Today's sharing begins. Please give us more advice~
Today, let's introduce Java cache and dynamic proxy.
Caching can make the pages that originally open slowly become "second open". Almost all the apps and websites that you usually visit involve the use of caching.
Proxy mode is to provide a proxy for other objects to control access to this object. In some cases, one object is not suitable or cannot directly reference another object, and the proxy object can act as an intermediary between the client and the target object.
This article will share with you how to understand cache and dynamic proxy, as well as their application ideas, hoping to inspire you.
cache
1, Foreword
In addition to accelerating data access, what is the role of caching?
In addition, everything has two sides. How can we give full play to the advantages of caching and avoid its disadvantages?
2, What can cache do?
As mentioned earlier, the most common understanding is that when we encounter a page that opens very slowly, we will think of introducing cache, so that the page opens quickly. In fact, fast and slow are relative. From a technical point of view, the reason why the cache is fast is that the cache is established based on memory, and the reading and writing speed of memory is many times faster than that of hard disk. Therefore, using memory instead of disk as the reading and writing medium can greatly improve the speed of accessing data.
This process is basically like this. The speed-up effect is achieved by storing the accessed data in memory for subsequent access.

In fact, there are two other important ways to use cache: pre read and delayed write.
3, Pre read
Pre reading is to read the data to be loaded in advance, which can also be called "pre storage preheating". It is to load a part of the hard disk into the memory in the system, and then provide external services.

Why do you do this? Because once some systems are started, they will face tens of thousands of requests. If these requests are directly sent to the database, it is very likely that the pressure on the database will soar and they will be directly stolen and unable to respond normally.
In order to alleviate this problem, it needs to be solved by "pre reading".
Maybe you can play, even if you use the cache, can't you carry it? That's the time for horizontal expansion and load balancing. This is not the content discussed in this article. Let's share it again when we have the opportunity.
If "pre read" is to add a pre buffer to the "data exit", then the following "delayed write" is to add a post buffer to the "data entry".
4, Delayed write
You may know that the writing speed of the database is slower than the reading speed, because there are a series of mechanisms to ensure data accuracy when writing. Therefore, if you want to improve the writing speed, you can either divide the database and table, or buffer through the cache, and then write to the disk in batch at one time to improve the speed.
Due to the huge side effects of database and table splitting on cross table operation and multi condition combined query, the complexity of introducing it is greater than that of introducing cache. We should give priority to the scheme of introducing cache.
Then, the process of accelerating "write" through the cache mechanism can be called "delayed write". It is to temporarily write the data to be written to the disk or database to the memory in advance, then return success, and then regularly write the data in the memory to the disk in batches.
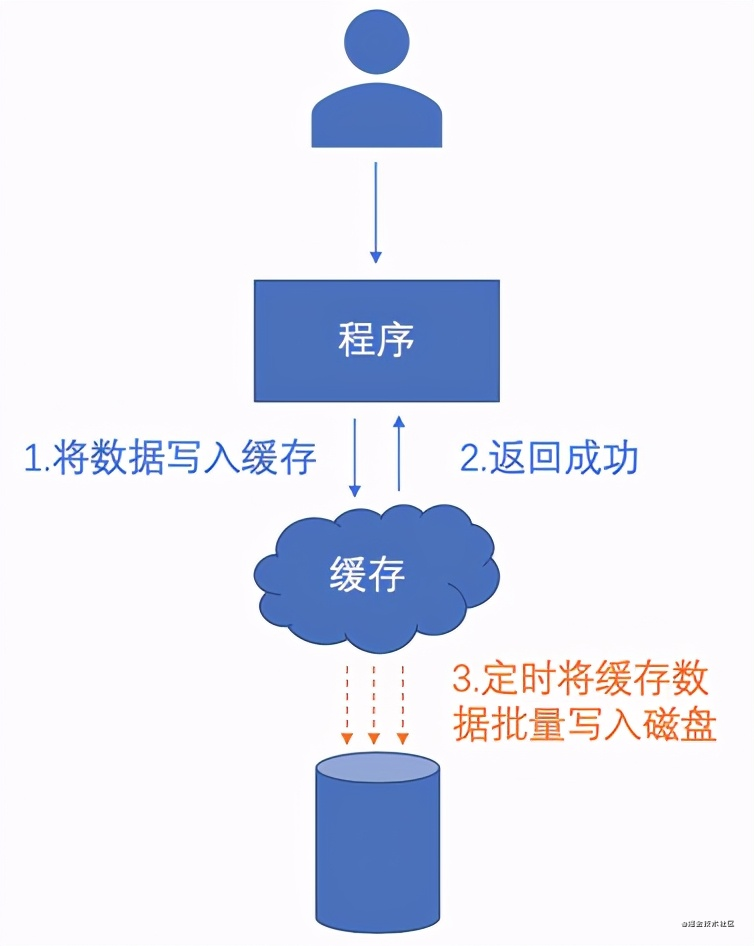
You may think that writing to memory is considered successful. In case of an accident, power failure, shutdown and other conditions leading to abnormal termination of the program, won't the data be lost?
