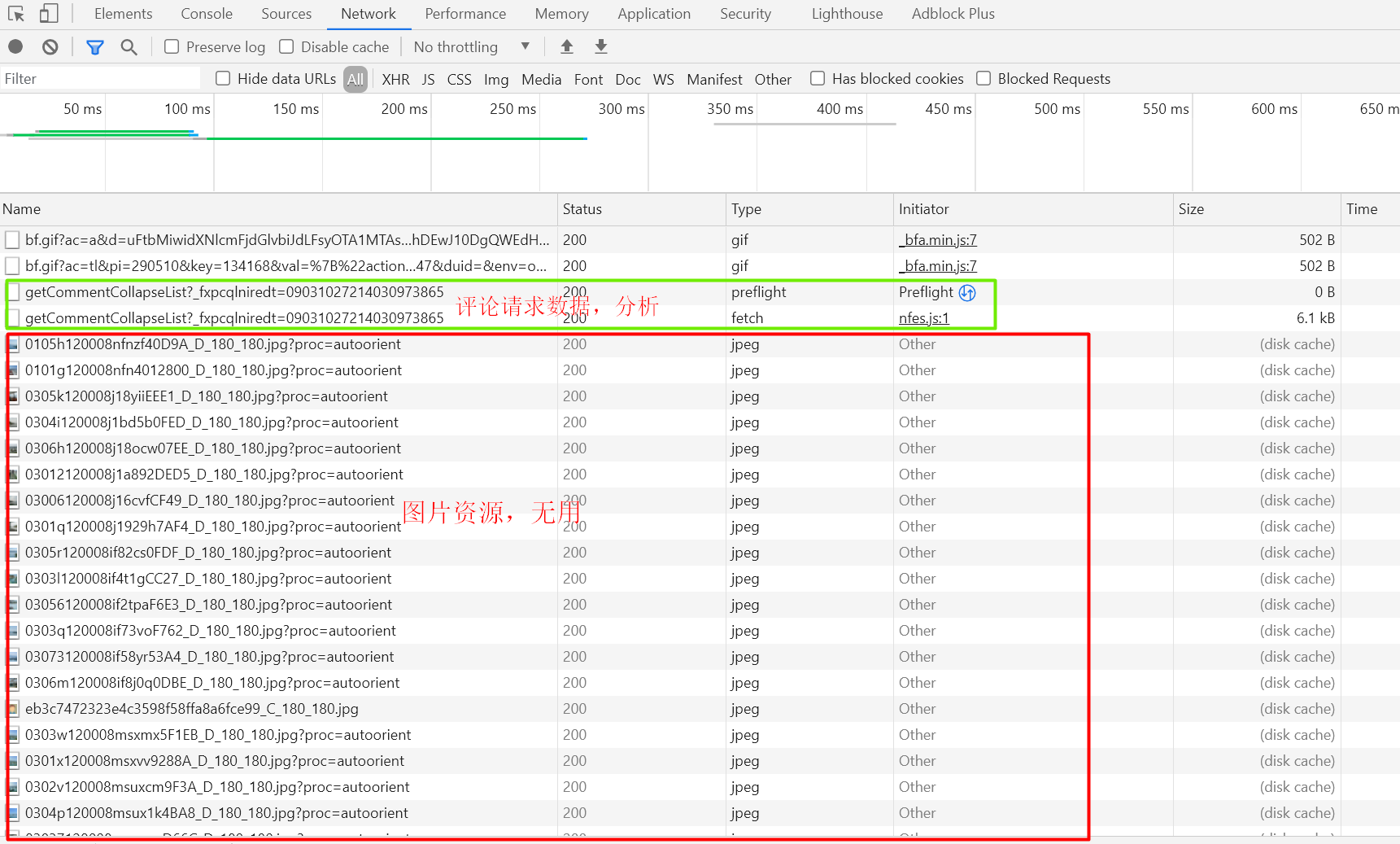
As can be seen from the figure, some of these data are image resources, because what we need is user comment data, so don't worry. The other two files are comment request data. You can also judge the processing from the file name: getCommentCollapseList.
