Topic modeling can help developers intuitively understand and explore data, so as to better mine topics in corpus. Successful topic modeling requires multiple iterations: cleaning the data, reading the results, adjusting the preprocessing accordingly, and trying again. This paper analyzes the theme of the New Year greetings of national leaders from 2014 to 2021, preprocesses the text data, establishes the theme model, model verification, model visualization and other operations, and finally summarizes the information obtained from the theme model. The specific implementation process is as follows:
1. Data preprocessing
The text data in this paper is the New Year greetings of national leaders from 2014 to 2021. The os module is used to read the data in batches and replace the line breaks and spaces in the text data. Then, in addition to the self-contained stop word list of spaCy, two more stop words "year" and "country" are added, (when modeling for the first time, we directly use the stop word list provided by spaCy. Through the results, it is found that the two keywords "year" and "country" appear many times in the text, but the two words themselves have little significance for the text analysis, so they are added to the user-defined stop word list.) Then deal with the stop words. The code is as follows:
data = []
for file in files:
for i in open(file,"r",encoding="utf-8"):
text = i.replace('\n','').replace('\u3000','')
data.append(text)
stopwords = ('year', 'country')
nlp=spacy.load('zh_core_web_sm')
#participle
texts=[]
for document in data:
doc = nlp(document)
text = []
for w in doc:
if not w.is_stop and not w.is_punct and not w.like_num:
text.append(w.text)
for stopword in stopwords:
w = nlp.vocab[stopword]
w.is_stop = True
texts.append(text)After preprocessing the data above, you can start to establish LDA subject model.
2. Establish topic model and verify
After the above word segmentation, each word is encoded by corpora to construct a dictionary. Then, based on the dictionary, the words are changed into sparse vectors, and the vectors are put into the list to form a sparse vector set. Finally, the LDA topic model is established through the models module for topic inference. The code is as follows:
#Construction dictionary
dictionary = corpora.Dictionary(texts)
# Based on the dictionary, make [word] → [sparse vector], and put the vector into the list to form [sparse vector set]
corpus = [dictionary.doc2bow(text) for text in texts]
# lda model, num_topics sets the number of topics
print("corpus:",corpus)
lda = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=2)
# Print all topics with 4 words per topic
for topic in lda.print_topics(num_words=4):
print(topic)
# Topic inference
print("Topic inference:",lda.inference(corpus)) ##Document distributionThe printing results of each step are as follows:
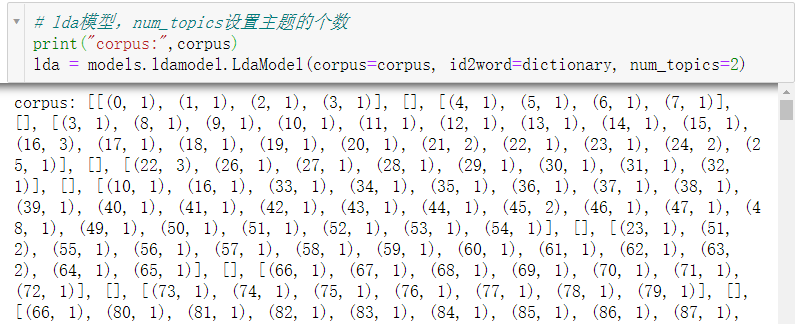
Subject printing:
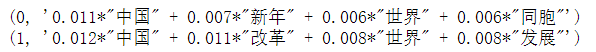
Topic inference:
In addition, in addition to establishing LDA subject model, this paper also establishes LDA, LSI and HDP models through gensim module for comparison. The code is as follows:
from gensim.models.coherencemodel import CoherenceModel ##Model building lda1 = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=2) lsi1 = models.lsimodel.LsiModel(corpus=corpus, id2word=dictionary, num_topics=2) hdp1 = models.hdpmodel.HdpModel(corpus=corpus, id2word=dictionary) ##Comparison model #print(corpus) lda_coherence = CoherenceModel(model = lda1, texts=texts, dictionary=dictionary, coherence='c_v') lsi_coherence = CoherenceModel(model = lsi1, texts=texts, dictionary=dictionary, coherence='c_v') hdp_coherence = CoherenceModel(model = hdp1, texts=texts, dictionary=dictionary, coherence='c_v') ##Output comparison results print(lda_coherence.get_coherence()) print(lsi_coherence.get_coherence()) print(hdp_coherence.get_coherence())
The output results are as follows:

It can be seen from the above results that the score of HDP model is the highest, while the result of LDA is not ideal, which proves that the consistency of subject model is not high, which is also the place that needs to be improved in the later stage.
Cross verify them and select the value with the greatest consistency (both positive and negative values are meaningful) to select the number of topics. The code is as follows:
c_v = []
for num_topics in range(1, 19):
lm = models.ldamodel.LdaModel(corpus=corpus, num_topics=num_topics, id2word=dictionary)
cm = CoherenceModel(model=lm, texts=texts, dictionary=dictionary,coherence='c_v')
c_v.append(cm.get_coherence())
print(c_v)The output results are as follows:

3. Model visualization
Finally, the model can be visualized through the pyLDAvis module, but due to the version problem, the visualization can no longer be displayed in the notebook (the problem has not been solved). Put the code here first:
import pyLDAvis.gensim data = pyLDAvis.gensim.prepare(lda, corpus, dictionary) #data = pyLDAvis.sklearn.prepare(lda_model, doc_term_matrix, vectorizer) #Enables visualization to be displayed in the notebook pyLDAvis.display(data)
4. Conclusion
It can be seen from the above theme inference and other relevant results that in the Spring Festival greetings from 2013 to 2021, the themes of national leaders are the Spring Festival blessings to the people of the whole country, as well as the achievements and future development direction of the national government's reform in the past year. In addition, the leaders also extended their most sincere greetings and best wishes to the compatriots in Taiwan, Hong Kong and Macao every year. At the same time, it summarizes China's influence in the world, from which we can see that China's world status is gradually rising, and building a community with a shared future for mankind is also one of China's expectations in recent years.