When deep learning multi band data training, the model has been unable to converge.
torch.functions.to_tensor() function
Here is to_tensor function source code
def to_tensor(pic):
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
This function does not support torchscript.
See :class:`~torchvision.transforms.ToTensor` for more details.
Args:
pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
Returns:
Tensor: Converted image.
"""
if not(F_pil._is_pil_image(pic) or _is_numpy(pic)):
raise TypeError('pic should be PIL Image or ndarray. Got {}'.format(type(pic)))
if _is_numpy(pic) and not _is_numpy_image(pic):
raise ValueError('pic should be 2/3 dimensional. Got {} dimensions.'.format(pic.ndim))
default_float_dtype = torch.get_default_dtype()
if isinstance(pic, np.ndarray):
# handle numpy array
if pic.ndim == 2:
pic = pic[:, :, None]
img = torch.from_numpy(pic.transpose((2, 0, 1))).contiguous()
# backward compatibility
if isinstance(img, torch.ByteTensor):
return img.to(dtype=default_float_dtype).div(255)
else:
return img
if accimage is not None and isinstance(pic, accimage.Image):
nppic = np.zeros([pic.channels, pic.height, pic.width], dtype=default_float_dtype)
pic.copyto(nppic)
return torch.from_numpy(nppic)
# handle PIL Image
if pic.mode == 'I':
img = torch.from_numpy(np.array(pic, np.int32, copy=False))
elif pic.mode == 'I;16':
img = torch.from_numpy(np.array(pic, np.int16, copy=False))
elif pic.mode == 'F':
img = torch.from_numpy(np.array(pic, np.float32, copy=False))
elif pic.mode == '1':
img = 255 * torch.from_numpy(np.array(pic, np.uint8, copy=False))
else:
img = torch.ByteTensor(torch.ByteStorage.from_buffer(pic.tobytes()))
img = img.view(pic.size[1], pic.size[0], len(pic.getbands()))
# put it from HWC to CHW format
img = img.permute((2, 0, 1)).contiguous()
if isinstance(img, torch.ByteTensor):
return img.to(dtype=default_float_dtype).div(255)
else:
return img
When we input an array instead of the Image object of PIL, we need to look at the following code:
Note that there is a dimension transformation operation here. If the photo you enter is (C,H,W), then it will become (W,C,H)
if isinstance(pic, np.ndarray):
# handle numpy array
if pic.ndim == 2:
pic = pic[:, :, None]
# Note that there is a dimension transformation operation here. If the photo you enter is (C,H,W), then it will become (W,C,H)
img = torch.from_numpy(pic.transpose((2, 0, 1))).contiguous()
# backward compatibility
if isinstance(img, torch.ByteTensor):
return img.to(dtype=default_float_dtype).div(255)
else:
return img
Let me first tell you the whole story of this problem. When I do the multi-channel image training model, the data reading part of the model is carried out with the PIL module, and the format of the photo is tif. However, when the number of image channels is greater than 4, the PIL module cannot read the TIF image. Therefore, I redefined the data reading part with the gdal module. The custom image reading function is to convert the image into numpy Ndarray type, because functions to. The tensor() function only supports PIL Image object and numpy Ndarray object. But functions to. When inputting an array, tensor () will transform the dimension of ndarray as I said above, so it encounters the problem of non convergence of the model. The image I input is (5600600), in to The output of the tensor () function becomes (600, 3600). Since my height and width are both 600, I can't tell whether the first 600 is high or wide at the first time. I used the transfer (1,0) function to exchange the dimensions of the output tensor, which became (3600600), but now it is actually (C, W, H). Therefore, the model has been calculated incorrectly during verification, resulting in failure to converge. Then I used tersor Permute (1,2,0) changes the dimension back to (C,H,W), and the model is normal.
Next, I'll show the comparison between (C,H,W) and (C,W,H) with images to facilitate you to understand why you made mistakes.
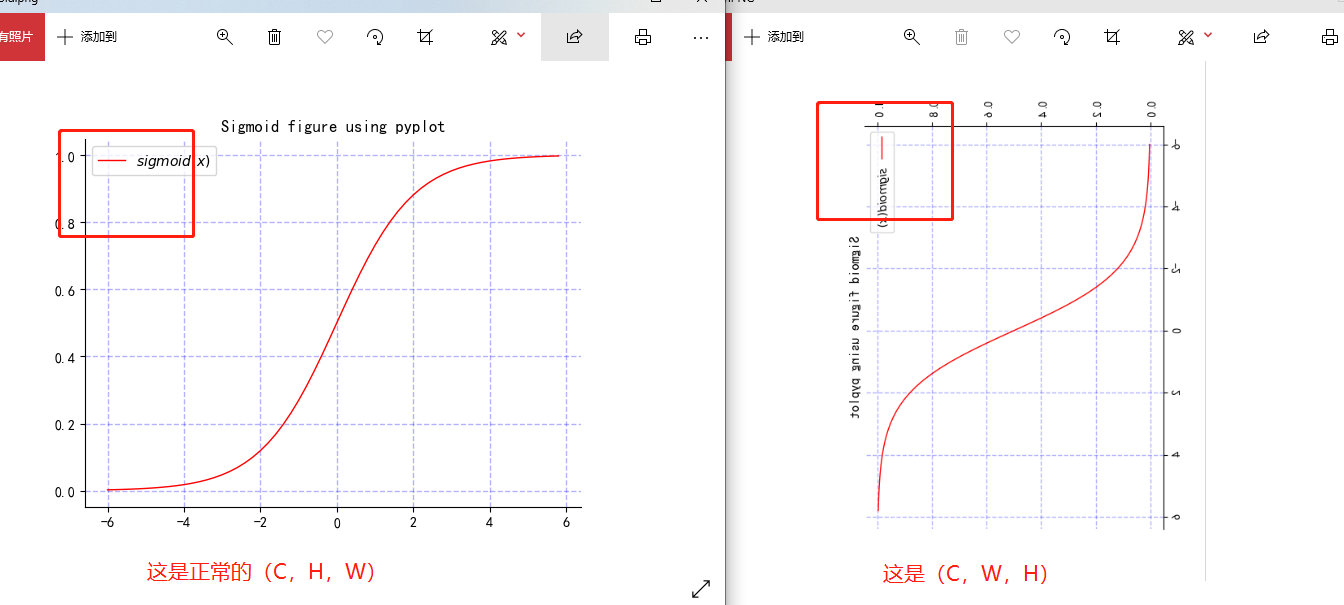
If the red is GT (correct label), you can see that the sample has been distorted, so the verification set cannot be verified accurately, and the model cannot converge.