1, Introduction
In actual business, we may use crawlers to obtain historical data of Baidu search index according to keywords, and then conduct corresponding data analysis.

Baidu Index, experience the beauty of big data. However, the difficulties in obtaining data related to Baidu Index are as follows:
-
It is not a static web page, and the data returned by the URL request address of Baidu Index cannot be directly parsed by json, but the encrypted data and uniqid. You need to request the corresponding URL again through uniqid to obtain the key for decryption, decrypt it on the front page, and then render it to the broken line graph.
-
You must log in to baidu account (get cookies) on Baidu Index page.
-
You need to convert the front-end decryption code into Python back-end code, or directly use execjs to execute JavaScript code.
Taking the Baidu search index data of recent days as an example, this paper explains the process of using Baidu crawler to obtain the historical data of Baidu search index according to keywords (taking the Winter Olympic Games as an example), then visualizes the search index of the Winter Olympic Games in recent 90 days, and collects the materials reported by the media to make word cloud pictures.
-
Environment: Anaconda + pychar
-
Main libraries used: requests, execjs, datetime, pandas, matplotlib, stylecloud
2, Web page analysis
If you don't have a baidu account, you need to register first and then enter the Baidu Index official website:
https://www.baidu.com/s?wd= baidu index
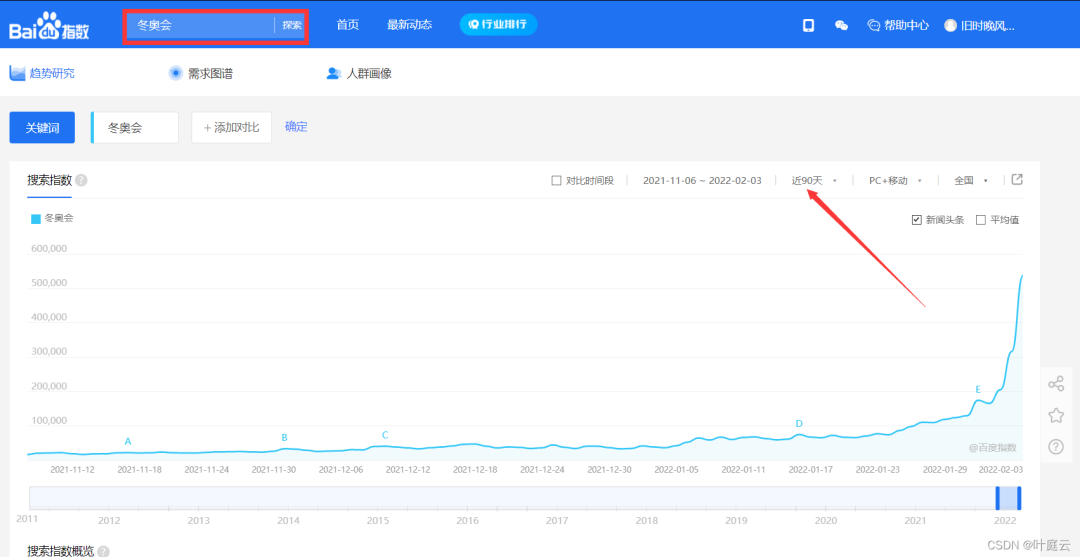
Search the Winter Olympics and select nearly 90 days to see the broken line chart of the search index of the Winter Olympics in recent 90 days:
The final thing to do is to get these search index data and save it to local Excel.
