Full text overview
Why need hystrix
hystrix official website address github
-
Hystrix is also netfix's contribution to distributed systems. Similarly, it has entered the non maintenance phase. Not maintaining does not mean being eliminated. It can only show that the new technology is constantly iterative. The brilliant design is still worth learning.
-
In the distributed environment, service scheduling is a feature and a headache. In the chapter of service governance, we introduced the functions of service governance. In the previous lesson, we also introduced ribbon and feign for service invocation. Now it's time for service monitoring and management. hystrix is to isolate and protect services. So that the service will not have joint and several failures. Make the whole system unavailable
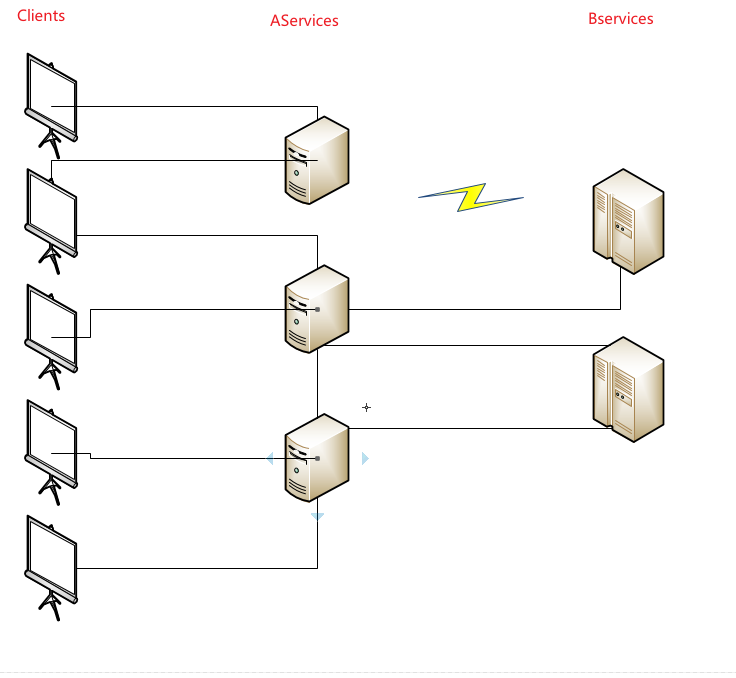
- As shown in the above figure, when multiple clients call Aservice for services, there are three services in Aservice in the distributed system, and some logic of Aservice needs to be processed by bservice. Bservice deploys two services in the distributed system. At this time, the communication between one of Aservice and bservice is abnormal due to network problems. If bservice does log processing. In the view of the whole system, it doesn't matter whether the log is lost or the system is down. However, at this time, the whole service of Aservice is unavailable due to network communication problems. It's a little hard to try.
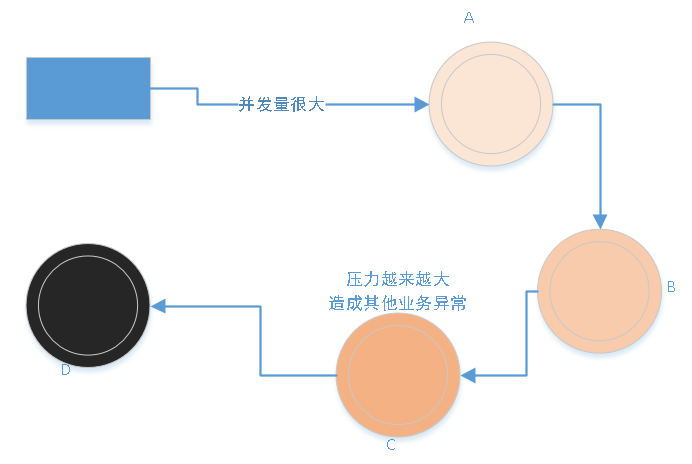
- Look at the picture. A–>B–>C–>D . At this time, the D service is down. Processing exception occurred due to downtime of C and D. But the thread of C is still responding to B. In this way, when concurrent requests come in, the C service thread pool is full, causing the CPU to rise. At this time, other services of C service will also be affected by the rise of CPU, resulting in slow response.
Characteristic function
Hystrix is a low latency and fault-tolerant third-party component library. Access points designed to isolate remote systems, services, and third-party libraries. Maintenance has been stopped and recommended on the official website resilience4j . But in China, we have springcloud alibaba.
Hystrix implements the delay and fault tolerance mechanism in distributed systems by isolating the access between services to solve the service avalanche scenario, and can provide fallback based on hystrix.
- Fault tolerance for network delays and faults
- Blocking distributed system avalanche
- Fast failure and smooth recovery
- service degradation
- Real time monitoring and alarm
99.9 9 30 = 99.7 % u p t i m e 0.3 % o f 1 b i l l i o n r e q u e s t s = 3 , 000 , 000 f a i l u r e s 2 + h o u r s d o w n t i m e / m o n t h e v e n i f a l l d e p e n d e n c i e s h a v e e x c e l l e n t u p t i m e . 99.99^{30} = 99.7\% \quad uptime \\ 0.3\% \quad of \quad 1 \quad billion \quad requests \quad = \quad 3,000,000 \quad failures \\ 2+ \quad hours \quad downtime/month \quad even \quad if \quad all \quad dependencies \quad have \quad excellent \quad uptime. 99.9930=99.7%uptime0.3%of1billionrequests=3,000,000failures2+hoursdowntime/monthevenifalldependencieshaveexcellentuptime.
- A statistic given on the interview website. The overview of abnormality in each of the 30 services is 0.01%. One hundred million requests will have 300000 failures. In this way, there will be at least 2 hours of downtime per month. This is fatal to the Internet system.
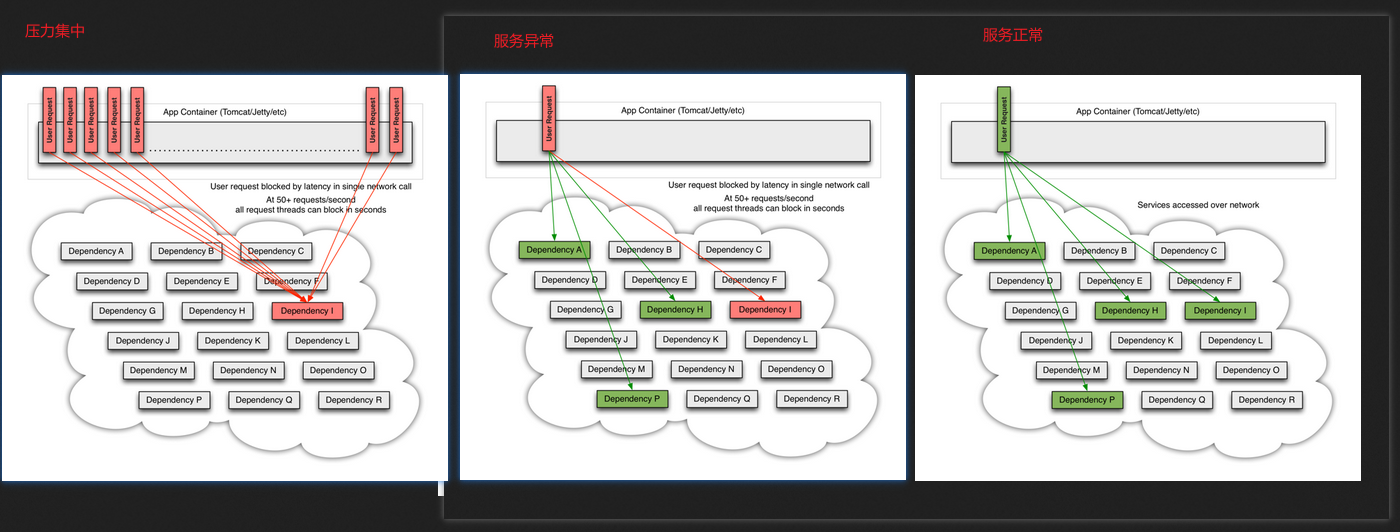
- The above figure shows the two situations given on the official website. Similar to our previous chapter. They are all scenes that introduce service avalanches.
Project preparation
- In the topic of openfeign, we discussed the service implementation based on feign. At that time, we said that the internal is based on hystrix. At that time, we also looked at the internal structure of pom. eureka has built-in ribbon and also built-in hystrix module.
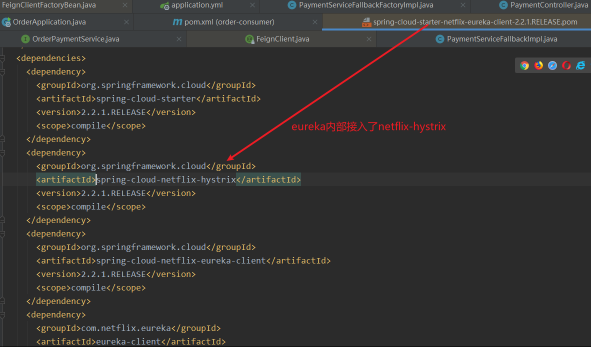
-
Although the package contains hystrix. Let's introduce the corresponding start to start the related configuration. This is actually the Liezi in the openfeign topic. In that topic, we provided PaymentServiceFallbackImpl and PaymentServiceFallbackFactoryImpl as alternatives. However, at that time, we only need to point out that openfeign supports the alternative of setting up two methods. Today we
<!--hystrix--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>Demonstrate what disaster will happen if traditional enterprises do not have alternatives.
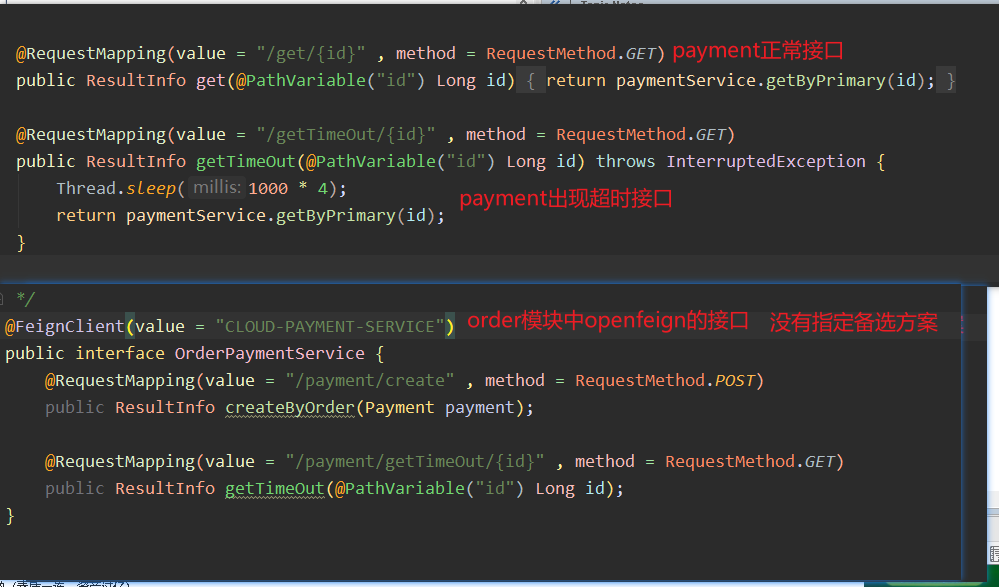

Interface test
-
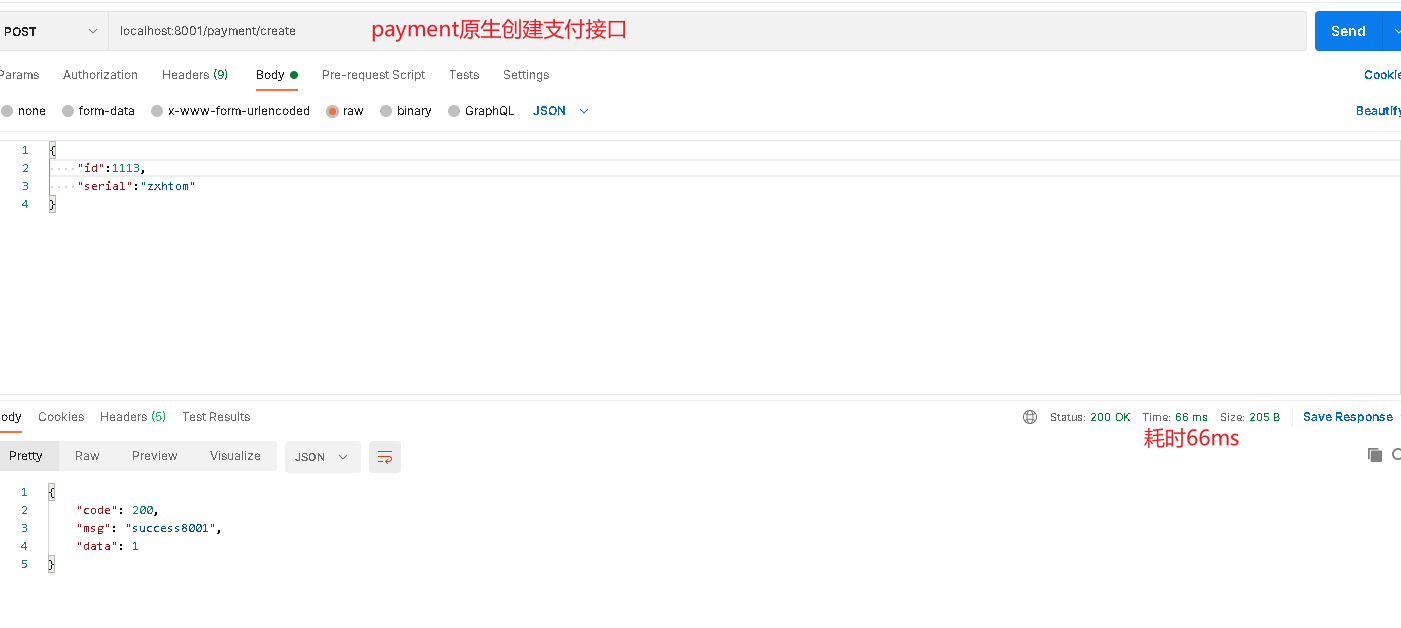
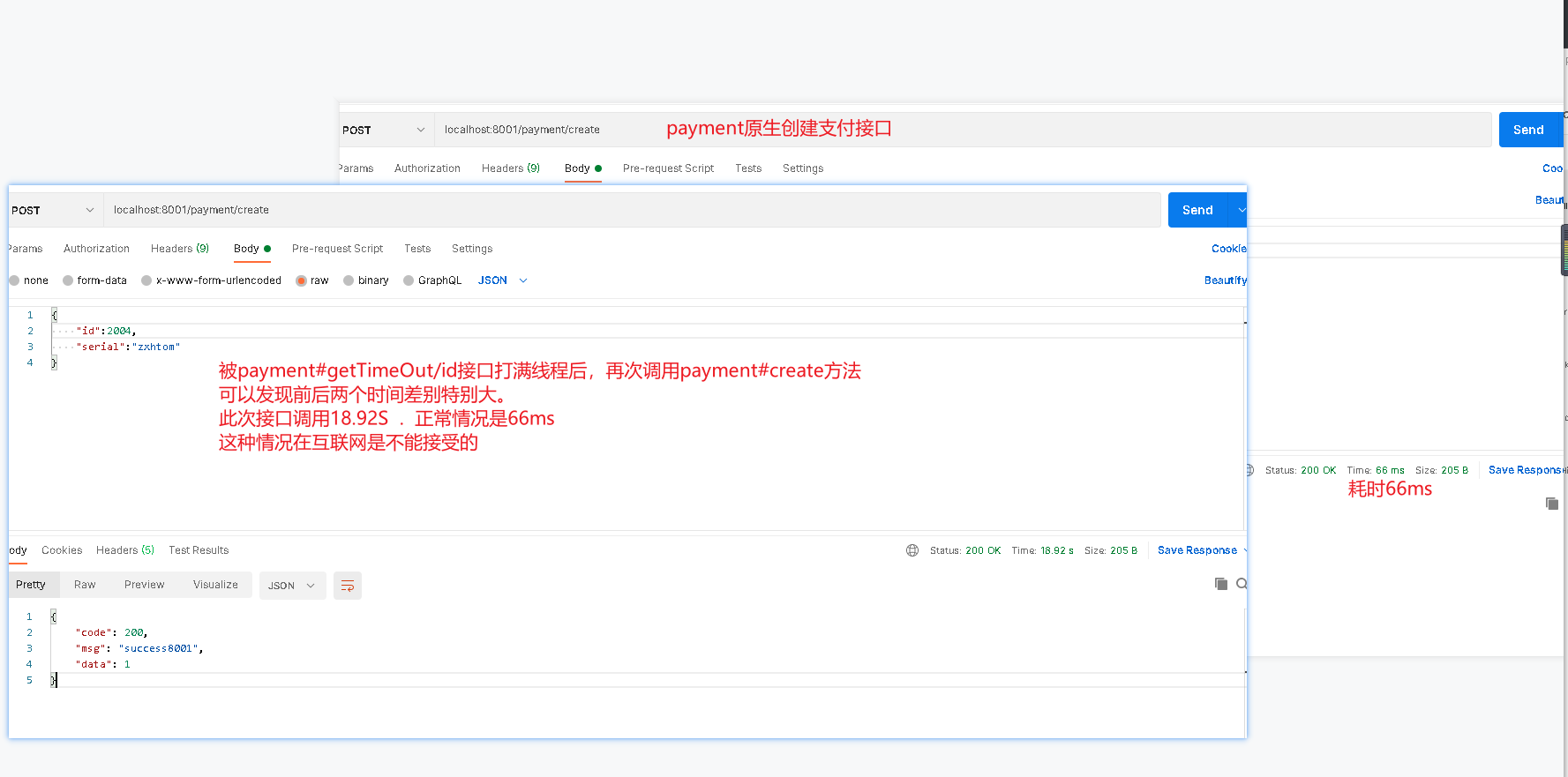
First, we test the payment#createByOrder interface. View the next response
-
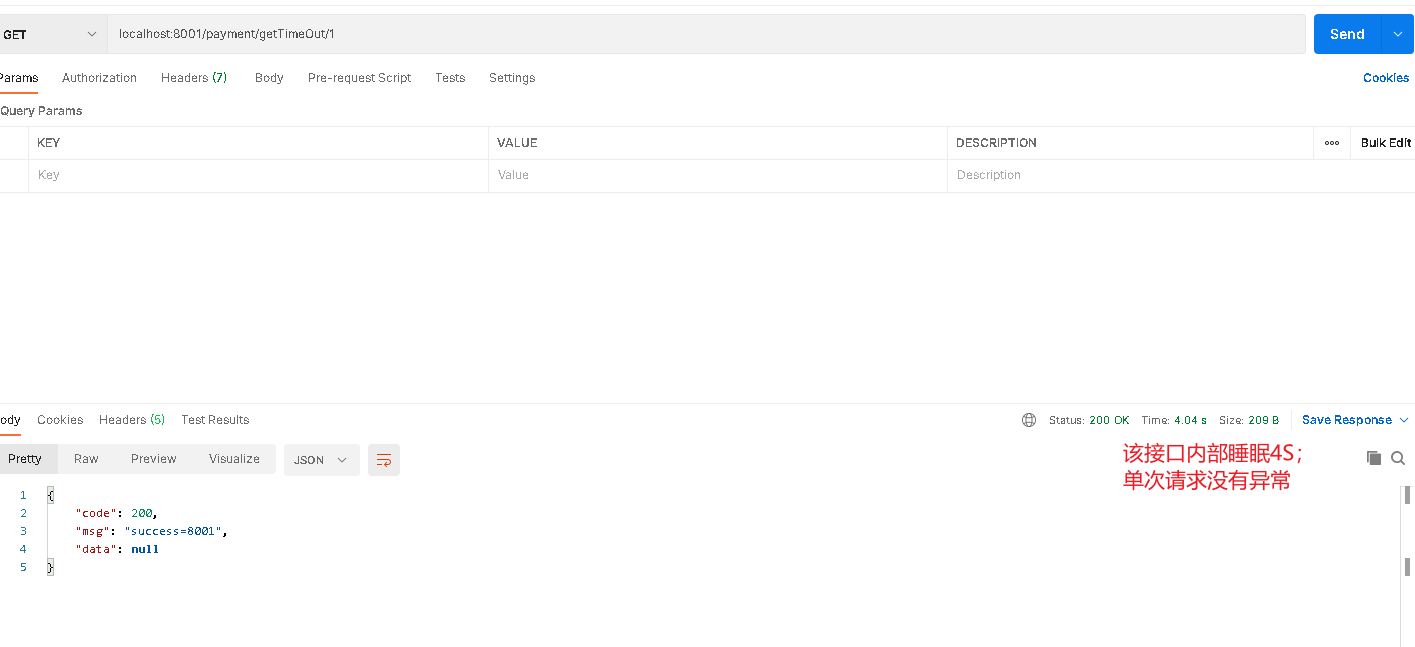
The payment#getTimeout/id method is being tested.
- Now let's use jemeter to test the interface of payment#getTimeOut/id. A customer who needs to wait at the 4S store will run out of resources. At this time, our payment#createByOrder will also be blocked.