Let's look at the file Type. One is preflight request. This is to ensure data security. You can understand it in detail This article (invasion and deletion)
The other is our protagonist, Fetch API. We can click this file to view the contents in headers
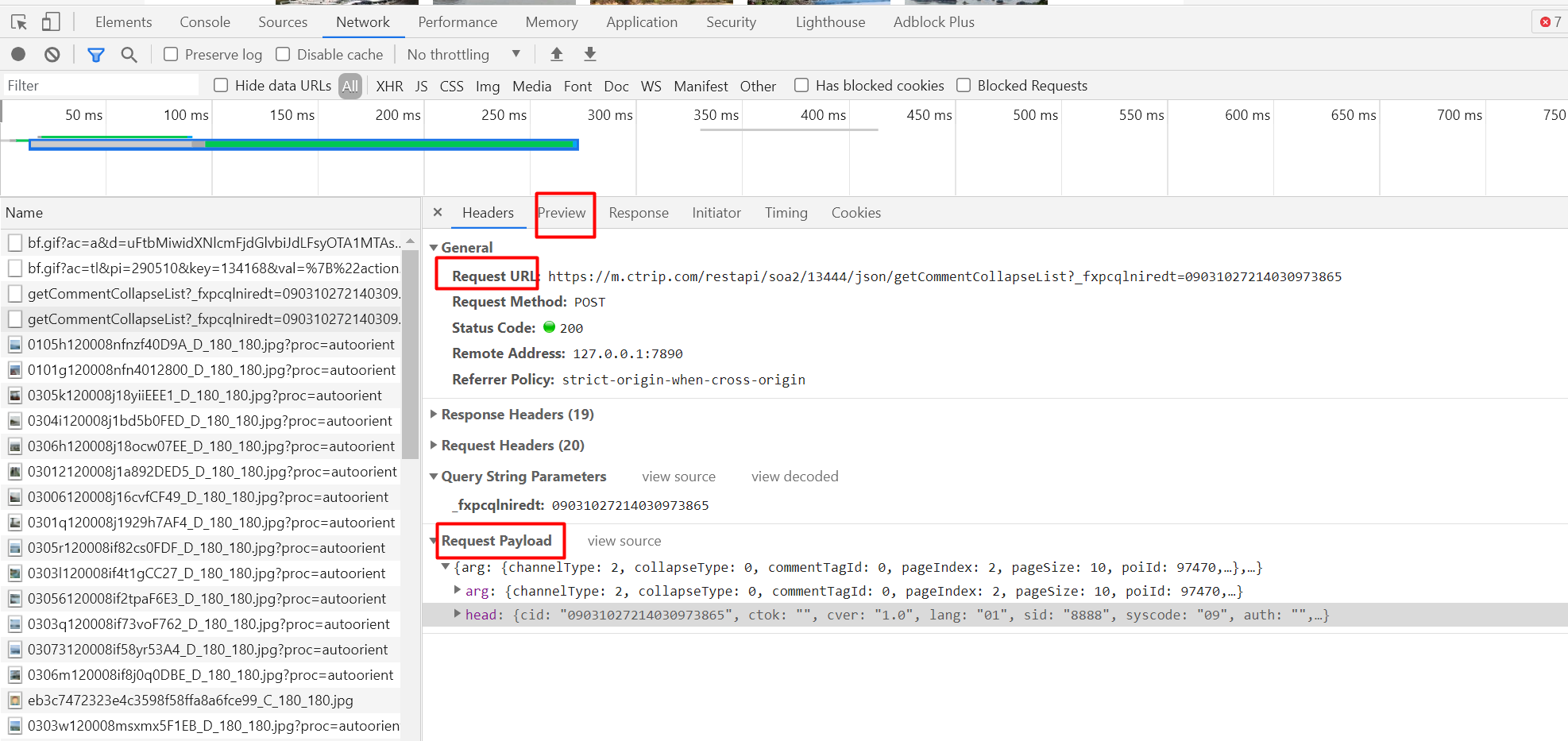
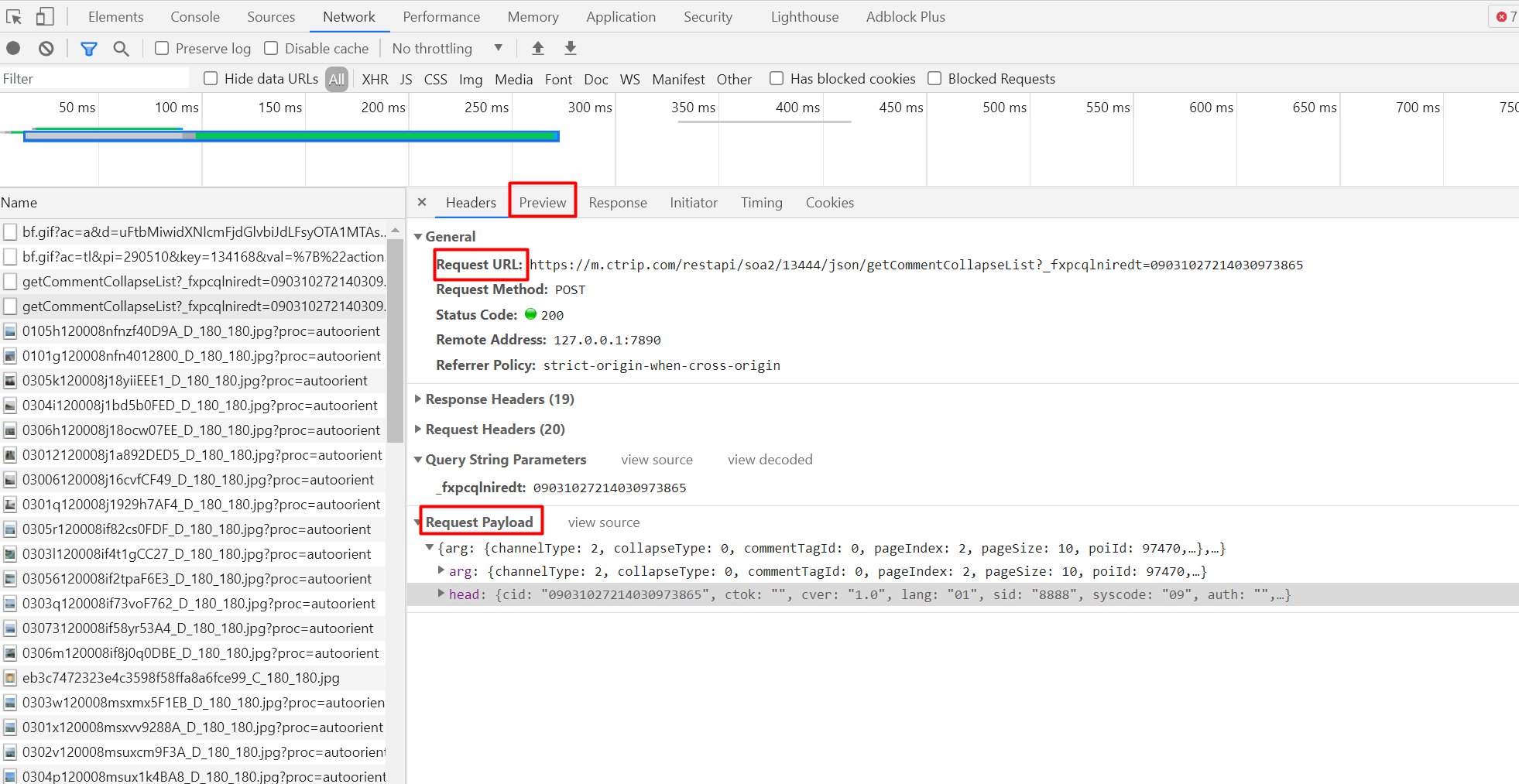
Among these, we need to pay attention to Request URL: and Request Payload
Request URL:https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList
It can be inferred that this is the address of the request and the general interface URL. The comment information is obtained through this URL
Request Payload, this is a request method. We only need to pay attention to its specific parameters and take it out
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":2,
"pageSize":10,
"poiId":97470,
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
We can see that this is a JSON format, but we don't know the specific meaning of each parameter. Don't worry at this time. There is a simple method, that is, open a new scenic spot first, obtain these parameters in the same way, and determine the changed parameters through a simple comparison method. This parameter is likely to be the difference between different scenic spots.
