background
In the development process of using fluent in depth, we encountered serious business code coupling and poor code maintainability, such as mud. We need a unified application framework to get rid of the current development dilemma, which is also a virgin land vacant in the field of fluent.
Fish Redux is an upper application framework to solve the above problems. It is an assembled fluent application framework based on Redux data management, which is especially suitable for building medium and large-scale complex applications.
Its biggest feature is configuration assembly. On the one hand, a large page is disassembled into mutually independent Component|Adapter layer by layer for View and data. The upper layer is responsible for assembly and the lower layer is responsible for implementation. On the other hand, the Component|Adapter is divided into mutually independent context free functions such as View, Reducer and Effect. So it will be very clean, easy to write, easy to maintain and easy to cooperate.
The inspiration of Fish Redux mainly comes from excellent frameworks such as Redux, React, Elm and Dva. Standing on the shoulders of giants, Fish Redux will further concentrate, divide, treat, reuse and isolate.
1. MVVM architecture pattern overview
This is to use the MVVM architecture mode + Kotlin collaboration + JetPack(ViewModel+LiveData)+Retrofit architecture to realize the small DEMO of WanAndroid login interface, and the WanAndroid client will be gradually improved in the future
1,ViewModel
In order to separate the View data ownership from the Activity/Fragment logic of the interface controller, the architecture component provides the ViewModel helper class for the interface controller, which is responsible for preparing data for the interface. ViewModel objects are automatically retained during configuration changes so that the data they store is immediately available to the next Activity or Fragment instance.
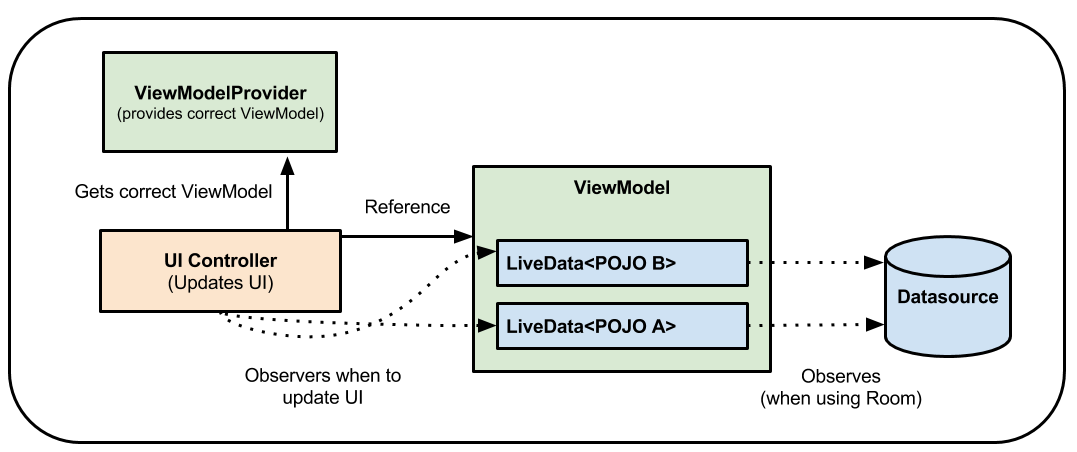
2,LiveData
LiveData is an observable data storage class with life cycle awareness, which means that it follows the life cycle of other application components, such as Activity, Fragment or Service, to ensure that LiveData only updates the application component observers in the active life cycle state. LiveData objects are usually stored in ViewModel objects and can be accessed through getter methods.
3. Kotlin synergy
Coprocessing is attached to threads, which can realize sequential writing of asynchronous code and automatic thread switching. Each ViewModel in the viewscope is defined and applied to the ViewModel. If the ViewModel has been cleared, the collaborations started within this range will be automatically cancelled.
4,Retrofit
Declare the network request function in the service interface as suspend suspend interface function to support Kotlin thread, and transfer the result of suspend function as LiveData object.