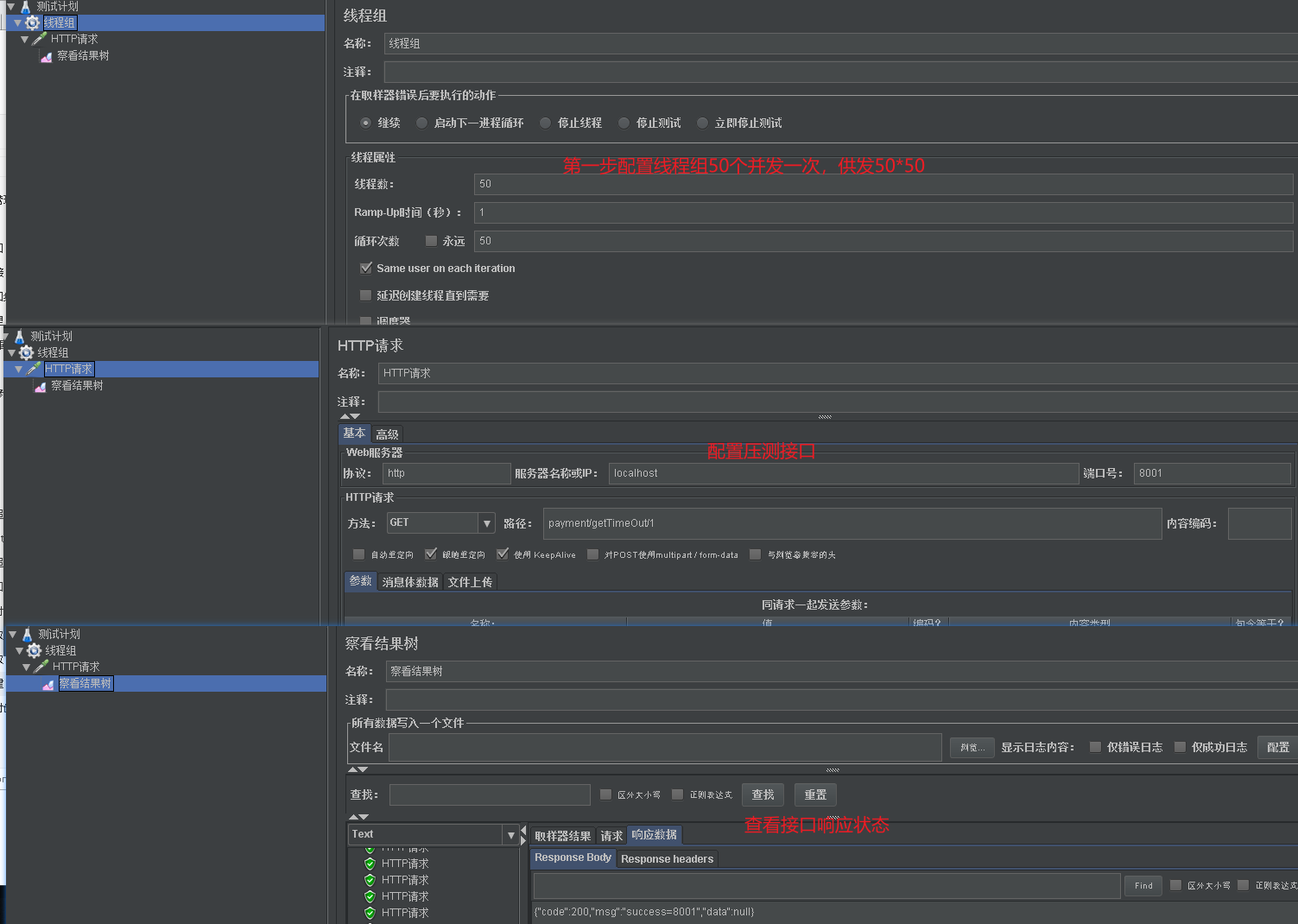
- The default maximum number of threads of tomcat in spring is 200 To protect our hard-working notebooks. Here we set the number of threads to a small point. In this way, it is easier for us to reproduce the situation that the thread is full. When the thread is full, the payment#createByOrder interface will be affected.
-
What we tested above is the native interface of payment. If the pressure measurement is the order module. If fallback is not configured in openfeign. Then the order service will cause the thread to be full due to the concurrency of the payment#getTimeOut/id interface, resulting in the slow response of the order module. This is the avalanche effect. Next, we will solve the occurrence of avalanche from two aspects.
Business isolation
-
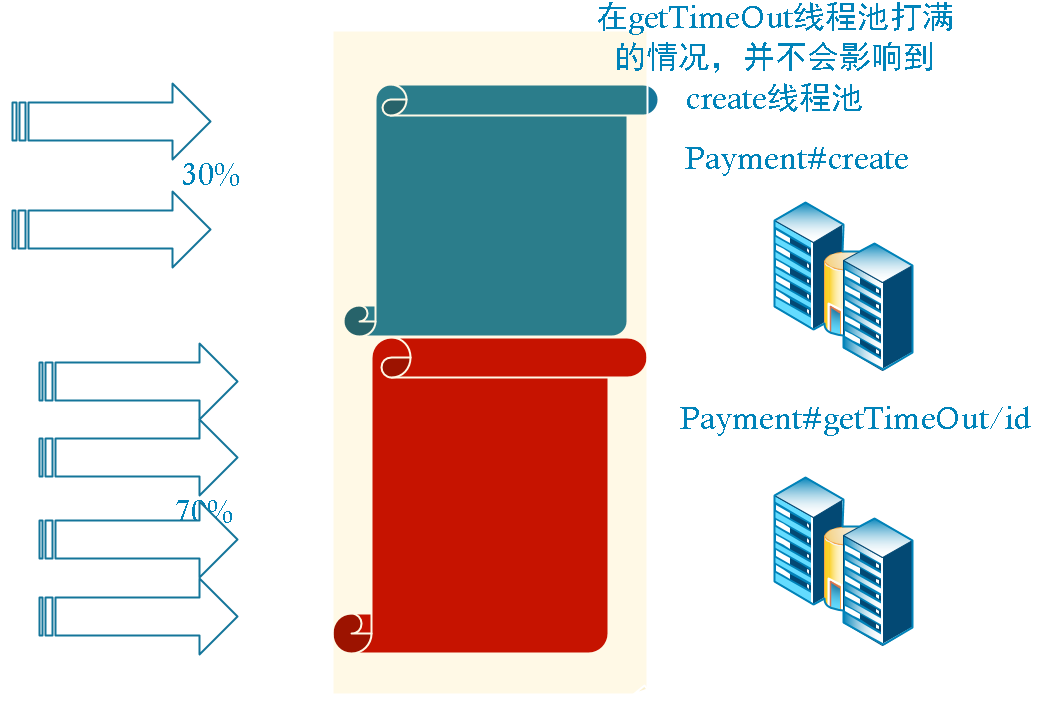
The above scenario occurs because payment#createByOrder and payment#getTimeOut/id belong to the payment service. A payment service is actually a tomcat service. The same tomcat service has a thread pool. Every time a request falls into the tomcat service, it will apply for a thread in the thread pool. Only when the thread is obtained can the thread process the requested business. Because the thread pool is shared in tomcat. Therefore, when the payment#getTimeOut/id comes up concurrently, the thread pool will be emptied. As a result, there are no resources to apply for other excuses or even irrelevant interfaces. Can only wait for the release of resources.
-
This is like taking an elevator during rush hours, because a company concentrates on working, resulting in all elevators being used for a period of time. At this time, the national leaders couldn't get on the elevator.
-
We also know that this situation is easy to solve. Each park will have special elevators for special use.
-
We solve the above problems in the same way. Isolate. Different interfaces have different thread pools. So there won't be an avalanche.
Thread isolation
-
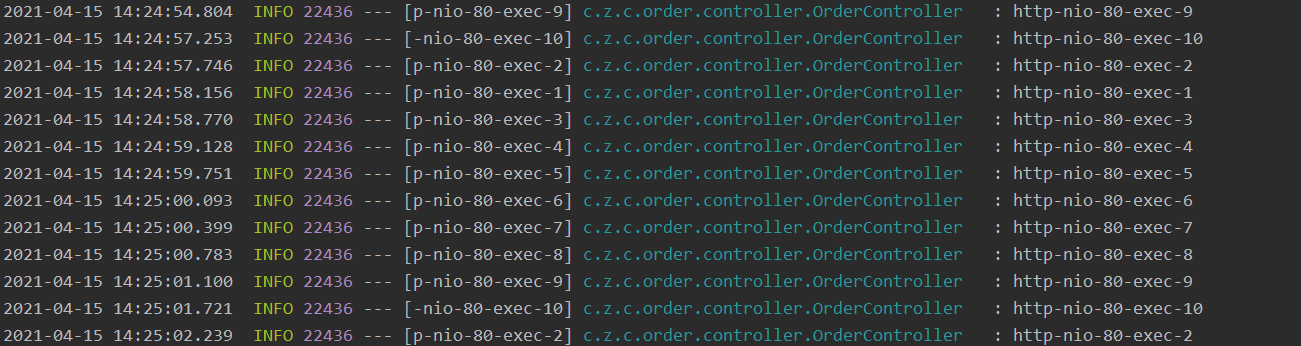
Remember that in order to demonstrate concurrency, we set the maximum number of threads in the order module to 10 Here, we call the order/getpayment/1 interface through the test tool to see the log printing
-
We print the current thread where the interface is called. We can see that all 10 threads are used back and forth. This is why the avalanche phenomenon is caused above.
@HystrixCommand(
groupKey = "order-service-getPaymentInfo",
commandKey = "getPaymentInfo",
threadPoolKey = "orderServicePaymentInfo",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "1000")
},
threadPoolProperties = {
@HystrixProperty(name = "coreSize" ,value = "6"),
@HystrixProperty(name = "maxQueueSize",value = "100"),
@HystrixProperty(name = "keepAliveTimeMinutes",value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold",value = "100")
},
fallbackMethod = "getPaymentInfoFallback"
)
@RequestMapping(value = "/getpayment/{id}",method = RequestMethod.GET)
public ResultInfo getPaymentInfo(@PathVariable("id") Long id) {
log.info(Thread.currentThread().getName());
return restTemplate.getForObject(PAYMENT_URL+"/payment/get/"+id, ResultInfo.class);
}
public ResultInfo getPaymentInfoFallback(@PathVariable("id") Long id) {
log.info("We have entered the alternative scheme. Now let the free thread execute it"+Thread.currentThread().getName());
return new ResultInfo();
}
@HystrixCommand(
groupKey = "order-service-getpaymentTimeout",
commandKey = "getpaymentTimeout",
threadPoolKey = "orderServicegetpaymentTimeout",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "10000")
},
threadPoolProperties = {
@HystrixProperty(name = "coreSize" ,value = "3"),
@HystrixProperty(name = "maxQueueSize",value = "100"),
@HystrixProperty(name = "keepAliveTimeMinutes",value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold",value = "100")
}
)
@RequestMapping(value = "/getpaymentTimeout/{id}",method = RequestMethod.GET)
public ResultInfo getpaymentTimeout(@PathVariable("id") Long id) {
log.info(Thread.currentThread().getName());
return orderPaymentService.getTimeOut(id);
}
- The demonstration effect here is not good. I'll show the data directly.
| The concurrency is in getpaymentTimeout | getpaymentTimeout/{id} | /getpayment/{id} |
|---|---|---|
| 20 | After three threads are full, an error is reported for a period of time | Can respond normally; Also slow, cpu thread switching takes time |
| 30 | ditto | ditto |
| 50 | ditto | It will also time out, because the pressure of order calling payment service will be affected |
- If we load hystrix into the payment native service, the third situation above will not occur. Why I put it on order just to show you the avalanche scene. When concurrency is 50, because the maximum thread set by payment is also 10, it also has throughput. Although the order#getpyament/id interface has its own thread running in the order module because of hystrix thread isolation, it suck its own timeout because of the lack of force in the native service, which affects the operation effect. This demonstration is also to lead to a scene simulation of fallback to solve avalanche.
