My father really loves basketball. He basically pursues it every season. I'm different. I haven't seen much basketball since I graduated from high school. Therefore, I have a feeling, whether I can crawl some information of active players to see if I still have a few acquaintances.

1. Page analysis
The page I crawled is Tencent sports, and the link is as follows:
https://nba.stats.qq.com/player/list.htm

Observe the above figure: the 30 NBA teams are shown on the left, and the details of the corresponding players of each team are shown on the right.
At this time, the idea is very clear. Every time we click on a player, the player information of the team will appear on the right.
The whole idea of crawler is simplified as follows:
- ① Get the url of each player page;
- ② Using Python code to obtain the data in each web page;
- ③ Sort out the obtained data and store it in different databases;
So, what we need to do now is to find the url of each player page and find their association.
Every time we click on a team, we copy its url. Below, I copy the page url of three teams, as shown below:
# 76 people https://nba.stats.qq.com/player/list.htm#teamId=20 # rocket https://nba.stats.qq.com/player/list.htm#teamId=10 # Miami Heat https://nba.stats.qq.com/player/list.htm#teamId=14
Observing the above url as like as two peas, url can be found to be exactly the same. Except for the corresponding numbers of teamId, the number of each team can be guessed, and the 30 teams are 30 numbers.
As long as it involves the word "Tencent", it is basically a dynamic web page. I have encountered it many times before. The basic method can't get data at all. If you don't believe it, you can check the web source code: right click - > Click to check the web source code.
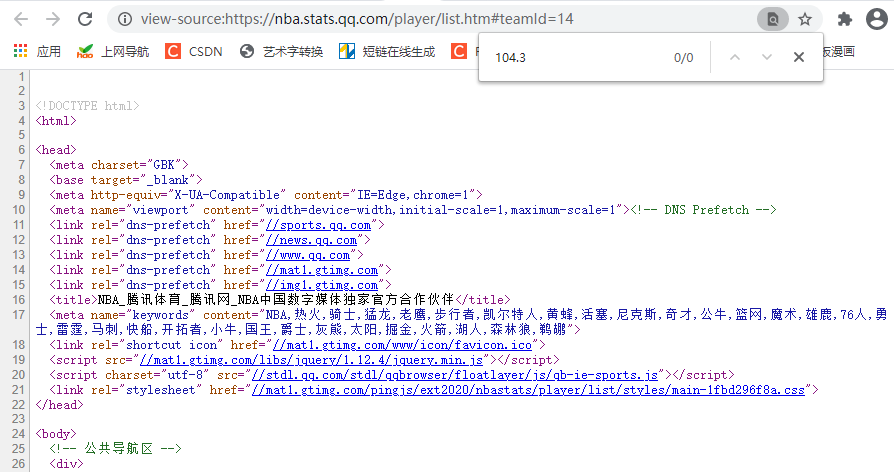
Then, copy some data in the web page (what you want to get), and then click crtl + f on the source code page to call out the "search box" and paste the copied data in. If there are 0 records like the above figure, you can basically judge that the web page belongs to a dynamic web page. Get the source code directly, and you will not find the data you want.
Therefore, if you want to get the data in the page, using selenium automatic crawler is one of the ways.
2. Data crawling
I have described the use and configuration of selenium in detail in an article. Post this link for your reference:
<https://mp.weixin.qq.com/s/PUPmpbiCJqRW8Swr1Mo2UQ>
I like to use xpath. I will use it for data acquisition in this article. About the use of xpath, that is another article, which will not be described in detail here.