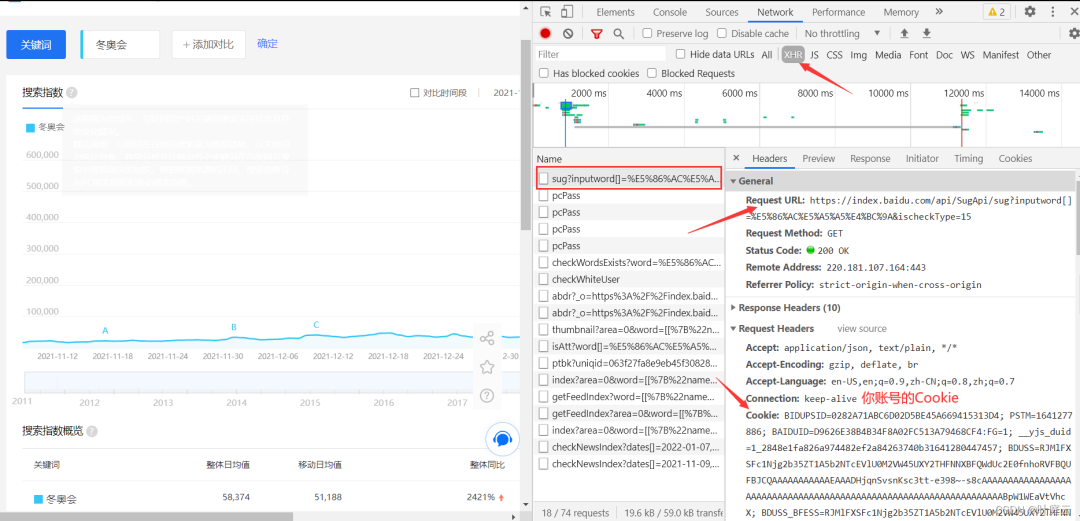
First, obtain the Cookie after you log in (there must be one, otherwise you cannot obtain the data). The specific Cookie acquisition is shown in the figure below:
The interface of json data can be found through analysis, as shown below:
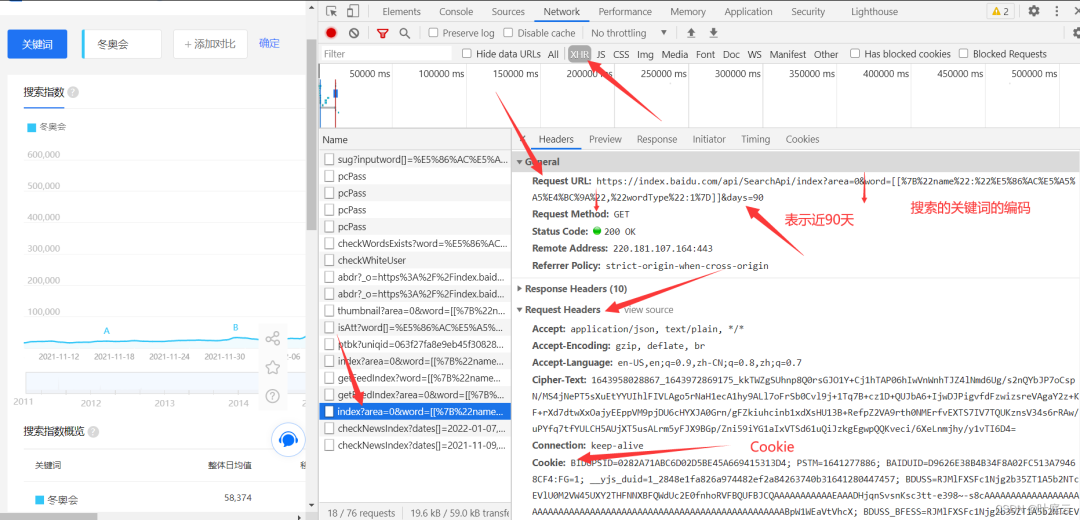
In the Request URL, after the word parameter is the search keyword (only the Chinese characters are encoded), days=90, which represents the data of nearly 90 days. It is pushed forward one month from the day before the current date. You can modify days as needed to obtain more data or less data. Paste the Request URL into the browser to access and view (it is convenient to have a plug-in such as JSON Handle when viewing JSON data web pages)
