preface
Quartz - task scheduling (I) from getting started to understanding all the concepts of quartz
Quartz - task scheduling (I) from getting started to understanding all the concepts of quartz
I SpringBoot integrated Quartz
1. Dependence
If the SpringBoot version is 2 After X, the spring boot starter has included the dependency of Quart, so you can directly use the spring boot starter quartz dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
If it is 1.5 X, add dependencies using the following:
<dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context-support</artifactId> </dependency>
I use SpringBoot version 2 X
2. Implementation steps
2.1. Write the configuration class of Quartz
import org.quartz.SchedulerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.quartz.CronTriggerFactoryBean;
import org.springframework.scheduling.quartz.JobDetailFactoryBean;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import org.springframework.scheduling.quartz.SimpleTriggerFactoryBean;
@Configuration
@Component
public class QuartzConfig {
/**
* 1.Create Job object
*/
@Bean
public JobDetailFactoryBean jobDetailFactoryBean() {
JobDetailFactoryBean factory = new JobDetailFactoryBean();
factory.setName("JobName");
factory.setGroup("JobGroup");
//Associate our own Job class
factory.setJobClass(QuartzJob.class);
return factory;
}
/**
* 2.Create Trigger object
* Simple Trigger
*/
/*@Bean
public SimpleTriggerFactoryBean simpleTriggerFactoryBean(JobDetailFactoryBean jobDetailFactoryBean){
SimpleTriggerFactoryBean factory = new SimpleTriggerFactoryBean();
//Associate JobDetail objects
factory.setJobDetail(jobDetailFactoryBean.getObject());
//This parameter represents the number of milliseconds of an execution
factory.setRepeatInterval(2000);
//Number of repetitions
factory.setRepeatCount(5);
return factory;
}*/
/**
* Cron Trigger
*/
@Bean
public CronTriggerFactoryBean cronTriggerFactoryBean(@Qualifier("jobDetailFactoryBean") JobDetailFactoryBean jobDetailFactoryBean) {
CronTriggerFactoryBean factory = new CronTriggerFactoryBean();
factory.setName("TriggerName");
factory.setGroup("TriggerGroup");
factory.setJobDetail(jobDetailFactoryBean.getObject()); //Set trigger time
factory.setCronExpression("0/2 * * * * ?");//Job execution is triggered every 2 seconds
return factory;
}
/**
* 3.Create Scheduler object
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean(@Qualifier("cronTriggerFactoryBean") CronTriggerFactoryBean cronTriggerFactoryBean) {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
//Associated trigger
//factory.setTriggers(simpleTriggerFactoryBean.getObject());
factory.setTriggers(cronTriggerFactoryBean.getObject());
//Set delayed start to ensure the injection of attributes in the job
factory.setStartupDelay(5);
return factory;
}
}
2.2. Enable SpringBoot task scheduling
Use the @ enableshcheduling annotation on the startup class or Quartz configuration class to start task scheduling
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
2.3. Inject object into job class
Initialize the UsersService class to the Spring container
import org.springframework.stereotype.Service;
@Service
public class UsersService {
public void addUsers() {
System.out.println("Add Users....");
}
}
Implement the Job interface and inject the objects in the Spring container into this class
import java.util.Date;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.beans.factory.annotation.Autowired;
public class QuartzJob implements Job {
@Autowired
private UsersService usersService;
/**
* The method executed when the task is triggered
*/
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("Execute...."+new Date());
this.usersService.addUsers();
}
}
Difficulty: null pointer exception will be generated when injecting SpringBean into Job
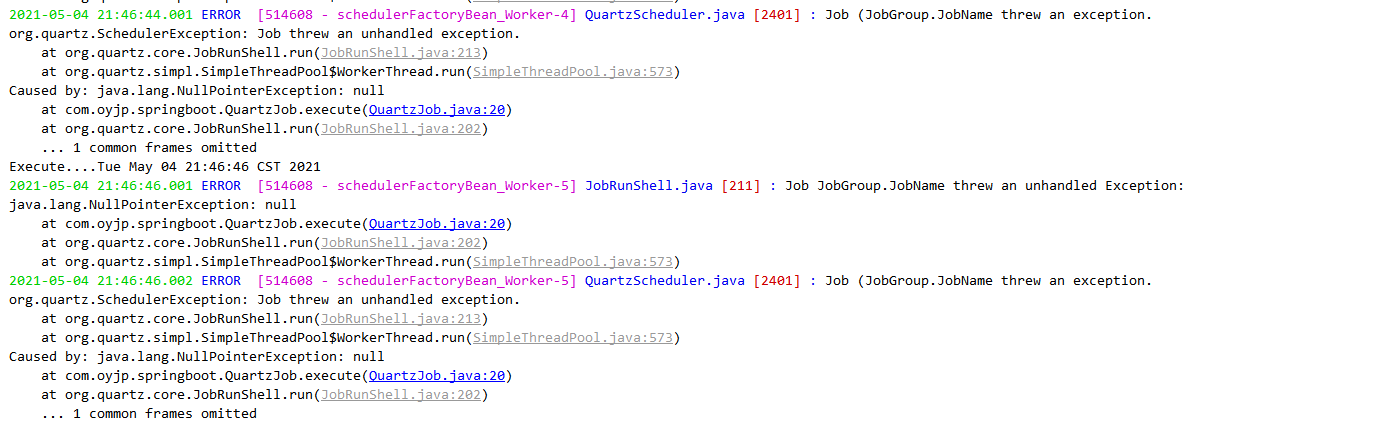
- Because UsersService is not injected into the Spring container in QuartzJob
- createJobInstance in AdaptableJobFactory is instantiated through reflection
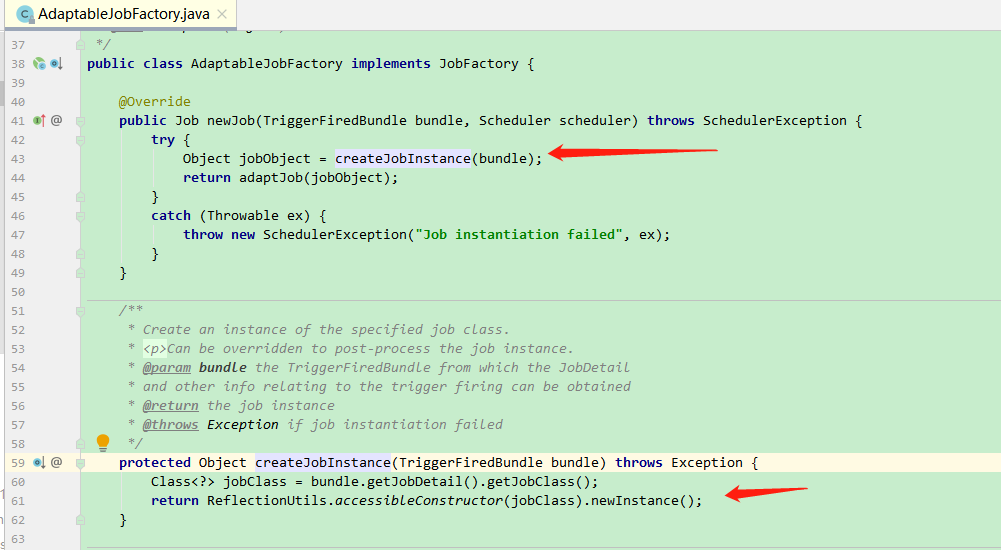
Solution: by inheriting SpringBeanJobFactory or AdaptableJobFactory, when generating the Job instance object, inject the Job instance into the Spring container through AutowireCapbaleBeanFactory.
