
Guide: many friends analyze data for two minutes and run for two hours? In the process of using SQL, we should not only pay attention to the data results, but also pay attention to the execution efficiency of SQL statements.

This article involves three parts with a long length. It is suggested to read it after collection:
-
SQL introduction
-
SQL optimization method
-
SQL optimization instance

01
Basic architecture of MySQL
1) MySQL infrastructure
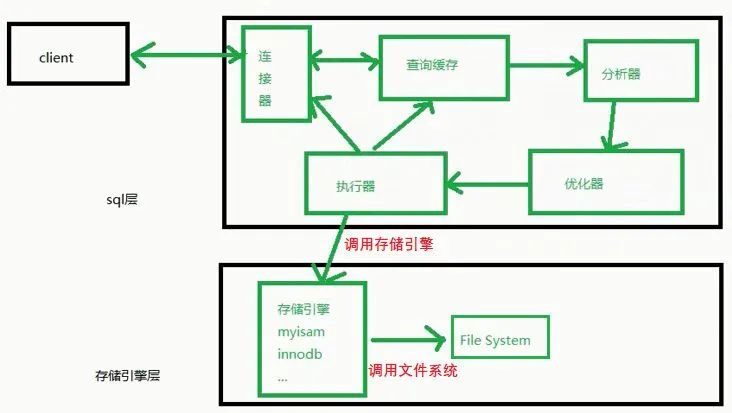
The client on the left can be regarded as a client. There are many clients, such as the CMD black window we often use, the WorkBench we often use for learning, and the Navicat tool often used by enterprises. They are all one client. The pile on the right can be regarded as Server (the Server of MySQL). We subdivide the Server into sql layer and storage engine layer.
When the data is queried, it will be returned to the actuator. On the one hand, the executor writes the results into the query cache. When you query again next time, you can get the data directly from the query cache. On the other hand, the result is directly responded back to the client.
2) Query database engine
① show engines;
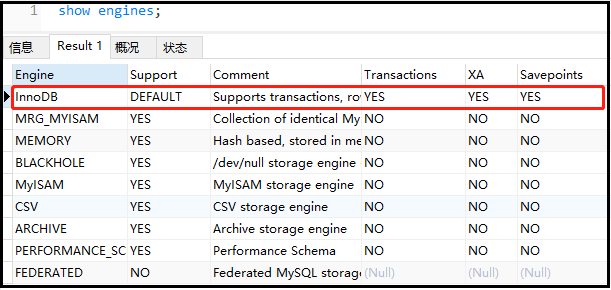
② show variables like "%storage_engine%";

3) Specifies the storage engine for the database object
create table tb( id int(4) auto_increment, name varchar(5), dept varchar(5), primary key(id) ) engine=myISAM auto_increment=1 default charset=utf8;
02
dba
1) Why do I need SQL optimization?
When performing multi table join query, sub query and other operations, the execution time of the server is too long and we wait for the results too long due to the poor SQL statement you write. Based on this, we need to learn how to optimize SQL.
2) mysql writing process and parsing process
① Writing process
select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..
② Analytical process
from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..
Provide a website that describes the mysql parsing process in detail:
https://www.cnblogs.com/annsshadow/p/5037667.html
3) SQL optimization - mainly index optimization
To optimize SQL, the most important thing is to optimize SQL index.
The index is equivalent to the directory of the dictionary. The process of using dictionary directory to find Chinese characters is equivalent to the process of using SQL index to find a record. With an index, you can easily and quickly locate a record.
① What is an index?
Index is a kind of data structure that helps MySQL get data efficiently. Index is a tree structure, and MySQL generally uses B + tree.
② Index illustration (binary tree is used here to help us understand the index)
The tree structure is characterized by: the child element smaller than the parent element is placed on the left; If the child element is larger than the parent element, put it on the right.
This diagram is just to help us understand the real description of [B + tree] of the index. We will explain it below.

How does the index find data? In the figure above, we assign an index to the age column, which is similar to the tree structure on the right. Each row record in the mysql table has a hardware address. For example, age=50 in the index points to the identifier of the row in the source table ("hardware address"). In other words, the tree index establishes a mapping relationship with the hardware address of each row of records in the source table. When you specify an index, this mapping relationship is established. This is why we can quickly locate the records in the source table through the index.
Take the [select * from student where age=33] query statement as an example. When we do not add an index, we will scan the source table from top to bottom. When we scan to row 5, we find the element we want to find. We have queried it for a total of 5 times. After the index is added, it is directly searched in the tree structure. If 33 is smaller than 50, it is queried from the left to 23. If 33 is greater than 23, it is queried to the right. Now 33 is found. The whole index is completed, and a total of three searches are carried out. Is it very convenient? If we need to find age=62 at this time, think about the change of search times before and after "adding index".
4) Disadvantages of index
1. When the amount of data is large, the index will be large (of course, it is quite small compared with the source table), and it also needs to be stored in memory / hard disk (usually in hard disk), occupying a certain memory space / physical space.
2. The index is not applicable to all situations: a. a small amount of data; b. Frequently changed fields are not suitable for indexing; c. Rarely used fields do not need to be indexed;
3. Index will improve the efficiency of data query, but it will reduce the efficiency of "add, delete and modify". When the index is not used, we only need to operate the source table to add, delete and modify the data. However, after adding the index, we need to modify not only the source table, but also the index again, which is very troublesome. Despite this, adding indexes is still very cost-effective, because most of us use queries, and "query" has a great impact on the performance of the program.
5) Advantages of indexing
1. Improve query efficiency (reduce IO utilization). When the index is created, the number of queries is reduced.
2. Reduce CPU utilization. For example, an operation such as [... order by age desc], when not indexed, will load the source table into memory for a sort operation, which greatly consumes resources. However, after using the index, the first index itself is smaller, and the second index itself is in good order. The data on the left is the smallest and the data on the right is the largest.
6) B + tree illustration
The index in MySQL uses the B + tree structure.