https://index.baidu.com/api/SearchApi/index?area=0&word[[%7B%22name%22:%22%E5%86%AC%E5%A5%A5%E4%BC%9A%22,%22wordType%22:1%7D]]&days=90
You can see the following data:
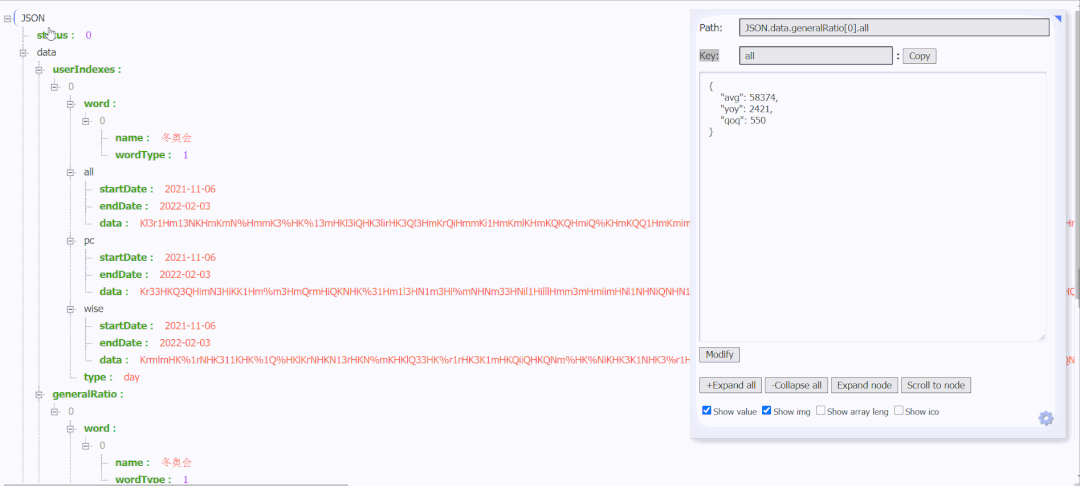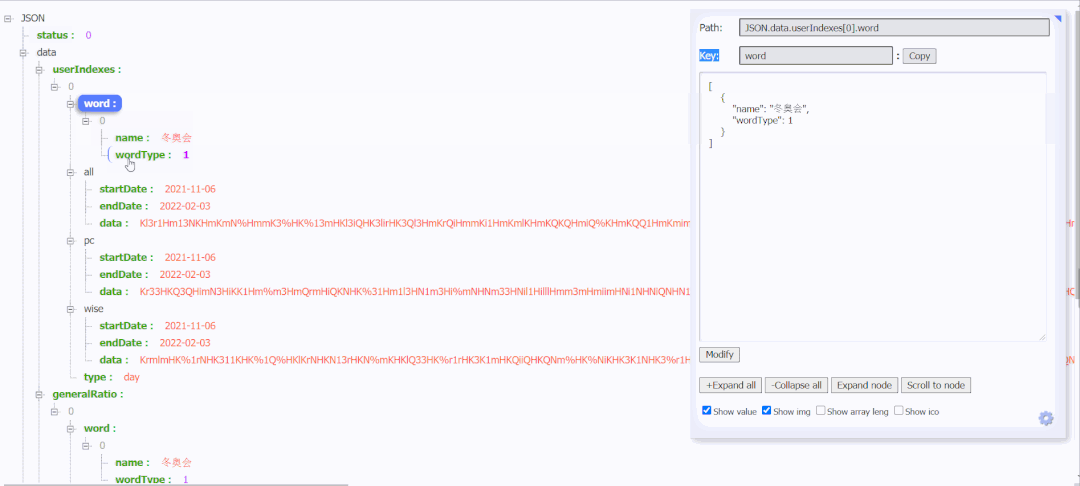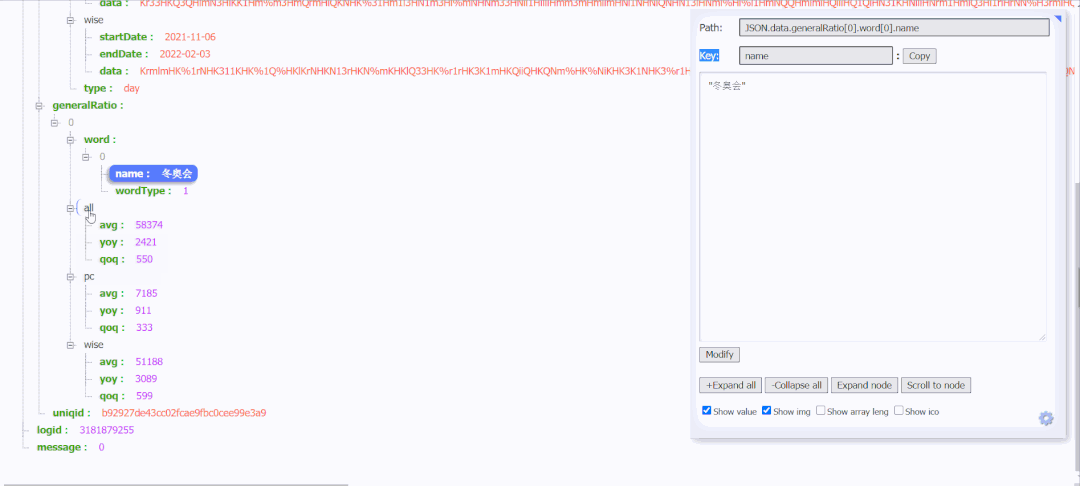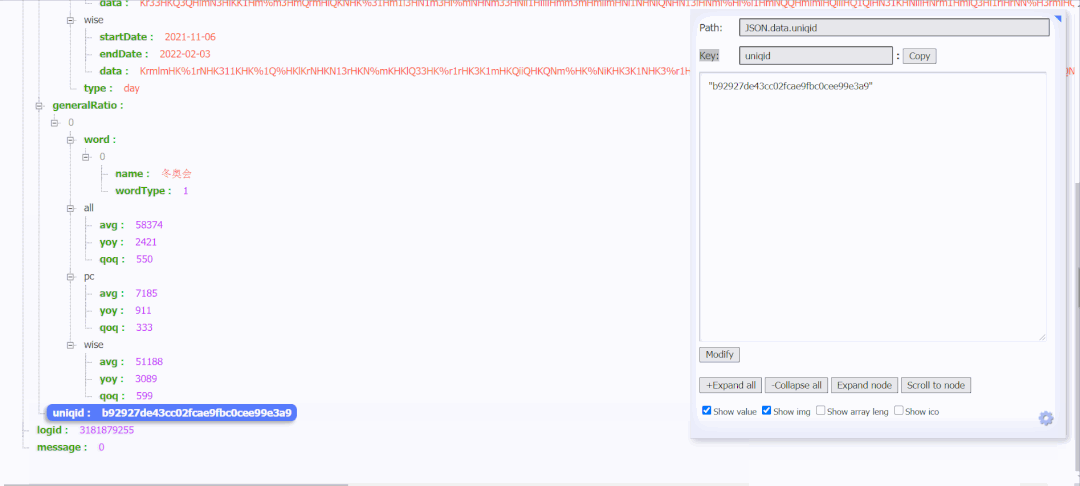
After decrypting the data corresponding to all, pc and wise, and comparing with the data displayed in the broken line diagram of the search index, it is found that the data of {all is the data of the search index. Here are all the data returned from this request. You can also see the uniqid, and the encrypted data and uniqid will change every time you refresh.