import org.quartz.spi.TriggerFiredBundle;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.AutowireCapableBeanFactory;
import org.springframework.scheduling.quartz.AdaptableJobFactory;
import org.springframework.stereotype.Component;
@Component("autowiredSpringBeanJobFactory")
public class AutowiredSpringBeanJobFactory extends AdaptableJobFactory {
//AutowireCapableBeanFactory can add an object to the spring IOC container and complete the object injection
@Autowired
private AutowireCapableBeanFactory autowireCapableBeanFactory;
/**
* This method needs to manually add the instantiated task object to the springIOC container and complete the object injection
*/
@Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {
//Call the method of the parent class
Object obj = super.createJobInstance(bundle);
//Add the obj object to the Spring IOC container and complete the injection
this.autowireCapableBeanFactory.autowireBean(obj);
return obj;
}
}
Modify configuration class QuartzConfig
- When initializing SchedulerFactoryBean, specify JobFactory and configure deferred loading
/**
* 3.Create Scheduler object
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean(@Qualifier("cronTriggerFactoryBean") CronTriggerFactoryBean cronTriggerFactoryBean, @Qualifier("autowiredSpringBeanJobFactory") AutowiredSpringBeanJobFactory autowiredSpringBeanJobFactory ) {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
//Associated trigger
//factory.setTriggers(simpleTriggerFactoryBean.getObject());
factory.setTriggers(cronTriggerFactoryBean.getObject());
//Inject the customized MyJobFactory into the configuration class and add the following configuration,
//Configure the object using spring's autowired, and inject the object into the job
factory.setJobFactory(autowiredSpringBeanJobFactory);
//Set delayed start to ensure the injection of attributes in the job
factory.setStartupDelay(5);
return factory;
}
results of enforcement

II Quartz built-in database execution task scheduling
1.JDBCStore concept
- By default, Quartz triggers, schedulers, tasks and other information are stored in memory, which is called RAMJobStore. The advantage is fast, but the disadvantage is that once the system is restarted, the information will be lost and you have to start all over again.
- So Quartz also provides another way to store this information in a database, called JobStoreTX. The advantage is that even if the system is restarted and it has been running for several times, this information is stored in the database, so you can continue the original pace and continue the planned tasks seamlessly. The disadvantage is that the performance is slower than the memory. After all, the database reading is always slower.
2. Create table sql
In order to store the relevant information into the mysql database, you must manually establish the database and table, and use the following script.
Note: the database name used here is quartz
- Specific table building sql from the article [JavaWeb] Quartz - task scheduling (III) Quartz 2 X description of built-in data table structure Just copy and paste
3. Implementation steps
3.1. New configuration file quartz properties
1. Add a configuration file
Under src/main/resources, create a new quartz Properties configuration file, which specifies to use JobStoreTX to manage tasks. And specify the driver, user name, password, url, etc. of the contact database
#Scheduling ID name each instance in the cluster must use the same name org.quartz.scheduler.instanceName=MyScheduler #The scheduler instance number is automatically generated, and each instance cannot be the same org.quartz.scheduler.instanceId=AUTO #Start distributed deployment and cluster org.quartz.jobStore.isClustered=true #Distributed node validity check interval, unit: ms, default value: 15000 org.quartz.jobStore.clusterCheckinInterval=2000 #All configurations related to remote management are closed org.quartz.scheduler.rmi.export=false org.quartz.scheduler.rmi.proxy=false org.quartz.scheduler.wrapJobExecutionInUserTransaction=false #When instantiating ThreadPool, the thread class used is SimpleThreadPool (generally, SimpleThreadPool can meet the needs of almost all users) org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool ##The number of concurrent threads. Specify the number of threads. At least 1 (no default value) (generally, an integer between 1-100 is appropriate) org.quartz.threadPool.threadCount=10 ##Set the priority of threads (the maximum is java.lang.Thread.MAX_PRIORITY 10, the minimum is Thread.MIN_PRIORITY 1, and the default is 5) org.quartz.threadPool.threadPriority=5 #org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true #The maximum allowable job extension time and the maximum tolerable trigger