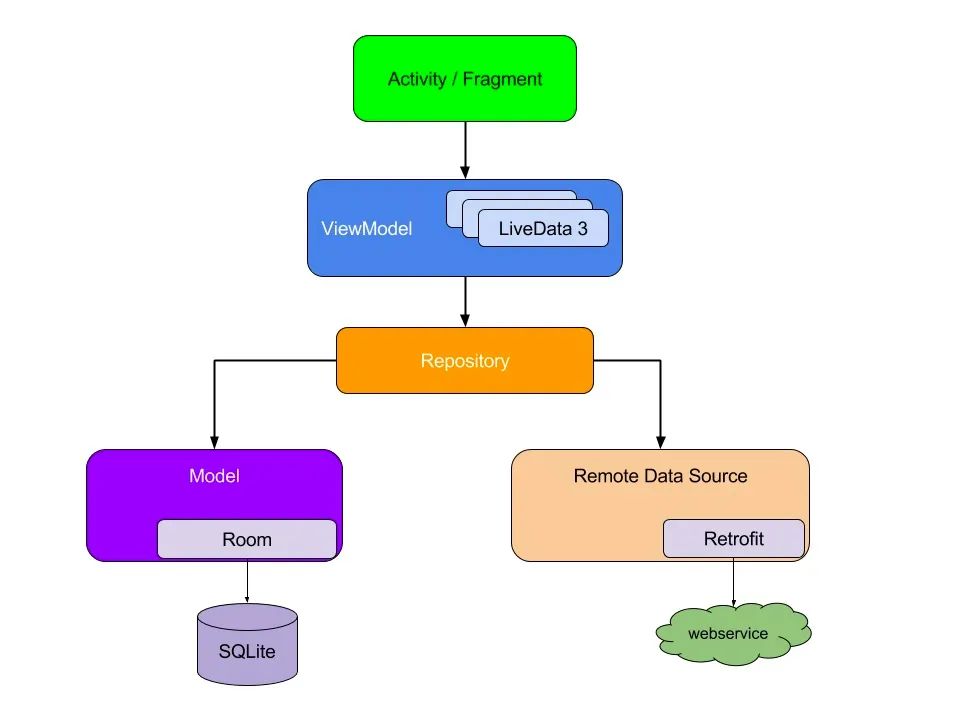
2,ViewModel
//Get ViewModel viewModel = ViewModelProvider(this).get(MainViewModel::class.java)`
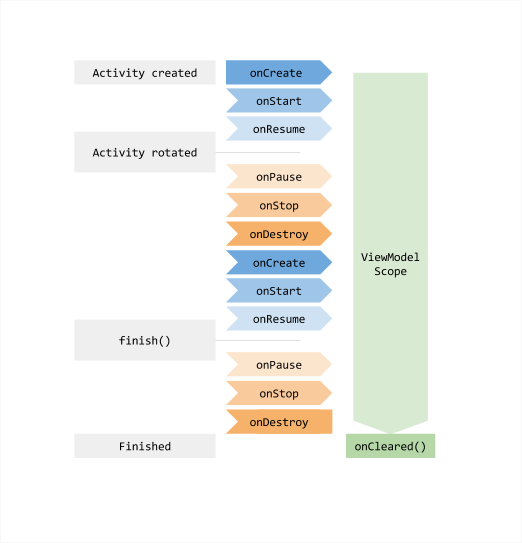
The time range in which the ViewModel object exists is the Lifecycle passed to the ViewModelProvider when the ViewModel is obtained. The ViewModel will remain in memory until the Lifecycle that defines its existence time range disappears permanently: for an Activity, when the Activity is completed; For fragments, it is when the fragments are separated.
3,LiveData
//Observe the User data
viewModel.user.observe(this, Observer {
//Show login results
if (it.errorCode == 0) {
Toast.makeText(this, it.data?.nickname, Toast.LENGTH_SHORT).show()
} else {
Toast.makeText(this, it.errorMsg, Toast.LENGTH_SHORT).show()
}
})
Using LiveData has the following advantages: ensure that the interface conforms to the data state
LiveData Follow the observer mode. When the lifecycle state changes, LiveData Will inform Observer Object. You can integrate code to Observer Object to update the interface. Instead of updating the interface every time the application data changes, observers can update the interface every time changes occur.