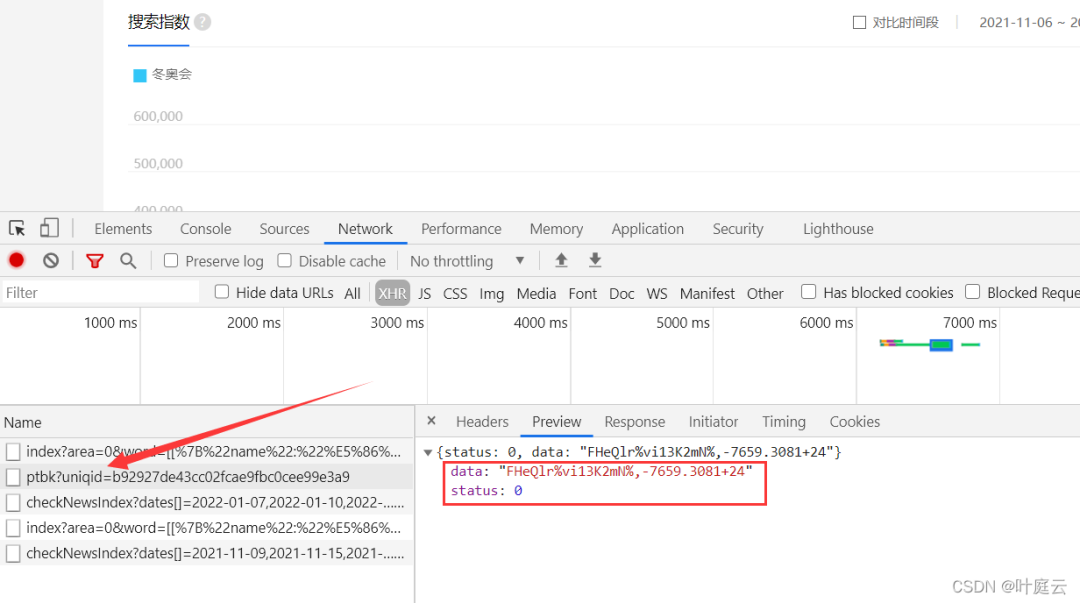
After multiple analysis, it is found that the uniqid under the url of the request data appears in this url, as shown above.
Therefore, it is necessary to get data from the corresponding url of the request data first, to analyze the encrypted data and uniqid corresponding to the search index, then to splice the url to get the key, and finally to decrypt the decryption method to get the data of the search index.
https://index.baidu.com/Interface/ptbk?uniqid=b92927de43cc02fcae9fbc0cee99e3a9
After finding the corresponding url, the basic idea of the crawler is the same: Send a request, obtain a response, parse the data, decrypt the data and save the data.