timeout time. If it exceeds, it will be considered as an "error" and should not be configured in memory or data org.quartz.jobStore.misfireThreshold=6000 #Persistent mode configuration # By default, it is stored in memory and saves the status information of job and Trigger to the class in memory #org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore #Database mode org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX #Configure data-driven and MySQL database in persistence mode (configure the JDBC agent class according to the selected database type) org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #quartz related data table prefix name org.quartz.jobStore.tablePrefix=QRTZ_ #Random database alias org.quartz.jobStore.dataSource=mysqlDatabase org.quartz.dataSource.mysqlDatabase.driver=com.mysql.jdbc.Driver org.quartz.dataSource.mysqlDatabase.URL=jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8&serverTimezone=UTC&useSSL=false org.quartz.dataSource.mysqlDatabase.user=root org.quartz.dataSource.mysqlDatabase.password=root org.quartz.dataSource.mysqlDatabase.maxConnection=5
2. Introduce dependency
In boot2 The spring boot starter quartz dependency in X does not depend on the c3p0 data source by default. If you want to use it, you need to reference the c3p0 data source separately, otherwise an exception will be thrown
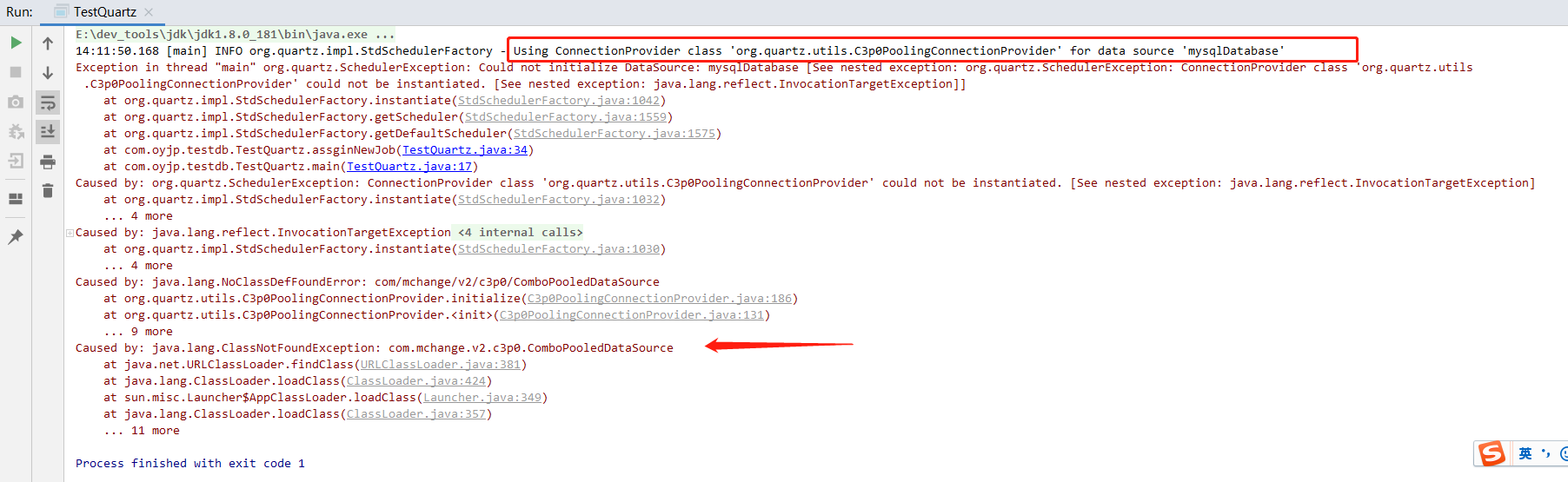
Here we use druid as the data source
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
You need to customize the Druid database connection pool and implement org quartz. utils. Connectionprovider interface
public class DruidConnectionProvider implements ConnectionProvider {
/*
* Constant configuration, and Quartz The key s of the properties file are consistent (remove the prefix), and the set method is provided. The Quartz framework automatically injects values.
*/
public static final int DEFAULT_DB_MAX_CONNECTIONS = 10;
public static final int DEFAULT_DB_MAX_CACHED_STATEMENTS_PER_CONNECTION = 120;
//JDBC Driver
public String driver;
//JDBC connection string
public String URL;
//Database user name
public String user;
//Database user password
public String password;
//Maximum number of database connections
public int maxConnection;
//The database SQL query executes back to the connection pool every time a connection is returned to ensure that it is still valid.
public String validationQuery;
public String maxCachedStatementsPerConnection;
private boolean validateOnCheckout;
private int idleConnectionValidationSeconds;
private String discardIdleConnectionsSeconds;
//Druid connection pool
private DruidDataSource datasource;
/*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*
* Interface implementation
*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*/
@Override
public Connection getConnection() throws SQLException {
return datasource.getConnection();
}
@Override
public void shutdown() throws SQLException {
datasource.close();
}
@Override
public void initialize() throws SQLException {
if (this.URL == null) {
throw new SQLException("DBPool could not be created: DB URL cannot be null");
}
if (this.driver == null) {
throw new SQLException("DBPool driver could not be created: DB driver class name cannot be null!");
}
if (this.maxConnection < 0) {
throw new SQLException("DBPool maxConnectins could not be created: Max connections must be greater than zero!");
}
datasource = new DruidDataSource();
try {
datasource.setDriverClassName(this.driver);
} catch (Exception e) {
try {
throw new SchedulerException("Problem setting driver class name on datasource: " + e.getMessage(), e);
} catch (SchedulerException e1) {
}
}
datasource.setUrl(this.URL);
datasource.setUsername(this.user);
datasource.setPassword(this.password);
datasource.setMaxActive(this.maxConnection);
datasource.setMinIdle(1);
datasource.setMaxWait(0);
datasource.setMaxPoolPreparedStatementPerConnectionSize(DEFAULT_DB_MAX_CONNECTIONS);
if (this.validationQuery != null) {
datasource.setValidationQuery(this.validationQuery);
if (!this.validateOnCheckout) {
datasource.setTestOnReturn(true);
}
else {
datasource.setTestOnBorrow(true);
}
datasource.setValidationQueryTimeout(this.idleConnectionValidationSeconds);
}
}
/*
* Provide get set method
*
*/
public String getDriver() {
return driver;
}
public void setDriver(String driver) {
this.driver = driver;
}
public String getURL() {
return URL;
}
public void setURL(String URL) {
this.URL = URL;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getMaxConnection() {
return maxConnection;
}
public void setMaxConnection(int maxConnection) {
this.maxConnection = maxConnection;
}
public String getValidationQuery() {
return validationQuery;
}
public void setValidationQuery(String validationQuery) {