Having said so much, let's go directly to the code! [there will be comments in the code]
from selenium import webdriver
# Create a browser object, which will automatically open the Google browser window for us
browser = webdriver.Chrome()
# Call the browser object and send a request to the server. This operation will open Google browser and jump to the "Baidu" home page
browser.get("https://nba.stats.qq.com/player/list.htm#teamId=20")
# maximize window
browser.maximize_window()
# Get player Chinese name
chinese_names = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[2]/a')
chinese_names_list = [i.text for i in chinese_names]
# Get player English name
english_names = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[3]/a')
english_names_list = [i.get_attribute('title') for i in english_names] # get attribute
# Get player number
numbers = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[4]')
numbers_list = [i.text for i in numbers_list]
# Get player location
locations = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[5]')
locations_list = [i.text for i in locations_list]
# Get player height
heights = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[6]')
heights_list = [i.text for i in heights_list]
# Get player weight
weights = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[7]')
weights_list = [i.text for i in weights_list]
# Get player age
ages = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[8]')
ages_list = [i.text for i in ages_list]
# Get player age
qiu_lings = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[9]')
qiu_lings_list = [i.text for i in qiu_lings_list]
There is only one team crawling here, and the task of crawling player data of the remaining 29 teams is up to you. The whole part of the code is basically the same. I wrote one. You draw the gourd and ladle according to the gourd. [just one cycle, it's not simple!]
3. Store to txt
The operation of saving data to txt text is very simple. txt is compatible with almost all platforms. The only disadvantage is that it is inconvenient to retrieve. If you do not have high requirements for retrieval and data structure and pursue convenience first, please use txt text storage.
Note: the str string is written in txt.
The rule for writing data to txt documents is as follows: start from scratch and fill from left to right. When filled to the far right, it will be squeezed to the next line. Therefore, if you want to store more regular data, you can automatically fill in the tab "\ t" and line feed "\ n".
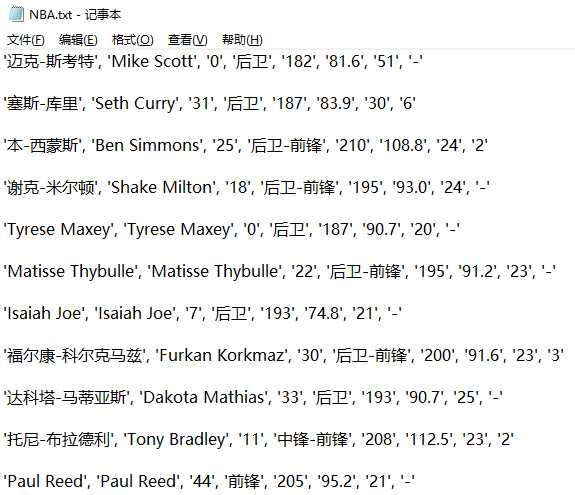
Taking this article as an example, the obtained data is stored in txt text.
for i in zip(chinese_names_list,english_names_list,numbers_list,locations_list,heights_list,weights_list,ages_list,qiu_lings_list):
with open("NBA.txt","a+",encoding="utf-8") as f:
# zip function to get a tuple. We need to convert it into a string
f.write(str(i)[1:-1])
# Auto wrap to write line 2 data
f.write("\n")
f.write("\n")
Some screenshots are as follows:
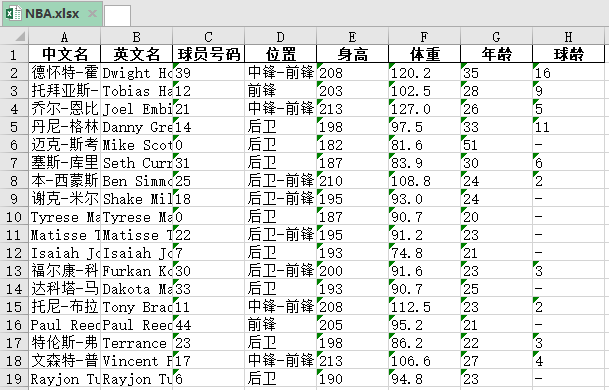
4. Store in excel
Excel has two formats of files, one is csv format and the other is xlsx format. Save the data to excel, of course, it is more convenient to use pandas library.
import pandas as pd
# Be sure to learn to organize data
df = pd.DataFrame({"Chinese name": chinese_names_list,
"English name": english_names_list,
"Player number": numbers_list,
"position": locations_list,
"height": heights_list,
"weight": weights_list,
"Age": ages_list,
"years of participation in a ball sport": qiu_lings_list})
# to_excel() function
df.to_excel("NBA.xlsx",encoding="utf-8",index=None)
The results are as follows:
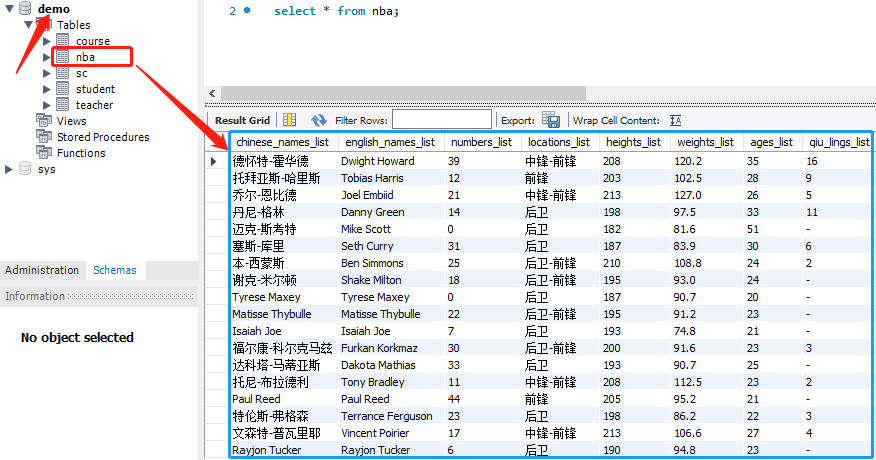
5. Store to mysql
MySQL is a relational database. The data is saved by two-dimensional tables similar to excel, that is, a table composed of rows and columns. Each row represents a record and each column represents a field.
I once wrote a blog about Python operating MySQL database. You can refer to the following:
http://blog.csdn.net/weixin_41261833/article/details/103832017
In order to make you better understand this process, I'll explain it here:
① Create a table nba
To insert data into the database, we first need to create a table named nba.
import pymysql
# 1. Connect to the database
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='demo', charset='utf8')
# 2. Create a table
# Create a cursor object;
cursor = db.cursor()
# Create table statement;
sql = """
create table NBA(
chinese_names_list varchar(20),
english_names_list varchar(20),
numbers_list varchar(20),
locations_list varchar(20),
heights_list varchar(20),
weights_list varchar(20),
ages_list varchar(20),
qiu_lings_list varchar(20)
)charset=utf8
"""
# Execute sql statements;
cursor.execute(sql)
# Disconnect the database;
db.close()
② Insert data into table nba
import pymysql
# 1. Organizational data
data_list = []
for i in zip(chinese_names_list,english_names_list,numbers_list,locations_list,heights_list,weights_list,ages_list,qiu_lings_list):
data_list.append(i)
# 2. Connect to the database
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='demo', charset='utf8')
# Create a cursor object;
cursor = db.cursor()
# 3. Insert data
sql = 'insert into nba(chinese_names_list,english_names_list,numbers_list,locations_list,heights_list,weights_list,ages_list,qiu_lings_list) values(%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.executemany(sql,data_list)
db.commit()
print("Insert successful")
except:
print("Insert failed")
db.rollback()
db.close()
The results are as follows: