Reprinted from AI Studio
Title item link https://aistudio.baidu.com/aistudio/projectdetail/3401596
PP minilm, a fast, small and accurate Chinese characteristic pre training model, has been released!
Transformer pre training model has achieved remarkable results in NLP tasks, but its huge model parameters and slow inference speed limit its wide application. It is a common practice in the current industry to directly use the ready-made small model or compress the pre training model by itself.
In recent years, many miniaturized models have emerged, such as distilbert, TinyBERT and ALBERT.
Flying oar PaddleNLP According to the characteristics of Chinese, the PaddleSlim Chinese distillation, tailoring and quantitative grade combined model compression technology to release fast, small and accurate Chinese characteristic pre training model—— PP-MiniLM(6L768H) , while ensuring the accuracy of the model, the reasoning speed of the model is 8.88 times that of BERT(12L768H), the amount of parameters is reduced by 52%, and the accuracy of the model is improved by 0.62 on the Chinese language understanding evaluation benchmark CLUE. The model accuracy on the seven classification tasks of CLUE exceeds that of BERTbase, TinyBERT6, UE py Roberta l6-h768 and RBT6.
This tutorial will first briefly introduce the small model PP minilm, and then introduce how to use PP minilm to fine tune, crop, quantify, predict and deploy.
PP-MiniLM
brief introduction
PP minilm compression scheme takes task agnostic distillation technology, pruning technology and quantization technology for pre training model as the core, making PP minilm fast, small and accurate.
-
Fast reasoning speed: Based on PaddleSlim's cutting and quantization technology, the PP minilm small model is compressed and accelerated, so that the GPU reasoning speed of PP minilm quantized model is up to 8.88 compared with BERT base;
-
High accuracy: We MiniLMv2 Based on the proposed multi head self attention relation distillation technology, the algorithm is further optimized by introducing the distillation of relationship knowledge between samples. The 6-layer PP minilm model is 0.62% higher than the 12-layer Bert base Chinese on the cloud dataset, and 2.57% and 2.24% higher than the TinyBERT6 and UE py Roberta of the same scale, respectively;
-
Small parameter scale: relying on task agnostic disintegration technology and PaddleSlim cutting technology, the amount of model parameters is reduced by 52% compared with BERT.
PP minilm is a small pre training model with six layers of Transformer Encoder Layer and Hidden Size of 768 produced by task independent distillation method and Roberta WwM ext large as teacher model distillation. The model accuracy of seven classification tasks on CLUE exceeds that of BERTbase, TinyBERT6, UE py Roberta l6-h768 and RBT6.
NOTE: if you are interested in the training process of PP minilm, you can view it Task independent document Know the details.
Overall effect
| Model | #Params | #FLOPs | Speedup | AFQMC | TNEWS | IFLYTEK | CMNLI | OCNLI | CLUEWSC2020 | CSL | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT-base, Chinese | 102.3M | 10.87B | 1.00x | 74.14 | 56.81 | 61.10 | 81.19 | 74.85 | 79.93 | 81.47 | 72.78 |
| TinyBERT6, Chinese | 59.7M | 5.44B | 2.04x | 72.59 | 55.70 | 57.64 | 79.57 | 73.97 | 76.32 | 80.00 | 70.83 |
| UER-py RoBERTa L6-H768 | 59.7M | 5.44B | 2.04x | 69.62 | 66.45 | 59.91 | 76.89 | 71.36 | 71.05 | 82.87 | 71.16 |
| RBT6, Chinese | 59.7M | 5.44B | 2.04x | 73.93 | 56.63 | 59.79 | 79.28 | 73.12 | 77.30 | 80.80 | 71.55 |
| ERNIE-Tiny | 90.7M | 4.83B | 2.30x | 71.55 | 58.34 | 61.41 | 76.81 | 71.46 | 72.04 | 79.13 | 70.11 |
| PP-MiniLM 6L-768H | 59.7M | 5.44B | 2.12x | 74.14 | 57.43 | 61.75 | 81.01 | 76.17 | 86.18 | 79.17 | 73.69 |
| After PP minilm cutting | 49.1M | 4.08B | 2.60x | 73.91 | 57.44 | 61.64 | 81.10 | 75.59 | 85.86 | 78.53 | 73.44 |
| PP minilm after clipping + quantization | 49.2M | - | 9.26x | 74.00 | 57.37 | 61.33 | 81.09 | 75.56 | 85.85 | 78.57 | 73.40 |
(right click to see more)
NOTE:
1. The accuracy test of all models in the above table is based on the Grid Search superparameter optimization in the superparameter range below. When training under each configuration, evaluate on the verification set every 100 steps, and take the best accuracy rate on the verification set as the accuracy rate under the current super parameter configuration;
- batch sizes: 16, 32, 64;
- learning rates: 3e-5, 5e-5, 1e-4
2. The model parameter quantity after quantization is 0.1M more than that before quantization because the scale value is saved;
3. The conditions of performance test are:
Hardware: NVIDIA Tesla T4 single card;
Software: CUDA 11.1, cuDNN 8.1, TensorRT 7.2, PaddlePaddle 2.2.2;
Experimental configuration: batch_size: 32, max_seq_len: 128;
Among them, except that the model after PP minilm clipping + quantization in the last row of the above table is to predict the INT8 model, the other models are based on FP32 accuracy test.
