If you are Xiao Bai, this data set can help you become a bull. If you have rich development experience, this data set can help you break through the bottleneck.
2022 Web Full Video Tutorial Front End Architecture H5 vue node Applet Video+Materials+Code+Interview Questions.
I've already described parsing data for CSS image offset and font backcrawl, and the links are as follows:
- Python extracts data for offset positioning of CSS pictures: https://blog.csdn.net/as604049322/article/details/118401598
- 20,000-character hard core profiling web page custom font resolution: https://blog.csdn.net/as604049322/article/details/119333427
- woff font metastructure analysis, custom font making and matching and recognition: https://blog.csdn.net/as604049322/article/details/119415686
The last one focuses on the random order of font backcrawling and upgrade to outline, or even basic font shape, a few years later. In recent years, I don't need to understand so deeply that I can't read the direct collection, because at present no website's fonts are as complex as I imagine.
SVG Mapping Reverse Crawl Example
Today, I'm going to share a relatively simple example, SVG Text Picture Offset Reverse Crawl Data Extraction.
This anti-crawling mechanism is also much weaker than the first two, so few websites are still using this anti-crawling mechanism.
A practice site for SVG mapping backcrawling has been found here for you to play with. The website is: http://www.porters.vip/confusion/food.html
Analyse the DOM structure:

You can clearly see that the CSS picture background offset is used to locate and display the corresponding data, but this picture is a text picture in svg format.
View the svg as follows:

This means that the actual storage of this svg is still plain text.
Then we can completely parse the svg and locate the matched actual text in the svg according to the offset value of the background directly.
To make extracting css data easier, I use the selenium operation directly here, first open the destination web address:
from selenium import webdriver browser = webdriver.Chrome() url = 'http://www.porters.vip/confusion/food.html#' browser.get(url)
Through food. As you can see from the code block at the beginning of line 4 of css, the CSS style for all labels positioned using svg text pictures is d[class^="vhk"]
So we take out the address of the svg by any element with that style:
d_tag = browser.find_element_by_css_selector('d[class^="vhk"]')
background_image_url = d_tag.value_of_css_property("background-image")
svg_url = background_image_url[5:-2]
svg_url
'http://www.porters.vip/confusion/font/food.svg'
Today, a new library, requests-html, is introduced for parsing purposes. The framework author is the author of requests.
You can install it using pip install requests-html. What are the advanced features of PIP install requests compared to previous requests? You can refer to the official manual for the address: https://requests-html.kennethreitz.org/
For me personally, the easiest thing to do now is to have built-in CSS and xpath selectors, and no additional packages to parse the data.
Today we will use the library's xpath selector directly to extract data from the svg file above. Looking at the xml structure of the svg content above, you can see that the x-attributes of each text node are consistent and increase in order.
