previously on
Before station b, the web page data is crawled, which can be crawled by python requests and Selenium. However, the web version of live consumption data of station b cannot be displayed and can only be seen on the mobile phone, so this article is available.
I read the article before that fiddler can also crawl, but I tried unsuccessfully. This time I chose appium to crawl. Similarly, mobile phone app data such as WeChat friends circle and jitter can be used tiktok.
text
#Environment configuration reference
Preliminary work preparation: python, jdk, pycharm, Appium-windows-x.x and appium need to be installed_ python_ Client, Android SDK and pycharm can be replaced by anaconda's jupyter
Preliminary preparation requires constant installation and configuration of environment variables, which is also a relatively boring process
When it's finished, you can really climb it
Import module
from appium import webdriver import numpy as np import pandas as pd import time
Open the mobile station b app through the program
desired_caps = {
'platformName': 'Android', # The tested mobile phone is Android
'platformVersion': '10', # Mobile Android version
'deviceName': 'xxx', # Device name and Android phone can be filled in at will
'appPackage': 'tv.danmaku.bili', # Start APP Package name
'appActivity': '.ui.splash.SplashActivity', # Start Activity name
'unicodeKeyboard': True, # Use the built-in input method, and fill in True when entering Chinese
'resetKeyboard': True, # After executing the program, restore the original input method
'noReset': True, # Don't reset the app. If it is False, the app data will be cleared after executing the script. For example, you signed in and quit after executing the script
'newCommandTimeout': 6000,
'automationName': 'UiAutomator2'
}
Open station b
# Connect Appium Server and initialize the automation environment
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
# Set the waiting time. If no time is given, the element may not be found
driver.implicitly_wait(4)
After opening, the following page is displayed
Click my - my live broadcast - consumption record on your mobile phone to view your personal consumption record,
Of course, you can also write two lines of code to realize this process (choose to skip here), as shown in the figure below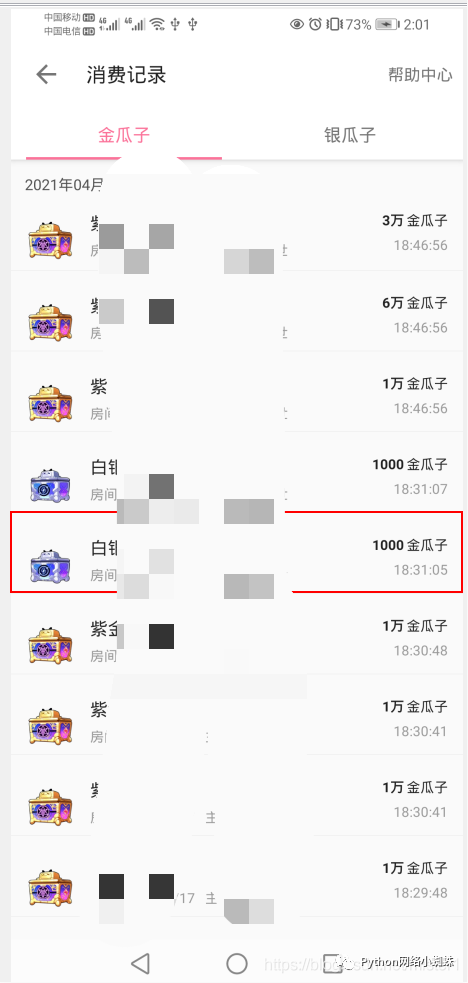
Because there are a lot of consumption records, only 10 items can be displayed on a page. If you want to crawl all of them, you can set sliding and crawl up to get all the data.
