The article is very long, it is recommended to collect! High concurrent enthusiast community: Crazy maker circle Offer the following valuable learning resources to the children:
-
Crazy maker circle classic books: Classic "high concurrency trilogy of Java" Necessary for interview + necessary for large factory + necessary for salary increase
-
Crazy maker circle classic books: Netty Zookeeper Redis high concurrency practice Necessary for interview + necessary for large factory + necessary for salary increase Free collar
-
Crazy maker circle classic books: SpringCloud and Nginx high concurrency core programming Necessary for interview + necessary for large factory + necessary for salary increase Free collar
-
Resource treasure house of crazy maker circle: Java must have Baidu online disk resource collection, value > 1000 yuan[ Free access ]
Recommendation 2: 21 topics of the most complete Java interview questions in history
Recommendation 3: high quality blog posts in crazy maker circle
Thread safety issues across JVM s
In a single application development scenario, when concurrent synchronization is involved in a multithreaded environment, in order to ensure that a code block can only be accessed by one thread at the same time, we can generally use synchronized syntax and ReetrantLock to ensure that this is actually a local lock.
In other words, within the same JVM, we often use synchronized or Lock to solve the security problems between multiple threads. However, in the development scenario of distributed cluster work, between JVMs, a more advanced locking mechanism is needed to deal with thread safety between processes across JVMs
The solution is to use distributed locks
In short, for distributed scenarios, we can use distributed locks, which is a way to control mutually exclusive access to shared resources between distributed systems.
For example, in a distributed system, multiple services are deployed on multiple machines. When a user on the client initiates a data insertion request, if there is no guarantee of the distributed lock mechanism, multiple services on multiple machines may perform concurrent insertion operations, resulting in repeated data insertion. For some businesses that do not allow redundant data, This will cause problems. The distributed lock mechanism is to solve such problems and ensure mutually exclusive access to shared resources among multiple services. If one service preempts the distributed lock and other services do not obtain the lock, subsequent operations will not be carried out.
The general meaning is shown in the figure below (not necessarily accurate):
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-3yqrnpzj-1620199477085)( https://camo.githubusercontent.com/c797cf8770e4873899aa0337530e655b98ab0e01ad48fc4d5f660d11fd82027e/68747470733a2f2f706a6d696b652d313235333739363533362e636f732e61702d6265696a696e672e6d7971636c6f75642e636f6d2f2545352538382538362545352542382538332545352542432538462545392539342538312e706e67 )]
What is distributed lock?
What is distributed lock?
- When there is only one copy of data (or limited) in the distributed model, the lock technology needs to be used to control the number of processes that modify the data at a certain time.
- A status value is used to represent the lock, and the occupation and release of the lock are identified by the status value.
Conditions for distributed locks:
- Mutex. At any time, only one client can hold the lock.
- There will be no deadlock. Even if one client crashes while holding the lock without actively unlocking, it can ensure that other subsequent clients can lock.
- Fault tolerance. As long as most Redis nodes operate normally, the client can lock and unlock.
- Whoever unties the bell must tie it. Locking and unlocking must be the same client. The client cannot unlock the lock added by others.
Implementation of distributed lock:
There are many ways to implement distributed locks, such as file locks, databases, redis, etc; There are many common implementations of distributed locks:
- Database lock
- Database lock;
- Redis based distributed lock;
- Distributed lock based on ZooKeeper.
In redis, the performance of distributed locks is better
Database pessimistic lock
The so-called pessimistic lock is a pessimistic attitude towards the modification of data (it is believed that there will be concurrency problems when the data is modified), so the data will be locked in the whole data processing process.
The implementation of pessimistic lock often depends on the locking mechanism provided by the database (only the locking mechanism provided by the database layer can truly ensure the exclusivity of data access. Otherwise, even if the locking mechanism is implemented in the application layer, it can not guarantee that the external system will not modify the data).
Row locks, table locks and exclusive locks of the database are pessimistic locks. Here, take row locks as an example. Take our commonly used MySQL as an example. We use the select... for update statement. After executing the statement, we will hold the row lock on the table until the transaction is committed and release the row lock.
Examples of usage scenarios:
In the second kill case, the operations of generating orders and deducting inventory can be protected through the line lock of commodity records. By using the select... for update statement, we lock the record when querying the inventory of the commodity table, and release the lock after the inventory reduction of the order is completed.
The SQL of the example is as follows:
//0. Start transaction begin; //1. Query the commodity information select stockCount from seckill_good where id=1 for update; //2. Generate orders based on commodity information insert into seckill_order (id,good_id) values (null,1); //3. Modify commodity stockCount minus one update seckill_good set stockCount=stockCount-1 where id=1; //4. Submission of services commit;
Above, before modifying the record with id = 1, lock it through for update, and then modify it. This is a typical pessimistic locking strategy.
If the above code for modifying the inventory is concurrent, only one thread can open the transaction and obtain the lock with id=1 at the same time, and other transactions can be executed only after the transaction is committed. In this way, we can ensure that the current data will not be modified by other transactions.
We use select_for_update. In addition, it must be written in the transaction
Note: to use pessimistic lock, we must close the automatically submitted attribute in MySQL database, and the command set autocommit=0; You can close it, because MySQL uses autocommit mode by default, that is, when you perform an update operation, MySQL will submit the results immediately.
The implementation of pessimistic lock often depends on the lock mechanism provided by the database. In the database, the pessimistic lock process is as follows:
- Try to apply exclusive locking to the record before modifying it.
- If locking fails, it indicates that the record is being modified. The current query may have to wait or throw an exception. The specific response method is determined by the developer according to the actual needs.
- If you lock successfully, you can modify the record and unlock it after the transaction is completed.
- In the meantime, if other transactions lock the record, they must wait for the current transaction to unlock or throw an exception directly.
Database optimistic lock
Using optimistic locking does not need to rely on the locking mechanism of the database.
In fact, the concept of optimistic lock has described its specific implementation details: there are mainly two steps: conflict detection and data update. A typical implementation method is the Compare and Swap(CAS) technology.
CAS is an optimistic locking technology. When multiple threads try to use CAS to update the same variable at the same time, only one thread can update the value of the variable, while other threads fail. The failed thread will not be suspended, but will be told that it has failed in the competition and can try again.
In the implementation of CAS, a version field is added to the table. Before operation, query the version information, and check whether the version field has been modified during data submission. If it has not been modified, submit it, otherwise it is considered to be expired data.
For example, the previous problem of inventory deduction can be realized through optimistic locking as follows:
//1. Query the commodity information select stockCount, version from seckill_good where id=1; //2. Generate orders based on commodity information insert into seckill_order (id,good_id) values (null,1); //3. Modify commodity inventory update seckill_good set stockCount=stockCount-1, version = version+1 where id=1, version=version;
Above, before updating, we first query the current version in the inventory table, and then use version as a modification condition when updating.
When we submit the update, we judge that the current version of the record corresponding to the database table is compared with the version retrieved for the first time. If the current version of the database table is equal to the version retrieved for the first time, it will be updated, otherwise it will be considered as expired data.
CAS optimistic lock has two problems:
(1) There is an important problem in CAS, that is, ABA problem The solution is to increment the version field sequentially.
(2) In the optimistic locking mode, when there is high concurrency, only one thread can execute successfully, which will cause a lot of failures, which is obviously very bad for the user experience.
Zookeeper distributed lock
In addition to adding distributed locks at the database level, the following distributed locks with higher performance and higher availability can also be used:
- Distributed cache (e.g. redis) lock
- Distributed coordination (e.g. zookeeper) locks
Please refer to the following for the specific principles and implementation of distributed locks:
Zookeeper distributed lock (illustration + second understanding + most complete in History)
Or read the author's Java high concurrency core programming (Volume 1)

Redis distributed lock
This article focuses on Redis distributed locks, which are divided into two dimensions:
(1) Hand made wheel distributed lock based on Jedis
(2) This paper introduces the use and principle of redistribution distributed lock.
Distributed locks generally have the following characteristics:
- Mutex: only one thread can hold a lock at a time
- Reentrant: if the same thread on the same node acquires the lock, it can acquire the lock again
- Lock timeout: like the lock in J.U.C, it supports lock timeout to prevent deadlock
- High performance and high availability: locking and unlocking need to be efficient, but also need to ensure high availability and prevent distributed lock failure
- Blocking and non blocking: it can be awakened from the blocking state in time
Handmade wheels: distributed locks based on Jedis API
Let's first explain the implementation of Jedis ordinary distributed lock, which is a purely manual mode, starting with the most basic Redis command.
Only by fully understanding the ordinary Redis commands related to distributed locks can we better understand the implementation of advanced Redis distributed locks, because the implementation of advanced distributed locks is completely based on ordinary Redis commands.
Several Redis architectures
Up to now, several common deployment architectures of Redis include:
- Stand alone mode;
- Master slave mode;
- Sentinel mode;
- Cluster mode;
From the perspective of distributed lock, the principles of single machine mode, master-slave mode, sentinel mode and cluster mode are similar. Only the master-slave mode, sentinel mode and cluster mode are more highly available or more concurrent.
Therefore, the next step is to realize its own distributed lock based on stand-alone mode and Jedis hand-made wheels.
First look at two commands:
Redis distributed locking mechanism is mainly completed by using setnx and expire commands.
setnx command:
SETNX is short for SET if Not eXists. Set the value of the key to value if and only if the key does not exist; If the given key already exists, SETNX will not take any action.
The following is an example of client usage:
127.0.0.1:6379> set lock "unlock" OK 127.0.0.1:6379> setnx lock "unlock" (integer) 0 127.0.0.1:6379> setnx lock "lock" (integer) 0 127.0.0.1:6379>
expire command:
The expire command sets the lifetime for the key. When the key expires (the lifetime is 0), it will be deleted automatically The format is:
EXPIRE key seconds
The following is an example of client usage:
127.0.0.1:6379> expire lock 10 (integer) 1 127.0.0.1:6379> ttl lock 8
Overall process of distributed lock based on Jedis API:
Simple locking mechanism can be realized through Redis setnx and expire commands:
- Create when the key does not exist, set the value and expiration time, and the return value is 1; Successfully obtain the lock;
- If 0 is returned directly when the key exists, lock grabbing fails;
- When the thread holding the lock releases the lock, manually delete the key; Or when the expiration time expires, the key is automatically deleted and the lock is released.
When a thread successfully calls setnx method, it returns 1. It is considered that locking is successful. Other threads cannot call setnx again until the current thread completes the business operation and releases the lock.
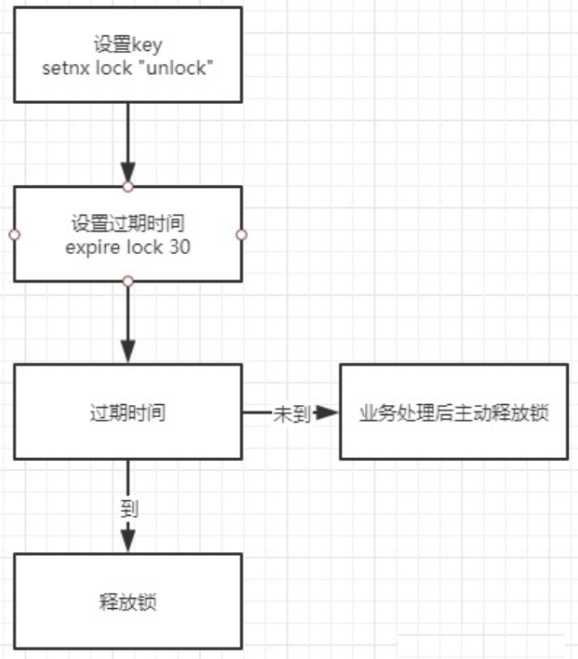
The above simple redis distributed lock problem:
If there is such a problem: if setnx is successful, but the expire setting fails, once the lock is released or not released manually, the lock will always be occupied and other threads will never grab the lock.
Therefore, it is necessary to ensure the atomicity of setnx and expire operations, either all or none. The two cannot be separated.
There are two solutions:
- When using the set command, set the expiration time at the same time, and do not use the expire command alone
- Use atomic lock in lua script
Simple locking: when using the set command, set the expiration time at the same time
When using the set command, an example of setting the expiration time at the same time is as follows:
127.0.0.1:6379> set unlock "234" EX 100 NX (nil) 127.0.0.1:6379> 127.0.0.1:6379> set test "111" EX 100 NX OK
This perfectly solves the atomicity of distributed locks; Full format of set command:
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds: Set the expiration time, in seconds PX milliseconds: Set the expiration duration in milliseconds NX: key Set when not present value,Successful return OK,Failure Return(nil) XX: key Set when present value,Successful return OK,Failure Return(nil)
Use the set command to realize the locking operation. First show the simple code practice of locking, and then slowly explain why it is implemented in this way.
Simple code implementation of locking
package com.crazymaker.springcloud.standard.lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisCommandLock {
private RedisTemplate redisTemplate;
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* Attempt to acquire distributed lock
* @param jedis Redis client
* @param lockKey lock
* @param requestId Request identification
* @param expireTime Overdue time
* @return Is it successful
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
As you can see, we use Jedis's set Api for locking:
jedis.set(String key, String value, String nxxx, String expx, int time)
This set() method has five formal parameters:
-
The first one is the key. We use the key as the lock because the key is unique.
-
The second one is value. We pass requestId. Many children's shoes may not understand. Isn't it enough to have a key as a lock? Why use value? The reason is that when we talk about reliability above, the distributed lock must meet the fourth condition. The person who tied the bell must unlock the lock. By assigning value to requestId, we can know which request added the lock and have a basis when unlocking.
requestId can use UUID randomUUID(). Generated by tostring() method.
-
The third parameter is nxxx. NX is filled in this parameter, which means SET IF NOT EXIST, that is, when the key does not exist, we perform set operation; If the key already exists, no operation will be performed;
-
The fourth parameter is expx. We pass PX, which means that we need to add an expiration setting to the key. The specific time is determined by the fifth parameter.
-
The fifth is time, which corresponds to the fourth parameter and represents the expiration time of the key.
In general, executing the set() method above will only lead to two results:
- If there is no lock at present (the key does not exist), then lock it and set a valid period for the lock. At the same time, value represents the locked client.
- Existing lock exists, no operation is required.
Careful children's shoes will find that our locking code meets three of the four conditions described above.
-
First, the NX parameter is added to set() to ensure that if the existing key exists, the function will not be called successfully, that is, only one client can hold the lock and meet the mutual exclusion.
-
Secondly, because we set the expiration time for the lock, even if the lock holder crashes and does not unlock it later, the lock will be unlocked automatically (i.e. the key will be deleted) and will not be occupied forever (and a life and death lock will occur).
-
Finally, because we assign value to requestId, which represents the request ID of the locked client, we can verify whether it is the same client when the client is unlocked.
-
Since we only consider the scenario of Redis single machine deployment, we will not consider the fault tolerance temporarily.
Simple unlocking code based on Jedis API
Let's show the code first, and then slowly explain why it is implemented in this way.
Simple code implementation of unlocking:
package com.crazymaker.springcloud.standard.lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisCommandLock {
private static final Long RELEASE_SUCCESS = 1L;
/**
* Release distributed lock
* @param jedis Redis client
* @param lockKey lock
* @param requestId Request identification
* @return Is the release successful
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
So what is the function of this Lua code?
In fact, it is very simple. First, get the value corresponding to the lock and check whether it is equal to requestId. If it is equal, delete the lock (unlock).
In the first line of code, we wrote a simple Lua script code.
In the second line of code, we transfer Lua code to jedis eval() method, and assign the parameter KEYS[1] to lockKey and ARGV[1] to requestId. The eval () method is to hand over the Lua code to the Redis server for execution.
So why use Lua language to implement it?
Because it is necessary to ensure that the above operations are atomic. The reason why the implementation of eval() method can ensure atomicity stems from the characteristics of Redis
To put it simply, when the eval command executes Lua code, Lua code will be executed as a command, and Redis will not execute other commands until the eval command is executed
Error example 1
The most common unlocking code is to directly use jedis Del () method deletes the lock. This method of directly unlocking the lock without first judging the owner of the lock will cause any client to unlock it at any time, even if the lock is not its own.
public static void wrongReleaseLock1(Jedis jedis, String lockKey) {
jedis.del(lockKey);
}
Error example 2
At first glance, this unlocking code is OK. Even I almost realized it before. It is similar to the correct posture. The only difference is that it is divided into two commands to execute. The code is as follows:
public static void wrongReleaseLock2(Jedis jedis, String lockKey, String requestId) {
// Judge whether locking and unlocking are the same client
if (requestId.equals(jedis.get(lockKey))) {
// If at this time, the lock is suddenly not owned by this client, it will be unlocked by mistake
jedis.del(lockKey);
}
}
Reengineering wheels: implementing distributed locks based on Lua script
Benefits of lua scripts
As mentioned earlier, executing lua script in redis has the following advantages:
So why use Lua language to implement it?