Description of B + tree:
First of all, Btree generally refers to [B + tree], and all data is stored in leaf nodes. For the above figure, the bottom layer 3 belongs to the leaf node, and the real data is stored in the leaf node. So what about the data in layers 1 and 2? A: it is used to split the pointer block, for example, P1 for those less than 26, P2 for those between 26-30, and P3 for those greater than 30.
Secondly, the three-tier [B + tree] can store millions of data. How do you put so much data? Increase the number of nodes. We have only three nodes in the figure.
Finally, the number of times to query any data in the [B + tree] is n, and N represents the height of the [B + tree].
03
Classification and creation of case index
1) Index classification
-
Single valued index
-
unique index
-
Composite index
① Single valued index
Create a single valued index using a field in the table. There are often multiple fields in a table, that is, each column can actually create an index, which can be created according to our actual needs. It should also be noted that a table can create multiple "single value indexes".
If a table has both age field and name field, we can create a single value index for age and name respectively, so that a table has two single value indexes.
② Unique index
It also uses a field in the table to create a single value index. Unlike a single value index, the data in the field that creates a unique index cannot have duplicate values. For example, age must have many people of the same age, and name must have some people with duplicate names, so it is not suitable to create a "unique index". Like number id and student id sid, they are different for everyone, so they can be used to create a unique index.
③ Composite index
An index composed of multiple columns. For example, when we create such a "composite index" (name,age), we first use name to query the index. When the name is the same, we use age to filter again. Note: the fields of the composite index do not have to be used up. When we use the name field to index the results we want, we don't need to use age to filter again.
2) Create index
① Grammar
Syntax: create index type index name on table (field);
The table creation statement is as follows:
The query table structure is as follows:
② The first way to create an index
Create single valued index
create index dept_index on tb(dept);
Create a unique index: Here we assume that the values in the name field are unique
create unique index name_index on tb(name);
Create composite index
create index dept_name_index on tb(dept,name);
③ The second way to create an index
First delete the index created before, and then test this index creation method;
Syntax: alter table table name add index type index name (field)
Create single valued index
alter table tb add index dept_index(dept);
Create a unique index: Here we assume that the values in the name field are unique
alter table tb add unique index name_index(name);
Create composite index
alter table tb add index dept_name_index(dept,name);
④ Supplementary notes
If a field is a primary key, it is the primary key index by default.
A primary key index is very similar to a unique index. Same point: the data in this column cannot have the same value; Difference: the primary key index cannot have null value, but the unique index can have null value.
3) Index deletion and index query
① Index deletion
Syntax: drop index index name on table name;
drop index name_index on tb;
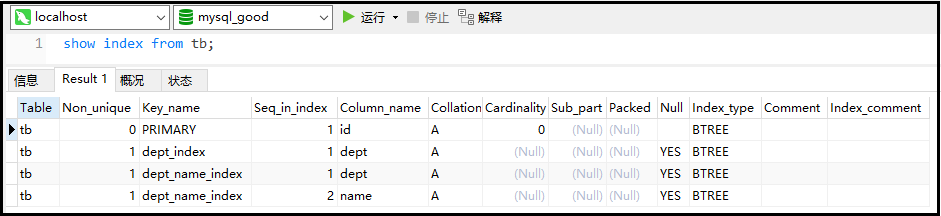
② Index query
Syntax: show index from table name;
show index from tb;
The results are as follows:
04
Exploration of SQL performance problems
Artificial Optimization: we need to use explain to analyze the execution plan of SQL. The execution plan can simulate the SQL optimizer to execute SQL statements, which can help us understand the quality of writing SQL.
Automatic optimization of SQL optimizer: when we first talked about the execution principle of MySQL, we already know that MySQL has an optimizer. When you write an SQL statement, if the SQL optimizer thinks that the SQL statement you write is not good enough, it will automatically write a better equivalent SQL to execute.
The automatic optimization function of SQL optimizer [will interfere with] our artificial optimization function. After we check the SQL execution plan, if it is not written well, we will optimize our SQL. When we think we have optimized well, the final execution plan is not executed according to our optimized SQL statements, but sometimes we change our optimized SQL and execute it.
SQL optimization is a probability problem. Sometimes the system will execute the results according to our optimized SQL (the optimizer thinks you write the same, so it won't move your SQL). Sometimes the optimizer will still modify the optimized SQL and then execute it.
1) View execution plan
Syntax: explain + SQL statement
eg: explain select * from tb;
2) Several "Keywords" in "execution plan"
id: No
select_type: query type
Table: table
Type: type
possible_keys: index used for prediction
key: the index actually used
key_len: the length of the index actually used
ref: references between tables
rows: the amount of data queried by index
Extra: additional information
Create table statement and insert data:
#Create table statement create table course ( cid int(3), cname varchar(20), tid int(3) ); create table teacher ( tid int(3), tname varchar(20), tcid int(3) ); create table teacherCard ( tcid int(3), tcdesc varchar(200) ); #Insert data insert into course values(1,'java',1); insert into course values(2,'html',1); insert into course values(3,'sql',2); insert into course values(4,'web',3); insert into teacher values(1,'tz',1); insert into teacher values(2,'tw',2); insert into teacher values(3,'tl',3); insert into teacherCard values(1,'tzdesc') ; insert into teacherCard values(2,'twdesc') ; insert into teacherCard values(3,'tldesc') ;
explain common keywords of execution plan
1) Description of id keyword
① Case: query the teacher's information with course number 2 or teacher certificate number 3:
#View execution plan explain select t.* from teacher t,course c,teacherCard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3);
The results are as follows:

Next, add several pieces of data to the teacher table.
insert into teacher values(4,'ta',4); insert into teacher values(5,'tb',5); insert into teacher values(6,'tc',6);
Review the execution plan again.
#View execution plan explain select t.* from teacher t,course c,teacherCard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3);
The results are as follows:

The execution order of the table. The reason for the change due to the change of the number of tables: Cartesian product.
a b c 2 3 4 Final: 2 * 3 * 4 = 6 * 4 = 24 c b a 4 3 2 Final: 4 * 3 * 2 = 12 * 2 = 24
Analysis: the number of articles finally executed, although it is consistent. However, in the intermediate process, a temporary table is 6 and a temporary table is 12. Obviously, 6 < 12. For memory, the smaller the amount of data, the better. Therefore, the optimizer will certainly choose the first execution order.
Conclusion: the id value is the same, which is executed from top to bottom. The execution order of tables changes due to the change of the number of tables.
② Case: query the description of the teacher who teaches SQL course (desc)
#View execution plan explain select tc.tcdesc from teacherCard tc where tc.tcid = ( select t.tcid from teacher t where t.tid = (select c.tid from course c where c.cname = 'sql') );
The results are as follows:

Conclusion: the larger the id value, the better the query priority. This is because when performing nested sub query, first check the inner layer and then the outer layer.
③ Make a simple modification for ②
#View execution plan explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ;
The results are as follows:

Conclusion: id values are the same but different. The larger the id value, the higher the priority; The execution order is the same from id down.
2)select_ Description of type keyword: query type
① Simple: simple query
No subqueries, no union queries.
explain select * from teacher;
The results are as follows:

② Primary: the primary query (outermost layer) that contains subqueries
③ subquery: the main query containing subqueries (not the outermost layer)
④ Derived: derived query (temporary table used)
a. In the from sub query, there is only one table;
b. In the from subquery, if table1 union table2, table1 is the derived table;
explain select cr.cname from ( select * from course where tid = 1 union select * from course where tid = 2 ) cr ;
The results are as follows:

⑤ Union: the table after union is called Union table, as shown in the above example
⑥ union result: tells us which tables use union queries
3) Description of type keyword: index type
system and const are only ideal conditions. In fact, they can only be optimized to the level of index -- > range -- > Ref. To optimize the type, you have to create an index.

① system
The source table has only one piece of data (practically impossible);
The derived table is the main query with only one piece of data (which can be reached occasionally).
② const
The SQL that can only find one piece of data is only valid for the Primary key or unique index type.
explain select tid from test01 where tid =1 ;
The results are as follows:

After deleting the previous primary key index, we add another common index:
create index test01_index on test01(tid) ; #Review the execution plan again explain select tid from test01 where tid =1 ;
The results are as follows:

③ eq_ref
Unique index: for the query of each index key, the data matching the unique row will be returned (there are only 1, no more than 0), and the query result must be consistent with the number of data entries.
This is common in unique indexes and primary key indexes.
delete from teacher where tcid >= 4; alter table teacherCard add constraint pk_tcid primary key(tcid); alter table teacher add constraint uk_tcid unique index(tcid) ; explain select t.tcid from teacher t,teacherCard tc where t.tcid = tc.tcid ;
The results are as follows:

Summary: the index used in the above SQL is t.tcid, that is, the tcid field in the teacher table; If the number of data in the teacher table is consistent with the number of data in the connection query (all three data), EQ may be satisfied_ Ref level; Otherwise, it cannot be satisfied. The conditions are harsh and difficult to achieve.
④ ref
Non unique index: for the query of each index key, return all matching rows (0, 1 or more)
Prepare data:
Create an index and view the execution plan:
#Add index alter table teacher add index index_name (tname) ; #View execution plan explain select * from teacher where tname = 'tz';
The results are as follows:

⑤ range
Retrieve the row of the specified range, where is followed by a range query (between, >, <, > =, in)
Sometimes, in will fail and become ALL when there is no index
#Add index alter table teacher add index tid_index (tid) ; #View execution plan: the following describes an equivalent SQL method to view the execution plan explain select t.* from teacher t where t.tid in (1,2) ; explain select t.* from teacher t where t.tid <3 ;
The results are as follows:

⑥ index
Query data in all indexes (scan the entire index)
⑦ ALL
Query data in all source tables (scan all tables)

Note: cid is an index field, so you only need to scan the index table to query the index field. However, tid is not an index field. Querying non index fields requires violent scanning of the entire source table, which will consume more resources.
4)possible_keys and key s
possible_ The index that keys may use. It's a prediction, not accurate. Just find out.
key refers to the index actually used.
#First, add an index to the cname field of the course table create index cname_index on course(cname); #View execution plan explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ;
The results are as follows:

One thing to note is: if possible_ If the key / key is NULL, the index is not used.
5)key_len
The length of the index, which is used to judge whether the composite index is fully used (a,b,c).
① Create a new table for testing
#Create table create table test_kl ( name char(20) not null default '' ); #Add index alter table test_kl add index index_name(name) ; #View execution plan explain select * from test_kl where name ='' ;
The results are as follows:
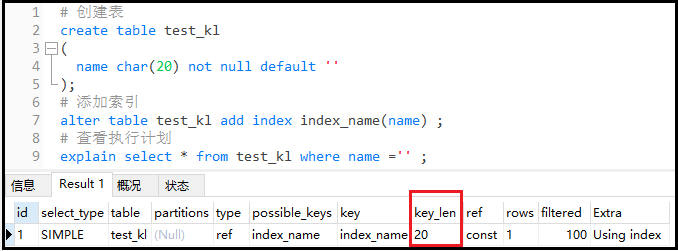
Result analysis: because I didn't set the character set of the server, the default character set is latin1. For latin1, a character represents a byte, so the key in this column_ The length of len is 20, indicating that the name index is used.
② Give test_kl table, add name1 column, which is not set with "not null"
The results are as follows:

Result analysis: if the index field can be null, the bottom layer of mysql will use 1 byte for identification.
③ Delete the original index name and name1 and add a composite index
#Delete the original index name and name1 drop index index_name on test_kl ; drop index index_name1 on test_kl ; #Add a composite index create index name_name1_index on test_kl(name,name1); #View execution plan explain select * from test_kl where name1 = '' ; --121 explain select * from test_kl where name = '' ; --60
The results are as follows:

Result analysis: for the following execution plan, we can see that we only use the first index field name of the composite index, so key_len is 20, which is very clear. Look at the above execution plan. Although we only use the name1 field in the composite index field after where, if you want to use the second index field of the composite index, the first index field name of the composite index will be used by default. Because name1 can be null, so key_len = 20 + 20 + 1 = 41!
④ Again, add a name2 field and create an index for it.
The difference is that the data type of this field is varchar
#Add a new field name2, which can be null alter table test_kl add column name2 varchar(20) ; #Set the name2 field as the index field alter table test_kl add index name2_index(name2) ; #View execution plan explain select * from test_kl where name2 = '' ;
The results are as follows:
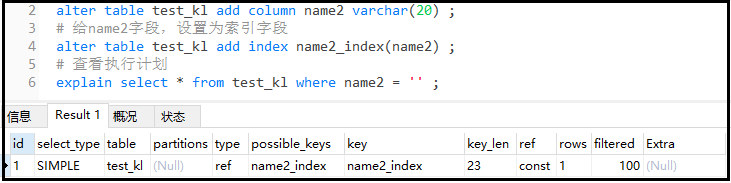
Result analysis: key_len = 20 + 1 + 2, this 20 + 1, we know, what does this 2 represent? Originally, varchar belongs to variable length. In the bottom layer of mysql, two bytes are used to identify the variable length.
6)ref
ref here is used to indicate the fields referenced by the current table.
Note that it is different from the ref value in type. In type, ref is only an option value of type.
#Add an index to the tid field of the course table create index tid_index on course(tid); #View execution plan explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tw';
The results are as follows:

Result analysis: there are two indexes. The c.tid of table C refers to the TID field of table t, so you can see that the display result is [database name. t.tid], and the t.name of table t refers to a constant "tw", so you can see that the result is displayed as const, indicating a constant.
7) Rows (this is still a little confused at present)
The number of data queried by index optimization (the number of data actually queried by index)
explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tz' ;
The results are as follows:
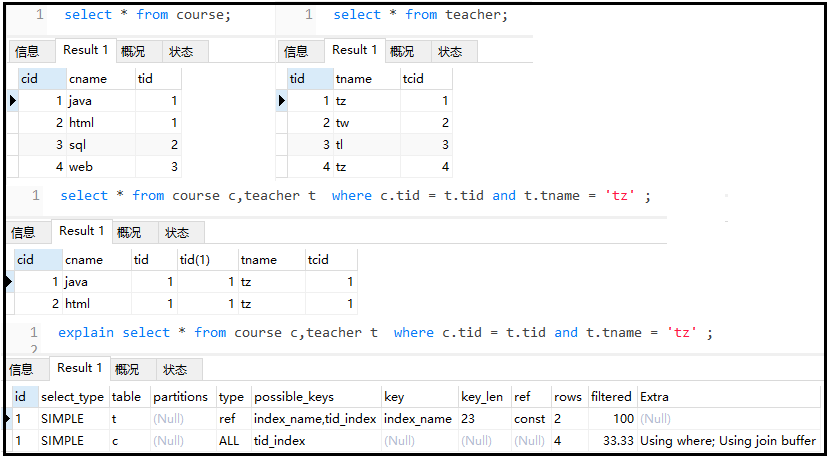
8)extra
Some other descriptions are also very useful.
① using filesort: for single index cases
When the word SQL appears, it means that your current performance consumption is large. Indicates that an "extra" sort has been performed. Common in order by statements.
What is the "extra" sort?
To make this clear, we first need to know what sorting is. In order to sort a field, you must first query the field and then sort it.
Next, let's look at the execution plans of the following two SQL statements.
#Create a new table and create an index at the same time create table test02 ( a1 char(3), a2 char(3), a3 char(3), index idx_a1(a1), index idx_a2(a2), index idx_a3(a3) ); #View execution plan explain select * from test02 where a1 ='' order by a1 ; explain select * from test02 where a1 ='' order by a2 ;
The results are as follows:

Result analysis: for the first execution plan, after where, we first query the a1 field, and then use a1 to sort in turn. This is very easy. However, for the second execution plan, after where, we query the a1 field, but use the a2 field to sort. At this time, the bottom layer of myql will query once to sort "extra".
Summary: for a single index, if sorting and searching are the same field, using filesort will not appear; If sorting and searching are not the same field, using filesort will appear; Therefore, the fields of where are the fields of order by.
② using filesort: for composite index
Cannot span columns (official term: best left prefix)
#Delete the index of test02 drop index idx_a1 on test02; drop index idx_a2 on test02; drop index idx_a3 on test02; #Create a composite index alter table test02 add index idx_a1_a2_a3 (a1,a2,a3) ; #View the execution plan of the following SQL statement explain select *from test02 where a1='' order by a3 ; --using filesort explain select *from test02 where a2='' order by a3 ; --using filesort explain select *from test02 where a1='' order by a2 ;
The results are as follows:
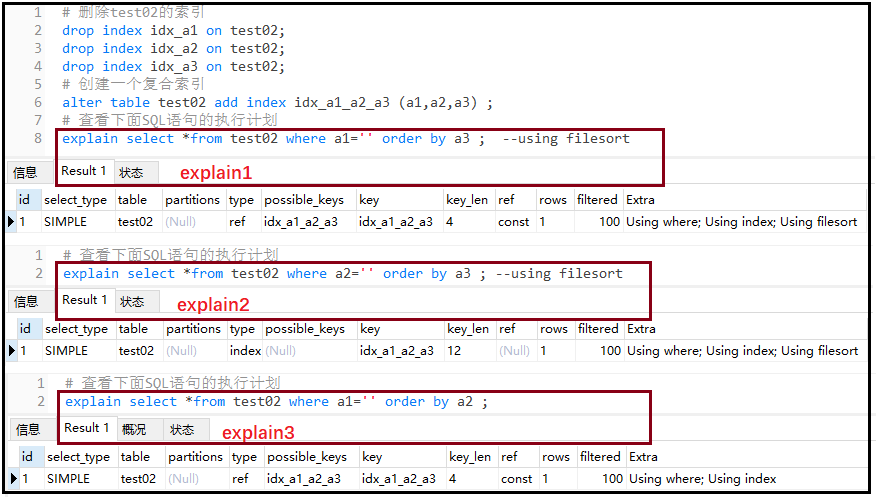
Result analysis: the order of the composite index is (a1,a2,a3). You can see that a1 is on the far left, so a1 is called the "best left prefix". If you want to use the subsequent index field, you must use this a1 field first. For explain1, we use the a1 field after where, but the subsequent sorting uses a3, which directly skips a2, which belongs to cross column; For explain2, we use a2 field after where, and directly skip a1 field, which also belongs to cross column; For explain3, we use a1 field after where and a2 field after where, so [using filesort] does not appear.
③ using temporary
When this word appears, it also indicates that your current SQL performance consumption is large. This is because the current SQL uses temporary tables. It usually appears in group by.
explain select a1 from test02 where a1 in ('1','2','3') group by a1 ;
explain select a1 from test02 where a1 in ('1','2','3') group by a2 ; --using temporary
The results are as follows:
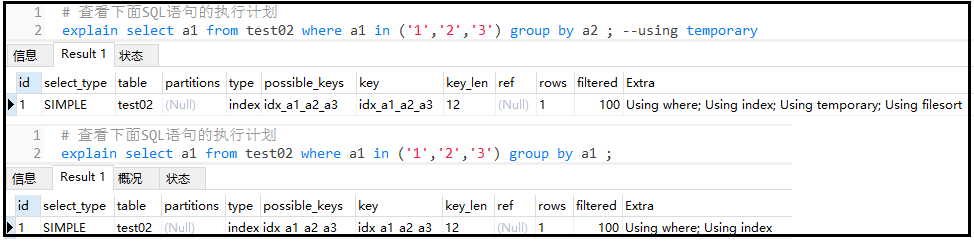
Result analysis: when you query which field, group according to that field, otherwise using temporary will appear.
For using temporary, we are looking at an example:
using temporary means that an additional table needs to be used, which usually appears in the group by statement. Although there is already a table, it does not apply. You must have another table.
Let's look at the writing process and parsing process of mysql again.
Writing process
select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..
Analytical process
from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..
Obviously, where is followed by group by and then select. Based on this, we will review the execution plans of the following two SQL statements.
explain select * from test03 where a2=2 and a4=4 group by a2,a4; explain select * from test03 where a2=2 and a4=4 group by a3;
The analysis is as follows: for the first execution plan, where is followed by a2 and a4. Then we group according to a2 and a4. Obviously, these two tables already exist. Just group them directly on a2 and a4. However, for the second implementation plan, where is followed by a2 and a4, and then we are grouped according to a3. Obviously, we don't have a3 table, so we need another temporary table a3. Therefore, using temporary appears.
④ using index
When you see this keyword, Congratulations, indicating that your SQL performance has improved.
using index is called "index overwrite".
When using index appears, it means that you do not need to read the source table, but only use the index to obtain data, and there is no need to query back to the source table.
As long as all the columns used appear in the index, it is index coverage.
#Delete id test02 in composite index_ a1_ a2_ a3 drop index idx_a1_a2_a3 on test02; #Recreate a composite index idx_a1_a2 create index idx_a1_a2 on test02(a1,a2); #View execution plan explain select a1,a3 from test02 where a1='' or a3= '' ; explain select a1,a2 from test02 where a1='' and a2= '' ;
The results are as follows:
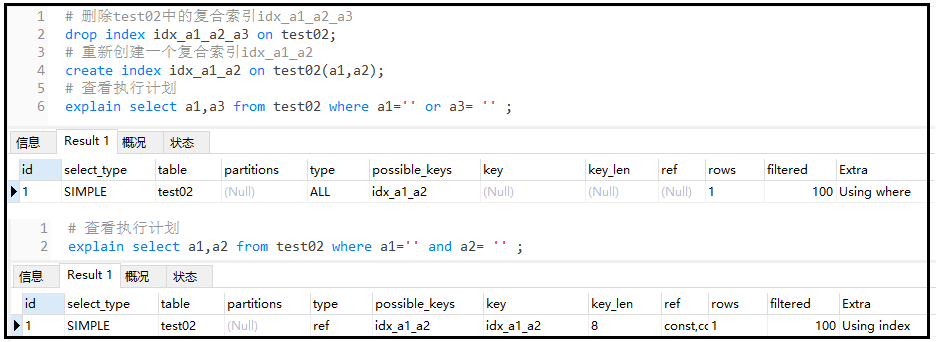
Result analysis: we created a composite index of a1 and a2, but for the first execution plan, we found a3. This field did not create an index, so there was no using index, but using where, indicating that we need to query back to the table. For the second execution plan, it belongs to complete index coverage, so using index appears.
For using index, we are looking at a case:
explain select a1,a2 from test02 where a1='' or a2= '' ; explain select a1,a2 from test02;
If index override is used (when using index), it will be used for possible_keys and key s affect:
a. If there is no where, the index only appears in the key;
b. If there is a where, the index appears in key and possible_keys.
⑤ using where
Indicates that you need to query back to table, which indicates that you have queried both in the index and back to the source table.
#Delete the composite index idx in test02_ a1_ a2 drop index idx_a1_a2 on test02; #Add an index to a1 field create index a1_index on test02(a1); #View execution plan explain select a1,a3 from test02 where a1="" and a3="" ;
The results are as follows:

Result analysis: we use index a1, which means we use index for query. However, for the a3 field, we do not use the index. Therefore, for the a3 field, we need to query back to the source table. At this time, using where appears.
⑥ Impossible where
When the where clause is always False, an impossible where will appear
#View execution plan explain select a1 from test02 where a1="a" and a1="b" ;
The results are as follows:

05
Optimization example
1) Introduction case
#Create a new table create table test03 ( a1 int(4) not null, a2 int(4) not null, a3 int(4) not null, a4 int(4) not null ); #Create a composite index create index a1_a2_a3_test03 on test03(a1,a2,a3); #View execution plan explain select a3 from test03 where a1=1 and a2=2 and a3=3;
The results are as follows:
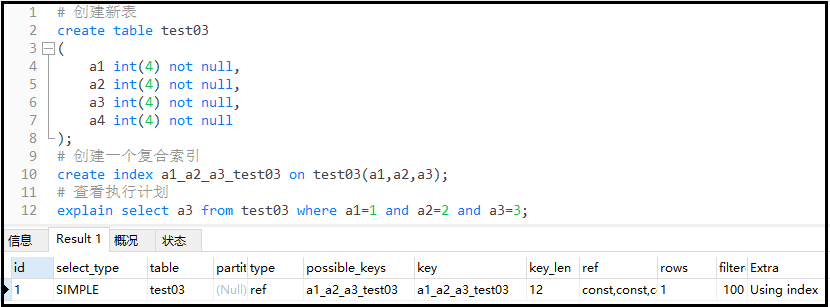
Recommended writing method: the order of composite index is consistent with the order of use.
Let's take a look at [not recommended]: the order of composite index is inconsistent with the order of use.
#View execution plan explain select a3 from test03 where a3=1 and a2=2 and a1=3;
The results are as follows:

Result analysis: Although the results are consistent with the above results, it is not recommended to write this way. But why is there no problem with this writing? This is due to the SQL optimizer, which helps us adjust the order.
Finally, add one more point: for composite indexes, do not use cross columns
#View execution plan explain select a3 from test03 where a1=1 and a3=2 group by a3;
The results are as follows:

Result analysis: a1_a2_a3 is a composite index. After using the a1 index, we directly use a3 across columns and directly skip the A2 index. Therefore, the a3 index fails. When using a3 for grouping, using where will appear.
2) Single table optimization
#Create a new table create table book ( bid int(4) primary key, name varchar(20) not null, authorid int(4) not null, publicid int(4) not null, typeid int(4) not null ); #Insert data insert into book values(1,'tjava',1,1,2) ; insert into book values(2,'tc',2,1,2) ; insert into book values(3,'wx',3,2,1) ; insert into book values(4,'math',4,2,3) ;
The results are as follows:
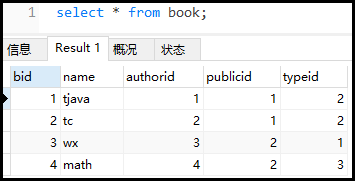
Case: query the bid with authorid=1 and typeid 2 or 3, and arrange it in descending order according to the typeid.
explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;
The results are as follows:

This is an SQL without any optimization. You can see that typ is of type ALL and extra is using filesort. You can imagine how terrible this SQL is.
Optimization: when adding an index, you should add the index according to the MySQL parsing order, which returns to the parsing order of MySQL. Next, let's take a look at the parsing order of MySQL.
from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..
① Optimization 1: Based on this, we add the index and view the execution plan again.
#Add index create index typeid_authorid_bid on book(typeid,authorid,bid); #Review the execution plan again explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;
The results are as follows:

Result analysis: the result is not the same as we thought. There is still using where. Check the index length key_len=8, which means that we only use two indexes, and one index is invalid.
② Optimization 2: the use of in sometimes leads to index failure. Based on this, we have the following optimization idea.
Put the in field at the end. One thing to note: every time you create a new index, it's best to delete the previous obsolete index, otherwise there will be interference (between indexes).
#Delete previous index drop index typeid_authorid_bid on book; #Create index again create index authorid_typeid_bid on book(authorid,typeid,bid); #Review the execution plan again explain select bid from book where authorid=1 and typeid in(2,3) order by typeid desc ;
The results are as follows:

Result analysis: Although there is no change here, it is an optimization idea.
The summary is as follows:
a. It is best to prefix and maintain the consistency of index definition and order of use
b. The index needs to be optimized step by step (each time a new index is created, the previous obsolete index should be deleted as needed)
c. Put the range query with In at the end of the where condition to prevent invalidation.
In this example, using where also appears; Using index: Reason: where authorid=1 and typeid in(2,3), the authorid is in the index (authorid,typeid,bid), so there is no need to return to the original table (you can find it directly in the index table); Although typeid is also in the index (authorid,typeid,bid), the range query with in has invalidated the typeid index. Therefore, it is equivalent to that there is no typeid index, so it needs to go back to the original table (using where);
For example, if there is no In below, using where will not appear:
explain select bid from book where authorid=1 and typeid =3 order by typeid desc ;
The results are as follows:

3) Two table optimization
#Create a new teacher2 table create table teacher2 ( tid int(4) primary key, cid int(4) not null ); #Insert data insert into teacher2 values(1,2); insert into teacher2 values(2,1); insert into teacher2 values(3,3); #Create course2 new table create table course2 ( cid int(4) , cname varchar(20) ); #Insert data insert into course2 values(1,'java'); insert into course2 values(2,'python'); insert into course2 values(3,'kotlin');
Case: use a left connection to find all the information about teaching java courses.
explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';
The results are as follows:
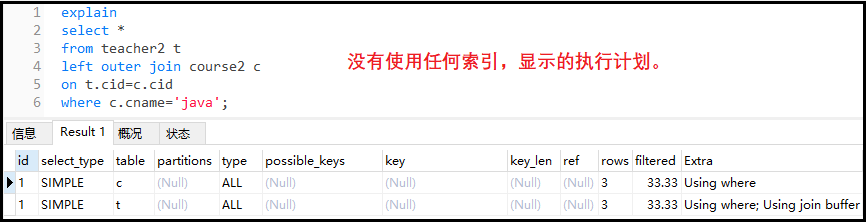
① Optimize
For two tables, where should the index be added? A: for table connection, small table drives large table. The index is based on frequently used fields.
Why is it better for a small watch to drive a large one?
Small watch:10
Big watch:300
#Small table drives large table
select ...where Small watch.x10=Big watch.x300 ;
for(int i=0;i<Small watch.length10;i++)
{
for(int j=0;j<Big watch.length300;j++)
{
...
}
}
#Large table drives small table
select ...where Big watch.x300=Small watch.x10 ;
for(int i=0;i<Big watch.length300;i++)
{
for(int j=0;j<Small watch.length10;j++)
{
...
}
}
Analysis: the above two FOR cycles will eventually cycle 3000 times; But FOR the double-layer loop: it is generally recommended to put the loop with small data in the outer layer. Large data loops are placed in the inner layer. Regardless of why, this is a principle of programming language. FOR double loops, the less outer loops and the larger memory loops, the higher the performance of the program.
Conclusion: when writing [... on t.cid=c.cid], put the table with small amount of data on the left (assuming that the amount of data in table t is small and that in table C is large.)
We already know that for the connection of two tables, we need to use the small table to drive the large table, for example [... on t.cid=c.cid]. If t is a small table (10 pieces) and C is a large table (300 pieces), then t needs to cycle 300 times every time t cycles, that is, the t.cid field of T table belongs to a frequently used field, so we need to add an index to the CID field.
More in-depth description: in general, the left connection is cited by the left table. The right connection gives the right table a reference. Whether other tables need to be indexed or not, let's try it step by step.
#Reference the fields of the left table create index cid_teacher2 on teacher2(cid); #View execution plan explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';
The results are as follows:

Of course, you can continue to optimize and add an index to cname. Index optimization is a step-by-step process, which requires a little attempt.
#Field reference to cname create index cname_course2 on course2(cname); #View execution plan explain select t.cid,c.cname from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';
The results are as follows:

Finally, add one: Using join buffer is an option in extra, which means that the MySQL engine uses "connection cache", that is, the bottom layer of MySQL moves your SQL, and your writing is too poor.
4) Three table optimization
Greater than or equal to tables, the optimization principle is the same
Small table drives large table
The index is based on frequently queried fields
06
Some principles to avoid index failure
① Points needing attention in composite index
Composite index, do not use across columns or out of order (the best left prefix)
Composite index, try to use full index matching, that is, if you build several indexes, use several indexes
② Do not perform any operation (calculation, function, type conversion) on the index, otherwise the index will become invalid
explain select * from book where authorid = 1 and typeid = 2; explain select * from book where authorid*2 = 1 and typeid = 2 ;
The results are as follows:

③ The index cannot be used that is not equal to (! = < >) or is null (is not null), otherwise it and all on the right will be invalid (for most cases). If there is > in the composite index, both the self index and the right index will be invalidated.
#For cases that are not composite indexes explain select * from book where authorid != 1 and typeid =2 ; explain select * from book where authorid != 1 and typeid !=2 ;
The results are as follows:
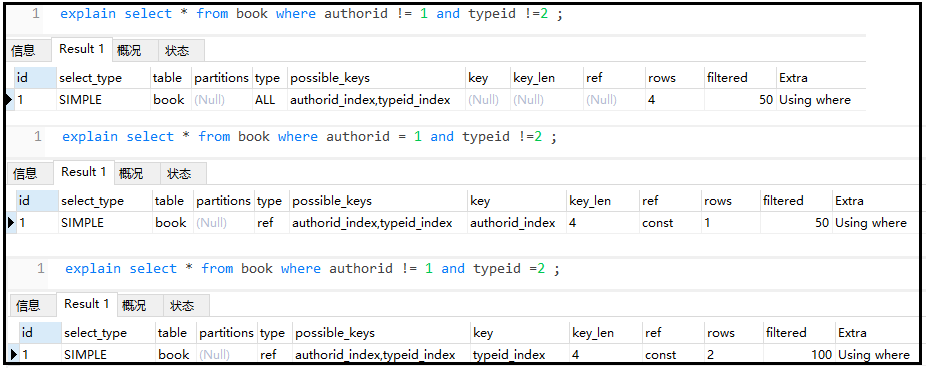
Take another look at the following case:
#Delete individual indexes drop index authorid_index on book; drop index typeid_index on book; #Create a composite index alter table book add index idx_book_at (authorid,typeid); #View execution plan explain select * from book where authorid > 1 and typeid = 2 ; explain select * from book where authorid = 1 and typeid > 2 ;
The results are as follows:

Conclusion: if there is [>] in the composite index, both the self index and the right index will be invalid.
In the composite index, you can see that there is [<]:
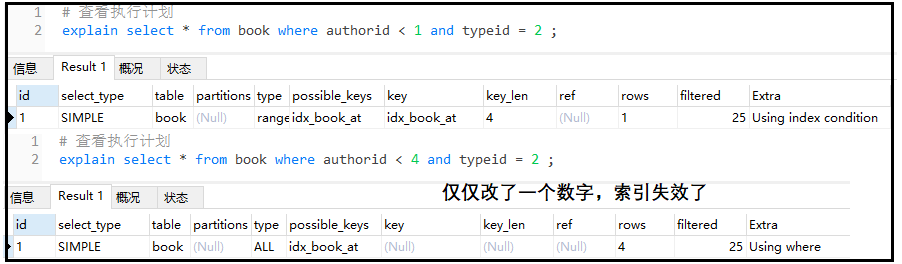
We learn index optimization, which is a conclusion applicable in most cases, but it is not 100% correct due to SQL optimizer and other reasons. Generally speaking, after a range query (> < in), the index becomes invalid.
④ SQL optimization is a probability level optimization. As for whether our optimization is actually used, we need to speculate through explain.
#Delete composite index drop index authorid_typeid_bid on book; #Create indexes for authorid and typeid respectively create index authorid_index on book(authorid); create index typeid_index on book(typeid); #View execution plan explain select * from book where authorid = 1 and typeid =2 ;
The results are as follows:

Result analysis: we created two indexes, but actually only one index was used. Because for two separate indexes, the program thinks that only one index is enough, and there is no need to use two indexes.
When we create a composite index, execute the above SQL again:
#View execution plan explain select * from book where authorid = 1 and typeid =2 ;
The results are as follows:

⑤ Index coverage, 100% no problem
⑥ like try to start with "constant" instead of '%', otherwise the index will become invalid
explain select * from teacher where tname like "%x%" ; explain select * from teacher where tname like 'x%'; explain select tname from teacher where tname like '%x%';
The results are as follows:
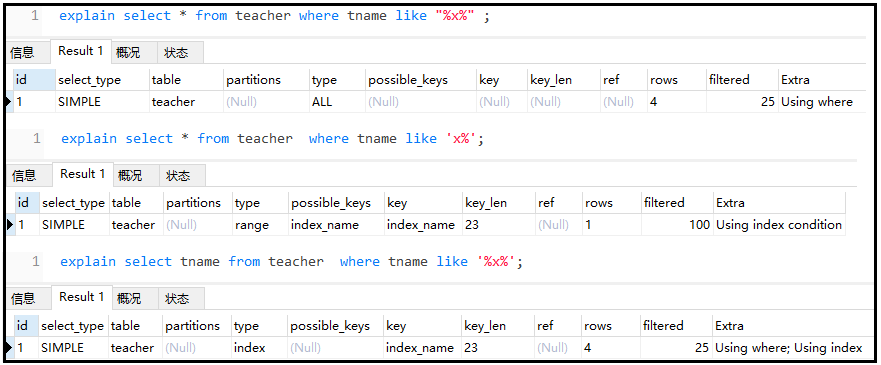
The conclusion is as follows: like try not to use situations like "% X%", but you can use "x%". Index override is required if '% X%' is not used.
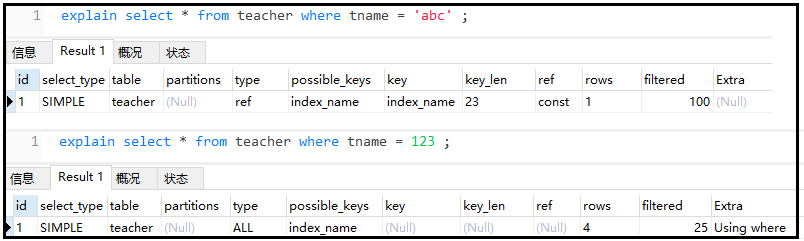
⑦ Try not to use type conversion (display, implicit), otherwise the index will fail
explain select * from teacher where tname = 'abc' ; explain select * from teacher where tname = 123 ;
The results are as follows:
⑧ Try not to use or, otherwise the index will become invalid
explain select * from teacher where tname ='' and tcid >1 ; explain select * from teacher where tname ='' or tcid >1 ;
The results are as follows:

Note: or is very fierce, which will invalidate its own index and the indexes on the left and right sides.
07
Some other optimization methods
1) Optimization of exists and in
If the data set of the main query is large, the i keyword is used, which is efficient.
If the data set of the sub query is large, the exist keyword is used, which is efficient.
select ..from table where exist (Subquery) ; select ..from table where field in (Subquery) ;
2) order by optimization
-
IO is the number of accesses to hard disk files
-
using filesort has two algorithms: two-way sorting and one-way sorting (according to the number of IO)
-
MySQL4.1. Before default, two-way sorting was used; Two way: scan the disk twice (1: read the sort field from the disk and sort the sort field (sort in buffer) 2: scan other fields)
-
MySQL4. After 1, one-way sorting is used by default: read only once (all fields) and sort in buffer. However, there are certain hidden dangers in single channel sorting (it may not be "single channel / one IO", but it may be multiple IO). Reason: if the amount of data is very large, the data of all fields cannot be read at one time, so "slice reading and multiple reading" will be carried out.
-
Note: single way sorting will occupy more buffer than two-way sorting.
-
When using one-way sorting, if the data is large, you can consider increasing the buffer capacity:
#It may not really be "single channel / one IO", but it may be multiple io set max_length_for_sort_data = 1024
If Max_ length_ for_ sort_ If the data value is too low, mysql will automatically change from one way to two ways (too low: the total size of the columns to be sorted exceeds the number of bytes defined by max_length_for_sort_data)
① Strategies to improve order by query:
-
Choose to use one-way or two-way; Adjust the buffer capacity
-
Avoid using select *... (writing all fields after select is also more efficient than writing *)
-
Composite indexes should not be used across columns. Avoid using filesort to ensure the consistency of all sorting fields and sorting (ascending or descending)