- We can set fallback through hystrix in the payment service. Ensure that the payment service has low latency, so as to ensure that the order module will not cause the normal interface exception of order#getpayment due to the slow payment itself.
- One more thing, though, is thread isolation through hystrix. But when we run other interfaces, the response time will be a little longer. Because the CPU has overhead when switching threads. This is also a pain point. We can't isolate threads at will. This leads to our semaphore isolation.
Semaphore isolation
- The signal isolation will not be demonstrated here. The demonstration is not very meaningful
@HystrixCommand(
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "1000"),
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY,value = "SEMAPHORE"),
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS,value = "6")
},
fallbackMethod = "getPaymentInfoFallback"
)
- The above configuration indicates that the maximum semaphore is 6. Indicates that the wait will occur after concurrency 6. The waiting timeout is less than 1s.
| measures | advantage | shortcoming | overtime | Fuse | asynchronous |
|---|---|---|---|---|---|
| Thread isolation | One call a thread pool; Do not interfere with each other; Ensure high availability | cpu thread switching overhead | √ | √ | √ |
| Semaphore isolation | Avoid CPU switching. Efficient | In high concurrency scenarios, the amount of stored signals becomes larger | × | √ | × |
- In addition to thread isolation, semaphore isolation and other isolation methods, we can strengthen stability through request merging, interface data caching and other means.
service degradation
Trigger condition
- Exception except HystrixBadRequestException occurred in the program.
- Service call timeout
- Service fuse
- Insufficient thread pool and semaphore
-
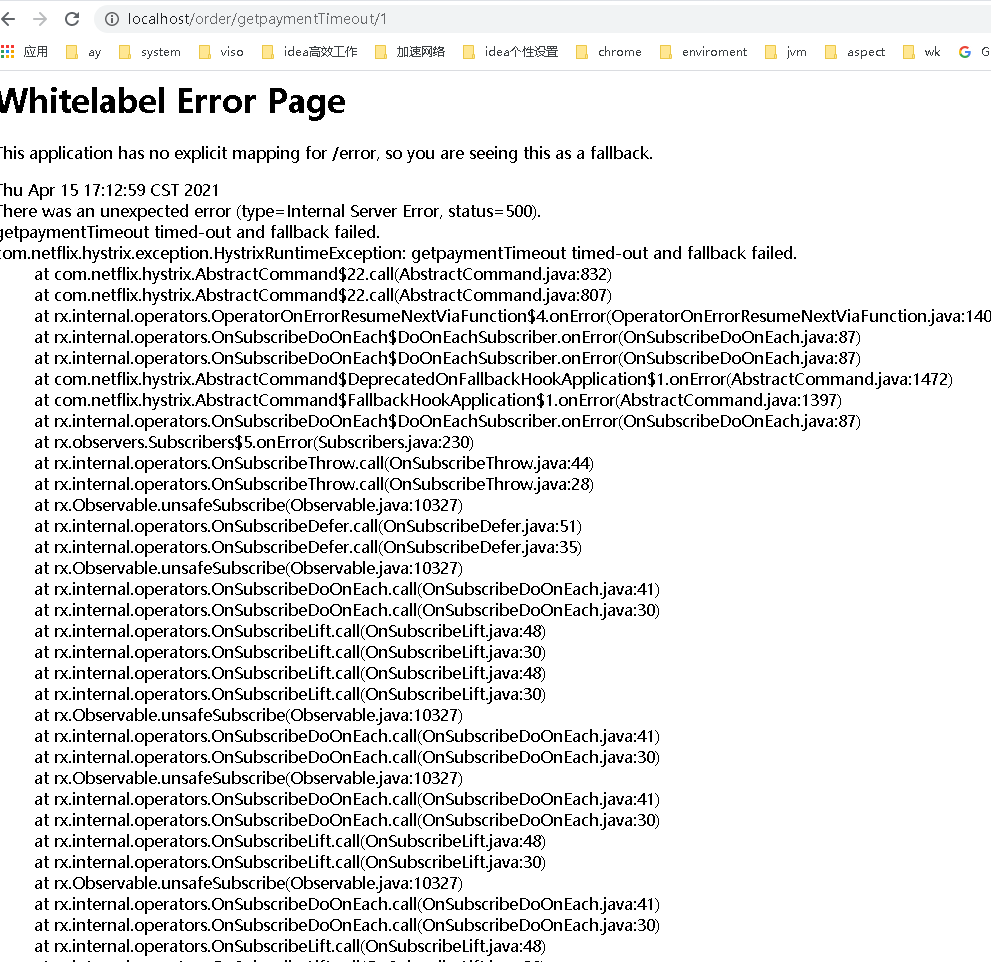
Our timeout interface above. Whether thread isolation or semaphore isolation, subsequent requests will be rejected directly when the conditions are met. That's rude. We also mentioned fallback above.
-
Also remember that the getpayment interface exception will be caused when we order 50 concurrent timeout s. At that time, it was located because the pressure of the native payment service could not hold up. If we add fallback to payment, we can ensure fast response when resources are insufficient. This at least ensures the availability of the order#getpayment method.
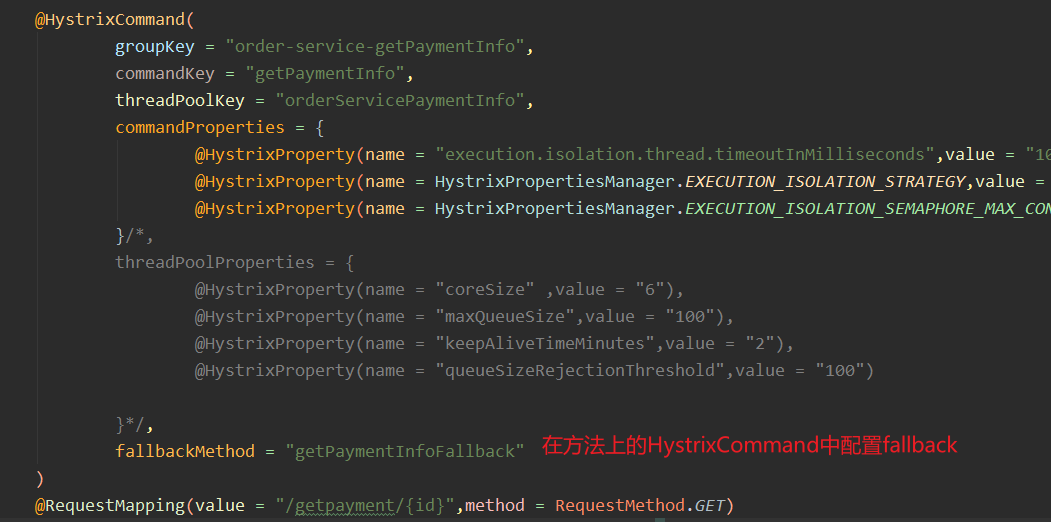
-
However, this configuration is experimental. In real production, it is impossible to configure fallback on each method. It's so stupid.
-
In addition to the specially customized fallback in the method, hystrix also has a global fallback. You only need to use @ DefaultProperties(defaultFallback = "globalFallback") on the class to implement the global alternative. When a method meets the conditions for triggering degradation, if fallback is not configured in the HystrixCommand annotation corresponding to the request, the global fallback of the class is used. Throw an exception if there is no global.
Insufficient
- Although DefaultProperties can avoid configuring fallback for each interface. But this kind of global fallback doesn't seem to be global. We still need to configure fallback on each class. The author looked up the information and didn't seem to have it
- However, in the topic of openfeign, we talked about the service degradation function realized by openfeign combined with hystrix. Did you mention a FallbackFactory class. This class can be understood as spring's BeanFactory. This class is used to generate the fallback we need. In this factory, we can generate a generic type of fallback proxy object. The proxy object can enter and exit parameters according to the method signature of the proxy method.
- In this way, we can configure this factory class in all openfeign places. In this way, you can avoid generating many fallbacks. The fly in the ointment still needs to be specified everywhere. For those interested in FallBackFactory, you can download the source code or go to the home page to view the openfeign topic.