Because it is necessary to ensure that the above operations are atomic. The reason why the implementation of eval() method can ensure atomicity stems from the characteristics of Redis
To put it simply, when the eval command executes Lua code, Lua code will be executed as a command, and Redis will not execute other commands until the eval command is executed
So:
Most of the distributed lock components in open source frameworks (such as redistribution) are implemented with pure lua scripts.
Aside: lua script is a necessary script language with high concurrency and high performance
For a detailed introduction to lua, please refer to the following books:

Well, let's simulate it
Execution flow of distributed lock based on pure Lua script
The operations of adding and deleting locks are encapsulated with pure lua to ensure the atomicity of their execution.
The execution process of distributed lock based on pure Lua script is roughly as follows:
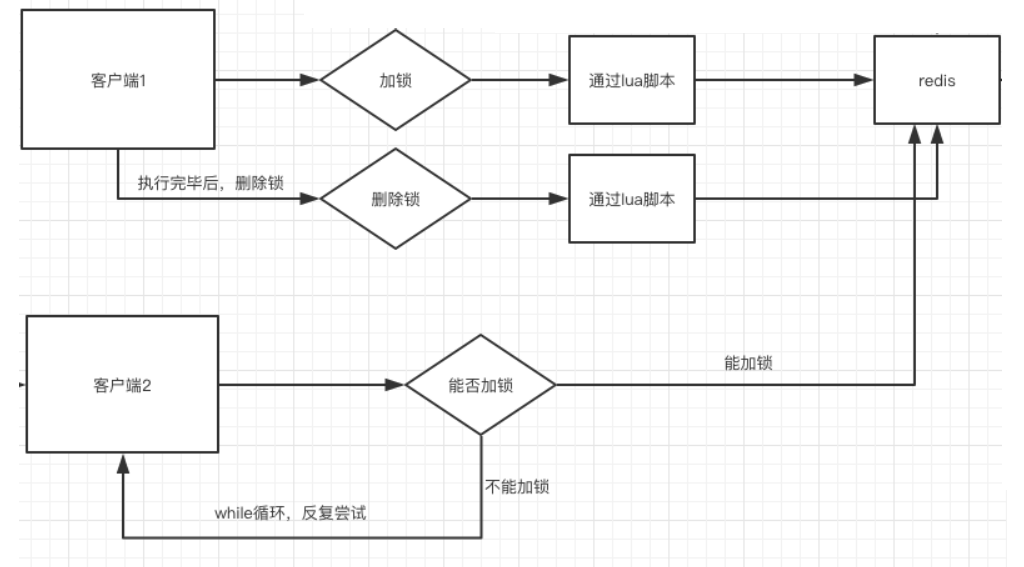
Lua script with lock: lock lua
--- -1 failed
--- 1 success
---
local key = KEYS[1]
local requestId = KEYS[2]
local ttl = tonumber(KEYS[3])
local result = redis.call('setnx', key, requestId)
if result == 1 then
--PEXPIRE:Specifies the expiration time in milliseconds
redis.call('pexpire', key, ttl)
else
result = -1;
-- If value If it is the same, it is considered as a request of the same thread, and it is considered as a re-entry lock
local value = redis.call('get', key)
if (value == requestId) then
result = 1;
redis.call('pexpire', key, ttl)
end
end
-- If the lock is obtained successfully, 1 is returned
return result
Unlocked Lua script: unlock lua:
--- -1 failed
--- 1 success
-- unlock key
local key = KEYS[1]
local requestId = KEYS[2]
local value = redis.call('get', key)
if value == requestId then
redis.call('del', key);
return 1;
end
return -1
Two files are put under the resource folder for standby:
The lua script is called in Java to complete the locking operation.
Next, implement the Lock interface to complete the distributed Lock of JedisLock.
For its locking operation, call lock Lua script is completed, and the code is as follows:
package com.crazymaker.springcloud.standard.lock;
import com.crazymaker.springcloud.common.exception.BusinessException;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisLock implements Lock {
private RedisTemplate redisTemplate;
RedisScript<Long> lockScript = null;
RedisScript<Long> unLockScript = null;
public static final int DEFAULT_TIMEOUT = 2000;
public static final Long LOCKED = Long.valueOf(1);
public static final Long UNLOCKED = Long.valueOf(1);
public static final Long WAIT_GAT = Long.valueOf(200);
public static final int EXPIRE = 2000;
String key;
String lockValue; // lockValue the value of the lock, which represents the uuid of the thread
/**
* The default is 2000ms
*/
long expire = 2000L;
public JedisLock(String lockKey, String lockValue) {
this.key = lockKey;
this.lockValue = lockValue;
}
private volatile boolean isLocked = false;
private Thread thread;
/**
* Obtain a distributed lock, and return failure if timeout
*
* @return Lock success - true | lock failure - false
*/
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
//Local reentrant
if (isLocked && thread == Thread.currentThread()) {
return true;
}
expire = unit != null ? unit.toMillis(time) : DEFAULT_TIMEOUT;
long startMillis = System.currentTimeMillis();
Long millisToWait = expire;
boolean localLocked = false;
int turn = 1;
while (!localLocked) {
localLocked = this.lockInner(expire);
if (!localLocked) {
millisToWait = millisToWait - (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if (millisToWait > 0L) {
/**
* It hasn't timed out yet
*/
ThreadUtil.sleepMilliSeconds(WAIT_GAT);
log.info("Sleep, start over, turn:{},Time remaining:{}", turn++, millisToWait);
} else {
log.info("Lock grabbing timeout");
return false;
}
} else {
isLocked = true;
localLocked = true;
}
}
return isLocked;
}
/**
* Snatch lock with return value
*
* @param millisToWait
*/
public boolean lockInner(Long millisToWait) {
if (null == key) {
return false;
}
try {
List<String> redisKeys = new ArrayList<>();
redisKeys.add(key);
redisKeys.add(lockValue);
redisKeys.add(String.valueOf(millisToWait));
Long res = (Long) redisTemplate.execute(lockScript, redisKeys);
return res != null && res.equals(LOCKED);
} catch (Exception e) {
e.printStackTrace();
throw BusinessException.builder().errMsg("Lock grabbing failed").build();
}
}
}
The lua script is called in Java to complete the unlocking operation.
To unlock it, call unlock Lua script is completed, and the code is as follows:
package com.crazymaker.springcloud.standard.lock;
import com.crazymaker.springcloud.common.exception.BusinessException;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
@Slf4j
@Data
@AllArgsConstructor
public class JedisLock implements Lock {
private RedisTemplate redisTemplate;
RedisScript<Long> lockScript = null;
RedisScript<Long> unLockScript = null;
//Release lock
@Override
public void unlock() {
if (key == null || requestId == null) {
return;
}
try {
List<String> redisKeys = new ArrayList<>();
redisKeys.add(key);
redisKeys.add(requestId);
Long res = (Long) redisTemplate.execute(unLockScript, redisKeys);
} catch (Exception e) {
e.printStackTrace();
throw BusinessException.builder().errMsg("Failed to release lock").build();
}
}
}
Write RedisLockService to manage JedisLock
Write a distributed lock service to load lua script and create distributed lock. The code is as follows:
package com.crazymaker.springcloud.standard.lock;
import com.crazymaker.springcloud.common.util.IOUtil;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
@Slf4j
@Data
public class RedisLockService
{
private RedisTemplate redisTemplate;
static String lockLua = "script/lock.lua";
static String unLockLua = "script/unlock.lua";
static RedisScript<Long> lockScript = null;
static RedisScript<Long> unLockScript = null;
{
String script = IOUtil.loadJarFile(RedisLockService.class.getClassLoader(),lockLua);
// String script = FileUtil.readString(lockLua, Charset.forName("UTF-8" ));
if(StringUtils.isEmpty(script))
{
log.error("lua load failed:"+lockLua);
}
lockScript = new DefaultRedisScript<>(script, Long.class);
// script = FileUtil.readString(unLockLua, Charset.forName("UTF-8" ));
script = IOUtil.loadJarFile(RedisLockService.class.getClassLoader(),unLockLua);
if(StringUtils.isEmpty(script))
{
log.error("lua load failed:"+unLockLua);
}
unLockScript = new DefaultRedisScript<>(script, Long.class);
}
public RedisLockService(RedisTemplate redisTemplate)
{
this.redisTemplate = redisTemplate;
}
public Lock getLock(String lockKey, String lockValue) {
JedisLock lock=new JedisLock(lockKey,lockValue);
lock.setRedisTemplate(redisTemplate);
lock.setLockScript(lockScript);
lock.setUnLockScript(unLockScript);
return lock;
}
}
test case
Next, we can finally test cases
package com.crazymaker.springcloud.lock;
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {DemoCloudApplication.class})
// Specify startup class
public class RedisLockTest {
@Resource
RedisLockService redisLockService;
private ExecutorService pool = Executors.newFixedThreadPool(10);
@Test
public void testLock() {
int threads = 10;
final int[] count = {0};
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++) {
pool.submit(() ->
{
String lockValue = UUID.randomUUID().toString();
try {
Lock lock = redisLockService.getLock("test:lock:1", lockValue);
boolean locked = lock.tryLock(10, TimeUnit.SECONDS);
if (locked) {
for (int j = 0; j < 1000; j++) {
count[0]++;
}
log.info("count = " + count[0]);
lock.unlock();
} else {
System.out.println("Lock grabbing failed");
}
} catch (Exception e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("10 Each thread adds up to 1000: = " + count[0]);
//Output statistical results
float time = System.currentTimeMillis() - start;
System.out.println("Run for(ms): " + time);
System.out.println("The duration of each execution is(ms): " + time / count[0]);
}
}
Execute the use case, and the results are as follows:
2021-05-04 23:02:11.900 INFO 22120 --- [pool-1-thread-7] c.c.springcloud.lock.RedisLockTest LN:50 count = 6000 2021-05-04 23:02:11.901 INFO 22120 --- [pool-1-thread-1] c.c.springcloud.standard.lock.JedisLock LN:81 Sleep, start over, turn:3,Time remaining: 9585 2021-05-04 23:02:11.902 INFO 22120 --- [pool-1-thread-1] c.c.springcloud.lock.RedisLockTest LN:50 count = 7000 2021-05-04 23:02:12.100 INFO 22120 --- [pool-1-thread-4] c.c.springcloud.standard.lock.JedisLock LN:81 Sleep, start over, turn:3,Time remaining: 9586 2021-05-04 23:02:12.101 INFO 22120 --- [pool-1-thread-5] c.c.springcloud.standard.lock.JedisLock LN:81 Sleep, start over, turn:3,Time remaining: 9585 2021-05-04 23:02:12.101 INFO 22120 --- [pool-1-thread-8] c.c.springcloud.standard.lock.JedisLock LN:81 Sleep, start over, turn:3,Time remaining: 9585 2021-05-04 23:02:12.101 INFO 22120 --- [pool-1-thread-4] c.c.springcloud.lock.RedisLockTest LN:50 count = 8000 2021-05-04 23:02:12.102 INFO 22120 --- [pool-1-thread-8] c.c.springcloud.lock.RedisLockTest LN:50 count = 9000 2021-05-04 23:02:12.304 INFO 22120 --- [pool-1-thread-5] c.c.springcloud.standard.lock.JedisLock LN:81 Sleep, start over, turn:4,Time remaining: 9383 2021-05-04 23:02:12.307 INFO 22120 --- [pool-1-thread-5] c.c.springcloud.lock.RedisLockTest LN:50 count = 10000 10 Each thread adds up to 1000: = 10000 Run for(ms): 827.0 The duration of each execution is(ms): 0.0827
Lock expiration caused by STW
Here is a simple example of using a lock, occupying the lock in 10 seconds:
//Write data to file
function writeData(filename, data) {
boolean locked = lock.tryLock(10, TimeUnit.SECONDS);
if (!locked) {
throw 'Failed to acquire lock';
}
try {
//Write data to file
var file = storage.readFile(filename);
var updated = updateContents(file, data);
storage.writeFile(filename, updated);
} finally {
lock.unlock();
}
}
The problem is: if a fullGC occurs during file writing, and its time span is longer than 10 seconds, the distributed will be released automatically.
In this process, client2 grabs the lock and writes the file.
After the fullGC of client1 is completed, continue to write the file. Note that client1 does not occupy the lock at this time. Writing at this time will lead to file data disorder and thread safety problems.
This is the problem of lock expiration caused by STW.
The lock expiration caused by STW is shown in the following figure:
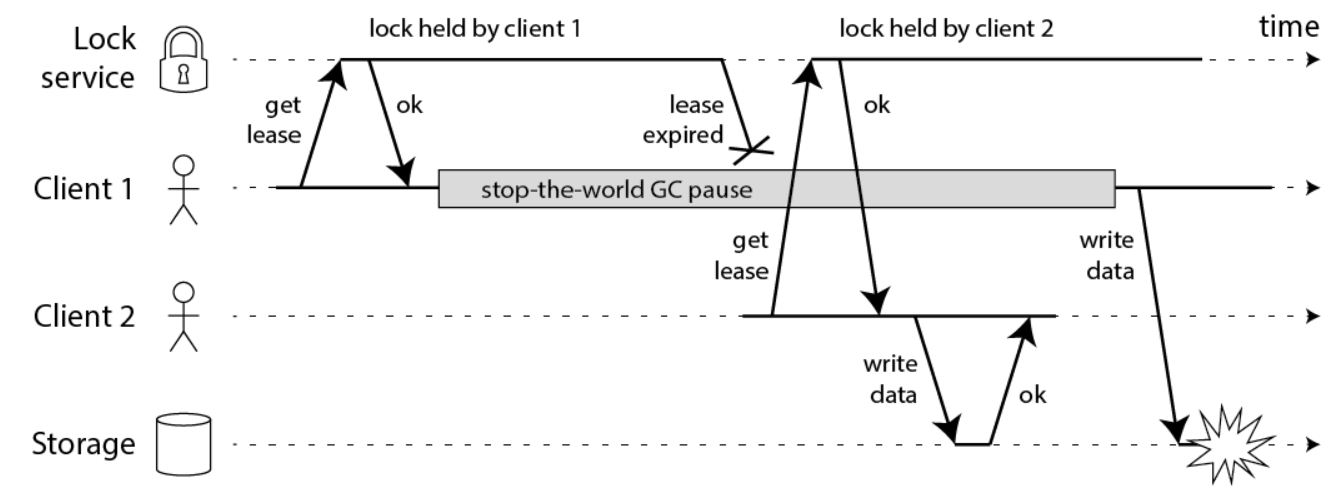
For the lock expiration problem caused by STW, the approximate solutions are:
1: Simulate CAS optimistic locking mode and increase version number
2: Automatic delay mechanism of watch dog
1: Simulate the optimistic lock mode of CAS and increase the version number (as shown in the token in the figure below)
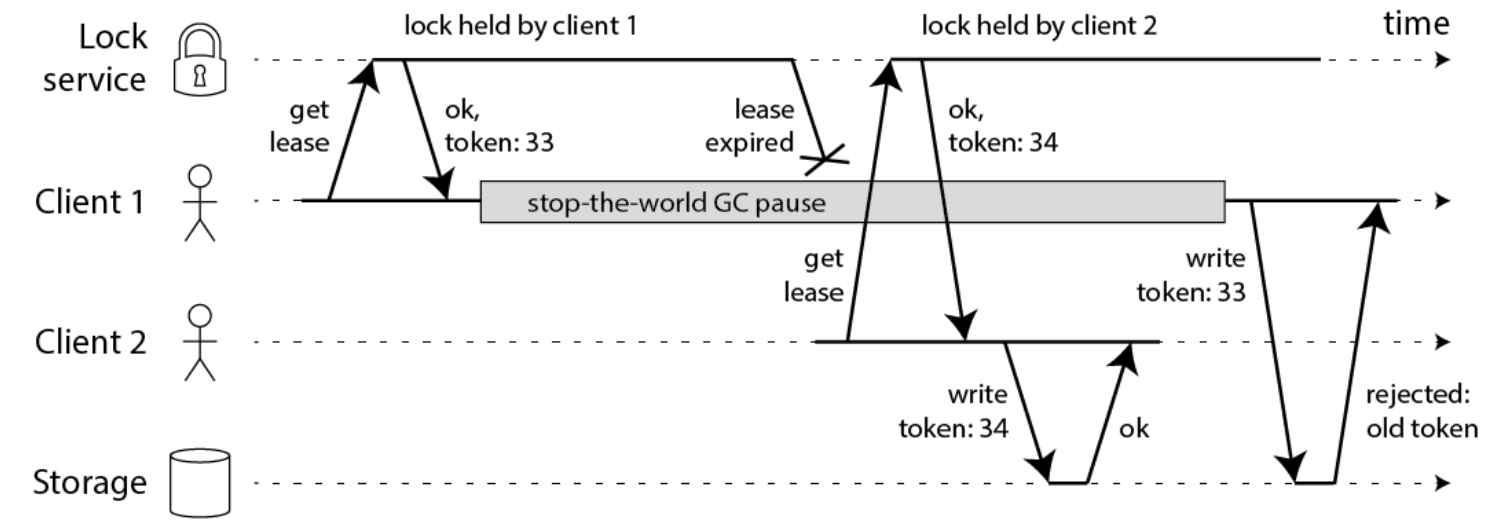
If this scheme is to be implemented, the business logic needs to be adjusted to cooperate with it, so it will invade the code.