Then I use the requests-html library to download and parse the code as follows:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get(svg_url)
xs = []
ys = []
data = []
for text_tag in r.html.xpath(r"//text"):
if not xs:
xs.extend(map(int, text_tag.xpath(".//@x")[0].split()))
ys.append(int(text_tag.xpath(".//@y")[0]))
data.append(list(text_tag.xpath(".//text()")[0]))
print(xs)
print(ys)
print(data)
[14, 28, 42, 56, 70, 84, 98, 112, 126, 140, 154, 168, 182, 196, 210, 224, 238, 252, 266, 280, 294, 308, 322, 336, 350, 364, 378, 392, 406, 420, 434, 448, 462, 476, 490, 504, 518, 532, 546, 560, 574, 588, 602, 616, 630, 644, 658, 672, 686, 700, 714, 728, 742, 756, 770, 784, 798, 812, 826, 840, 854, 868, 882, 896, 910, 924, 938, 952, 966, 980, 994, 1008, 1022, 1036, 1050, 1064, 1078, 1092, 1106, 1120, 1134, 1148, 1162, 1176, 1190, 1204, 1218, 1232, 1246, 1260, 1274, 1288, 1302, 1316, 1330, 1344, 1358, 1372, 1386, 1400, 1414, 1428, 1442, 1456, 1470, 1484, 1498, 1512, 1526, 1540, 1554, 1568, 1582, 1596, 1610, 1624, 1638, 1652, 1666, 1680, 1694, 1708, 1722, 1736, 1750, 1764, 1778, 1792, 1806, 1820, 1834, 1848, 1862, 1876, 1890, 1904, 1918, 1932, 1946, 1960, 1974, 1988, 2002, 2016, 2030, 2044, 2058, 2072, 2086, 2100]
[38, 83, 120, 164]
[['1', '5', '4', '6', '6', '9', '1', '3', '6', '4', '9', '7', '9', '7', '5', '1', '6', '7', '4', '7', '9', '8', '2', '5', '3', '8', '3', '9', '9', '6', '3', '1', '3', '9', '2', '5', '7', '2', '0', '5', '7', '3'], ['5', '6', '0', '8', '6', '2', '4', '6', '2', '8', '0', '5', '2', '0', '4', '7', '5', '5', '4', '3', '7', '5', '7', '1', '1', '2', '1', '4', '3', '7', '4', '5', '8', '5', '2', '4', '9', '8', '5', '0', '1', '7'], ['6', '7', '1', '2', '6', '0', '7', '8', '1', '1', '0', '4', '0', '9', '6', '6', '6', '3', '0', '0', '0', '8', '9', '2', '3', '2', '8', '4', '4', '0', '4', '8', '9', '2', '3', '9', '1', '8', '5', '9', '2', '3'], ['6', '8', '4', '4', '3', '1', '0', '8', '1', '1', '3', '9', '5', '0', '2', '7', '9', '6', '8', '0', '7', '3', '8', '2']]
You can see that you have successfully extracted the data you need.
Let's start by demonstrating how to get an offset value using a phone number as an example:
import re
d_tags = browser.find_elements_by_css_selector('.more d[class^="vhk"]')
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("d+", position))
print(position, x, y)
-8px -15px 8 15
-274px -141px 274 141
-274px -141px 274 141
-176px -141px 176 141
-7px -15px 7 15
-288px -141px 288 141
-288px -141px 288 141
-7px -15px 7 15
This resolves the svg image offset value for each numeric position.
What if you understand these numbers? I will manually change the first digit to -8px -15px, as shown below:
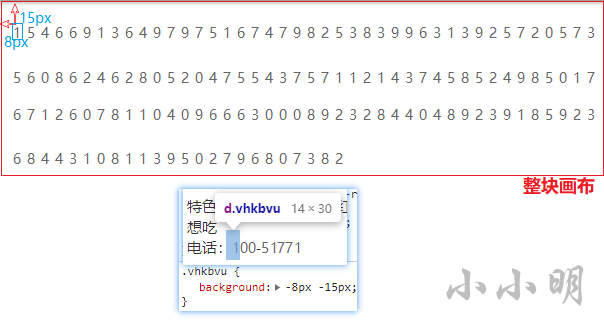
The red part is the whole picture canvas, -8px means 8 pixels to the left, -15px means 15 pixels to the up, so the upper left part is clipped out, and then just get the picture of the specified length and width range, and the blue box part of the picture is displayed on the interface.
So how do we match to get the data we need?