Yes, so "delayed write" is generally only used in scenarios with less stringent requirements on data integrity, such as the number of likes and participating users, which can greatly alleviate the pressure caused by frequent database modifications.
In fact, in the well-known distributed cache Redis, the default persistence mechanism RDB is the same idea.
In a mature system, the cache can be used in different places. Let's sort out where we can add "cache".
5, Where can I add cache?
Before saying where to add cache, let's find out one thing. What do we want to cache? That is, what characteristics of data need to be cached? After all, caching is an additional cost investment, and it's worth it.
Generally speaking, you can measure it by two criteria:
Hot data: accessed by high frequency, such as dozens of times / second or more.
Static data: little change, reading is greater than writing.
Then you can find a suitable place for them to cache.
The essence of caching is a "defensive" mechanism, and the data flow between systems is an orderly process. Therefore, choosing where to add caching is equivalent to choosing where to set up roadblocks on a road. The roads behind this barricade can be protected from traffic.
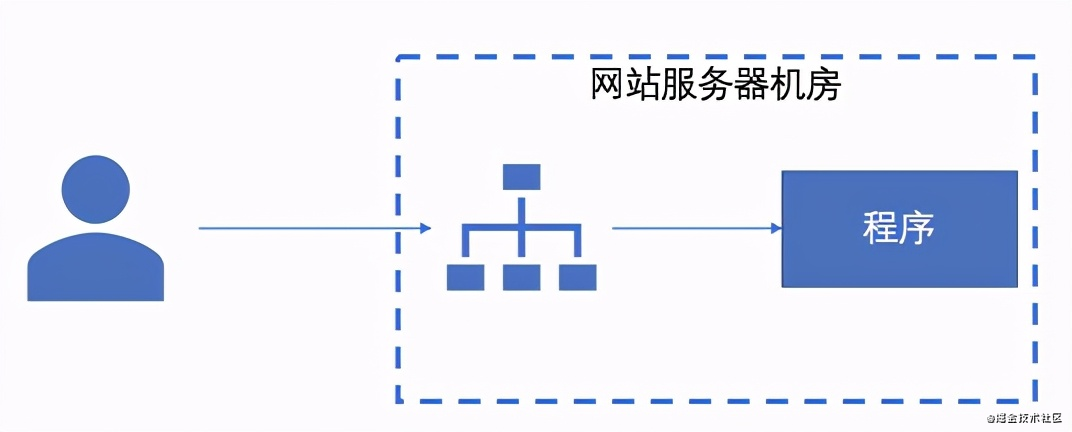
Then, on the road starting from the end user and ending with the database used by the system, the locations that can be used as cache setting points are roughly as follows:

Each set-up point can block some traffic and finally form a funnel-shaped interception effect, so as to protect the last system and the final database.

The following is a brief description of each application scenario and points needing attention.
6, Cache category
1. Browser cache
This is the place nearest to the user that can be used as a cache, and with the help of the user's "resources" (the cached data is on the user's terminal device), the cost performance is the best, so that the user can help you share the pressure.
When you open the developer tool of the browser and see from cache, from memory cache and from disk cache, it means that these data have been cached on the user's terminal device, and some contents can be accessed when there is no Internet. That's why.
This process is completed by the browser for us. It is generally used to cache resources such as pictures, js and css. We can control it through cache control in Http message header. The specific details will not be expanded here. In addition, the use of global variables and cookie s in js also belongs to this category.