Flick for specific parameter settings_ Distance = 1050 can be crawled without repetition and leakage, as shown below:
Set sliding
flick_start_x=540
flick_start_y=192
flick_distance=1050
while True:
driver.swipe(flick_start_x,flick_start_y+flick_distance,flick_start_x,flick_start_y)
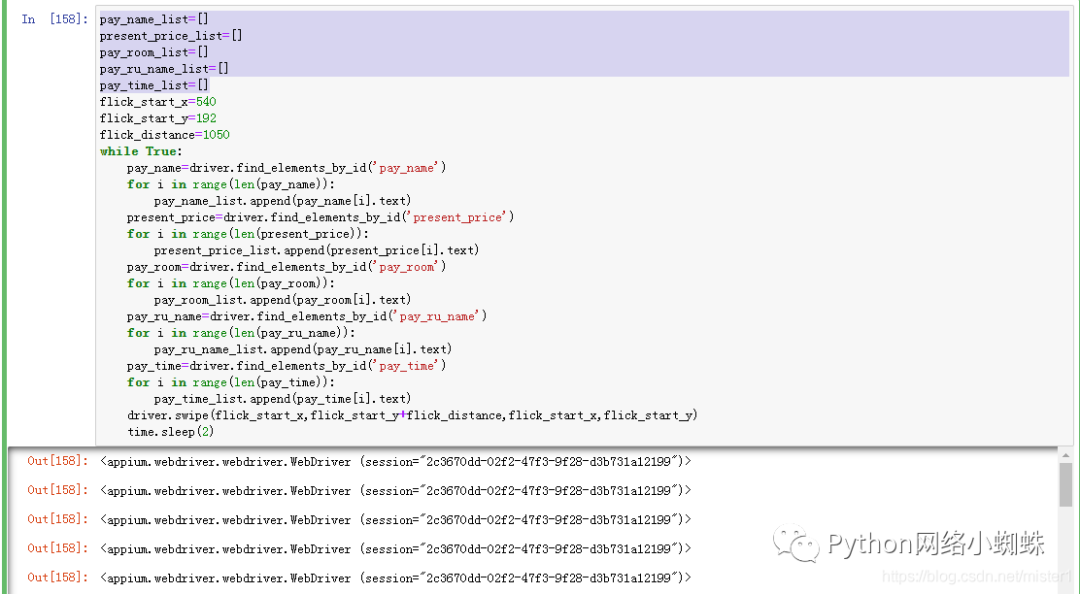
Crawling
pay_name_list=[]
present_price_list=[]
pay_room_list=[]
pay_ru_name_list=[]
pay_time_list=[]
flick_start_x=540
flick_start_y=192
flick_distance=1050
while True:
pay_name=driver.find_elements_by_id('pay_name')
for i in range(len(pay_name)):
pay_name_list.append(pay_name[i].text)
present_price=driver.find_elements_by_id('present_price')
for i in range(len(present_price)):
present_price_list.append(present_price[i].text)
pay_room=driver.find_elements_by_id('pay_room')
for i in range(len(pay_room)):
pay_room_list.append(pay_room[i].text)
pay_ru_name=driver.find_elements_by_id('pay_ru_name')
for i in range(len(pay_ru_name)):
pay_ru_name_list.append(pay_ru_name[i].text)
pay_time=driver.find_elements_by_id('pay_time')
for i in range(len(pay_time)):
pay_time_list.append(pay_time[i].text)
driver.swipe(flick_start_x,flick_start_y+flick_distance,flick_start_x,flick_start_y)
time.sleep(2)
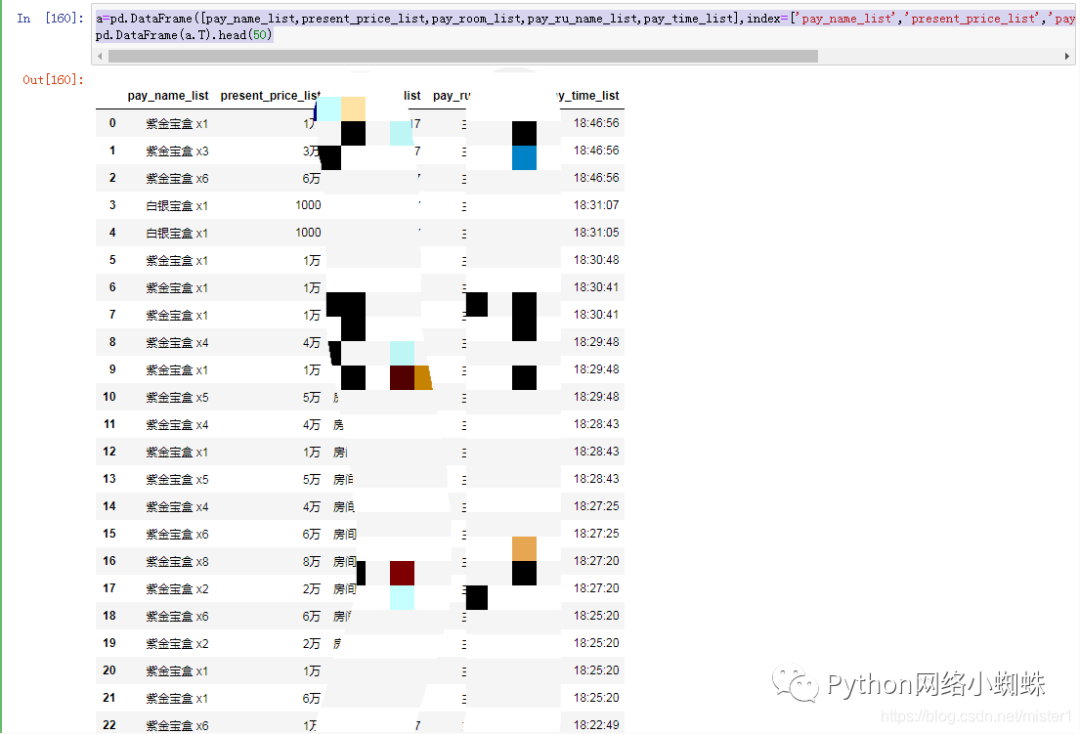
Convert to dataframe
a=pd.DataFrame([pay_name_list,present_price_list,pay_room_list,pay_ru_name_list,pay_time_list],index=['pay_name_list','present_price_list','pay_room_list','pay_ru_name_list','pay_time_list']) pd.DataFrame(a.T).head(50)
Let's comment on the collection of one button three links, old fellow!!!


Dry goods mainly include:
① More than 2000 Python e-books (both mainstream and classic books should be available)
② Python standard library materials (the most complete Chinese version)
③ Project source code (forty or fifty interesting and classic hand training projects and source code)
④ Python basic introduction video and so on (suitable for Xiaobai learning)
Here I would like to recommend my own Python learning Q group: 705933274. All of them are learning python. If you want to learn or are learning python, you are welcome to join. Everyone is a software development party and shares dry goods from time to time (only related to Python software development), including a copy of the latest Python advanced materials and zero basic teaching in 2021 compiled by myself, Welcome to advanced and interested partners of Python!