No memory leaks
The observer is bound to Lifecycle Object and clean itself up after its associated lifecycle is destroyed.
No crash due to Activity stop
If the life cycle of the observer is inactive (e.g. returning to the stack) Activity),Then it will not receive any LiveData event. You no longer need to manually process the lifecycle The interface component only observes relevant data and will not stop or resume observation. LiveData All of these operations will be managed automatically because it can perceive the relevant lifecycle state changes when observing.
Data is always up-to-date
If the lifecycle becomes inactive, it receives the latest data when it becomes active again. For example, once in the background Activity It will receive the latest data immediately after returning to the foreground.
Appropriate configuration changes
If it is recreated due to configuration changes, such as device rotation Activity or Fragment,It will immediately receive the latest available data.
shared resource
You can extend using single instance mode LiveData Object to encapsulate system services so that they can be shared in applications.
4. Kotlin synergy
4.1. Asynchronous nature
What is asynchronous?
Asynchronous is to perform more than one task with different purposes at the same time.
But how to deal with asynchronous tasks with pre and post dependencies?
Using the callback mechanism in asynchronous processing.
Why do you need an asynchronous callback mechanism?
Because there are pre and post dependencies between different tasks.
What are the disadvantages of asynchronous callback mechanism?
The code structure is over coupled. In case of nested coupling of multiple function callbacks, that is, callback hell, the code will be difficult to maintain.
What are the solutions?
Chain call structure. The common way is to use RxJava,It is reactive functional programming in Java Implementation in. however RxJava The creation, transformation and consumption of midstream need to use various classes and rich operators, which increases the RxJava Learning costs. Reduce use without packaging RxJava,Because you can't guarantee that every member of the team can understand it and make the right choice when revising it.
In serial execution, although the code is indeed executed sequentially, it is actually executed sequentially on different threads. So why use callbacks when the code is executed in the same order in serial execution?
Because in the serial execution, the execution is blocking, and the blocking of the main thread will lead to serious problems, all time-consuming operations cannot be executed in the main thread, so multi threads are required to execute in parallel.
In parallel execution, asynchronous callback is actually multi-threaded sequential execution of code. Can we not only write the code in a sequential way, but also let the code execute in different thread sequences to automatically complete the thread switching?
That's it Kotlin Synergetic process. Kotlin The co process of is an implementation of stack free co process. Its control flow depends on the state flow of the state machine compiled by the co process body itself, and variable saving is also realized through closure syntax.
Conclusion:
Asynchronous callback is the multi-threaded sequential execution of code, and Kotlin Coprocessing can write asynchronous code in sequence and automatically switch threads.
So what is the principle of automatic thread switching?
Yield: Give up CPU,Give up scheduling control and go back to the previous time Resume Place Resume: Obtain scheduling control and continue to execute the program until the last time Yield Place
example:
1. GlobalScope.launch Launched a collaborative process and IO Executed on a thread, 2\. In the process, call the interface to get the result. 3. Get the result and use it withContext(Dispatchers.Main)Switch to the main thread and update the interface
4.2 type of cooperation process
It refers to the scope of the cooperation process, which refers to the time cycle range of the code running in the cooperation process. If it exceeds the specified scope of the cooperation process, the execution of the cooperation process will be cancelled.
GlobalScope
It refers to the same scope of the collaboration process as the application process, that is, the code in the collaboration process can run before the process ends.
Life cycle aware collaboration scope provided in JetPack:
ViewModelScope,For each in the application ViewModel Defined ViewModelScope. If ViewModel If it has been cleared, the collaboration started within this range will be automatically cancelled. LifecycleScope,For each Lifecycle Object defined LifecycleScope. The coordination process started within this range will be Lifecycle Cancel when destroyed. use LiveData You may need to calculate values asynchronously. have access to liveData Builder function call suspend Function and take the result as LiveData Object transfer.