this.validationQuery = validationQuery;
}
public boolean isValidateOnCheckout() {
return validateOnCheckout;
}
public void setValidateOnCheckout(boolean validateOnCheckout) {
this.validateOnCheckout = validateOnCheckout;
}
public int getIdleConnectionValidationSeconds() {
return idleConnectionValidationSeconds;
}
public void setIdleConnectionValidationSeconds(int idleConnectionValidationSeconds) {
this.idleConnectionValidationSeconds = idleConnectionValidationSeconds;
}
public DruidDataSource getDatasource() {
return datasource;
}
public void setDatasource(DruidDataSource datasource) {
this.datasource = datasource;
}
public String getDiscardIdleConnectionsSeconds() {
return discardIdleConnectionsSeconds;
}
public void setDiscardIdleConnectionsSeconds(String discardIdleConnectionsSeconds) {
this.discardIdleConnectionsSeconds = discardIdleConnectionsSeconds;
}
}
quartz.properties add a new line of configuration
#The database connection pool used is c3p0 by default. I use alibaba's druid data source here, which needs to introduce dependency org.quartz.dataSource.mysqlDatabase.connectionProvider.class=com.oyjp.testdb.DruidConnectionProvider
3.2. Write code
MailJob
@DisallowConcurrentExecution//Serial execution
public class MailJob implements Job {
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDetail detail = context.getJobDetail();
String email = detail.getJobDataMap().getString("email");
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
String now = sdf.format(new Date());
System.out.printf("Give email address %s Sent a regular email, current time is: %s (%s)%n" ,email, now,context.isRecovering());
}
}
test method
public class TestQuartz {
public static void main(String[] args) throws Exception {
try {
assginNewJob();
} catch (ObjectAlreadyExistsException e) {
System.err.println("The discovery task already exists in the database and runs directly from the database:"+ e.getMessage());
resumeJobFromDatabase();
}
}
//When assginewjob() reports an exception in task scheduling, it calls the current method to restore task scheduling from the database
// The trigger of the task is also adjusted to once every 15 seconds, a total of 11 times.
private static void resumeJobFromDatabase() throws Exception {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
// Wait for 200 seconds, and then close the scheduler after all the previous tasks have been executed
Thread.sleep(200000);
scheduler.shutdown(true);
}
//Create a task schedule
private static void assginNewJob() throws SchedulerException, InterruptedException {
// Create scheduler
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// Define a trigger
Trigger trigger = newTrigger().withIdentity("trigger1", "group1") // Define the name and the rent to which it belongs
.startNow()
.withSchedule(simpleSchedule().withIntervalInSeconds(15) // Every 15 seconds
.withRepeatCount(10)) // A total of 11 executions (the first execution does not affect the base number)
.build();
// Define a JobDetail
JobDetail job = newJob(MailJob.class) // Specifies the MailJob class for the job
.withIdentity("mailjob1", "mailgroup") // Define task names and groups
.usingJobData("email", "admin@10086.com") // Define attributes
.build();
// Schedule to join this job
scheduler.scheduleJob(job, trigger);
// start-up
scheduler.start();
// Wait for 20 seconds, and then close the scheduler after all the previous tasks have been executed
Thread.sleep(20000);
scheduler.shutdown(true);
}
}
test method
- If you run it once, you won't see red, because there are no tasks in the database at this time, and it will be executed smoothly

- After 20 seconds, it ends automatically. At this time, the task has not been completed (the task design is 10 times in total, with an interval of 15 seconds).
- If you do not need to modify the code and execute it again, you will see the red words, indicating that you are trying to add a task to the database, but you find that the task already exists in the database. At this time, the scheduling will automatically run the tasks in the database, so as to achieve the effect of automatic connection after system restart
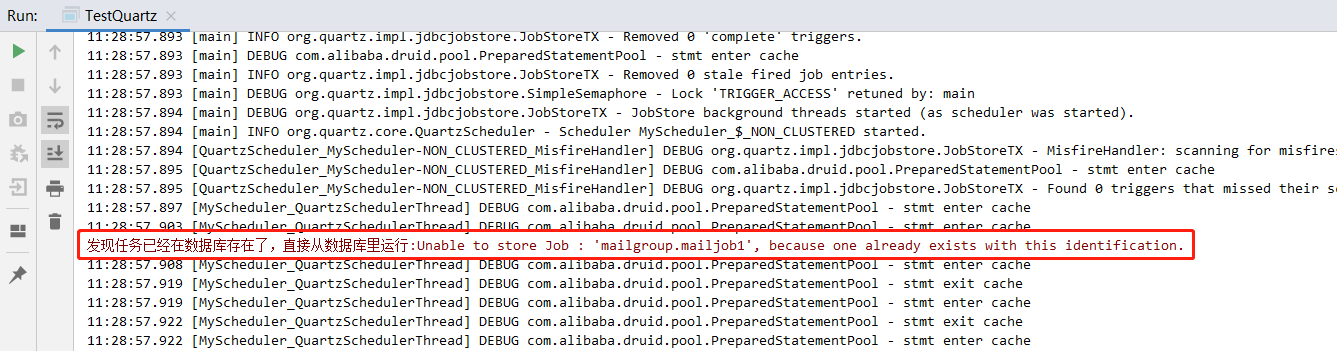
Note (as shown in the red font above)
- If you use JDBC to save task scheduling data, when you run a job and exit, when you want to run a job again, the system will throw an exception ObjectAlreadyExistsException with the same name as JobDetail:
Unable to store Jobwith name: 'job1_1' and group: 'jGroup1', because one already exists with thisidentification.
- Because every time Scheduler#scheduleJob() is called, Quartz will save the information of JobDetail and Trigger to the database. If a JobDetail or Trigger with the same name already exists in the data table, an exception will be generated.