2: Automatic delay mechanism of watch dog
The default lifetime of the lock key locked by client 1 is only 30 seconds. If it exceeds 30 seconds, client 1 still wants to hold the lock all the time. What should I do?
Simple! As long as client 1 succeeds in locking, it will start a watch dog. It is a background thread and will check every 10 seconds. If client 1 still holds the lock key, it will continue to prolong the survival time of the lock key.
Redismission adopts this scheme, which will not invade business code.
Why is redistribution recommended
As Java developers, if we want to integrate Redis in the program, we must use the third-party library of Redis. At present, the most used third-party library is jedis.
Like spring cloud gateway, Redisson is also implemented based on Netty and is a third-party library with higher performance. Therefore, it is recommended to use redistribution instead of jedis.
Before using Redission, I suggest you master the knowledge of Netty.
I recommend you to read the most understandable NIO and Netty books in history rated by many small partners: "Java high concurrency core programming (Volume 1)"
About Redisson
Redisson is a Java in memory data grid implemented on the basis of Redis. It not only provides a series of Distributed Common Java objects, but also implements Reentrant Lock, Fair Lock, MultiLock, RedLock, ReadWriteLock, etc. it also provides many distributed services.

Redisson provides the simplest and most convenient way to use Redis. Redisson aims to promote users' Separation of Concern on Redis, so that users can focus more on processing business logic.

Comparison between Redisson and Jedis
1. Overview comparison
Jedis is the java implementation client of Redis. Its API provides comprehensive support for Redis commands. Redison implements a distributed and extensible java data structure. Compared with jedis, the function is relatively simple, does not support string operation, sorting, things, management, partition and other Redis features. Redisson aims to promote the separation of users' attention to Redis, so that users can focus more on processing business logic.
2. Scalability
Jedis uses blocked I/O, and its method calls are synchronous. The program flow cannot be executed until the sockets process I/O. asynchronous is not supported. Jedis client instance is not thread safe, so jedis needs to be used through connection pool.
Redisson uses non blocking I/O and event driven communication layer based on Netty framework, and its method calls are asynchronous. Redisson API is thread safe, so operate a single redisson connection to complete various operations.
3. Third party framework integration
Redisson implements the java cache standard based on Redis; Redisson also provides the implementation of Spring Session reply manager.
Redission's source code address:
Official website: https://redisson.org/
github: https://github.com/redisson/redisson#quick-start
Features & functions:
-
It supports Redis single node mode, sentinel mode, Master/Slave mode and Redis Cluster mode
-
The calling mode of program interface adopts asynchronous execution and asynchronous flow execution
-
Data serialization: Redisson's object encoding class is used to serialize and deserialize objects to realize the reading and storage of the object in Redis
-
Single set data fragmentation. In the cluster mode, redison provides automatic fragmentation for a single Redis set type
-
Provide a variety of distributed objects, such as Object Bucket, Bitset, AtomicLong, Bloom Filter and hyperlog
-
Provide rich distributed collections, such as Map, Multimap, Set, SortedSet, List, Deque, Queue, etc
-
Implementation of distributed lock and synchronizer, Reentrant Lock, Fair Lock, MultiLock, Red Lock, semaphore, permitexpirable semaphore, etc
-
Provide advanced distributed services, such as Remote Service, Live Object service, Executor Service, Schedule Service and MapReduce
Use of Redisson
How to install Redisson
The most convenient way to install Redisson is to use Maven or Gradle:
•Maven
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.4</version>
</dependency>
•Gradle
compile group: 'org.redisson', name: 'redisson', version: '3.11.4'
At present, the latest version of Redisson is 3.11.4. Of course, you can also find various versions of Redisson by searching Maven central warehouse mvnrepository[1].
Get RedissonClient object
RedissonClient has many modes. The main modes are:
-
Single node mode
-
Sentinel mode
-
Master-slave mode
-
Cluster mode
First, the single node mode is introduced.
The programmed configuration method of single node mode is roughly as follows:
Config config = new Config();
config.useSingleServer().setAddress("redis://myredisserver:6379");
RedissonClient redisson = Redisson.create(config);xxxxxxxxxx Config config = new Config();config.useSingleServer().setAddress("redis://myredisserver:6379");RedissonClient redisson = Redisson.create(config);// connects to 127.0.0.1:6379 by defaultRedissonClient redisson = Redisson.create();
SingleServerConfig singleConfig = config.useSingleServer();
The setting parameters of SingleServerConfig class are as follows:
Address (node address)
You can specify the node address in the format of host:port.
subscriptionConnectionMinimumIdleSize (minimum number of free connections for publish and subscribe connections)
Default: 1
Minimum number of persistent connections (long connections) for publish and subscribe connections. Redisson often implements many functions through publishing and subscription. It is necessary to maintain a certain number of publish and subscribe connections for a long time.
subscriptionConnectionPoolSize (publish and subscribe connection pool size)
Default: 50
The maximum capacity of the connection pool for publish and subscribe connections. The number of connections in the connection pool automatically scales elastically.
connectionMinimumIdleSize
Default: 32
Minimum number of maintained connections (long connections). Maintaining a certain number of connections for a long time is conducive to improving the instantaneous write response speed.
connectionPoolSize
Default: 64
Maximum connection pool capacity. The number of connections in the connection pool automatically scales elastically.
dnsMonitoring (enable DNS monitoring)
Default: false
After enabling this function, Redisson will monitor the changes of DNS.
dnsMonitoringInterval (DNS monitoring interval, unit: ms)
Default: 5000
Time interval to monitor changes in DNS.
idleConnectionTimeout (connection idle timeout in milliseconds)
Default: 10000
If the number of connections in the current connection pool exceeds the minimum number of idle connections, and the idle time of some connections exceeds this value, these connections will be automatically closed and removed from the connection pool. The unit of time is milliseconds.
connectTimeout (connection timeout in milliseconds)
Default: 10000
Wait timeout when establishing connection with node. The unit of time is milliseconds.
Timeout (command wait timeout in milliseconds)
Default: 3000
The time to wait for the node to reply to the command. This time starts when the command is sent successfully.
retryAttempts (number of command failure retries)
Default: 3
An error will be thrown if the command cannot be sent to a specified node after trying to reach retryAttempts. If the attempt to send within this limit is successful, enable the timeout timer.
retryInterval (interval between command retry sending, unit: ms)
Default: 1500
The time interval between waiting to retry sending after a command fails to be sent. The unit of time is milliseconds.
reconnectionTimeout (reconnection interval in milliseconds)
Default: 3000
The interval of time to wait for a connection to be reestablished with a node when it is disconnected. The unit of time is milliseconds.
failedAttempts (maximum number of execution failures)
Default: 3
When a node executes the same or different commands, the node will be cleared from the list of available nodes in case of continuous failure of failedAttempts (maximum number of execution failures), and will try again after the reconnectionTimeout (reconnection interval) expires.
Database (database number)
Default: 0
The number of the database you are trying to connect to.
password
Default: null
Password used for node authentication.
subscriptionsPerConnection (maximum number of subscriptions per connection)
Default: 5
Maximum number of subscriptions per connection.
clientName (client name)
Default: null
The name of the client displayed in the Redis node.
sslEnableEndpointIdentification (enable SSL terminal identification)
Default value: true
Enable SSL terminal identification.
sslProvider (SSL Implementation)
Default: JDK
Determine which method (JDK or OPENSSL) is used to realize SSL connection.
SSL truststore (path of SSL trust certificate store)
Default: null
Specify the path to the SSL trust certificate library.
SSL truststorepassword (SSL trust certificate store password)
Default: null
Specify the password for the SSL trust library.
SSL keystore (SSL keystore path)
Default: null
Specifies the path to the SSL keystore.
SSL keystorepassword (SSL keystore password)
Default: null
Specifies the password for the SSL keystore.
Spring boot integrates Redisson
Redisson has many modes. First, introduce the integration of single machine mode.
1, Import Maven dependencies
<!-- redisson-springboot -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.11.4</version>
</dependency>
2, Core profile
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 5000
3, Add configuration class
RedissonConfig.java
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedissonConfig {
@Autowired
private RedisProperties redisProperties;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
String redisUrl = String.format("redis://%s:%s", redisProperties.getHost() + "", redisProperties.getPort() + "");
config.useSingleServer().setAddress(redisUrl).setPassword(redisProperties.getPassword());
config.useSingleServer().setDatabase(3);
return Redisson.create(config);
}
}
Custom starter
Because redismission can have multiple modes, for the purpose of learning, encapsulating multiple modes into a start, you can learn how to make a starter.
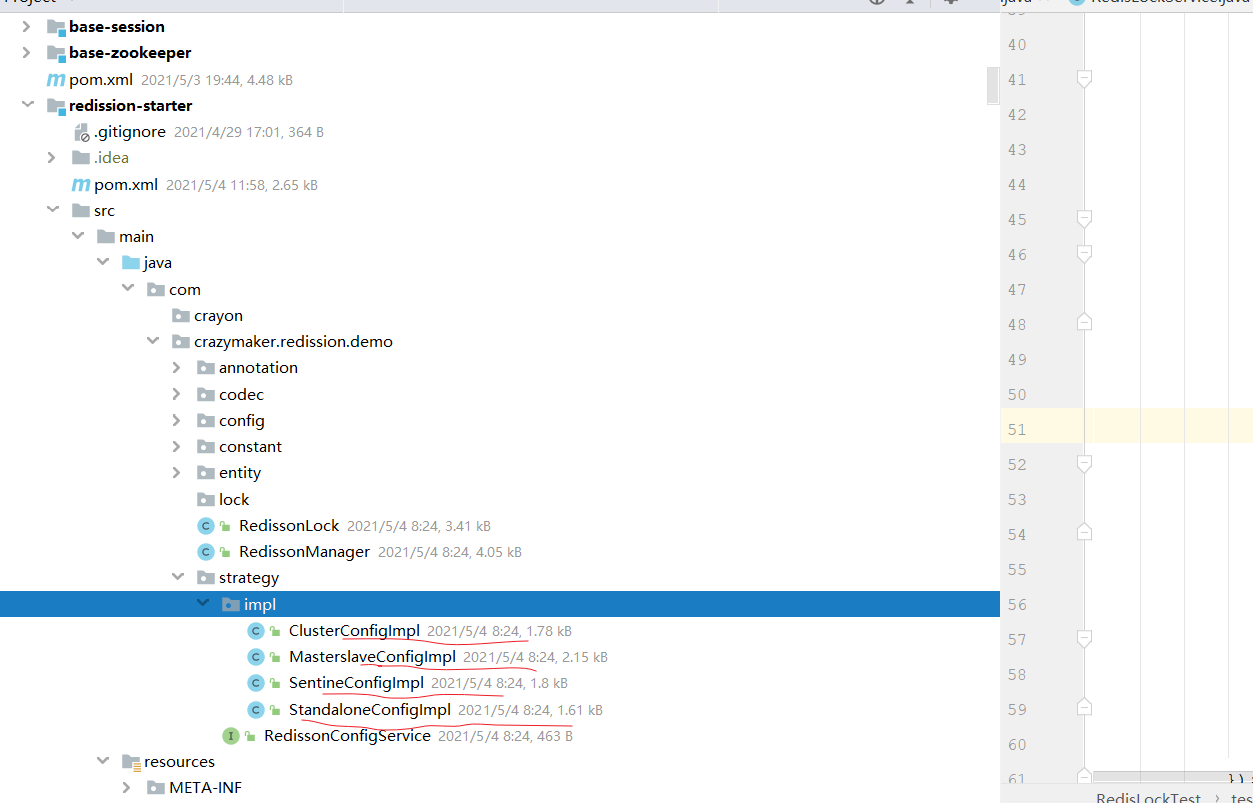
Encapsulate a redissionmanager, create RedissionConfig instance according to different configuration types through policy mode, and then create RedissionClient object.
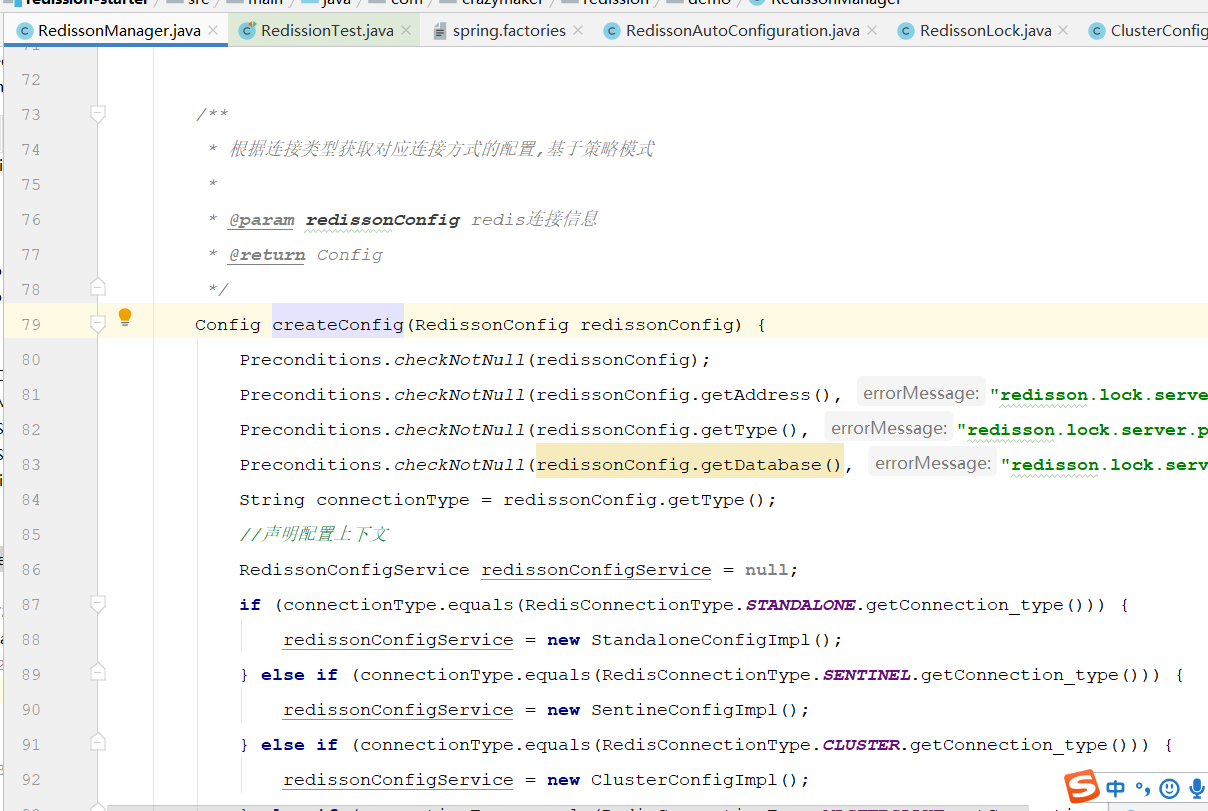
Using RBucket to manipulate distributed objects
Redistribution simulates the object-oriented programming idea of Java, which can be simply understood as that everything is an object.