Related links: https://developer.android.google.cn/topic/libraries/architecture/coroutines
4.3 startup of coordination process
launch method:
/**
* Important knowledge: ViewModel + collaboration
*/
fun ViewModel.launch(
block: suspend CoroutineScope.() -> Unit,
onError: (e: Throwable) -> Unit = {},
onComplete: () -> Unit = {}
) {
viewModelScope.launch(CoroutineExceptionHandler { _, e -> onError(e) }) {
try {
block.invoke(this)
} finally {
onComplete()
}
}
}
Source code:
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
4.3.1 explanation of launch method
context
In the context of a collaboration, you can specify the thread on which the collaboration runs. Default and specified CoroutineScope Medium coroutineContext Consistent, for example GlobalScope By default, it runs in a background worker thread. You can also change the running thread of the coroutine by displaying the specified parameters, Dispatchers Several values are provided to specify: Dispatchers.Default,Dispatchers.Main,Dispatchers.IO,Dispatchers.Unconfined.
start
Startup mode of collaborative process. default CoroutineStart.DEFAULT It means that the coordination process is executed immediately. In addition, there are CoroutineStart.LAZY,CoroutineStart.ATOMIC,CoroutineStart.UNDISPATCHED.
block
Collaborative process subject. That is, the code to be run inside the collaboration can be lamda The way of expression is convenient to write the code running in the collaborative process.
CoroutineExceptionHandler
appoint CoroutineExceptionHandler To handle exceptions within the process.
Job
Return value, a reference to the currently created collaboration. Can pass Job of start,cancel,join And other methods to control the startup and cancellation of the cooperation process.
4.4 suspend function
The suspend keyword only serves as a flag. This function is a time-consuming operation and must be executed in the coroutine, while the withContext method switches threads.
The code in the collaboration process automatically switches to other threads, and then automatically switches back to the main thread! Sequential programming ensures the intuitiveness of logic, and the automatic thread switching of coroutine ensures the non blocking of code. The suspended function must be called in the coroutine or other suspended functions, that is, the suspended function must be executed directly or indirectly in the coroutine.
Then why is the code in the collaboration not executed in the main thread? And why does it automatically switch back to the main thread after execution?
The suspension of a collaboration process can be understood as the process in which the code in the collaboration process leaves the thread in which the collaboration process is located, and the recovery of the collaboration process can be understood as the process in which the code in the collaboration process re enters the thread in which the collaboration process is located. The coroutine switches threads through the suspend recovery mechanism.
4.5 async await method
The suspend method is wrapped with async method to execute the concurrent request. After the concurrent results are returned, switch to the main thread, and then use await method to obtain the concurrent request results.
5,Retrofit
HTTP interface suspend suspend function:
interface ApiService {
@FormUrlEncoded
@POST("user/login")
suspend fun loginForm(@Field("username") username: String,@Field("password") password: String): BaseResponse<User>
}
kotlin generics:
data class BaseResponse<T>( val errorCode: Int=0, val errorMsg:String? = null, var data: T? = null )
This is to use the MVVM architecture mode + Kotlin collaboration + JetPack(ViewModel+LiveData)+Retrofit architecture to realize the small DEMO of WanAndroid login interface, and the WanAndroid client will be gradually improved in the future
How to do interview raids and plan the learning direction?
The interview question set can help you find out omissions and fill vacancies, study in a directional and targeted way, and prepare for entering a large factory later. But if you just watch it once without learning and delving into it. Then this interview question will be of limited help to you. Finally, it depends on the senior technical level.
There are a lot of materials for learning Android online, but if the knowledge learned is not systematic, only a superficial taste when encountering problems and no further research, it is difficult to achieve real technology improvement. It is suggested to make a learning plan first, and connect the knowledge points according to the learning plan to form a systematic knowledge system.
