Complex multi table query -- Taking supermarket transaction data as an example
The previous content is basically based on the query operation of single table, but in practical work, the data is often scattered in multiple tables. At this time, we need to use the knowledge of multi table query.
Generally speaking, there are two main types of multi table queries: one is vertical table merging, that is, splicing tables with the same structure up and down; The other is horizontal table connection, which combines the fields in multiple tables into a large table.
(1) Vertical table consolidation
Vertical table merging is very easy to understand, that is, merging multiple tables with the same structure in a vertical direction. A straightforward understanding is stacking up and down (that is, adding records). Let's take the operation data of a supermarket as an example to learn about vertical table consolidation.
Suppose there is a large supermarket chain with many franchise stores. Each franchise store stores the operation data of different months in their own data table. The data of each store is stored in the same way, that is, the fields are the same: store ID, user ID (if there is no processing member, the user ID is blank), order ID, transaction date, payable amount, discount amount, paid in amount and payment type.
The current demand is to merge the transaction records of supermarkets A, B and C into one table.
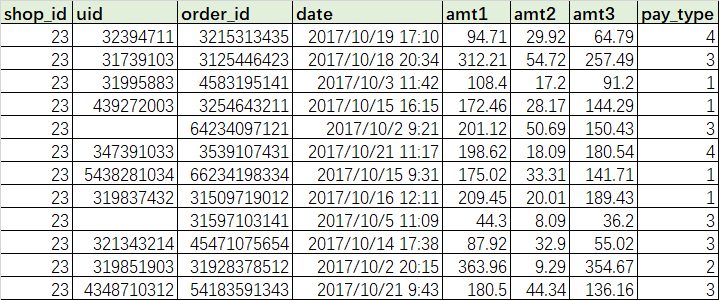
The vertical consolidation table needs to use the keyword UNION or UNION ALL. The functions of these two keywords are the same (both are consolidation operations), but there are still great differences:
- UNION ALL does not do any additional actions when merging tables, but simply connects multiple tables head to tail;
- When the UNION merges tables, there will be an additional action besides splicing - de duplication (the old version also has the sorting function, and the new version discards the sorting function)
In terms of performance, the merging speed of UNION ALL is much faster than that of UNION. Especially when the amount of data is large, the difference between the merging speed of UNION ALL and UNION ALL is very obvious. Therefore, when doing vertical table consolidation, we must consider whether to reprocess.
# The difference between UNION and UNION ALL SELECT pay_type FROM TransC1805 UNION ALL SELECT pay_type FROM transD1810; SELECT pay_type FROM TransC1805 UNION SELECT pay_type FROM transD1810;
Next, try to use UNION ALL to merge three transaction tables into one table:
SELECT * from TransA1710 UNION ALL SELECT * from TransB1801 UNION ALL SELECT * FROM TransC1805;
When the number and order of fields in the table to be merged are the same, there is no problem with this writing. If the structure of one of the tables is inconsistent (including quantity and arrangement order), there will be a problem in writing. For example, there is the transaction data of supermarket D in October 2018, but the field order has been adjusted when the store records the data:
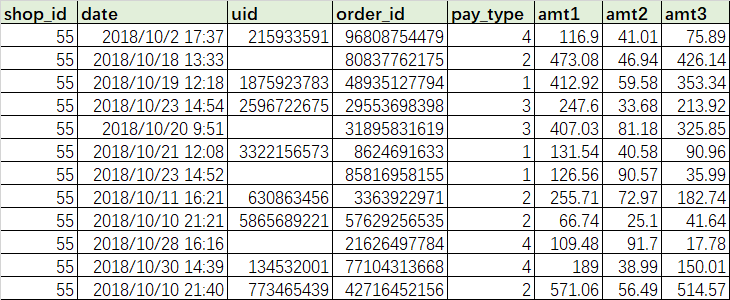
# If you merge in the above way, the result will be problematic: it will be spliced directly in a disordered order SELECT * FROM TransC1805 UNION ALL SELECT * FROM transD1810; # Correct writing SELECT * FROM TransC1805 UNION ALL SELECT shop_id,uid,order_id,date,amt1,amt2,amt3,pay_type FROM transD1810; SELECT shop_id,uid,order_id,idate,amt1,amt2,amt3,pay_type FROM TransC1805 UNION ALL SELECT shop_id,uid,order_id,date,amt1,amt2,amt3,pay_type FROM transD1810;
When the field order of the table to be merged is inconsistent, manually write out all the required fields and ensure that the order is consistent.