-
Service fuse
@HystrixCommand(
commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled",value = "true"), //Is the circuit breaker on
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"), //Number of requests
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"), //time frame
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60"), //What is the failure rate before tripping
},
fallbackMethod = "getInfoFallback"
)
@RequestMapping(value = "/get", method = RequestMethod.GET)
public ResultInfo get(@RequestParam Long id) {
if (id < 0) {
int i = 1 / 0;
}
log.info(Thread.currentThread().getName());
return orderPaymentService.get(id);
}
public ResultInfo getInfoFallback(@RequestParam Long id) {
return new ResultInfo();
}
- First, we use circuitbreaker Enabled = true open the fuse
- circuitBreaker. Requestvolumthreshold sets the count of requests
- circuitBreaker.sleepWindowInMilliseconds sets the time sliding unit, how long to try to open after triggering the fuse, and the commonly known half open state
- circuitBreaker.errorThresholdPercentage sets the critical condition for triggering the fused switch
- In the above configuration, if the error rate of the last 10 requests reaches 60%, the fuse degradation will be triggered, and the service will be degraded if it is in the fuse state within 10S. After 10S, try to get the latest service status
- Let's interface through jmeter http://localhost/order/get?id=-1 conduct 20 tests. Although there is no additional error in these 20 times. But we will find that the initial error is due to the error in our code. The following error is the error of hystrix fusing. At first, try by zero error, and then short circuited and fallback failed
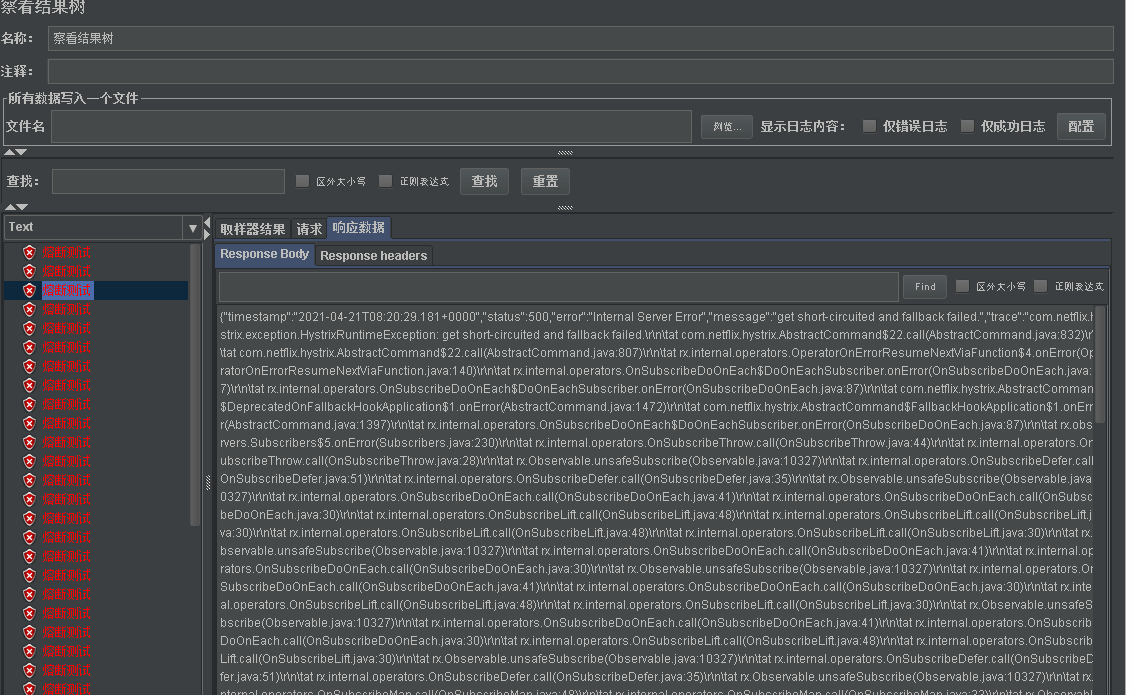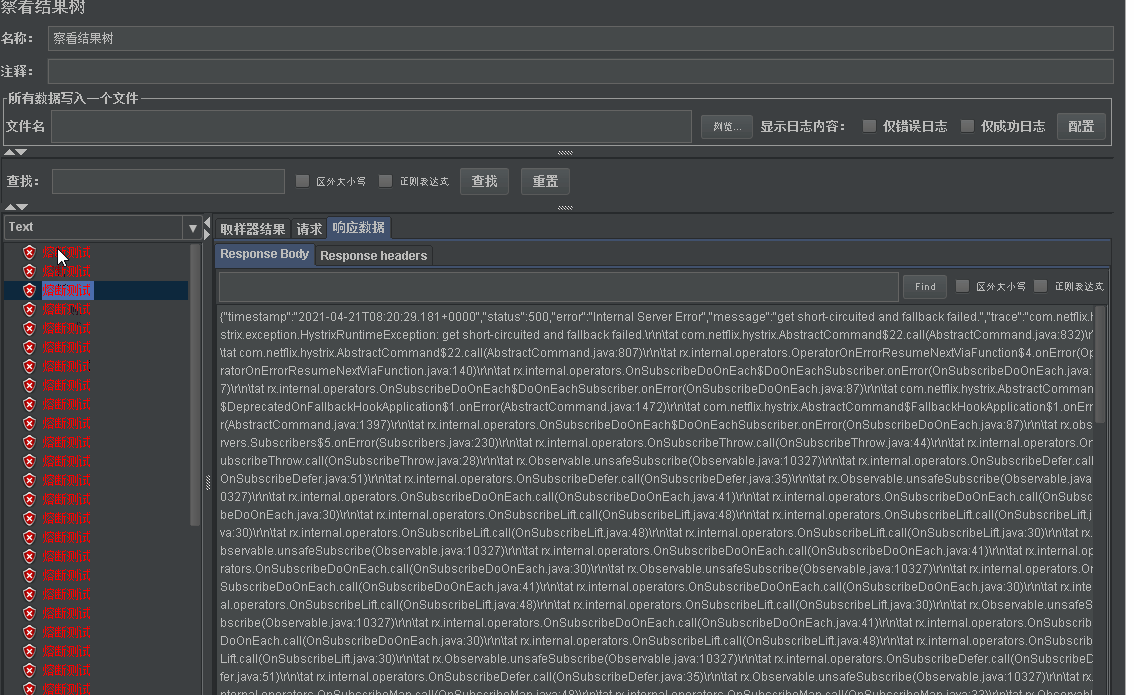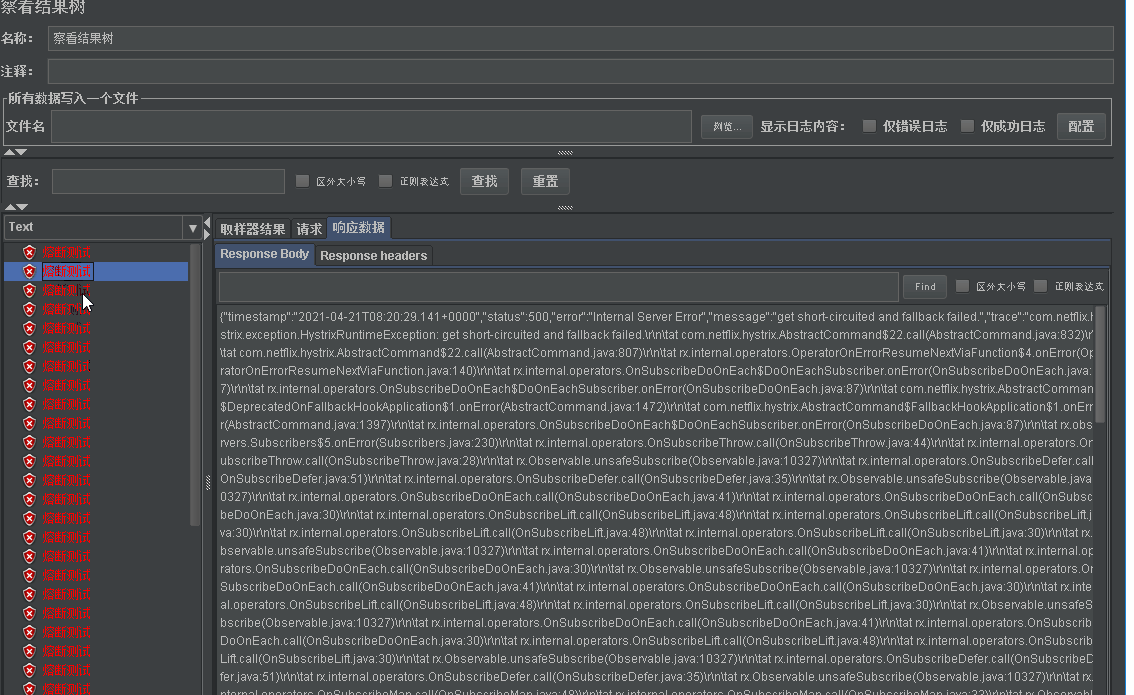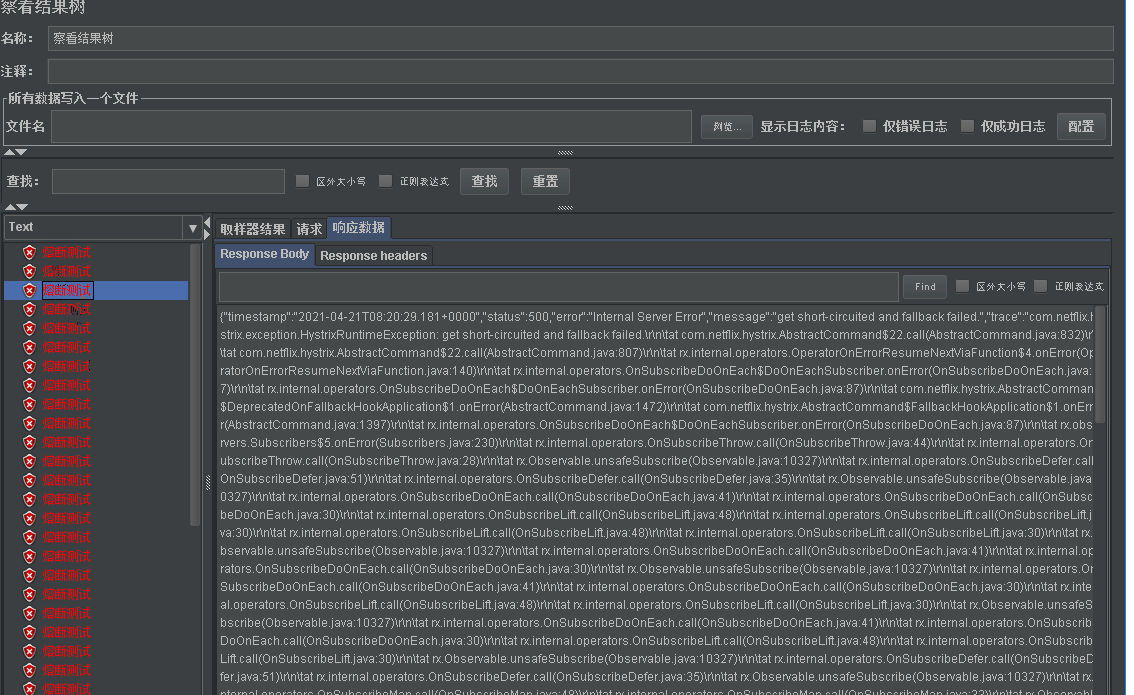
- Normally, we will configure fallback in hystrix. We have implemented the two methods of fallback in the above degradation chapter. Here is to make it easier to see the difference of errors.
