
Author: Mintimate
Blog: https://www.mintimate.cn Mintimate's Blog, just to share with you
preface
Generally, using JDK means using OracleJDK or OpenJDK. The agreement of OracleJDK commercial license often changes; To be on the safe side, it's better to use OpenJDK for project development.
Among the many branches of OpenJDK, I prefer ZuluJDK: https://www.azul.com/downloads/
But it's a little embarrassing. ZuluJDK's project official website is not very friendly. Sometimes, even if you go up, the speed is very slow, and even a JDK can't be downloaded.
Therefore, I want to use the Hong Kong server of my Tencent cloud lightweight application server to transit and build my own mirror station; The mirror station built can provide direct download links to Shanghai, Nanjing and other regions of our lightweight application server; You can even download JDK for your friends to share your joy (´▽ ')
ZuluJDK
ZuluJDK is developed based on OpenJDK and uses the following protocol: GPL v2 + Classpath exception (GPL v2 + CE):
Using ZuluJDK is basically no different from using OracleJDK, and will not be affected by Oracle protocol (ZuluJDK has always been GPL v2+CE)
There is a heated discussion on whether it is necessary to follow GPLv2 and open source to develop Java software using OpenJDK; However, pay attention to this Classpath exception. I think the developed software can still not use GPL protocol; Specifically, please call the boss for support in the comment area (¥ u ¥);
Design ideas
In order to download the latest version of zulujdk. Prepare to use Python to parse the download address of zulujdk, then download it to the server with wget, and finally use Nginx for directory mapping.
Environmental dependence
The environment dependence is very simple. In terms of hardware:
- Tencent cloud lightweight application server Debian image system: Python uses its wget module to call the system wget; The Windows operating system does not know whether wget can be called by python.
Software level:
- Python3.x: Core software for writing crawlers.
- Vim8.2 With YCM: text editor for writing Python scripts.
- PAW: network API test software, which can be replaced by curll and grep command.
Python's module dependencies:
requests==2.27.1 wget==3.2
Data acquisition
First look at the page: https://www.azul.com/downloads/
Discovery data interface:
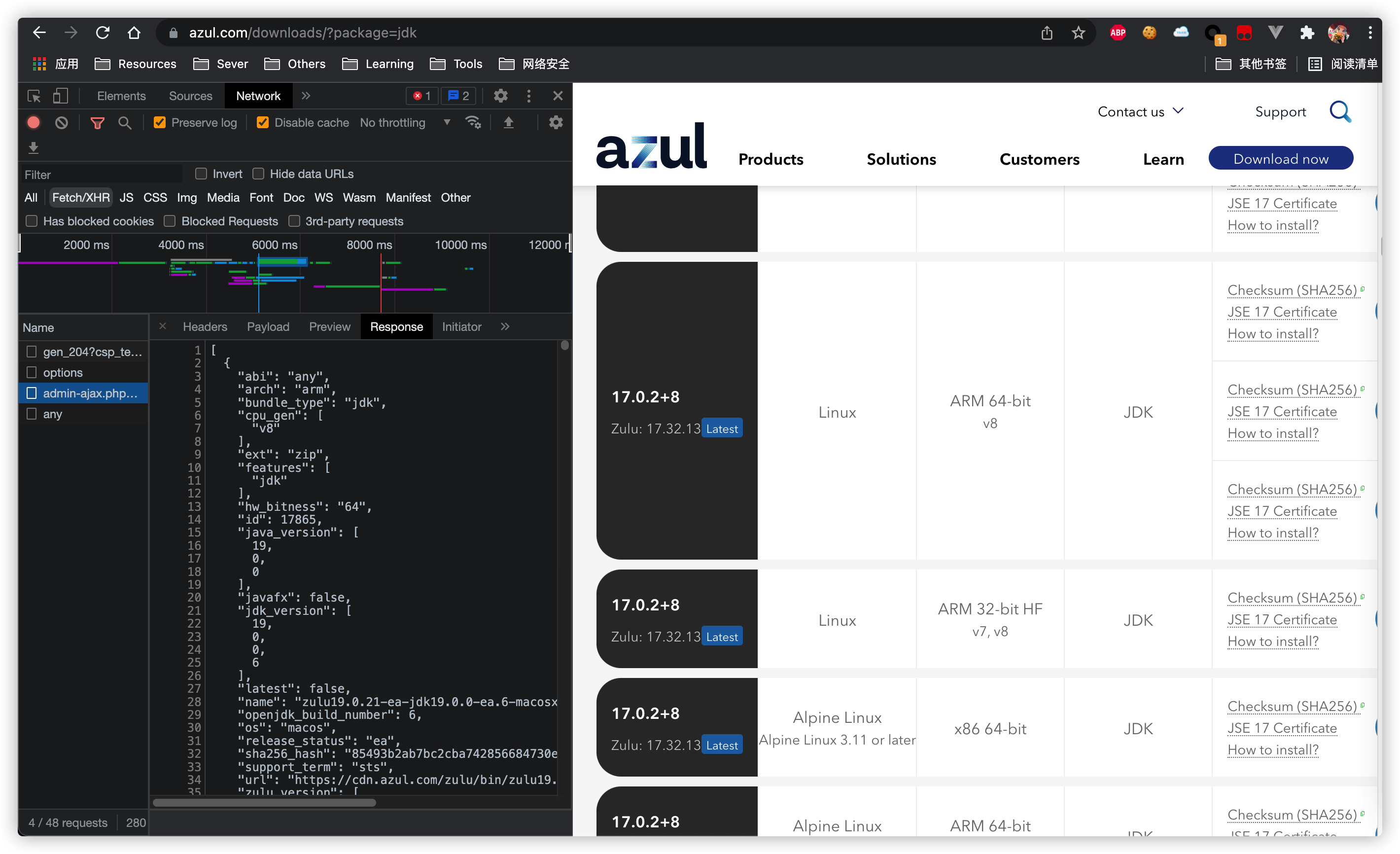
Copy its interface and use paw perhaps postman Test:
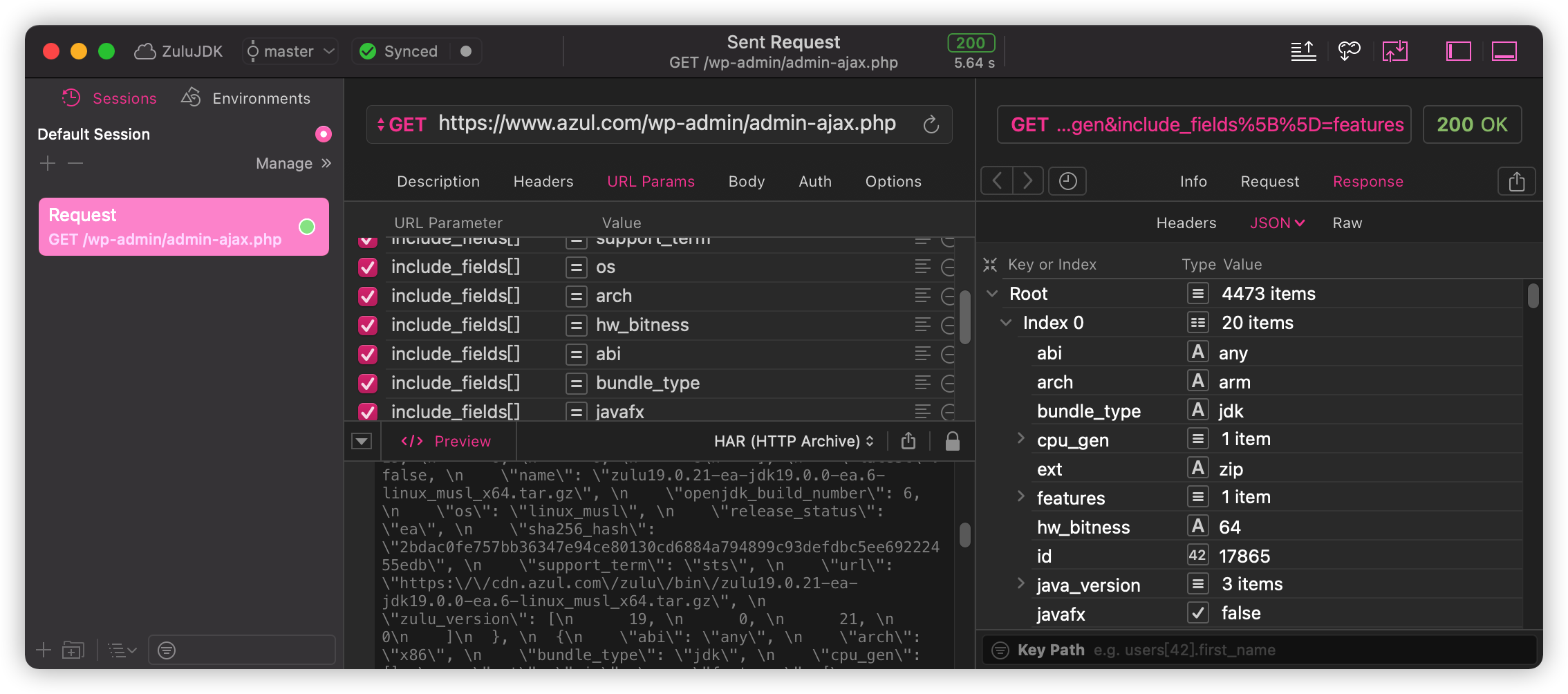