The learning direction is easy to plan, but if you only study through fragmentation, your improvement is very slow.
At the same time, I also collected and sorted out the interview questions of byte beat in 2020 and Tencent, Alibaba, Huawei, Xiaomi and other companies, and sorted out the interview requirements and technical points into a large and comprehensive "Android architect" interview Xmind (actually spent a lot more energy than expected), including knowledge context + branch details.
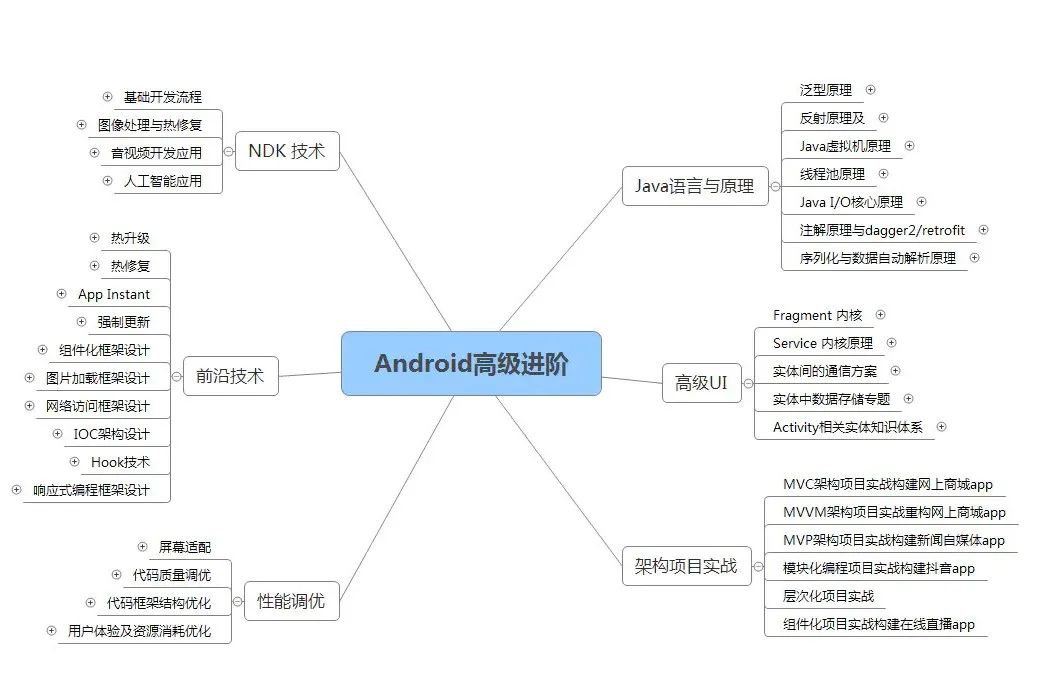
When building these technical frameworks, we also sorted out the advanced tutorials of the system, which will be much more effective than our own fragmented learning.
Click: Android architecture Video + BAT interview topic PDF + learning notes You can get it for free~
There are a lot of materials for learning Android online, but if the knowledge learned is not systematic, only a superficial taste when encountering problems and no further research, it is difficult to achieve real technology improvement. I hope this systematic technical system has a direction reference for you.
Architecture Video + BAT interview topic PDF + learning notes * *]( https://github.com/a120464/Android-P7/blob/master/Android%E5%BC%80%E5%8F%91%E4%B8%8D%E4%BC%9A%E8%BF%99%E4%BA%9B%EF%BC%9F%E5%A6%82%E4%BD%95%E9%9D%A2%E8%AF%95%E6%8B%BF%E9%AB%98%E8%96%AA%EF%BC%81.md )You can get it for free~
There are a lot of materials for learning Android online, but if the knowledge learned is not systematic, only a superficial taste when encountering problems and no further research, it is difficult to achieve real technology improvement. I hope this systematic technical system has a direction reference for you.