Each Redisson object implements RObject and RExpirable Two interfaces
Usage example:
RObject object = redisson.get...()
object.sizeInMemory();
object.delete();
object.rename("newname");
object.isExists();
// catch expired event
object.addListener(new ExpiredObjectListener() {
...
});
// catch delete event
object.addListener(new DeletedObjectListener() {
...
});
The name of each Redisson object is the Key in Redis
RMap map = redisson.getMap("mymap");
map.getName(); // = mymap
Can pass RKeys Interface operation: keys in Redis
Usage example:
RKeys keys = redisson.getKeys();
Iterable<String> allKeys = keys.getKeys();
Iterable<String> foundedKeys = keys.getKeysByPattern('key*');
long numOfDeletedKeys = keys.delete("obj1", "obj2", "obj3");
long deletedKeysAmount = keys.deleteByPattern("test?");
String randomKey = keys.randomKey();
long keysAmount = keys.count();
keys.flushall();
keys.flushdb();
Redisson can access any type of basic object or ordinary object through the RBucket interface.
RBucket has a series of tool methods, such as compareAndSet(), get(), getAndDelete(), getAndSet(), set(), size(), trySet(), and so on, which are used to set value / value / obtain size.
The maximum size of an RBucket ordinary object is 512 megabytes.
RBucket<AnyObject> bucket = redisson.getBucket("anyObject");
bucket.set(new AnyObject(1));
AnyObject obj = bucket.get();
bucket.trySet(new AnyObject(3));
bucket.compareAndSet(new AnyObject(4), new AnyObject(5));
bucket.getAndSet(new AnyObject(6));
Here is a complete example:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testRBucketExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient client = redissonManager.getRedisson();
// RList inherits Java util. List interface
RBucket<String> rstring = client.getBucket("redission:test:bucket:string");
rstring.set("this is a string");
RBucket<UserDTO> ruser = client.getBucket("redission:test:bucket:user");
UserDTO dto = new UserDTO();
dto.setToken(UUID.randomUUID().toString());
ruser.set(dto);
System.out.println("string is: " + rstring.get());
System.out.println("dto is: " + ruser.get());
client.shutdown();
}
}
When you run the above code, you get the following output:
string is: this is a string dto is: UserDTO(id=null, userId=null, username=null, password=null, nickname=null, token=183b6eeb-65a8-4b2a-80c6-cf17c08332ce, createTime=null, updateTime=null, headImgUrl=null, mobile=null, sex=null, enabled=null, type=null, openId=null, isDel=false)
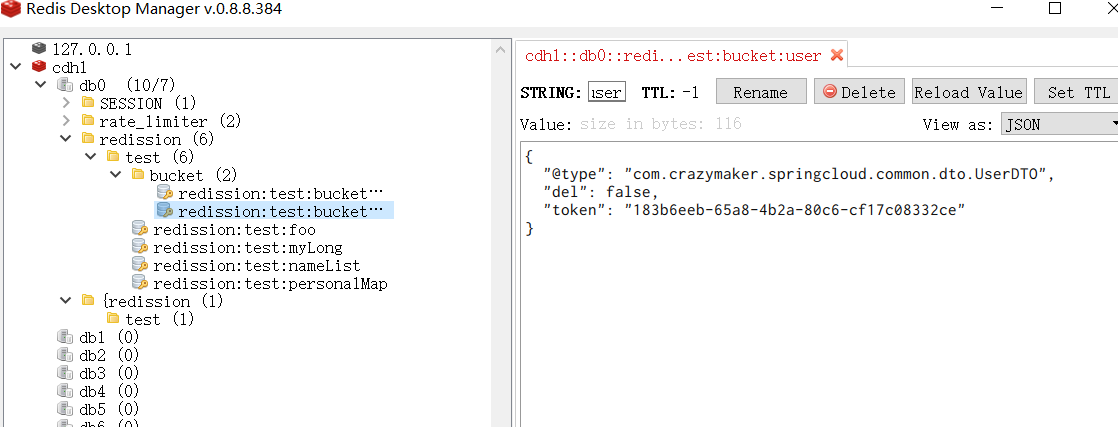
Use RList to operate Redis list
The following code simply demonstrates how to use the RList object in Redisson. RList is a distributed concurrent implementation of Java's List collection.
Consider the following codes:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testListExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient client = redissonManager.getRedisson();
// RList inherits Java util. List interface
RList<String> nameList = client.getList("redission:test:nameList");
nameList.clear();
nameList.add("Zhang San");
nameList.add("Li Si");
nameList.add("Wang Wu");
nameList.remove(-1);
System.out.println("List size: " + nameList.size());
boolean contains = nameList.contains("Li Si");
System.out.println("Is list contains name 'Li Si': " + contains);
nameList.forEach(System.out::println);
client.shutdown();
}
}
When you run the above code, you get the following output:
List size: 2 Is list contains name 'Li Si': true Zhang San Li Si
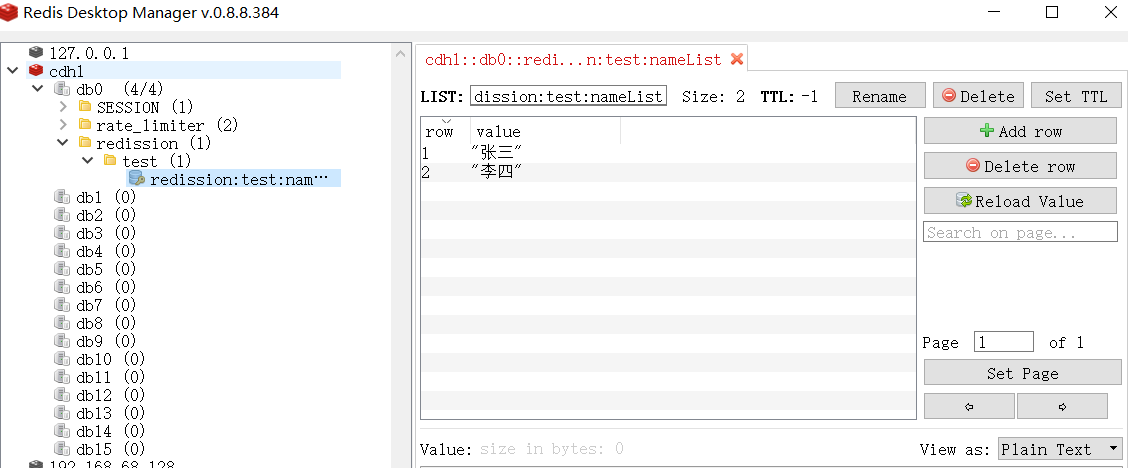
Redis hash using RMap operation
Redisson also includes RMap, which is a distributed concurrent implementation of Java Map collection. Consider the following code:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testListExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient client = redissonManager.getRedisson();
// RMap inherits Java util. concurrent. Concurrentmap interface
RMap<String, Object> map = client.getMap("redission:test:personalMap");
map.put("name", "Zhang San");
map.put("address", "Beijing");
map.put("age", new Integer(50));
System.out.println("Map size: " + map.size());
boolean contains = map.containsKey("age");
System.out.println("Is map contains key 'age': " + contains);
String value = String.valueOf(map.get("name"));
System.out.println("Value mapped by key 'name': " + value);
client.shutdown();
}
}
When you run the above code, you will see the following output:
Map size: 3 Is map contains key 'age': true Value mapped by key 'name': Zhang San
Execute Lua script
Lua is an open source, easy to learn, lightweight and compact scripting language, which is written in standard C language.
The purpose of its design is to embed in the application, so as to provide flexible expansion and customization functions for the application.
Redis has supported Lua scripts since version 2.6. Using Lua, redis can:
- Atomic operation. Redis will execute the whole script as a whole without interruption. It can be used for batch update and batch insertion
- Reduce network overhead. Multiple Redis operations are combined into one script to reduce network delay
- Code reuse. The script sent by the client can be stored in Redis, and other clients can call it according to the id of the script.
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testLuaExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient redisson = redissonManager.getRedisson();
redisson.getBucket("redission:test:foo").set("bar");
String r = redisson.getScript().eval(RScript.Mode.READ_ONLY,
"return redis.call('get', 'redission:test:foo')", RScript.ReturnType.VALUE);
System.out.println("foo: " + r);
// Do the same through the pre stored script
RScript s = redisson.getScript();
// First, load the script into Redis
String sha1 = s.scriptLoad("return redis.call('get', 'redission:test:foo')");
// Return value res == 282297a0228f48cd3fc6a55de6316f31422f5d17
System.out.println("sha1: " + sha1);
// Then call the script through SHA value
Future<Object> r1 = redisson.getScript().evalShaAsync(RScript.Mode.READ_ONLY,
sha1,
RScript.ReturnType.VALUE,
Collections.emptyList());
try {
System.out.println("res: " + r1.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
client.shutdown();
}
}
When you run the above code, you will see the following output:
foo: bar sha1: 282297a0228f48cd3fc6a55de6316f31422f5d17 res: bar
Redis distributed lock using RLock
RLock implements the use of RLock in distributed Java. The following code demonstrates the use of RLock:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testLockExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient redisson = redissonManager.getRedisson();
// RLock inherits Java util. concurrent. locks. Lock interface
RLock lock = redisson.getLock("redission:test:lock:1");
final int[] count = {0};
int threads = 10;
ExecutorService pool = Executors.newFixedThreadPool(10);
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++) {
pool.submit(() ->
{
for (int j = 0; j < 1000; j++) {
lock.lock();
count[0]++;
lock.unlock();
}
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("10 Each thread adds up to 1000: = " + count[0]);
//Output statistical results
float time = System.currentTimeMillis() - start;
System.out.println("The running time is:" + time);
System.out.println("The duration of each execution is:" + time/count[0]);
}
}
This code will produce the following output:
10 Each thread adds up to 1000: = 10000 Running time: 14172.0 The duration of each execution is: 1.4172
Redis atomic operation using RAtomicLong
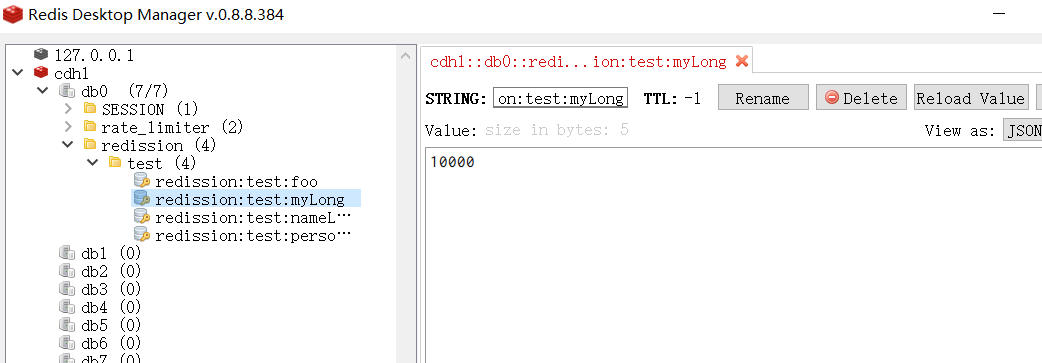
RAtomicLong is a distributed "substitute" for AtomicLong class in Java, which is used to save long values in a concurrent environment. The following example code demonstrates the usage of RAtomicLong:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testRAtomicLongExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient redisson = redissonManager.getRedisson();
RAtomicLong atomicLong = redisson.getAtomicLong("redission:test:myLong");
// Number of threads
final int threads = 10;
// Number of execution rounds per thread
final int turns = 1000;
ExecutorService pool = Executors.newFixedThreadPool(threads);
for (int i = 0; i < threads; i++)
{
pool.submit(() ->
{
try
{
for (int j = 0; j < turns; j++)
{
atomicLong.incrementAndGet();
}
} catch (Exception e)
{
e.printStackTrace();
}
});
}
ThreadUtil.sleepSeconds(5);
System.out.println("atomicLong: " + atomicLong.get());
redisson.shutdown();
}
}
The output of this code will be:
atomicLong: 10000
Full length accumulator
Redisson distributed full length accumulator based on Redis adopts Java util. concurrent. atomic. LongAdder similar interface. By using the LongAdder object built in the client, it provides high performance for increasing and decreasing operations in a distributed environment. According to statistics, its highest performance is 12000 times faster than distributed AtomicLong objects.
Perfect for distributed statistical measurement scenarios. The following is a use case of RLongAdder:
RLongAdder atomicLong = redisson.getLongAdder("myLongAdder");
atomicLong.add(12);
atomicLong.increment();
atomicLong.decrement();
atomicLong.sum();
The following example code demonstrates the use of RLongAdder:
public class RedissionTest {
@Resource
RedissonManager redissonManager;
@Test
public void testRAtomicLongExamples() {
// 127.0.0.1:6379 on default connection
RedissonClient redisson = redissonManager.getRedisson();
RAtomicLong atomicLong = redisson.getAtomicLong("redission:test:myLong");
// Number of threads
final int threads = 10;
// Number of execution rounds per thread
final int turns = 1000;
ExecutorService pool = Executors.newFixedThreadPool(threads);
for (int i = 0; i < threads; i++)
{
pool.submit(() ->
{
try
{
for (int j = 0; j < turns; j++)
{
atomicLong.incrementAndGet();
}
} catch (Exception e)
{
e.printStackTrace();
}
});
}
ThreadUtil.sleepSeconds(5);
System.out.println("atomicLong: " + atomicLong.get());
redisson.shutdown();
}
}
This code will produce the following output:
longAdder: 10000 Running time: 5085.0 The duration of each execution is: 0.5085
When the full-length accumulator object is no longer used, it should be destroyed manually. If the Redisson object is shut down, it does not need to be destroyed manually.
RLongAdder atomicLong = ... atomicLong.destroy();
serialize
Redisson's object encoding class is used to serialize and deserialize an object to read and store the object in Redis. Redisson provides the following object coding applications for you to choose from:
| Code class name | explain |
|---|---|
| org.redisson.codec.JsonJacksonCodec | Jackson JSON Code default code |
| org.redisson.codec.AvroJacksonCodec | Avro A binary JSON encoding |
| org.redisson.codec.SmileJacksonCodec | Smile Another binary JSON encoding |
| org.redisson.codec.CborJacksonCodec | CBOR Another binary JSON encoding |
| org.redisson.codec.MsgPackJacksonCodec | MsgPack Another binary JSON encoding |
| org.redisson.codec.IonJacksonCodec | Amazon Ion Amazon's Ion code has a format similar to JSON |
| org.redisson.codec.KryoCodec | Kryo Binary object serialization encoding |
| org.redisson.codec.SerializationCodec | JDK serialization encoding |
| org.redisson.codec.FstCodec | FST 10 times the serialization performance of JDK and 100% compatible encoding |
| org.redisson.codec.LZ4Codec | LZ4 Compressed serialization object encoding |
| org.redisson.codec.SnappyCodec | Snappy Another compressed serialization object encoding |
| org.redisson.client.codec.JsonJacksonMapCodec | The encoding used by Jackson based mapping classes. Information that can be used to avoid serializing classes and to solve problems encountered with byte []. |
| org.redisson.client.codec.StringCodec | Pure string encoding (no conversion) |
| org.redisson.client.codec.LongCodec | Full length digital coding (no conversion) |
| org.redisson.client.codec.ByteArrayCodec | Byte array encoding |
| org.redisson.codec.CompositeCodec | Used to combine multiple different codes together |
Redisson's default encoder is binary encoder. In order to make the serialized content visible, you need to use the Json text serialization encoding tool class. Redisson provides the coder jsonjackson codec as a tool class for Json text serialization coding.
The problem is: when JsonJackson serializes an object with two-way references, an infinite loop exception occurs. fastjson will automatically replace the two-way reference with the reference character $ref after checking the two-way reference and terminate the loop.
Therefore, in some special scenarios: it can be serialized to redis normally with fastjson, while Jason Jackson throws an infinite loop exception.