III Quartz clusters based on Database
1. Cluster concept
- Quart distributed scheduling task is a "preemptive scheduling" realized through the database. A task can only be executed on one Quartz node. His cluster only solves the single point of failure (task level) and realizes high availability. Multiple tasks are load balanced in the cluster, which does not solve the problem of task fragmentation and cannot realize horizontal expansion, If a large number of short tasks are performed, and each node frequently competes for database locks, the more nodes there are, the more serious the situation is, and the performance will be very low.
Note: the Quartz application described in this paper is also called Quartz server node in some contexts, which is the same concept.
quartz's clustering idea is as follows: by configuring timer information in the database, only one node is running in the same task in the way of database pessimistic lock,
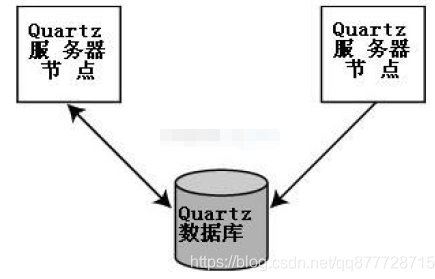
tips:
.
Running all Quartz nodes on the same machine is called vertical cluster, or running all nodes on different machines is called horizontal cluster.
- For vertical clusters, there is a single point of failure problem. This is bad news for high availability applications, because once the machine goes down, all nodes will be effectively terminated.
- When you run a horizontal cluster, a strict requirement is that our clock time must be synchronized to avoid strange and unpredictable behavior. If the clock cannot be synchronized, the Scheduler instance will confuse the state of other nodes, causing trouble that is difficult to estimate.
advantage:
- Ensure high availability (HA) of nodes. If a node hangs up at some point, other nodes can be on top
Disadvantages:
- Only one node can run the same task, and other nodes will not perform the task, resulting in low performance and waste of resources
- When encountering a large number of short tasks, each node frequently competes for database locks. The more nodes, the more serious the situation is. The performance will be very low
- quartz distributed only solves the problem of high availability of clusters, does not solve the problem of task fragmentation, and can not achieve horizontal expansion
2. Use steps
1. Create a quartz database
Jump
2.quartz.properties adjustment
- Start cluster
org.quartz.jobStore.isClustered = true
- To cluster, multiple application scheduling names instanceName should be the same
org.quartz.scheduler.instanceName = quartzScheduler
- To cluster, multiple application scheduling IDS instanceid must be different. If AUTO is used here, different IDS will be automatically assigned. Visual inspection is the name of the local machine with time stamp
org.quartz.scheduler.instanceId = AUTO
- Check the database every second to make it up in time after other applications hang up
org.quartz.jobStore.clusterCheckinInterval = 1000
Complete quartz Properties file
#Scheduling ID name each instance in the cluster must use the same name org.quartz.scheduler.instanceName=MyScheduler #The scheduler instance number is automatically generated, and each instance cannot be the same org.quartz.scheduler.instanceId=AUTO #Start distributed deployment and cluster org.quartz.jobStore.isClustered=true #Distributed node validity check interval, unit: ms, default value: 15000 org.quartz.jobStore.clusterCheckinInterval=2000 #All configurations related to remote management are closed org.quartz.scheduler.rmi.export=false org.quartz.scheduler.rmi.proxy=false org.quartz.scheduler.wrapJobExecutionInUserTransaction=false #When instantiating ThreadPool, the thread class used is SimpleThreadPool (generally, SimpleThreadPool can meet the needs of almost all users) org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool ##The number of concurrent threads. Specify the number of threads. At least 1 (no default value) (generally, an integer between 1-100 is appropriate) org.quartz.threadPool.threadCount=10 ##Set the priority of threads (the maximum is java.lang.Thread.MAX_PRIORITY 10, the minimum is Thread.MIN_PRIORITY 1, and the default is 5) org.quartz.threadPool.threadPriority=5 #org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true #The maximum allowable job extension time and the maximum tolerable trigger timeout time. If it exceeds, it will be considered as an "error" and should not be configured in memory or data org.quartz.jobStore.misfireThreshold=6000 #Persistent mode configuration # By default, it is stored in memory and saves the status information of job and Trigger to the class in memory #org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore #Database mode org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX #Configure data-driven and MySQL database in persistence mode (configure the JDBC agent class according to the selected database type) org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #quartz related data table prefix name org.quartz.jobStore.tablePrefix=QRTZ_ #Random database alias org.quartz.jobStore.dataSource=mysqlDatabase org.quartz.dataSource.mysqlDatabase.driver=com.mysql.jdbc.Driver org.quartz.dataSource.mysqlDatabase.URL=jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8&serverTimezone=UTC&useSSL=false org.quartz.dataSource.mysqlDatabase.user=root org.quartz.dataSource.mysqlDatabase.password=root org.quartz.dataSource.mysqlDatabase.maxConnection=5
3. Test method
There are many steps in operation. Please follow the steps strictly:
- Start TestQuartz once, which is called a application
- Then (within a few seconds) start TestQuartz again, called the b application
This launches two Quartz applications - Use the multi console display mode to observe the phenomenon in two different consoles
The following phenomena will be observed:
- a application will only run for 20 seconds and end automatically. These 20 seconds are only enough to run two tasks, so two outputs are observed.