The browser cache is a cache point on the user side, so we have poor control over it. You can't take the initiative to update the data without initiating a new request.
2. CDN cache
Service providers providing CDN services deploy a large number of server nodes (which can be called "edge servers") across the country and even around the world. Then, distributing the data to these servers all over the country as a cache and allowing users to access the cached data on the nearest server can play the effect of pressure sharing and acceleration. This is particularly effective when applied to TOC type systems.
However, it should be noted that due to the large number of nodes, updating cache data is relatively slow, generally at least at the minute level, so it is generally only applicable to static data that does not change frequently.
There are also solutions, that is, the url is followed by a self increasing number or a unique identifier, such as? v=1001. Because different URLs will be regarded as "new" data and files and re create d.
3. Gateway (proxy) cache
Many times, we add a layer of gateway in front of the source station to make some security mechanisms or serve as the entrance of a unified diversion strategy.
At the same time, it is also a good place for caching. After all, the gateway is "business independent". It can stop requests, which also benefits the source station behind it and reduces a lot of CPU operations.
The commonly used gateway caches are Varnish, Squid and Ngnix. In general, for simple cache application scenarios, we can use Ngnix, because most of the time we will use it for load balancing. If we can introduce less technology, it will reduce the complexity. For a large number of small files, Varnish can be used, while Squid is relatively large and complete, and the application cost is higher.
4. In process cache
Perhaps this is the first time that most of us programmers deliberately use caching.
If a request can come here, it means that it is "business related" and needs to be calculated by business logic.
Because of this, the cost of introducing cache from here is much higher than that of the previous three, because there are higher requirements for "data consistency" between cache and database.
5. Out of process cache
You are also familiar with Redis and Memcached. You can even write a separate program to store cached data for other programs to call remotely.
Here's a few more thoughts on how to choose Redis and Memcached.
If you pay special attention to the utilization of resources (CPU, memory, etc.), you can use memcached, but the program needs to tolerate possible data loss when using it, because of the pure memory mechanism. If you can't tolerate this order and are bold in resource utilization, you can use Redis. Moreover, Redis has more database structures. Memcached has only key value, which is more like a NoSQL storage.
6. Database cache
The database itself has its own cache module, otherwise it won't be called a memory killer. Basically, it can eat as much memory as you give it. Database cache is the internal mechanism of the database. Generally, the configuration of setting the cache space size will be given for you to intervene.
Finally, the disk itself has a cache. So you will find that it is really twists and turns to make the data write to the physical disk smoothly.
7, Is the cache a silver bullet?
Maybe you want the cache to be so good, so the more the better. As long as it's slow, go to the cache to solve it?
No matter how good a thing looks, it also has its negative side. Caching also has a series of side effects to consider. In addition to the aforementioned issues of "cache update" and "consistency between cache and data", there are also issues such as the following:
1. Cache avalanche
When a large number of requests enter concurrently, due to some reasons, it does not play the expected buffering effect, even if it is only a short period of time, resulting in all requests transferred to the database, resulting in excessive pressure on the database. It can be solved by "locking queue" or "increasing random value of cache time".
2. Cache penetration
Similar to the cache avalanche, the difference is that it will last longer, because it is still unable to load data from the data source to the cache after each "cache miss", resulting in continuous "cache miss". It can be solved by "Bloom filter" or "cache empty objects".
3. Cache concurrency
The data under a cache key is set at the same time. How to ensure the accuracy of the business? Plus the database? What about in-process cache, out of process cache and database? In one sentence, the proposed scheme is to use the method of "DB first and then cache", and the cache operation is delete instead of set.
4. Cache bottomless hole
Although the distributed cache can be expanded infinitely horizontally, is it true that the more nodes in the cluster, the better? Of course not. Caching also conforms to the law of "diminishing marginal utility".
5. Cache obsolescence
Memory is always limited. If there is a large amount of data, it is essential to customize reasonable elimination strategies according to specific scenarios, such as LRU, LFU and FIFO.
Java Dynamic Proxy
1, Agent mode
A famous example of proxy mode is the reference counting pointer object.