In order to make the serialized content visible, the fastjson encoder is implemented by ourselves without redistributing other self-contained ones:
package com.crayon.distributedredissionspringbootstarter.codec;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.ByteBufInputStream;
import io.netty.buffer.ByteBufOutputStream;
import org.redisson.client.codec.BaseCodec;
import org.redisson.client.protocol.Decoder;
import org.redisson.client.protocol.Encoder;
import java.io.IOException;
public class FastjsonCodec extends BaseCodec {
private final Encoder encoder = in -> {
ByteBuf out = ByteBufAllocator.DEFAULT.buffer();
try {
ByteBufOutputStream os = new ByteBufOutputStream(out);
JSON.writeJSONString(os, in, SerializerFeature.WriteClassName);
return os.buffer();
} catch (IOException e) {
out.release();
throw e;
} catch (Exception e) {
out.release();
throw new IOException(e);
}
};
private final Decoder<Object> decoder = (buf, state) ->
JSON.parseObject(new ByteBufInputStream(buf), Object.class);
@Override
public Decoder<Object> getValueDecoder() {
return decoder;
}
@Override
public Encoder getValueEncoder() {
return encoder;
}
}
The replacement method is as follows:
*/
@Slf4j
public class StandaloneConfigImpl implements RedissonConfigService {
@Override
public Config createRedissonConfig(RedissonConfig redissonConfig) {
Config config = new Config();
try {
String address = redissonConfig.getAddress();
String password = redissonConfig.getPassword();
int database = redissonConfig.getDatabase();
String redisAddr = GlobalConstant.REDIS_CONNECTION_PREFIX.getConstant_value() + address;
config.useSingleServer().setAddress(redisAddr);
config.useSingleServer().setDatabase(database);
//Password can be blank
if (!StringUtils.isEmpty(password)) {
config.useSingleServer().setPassword(password);
}
log.info("initialization[Stand alone deployment]mode Config,redisAddress:" + address);
// config.setCodec( new FstCodec());
config.setCodec( new FastjsonCodec());
} catch (Exception e) {
log.error("Stand alone deployment Redisson init error", e);
}
return config;
}
}
Sentinel mode
Sentinel mode is sentinel mode. The official document for configuring Redis sentinel service is in here.
The implementation code of sentry mode is almost the same as that of stand-alone mode. The only difference is the configuration of Config
The method of programmatically configuring sentinel mode is as follows:
Config config = new Config();
config.useSentinelServers()
.setMasterName("mymaster")
// use "rediss://" for SSL connection
.addSentinelAddress("redis://127.0.0.1:26389", "redis://127.0.0.1:26379")
.addSentinelAddress("redis://127.0.0.1:26319");
RedissonClient redisson = Redisson.create(config);
Redisson's sentinel mode is used as follows:
SentinelServersConfig sentinelConfig = config.useSentinelServers();
SentinelServersConfig configuration parameters are as follows:
The official document for configuring Redis sentinel service is in here . The sentinel mode of Redisson is used as follows: sentinelserversconfig sentinelconfig = config useSentinelServers();
The setting parameters of SentinelServersConfig class are as follows:
dnsMonitoringInterval (DNS monitoring interval, unit: ms)
Default: 5000
Used to specify the time interval for checking node DNS changes. When using, you should ensure that the cache time of DNS data in the JVM is kept low enough to make sense. Use - 1 to disable this feature.
masterName (name of the master server)
The name of the master server is used to monitor the handover of master-slave services in the sentinel process.
addSentinelAddress (add sentinel node address)
You can specify the address of the sentinel node in the format of host:port. Multiple nodes can be added in batch at one time.
readMode (load balancing mode of read operation)
Default value: SLAVE (only read from the service node)
Note: the data read from the service node indicates that at least two nodes have saved the data to ensure the high availability of the data.
Sets the mode of the read operation selection node. The available values are: SLAVE - only read from the service node. Master - read only in the main service node. MASTER_SLAVE - can be read in both master and SLAVE service nodes.
subscriptionMode (load balancing mode of subscription operation)
Default value: SLAVE (only subscribed from the service node)
Set the mode of subscription operation selection node. Available values are: SLAVE - subscribe only from the service node. MASTER - subscribe only in the main service node.
loadBalancer (selection of load balancing algorithm class)
Default: org redisson. connection. balancer. RoundRobinLoadBalancer
In the environment where multiple Redis service nodes are used, the following load balancing methods can be used to select a node: org redisson. connection. balancer. Weightedroundrobin balancer - weighted polling scheduling algorithm org redisson. connection. balancer. Roundrobin loadbalancer - polling scheduling algorithm org redisson. connection. balancer. Randomloadbalancer - random scheduling algorithm
subscriptionConnectionMinimumIdleSize (minimum number of free connections for publish and subscribe connections from node)
Default: 1
In a multi slave environment, the minimum number of maintained connections (long connections) for publish and subscribe connections in each slave service node. Redisson often implements many functions through publishing and subscription. It is necessary to maintain a certain number of publish and subscribe connections for a long time.
subscriptionConnectionPoolSize (publish and subscribe connection pool size from node)
Default: 50
In a multi slave environment, the maximum capacity of the connection pool used for publish and subscribe connections in each slave service node. The number of connections in the connection pool automatically scales elastically.
slaveConnectionMinimumIdleSize (minimum number of free connections from the node)
Default: 32
In a multi slave environment, the minimum number of maintained connections (long connections) for common operations (non publish and subscribe) in each slave service node. Maintaining a certain number of connections for a long time is conducive to improving the instantaneous reading and reflection speed.
slaveConnectionPoolSize (slave node connection pool size)
Default: 64
In a multi slave environment, the maximum capacity of the connection pool used for normal operation (non publish and subscribe) connections in each slave service node. The number of connections in the connection pool automatically scales elastically.
masterConnectionMinimumIdleSize (minimum number of idle connections of the master node)
Default: 32
In the environment of multi slave nodes, the minimum number of maintained connections (long connections) of each master node. Maintaining a certain number of connections for a long time is conducive to improving the instantaneous write response speed.
masterConnectionPoolSize (master node connection pool size)
Default: 64
The maximum capacity of the connection pool of the primary node. The number of connections in the connection pool automatically scales elastically.
idleConnectionTimeout (connection idle timeout in milliseconds)
Default: 10000
If the number of connections in the current connection pool exceeds the minimum number of idle connections, and the idle time of some connections exceeds this value, these connections will be automatically closed and removed from the connection pool. The unit of time is milliseconds.
connectTimeout (connection timeout in milliseconds)
Default: 10000
The wait timeout when establishing a connection with any node. The unit of time is milliseconds.
Timeout (command wait timeout in milliseconds)
Default: 3000
The time to wait for the node to reply to the command. This time starts when the command is sent successfully.
retryAttempts (number of command failure retries)
Default: 3
An error will be thrown if the command cannot be sent to a specified node after trying to reach retryAttempts. If the attempt to send within this limit is successful, enable the timeout timer.
retryInterval (interval between command retry sending, unit: ms)
Default: 1500
The time interval between waiting to retry sending after a command fails to be sent. The unit of time is milliseconds.
reconnectionTimeout (reconnection interval in milliseconds)
Default: 3000
The interval of time to wait for a connection to be reestablished with a node when it is disconnected. The unit of time is milliseconds.
failedAttempts (maximum number of execution failures)
Default: 3
When a node executes the same or different commands, the node will be cleared from the list of available nodes in case of continuous failure of failedAttempts (maximum number of execution failures), and will try again after the reconnectionTimeout (reconnection interval) expires.
Database (database number)
Default: 0
The number of the database you are trying to connect to.
password
Default: null
Password used for node authentication.
subscriptionsPerConnection (maximum number of subscriptions per connection)
Default: 5
Maximum number of subscriptions per connection.
clientName (client name)
Default: null
The name of the client displayed in the Redis node.
sslEnableEndpointIdentification (enable SSL terminal identification)
Default value: true
Enable SSL terminal identification.
sslProvider (SSL Implementation)
Default: JDK
Determine which method (JDK or OPENSSL) is used to realize SSL connection.
SSL truststore (path of SSL trust certificate store)
Default: null
Specify the path to the SSL trust certificate library.
SSL truststorepassword (SSL trust certificate store password)
Default: null
Specify the password for the SSL trust library.
SSL keystore (SSL keystore path)
Default: null
Specifies the path to the SSL keystore.
SSL keystorepassword (SSL keystore password)
Default: null
Specifies the password for the SSL keystore.
Through the property file, an example of configuration is as follows:
---
sentinelServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
failedSlaveReconnectionInterval: 3000
failedSlaveCheckInterval: 60000
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 24
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 24
masterConnectionPoolSize: 64
readMode: "SLAVE"
subscriptionMode: "SLAVE"
sentinelAddresses:
- "redis://127.0.0.1:26379"
- "redis://127.0.0.1:26389"
masterName: "mymaster"
database: 0
threads: 16
nettyThreads: 32
codec: !<org.redisson.codec.MarshallingCodec> {}
transportMode: "NIO"
Master-slave mode
The document describing the configuration of Redis master-slave service is here.
The method of programmatically configuring the master-slave mode is as follows:
Config config = new Config();
config.useMasterSlaveServers()
// use "rediss://" for SSL connection
.setMasterAddress("redis://127.0.0.1:6379")
.addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419")
.addSlaveAddress("redis://127.0.0.1:6399");
RedissonClient redisson = Redisson.create(config);
Master slave mode is used to MasterSlaveServersConfig:
MasterSlaveServersConfig masterSlaveConfig = config.useMasterSlaveServers();
The setting parameters of MasterSlaveServersConfig class are as follows:
dnsMonitoringInterval (DNS monitoring interval, unit: ms)
Default: 5000
Used to specify the time interval for checking node DNS changes. When using, you should ensure that the cache time of DNS data in the JVM is kept low enough to make sense. Use - 1 to disable this feature.
Master address
You can specify the master node address in the format of host:port.
addSlaveAddress (add slave master node address)
You can specify the address of the slave node in the format of host:port. Multiple nodes can be added in batch at one time.
readMode (load balancing mode of read operation)
Default value: SLAVE (only read from the service node)
Note: the data read from the service node indicates that at least two nodes have saved the data to ensure the high availability of the data.
Sets the mode of the read operation selection node. The available values are: SLAVE - only read from the service node. Master - read only in the main service node. MASTER_SLAVE - can be read in both master and SLAVE service nodes.
subscriptionMode (load balancing mode of subscription operation)
Default value: SLAVE (only subscribed from the service node)
Set the mode of subscription operation selection node. Available values are: SLAVE - subscribe only from the service node. MASTER - subscribe only in the main service node.
loadBalancer (selection of load balancing algorithm class)
Default: org redisson. connection. balancer. RoundRobinLoadBalancer
In the environment where multiple Redis service nodes are used, the following load balancing methods can be used to select a node: org redisson. connection. balancer. Weightedroundrobin balancer - weighted polling scheduling algorithm org redisson. connection. balancer. Roundrobin loadbalancer - polling scheduling algorithm org redisson. connection. balancer. Randomloadbalancer - random scheduling algorithm
subscriptionConnectionMinimumIdleSize (minimum number of free connections for publish and subscribe connections from node)
Default: 1
In a multi slave environment, the minimum number of maintained connections (long connections) for publish and subscribe connections in each slave service node. Redisson often implements many functions through publishing and subscription. It is necessary to maintain a certain number of publish and subscribe connections for a long time.
subscriptionConnectionPoolSize (publish and subscribe connection pool size from node)
Default: 50
In a multi slave environment, the maximum capacity of the connection pool used for publish and subscribe connections in each slave service node. The number of connections in the connection pool automatically scales elastically.
slaveConnectionMinimumIdleSize (minimum number of free connections from the node)
Default: 32
In a multi slave environment, the minimum number of maintained connections (long connections) for common operations (non publish and subscribe) in each slave service node. Maintaining a certain number of connections for a long time is conducive to improving the instantaneous reading and reflection speed.
slaveConnectionPoolSize (slave node connection pool size)
Default: 64
In a multi slave environment, the maximum capacity of the connection pool used for normal operation (non publish and subscribe) connections in each slave service node. The number of connections in the connection pool automatically scales elastically.
masterConnectionMinimumIdleSize (minimum number of idle connections of the master node)
Default: 32
In the environment of multi slave nodes, the minimum number of maintained connections (long connections) of each master node. Maintaining a certain number of connections for a long time is conducive to improving the instantaneous write response speed.
masterConnectionPoolSize (master node connection pool size)
Default: 64
The maximum capacity of the connection pool of the primary node. The number of connections in the connection pool automatically scales elastically.
idleConnectionTimeout (connection idle timeout in milliseconds)
Default: 10000
If the number of connections in the current connection pool exceeds the minimum number of idle connections, and the idle time of some connections exceeds this value, these connections will be automatically closed and removed from the connection pool. The unit of time is milliseconds.
connectTimeout (connection timeout in milliseconds)
Default: 10000
The wait timeout when establishing a connection with any node. The unit of time is milliseconds.
Timeout (command wait timeout in milliseconds)
Default: 3000
The time to wait for the node to reply to the command. This time starts when the command is sent successfully.
retryAttempts (number of command failure retries)
Default: 3
An error will be thrown if the command cannot be sent to a specified node after trying to reach retryAttempts. If the attempt to send within this limit is successful, enable the timeout timer.
retryInterval (interval between command retry sending, unit: ms)
Default: 1500
The time interval between waiting to retry sending after a command fails to be sent. The unit of time is milliseconds.
reconnectionTimeout (reconnection interval in milliseconds)
Default: 3000
The interval of time to wait for a connection to be reestablished with a node when it is disconnected. The unit of time is milliseconds.
failedAttempts (maximum number of execution failures)
Default: 3
When a node executes the same or different commands, the node will be cleared from the list of available nodes in case of continuous failure of failedAttempts (maximum number of execution failures), and will try again after the reconnectionTimeout (reconnection interval) expires.
Database (database number)
Default: 0
The number of the database you are trying to connect to.
password
Default: null
Password used for node authentication.
subscriptionsPerConnection (maximum number of subscriptions per connection)
Default: 5
Maximum number of subscriptions per connection.
clientName (client name)
Default: null
The name of the client displayed in the Redis node.
sslEnableEndpointIdentification (enable SSL terminal identification)
Default value: true
Enable SSL terminal identification.
sslProvider (SSL Implementation)
Default: JDK
Determine which method (JDK or OPENSSL) is used to realize SSL connection.
SSL truststore (path of SSL trust certificate store)
Default: null
Specify the path to the SSL trust certificate library.
SSL truststorepassword (SSL trust certificate store password)
Default: null
Specify the password for the SSL trust library.
SSL keystore (SSL keystore path)
Default: null
Specifies the path to the SSL keystore.
SSL keystorepassword (SSL keystore password)
Default: null
Specifies the password for the SSL keystore.
Cluster mode
In addition to the Redis cluster environment, the cluster mode is also applicable to the cluster mode provided by any cloud computing service provider, such as AWS ElastiCache cluster Edition,Azure Redis Cache and Redis version of Alibaba cloud's cloud database.
The document that describes how to configure Redis cluster configuration here . The minimum requirement for Redis cluster configuration is that there must be three master nodes.
The configuration of Config in cluster mode is as follows:
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // Cluster status scanning interval, in milliseconds
//You can use "Reiss: / /" to enable SSL connections
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);
Cluster mode uses ClusterServersConfig:
ClusterServersConfig clusterConfig = config.useClusterServers();
The configuration parameters of ClusterServersConfig are as follows:
Nodeaddress (add node address)
You can add the address of the Redis cluster node in the format of host:port. Multiple nodes can be added in batch at one time.
scanInterval (cluster scan interval)
Default: 1000
The time interval for status scanning of Redis cluster nodes. The unit is milliseconds.
slots (number of slices)
Default value: 231 is used to specify the number of slices in the process of data fragmentation. Supporting data fragmentation / framework structures include: Set,Map,BitSet,Bloom filter, Spring Cache and Hibernate Cache Wait
readMode (load balancing mode of read operation)
Default value: SLAVE (only read from the service node)
Note: the data read from the service node indicates that at least two nodes have saved the data to ensure the high availability of the data.