- The b application will not run until the a application is finished
- After the application of a, application b automatically took over the torch of revolution and kept running the subsequent tasks
import static org.quartz.JobBuilder.newJob;
import static org.quartz.SimpleScheduleBuilder.simpleSchedule;
import static org.quartz.TriggerBuilder.newTrigger;
import org.quartz.JobDetail;
import org.quartz.ObjectAlreadyExistsException;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.Trigger;
import org.quartz.impl.StdSchedulerFactory;
public class TestQuartz {
public static void main(String[] args) throws Exception {
try {
assginNewJob();
} catch (ObjectAlreadyExistsException e) {
System.err.println("The discovery task already exists in the database and runs directly from the database:"+ e.getMessage());
resumeJobFromDatabase();
}
}
private static void resumeJobFromDatabase() throws Exception {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
System.out.println("Current scheduler id Yes:"+scheduler.getSchedulerInstanceId());
scheduler.start();
// Wait for 200 seconds, and then close the scheduler after all the previous tasks have been executed
Thread.sleep(200000);
scheduler.shutdown(true);
}
private static void assginNewJob() throws SchedulerException, InterruptedException {
// Create scheduler
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// Define a trigger
Trigger trigger = newTrigger().withIdentity("trigger1", "group1") // Define the name and the rent to which it belongs
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(15) // Every 15 seconds
.withRepeatCount(10)) // A total of 11 executions (the first execution does not affect the base number)
.build();
// Define a JobDetail
JobDetail job = newJob(MailJob.class) // Specifies the MailJob class for the job
.withIdentity("mailjob1", "mailgroup") // Define task names and groups
.usingJobData("email", "admin@10086.com") // Define attributes
.build();
// Schedule to join this job
scheduler.scheduleJob(job, trigger);
System.out.println("Current scheduler id Yes:"+scheduler.getSchedulerInstanceId());
// start-up
scheduler.start();
// Wait for 20 seconds, and then close the scheduler after all the previous tasks have been executed
Thread.sleep(20000);
scheduler.shutdown(true);
}
}
IV Integrating Quartz clusters with Springboot
1. Introduce dependency
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.43</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.9</version>
</dependency>
2.application.yml configuration
application.yml file configuration (here is the configuration mode of single data source. If it is the configuration mode of multiple data sources, please refer to my article [SpringBoot] realize the dynamic switching of multiple data sources of JdbcTemplate, Druid and dynamic datasource)
server:
port: 8080
spring:
application:
name: quartz
datasource:
url: jdbc:mysql://localhost:3306/quartzdb?characterEncoding=utf-8&useUnicode=true&useSSL=false
driver-class-name: com.mysql.jdbc.Driver # mysql8.0 used com mysql. jdbc. Driver
username: root
password: root
platform: mysql
#Through this configuration, druid connection pool is introduced into our configuration. spring will judge the type as much as possible, and then match the driver class according to the situation.
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5 # Initialization size
min-idle: 5 # minimum
max-active: 100 # maximum
max-wait: 60000 # Configure the timeout time for getting connections
time-between-eviction-runs-millis: 60000 # How often is the configuration interval detected? Idle connections that need to be closed are detected in milliseconds
min-evictable-idle-time-millis: 300000 # Specifies the minimum number of milliseconds after which an idle connection can be cleared
validationQuery: select 'x'
test-while-idle: true # Whether to perform connection test when the connection is idle
test-on-borrow: false # When borrowing a connection from a connection pool, do you want to test the connection
test-on-return: false # Whether to test the connection when it is returned to the connection pool
filters: config,wall,stat # Configure the filters for monitoring statistics interception. After removal, the sql in the monitoring interface cannot be counted, 'wall' is used for firewall
poolPreparedStatements: true # The size of the PSCache on each connection is specified, and the PSCache is opened
maxPoolPreparedStatementPerConnectionSize: 20
maxOpenPreparedStatements: 20
# Open the mergeSql function through the connectProperties property; Slow SQL record
connectionProperties: druid.stat.slowSqlMillis=200;druid.stat.logSlowSql=true;config.decrypt=false
# Merge monitoring data of multiple DruidDataSource
#use-global-data-source-stat: true
#For the configuration of WebStatFilter, please refer to the Druid Wiki_ Configure WebStatFilter
web-stat-filter:
enabled: true #Whether to enable StatFilter. The default value is true
url-pattern: /*
exclusions: /druid/*,*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico
session-stat-enable: true
session-stat-max-count: 10
#For StatViewServlet configuration, please refer to Druid Wiki configuration_ StatViewServlet configuration
stat-view-servlet:
enabled: true #Whether to enable StatViewServlet. The default value is true
url-pattern: /druid/*
reset-enable: true
login-username: admin
login-password: admin
3.quartz.properties configuration file reference resources
4. Simulate the business logic of task scheduling service layer
@Service
public class UserService {
public void getUserInfo() {
System.err.println("dispatch getUserInof success");
}
public void getUserAddr() {
System.err.println("dispatch getUserAddr success");
}
}
5. Tasks
@Component
@DisallowConcurrentExecution //Ensure that the last task is completed before executing the next task
//@PersistJobDataAfterExecution / / before the previous task is completed, write the variables to be obtained by the next task and the corresponding attribute values, similar to summation and accumulation
public class JobOne extends QuartzJobBean {
private UserService userService;
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
userService.getUserInfo();
}
public void setUserService(UserService userService) {
this.userService = userService;
}
}
@Component
@DisallowConcurrentExecution
public class JobTwo extends QuartzJobBean {
//You can't use injection. You can only use DateMap to pass in parameters
private UserService userService;