It is found that this is a pure JSON object, and the received request is well structured.
Then the design is too simple.
In Python, simulate the request with the requests library. The request header is:
URL = "https://www.azul.com/wp-admin/admin-ajax.php?action=bundles&endpoint=community&use_stage=false&include_fields%5B%5D=java_version&include_fields%5B%5D=os&include_fields%5B%5D=javafx&include_fields%5B%5D=latest&include_fields%5B%5D=ext"
HEADERS = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'x-csrf-token': '',
'x-requested-with': 'XMLHttpRequest',
'cookie': ''
,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}Send the request and parse it into JSON:
def get_zulu_json():
response = requests.get(url=URL,
headers=HEADERS).json()
return response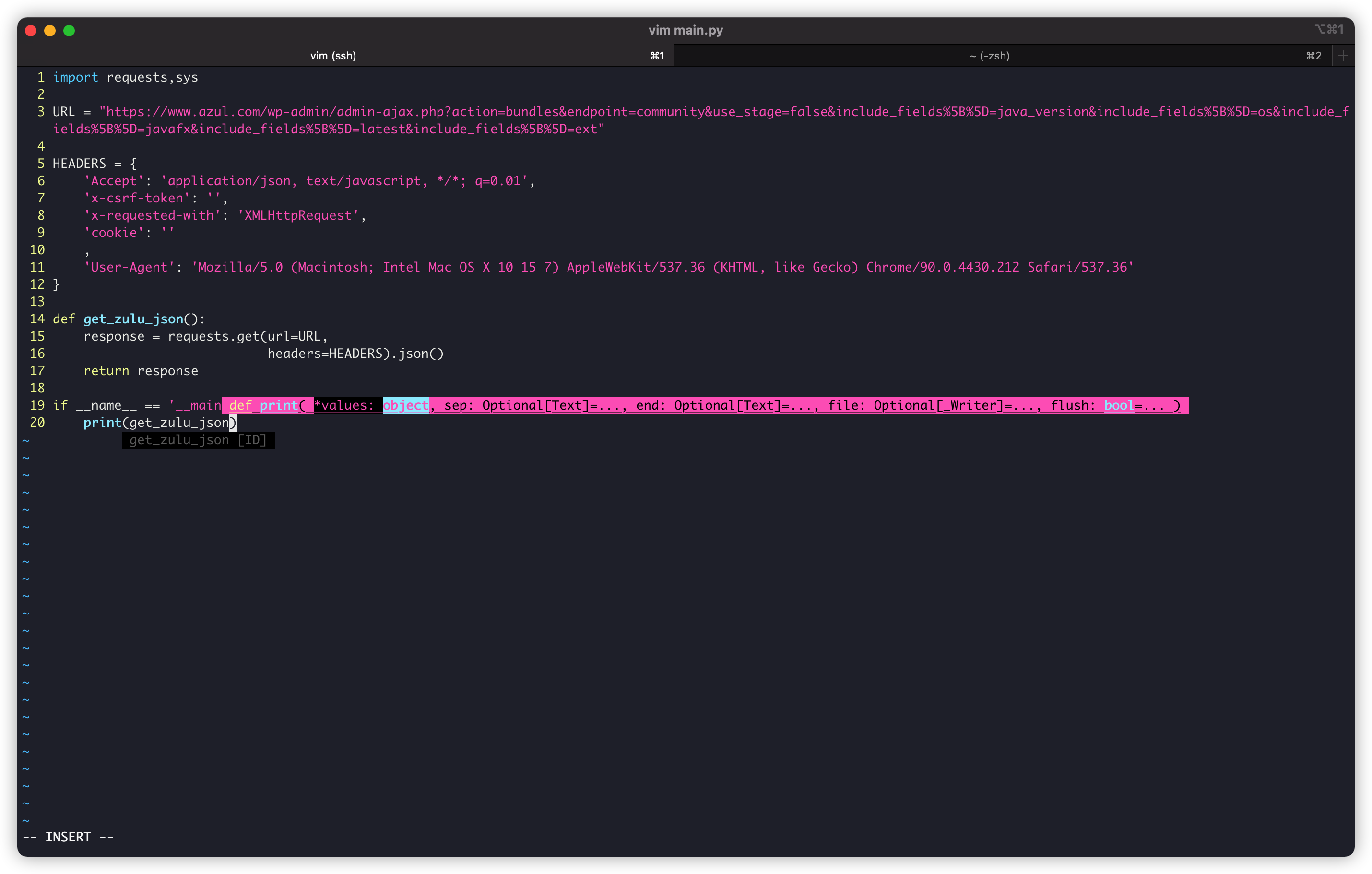
In this way, the version information of all ZuluJDK can be obtained:
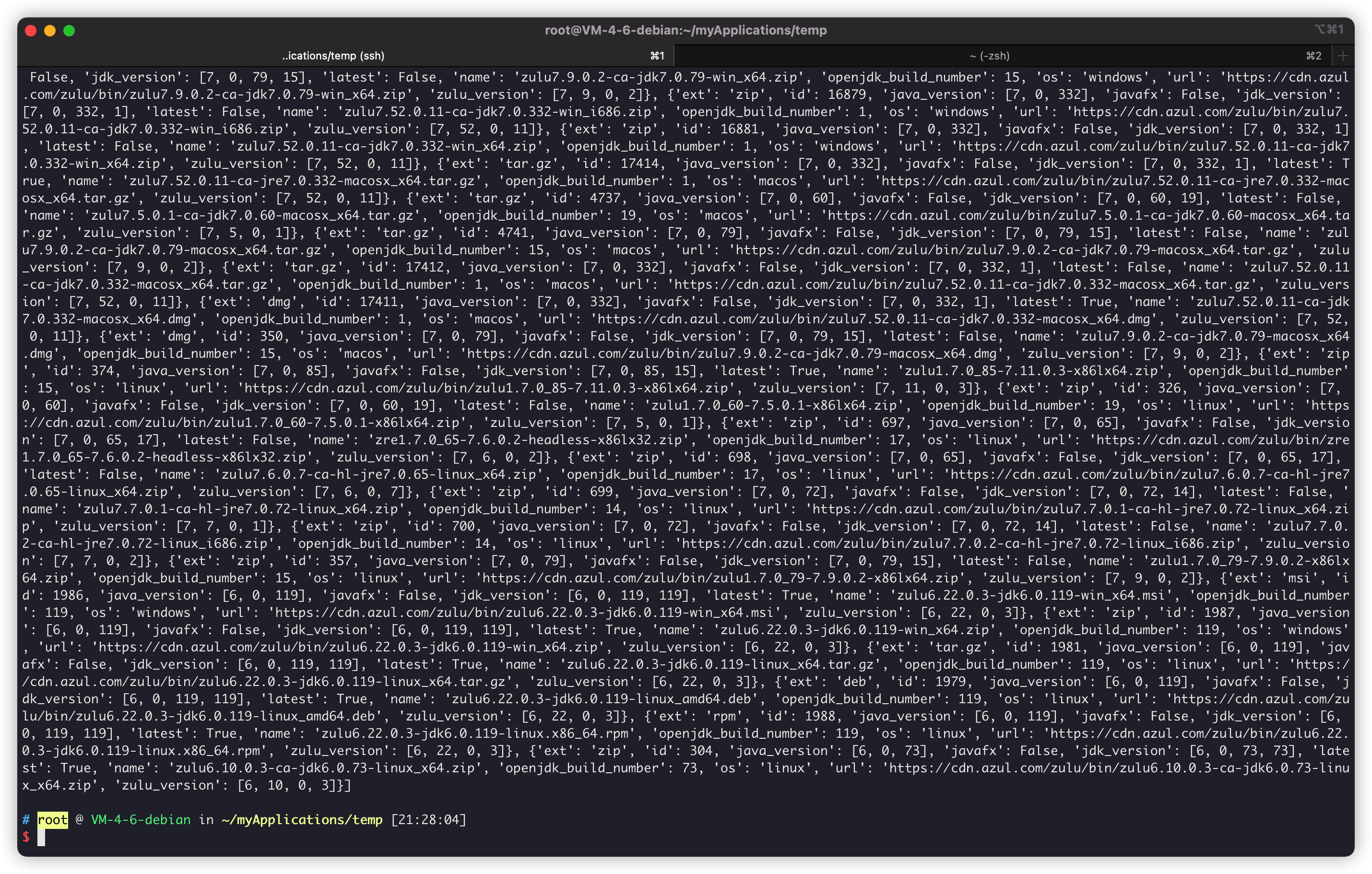
But this is a bit embarrassing. I didn't expect so many people to directly cover the console of my Tencent cloud lightweight application server
Poor little white cloud, it's all right!!! I'll take PAW to help you share the pressure ~ ~
PAW shows that there are 4473 items, obviously all the previous builds are here.
Zulu's server is so big... 4473 jdks / jres... At least 1T of storage space.