Sets the mode of the read operation selection node. The available values are: SLAVE - only read from the service node. Master - read only in the main service node. MASTER_SLAVE - can be read in both master and SLAVE service nodes.
subscriptionMode (load balancing mode of subscription operation)
Default value: SLAVE (only subscribed from the service node)
Set the mode of subscription operation selection node. Available values are: SLAVE - subscribe only from the service node. MASTER - subscribe only in the main service node.
loadBalancer (selection of load balancing algorithm class)
Default: org redisson. connection. balancer. RoundRobinLoadBalancer
In the environment of multiple Redis service nodes, the following load balancing methods can be used to select a node: org redisson. connection. balancer. Weightedroundrobin balancer - weighted polling scheduling algorithm org redisson. connection. balancer. Roundrobin loadbalancer - polling scheduling algorithm org redisson. connection. balancer. Randomloadbalancer - random scheduling algorithm
subscriptionConnectionMinimumIdleSize (minimum number of free connections for publish and subscribe connections from node)
Default: 1
In a multi slave environment, the minimum number of maintained connections (long connections) for publish and subscribe connections in each slave service node. Redisson often implements many functions through publishing and subscription. It is necessary to maintain a certain number of publish and subscribe connections for a long time.
subscriptionConnectionPoolSize (publish and subscribe connection pool size from node)
Default: 50
In a multi slave environment, the maximum capacity of the connection pool used for publish and subscribe connections in each slave service node. The number of connections in the connection pool automatically scales elastically.
slaveConnectionMinimumIdleSize (minimum number of free connections from the node)
Default: 32
In a multi slave environment, the minimum number of maintained connections (long connections) for common operations (non publish and subscribe) in each slave service node. Maintaining a certain number of connections for a long time is conducive to improving the instantaneous reading and reflection speed.
slaveConnectionPoolSize (slave node connection pool size)
Default: 64
In a multi slave environment, the maximum capacity of the connection pool used for normal operation (non publish and subscribe) connections in each slave service node. The number of connections in the connection pool automatically scales elastically.
masterConnectionMinimumIdleSize (minimum number of idle connections of the master node)
Default: 32
In a multi node environment, the minimum number of maintained connections (long connections) of each master node. Maintaining a certain number of connections for a long time is conducive to improving the instantaneous write response speed.
masterConnectionPoolSize (master node connection pool size)
Default: 64
In a multi master environment, the maximum capacity of the connection pool of each master node. The number of connections in the connection pool automatically scales elastically.
idleConnectionTimeout (connection idle timeout in milliseconds)
Default: 10000
If the number of connections in the current connection pool exceeds the minimum number of idle connections, and the idle time of some connections exceeds this value, these connections will be automatically closed and removed from the connection pool. The unit of time is milliseconds.
connectTimeout (connection timeout in milliseconds)
Default: 10000
The wait timeout when establishing a connection with any node. The unit of time is milliseconds.
Timeout (command wait timeout in milliseconds)
Default: 3000
The time to wait for the node to reply to the command. This time starts when the command is sent successfully.
retryAttempts (number of command failure retries)
Default: 3
An error will be thrown if the command cannot be sent to a specified node after trying to reach retryAttempts. If the attempt to send within this limit is successful, enable the timeout timer.
retryInterval (interval between command retry sending, unit: ms)
Default: 1500
The time interval between waiting to retry sending after a command fails to be sent. The unit of time is milliseconds.
reconnectionTimeout (reconnection interval in milliseconds)
Default: 3000
The interval of time to wait for a connection to be reestablished with a node when it is disconnected. The unit of time is milliseconds.
failedAttempts (maximum number of execution failures)
Default: 3
When a node executes the same or different commands, the node will be cleared from the list of available nodes in case of continuous failure of failedAttempts (maximum number of execution failures), and will try again after the reconnectionTimeout (reconnection interval) expires.
password
Default: null
Password used for node authentication.
subscriptionsPerConnection (maximum number of subscriptions per connection)
Default: 5
Maximum number of subscriptions per connection.
clientName (client name)
Default: null
The name of the client displayed in the Redis node.
sslEnableEndpointIdentification (enable SSL terminal identification)
Default value: true
Enable SSL terminal identification.
sslProvider (SSL Implementation)
Default: JDK
Determine which method (JDK or OPENSSL) is used to realize SSL connection.
SSL truststore (path of SSL trust certificate store)
Default: null
Specify the path to the SSL trust certificate library.
SSL truststorepassword (SSL trust certificate store password)
Default: null
Specify the password for the SSL trust library.
SSL keystore (SSL keystore path)
Default: null
Specifies the path to the SSL keystore.
SSL keystorepassword (SSL keystore password)
Default: null
Specifies the password for the SSL keystore.
Principle of simple Redision lock
Up to now, several common deployment architectures of Redis include:
- Stand alone mode;
- Sentinel mode;
- Cluster mode;
First, introduce the use of simple Redision lock based on stand-alone mode.
Use of simple Redision lock
In stand-alone mode, the use of simple Redision lock is as follows:
// Construct redisson to realize the necessary Config of distributed lock
Config config = new Config();
config.useSingleServer().setAddress("redis://172.29.1.180:5379").setPassword("a123456").setDatabase(0);
// Construct RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// Set locked resource name
RLock disLock = redissonClient.getLock("DISLOCK");
//Attempt to acquire distributed lock
boolean isLock= disLock.tryLock(500, 15000, TimeUnit.MILLISECONDS);
if (isLock) {
try {
//TODO if get lock success, do something;
Thread.sleep(15000);
} catch (Exception e) {
} finally {
// In any case, unlock it in the end
disLock.unlock();
}
}
It can be seen from the code that it is very convenient to realize Redis distributed Lock after being encapsulated by redison, and the use method is the same as that of explicit Lock. RLock interface inherits Lock interface.
Let's take another look at the value in redis. Like the previous analysis, the hash structure and the key of redis is the resource name.
The key of the hash structure is UUID+threadId, and the value of the hash structure is the re-entry value. In the case of distributed lock, this value is 1 (Redisson can also implement re-entry lock, so this value depends on the number of re-entry):
172.29.1.180:5379> hgetall DISLOCK 1) "01a6d806-d282-4715-9bec-f51b9aa98110:1" 2) "1"
The effects of using client tools are as follows:
getLock() method

You can see that a RedissonLock object is actually returned after calling the getLock() method
tryLock method
Let's take a look at the tryLock method. The source code is as follows:
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long time = unit.toMillis(waitTime);
long current = System.currentTimeMillis();
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
current = System.currentTimeMillis();
RFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
if (!subscribeFuture.await(time, TimeUnit.MILLISECONDS)) {
if (!subscribeFuture.cancel(false)) {
subscribeFuture.onComplete((res, e) -> {
if (e == null) {
unsubscribe(subscribeFuture, threadId);
}
});
}
acquireFailed(threadId);
return false;
}
try {
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
while (true) {
long currentTime = System.currentTimeMillis();
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
}
} finally {
unsubscribe(subscribeFuture, threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
}
The above code uses the asynchronous callback mode, and RFuture inherits Java util. concurrent. For the basic knowledge of future, completionstage and asynchronous callback mode, please refer to Java high concurrency core Programming Volume 2

tryAcquire() method
The lock() method of RedissonLock object mainly calls the tryAcquire() method

tryLockInnerAsync
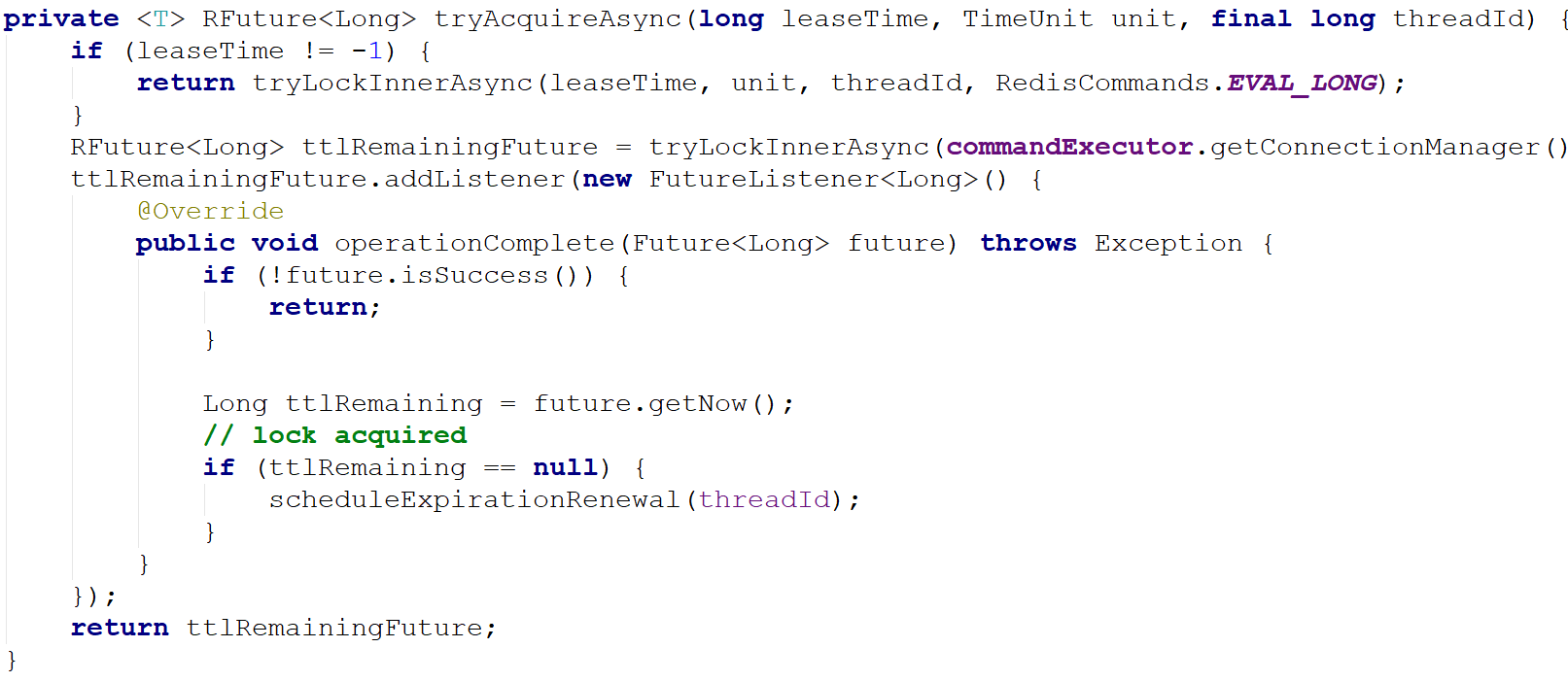
Since leaseTime == -1, the tryLockInnerAsync() method is the key

First, let's take a look at the definition of the evalWriteAsync method
<T, R> RFuture<R> evalWriteAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script, List<Object> keys, Object ... params);
This is similar to the previous jedis calling lua script. The last two parameters are keys and params.
Separate the calling paragraph and see that the actual calling is as follows:
commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
Combined with the above parameter declaration, we can know that here KEYS[1] is getName(), ARGV[2] is getLockName(threadId)
Assumptions:
- The name passed when obtaining the lock is "unlock",
- Suppose the thread ID of the call is 1,
- Suppose the id of the member variable UUID type is 01a6d806-d282-4715-9bec-f51b9aa98110
Then keys [1] = unlock, ARGV[2]=01a6d806-d282-4715-9bec-f51b9aa98110:1
So what this script means is
1. Judge whether there is a key called "unlock"
2. If not, set a key value pair with a field of "01a6d806-d282-4715-9bec-f51b9aa98110:1" and a value of "1" under it, and set its expiration time
3. If it exists, further judge whether "01a6d806-d282-4715-9bec-f51b9aa98110:1" exists. If it exists, increase its value by 1 and reset the expiration time
4. Returns the lifetime of "unlock" (in milliseconds)
Principle: locking mechanism
The data structure used here is hash. The structure of hash is: key field 1 value 1 field 2 value 2...
In the lock scenario, the key represents the name of the lock, which can also be understood as critical resources, and the field represents the thread that currently obtains the lock
All threads competing for this lock must determine whether there is a field of their own thread under this key. If not, they cannot obtain the lock. If there is, it is equivalent to reentry, and the field value is increased by 1 (Times)
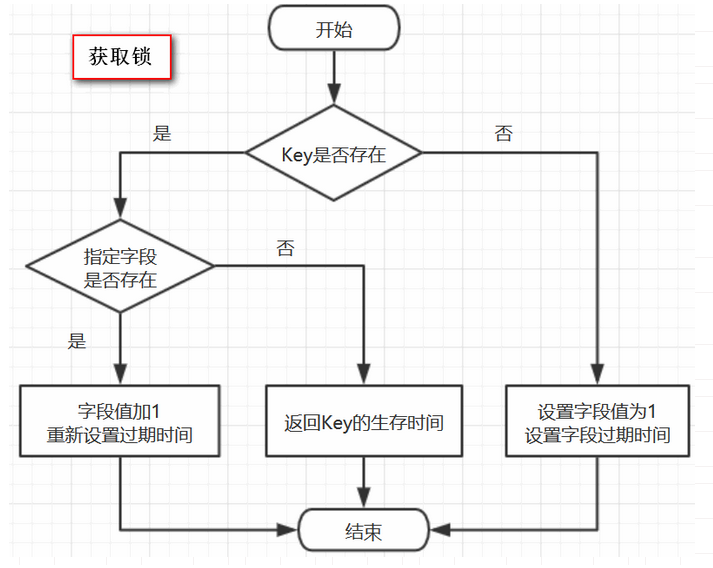
Detailed explanation of Lua script
Why use lua?
Because a lot of complex business logic can be encapsulated in lua script and sent to redis to ensure the atomicity of this complex business logic
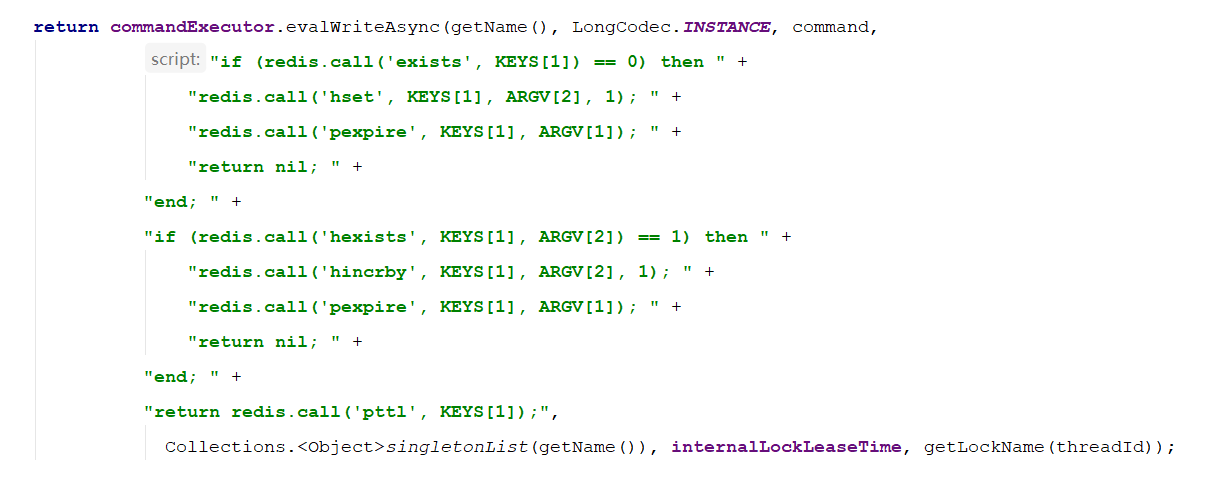
Review the definition of the evalWriteAsync method
<T, R> RFuture<R> evalWriteAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script, List<Object> keys, Object ... params);
Note that the last two parameters are keys and params.
Explanation of lua script parameters:
**KEYS[1] * * represents the key you locked, for example:
RLock lock = redisson.getLock("DISLOCK");
Here, you set the lock key for locking, which is "unlock".
**ARGV[1] * * represents the default lifetime of the lock key
When calling, the parameter passed is internalLockLeaseTime, which defaults to 30 seconds.
**ARGV[2] * * represents the ID of the locked client, similar to the following:
01a6d806-d282-4715-9bec-f51b9aa98110:1
The first if judgment statement of lua script is to use the "exists unlock" command to judge. If the lock key you want to lock does not exist, you will lock it.
