Detailed explanation of the underlying principle and source code analysis of java Concurrent thread pool
Performance comparison between thread and thread pool
The first part analyzes Java threads. Now let's analyze the java thread pool. Before analyzing the thread pool, let's think about whether the more threads we create, the better. Obviously not. Why should we use the thread pool? Let's take the following example
/***
* Use threads to execute programs
*/
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 100000; i++) {
Thread thread = new Thread() {
@Override
public void run() {
list.add(random.nextInt());
}
};
thread.start();
thread.join();
}
System.out.println("Time:" + (System.currentTimeMillis() - start));
System.out.println("size:" + list.size());
}
}
/***
* Thread pool execution
*/
public class ThreadPoolTest {
public static void main(String[] args) throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<Integer>();
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 100000; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
list.add(random.nextInt());
}
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.DAYS);
System.out.println("Time:"+(System.currentTimeMillis() - start));
System.out.println("size:"+list.size());
}
}
The above two codes are executed 100000 times to add random numbers to the set. The difference is that the first code creates threads to execute tasks every cycle, and the second code executes tasks through thread pool. That'll be faster. The answer is that the thread pool is much faster.
Why? In the previous article, it was mentioned that java thread creation is a heavyweight, involving from user state to kernel state. At the same time, too many threads lead to continuous context switching of cpu.
In the first code, 100000 objects and 100000 threads were created. The second code also creates 100000 objects, but only two threads are created. Why only two threads are created? We will analyze the newSingleThreadExecutor later.
So the thread pool performance must be good? Take a look at the example below
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService1 = Executors.newCachedThreadPool();//fast
ExecutorService executorService2 = Executors.newFixedThreadPool(10);//slow
ExecutorService executorService3 = Executors.newSingleThreadExecutor();//Slowest
for (int i = 1; i <= 100; i++) {
executorService1.execute(new MyTask(i));
}
}
}
/***
* project
*/
class MyTask implements Runnable {
int i = 0;
public MyTask(int i) {
this.i = i;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "Programmers do the second" + i + "Items");
try {
Thread.sleep(3000L);//Business logic
} catch (Exception e) {
e.printStackTrace();
}
}
}
The above code is very simple. Different thread pools execute the run method of MyTask. This run method outputs one sentence and blocks it for three seconds. The thread pool will be fast. The answer is already in the comment.
The performance obtained by using different threads in different scenarios is different.
Analysis of three thread pools created by Executors
If you pay attention to Alibaba's development manual, you should know that the three thread pools created by Executors are not recommended. So why not recommend it? Let's analyze it one by one.
Let's first look at the meaning of several parameters of the process pool
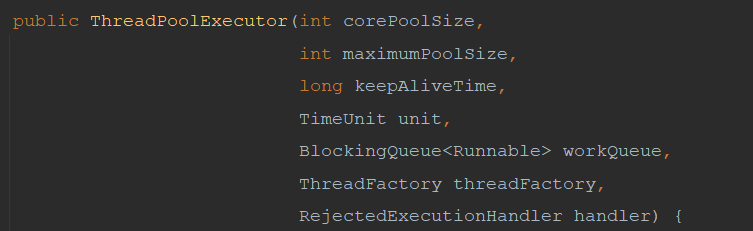
corePoolsize: number of core threads, which is the number of threads contained when creating a thread pool
maximumPoolSize is the maximum number of threads. When the number of core threads is insufficient, the maximum number of threads (including core threads) can be created
keepAliveTime and TimeUnit are the length and time unit of non core threads
BlockingQueue < runnable > queue (the queue will be analyzed separately in subsequent blogs)
ThreadFactory thread factory, as mentioned in the previous article
RejectedExecutionHandler reject policy
newCachedThreadPool analysis
ExecutorService executorService1 = Executors.newCachedThreadPool()

The number of core threads in newCachedThreadPool is 0, the maximum number of threads is the maximum, and the survival time of threads in the thread pool is 60 seconds. The queue adopts synchronous queue.