Sometimes we don't need to merge all records and fields in the table. At this time, we can use UNION ALL more flexibly. For example, we can merge the transactions whose payment method is cash (pay_type=1) in the three tables, and keep the store ID, user ID, transaction order number, transaction time and actual transaction amount information.
# Merge the transactions in the three tables whose payment method is cash (pay_type=1), and keep the store ID, user ID, transaction order number, transaction time and actual transaction amount information. SELECT shop_id,uid,order_id,idate,amt3 from TransA1710 where pay_type=1 UNION ALL SELECT shop_id,uid,order_id,idate,amt3 from TransB1801 where pay_type=1 UNION ALL SELECT shop_id,uid,order_id,idate,amt3 FROM TransC1805 where pay_type=1;
(2) Table join operation
The table JOIN operation is a little complicated. Various JOIN operations will be used here, which is easy to confuse for beginners. Let's learn about the JOIN operation through two simple data sets:
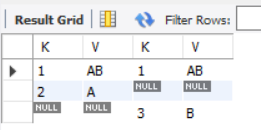
CREATE TABLE TA(K INT, V VARCHAR(10)); INSERT INTO TA VALUES (1,"AB"), (2,"A"); SELECT * FROM TA; CREATE TABLE TB(K INT, V VARCHAR(10)); INSERT INTO TB VALUES (1,"AB"), (3,"B"); SELECT * FROM TB;
Records of K=1 are found in both TA and TB tables. Records of K=2 are unique to ta table and records of K=3 are unique to TB table.
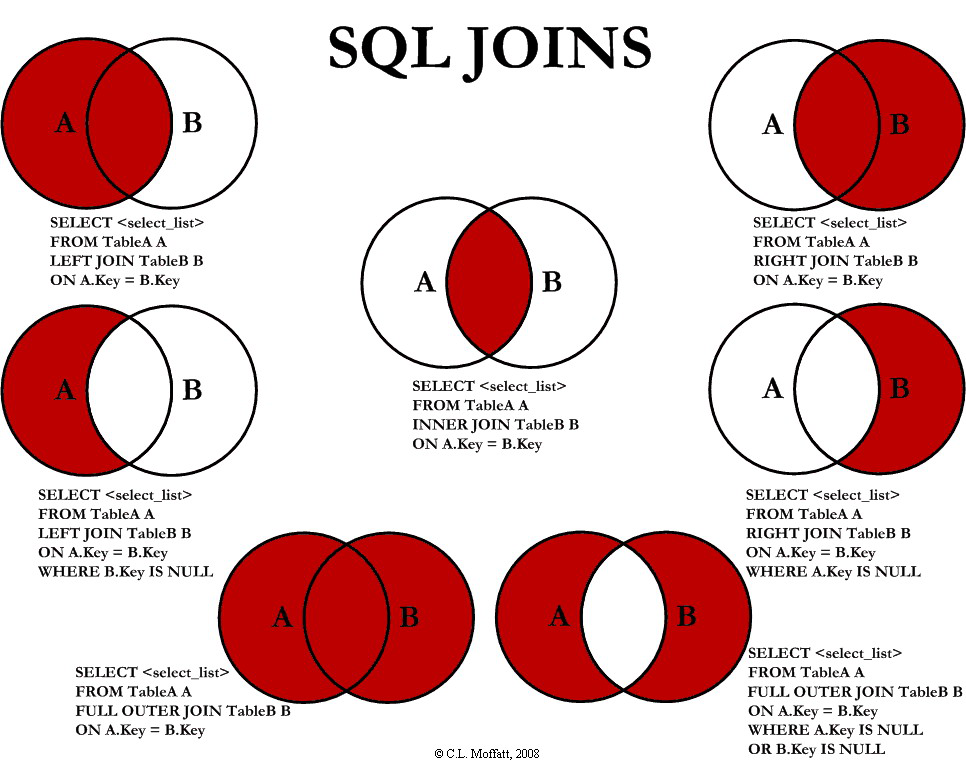
- INNER JOIN
Inner join is to extract the data shared by two tables.
