redis
pipeline
Beer theory, for example, there are 24 bottles of beer in the store. You can't take one bottle home and drink another. You need to find a box to carry the beer home together
The buffer mechanism can also be understood in this way to avoid calling back and forth

A request / response server can handle new requests even if the old requests have not been responded to. This allows multiple commands to be sent to the server without waiting for a reply, which is read in the last step.
This is pipelining, a technology widely used for decades. For example, many POP3 protocols have been implemented to support this function, which greatly speeds up the process of downloading new mail from the server.
Redis has long supported pipelining technology, so no matter what version you are running, you can use pipelining to operate redis.
The cold start of redis can be preloaded through it
[root@admin vmuser]# nc localhost 16379 keys * -NOAUTH Authentication required. auth 123456 +OK keys * *0 set k1 hello
Log in to redis cli at this time
127.0.0.1:16379> get k1 "hello" 127.0.0.1:16379>
Use pipes to insert redis values as \ n splits
The following $3 means a width of 3 is 100
[root@admin vmuser]# echo -e "auth 123456\n set k2 99\n incr k2\n get k2" | nc localhost 16379 +OK +OK :100 $3 100
Pub/Sub publish subscription
help @pubsub
PSUBSCRIBE pattern [pattern ...] summary: Listen for messages published to channels matching the given patterns since: 2.0.0 PUBLISH channel message summary: Post a message to a channel since: 2.0.0 PUBSUB subcommand [argument [argument ...]] summary: Inspect the state of the Pub/Sub subsystem since: 2.8.0 PUNSUBSCRIBE [pattern [pattern ...]] summary: Stop listening for messages posted to channels matching the given patterns since: 2.0.0 SUBSCRIBE channel [channel ...] summary: Listen for messages published to the given channels since: 2.0.0 UNSUBSCRIBE [channel [channel ...]] summary: Stop listening for messages posted to the given channels since: 2.0.0
Server
127.0.0.1:16379> PUBLISH ooxx hello (integer) 0
client
127.0.0.1:16379> SUBSCRIBE ooxx Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "ooxx" 3) (integer) 1
At this time, the client cannot obtain the data. The server needs to re execute publish, and the client can obtain the data of the server only after maintaining it
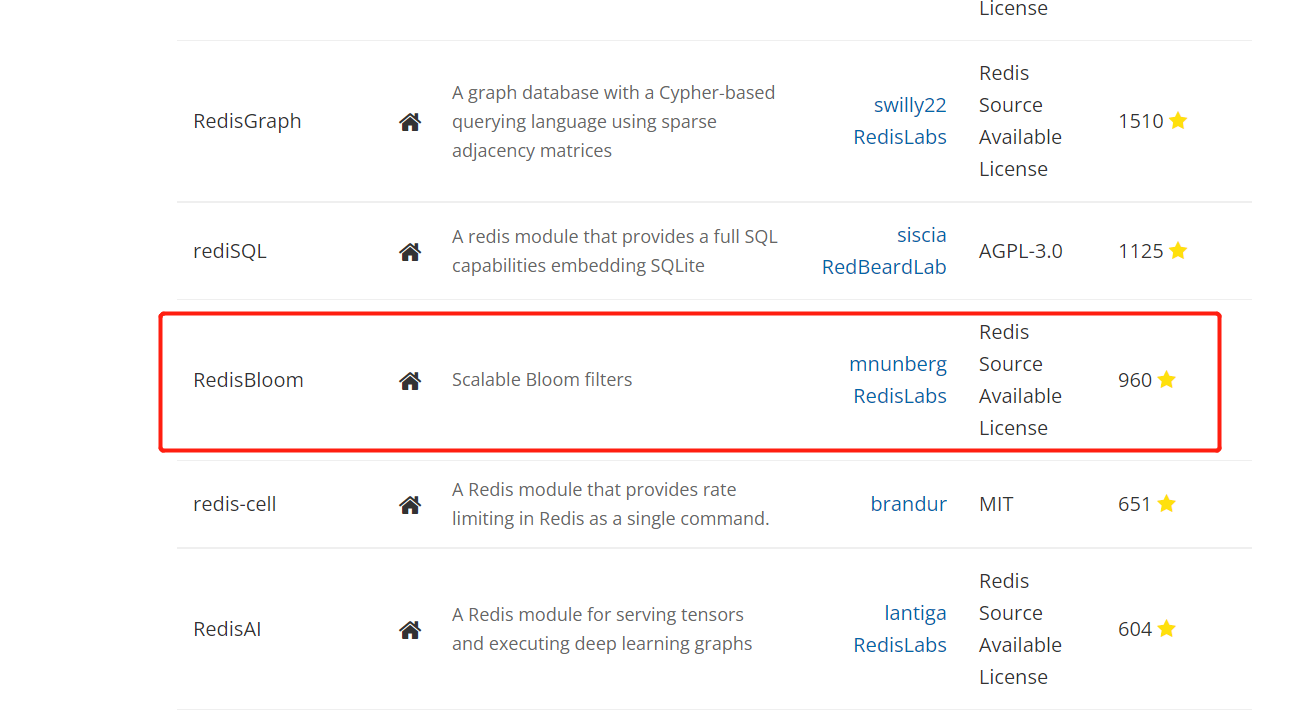
If you want to see the previous records, if you insert them into the database, it will become very expensive for everyone to check from the database
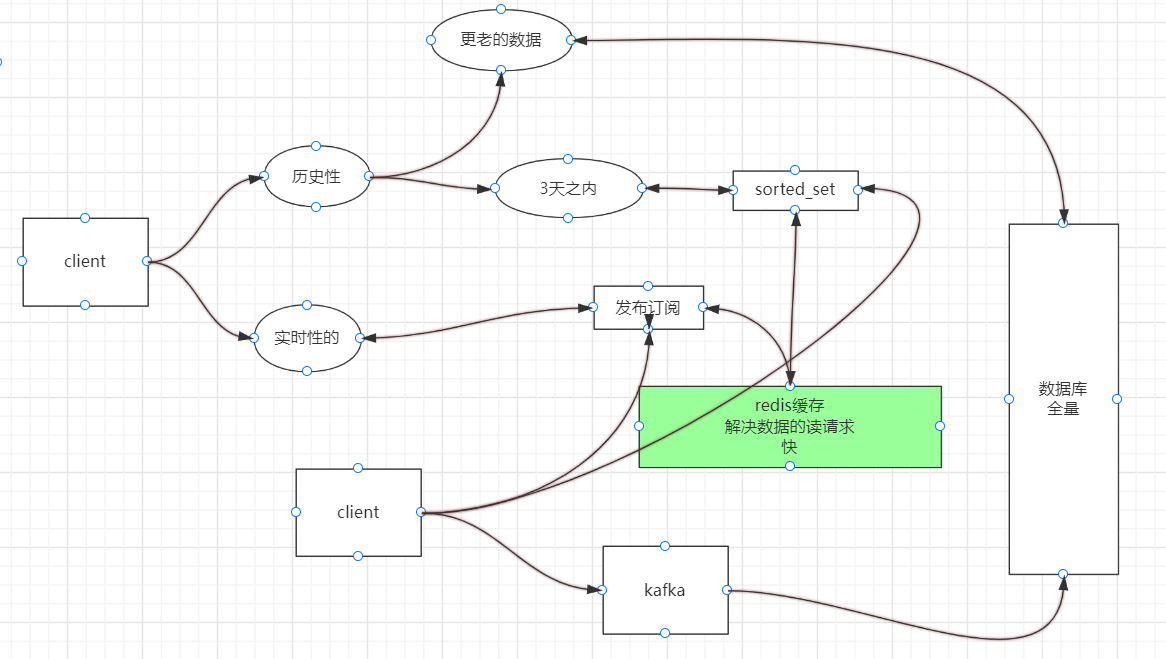
It can be used like this, but what if client1 goes to publish and client2 does not receive the message, but the sorted set receives the message and caches it?