When multiple copies of a complex object must exist, the agent mode can be combined with the sharing mode to reduce the memory consumption. A typical approach is to create a complex object and multiple agents, and each agent will refer to the original complex object. The operation acting on the agent will be transferred to the original object. Once all agents do not exist, complex objects are removed.
2, Composition
- Abstract role: declare the business method implemented by the real role through the interface or abstract class.
- Agent role: the abstract role is the agent of the real role. The abstract method is realized through the business logic method of the real role, and its own operation can be attached.
- Real role: realize the abstract role and define the business logic to be realized by the real role for the agent role to call.
3, Advantages
1. Clear responsibilities
The real role is to realize the actual business logic. You don't need to care about other transactions that are not your responsibility. You can complete one transaction through the later agent. The incidental result is that the programming is concise and clear.
2. Protected object
The proxy object can play the role of intermediary between the client and the target object, which plays the role of intermediary and protects the target object.
3. High scalability
4, Pattern structure
One is the real object you want to access (target class), and the other is the proxy object. The real object and proxy
Object implements the same interface. First access the proxy class, and then access the object to be accessed.
Agent mode is divided into static agent and dynamic agent.
Static proxy is created by programmers or tools to generate the source code of proxy class, and then compile the proxy class. The so-called static means that the bytecode file of the agent class already exists before the program runs, and the relationship between the agent class and the delegate class is determined before the program runs.
Dynamic agent does not care about the agent class in the implementation stage, but specifies which object in the run stage.
5, Static proxy
Create an interface, and then create the proxy class to implement the interface and implement the abstract methods in the interface. Then create a proxy class and make it also implement this interface. In the proxy class, a reference to the proxy is held, then the method of the object is called in the proxy class method.
Using static proxy, it is easy to complete the proxy operation of a class. However, the disadvantages of static agent are also exposed: because the agent can only serve one class, if there are many classes that need to be represented, a large number of agent classes need to be written, which is cumbersome.
6, Dynamic agent
1. Dynamic agent flow chart
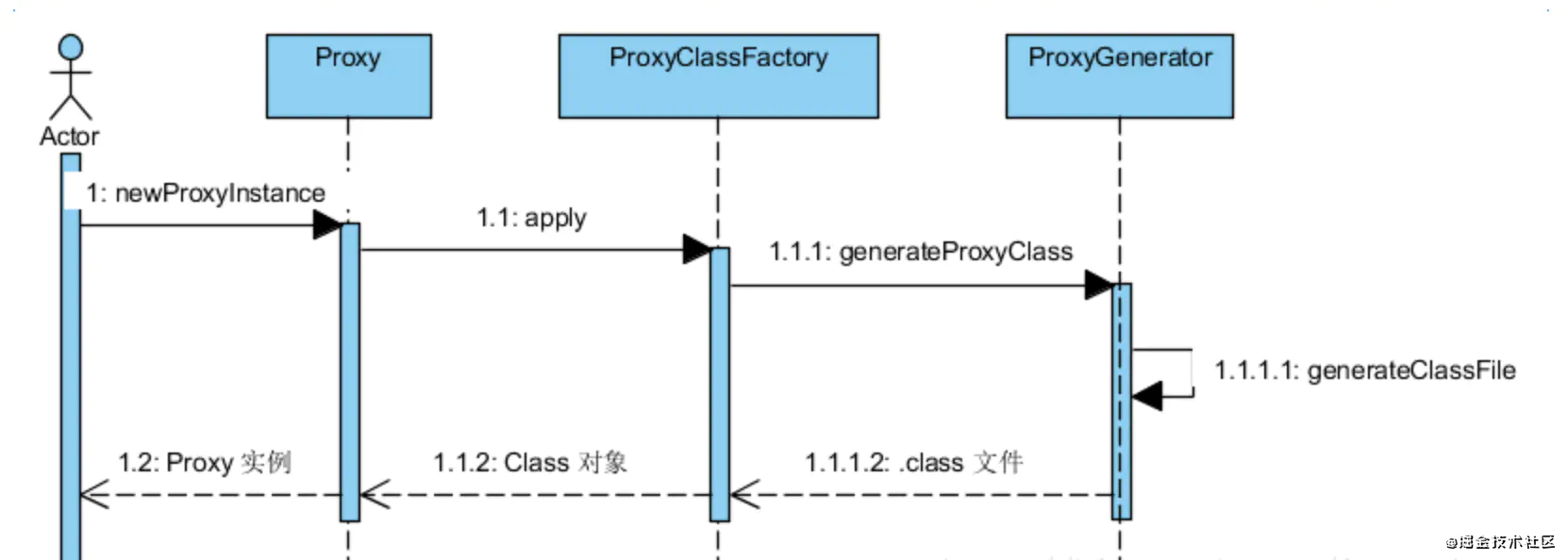
2. Dynamic proxy code implementation
(1) Agent class
Create proxy classes at run time using reflection mechanisms. The interface and the proxy class remain unchanged. We build a ProxyInvocationHandler class to implement the InvocationHandler interface.