3, Data acquisition
Python code:
# -*- coding: UTF-8 -*-
"""
@Author : Ye Tingyun
@official account : AI Yun Jun Ting
@CSDN : https://yetingyun.blog.csdn.net/
"""
import execjs
import requests
import datetime
import pandas as pd
from colorama import Fore, init
init()
# Python code for decryption of search index data
def decryption(keys, data):
dec_dict = {}
for j in range(len(keys) // 2):
dec_dict[keys[j]] = keys[len(keys) // 2 + j]
dec_data = ''
for k in range(len(data)):
dec_data += dec_dict[data[k]]
return dec_data
if __name__ == "__main__":
# Beijing Winter Olympics Opening Ceremony
keyword = 'Beijing Winter Olympics' # Keywords included in Baidu search
period = 90 # Nearly 90 days
start_str = 'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22'
end_str = '%22,%22wordType%22:1%7D]]&days={}'.format(period)
dataUrl = start_str + keyword + end_str
keyUrl = 'https://index.baidu.com/Interface/ptbk?uniqid='
# Request header
header = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'Note: replace it with yours Cookie',
'Host': 'index.baidu.com',
'Referer': 'https://index.baidu.com/v2/main/index.html',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
# Set the request timeout to 16 seconds
resData = requests.get(dataUrl,
timeout=16, headers=header)
uniqid = resData.json()['data']['uniqid']
print(Fore.RED + "uniqid: {}".format(uniqid))
keyData = requests.get(keyUrl + uniqid,
timeout=16, headers=header)
keyData.raise_for_status()
keyData.encoding = resData.apparent_encoding
# Parsing json data
startDate = resData.json()['data']['userIndexes'][0]['all']['startDate']
print(Fore.RED + "startDate: {}".format(startDate))
endDate = resData.json()['data']['userIndexes'][0]['all']['endDate']
print(Fore.RED + "endDate: {}".format(endDate))
source = (resData.json()['data']['userIndexes'][0]['all']['data']) # Original encrypted data
print(Fore.RED + "Original encrypted data:{}".format(source))
key = keyData.json()['data'] # secret key
print(Fore.RED + "Key:{}".format(key))