According to the above case,
Firstly, there is no core thread in newCachedThreadPool, so when a task is received, it will be put into the synchronization queue (the synchronization queue is a typical production and consumption mode. When there is a task in the synchronization queue, you must consume this task before receiving other tasks). At this time, thread 1 will be created to execute task 1. When the task of the synchronization queue is consumed, it can receive the second task, and thread 2 will also be created to execute task 2. Then task 3 will be received again. At this time, if thread 1 finishes executing task 1 and the idle time is within 60 seconds (the survival time is 60 seconds), task 3 will be assigned to thread 1. At this time, thread 1 executes task 1 and task 3. This is thread reuse. If there is no idle thread when receiving task 3, thread 3 will be created to execute. This is the process of newCachedThreadPool thread pool.
newFixedThreadPool analysis
ExecutorService executorService2 = Executors.newFixedThreadPool(10)

The number of core threads in newFixedThreadPool is 10, the maximum number of threads is 10, and the survival time of non core threads is 0. The maximum number of threads is equal to the number of core threads, and there is no way to create other non core threads. The queue is a LinkedBlockingQueue unbounded queue, which can store data indefinitely. Queue is a data structure with FIFO, that is, first in first out. According to the above case analysis:
First, the newFixedThreadPool has 10 core threads, so you can receive 10 tasks at the beginning. These 10 tasks do not need to be put into the queue. From the 11th task, it will be put into the queue. After each core thread task is executed, it will get the task from the queue.
This is why the above case uses newFixedThreadPool to print 10 statements.
If executorservice executorservice2 = executors If newfixedthreadpool (100), the execution efficiency of the above case will be the same as that of newCachedThreadPool.
Newsinglethreadexecution analysis
ExecutorService executorService3 = Executors.newSingleThreadExecutor()
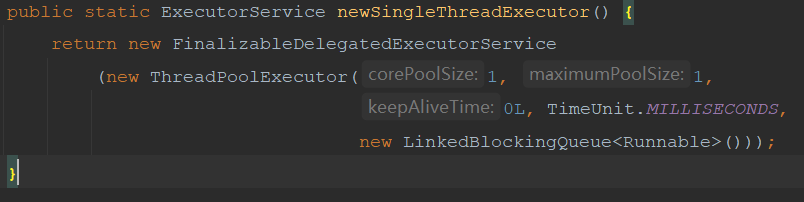
The newsinglethreadexecution is similar to the newFixedThreadPool, except that the core thread and the maximum thread are both 1. When receiving a task, the core thread will execute task 1, then task 2 to task 100 will be put into the queue and wait for the core thread to execute. Therefore, in the above case, the execution efficiency is the slowest.
According to the above analysis, different thread pool parameters should be used for different tasks and scenarios. Then why does Alibaba's development manual not recommend the use of these three thread pools.
First of all, the most fundamental reason is that developers do not necessarily know the meaning of thread pool parameters, or developers do not know the underlying parameters of newFixedThreadPool, newFixedThreadPool and newCachedThreadPool. They just want to create a thread pool, so problems will occur at this time. According to the analysis just now, the thread pool parameters used by different businesses in different scenarios are different. Improper use will lead to performance degradation.
Secondly, these three thread pools have different problems. For example, the queue used by newSingleThreadExecutor and newFixedThreadPool is LinkedBlockingQueue unbounded queue.
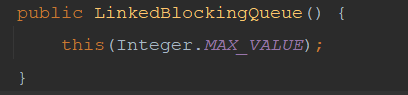
You can see that the maximum capacity of LinkedBlockingQueue is the maximum of Integer, that is, when there are too many tasks, it may lead to OOM. However, the size of LinkedBlockingQueue can be specified, but the size is not specified at the bottom of newSingleThreadExecutor and newFixedThreadPool. Therefore, the two thread pools may be OOM. Even if they do not cause OOM, excessive capacity will lead to frequent GC.