package com.guor.aop.dynamicproxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class ProxyInvocationHandler implements InvocationHandler {
private Object target;
public Object getTarget() {
return target;
}
public void setTarget(Object target) {
this.target = target;
}
//Generated proxy class
public Object getProxy() {
return Proxy.newProxyInstance(this.getClass().getClassLoader(), target.getClass().getInterfaces(),this);
}
//Process the proxy instance and return the result
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
log(method.getName());
//The essence of dynamic agent is to use reflection mechanism
Object result = method.invoke(target, args);
return result;
}
public void log(String msg) {
System.out.println("Yes"+msg+"method");
}
}
Return the Proxy instance of an interface through the static method newProxyInstance of the Proxy class. For different agent classes, pass in the corresponding agent controller InvocationHandler.
(2) Proxy class UserService


(3) Execute dynamic proxy

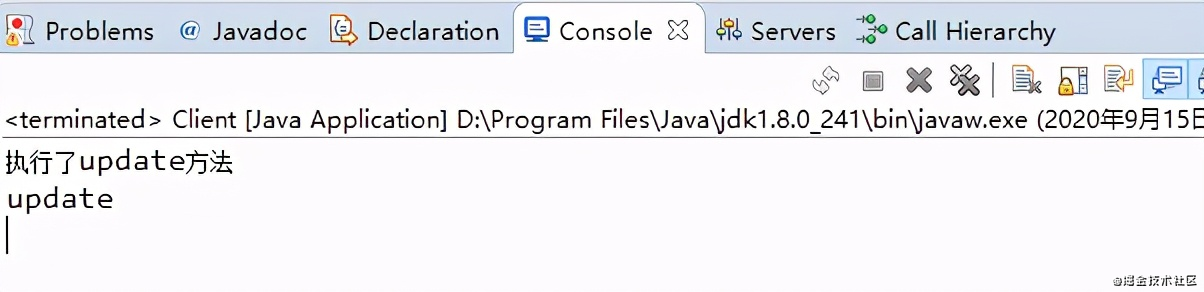
(4) Console output
7, Underlying implementation of dynamic agent
1. Specific steps of dynamic agent
Create your own calling processor by implementing the InvocationHandler interface;
Create a dynamic Proxy class by specifying a ClassLoader object and a set of interface s for the Proxy class;
The constructor of the dynamic proxy class is obtained through the reflection mechanism, and its only parameter type is the calling processor interface type;
The dynamic proxy class instance is created through the constructor, and the calling processor object is passed in as a parameter during construction.
2. Source code analysis
(1)newProxyInstance
Since the Proxy object is generated using the static newProxyInstance of the Proxy class, let's go to its source code to see what it has done?


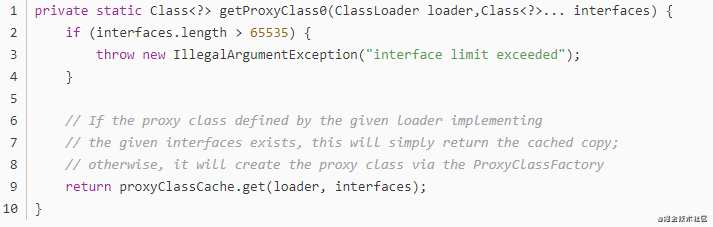
(2)getProxyClass0
Use getProxyClass0(loader, intfs) to generate the Class object of Proxy Class Proxy.