Venn's diagram:
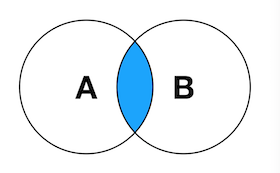
#Inner connection SELECT TA.K AS A_K,TB.K AS B_K,TA.V AS A_V,TB.V AS B_V FROM TA INNER JOIN TB ON TA.K=TB.K;

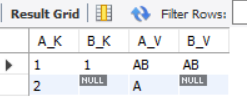
- LEFT JOIN: LEFT JOIN
The left join query will return all records in the left table (TA), regardless of whether there is associated data in the right table. If there is associated data in the right table, it will be returned together (fields not in the right table will be filled with NULL values).
Venn's diagram:
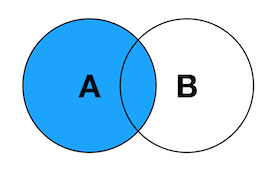
#Left connection SELECT TA.K AS A_K,TB.K AS B_K,TA.V AS A_V,TB.V AS B_V FROM TA #Left table LEFT JOIN TB #Right table ON TA.K=TB.K;
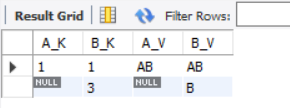
- Right connection:
The right join query will return all records in the right table (TB), regardless of whether there is associated data in the left table. If there is associated data in the left table
The data will be returned together (if there is no field in the left table, it will be filled with NULL value)
Venn's diagram:
#Right connection SELECT TA.K AS A_K,TB.K AS B_K,TA.V AS A_V,TB.V AS B_V FROM TA RIGHT JOIN TB ON TA.K=TB.K;
- FULL OUTER JOIN
FULL OUTER JOIN is generally called FULL JOIN or outer join. In actual query statements, FULL OUTER JOIN or FULL JOIN can be written. After the left and right records are connected, the left and right records can be returned
return.
Venn's diagram: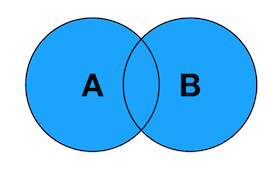
# FULL OUTER JOIN is not supported in MySQL. If it is used directly, an error will be reported SELECT TA.K AS A_K,TB.K AS B_K,TA.V AS A_V,TB.V AS B_V FROM TA FULL OUTER JOIN TB ON TA.K=TB.K; # You can use UNION to simulate the results returned by a full connection SELECT TA.K AS A_K,TB.K AS B_K,TA.V AS A_V,TB.V AS B_V FROM TA LEFT JOIN TB ON TA.K=TB.K UNION SELECT TA.K AS A_K,TB.K AS B_K,TA.V AS A_V,TB.V AS B_V FROM TA RIGHT JOIN TB ON TA.K=TB.K;
These are the four common table connection methods in SQL. In addition, there are three extended usages. If you are interested, you can study them by yourself.
(3) Comprehensive case -- connection operation of Campus All-in-one Card data table
Let's learn about the table join operation of SQL through a comprehensive case. The data used here is the flow record of Campus All-in-one Card. The data comes from DC competition network. This data set consists of two parts: Students' book borrowing records (including 239947 data) and consumption records (including data).
- Import dataset into MySQL
# Create student book borrowing record form CREATE TABLE stu_borrow (stu_id VARCHAR(10), borrow_date DATE, book_title VARCHAR(500), book_number VARCHAR(50) ); # Import book borrowing data LOAD DATA local INFILE "/Users/zhucan/Desktop/borrow.csv" INTO TABLE stu_borrow FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n'; # Create a student's all-in-one card consumption table CREATE TABLE stu_card( stu_id VARCHAR(10), custom_class VARCHAR(10), custom_add VARCHAR(20), custom_type VARCHAR(20), custom_date DATETIME, amt FLOAT, balance FLOAT ); # Import consumption data LOAD DATA local INFILE '/Users/zhucan/Desktop/card.txt' INTO TABLE stu_card111 FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
- Simple data exploration
After all the data is imported into MySQL, you need to explore the data and understand the current situation of the data:
# Query a student's borrowing record SELECT * FROM stu_borrow WHERE stu_id = '9708' ORDER BY borrow_date;

From the returned results, there are duplicate records in the book borrowing record table. According to the actual business situation, such data should not appear, so it needs to be reprocessed in the subsequent data processing.