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
userService.getUserAddr();
}
public void setUserService(UserService userService) {
this.userService = userService;
}
}
QuartzJobBean is an abstract class of the Job interface implemented by Spring. There are only some Spring specific processing, as shown in the figure
6. Task configuration
@Configuration
public class JobConfig {
@Bean("jobOneDetail")
public JobDetailFactoryBean jobOneDetailFactoryBean(JobOne jobOne) {
JobDetailFactoryBean jobDetailFactoryBean = new JobDetailFactoryBean();
jobDetailFactoryBean.setJobClass(jobOne.getClass());
//The unbound trigger remains in Quartz's JobStore
jobDetailFactoryBean.setDurability(true);
jobDetailFactoryBean.setName("jobOneDetailName");
jobDetailFactoryBean.setGroup("jobOneDetailGroup");
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("test1", "1111");
jobDetailFactoryBean.setJobDataMap(jobDataMap);
return jobDetailFactoryBean;
}
@Bean("jobOneTrigger")
public CronTriggerFactoryBean cronTriggerOneFactoryBean(@Qualifier("jobOneDetail") JobDetailFactoryBean jobDetailFactoryBean) {
CronTriggerFactoryBean cronTriggerFactoryBean = new CronTriggerFactoryBean();
cronTriggerFactoryBean.setJobDetail(jobDetailFactoryBean.getObject());
cronTriggerFactoryBean.setCronExpression("*/1 * * * * ?");
cronTriggerFactoryBean.setName("jobOneTriggerName");
cronTriggerFactoryBean.setGroup("jobOneTriggerGroup");
return cronTriggerFactoryBean;
}
@Bean("jobTwoDetail")
public JobDetailFactoryBean jobTwoDetailFactoryBean(JobTwo jobTwo) {
JobDetailFactoryBean jobDetailFactoryBean = new JobDetailFactoryBean();
jobDetailFactoryBean.setJobClass(jobTwo.getClass());
jobDetailFactoryBean.setDurability(true);
jobDetailFactoryBean.setName("jobTwoDetailName");
jobDetailFactoryBean.setGroup("jobTwoDetailGroup");
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("test2", "2222");
jobDetailFactoryBean.setJobDataMap(jobDataMap);
return jobDetailFactoryBean;
}
@Bean("jobTwoTrigger")
public CronTriggerFactoryBean cronTriggerTwoFactoryBean(@Qualifier("jobTwoDetail") JobDetailFactoryBean jobDetailFactoryBean) {
CronTriggerFactoryBean cronTriggerFactoryBean = new CronTriggerFactoryBean();
cronTriggerFactoryBean.setJobDetail(jobDetailFactoryBean.getObject());
cronTriggerFactoryBean.setCronExpression("*/1 * * * * ?");
cronTriggerFactoryBean.setName("jobTwoTriggerName");
cronTriggerFactoryBean.setGroup("jobTwoTriggerGroup");
return cronTriggerFactoryBean;
}
}
7.Method to solve null pointer exception when injecting SpringBean into Job
8. Scheduler configuration
@Configuration
public class SchedulerConfig {
// Profile path
private static final String QUARTZ_CONFIG = "/quartz.properties";
@Autowired
@Qualifier("autowiredSpringBeanJobFactory")
private AutowiredSpringBeanJobFactory autowiredSpringBeanJobFactory;
//Configure data source
//You can leave @ Bean to spring to manage, otherwise you may have the problem of default data source
@Bean("quartzDataSource")
public DataSource quartzDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8&serverTimezone=UTC&useSSL=false");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
return dataSource;
}
/**
* From Quartz Read Quartz configuration properties from the properties file
* @return
* @throws IOException
*/
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource(QUARTZ_CONFIG));
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
//Perform the task. With the trigger, we can perform the task. Register a SchedulerFactroyBean, and then pass the trigger in the form of a list
@Bean
public SchedulerFactoryBean schedulerFactoryBean(@Qualifier("jobOneTrigger") Trigger jobOneTrigger, @Qualifier("jobTwoTrigger") Trigger jobTwoTrigger) throws IOException {
SchedulerFactoryBean schedulerFactoryBean=new SchedulerFactoryBean();
//Scheduler name
schedulerFactoryBean.setSchedulerName("TestScheduler");
//data source
schedulerFactoryBean.setDataSource(quartzDataSource());
//Overwrite the existing tasks, which are used in the Quartz cluster. The startup of the Quartz scheduler will update the existing jobs
schedulerFactoryBean.setOverwriteExistingJobs(true);
//Delay 1 s to start the scheduled task, so as to avoid the situation that the system starts to execute the scheduled task before it is fully started
schedulerFactoryBean.setStartupDelay(1);
//Set the loaded quartz Properties configuration file
schedulerFactoryBean.setQuartzProperties(quartzProperties());
//Auto start
schedulerFactoryBean.setAutoStartup(true);
//Register trigger
schedulerFactoryBean.setTriggers(jobOneTrigger,jobTwoTrigger);
//Inject the customized MyJobFactory into the configuration class and add the following configuration,
//Configure the object using spring's autowired, and inject the object into the job
schedulerFactoryBean.setJobFactory(autowiredSpringBeanJobFactory);
return schedulerFactoryBean;
}
}
test result
- When two tasks are scheduled, 1 will cross
- When services a and b are started, services a and b will select a task to execute all the time
- When two services a and b are started and executed for a certain time, service b is closed. Service a will obtain the scheduling task execution of service b after detecting the exception of service b
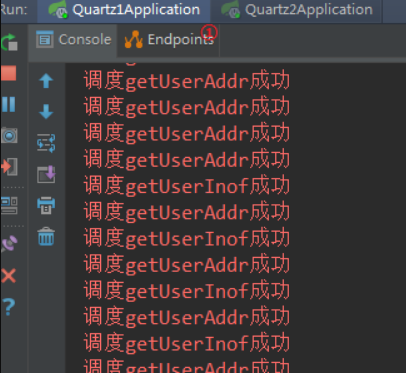
V External expansion task CRUD
Based on the above IV Integrating Quartz clusters with Springboot , we can operate the task through the interface, so as to realize the visualization of the task
task
public class AsyncJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("========================Immediate tasks, only once===============================");
System.out.println("jobName=====:"+jobExecutionContext.getJobDetail().getKey().getName());
System.out.println("jobGroup=====:"+jobExecutionContext.getJobDetail().getKey().getGroup());
System.out.println("taskData=====:"+jobExecutionContext.getJobDetail().getJobDataMap().get("asyncData"));
}
}
public class CronJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("=========================The scheduled task is executed every 5 seconds===============================");
System.out.println("jobName=====:"+jobExecutionContext.getJobDetail().getKey().getName());
System.out.println("jobGroup=====:"+jobExecutionContext.getJobDetail().getKey().getGroup());
System.out.println("taskData=====:"+jobExecutionContext.getJobDetail().getJobDataMap().get("taskData"));
}
}
Business interface of task operation
public interface JobService {
/**
* Add a scheduled task
* @param jobName