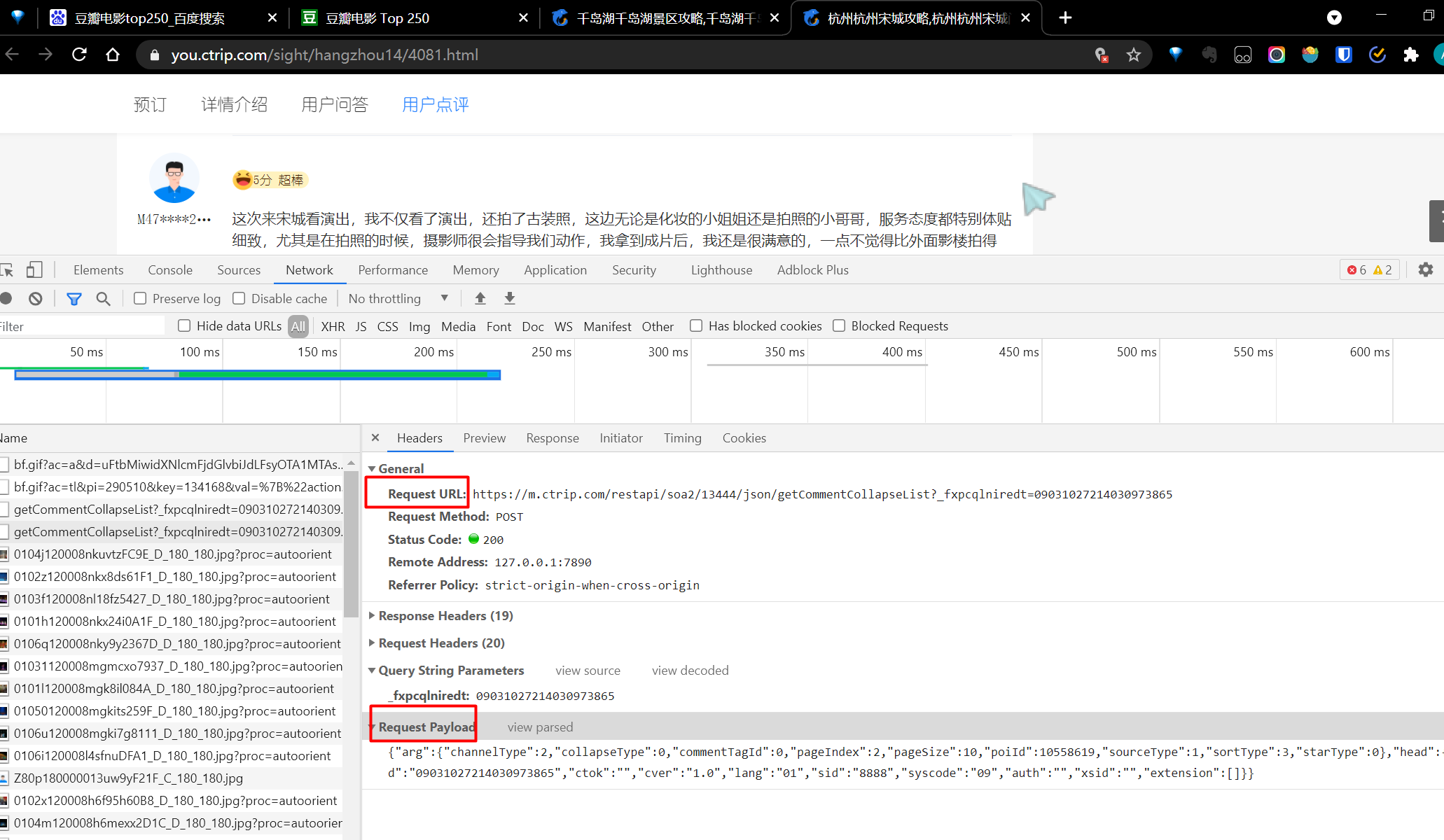
We reopen the "Song Cheng" web page and follow the same pattern to view the request parameters.
You can see that the Request URL remains unchanged, which confirms our previous guess.
Then take out the Request Payload
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":2,
"pageSize":10,
"poiId":10558619,
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
It can be seen that there is no change except the poiID parameter, so it is determined
All comment information is obtained through the same address, and poiID is the ID of different scenic spots
So far, the request interface analysis of ajax is completed
PS: there is another parameter in "Arg": pageIndex, which means literally. We can also determine that it is the subscript of the number of pages. Clicking on different pages will change it accordingly. This parameter will be used in the code we write later.
Analyze comments and return data
On the Fetch parameter page just now, this time we click Preview. Here is the data returned after the request is successful. We can view the specific data returned here to directly obtain the corresponding value when writing code later.
It also returns data in JSON format. We can see that there are 10 lists in the items under result, and we click one of them

The positive Lord finally appeared, and the content is the comment information. We also determine the path of the return value: result - > items - > n] - > content
But with this path, can we start writing code?
Not yet. Because we still haven't found a key value, that is, how many comments are there in total.
Only when we know this can we start writing code. We can speculate that this information will certainly be included in the obtained data. Otherwise, how many items are displayed on the page and how many pages are determined?