For newCachedThreadPool, SynchronousQueue is used, which is a synchronous queue and will not cause OOM, but its maximum number of threads is integer MAX_ VALUE. If there is any problem caused by unlimited thread creation, CPU100%.
Therefore, each of the three thread pools has its own problems. However, for small and medium-sized projects, these problems will not be caused due to insufficient quantity. It doesn't matter to use it. Specific situation specific analysis.
So the above three thread pools are not recommended. What thread pool do you use? Custom thread pool is recommended
Custom thread pool analysis
In the above case, none of the above three threads seems to be very satisfied. Either too many threads are created, or the queue space is too large, or the number of threads is too small. In this case, a custom thread pool is used.
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService1 = Executors.newCachedThreadPool();//fast
ExecutorService executorService2 = Executors.newFixedThreadPool(10);//slow
ExecutorService executorService3 = Executors.newSingleThreadExecutor();//Slowest
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(10, 20, 0L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(10));
for (int i = 1; i <= 100; i++) {
poolExecutor.execute(new MyTask(i));
}
}
}
Look at the execution results
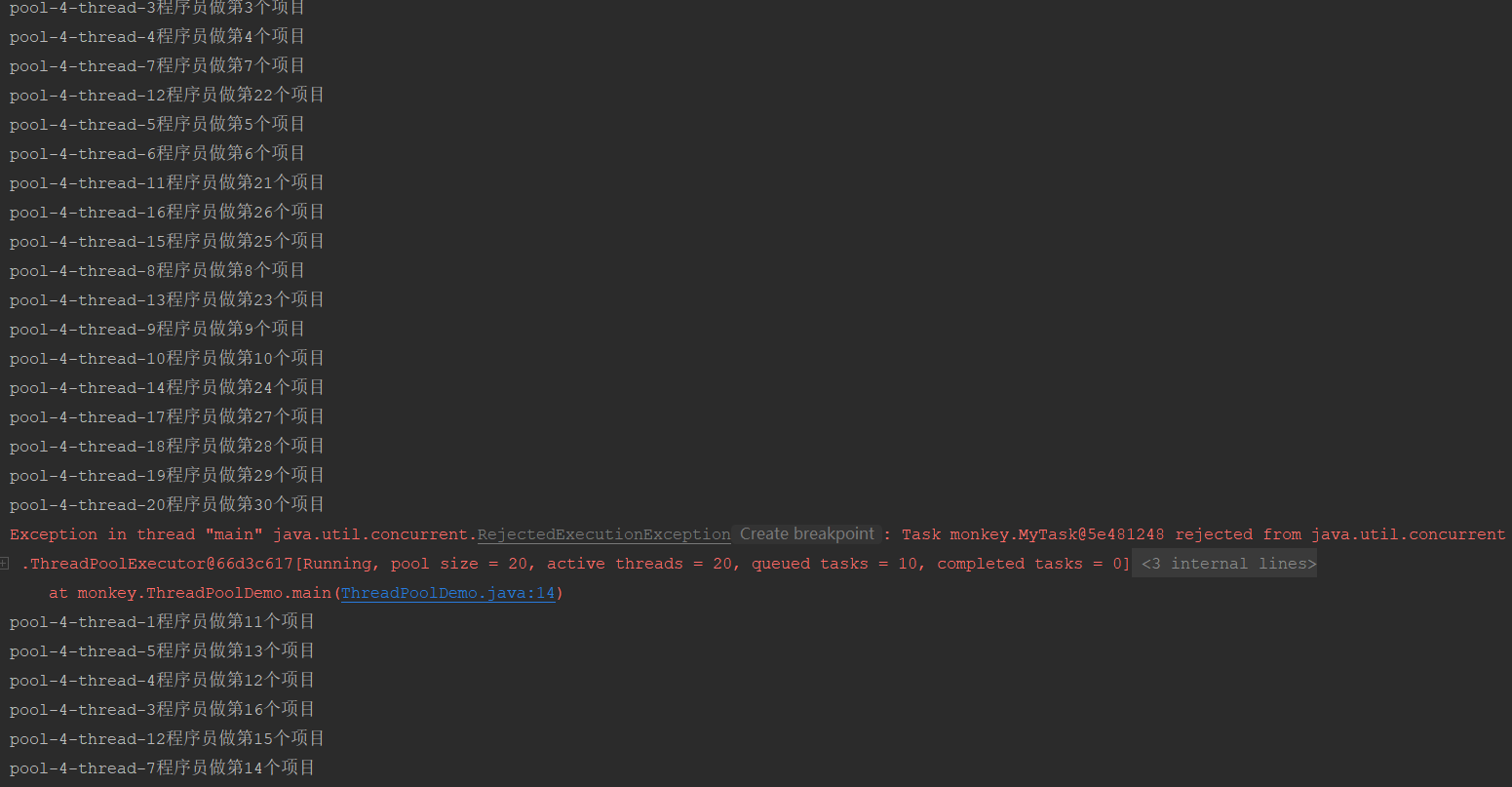