The insertion point can then be obtained by a 2-point lookup, for example, for the number 1 in the upper right corner, which can be obtained as follows:
from bisect import bisect data[bisect(ys, 15)][bisect(xs, 8)] '1'
After refreshing the page, try again in batches:
import re
d_tags = browser.find_elements_by_css_selector('.more d[class^="vhk"]')
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("d+", position))
print(x, y, data[bisect(ys, y)][bisect(xs, x)])
From the result, each node matches the corresponding text number accurately:
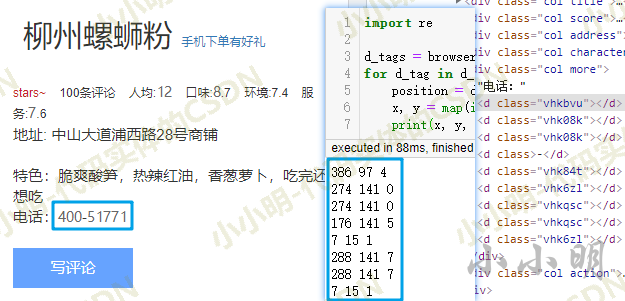
Now consider replacing all the above svg nodes with corresponding text, then you can directly extract the text data as a whole (call a JavaScript script for node replacement):
import re
def parseAndReplaceSvgNode(d_tags):
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("d+", position))
num = data[bisect(ys, y)][bisect(xs, x)]
# Replace node with plain text
browser.execute_script(f"""
var element = arguments[0];
element.parentNode.replaceChild(document.createTextNode("{num}"), element);
""", d_tag)
d_tags = browser.find_elements_by_css_selector('.more d[class^="vhk"]')
parseAndReplaceSvgNode(d_tags)
phone = browser.find_element_by_css_selector('.more').text
phone
'Telephone: 400-51771'
After execution, the corresponding svg nodes are converted to corresponding text nodes:

This allows us to easily parse all the data we need.
Based on this, I have parsed the basic knowledge completely, and publish the complete processing code below:
import re
from requests_html import HTMLSession
from selenium import webdriver
from bisect import bisect
def parseAndReplaceSvgNode(d_tags):
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("d+", position))
num = data[bisect(ys, y)][bisect(xs, x)]
# Replace node with plain text
browser.execute_script(f"""
var element = arguments[0];
element.parentNode.replaceChild(document.createTextNode("{num}"), element);
""", d_tag)
browser = webdriver.Chrome()
url = 'http://www.porters.vip/confusion/food.html#'
browser.get(url)
d_tag = browser.find_element_by_css_selector('d[class^="vhk"]')
background_image_url = d_tag.value_of_css_property("background-image")
svg_url = background_image_url[5:-2]
session = HTMLSession()
html_session = session.get(svg_url)
xs = []
ys = []
data = []
for text_tag in html_session.html.xpath(r"//text"):
if not xs:
xs.extend(map(int, text_tag.xpath(".//@x")[0].split()))
ys.append(int(text_tag.xpath(".//@y")[0]))
data.append(list(text_tag.xpath(".//text()")[0]))
# Replace all svg nodes in the entire DOM as corresponding text at once
parseAndReplaceSvgNode(
browser.find_elements_by_css_selector('d[class^="vhk"]'))
# Remove label a
element = browser.find_element_by_css_selector('.title a')
browser.execute_script("""
var element = arguments[0];
element.parentNode.removeChild(element);
""", element)
# Get Title
title = browser.find_element_by_class_name("title").text
# Get comments
comment = browser.find_element_by_class_name("comments").text
# per capita
avgPrice = browser.find_element_by_class_name('avgPriceTitle').text
# Taste, environment, service
comment_score_tags = browser.find_elements_by_css_selector(
".comment_score .item")
taste = comment_score_tags[0].text
environment = comment_score_tags[1].text
service = comment_score_tags[2].text
# address
address = browser.find_element_by_css_selector('.address .address_detail').text
# characteristic
characteristic = browser.find_element_by_css_selector(
'.characteristic .info-name').text
# Telephone
phone = browser.find_element_by_class_name("more").text
print(title, comment, avgPrice, taste, environment,
service, address, characteristic, phone)
Liuzhou spiral jelly powder 100 reviewers per capita:12 Flavor:8.7 Environmental Science:7.4 service:7.6 Shop characteristics of No. 28 Puxi Road, Zhongshan Avenue: crisp and cool bamboo shoots, hot and spicy red oil, chives and radishes, want to have a call after eating: 400-51771
You can see that each text is extracted perfectly and accurately.