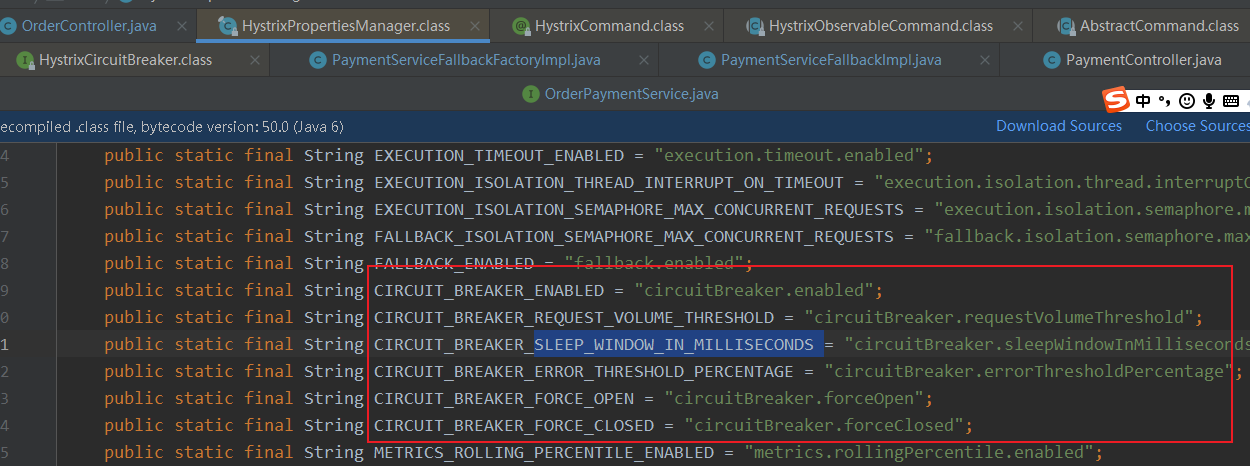
- The parameters configured in the HystrixCommand are basically in the HystrixPropertiesManager object. We can see that there are 6 parameters about the configuration of fuse. It's basically the four configurations above
Service current limiting
- Service degradation: the two isolation methods mentioned above are the strategies to implement flow restriction.
Request merge
- In addition to fusing, degradation and current limiting, hystrix also provides us with request merging. As the name suggests, merging multiple requests into one request has achieved the problem of reducing concurrency.
- For example, we have one order after another to query the order information order/getId?id=1 suddenly 10000 requests came. To ease the pressure, let's focus on the request. Call order / getids every 100 requests? ids=xxxxx . In this way, the final payment module is 10000 / 100 = 100 requests. Next, we implement the request merging through code configuration.
HystrixCollapser
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface HystrixCollapser {
String collapserKey() default "";
String batchMethod();
Scope scope() default Scope.REQUEST;
HystrixProperty[] collapserProperties() default {};
}
| attribute | meaning |
|---|---|
| collapserKey | Unique identification |
| batchMethod | Request merge processing method. That is, the method to be called after merging |
| scope | Scope; Two methods [REQUEST, GLOBAL]; REQUEST: if the condition is met in the same user REQUEST, it will be merged GLOBAL: requests from any thread will be added to this GLOBAL statistics |
| HystrixProperty[] | Configure relevant parameters |