The exception thrown here is because the queue length is not enough, and the exception is thrown at the 31st task. Why is the exception thrown at the 31st task? Also, in terms of results, there is another problem, that is, the problem of order. From the above figure, tasks are performed from 1-10, then 20-30, and then 11-20. Our hypothetical execution order is 1-10, 10-20, 20-30. Why does this happen?
There are two knowledge points involved here: submission priority and execution priority. These are reflected in the source code.
Now start analyzing the source code to answer the above problems.
Thread pool source code analysis
Inheritance relationship
Let's take a look at the following class inheritance diagram:
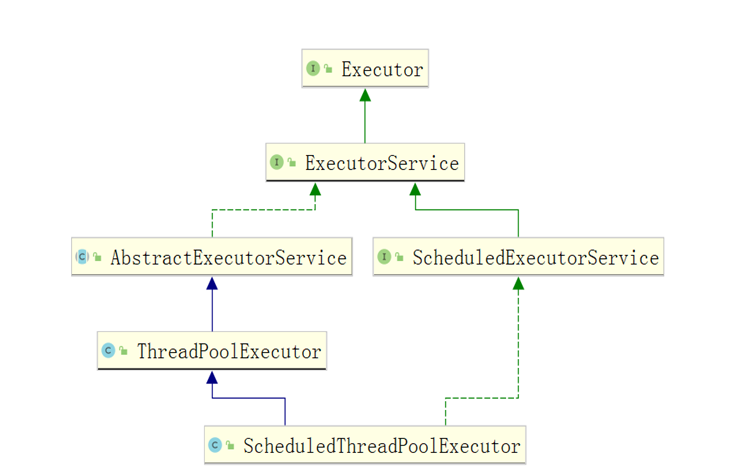
Executor has only one empty method of execute
ExecutorService inherits from Executor and provides the submit interface. ExecutorService is an interface, so the following methods are empty methods.
We often ask about the difference between the submit method and the execute method, which will also be mentioned later in the analysis.
AbstractExecutorService is an abstract class that implements the ExecutorService method and the submit method
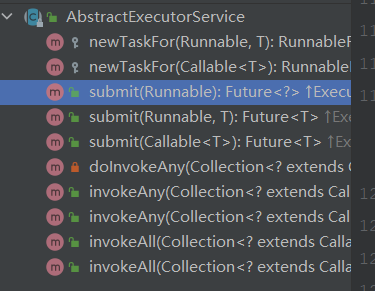
Thread pool ThreadPoolExecutor inherits AbstractExecutorService. The core of source code analysis. Override the execute method.
Source code analysis of ThreadPoolExecutor
AbstractExecutorService implements the ExecutorService method and the submit method
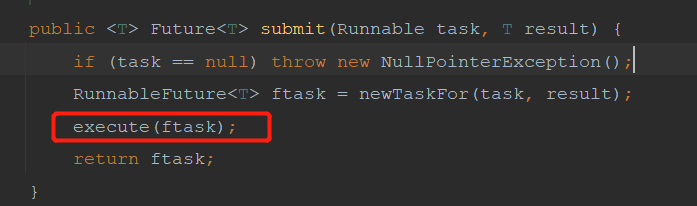
The submit underlying layer calls the execute method. So what's the difference between execute and submit. The first difference is that execute has no return value and submit has a return value.