How to lock it? Very simple, use the following redis command:
hset DISLOCK 01a6d806-d282-4715-9bec-f51b9aa98110:1 1
Set a hash data structure through this command. After this command is executed, a data structure similar to the following will appear:
DISLOCK:
{
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
}
Then, execute the command "pexpire unlock 30000" and set the lifetime of the lock key to 30 seconds (default)
Lock mutual exclusion mechanism
So at this time, what happens if client 2 tries to lock and executes the same lua script?
Very simply, the first if judgment will execute "exists unlock", and it is found that the lock key of unlock already exists.
The second if judgment is to judge whether the hash data structure of the unlock lock key contains the ID of client 2, but it is obviously not, because it contains the ID of client 1.
Therefore, client 2 will get a number returned by pttl unlock, which represents the * * remaining lifetime of the lock key** For example, there are 15000 milliseconds left.
At this time, client 2 will enter a while loop and keep trying to lock.
Reentrant locking mechanism
If client 1 already holds this lock, what happens to the reentrant lock?
RLock lock = redisson.getLock("DISLOCK")
lock.lock();
//Business code
lock.lock();
//Business code
lock.unlock();
lock.unlock();
Analyze the lua script above.
The first if judgment is definitely not true. "Exists unlock" will show that the lock key already exists.
The second if judgment will hold because the ID contained in the hash data structure of unlock is the ID of client 1, that is, "8743c9c0-0795-4907-87fd-6c719a6b4586:1"
At this time, the logic of reentrant locking will be executed. He will use:
incrby DISLOCK
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
Through this command, the number of locks on client 1 is accumulated by 1.
At this point, the disk data structure changes to the following:
DISLOCK:
{
8743c9c0-0795-4907-87fd-6c719a6b4586:1 2
}
Release lock mechanism
If you execute lock Unlock (), you can release the distributed lock. At this time, the business logic is also very simple.
In fact, to put it bluntly, it is to reduce the number of locks in the unlock data structure by 1 every time.
If it is found that the number of locks is 0, it means that the client no longer holds the lock. At this time, it will use:
"Del unlock" command to delete this key from redis.
Then, another client 2 can try to complete locking.
unlock source code
@Override
public void unlock() {
try {
get(unlockAsync(Thread.currentThread().getId()));
} catch (RedisException e) {
if (e.getCause() instanceof IllegalMonitorStateException) {
throw (IllegalMonitorStateException) e.getCause();
} else {
throw e;
}
}
// Future<Void> future = unlockAsync();
// future.awaitUninterruptibly();
// if (future.isSuccess()) {
// return;
// }
// if (future.cause() instanceof IllegalMonitorStateException) {
// throw (IllegalMonitorStateException)future.cause();
// }
// throw commandExecutor.convertException(future);
}
Further, what is actually called is the unlockInnerAsync method
unlockInnerAsync method
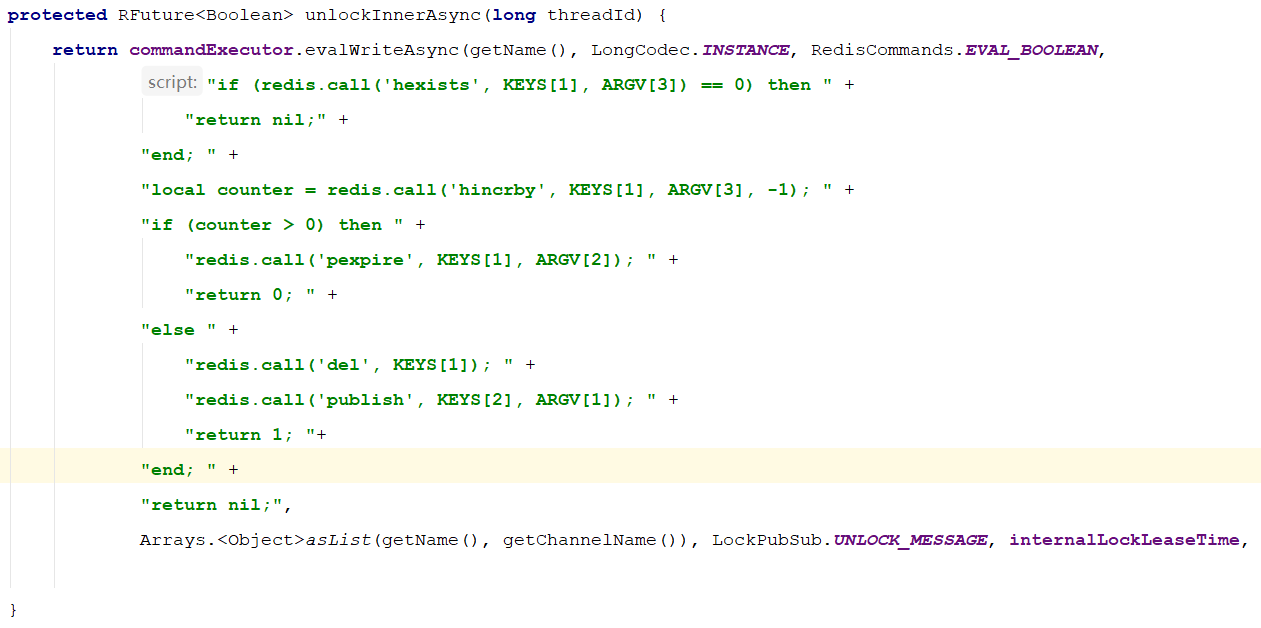
Principle: Redision unlocking mechanism
The above figure is not completely intercepted. The complete source code is as follows:
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}
Let's assume that name = unlock and thread ID is 1
Similarly, we can know
KEYS[1] is getName(), that is, KEYS[1] = unlock
KEYS[2] is getChannelName(), that is, KEYS[2] = reisson_ lock__ channel:{DISLOCK}
ARGV[1] is lockpubsub Unlockmessage, i.e. ARGV[1]=0
ARGV[2] is the survival time
ARGV[3] is getLockName(threadId), that is, ARGV[3]=8743c9c0-0795-4907-87fd-6c719a6b4586:1
Therefore, the above script means:
1. Judge whether there is a key called "unlock"
2. If it does not exist, nil is returned
3. If it exists, use the Redis Hincrby command to add the specified increment value of - 1 to the field value in the hash table, which means to subtract 1
4. If counter >, it returns null. If the field exists, the field value will be reduced by 1
5. If the value of counter > 0 is still greater than 0 after subtraction, 0 will be returned
6. After subtraction, if the field value is less than or equal to 0, broadcast a message with the publish command. The broadcast content is 0 and returns 1;
It can be guessed that broadcast 0 indicates that resources are available, that is, it informs those threads waiting to acquire locks that they can now acquire locks
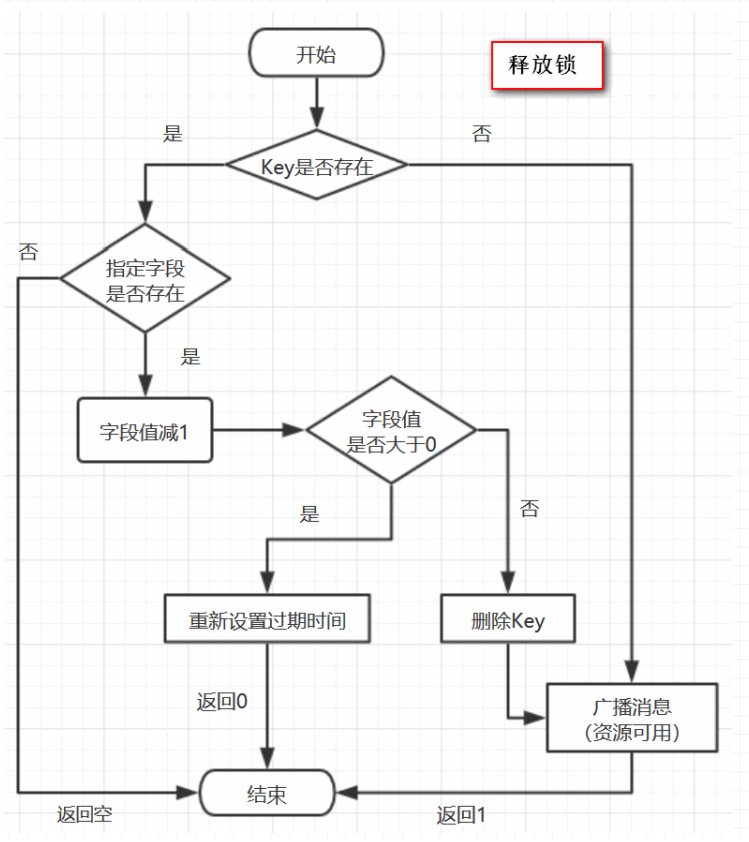
Unlock subscription through redis Channel
The above is the case when the lock is obtained under normal circumstances. What should we do when the lock cannot be obtained immediately?
Go back to the previous position to obtain the lock
@Override
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
// subscribe
RFuture<RedissonLockEntry> future = subscribe(threadId);
commandExecutor.syncSubscription(future);
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().acquire();
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
protected static final LockPubSub PUBSUB = new LockPubSub();
protected RFuture<RedissonLockEntry> subscribe(long threadId) {
return PUBSUB.subscribe(getEntryName(), getChannelName(), commandExecutor.getConnectionManager().getSubscribeService());
}
protected void unsubscribe(RFuture<RedissonLockEntry> future, long threadId) {
PUBSUB.unsubscribe(future.getNow(), getEntryName(), getChannelName(), commandExecutor.getConnectionManager().getSubscribeService());
}
The Channel will be subscribed here. When resources are available, they can be known in time and preempted to prevent invalid polling and waste of resources
The channel here is:
redisson_lock__channel:{DISLOCK}
When resources are available, the loop attempts to obtain locks. Since multiple threads compete for resources at the same time, semaphores are used here. For the same resource, only one thread is allowed to obtain locks, and other threads are blocked
This is similar to Zookeeper distributed lock:
Please refer to the following for the specific principles and implementation of distributed locks:
Zookeeper distributed lock (illustration + second understanding + most complete in History)
Automatic delay mechanism of watch dog
The default lifetime of the lock key locked by client 1 is only 30 seconds. If it exceeds 30 seconds, client 1 still wants to hold the lock all the time. What should I do?
Simple! As long as client 1 succeeds in locking, it will start a watch dog. It is a background thread and will check every 10 seconds. If client 1 still holds the lock key, it will continue to prolong the survival time of the lock key.
Using watchDog mechanism to renew locks
But smart students will certainly ask:
How long is the effective time set? If my business operation is longer than the effective time and my business code has not been executed, it will be unlocked automatically. Isn't it over.
This problem is a little tricky, and there are many discussions on the Internet:
The first solution is to rely on the programmer to grasp, estimate the execution time of the business code, and then set the validity period to be longer than the execution time to ensure that the execution of the client business code will not be affected by automatic unlocking.
However, this is not a panacea. For example, network jitter is unpredictable and may lead to longer execution time of business code, so it is not safe.
The second method uses the watchDog mechanism to renew the lock.
The second method is more reliable and has no business intrusion.
The idea of implementing distributed locks in Redisson framework is to use watchDog mechanism to renew locks.
When the lock is successfully added, the daemon thread is started at the same time. The default validity period is 30 seconds. The lock will be renewed to 30 seconds every 10 seconds. As long as the client holding the lock is not down, it can be guaranteed to hold the lock until the business code is executed. The client will unlock it by itself. If it is down, it will automatically unlock after the validity period expires.
Here, the lock expiration problem of JVM STW is a little similar to the previous solution. However, the automatic renewal of watchDog does not completely solve the lock expiration problem of JVM STW.
How to completely solve the lock expiration problem of JVM STW can be discussed in the community of crazy maker circle.
Usage and principle of redisson watchdog
In fact, the basic flow chart of reisson locking is as follows:
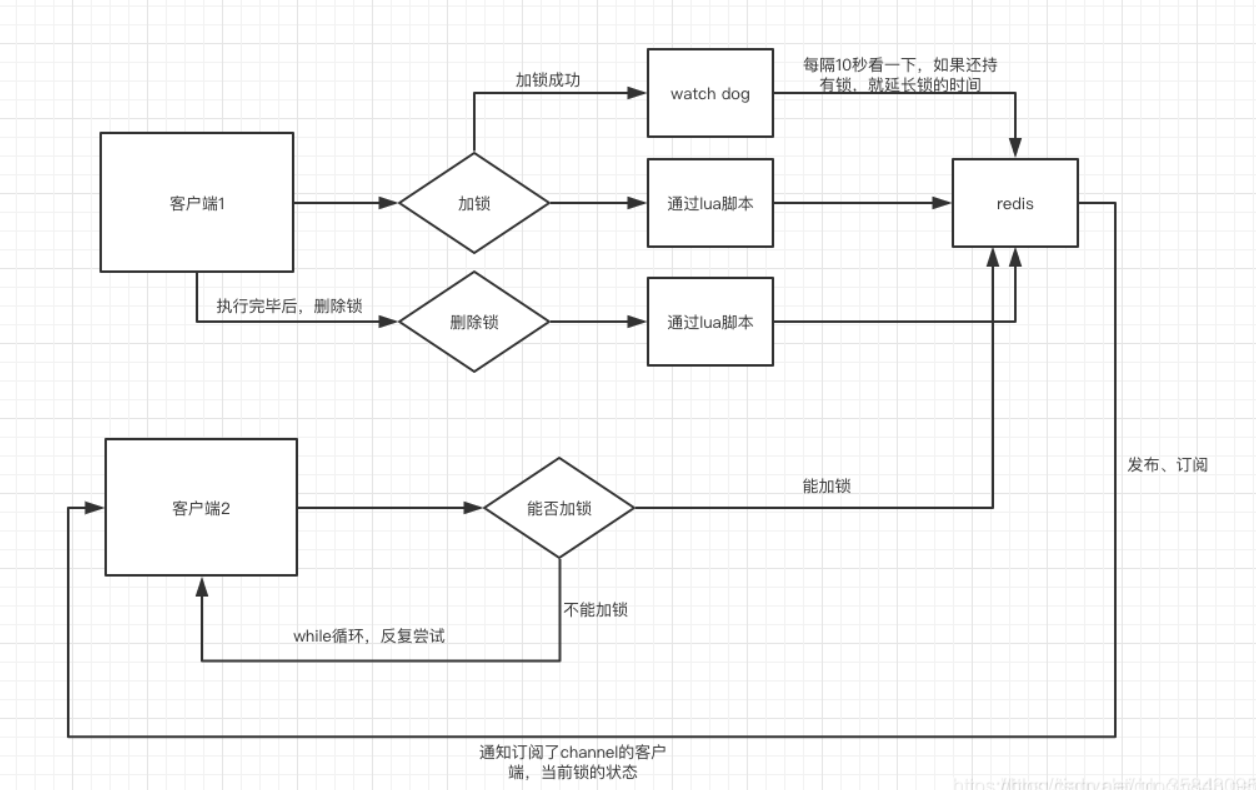
Here we focus on watchdog.
Firstly, the specific idea of watchdog is to lock for 30 seconds by default, check every 10 seconds, and reset the expiration time to 30 seconds if it exists.
Then set the parameter of default locking time as lockWatchdogTimeout (watchdog timeout of monitoring lock, unit: ms)
The official documents are described below
lockWatchdogTimeout (watchdog timeout of monitoring lock, unit: ms)
Default: 30000
Watchdog timeout of monitoring lock, in milliseconds. This parameter is only applicable to the case where the leaseTimeout parameter is not explicitly used in the lock request of distributed lock. If the watchdog does not use lockWatchdogTimeout to readjust the lockWatchdogTimeout timeout of a distributed lock, the lock will become invalid. This parameter can be used to avoid deadlock caused by reisson client node downtime or other reasons.
It should be noted that
Only when you do not specify the time of dotch1 will be displayed. (this is important)
2. The lockwatchdogtimeout setting time should not be too small. For example, I previously set it to 100 milliseconds. After locking is directly caused by the network, when watchdog goes to delay, this key has been deleted in redis.
tryAcquireAsync principle
When the lock method is called, tryAcquireAsync is eventually called. The detailed explanation is as follows:
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
//If the locking time is specified, it will be locked directly
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
//If the lock time is not specified, the lock will be locked first, and the default time is the LockWatchdogTimeout time
//This is an asynchronous operation that returns RFuture, similar to the future in netty
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
//Here is also an addListener similar to netty Future, which is executed after the execution of future content is completed
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
//Here is the action of automatically delaying the current lock
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
}
renewExpiration is called in scheduleExpirationRenewal.
renewExpiration performs a deferred action
Here we can see that a timeout timer is enabled to execute the delay action
private void renewExpiration() {
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) {
//If there is no error, it will be postponed regularly again
// reschedule itself
renewExpiration();
}
});
}
// Here, we can see that the scheduled task takes 1 / 3 of lockWatchdogTimeout to execute renew expiration async
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
Finally, scheduleExpirationRenewal will call reneweexpirationasync,
renewExpirationAsync
Execute the lua script below. His main judgment is whether the lock exists in redis. If it exists, pexpire will be postponed.