- In Hystrix, all property configurations will be in hystrix properties manager Java. We can find Collapser in it. There are only two related configurations. Represents the maximum number of requests and statistical time unit respectively.
@HystrixCollapser(
scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,
batchMethod = "getIds",
collapserProperties = {
@HystrixProperty(name = HystrixPropertiesManager.MAX_REQUESTS_IN_BATCH , value = "3"),
@HystrixProperty(name = HystrixPropertiesManager.TIMER_DELAY_IN_MILLISECONDS, value = "10")
}
)
@RequestMapping(value = "/getId", method = RequestMethod.GET)
public ResultInfo getId(@RequestParam Long id) {
if (id < 0) {
int i = 1 / 0;
}
log.info(Thread.currentThread().getName());
return null;
}
@HystrixCommand
public List<ResultInfo> getIds(List<Long> ids) {
System.out.println(ids.size()+"@@@@@@@@@");
return orderPaymentService.getIds(ids);
}
- Above, we configured getId to execute getIds request, which is 10S at most. The three requests will be merged together. Then getIds has the payment service to query separately and finally return multiple ResultInfo.
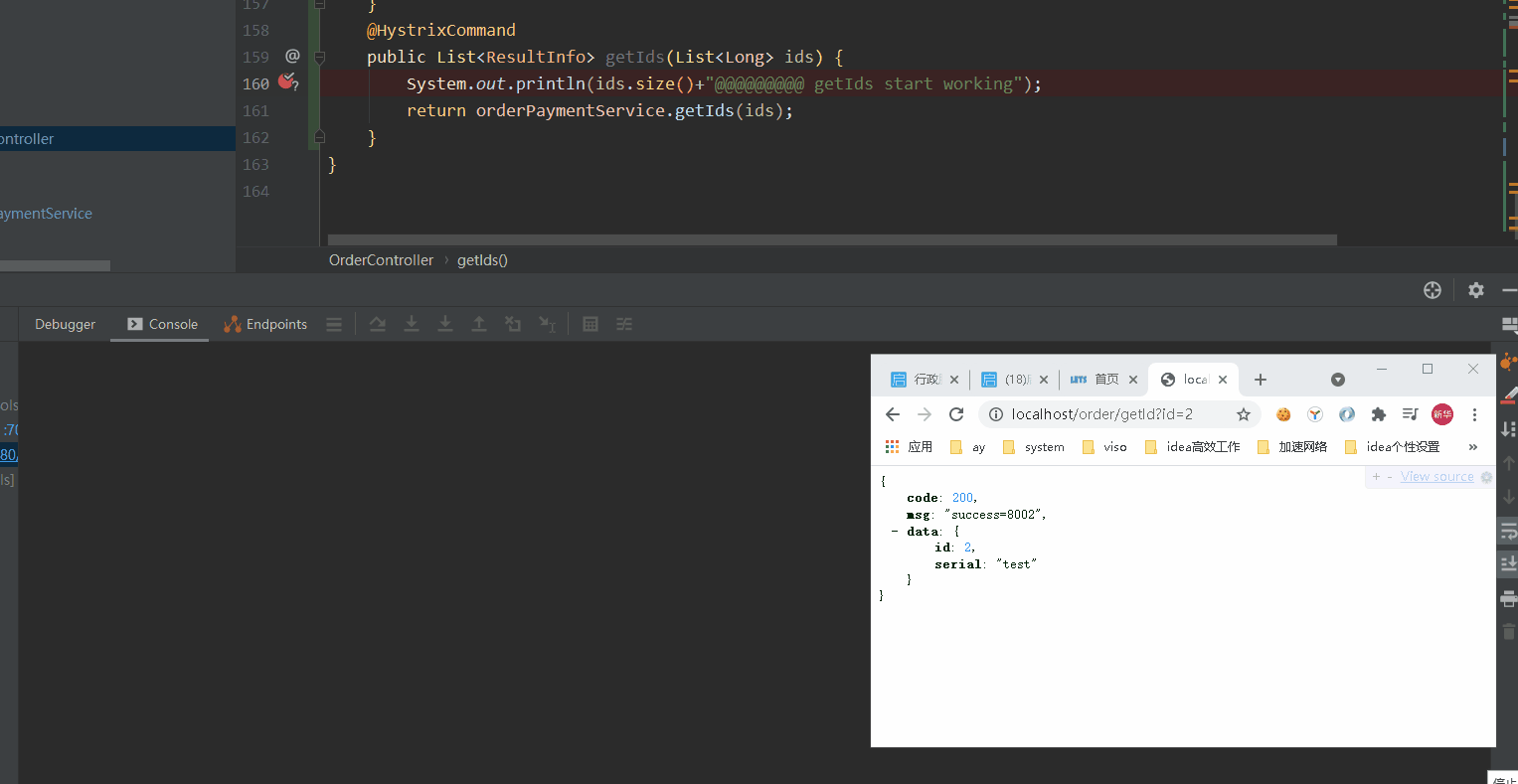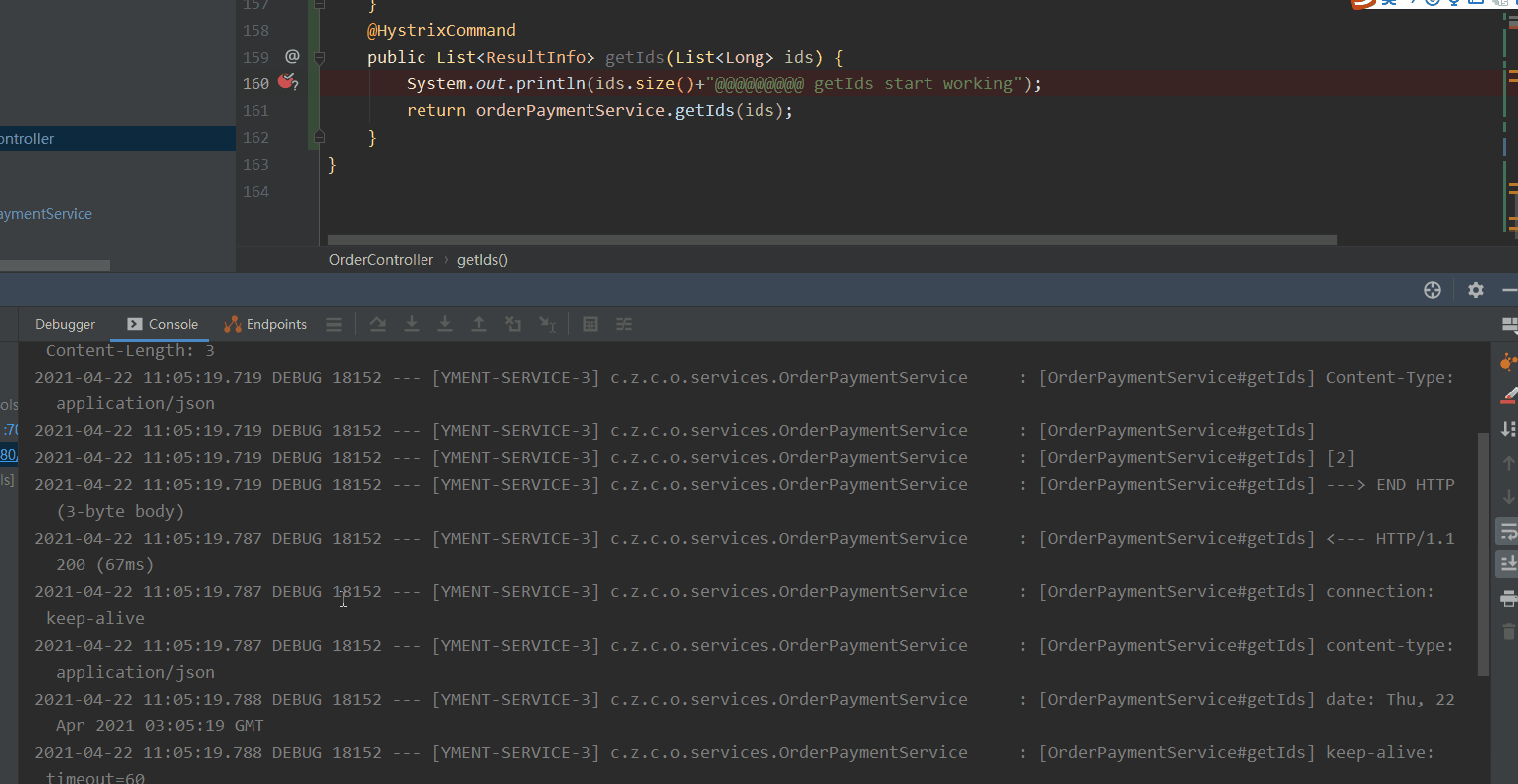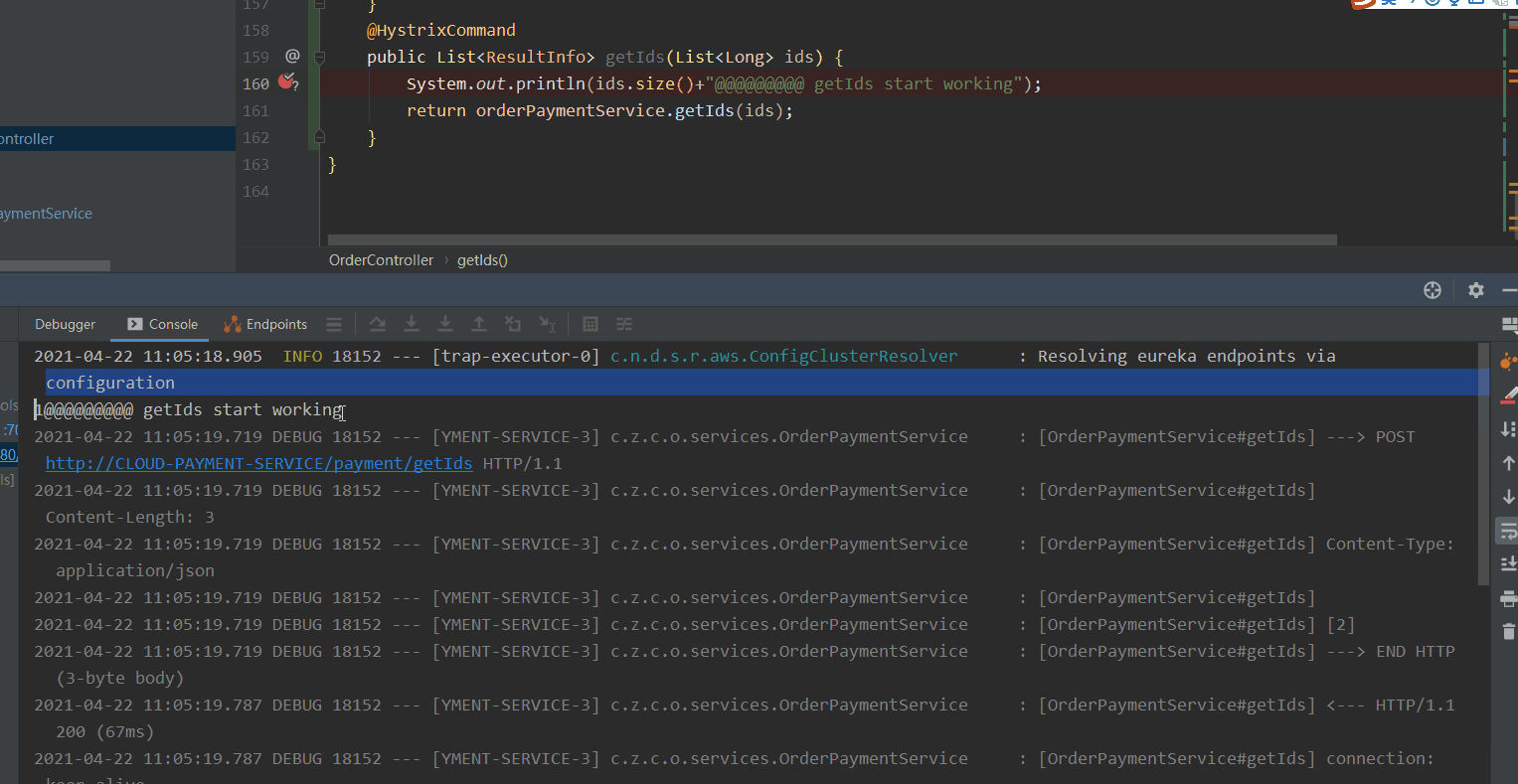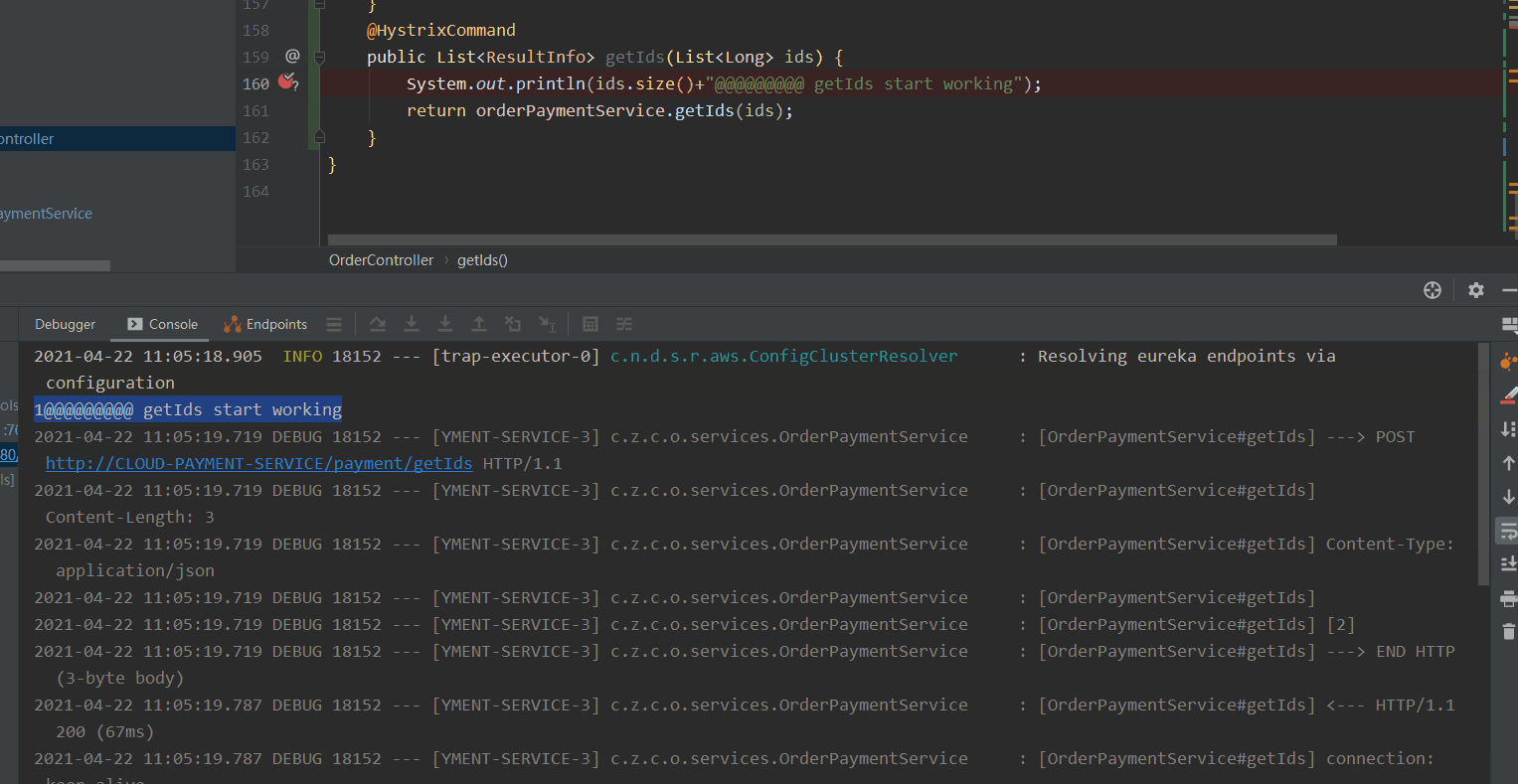
-
We conduct the pressure test of getId interface through jemeter. The maximum length of ids in the log is 3. Verify the configuration of the getId interface above. In this way, it can ensure that interface merging will be carried out in case of high concurrency and reduce TPS.
-
Above, we perform interface merging by requesting method annotations. In fact, the internal hystrix is through the HystrixCommand
Workflow
-
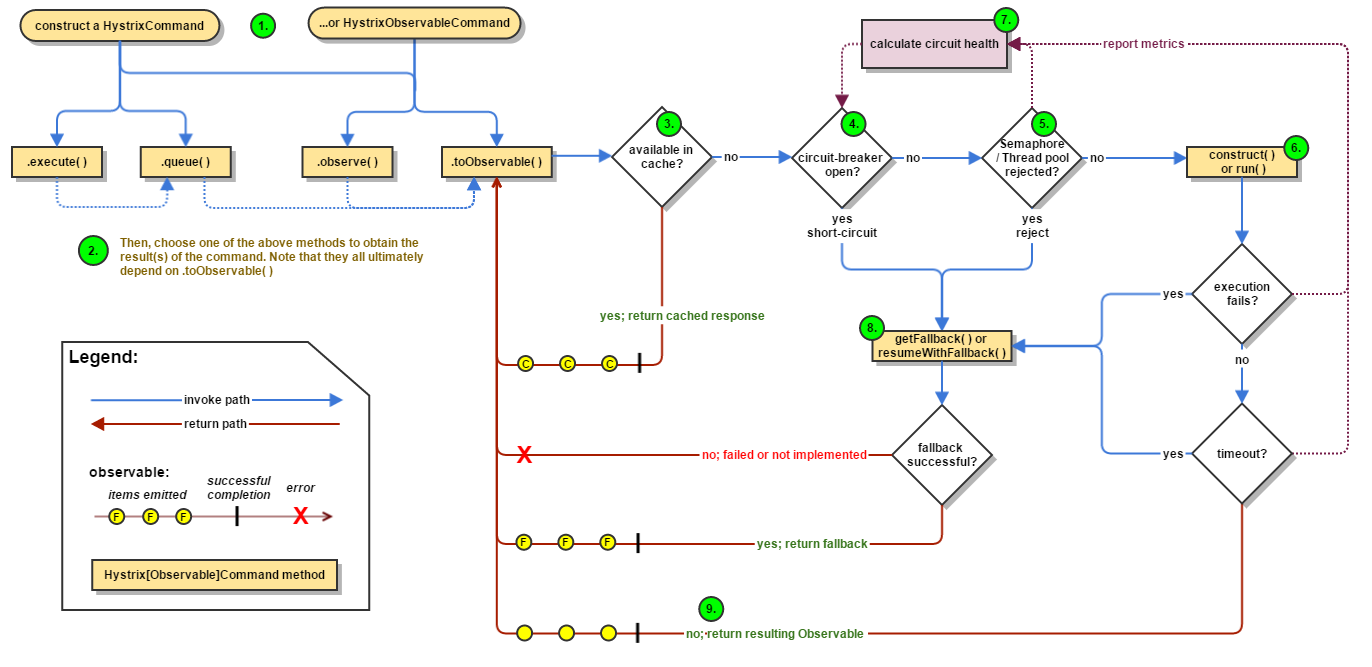
There are 9 process diagrams and process descriptions given on the official website. Now let's translate.