When we use thread pool to execute tasks, poolexecutor execute(new MyTask(i)); The execute method was called to execute the task. As mentioned before, there are submission priority and execution priority. Although execute translates to execution, the source code of execute is the priority of submission, and the task must be submitted before execution.
Now let's look at the execute method
public void execute(Runnable command) {
//Judge whether Runnable is empty, and if it is empty, the pointer is abnormal
if (command == null)
throw new NullPointerException();
//ctl is a CAS operation of AtomicInteger type
int c = ctl.get();
//Judge whether the current number of threads is less than corePoolSize. If so, create a new thread through the addWord method
//If a new thread can be created, the execute method ends and the task is submitted successfully;
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//isRunning(c) determines the status of the thread,
//workQueue.offer an add method similar to a queue to add tasks to the queue
//If the status of the task can be added to the queue, and if the status is
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//A double test was done here
//If the status changes to non running after the task is added to the queue (it may be that the thread pool is shut down at this point of execution)
if (! isRunning(recheck) && remove(command))
//Call reject policy
reject(command);
//If the double check succeeds and the number of threads in the thread pool = = 0
else if (workerCountOf(recheck) == 0)
//Why is it null? When analyzing the source code of addWorker
// It is understood that a thread is created and an empty task is given
addWorker(null, false);
}else if (!addWorker(command, false)) //addWorker(command, false) here means to create a non core thread. If the creation fails, false will be returned
//The reject policy is invoked when addWorker returns false
reject(command);
}
ctl in the source code is the private final atomicinteger defined by ThreadPoolExecutor. ctl = new atomicinteger (ctlof (running, 0));
What is the difference between the offer method and the add method of workQueue? The offer and add methods of workQueue actually call the offer and add methods of AbstractQueue
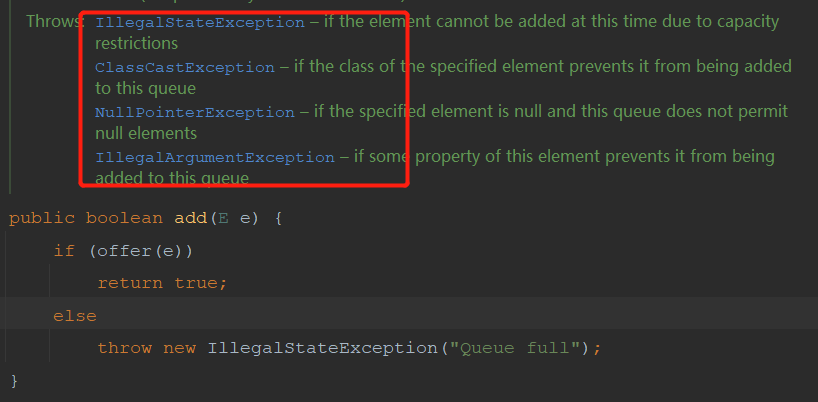
The bottom layer of the add method also calls the offer method. If the queue is full, add will throw an IllegalStateException exception, and the offer will only return false. And offer will throw three exceptions and add will throw four exceptions. The extra exception is the IllegalStateException exception.