Solution: start different redis to receive subscription messages, some for pushing to users, some for sending to kafka, and then store them in the database for consumption
affair
redis transaction is actually very simple, not as complex as mysql, because the author designed it for fast reading
help @transactions
DISCARD - summary: Discard all commands issued after MULTI since: 2.0.0 EXEC - summary: Execute all commands issued after MULTI since: 1.2.0 MULTI - summary: Mark the start of a transaction block since: 1.2.0 UNWATCH - summary: Forget about all watched keys since: 2.2.0 WATCH key [key ...] summary: Watch the given keys to determine execution of the MULTI/EXEC block since: 2.2.0
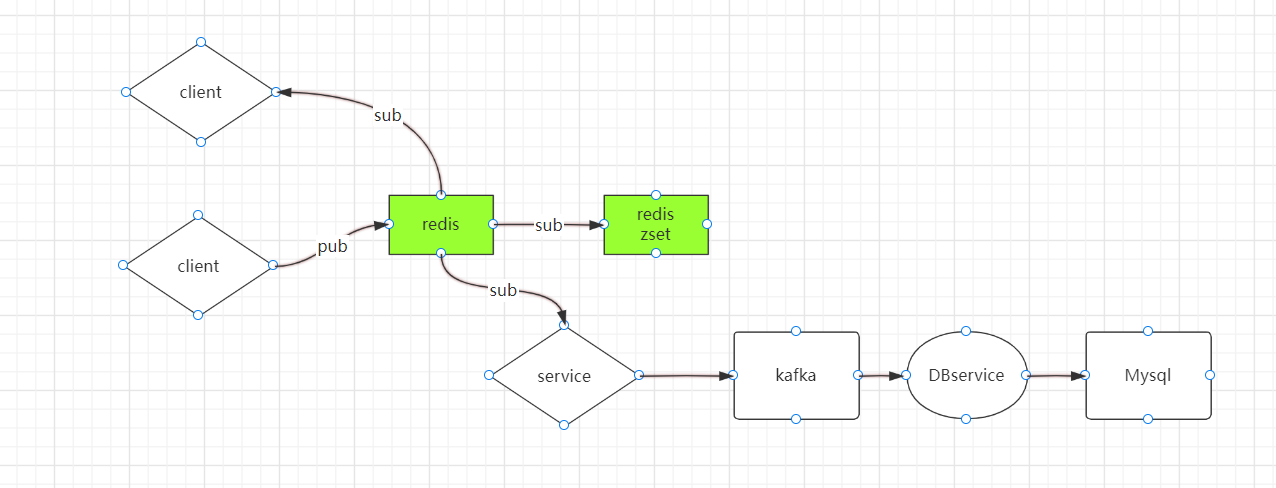
First of all, the original concept is that redis is a single process. If client1 and client2 initiate transactions at the same time, how to deal with them at this time
client1 is green
client2 is yellow

If the Yellow client2's exec arrives at redis first, execute client2 first. When executing client1, whose exec arrives first, execute whose first
Add a watch to use. If the key of redis has changed, the following operations will not be performed. For example, the get key of client1 will not be operated
Open transaction
127.0.0.1:16379> MULTI
OK
127.0.0.1:16379(TX)> set k1 aaa
QUEUED
127.0.0.1:16379(TX)> set k2 bbb
QUEUED
Submit
127.0.0.1:16379(TX)> exec
1) OK
2) OK
client1 starts the transaction first, but the commit exec is behind client2. At this time, it gets null
127.0.0.1:16379> MULTI OK 127.0.0.1:16379(TX)> get k1 QUEUED 127.0.0.1:16379(TX)> exec 1) (nil)
client2 finally starts the transaction and submits exec in advance
127.0.0.1:16379> MULTI OK 127.0.0.1:16379(TX)> del k1 QUEUED 127.0.0.1:16379(TX)> exec 1) (integer) 1 127.0.0.1:16379>
WATCH
client 1 transaction is not under operation, so it is nil
127.0.0.1:16379> WATCH k1 OK 127.0.0.1:16379> MULTI OK 127.0.0.1:16379(TX)> get k1 QUEUED 127.0.0.1:16379(TX)> keys * QUEUED 127.0.0.1:16379(TX)> exec (nil)
127.0.0.1:16379> MULTI OK 127.0.0.1:16379(TX)> keys * QUEUED 127.0.0.1:16379(TX)> set k1 sdfsfds QUEUED 127.0.0.1:16379(TX)> exec 1) (empty array) 2) OK 127.0.0.1:16379> get k1 "sdfsfds"
Why does Redis not support roll back
If you have experience in using relational database, you may find it a little strange that "Redis does not roll back when the transaction fails, but continues to execute the remaining commands".
The following are the advantages of this approach:
Redis commands will only fail because of the wrong syntax (and these problems cannot be found when joining the queue), or the command is used on the wrong type of key: that is, from a practical point of view, the failed commands are caused by programming errors, which should be found in the development process, not in the production environment.
Because there is no need to support rollback, Redis's internal can remain simple and fast.
There is a view that Redis's handling of transactions will cause bug s. However, it should be noted that under normal circumstances, rollback cannot solve the problems caused by programming errors. For example, if you want to add 1 to the value of the key through the INCR command, but accidentally add 2, or perform INCR on the wrong type of key, rollback cannot deal with these situations.
modules
Similar to the mode of others in the game, you can use it to play
Click in. The hot bloom of redis is right here
RedisBloom
Point a small house into the description