res = decryption(key, source)
# print(type(res))
resArr = res.split(",")
# Generate datetime
dateStart = datetime.datetime.strptime(startDate, '%Y-%m-%d')
dateEnd = datetime.datetime.strptime(endDate, '%Y-%m-%d')
dataLs = []
# Every day from the start date to the end date
while dateStart <= dateEnd:
dataLs.append(str(dateStart))
dateStart += datetime.timedelta(days=1)
# print(dateStart.strftime('%Y-%m-%d'))
ls = []
# Organize data and traverse print view
for i in range(len(dataLs)):
ls.append([keyword, dataLs[i], resArr[i]])
for i in range(len(ls)):
print(Fore.RED + str(ls[i]))
# Save data to Excel and set column name
df = pd.DataFrame(ls)
df.columns = ["key word", "date", "Baidu search index"]
df.to_excel("Beijing Winter Olympics search index data 90 days.xlsx", index=False)The results are as follows:
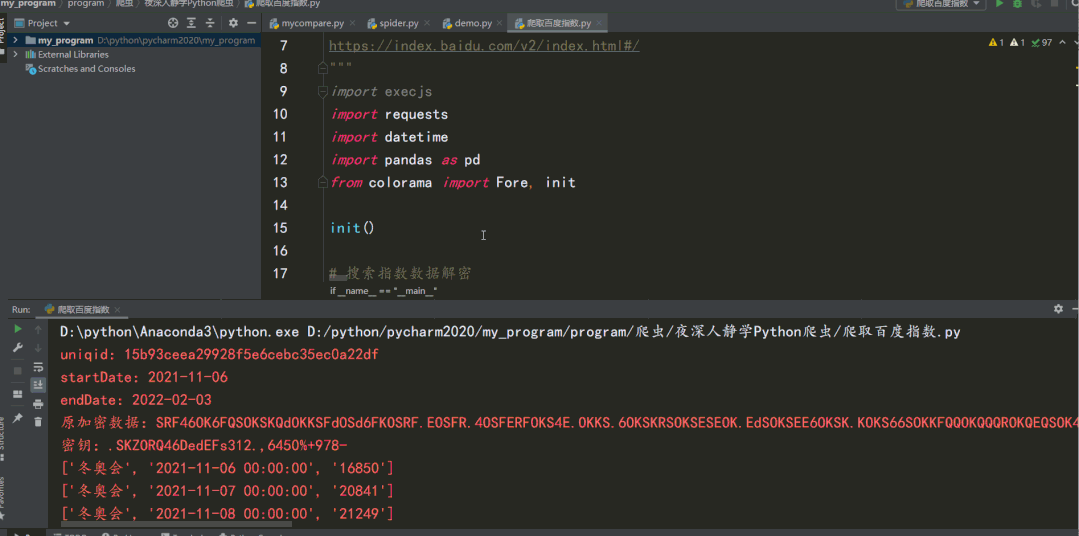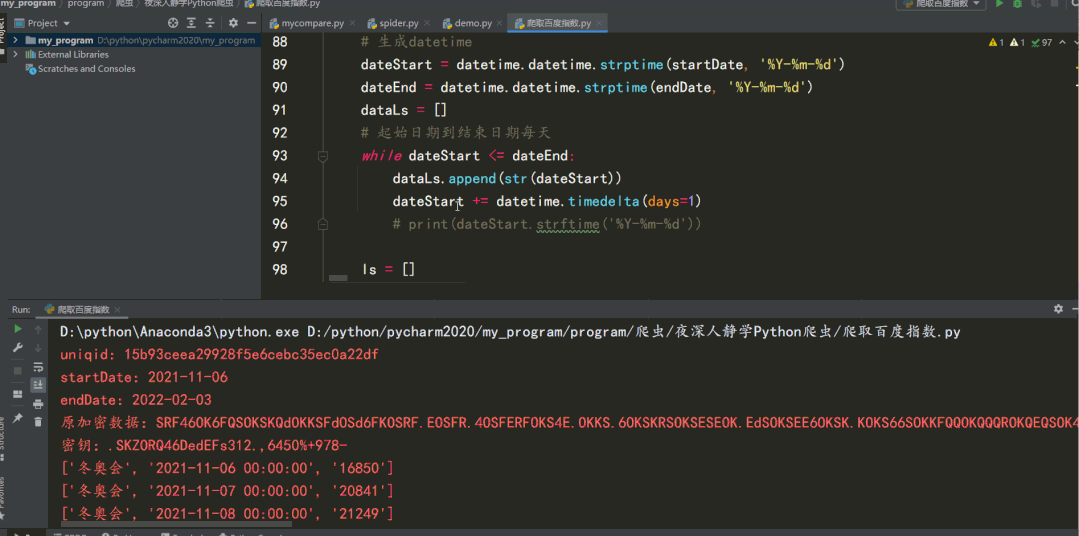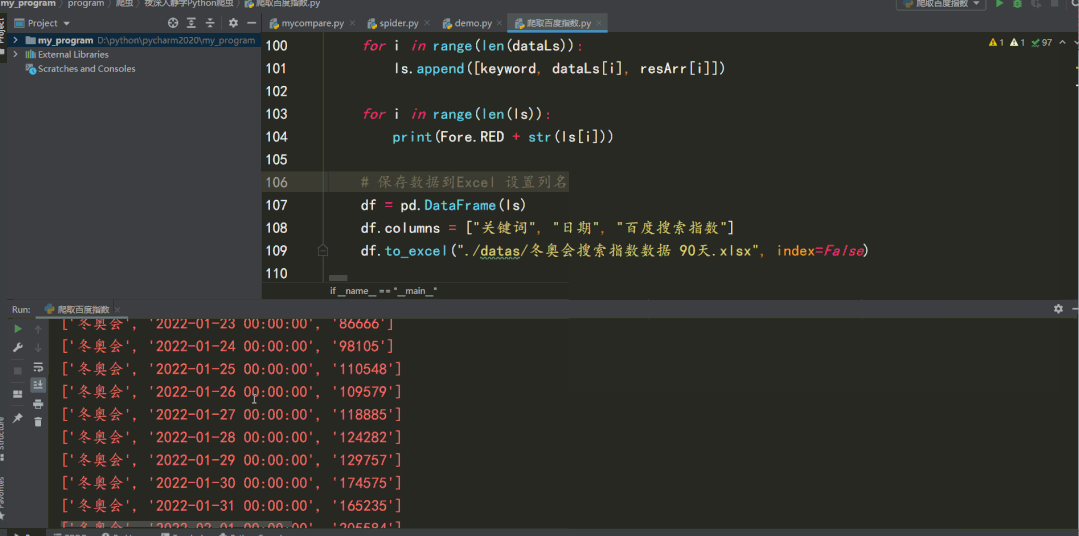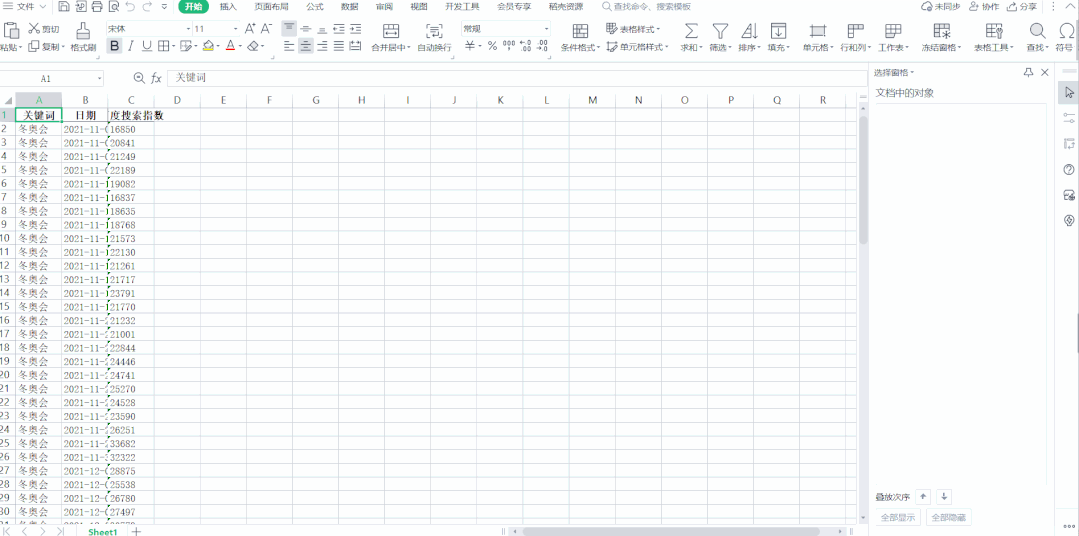
The decryption part can also be directly implemented using JavaScript, as shown in the following figure:
# The strength of Python is that it has a powerful third-party library, which can directly execute js code, that is, if you are not familiar with the decryption algorithm and you cannot write Python code, you can directly execute js code
js = execjs.compile('''
function decryption(t, e){
for(var a=t.split(""),i=e.split(""),n={},s=[],o=0;o<a.length/2;o++)
n[a[o]]=a[a.length/2+o]
for(var r=0;r<e.length;r++)
s.push(n[i[r]])
return s.join("")
}
''')
res = js.call('decryption', key, source) # Call this method to decrypt
res = decryption(key, source)Python crawler runs successfully, and the data is saved as the Winter Olympics search index data for 90 days xlsx.
4, Search index visualization
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import math
import warnings
warnings.filterwarnings("ignore")
df1 = pd.read_excel("Winter Olympics opening ceremony search index data 90 days.xlsx")
df2 = pd.read_excel("Beijing Winter Olympics search index data 90 days.xlsx")