* @param jobGroup
*/
void addCronJob(String jobName, String jobGroup);
/**
* Add asynchronous task
* @param jobName
* @param jobGroup
*/
void addAsyncJob(String jobName, String jobGroup);
/**
* Suspend task
* @param jobName
* @param jobGroup
*/
void pauseJob(String jobName, String jobGroup);
/**
* Recovery task
* @param jobName
* @param jobGroup
*/
void resumeJob(String jobName, String jobGroup);
/**
* Delete job
* @param jobName
* @param jobGroup
*/
void deleteJob(String jobName, String jobGroup);
}
Business interface implementation class of task operation
@Service
public class JobServiceImpl implements JobService {
Logger log = LoggerFactory.getLogger(this.getClass());
@SuppressWarnings("SpringJavaInjectionPointsAutowiringInspection")
@Autowired
private SchedulerFactoryBean schedulerFactoryBean;
/**
* Create a scheduled task
*
* @param jobName
* @param jobGroup
*/
@Override
public void addCronJob(String jobName, String jobGroup) {
try {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(jobName, jobGroup);
JobDetail jobDetail = scheduler.getJobDetail(jobKey);
if (jobDetail != null) {
log.info("job:" + jobName + " Already exists");
}
else {
//Build job information
jobDetail = JobBuilder.newJob(CronJob.class).withIdentity(jobName, jobGroup).build();
//Transfer data with JopDataMap
jobDetail.getJobDataMap().put("taskData", "hzb-cron-001");
//Expression scheduling Builder (i.e. the execution time of the task, which is executed every 5 seconds)
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("*/5 * * * * ?");
//Build a new trigger according to the new cronExpression expression
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity(jobName + "_trigger", jobGroup + "_trigger")
.withSchedule(scheduleBuilder).build();
scheduler.scheduleJob(jobDetail, trigger);
}
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void addAsyncJob(String jobName, String jobGroup) {
try {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(jobName, jobGroup);
JobDetail jobDetail = scheduler.getJobDetail(jobKey);
if (jobDetail != null) {
log.info("job:" + jobName + " Already exists");
}
else {
//To build job information, when creating JobDetail with JobBuilder, there is a storereliable () method, which can save the task in the queue when there is no trigger pointing to the task. Then it can be triggered manually
jobDetail = JobBuilder.newJob(AsyncJob.class).withIdentity(jobName, jobGroup).storeDurably().build();
jobDetail.getJobDataMap().put("asyncData", "this is a async task");
Trigger trigger = TriggerBuilder.newTrigger().withIdentity(jobName + "_trigger", jobGroup + "_trigger") //Define name/group
.startNow()//Once you join the scheduler, it takes effect immediately
.withSchedule(simpleSchedule())//Using SimpleTrigger
.build();
scheduler.scheduleJob(jobDetail, trigger);
}
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void pauseJob(String jobName, String jobGroup) {
try {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
TriggerKey triggerKey = TriggerKey.triggerKey(jobName + "_trigger", jobGroup + "_trigger");
scheduler.pauseTrigger(triggerKey);
log.info("=========================pause job:" + jobName + " success========================");
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* Recovery task
*
* @param jobName
* @param jobGroup
*/
@Override
public void resumeJob(String jobName, String jobGroup) {
try {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
TriggerKey triggerKey = TriggerKey.triggerKey(jobName + "_trigger", jobGroup + "_trigger");
scheduler.resumeTrigger(triggerKey);
log.info("=========================resume job:" + jobName + " success========================");
} catch (SchedulerException e) {
e.printStackTrace();
}
}
@Override
public void deleteJob(String jobName, String jobGroup) {
try {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(jobName, jobGroup);
scheduler.deleteJob(jobKey);
log.info("=========================delete job:" + jobName + " success========================");
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}
External exposure interface
@RestController
@RequestMapping("/quartztest")
public class JobController {
@Autowired
private JobService jobService;
/**
* Create cron task
*
* @param jobName
* @param jobGroup
* @return
*/
@RequestMapping(value = "/cron", method = RequestMethod.POST)
public String startCronJob(@RequestParam("jobName") String jobName, @RequestParam("jobGroup") String jobGroup) {
jobService.addCronJob(jobName, jobGroup);
return "create cron task success";
}
/**
* Create asynchronous task
*
* @param jobName
* @param jobGroup
* @return
*/
@RequestMapping(value = "/async", method = RequestMethod.POST)
public String startAsyncJob(@RequestParam("jobName") String jobName, @RequestParam("jobGroup") String jobGroup) {
jobService.addAsyncJob(jobName, jobGroup);
return "create async task success";
}
/**
* Suspend task
*
* @param jobName
* @param jobGroup
* @return
*/
@RequestMapping(value = "/pause", method = RequestMethod.POST)
public String pauseJob(@RequestParam("jobName") String jobName, @RequestParam("jobGroup") String jobGroup) {
jobService.pauseJob(jobName, jobGroup);
return "pause job success";
}
/**
* Recovery task
*
* @param jobName
* @param jobGroup
* @return
*/
@RequestMapping(value = "/resume", method = RequestMethod.POST)
public String resumeJob(@RequestParam("jobName") String jobName, @RequestParam("jobGroup") String jobGroup) {
jobService.resumeJob(jobName, jobGroup);
return "resume job success";
}
/**
* Delete task
*
* @param jobName
* @param jobGroup
* @return
*/
@RequestMapping(value = "/delete", method = RequestMethod.PUT)
public String deleteJob(@RequestParam("jobName") String jobName, @RequestParam("jobGroup") String jobGroup) {
jobService.deleteJob(jobName, jobGroup);
return "delete job success";
}
}
-----------------Relevant good articles--------------------
Quartz official documents
Quartz framework set nice
Task scheduling framework Quartz set - two NIC
Project restart quartz scheduled task execution strategy - misfire
Comparison of 6 distributed scheduled tasks?? Here's the plate for you
Quartz source code analysis (I) -- basic introduction
Quartz source code analysis (II) -- Scheduler initialization
Quartz source code analysis (III) -- JobDetail, Trigger and their Builder
Quartz source code analysis (IV) -- QuartzScheduler and Listener event listening
Quartz source code analysis (V) -- QuartzSchedulerThread
Quartz source code analysis (VI) -- Analyzing Cron expression