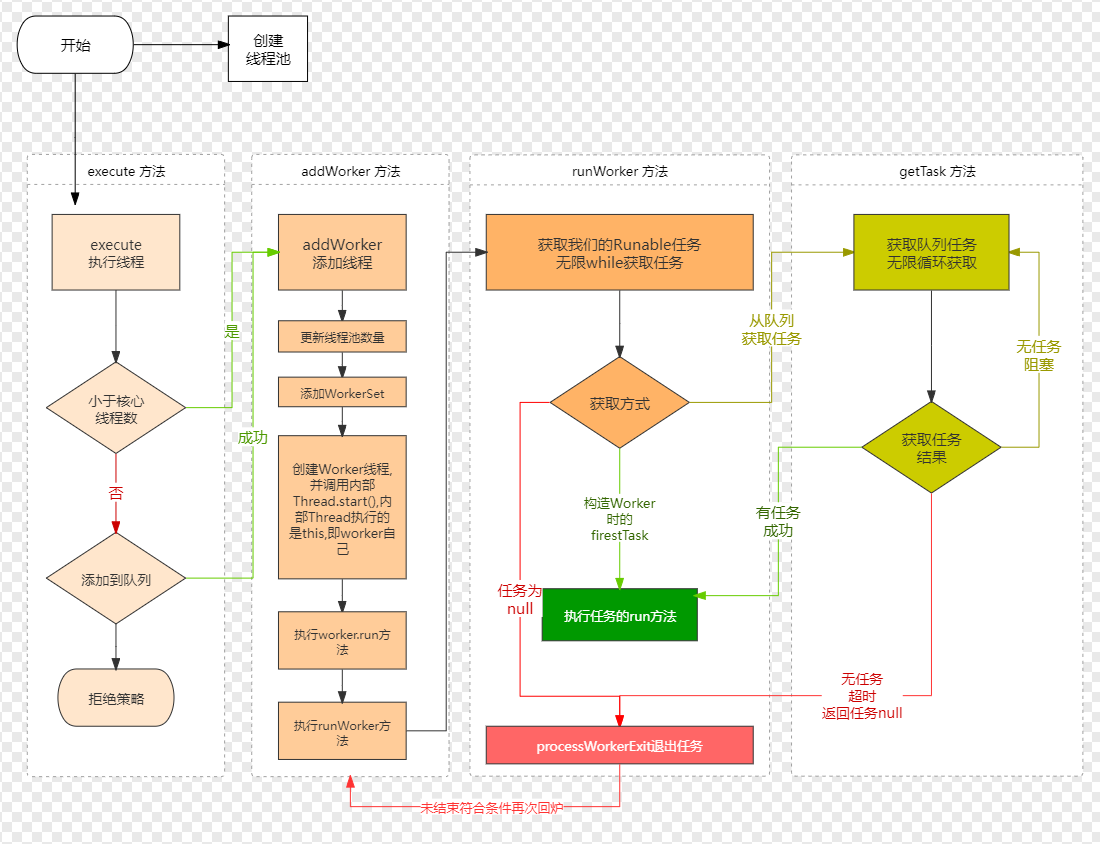
The above execute source code process is written in the notes. Now, through the above case, sort out the process again. In the case of custom thread pool analysis, the task is executed through the thread pool cycle 100 times. The whole process is as follows:
- When the first task comes in and execute s for the first time, judge whether the task is empty or not, and judge whether the current number of threads is less than the number of core threads. The number of core threads defined in the case is 10. If there is no thread at present, it must be less than 10. Then a thread is created through the addwork method. At this time, the thread is the core thread, and return is returned after the creation is successful. This thread is considered to be counted from 0. Less than 10 is also 10 core threads. Therefore, the tasks of 1-10 are handed over to 10 core threads.
- Then the 11th task came in. At this time, the core thread is no less than 10. Judge whether the thread state is running state (the default is running state), and then add it to the queue through the offer method. After success, the 11th task will be placed in the queue, and then make a secondary judgment to judge the thread running state again. If it is not running state and the task can be removed from the queue, call the reject policy. If the second judgment is successful and the number of thread pools is equal to 0, call the addwork method to pass in the null parameter. Since the capacity of the queue in the case is 10, tasks from 11 to 20 can be added to the queue, and since core threads are created, the number of thread pools is not equal to 0 at this time, so addwork(null,false) will not be executed; method
- Then task 21 comes in. At this time, the queue is full. The offer method returns false, so the else if method is executed to create a non core thread through addwork. If the creation is successful, the 21st task will be handed over to the non core thread; If the creation fails, the reject policy is called. Since the maximum number of threads in the case is 20, 10 non core threads can be created in addition to 10 core threads. So the tasks from 21 to 30 are handed over to non core threads.
- When the 31st task comes in, the core thread is full and the queue is full. Put the offer back to false and execute the addwork method in else if. Since the maximum number of threads is 20, there are already 20, so it is impossible to create the line layer. The reject policy is called and an exception is thrown.
This is why the exception thrown by the 31st task in the custom thread pool case. At the same time, the core thread executes 1-10 tasks, and the non core thread executes 21-30 tasks. Only when the thread has finished executing the task can it get the task execution from the queue. The tasks in the queue are 11-20, which is the reason why the tasks of 1-10 are executed first, the tasks of 21-30 are executed, and the tasks of 11-20 are executed last.
Let's analyze the source code of addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
retry: //goto statement not recommended by java is used
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
//Judge that if the thread is not running and the task is empty in the non SHUTDOWN state, the queue is not empty, and no more threads can be added
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
//Gets the current number of threads
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
//If the number of threads is greater than the maximum number of threads, do not increase the number of threads
return false;
//compareAndIncrementWorkerCount(c) ctl+1 number of worker threads + 1 if successful
//Here is only the number of threads + 1. There is no real creation of new threads. The creation work is later
if (compareAndIncrementWorkerCount(c))
//Jump out of loop
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//Creating a worker object can be temporarily understood as this thread
w = new Worker(firstTask);
//Get thread from worker object
final Thread t = w.thread;
if (t != null) {
//Lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
//Get thread status
int rs = runStateOf(ctl.get());
//Less than shutdown is the running state
//Or if SHUTDOWN and firstTask are empty, the task can be processed from the queue and put into the collection
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
//Judge whether the thread is alive before it is start ed, and directly exception
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//If everything is normal, add worker to workers, which is the HashSet set
workers.add(w);
//Get the number of current worker s
int s = workers.size();
if (s > largestPoolSize)
//The number of recording worker s is equal to the number of recording threads
largestPoolSize = s;
//Flag thread added successfully
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//If the thread is added successfully
if (workerAdded) {
//Execute thread start method
t.start();
//Marks the start of thread execution
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
There are notes on the general process of addWorker. Before further analysis, let's solve some problems. First, what is this worker. Look at the source code of worker
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
//thread
final Thread thread;
// First task
Runnable firstTask;
//How many tasks were performed
volatile long completedTasks;
//There is a parameter structure, where threads are created and tasks are set
Worker(Runnable firstTask) {
setState(-1); // Interrupt is not allowed during initialization
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
//run method to implement Runnable
public void run() {
runWorker(this);
}
}
The above is the more important source code display of Worker.
Solve another problem. Int c = CTL in both addWorker and execute methods get(); This C sometimes represents both the thread state and the number of threads. How to do this. Here is a simple explanation. See the definition of ThreadPoolExecutor of thread pool
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// The upper three bits indicate the status of the thread
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Get the thread status through the top three bits of ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
//Get the number of threads through the other 29 bits of ctl
private static int workerCountOf(int c) { return c & CAPACITY; }
//Calculate the number of CTLs
private static int ctlOf(int rs, int wc) { return rs | wc; }
Including COUNT_BITS is an int digit private static final int COUNT_BITS = Integer.SIZE - 3; //Integer.SIZE=32, so the actual COUNT_BITS = 29. The above five constants represent the status of the thread pool. In fact, they are represented by the upper three bits of 32 bits
After solving these two problems, let's analyze the addwork method through the above case.
- When the second task comes in, the execute method is executed, and then the addWorker(command, true) method is called. Judge the first for loop, judge the thread status, the queue is not empty, and so on; Through the judgment of the second for loop later, judge whether the current number of threads is greater than the maximum number of threads, and judge the thread state again. After passing ctl+1, exit the loop. By creating the worker object, the thread is created and the task is given (see the worker source code above for details). Then lock it and judge the thread state again. If it is in running state or shutdown state and the task is empty, it will be added to the HashSet set set of workers. Record the number of threads at this time. And call the start method.
- Then when the first task comes in and executes addWorker(command, true); Judging from the first for loop, there is no thread at this time, so you can also judge from the second for loop. Start to create a worker object, submit the first task to the worker through the worker's construction method, and create a thread at the same time. Finally, it is added to workers after judgment. The first ten tasks correspond to a core thread
- The 11th task is put into the queue in the execute method and will not execute addWorker, so no thread will be created. So the tasks of 11-20 will be in the queue
- 21 tasks come in and execute addWorker(command, false) in the same way; Method creates a thread in the same way
Finally, start () is executed in addwork; Method, because the Worker implements the Runnable interface, actually start(); Method is to call the Worker's run method. This run method calls runWorker(this); So we have to look at the source code of runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();//Get current thread
Runnable task = w.firstTask;//Get tasks in worker
w.firstTask = null;//Set worker's task to null
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//If the task is not null, execute the task. If the task is null, get the task from the queue
while (task != null || (task = getTask()) != null) {
w.lock();
//Judge the thread status. If it is stop, it will be interrupted immediately
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);//Task execution pre method this is an empty method
Throwable thrown = null;
try {
task.run();//Start task
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);//Task execution post method this is an empty method
}
} finally {
task = null; //Set the task to null and get it from the queue next time
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//Here is thread reuse
processWorkerExit(w, completedAbruptly);
}
}
The source code meaning of runWorker is very simple. Get the current thread and task, and then execute it. No matter how, the task will be set to null in order to get the task from the queue next time. The point is (task! = null 𞓜 (task = getTask())= Null) as mentioned before, submit priority and execution priority. The execute code describes the submission priority. This line of code is the execution priority. First judge whether the worker object has a task and execute it if there is; Failed to pass getTask(); Get object from queue.
Another knowledge point is that beforeExecute and afterExecute are empty methods, which can be implemented by themselves if necessary.
getTask(); The source code of the method is not analyzed, that is, get the task from the queue. Then analyze the source code of processWorkerExit
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
//Delete the worker
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
//The worker object is recreated and the task is null
addWorker(null, false);
}
}
The code of processWorkerExit is used to realize thread reuse, display the remove d worker in the source code, and then add worker (null, false); Then the created worker will get the task from the queue.
Here, the source code of thread pool is analyzed.
Reject strategy
ThreadPoolExecutor implements four rejection policies:
- CallerRunsPolicy, which is executed by the thread that calls the execute method to submit the task;
- AbortPolicy, throw an exception RejectedExecutionException and refuse to submit the task;
- Discard policy: directly discard the task without any processing;
- DiscardOldestPolicy: remove the first task (oldest) in the task queue and resubmit;
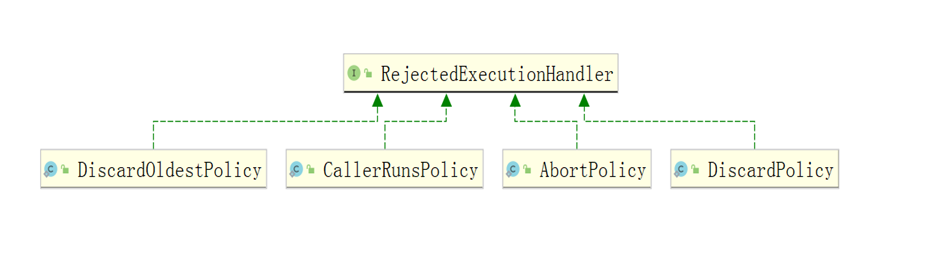
Generally speaking, the rejection policy provided internally is not used, but the rejection policy is implemented by yourself, and then business processing is carried out, such as recording database, logging, etc. How to use it?
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(1, 5, 1L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(10), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("Business processing, logging");
}
});
Thread pool flowchart