mpl.rcParams['font.family'] = 'SimHei'
# Generate derivation of x-axis data list
# x_data = [i for i in range(1, len(df1) + 1)]
x_data = [i for i in range(1, len(df1) - 1)]
y_data1 = df1["Baidu search index"][:-2]
y_data2 = df2["Baidu search index"][:-2]
# Set figure pixel size
fig, ax = plt.subplots(figsize=(6, 4), dpi=500)
# Draw the shape color label of three polyline points: for legend display
plt.plot(x_data, y_data1,
color="#FF1493", label =" opening ceremony of Winter Olympics ")
plt.plot(x_data, y_data2,
color="#00BFFF", label =" Beijing Winter Olympics ")
# x y axis label font size
plt.xlabel("Chronological order",
fontdict={"size": 15, "weight": "bold", "color": "black"})
plt.ylabel("Baidu search index",
fontdict={"size": 15, "weight": "bold", "color": "black"}
)
# Sets the size of the axis scale label
plt.tick_params(axis='x', direction='out',
labelsize=12, length=4.6)
plt.tick_params(axis='y', direction='out',
labelsize=12, length=4.6)
# Show Legend
plt.legend(fontsize=15, frameon=False)
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontname('Times New Roman') for label in labels]
[label.set_color('black') for label in labels]
plt.grid(alpha=0.7, ls=":")
# Show show
plt.show()The results are as follows:
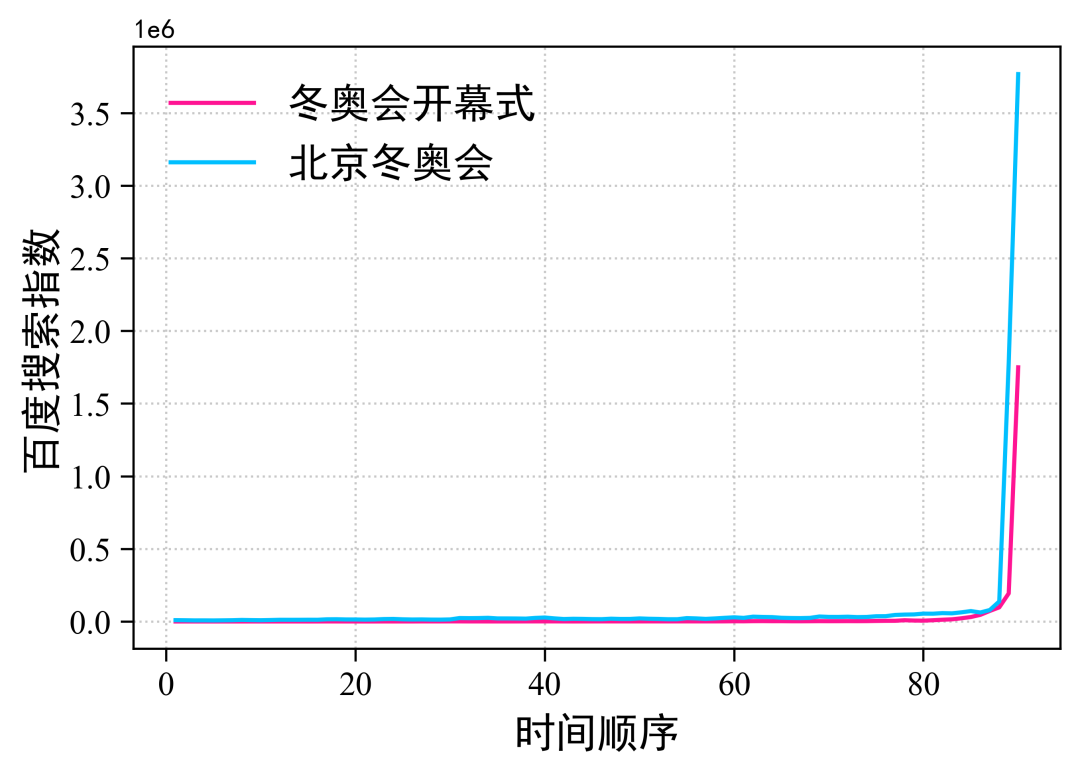
Please add picture description
The search index of the opening ceremony of the Winter Olympic Games and the Beijing Winter Olympic Games has soared in a straight line in recent days. It shows that everyone is very concerned.

Science and technology, humanities, romance and passion are now united. In the name of the Olympics. Write a beautiful chapter in the community with a shared future for mankind. I also wish you a complete success in this year's Beijing Winter Olympics!! 🏆🏆❤️❤️
5, Word cloud picture
Many media are rushing to cover the opening ceremony of the Winter Olympics. Collect some text materials here and make a word cloud picture to have a look.
with open("Opening ceremony of Winter Olympics.txt", encoding="utf-8") as f:
data = f.read()
# Text preprocessing removes some useless characters and only extracts Chinese characters
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# Precise mode of text word segmentation
seg_list_exact = jieba.cut(new_data, cut_all=False)
# Load stop words
with open('stop_words.txt', encoding='utf-8') as f:
# Get the stop word of each line and add it to the collection
con = f.read().split('\n')
stop_words = set()
for i in con:
stop_words.add(i)
# List parsing removes stop words and single words
result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1]
print(result_list)
# https://fontawesome.com/license/free
# The palette color scheme recommended by me works very well. I felt it was average after other tests~~
# colorbrewer.qualitative.Dark2_7
# cartocolors.qualitative.Bold_5
# colorbrewer.qualitative.Set1_8
gen_stylecloud(
text=' '.join(result_list), # Text data
size=600, # Word cloud size
font_path='./font/Cat gnawing net sugar round body.ttf', # Font needs to be set for Chinese word cloud display
icon_name = "fas fa-grin-beam", # Icon
output_name='Opening ceremony of Winter Olympics.png', # Output word cloud name
palette='colorbrewer.qualitative.Set1_8', # Select color scheme
)If we say that in the 2008 Olympic Games, China showed the world the beauty of traditional culture! So this winter Olympics, China has perfectly demonstrated to the world what is the rapid change and take-off of science and technology!

6, Summary
The opening ceremony of this year's Winter Olympic Games is really beautiful and amazing all over the world!
Summary:
-
Python crawler: obtain historical data of Baidu search index according to keywords
-
Parse JSON data, decrypt encrypted data, and save the data to Excel
-
matplotlib: visualization of Baidu search index
-
stylecloud: draw word cloud
end: that's all for sharing. I like to make up a three company for Xiao!
To get more complete source code and Python learning materials, click this line of font