If we continue to look, we can find a parameter: totalCount: total quantity
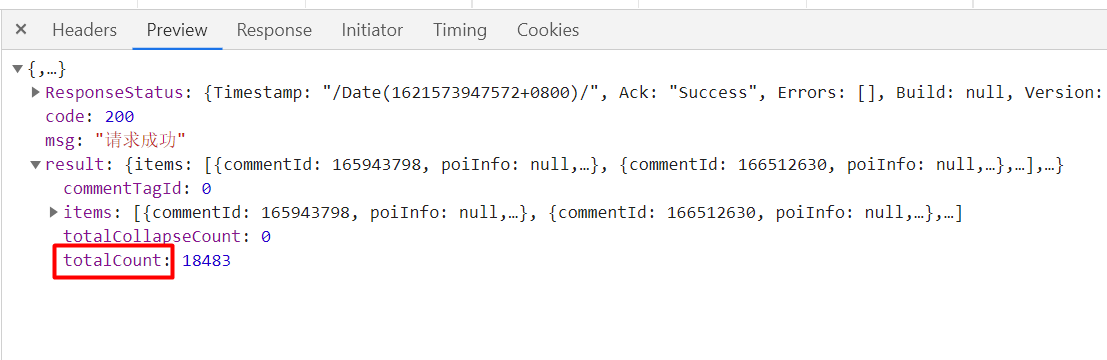
For verification, we return to the page,

Not bad. Now you can finally start writing code
Source code disassembly
Write the scenic spot information to be crawled into the array
postUrl="https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList"
# Add poiId and name of attraction here
urls = [
['97470','Qiandao Lake']
]
We define a variable to store the URL that needs to be crawled.
Then create an array and add the ID and name of the scenic spot to be crawled
Modify the request parameters according to the array to make the first request
for id in urls:
print("Climbing scenic spots:", id[1])
data_pre={
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":1,
"pageSize":10,
"poiId":id[0],
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
}
html=requests.post(postUrl,data=json.dumps(data_pre)).text
html=json.loads(html)
According to the above analysis, the corresponding parameters are required when requesting the interface. We take out the previously obtained Request Payload parameter and make it into a JSON file, replace the value of "poiID" (scenic spot ID) in it with the variable obtained from the scenic spot array, and then add the request address and parameters through the post function in the requests module to make a request. And load the obtained data in JSON format.
Determine the total number of comment pages
# Determine total pages total pages
total_page = int(html['result']['totalCount']) / 9
if total_page > 200:
total_page = 200
# Traversal query comments
print("PageCount :", total_page, "Crawling")
According to the "totalCount" path obtained from the analysis, we take out the value of the total number of comments. When analyzing and obtaining the data, we find that there are only ten pieces of data per page, and the "pageIndex" parameter in the request parameter will also change according to the change of the number of pages. Therefore, we calculate the total number of pages through simple calculation and ensure that the number of pages does not exceed 200 pages, that is, 2000 pieces of data. (required on demand)
Create and write csv files
# Create and write csv files path = str(id[1]) + '.csv' xuhao = 0 with open(path, 'w', newline='', encoding='utf-8') as f: file = csv.writer(f) file.writerow(['Serial number', 'scenic spot ID', 'Name of scenic spot', 'comment'])
Take the scenic spot name as the file name, create a csv file for each scenic spot, save the comment data, and use utf-8 coding
By looping through the number of pages, crawl the comment data and save it
for page in range(1, total_page+1):
data={
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":page,
"pageSize":10,
"poiId":id[0],
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
}
html=requests.post(postUrl,data=json.dumps(data)).text
html=json.loads(html)
# Get comments
for j in range(0,9):
result = html['result']['items'][j]['content']
file.writerow([xuhao, id[0], id[1], result])
xuhao += 1
Get the number of comments from the "page scv" variable and write it into the "page scv" variable for analysis.
At this point, the coding is complete. The source code is posted below for easy viewing.
Source sharing
import requests
import json
import csv
postUrl="https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList"
# Add poiId and name of attraction here
urls = [
['97470','Qiandao Lake']
]
for id in urls:
print("Climbing scenic spots:", id[1])
# Judge the total number of comments through the return value. There are 9 comments per page, and calculate the total number of pages. For data greater than 2000, only 2000 comments are crawled
data_pre={
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":1,
"pageSize":10,
"poiId":id[0],
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
}
html=requests.post(postUrl,data=json.dumps(data_pre)).text
html=json.loads(html)
# Determine total pages total pages
total_page = int(html['result']['totalCount']) / 9
if total_page > 222:
total_page = 222
# Traversal query comments
print("PageCount :", total_page, "Crawling")
# Create and write csv files
path = str(id[1]) + '.csv'
xuhao = 0
with open(path, 'w', newline='', encoding='utf-8') as f:
file = csv.writer(f)
file.writerow(['Serial number', 'scenic spot ID', 'Name of scenic spot', 'comment'])
for page in range(1, total_page+1):
data={
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":page,
"pageSize":10,
"poiId":id[0],
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
}
html=requests.post(postUrl,data=json.dumps(data)).text
html=json.loads(html)
# Get comments
for j in range(1,10):
result = html['result']['items'][j]['content']
file.writerow([xuhao, id[0], id[1], result])
xuhao += 1
print(id[1], "Crawling completed")