So we need to filter, abbreviated as: disassembly object ⁄ (⁄ ⁄ ⁄) ω⁄ ⁄ ⁄)⁄
data processing
It's easy to handle. Observe the properties of JSON objects, for example:
{
"abi": "any",
"arch": "arm",
"bundle_type": "jdk",
"cpu_gen": [
"v8"
],
"ext": "zip",
"features": [
"jdk"
],
"hw_bitness": "64",
"id": 17865,
"java_version": [
19,
0,
0
],
"javafx": false,
"jdk_version": [
19,
0,
0,
6
],
"latest": false,
"name": "zulu19.0.21-ea-jdk19.0.0-ea.6-macosx_aarch64.zip",
"openjdk_build_number": 6,
"os": "macos",
"release_status": "ea",
"sha256_hash": "85493b2ab7bc2cba742856684730ee42a8ee71d3d0a510770a5d0071a2622903",
"support_term": "sts",
"url": "https://cdn.azul.com/zulu/bin/zulu19.0.21-ea-jdk19.0.0-ea.6-macosx_aarch64.zip",
"zulu_version": [
19,
0,
21,
0
]
}, You can see that there are ext, latest, name and other parameters. Generally, JDK is configured by itself, and the operating system is generally Windows, Linux and macOS.
No one installed it with an installer, right? No, no, no... install it with the installer. Will it not be found when uninstalling ́︿ ̀。)
Zulujdk of macOS and Linux must be archive files (tar, tar.gz). Zulujdk of Windows is zip file, and os="windows".
So we filter it twice. (remove the object twice, Wuhu, I'm good or bad)
macOS/Linux
So we filter JSON:
def filter_by(zulu_info, latest=None, javafx=None, ext=None, os=None):
params = locals()
params.pop('zulu_info')
for key in params:
if params[key] is None:
continue
if zulu_info.get(key) != params[key]:
return False
return True
download_list=list(filter(lambda x: filter_by(x, javafx=True, ext="tar.gz"), zulu_json))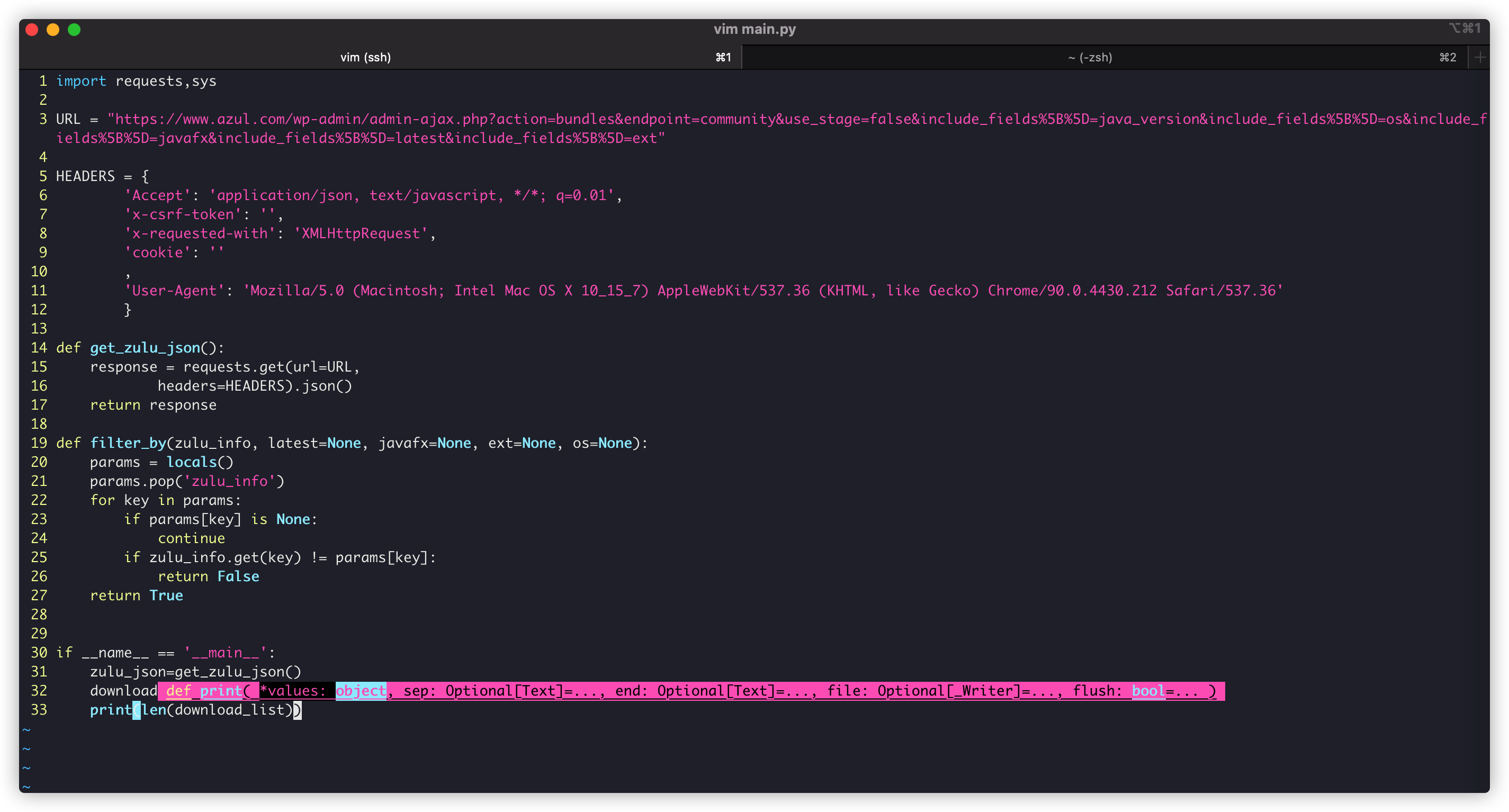
Of which:
- zulu_json: the JSON obtained from the above data crawl (that is, the ◡ JSON ヽ of more than 4000 objects)` Д ´)ノ ┻━┻)
Calculate the length:

That's good. There are only 342 items.
But there is JRE here, and the little partner still needs JRE???
Cut it directly!!! And you can find that the earlier the data, the newer the version of this JSON object. Let's just buffer and download the latest version at a time:
# For counting
temp_list = {}
for item in filtered_list:
# Regular judge whether it is JDK
if re.search(r"jdk", item['name']) is None:
# Not JDK, skip the loop directly
continue
# Check the JDK Version (large version, such as JDK11, JDK17, etc.)
jdk_version_code = str(item['jdk_version'][0])
# Splicing is in the form of system + JDK version
OS_version = jdk_version_code + item['name'].split("-")[-1]
# If the object exists, jump out of the loop directly
if OS_version in temp_list.keys():
continue
else:
temp_list[OS_version] = 1,In this way, it can be ensured that each large version of each system can be downloaded only once:
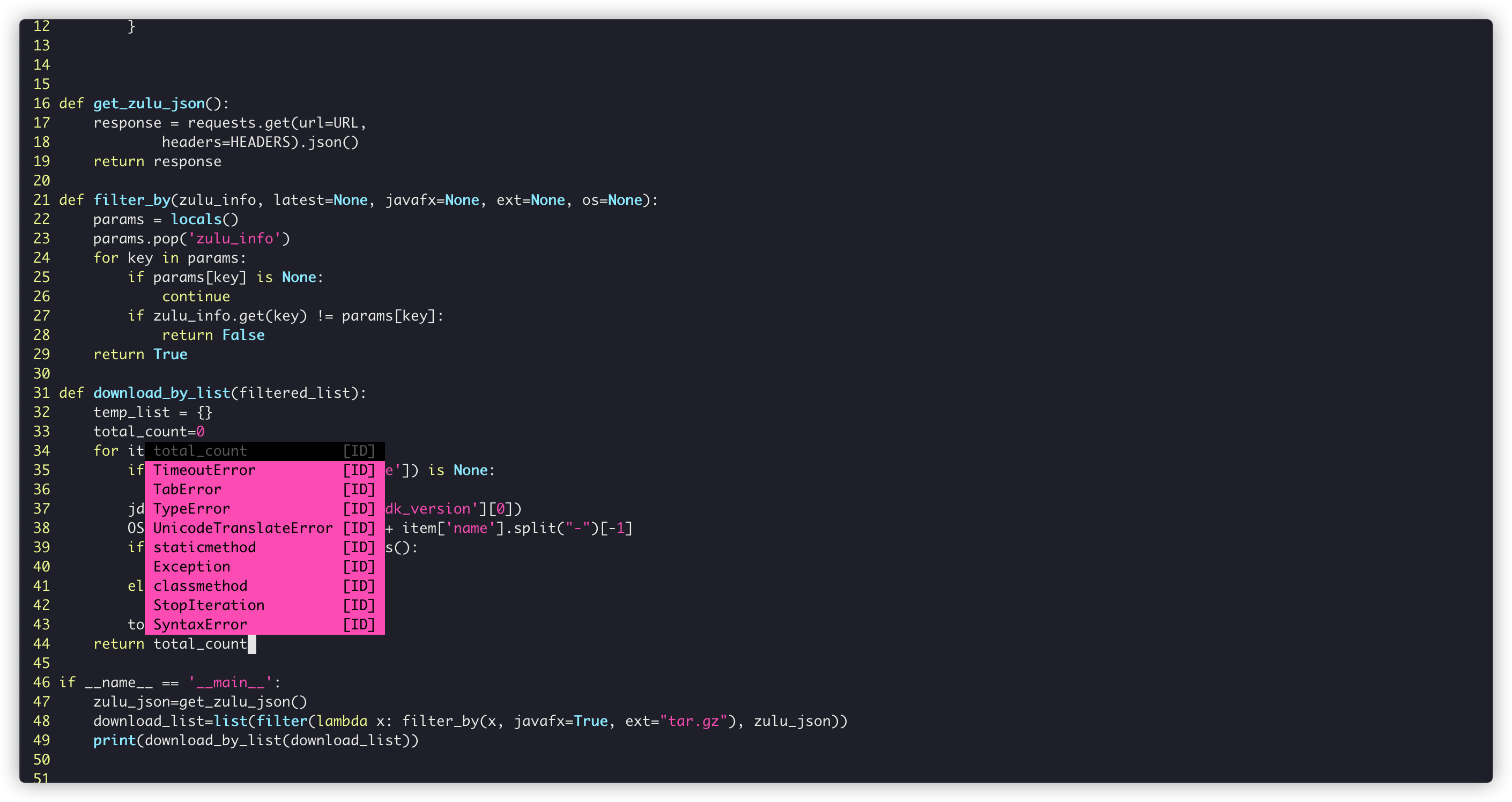

It can be seen that in this way, 342 items will become only 27 items (macOS/Windows)
Windows
The method of filtering and downloading macOS and Linux in Windows is the same:
download_list=list(filter(lambda x: filter_by(x, javafx=True, ext="zip",os="windows"), zulu_json))
Just like the Linux method just now, filter out the JRE and leave only the latest version:
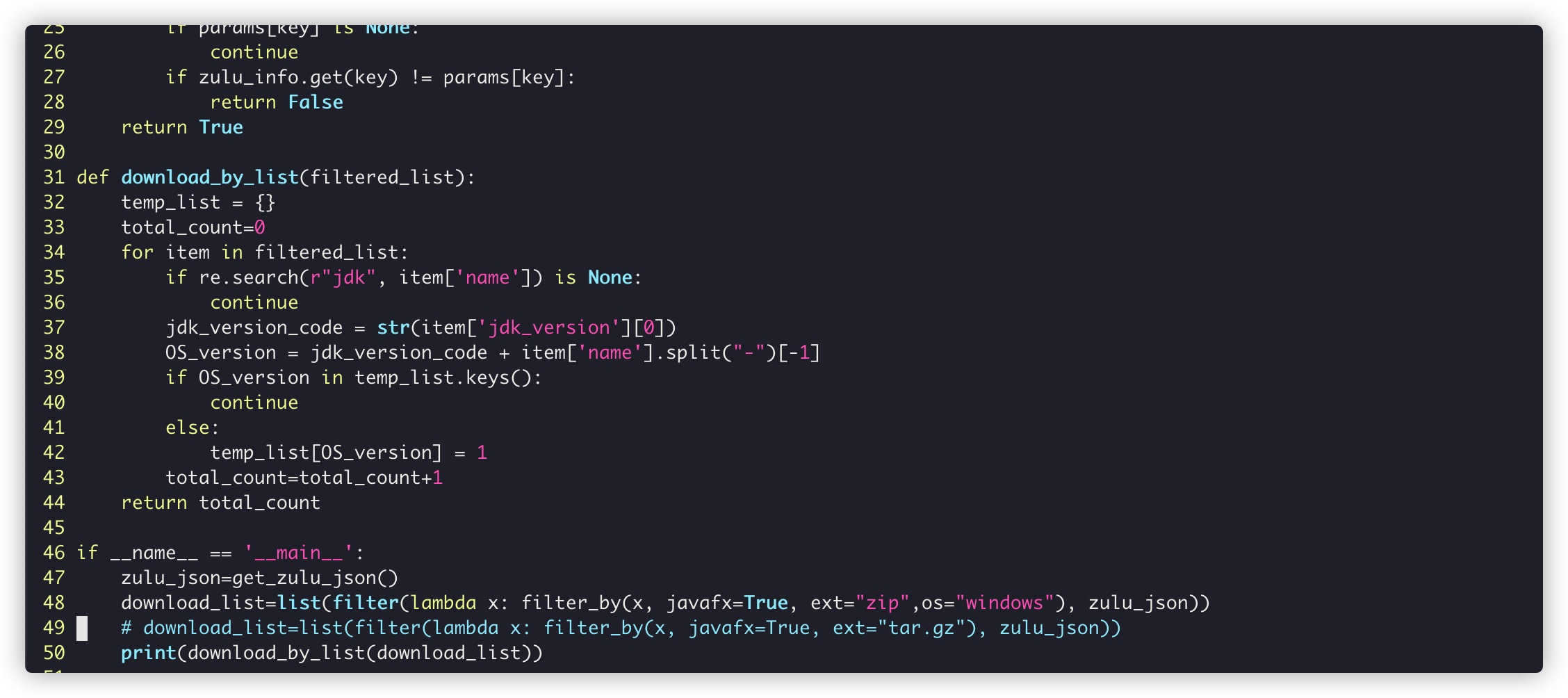

In this way, there is not much content to download (27 + 12)
Download JDK
Finally, we download it. Here, wget is used to download the data; Python wget module: https://pypi.org/project/wget/
This is not the wget tool of GNU. It is used to call wget in Python for download.
Install wget module:
pip3 install wget

Define a download directory:
def has_dir(path):
if not os.path.exists(path):
os.makedirs(path)Code for subsequent incomplete filtering:
def download_by_list(filtered_list):
temp_list = {}
for item in filtered_list:
if re.search(r"jdk", item['name']) is None:
continue
jdk_version_code = str(item['jdk_version'][0])
OS_version = jdk_version_code + item['name'].split("-")[-1]
if OS_version in temp_list.keys():
continue
else:
temp_list[OS_version] = 1,
# Set wget download directory
save_path = "ZuluJDK_Mirror/" + jdk_version_code + "/"
# Determine whether the directory exists
has_dir(save_path)
print("Start download:" + item['name'])
# download
wget.download(item['url'], out=save_path + item['name'])
print("\n")
# Thread sleep
time.sleep(20)Final effect
Finally, the Python script we wrote:
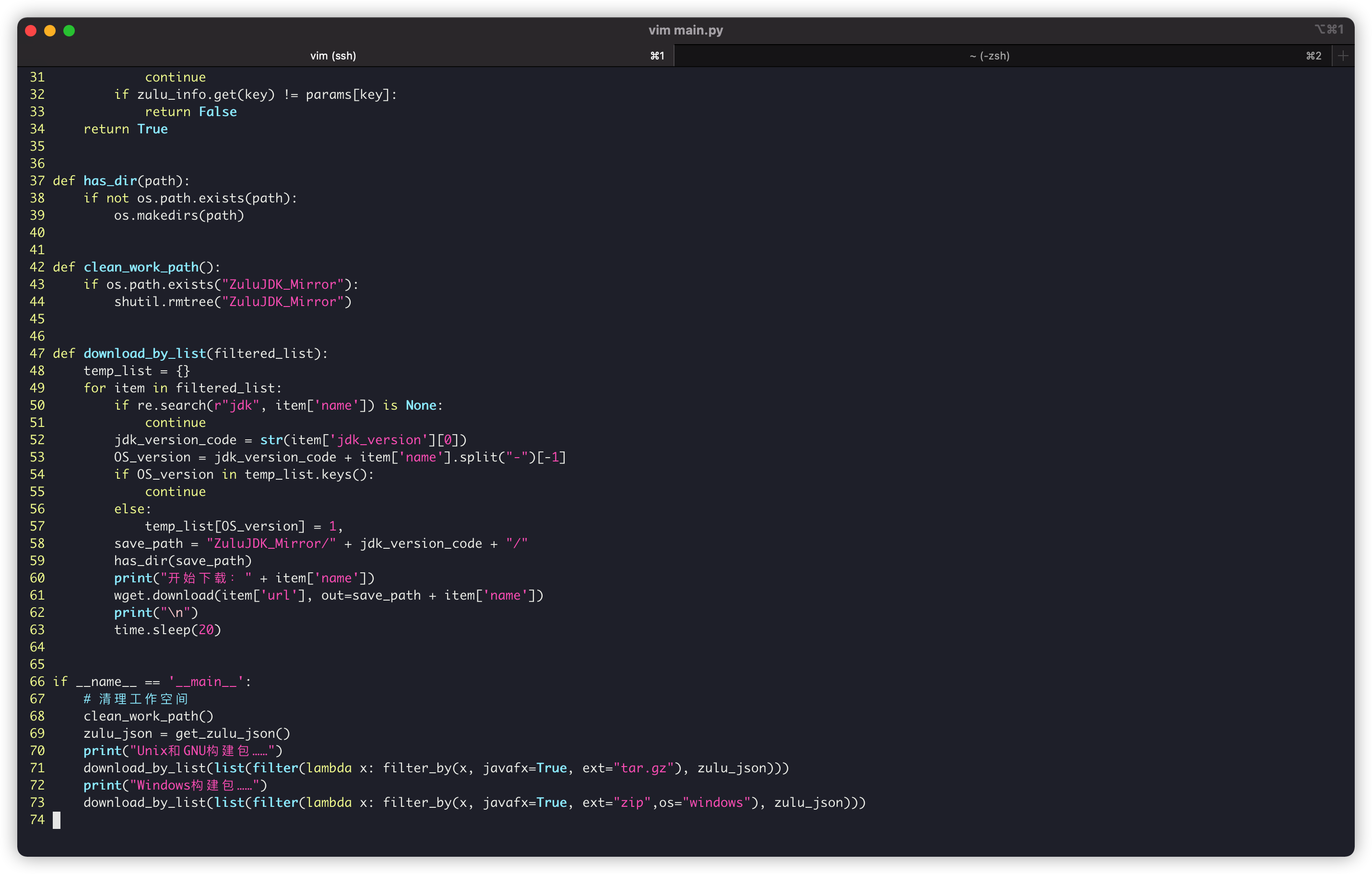
Run with Python commands:
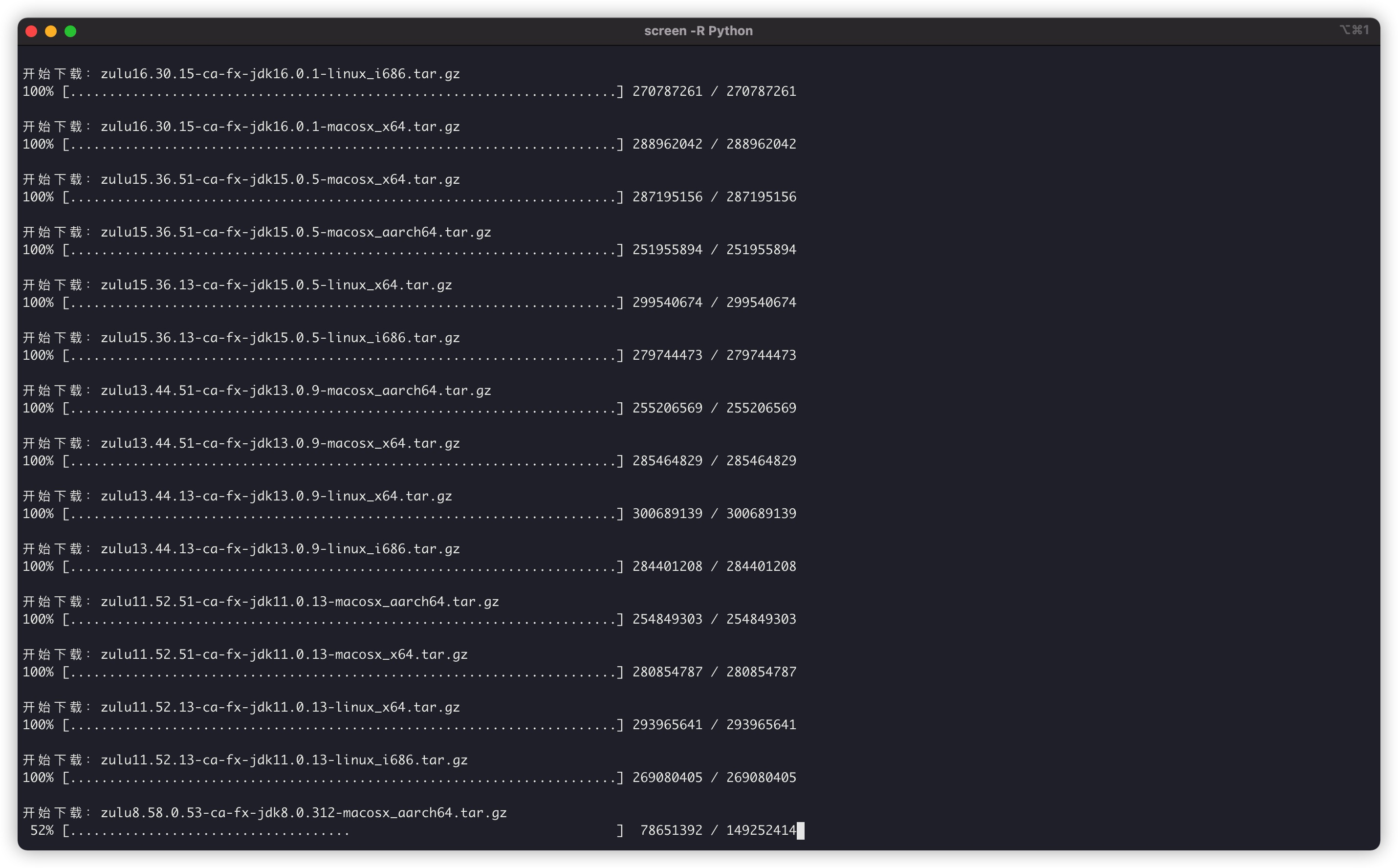
Last downloaded file:
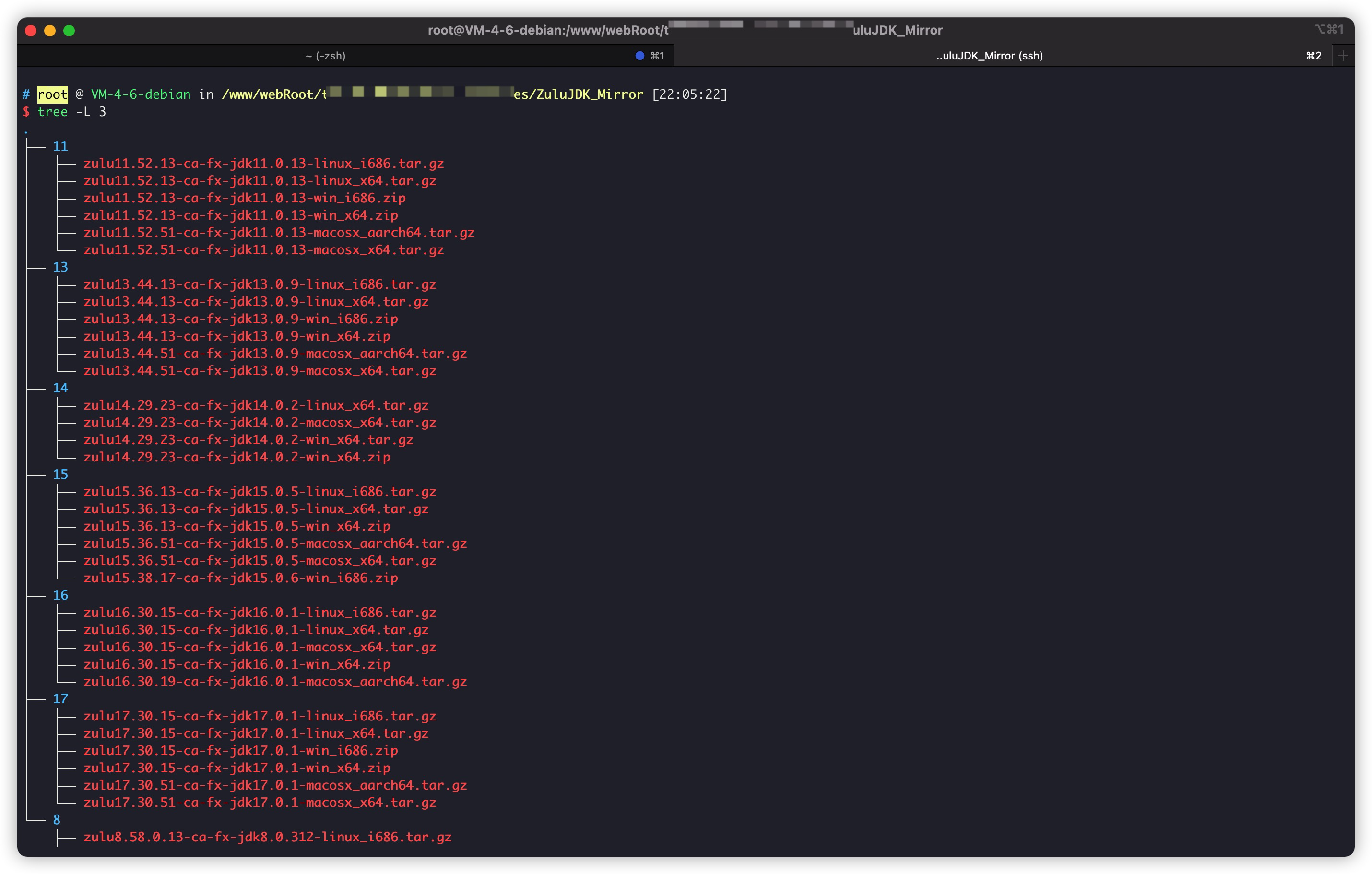
Use Nginx for directory mapping:
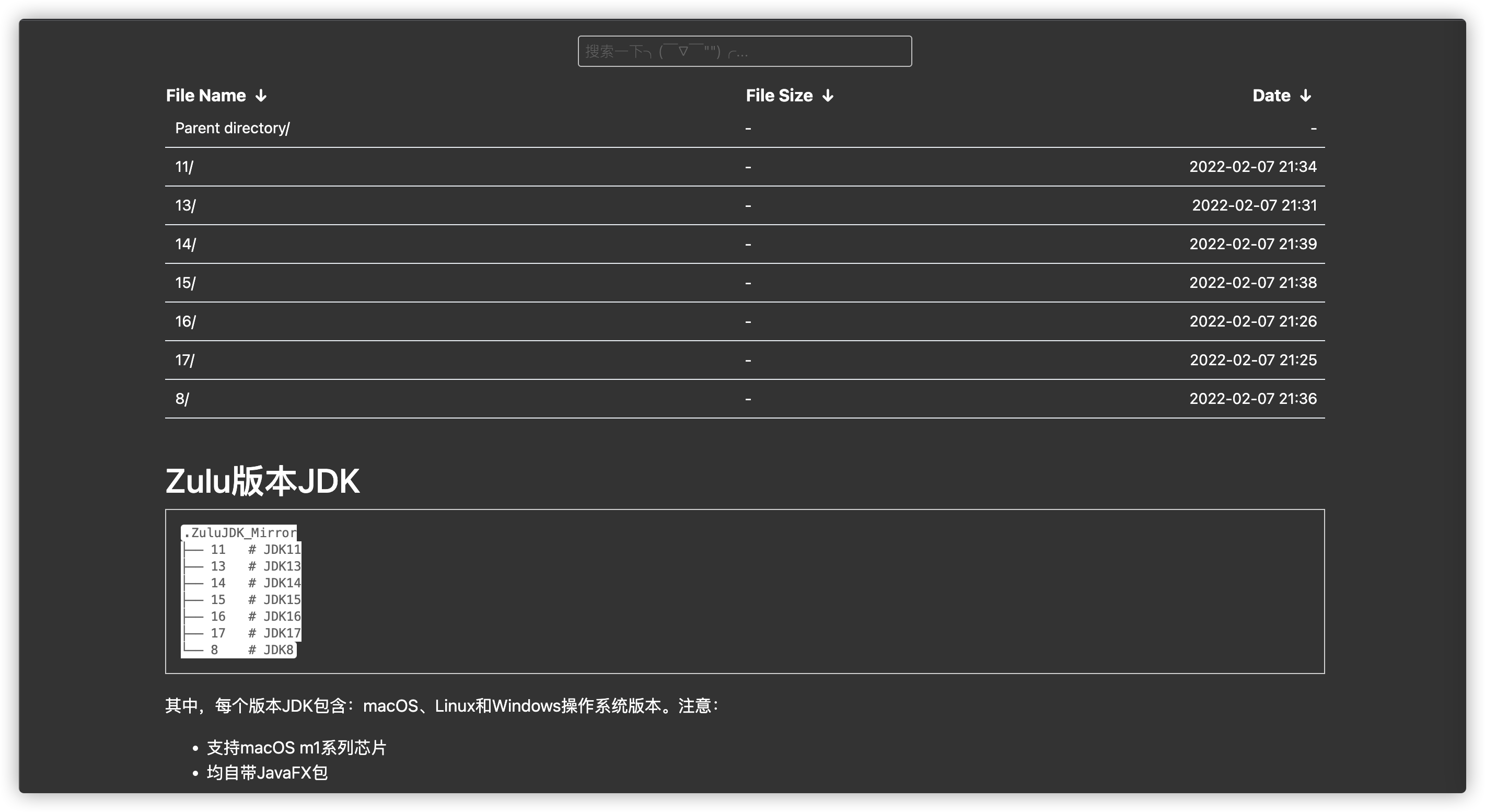
We can use the latest version of cruzon regularly, of course.
END
Finally, we can send the address of Nginx directory mapping to the little partner who wants to download ZuluJDK.
In addition... I suddenly found that: I directly analyzed the straight chain of ZuluJDK and reversed it with Nginx... It seems more convenient; Don't take up server space yet!!!
However, it's better to ensure the persistence of resources ~ ~ ~ moreover, the hard disk resources in Hong Kong, China of Tencent cloud lightweight application server are used more fully and enjoy the happiness of making their own "wheels" (* ☻ - ☻ *)