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getName()),
internalLockLeaseTime, getLockName(threadId));
}
watchLog summary
1. To make the watchLog mechanism effective, do not set the expiration time during lock
2. The default delay time of watchlog can be specified by lockWatchdogTimeout, but it should not be set too small. Such as 100
3.watchdog will delay every lockWatchdogTimeout/3 time.
4.watchdog realizes asynchronous delay through Future function similar to netty
5.watchdog is finally delayed through lua script
Distributed locks in Redisson framework
The Redisson framework is very powerful. In addition to the distributed lock obtained by the getLock method described earlier (the type of input reentrant lock), there are many other distributed lock types.
The overall distributed lock types of Redisson framework are as follows:
- Reentrant lock
- Fair lock
- interlocking
- Red lock
- Read write lock
- Semaphore
- Expirable semaphore
- Latch (/ countdown latch)
1. Reentrant Lock
Redisson's distributed reentrant lock RLock Java object implements Java util. concurrent. locks. Lock interface, and it also supports automatic expiration and unlocking.
public void testReentrantLock(RedissonClient redisson){
RLock lock = redisson.getLock("anyLock");
try{
// 1. The most common usage
//lock.lock();
// 2. It supports the function of unlocking after expiration. It will be unlocked automatically after 10 seconds without calling the unlock method to unlock manually
//lock.lock(10, TimeUnit.SECONDS);
// 3. Try to lock, wait up to 3 seconds, and unlock automatically after 10 seconds
boolean res = lock.tryLock(3, 10, TimeUnit.SECONDS);
if(res){ //success
// do your business
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
Redisson also provides asynchronous execution methods for distributed locks:
public void testAsyncReentrantLock(RedissonClient redisson){
RLock lock = redisson.getLock("anyLock");
try{
lock.lockAsync();
lock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = lock.tryLockAsync(3, 10, TimeUnit.SECONDS);
if(res.get()){
// do your business
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
2. Fair Lock
Redisson distributed reentrant fair lock also implements Java util. concurrent. locks. A RLock object of the lock interface. While providing the function of automatic expiration unlocking, it ensures that when multiple redisson client threads request locking at the same time, it is preferentially allocated to the thread that makes the request first.
public void testFairLock(RedissonClient redisson){
RLock fairLock = redisson.getFairLock("anyLock");
try{
// Most common usage
fairLock.lock();
// It supports the function of unlocking after expiration. It will be unlocked automatically after 10 seconds without calling the unlock method to unlock manually
fairLock.lock(10, TimeUnit.SECONDS);
// Try to lock, wait for 100 seconds at most, and unlock automatically after 10 seconds
boolean res = fairLock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
fairLock.unlock();
}
}
Redisson also provides asynchronous execution methods for distributed reentrant fair locks:
RLock fairLock = redisson.getFairLock("anyLock");
fairLock.lockAsync();
fairLock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = fairLock.tryLockAsync(100, 10, TimeUnit.SECONDS);
3. Interlock (MultiLock)
Redisson's RedissonMultiLock object can associate multiple RLock objects into an interlock, and each RLock object instance can come from different redisson instances.
public void testMultiLock(RedissonClient redisson1,RedissonClient redisson2, RedissonClient redisson3){
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);
try {
// Lock at the same time: lock1 lock2 lock3. All locks are locked successfully.
lock.lock();
// Try to lock, wait for 100 seconds at most, and unlock automatically after 10 seconds
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
4. Red lock
Redisson's RedissonRedLock object implements the locking algorithm introduced by Redlock. This object can also be used to associate multiple RLock objects into a red lock. Each RLock object instance can come from different redisson instances.
public void testRedLock(RedissonClient redisson1,RedissonClient redisson2, RedissonClient redisson3){
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
try {
// Lock at the same time: lock1, lock2, lock3. If the red lock is successfully locked on most nodes, it will be successful.
lock.lock();
// Try to lock, wait for 100 seconds at most, and unlock automatically after 10 seconds
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
5. Read write lock
Redisson's distributed reentrant read-write lock rreadwritelock is implemented in Java util. concurrent. locks. Readwritelock interface. It also supports automatic expiration and unlocking. The object allows multiple read locks at the same time, but there can be at most one write lock.
RReadWriteLock rwlock = redisson.getLock("anyRWLock");
// Most common usage
rwlock.readLock().lock();
// or
rwlock.writeLock().lock();
// Support expiration unlocking function
// Automatic unlocking after 10 seconds
// There is no need to call the unlock method to unlock manually
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// or
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// Try to lock, wait for 100 seconds at most, and unlock automatically after 10 seconds
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// or
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
6. Semaphore
Redisson's distributed semaphore Java object RSemaphore is similar to Java util. concurrent. Semaphore has similar interfaces and usage.
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//or
semaphore.acquireAsync();
semaphore.acquire(23);
semaphore.tryAcquire();
//or
semaphore.tryAcquireAsync();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
//or
semaphore.tryAcquireAsync(23, TimeUnit.SECONDS);
semaphore.release(10);
semaphore.release();
//or
semaphore.releaseAsync();
7. PermitExpirableSemaphore
Redisson's expirable semaphore adds an expiration time for each signal based on the RSemaphore object. Each signal can be identified by an independent ID. when releasing, it can only be released by submitting this ID.
RPermitExpirableSemaphore semaphore = redisson.getPermitExpirableSemaphore("mySemaphore");
String permitId = semaphore.acquire();
// Get a signal, valid for only 2 seconds.
String permitId = semaphore.acquire(2, TimeUnit.SECONDS);
// ...
semaphore.release(permitId);
8. Countdown latch
Redisson's CountDownLatch Java object RCountDownLatch is similar to Java util. concurrent. CountDownLatch has similar interface and usage.
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// In other threads or other JVM s
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
High availability of redis distributed locks
The high availability of Redis distributed locks is as follows:
In the cluster architecture of master slave, if you write the value of the unlock lock key to a redis master instance, it will be asynchronously copied to the corresponding master slave instance.
However, in this process, once the redis Master goes down, the active and standby switches, and the redis slave becomes the redis master. At this time, the master-slave replication is not completely completed
Then, when client 2 tries to lock, it completes locking on the new redis master, and client 1 thinks it has successfully locked.
This will cause multiple clients to lock a distributed lock.
At this time, the system will have problems in business semantics, resulting in dirty data.
Therefore, this is the biggest defect of redis distributed lock caused by master-slave asynchronous replication of redis master slave architecture:
When the redis master instance goes down, multiple clients may be locked at the same time.
High availability RedLock principle
RedLock algorithm idea:
You can't create locks on only one redis instance. You should create locks on multiple redis instances. n / 2 + 1. You must successfully create locks on most redis nodes to calculate the success of the overall RedLock locking, so as to avoid the problems caused by locking only one redis instance.
This scenario assumes that there is a redis cluster and five redis master instances. Then perform the following steps to obtain a red lock:
- Get the current timestamp, in milliseconds;
- Similar to the above, try to create locks on each master node in turn. The expiration time is short, usually tens of milliseconds;
- Try to establish a lock on most nodes. For example, five nodes require three nodes n / 2 + 1;
- The client calculates the time to establish the lock. If the time to establish the lock is less than the timeout, the establishment is successful;
- If the lock creation fails, delete the previously created locks in turn;
- As long as you keep trying to get the lock, you have to try to get it.

RedLock is a distributed lock based on redis. It can guarantee the following features:
-
Mutex: at any time, only one client can hold the lock; Deadlock avoidance:
-
When the client gets the lock, the deadlock will not occur even if the network partition or the client goes down; (using the survival time of the key)
-
Fault tolerance: as long as the redis instances of most nodes are running normally, they can provide external services, lock or release locks;
Take sentinel mode architecture as an example. As shown in the following figure, there are three sentinel mode clusters: sentinel-1, sentinel-2 and sentinel-3. If you want to obtain distributed locks, you need to execute LUA script through EVAL command to these three sentinel clusters. You need 3 / 2 + 1 = 2, that is, at least two sentinel clusters respond successfully before you can obtain distributed locks with Redlock algorithm:
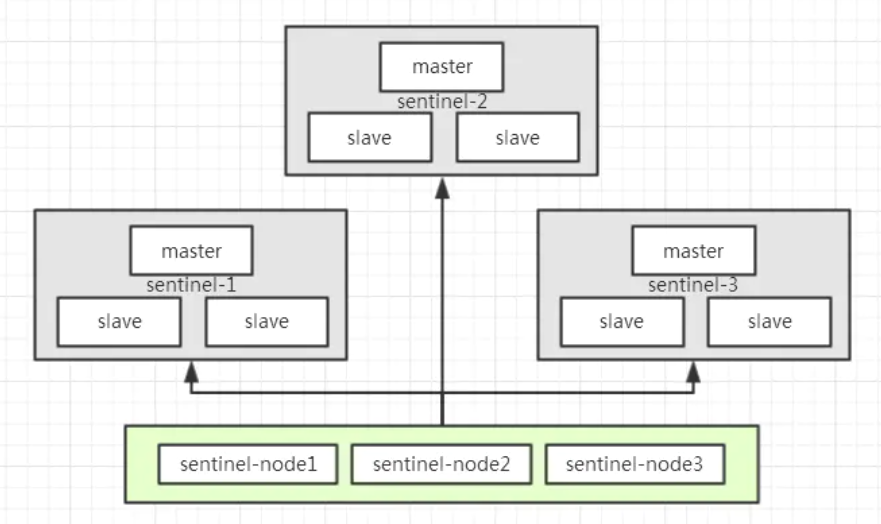
High availability red locks can lead to performance degradation
It is explained in advance that using redis distributed lock is to pursue high performance. In cap theory, it is ap rather than cp.
It is recommended to use distributed lock, so if zooker is available, it is recommended to use distributed lock.
The data inconsistency caused by redis distributed lock is recommended to be compensated by business compensation. Therefore, it is not recommended to use red lock, but from the perspective of learning, we must master it.
Implementation principle
There is a concept of MultiLock in Redisson, which can combine multiple locks into one large lock, and uniformly apply for locking and releasing a large lock
The implementation of RedLock in Redisson is based on MultiLock. Next, let's take a look at the corresponding implementation
RedLock use case
First look at the official code usage:
(https://github.com/redisson/redisson/wiki/8.-distributed-locks-and-synchronizers#84-redlock)
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RLock redLock = anyRedisson.getRedLock(lock1, lock2, lock3);
// traditional lock method
redLock.lock();
// or acquire lock and automatically unlock it after 10 seconds
redLock.lock(10, TimeUnit.SECONDS);
// or wait for lock aquisition up to 100 seconds
// and automatically unlock it after 10 seconds
boolean res = redLock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
redLock.unlock();
}
}
Here is to lock three redis instances respectively, and then obtain a final locking result.
Implementation principle of RedissonRedLock
The above example uses redlock Lock () or tryLock() ultimately executes the methods in redissoredlock.
RedissonRedLock inherits from RedissonMultiLock and implements some of its methods:
public class RedissonRedLock extends RedissonMultiLock {
public RedissonRedLock(RLock... locks) {
super(locks);
}
/**
* The number of times a lock can fail, the number of locks - the minimum number of successful clients
*/
@Override
protected int failedLocksLimit() {
return locks.size() - minLocksAmount(locks);
}
/**
* Number of locks / 2 + 1. For example, if there are 3 clients locked, at least 2 clients need to be locked successfully
*/
protected int minLocksAmount(final List<RLock> locks) {
return locks.size()/2 + 1;
}
/**
* Calculate the timeout of multiple clients locking together and the waiting time of each client
* remainTime The default is 4.5s
*/
@Override
protected long calcLockWaitTime(long remainTime) {
return Math.max(remainTime / locks.size(), 1);
}
@Override
public void unlock() {
unlockInner(locks);
}
}
See locks Size () / 2 + 1. For example, if we have 3 client instances, then locking at least 2 instances is successful.
Next, let's look at the concrete implementation of lock()
Implementation principle of RedissonMultiLock
public class RedissonMultiLock implements Lock {
final List<RLock> locks = new ArrayList<RLock>();
public RedissonMultiLock(RLock... locks) {
if (locks.length == 0) {
throw new IllegalArgumentException("Lock objects are not defined");
}
this.locks.addAll(Arrays.asList(locks));
}
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long newLeaseTime = -1;
if (leaseTime != -1) {
// If the waiting time is set, the waiting time will be * 2
newLeaseTime = unit.toMillis(waitTime)*2;
}
// time is the current timestamp
long time = System.currentTimeMillis();
long remainTime = -1;
if (waitTime != -1) {
remainTime = unit.toMillis(waitTime);
}
// Calculate the waiting time of the lock. In RedLock: if remainTime=-1, lockWaitTime is 1
long lockWaitTime = calcLockWaitTime(remainTime);
// failedLocksLimit in RedLock is n/2 + 1
int failedLocksLimit = failedLocksLimit();
List<RLock> acquiredLocks = new ArrayList<RLock>(locks.size());
// Cycle each redis client to obtain the lock
for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
// Call the tryLock method to obtain the lock. If the lock is obtained successfully, lockAcquired=true
if (waitTime == -1 && leaseTime == -1) {
lockAcquired = lock.tryLock();
} else {
long awaitTime = Math.min(lockWaitTime, remainTime);
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
}
} catch (Exception e) {
lockAcquired = false;
}
// If the lock is obtained successfully, the lock is added to the list collection
if (lockAcquired) {
acquiredLocks.add(lock);
} else {
// If the lock acquisition fails, judge whether the number of failures is equal to the limit number of failures
// For example, three redis clients can only fail once at most
// Here are locks Size = 3, 3-x = 1, indicating that you can break the cycle directly as long as you succeed twice
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
// If the maximum number of failures equals 0
if (failedLocksLimit == 0) {
// Release all locks. RedLock failed to lock
unlockInner(acquiredLocks);
if (waitTime == -1 && leaseTime == -1) {
return false;
}
failedLocksLimit = failedLocksLimit();
acquiredLocks.clear();
// Reset the iterator and try to acquire the lock again
while (iterator.hasPrevious()) {
iterator.previous();
}
} else {
// The limit number of failures is reduced by one
// For example, for three redis instances, the maximum limit is 1. If the first redis instance fails, the failedLocksLimit will be reduced to 0
// If failedLocksLimit follows the if logic above, releases all locks, and then returns false
failedLocksLimit--;
}
}
if (remainTime != -1) {
remainTime -= (System.currentTimeMillis() - time);
time = System.currentTimeMillis();
if (remainTime <= 0) {
unlockInner(acquiredLocks);
return false;
}
}
}
if (leaseTime != -1) {
List<RFuture<Boolean>> futures = new ArrayList<RFuture<Boolean>>(acquiredLocks.size());
for (RLock rLock : acquiredLocks) {
RFuture<Boolean> future = rLock.expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);
futures.add(future);
}
for (RFuture<Boolean> rFuture : futures) {
rFuture.syncUninterruptibly();
}
}
return true;
}
}
The core code has been annotated. The implementation principle is actually very simple. Based on the idea of RedLock, traverse all Redis clients, lock them in turn, and finally count the number of successful times to judge whether the locking is successful.
The core content and source code of the article
Book: introduction to Netty Zookeeper Redis high concurrency practice - Crazy creation
Reference documents:
Book: introduction to Netty Zookeeper Redis high concurrency practice - Crazy creation
Usage and principle of redisson watchdog
Implementation of distributed lock by zookeeper_ java_ Script house
Implementation of distributed lock based on Zookeeper - SegmentFault
Redis or Zookeeper for distributed locks
Implementation principle of ZooKeeper distributed lock - rookie struggle history - blog Garden
https://blog.csdn.net/men_wen/article/details/72853078
Question exchange of this article: Crazy maker circle community