-
① , create a HystrixCommand or hystrixobservercommand object
- HystrixCommand: used for relying on a single service
- HystrixObservableCommand: used for relying on multiple services
-
② . execute the command, and execute and queue the hystrixcommand; The hystrixobservable command executes observe and toObservable
| method | effect |
|---|---|
| execute | Synchronous execution; Return result object or throw exception |
| queue | Asynchronous execution; Return Future object |
| observe | Return Observable object |
| toObservable | Return Observable object |
- ③ . check whether the cache is enabled and whether it hits the cache. If it hits, the cache response is returned
- ④ Whether it is fused. If it is fused, the fallback will be degraded; Release if the fuse is closed
- ⑤ Whether resources are available for, thread pool and semaphore. If there are not enough resources, a fallback occurs. Release if necessary
- ⑥ , execute run or construct methods. These two methods are native to hystrix. Implementing hystrix in java will implement the logic of the two methods, which has been encapsulated by spring cloud. Don't look at these two methods here. If the execution is wrong or timed out, a fallback occurs. During this period, the log will be collected to the monitoring center.
- ⑦ Calculate the fuse data and judge whether it is necessary to try to release; The statistics here will be in hystrix View in the dashboard of stream. It is convenient for us to locate the health status of the interface
- ⑧ In the flow chart, we can also see that ④, ⑤ and ⑥ all point to fallback. It is also commonly known as service degradation. It can be seen that service degradation is a hot business of hystrix.
- ⑨ . return response
HystrixDashboard
-
In addition to service fusing, degradation and current limiting, hystrix also has an important feature of real-time monitoring. And form report statistics interface request information.
-
The installation of hystrix is also very simple. You only need to configure the actor and hystrix dashboard modules in the project
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- Adding EnableHystrixDashboard to the startup class introduces the dashboard. We don't need any development. Like eureka, the master needs a simple package.

-
In this way, the dashboard is built. Dashboard is mainly used to monitor the request processing of hystrix. Therefore, we also need to expose the endpoint in the hystrix request.
-
Add the following configuration to the module using the hystrix command. I'll add it to the order module
@Component
public class HystrixConfig {
@Bean
public ServletRegistrationBean getServlet(){
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
//Note that / hystrix. Is configured here The final access address of stream is localhost: port / hystrix stream ; If the configuration in the configuration file is required in the new version
//Add an actor, that is, localhost: port / actor
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
}
- Then we visit the order module localhost / hystrix The ping interface will appear in the stream. It indicates that our order module is successfully installed and monitored. Of course, order also requires the actor module
- Now let's use jmeter to measure our fusing, degradation and current limiting interfaces. Let's look at each state through the dashboard.

- The animation above looks like our service is still very busy. Think about e-commerce. When you look at the broken line image of each interface, it doesn't seem to be your heartbeat. I'm afraid you're too tall. Too low, there is no high achievement. Let's take a look at the indicator details of dashboard
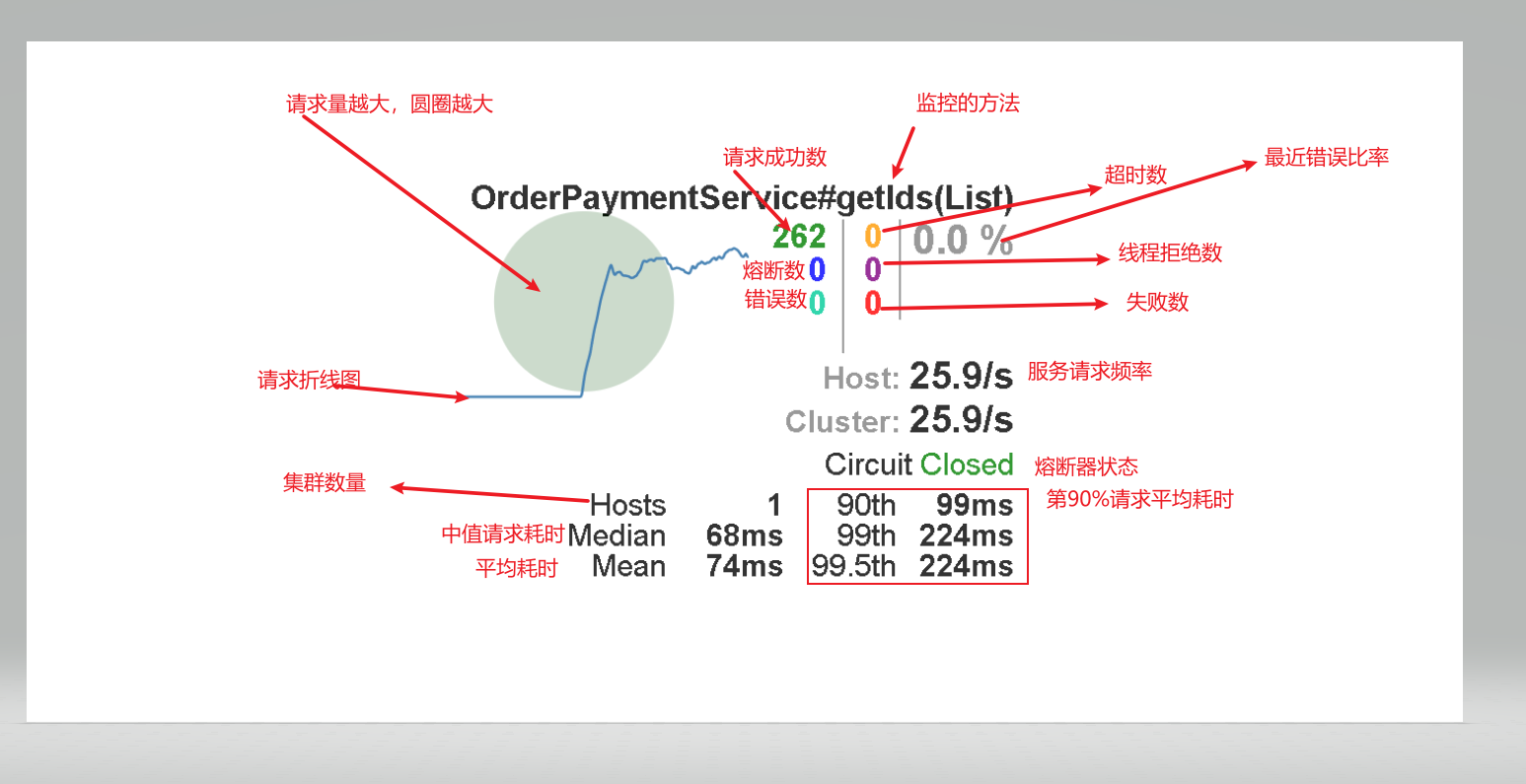
- Let's take a look at the status of each interface during the operation of our service.

Aggregation monitoring
- Above, we monitor our order module through the new module hystrix dashboard. However, in practical application, it is impossible to configure hystrix only in order.
- We just configured it in order for demonstration. Now we also configure it in hystrix in payment. Then we need to switch the monitoring data of order and payment back and forth in the dashboard.
- So here comes our aggregation monitoring. Before aggregate monitoring, we will also introduce payment into hystrix. Note that we injected hystrix. XML in bean mode above Stream. The actor is not required to access the prefix
Create a new hystrix turbine
pom
<!--newly added hystrix dashboard-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
- The main thing is to add turbo coordinates. Others are hystrix, dashboard and other modules. See the source code at the end for details
yml
spring:
application:
name: cloud-hystrix-turbine
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
# Aggregation monitoring
turbine:
app-config: cloud-order-service,cloud-payment-service
cluster-name-expression: "'default'"
# The configuration here is the same as the url. If / Actor / hystrix For stream, you need to configure actor
instanceUrlSuffix: hystrix.stream
Startup class
Add EnableTurbine annotation on startup class
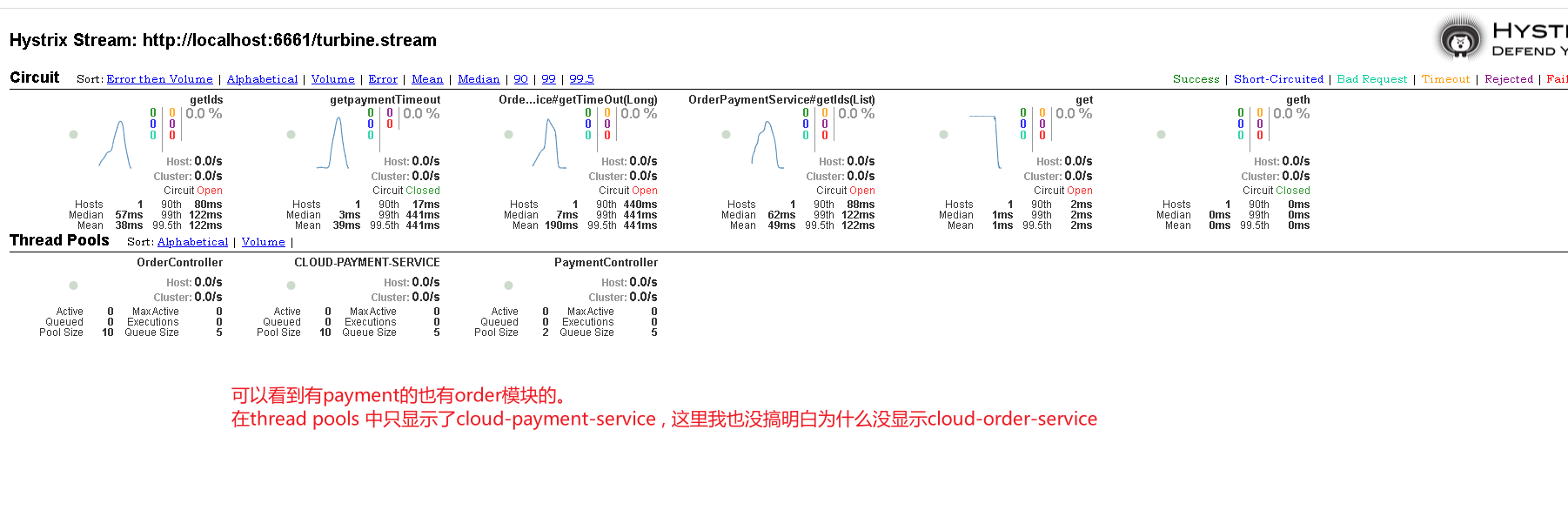
Source code