# Query a student's consumption record SELECT * FROM stu_card WHERE stu_id = '1040' ORDER BY custom_date;
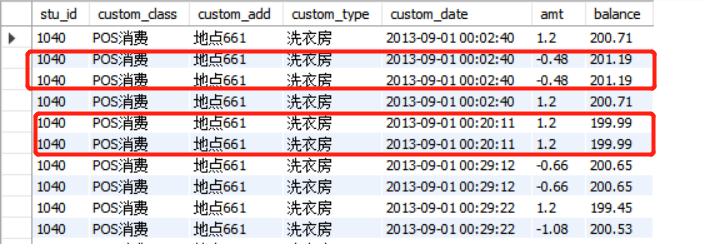
Similarly, for consumption records, there are duplicate values, and subsequent data processing requires de duplication. In addition, the consumption amount also has a complex number. Here we understand it as recharge behavior (because negative consumption amount will increase the balance).
- data processing
Since there are duplicate values in both tables, we first make a statistical summary of the data set to ensure that there is only one record corresponding to each student. For students, the analysis is generally based on the school year, so we choose September 2014 to September 2015 as the statistical window period.
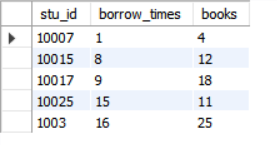
# Count the number of books borrowed and the number of books borrowed by each student from September 2014 to September 2015, and form a new table based on the statistical results CREATE TABLE borrow_times AS SELECT stu_id ,COUNT(DISTINCT borrow_date) AS borrow_times ,COUNT(DISTINCT book_title) AS books FROM stu_borrow WHERE borrow_date BETWEEN '2014-09-01' AND '2015-08-31' GROUP BY stu_id; # View the first 5 rows of statistical results SELECT * FROM borrow_times LIMIT 5;
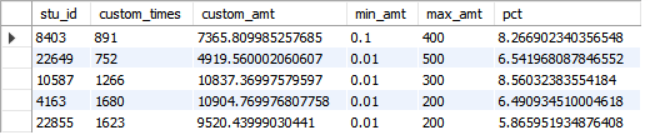
# Delete stu_ Duplicate records and records with negative consumption amount in the card table, and the cleaning results are directly stored in stu_card_ In the distinct table CREATE TABLE stu_card_distinct AS SELECT DISTINCT * FROM stu_card WHERE amt>0; # If the operation reports an error: Error Code: 1206. The total number of locks exceeds the lock table size # It indicates that the cache memory is insufficient (8M by default), and it needs to be set larger (for example, 64M = 64*1024*1024 = 67108864 B) show variables like "%_buffer_pool_size%"; SET GLOBAL innodb_buffer_pool_size=67108864; # Make statistics on the total consumption, minimum amount, maximum amount and customer unit price of each student from September 2014 to September 2015, and store the statistical results directly in the custom table CREATE TABLE custom AS SELECT stu_id ,COUNT(*) AS custom_times , SUM(amt) AS custom_amt ,MIN(amt) AS min_amt , MAX(amt) AS max_amt ,SUM(amt)/COUNT(*) pct FROM stu_card_distinct WHERE custom_date BETWEEN '2014-09-01' AND '2015-08-31' GROUP BY stu_id; # 5 lines of information of query statistics results SELECT * FROM custom LIMIT 5;
- Table join operation
Integrate the two tables processed above into one table. The specific choice of connection mode needs to be based on the actual business needs.
# Integration of statistical results SELECT COUNT(*) FROM custom; # A total of 5427 articles SELECT COUNT(*) FROM borrow_times; # 4158 articles in total # The student consumption table custom is used as the main table, and the book borrowing table borrow_times as secondary table (left join) SELECT t1.*, t2.borrow_times,t2.books FROM custom AS t1 LEFT JOIN borrow_times AS t2 ON t1.stu_id = t2.stu_id; # Inner connection: extract the student records shared by the two tables SELECT t1.*, t2.borrow_times,t2.books FROM custom AS t1 INNER JOIN borrow_times AS t2 ON t1.stu_id = t2.stu_id;
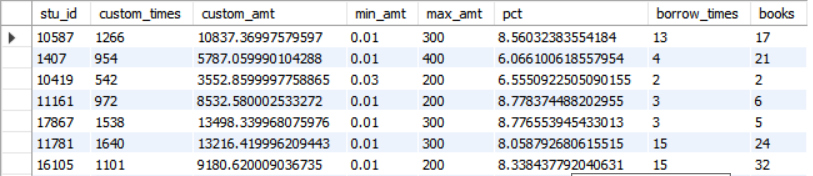
[supplement] detailed usage of LOAD DATA
For detailed explanation, see MySQL user manual refman-8.0-en.a4.pdf P2449-P2459