(3)ProxyClassFactory
ProxyClassFactory internal class creates and defines proxy class, and returns proxy class of given ClassLoader and interfaces.
private static final class ProxyClassFactory implements BiFunction<ClassLoader, Class<?>[], Class<?>>
{
// prefix for all proxy class names
private static final String proxyClassNamePrefix = "$Proxy";
// next number to use for generation of unique proxy class names
private static final AtomicLong nextUniqueNumber = new AtomicLong();
@Override
public Class<?> apply(ClassLoader loader, Class<?>[] interfaces) {
Map<Class<?>, Boolean> interfaceSet = new IdentityHashMap<>(interfaces.length);
for (Class<?> intf : interfaces) {
/*
* Verify that the class loader resolves the name of this
* interface to the same Class object.
*/
Class<?> interfaceClass = null;
try {
interfaceClass = Class.forName(intf.getName(), false, loader);
} catch (ClassNotFoundException e) {
}
if (interfaceClass != intf) {
throw new IllegalArgumentException(
intf + " is not visible from class loader");
}
/*
* Verify that the Class object actually represents an
* interface.
*/
if (!interfaceClass.isInterface()) {
throw new IllegalArgumentException(
interfaceClass.getName() + " is not an interface");
}
/*
* Verify that this interface is not a duplicate.
*/
if (interfaceSet.put(interfaceClass, Boolean.TRUE) != null) {
throw new IllegalArgumentException(
"repeated interface: " + interfaceClass.getName());
}
}
String proxyPkg = null; // package to define proxy class in
int accessFlags = Modifier.PUBLIC | Modifier.FINAL;
/*
* Record the package of a non-public proxy interface so that the
* proxy class will be defined in the same package. Verify that
* all non-public proxy interfaces are in the same package.
*/
for (Class<?> intf : interfaces) {
int flags = intf.getModifiers();
if (!Modifier.isPublic(flags)) {
accessFlags = Modifier.FINAL;
String name = intf.getName();
int n = name.lastIndexOf('.');
String pkg = ((n == -1) ? "" : name.substring(0, n + 1));
if (proxyPkg == null) {
proxyPkg = pkg;
} else if (!pkg.equals(proxyPkg)) {
throw new IllegalArgumentException(
"non-public interfaces from different packages");
}
}
}
if (proxyPkg == null) {
// if no non-public proxy interfaces, use com.sun.proxy package
proxyPkg = ReflectUtil.PROXY_PACKAGE + ".";
}
/*
* Choose a name for the proxy class to generate.
*/
long num = nextUniqueNumber.getAndIncrement();
String proxyName = proxyPkg + proxyClassNamePrefix + num;
/*
* Generate the specified proxy class.
*/
byte[] proxyClassFile = ProxyGenerator.generateProxyClass(
proxyName, interfaces, accessFlags);
try {
return defineClass0(loader, proxyName,
proxyClassFile, 0, proxyClassFile.length);
} catch (ClassFormatError e) {
/*
* A ClassFormatError here means that (barring bugs in the
* proxy class generation code) there was some other
* invalid aspect of the arguments supplied to the proxy
* class creation (such as virtual machine limitations
* exceeded).
*/
throw new IllegalArgumentException(e.toString());
}
}
}
(4)generateProxyClass
After a series of checks, call ProxyGenerator.. Generateproxyclass to generate bytecode files.


(5)generateClassFile
generateClassFile method for generating proxy class bytecode file:






After the bytecode is generated, defineClass0 is used to parse the bytecode and generate the Class object of Proxy. After the generation of the agent class, understand who will execute the agent class dynamically.
Where, in proxygenerator saveGeneratedFiles in the generateproxyclass function is defined as follows. It refers to whether to save the generated proxy class file. By default, false is not saved.
In the previous example, we modified this system variable:
System.getProperties().setProperty("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
Summary:
This paper introduces three ideas of using cache, then combs several locations where cache can be set up in a complete system, and shares some practical experience about cache such as browser, CDN and gateway (proxy). There is no specific details, but we hope to have a more systematic understanding of cache and hope to make us more comprehensive.
Today's sharing is over, please forgive and give advice!
See the little partner here, give me a button three times!!!