4. PP minilm model is connected with FasterTokenizer. FasterTokenizer has no impact on the accuracy of the model, but it will speed up the reasoning speed.
Recommended usage
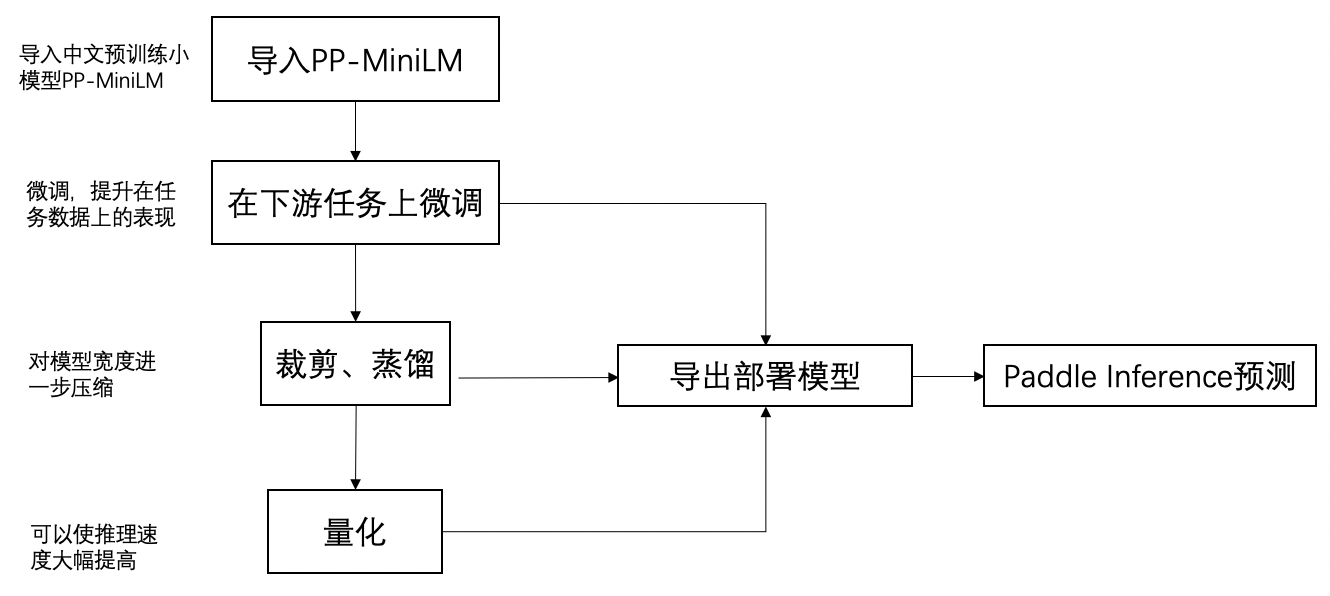
PP minilm usage flow chart
-
PP minilm is a 6-layer pre training model. Like other pre training models, call from_ After PP minilm is imported by the pre trained () interface, you can use your own dataset for fine tuning in downstream tasks.
-
If you want to further improve the prediction performance, you can continue to compress the fine tuned model through cutting and offline quantization strategies. The complete Chinese small model scheme is: import the PP minilm Chinese pre training small model, fine-tuning downstream tasks, cutting, offline quantification and prediction deployment. Each step here will be introduced below. In addition to the fine-tuning steps of downstream tasks, other steps can be omitted. If we pursue the ultimate performance, we suggest to keep each of the following steps.
PP minilm compression scheme
In order to show how to further compress PP minilm, we will take the CLUEWSC2020 data set in CLUE as an example to fine tune, crop, quantify and deploy the model respectively.
1, Environmental preparation
- Python
Python version requires 3.6+
-
PaddlePaddle
The compression scheme of PP-MiniLM depends on the PaddlePaddle 2.2.2 and above versions with the prediction library. Please refer to Installation guide Install
-
PaddleNLP
PP minilm relies on PaddleNLP 2.2.3 and later. You can install as follows:
pip install --upgrade paddlenlp -i https://pypi.org/simple
- PaddleSlim
Compression scheme dependency PaddleSlim It provides cutting and quantization functions, so PaddleSlim needs to be installed. PaddleSlim is a tool library focusing on deep learning model compression. It provides model compression strategies such as clipping, quantification, distillation and model structure search to help users quickly realize the miniaturization of models. You can install as follows:
pip install --upgrade paddleslim -i https://pypi.org/simple
!pip install --upgrade paddlenlp -i https://pypi.org/simple !pip install -U paddleslim -i https://pypi.org/simple
Requirement already satisfied: paddlenlp in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.1.1)
Collecting paddlenlp
Downloading paddlenlp-2.2.4-py3-none-any.whl (1.1 MB)
|████████████████████████████████| 1.1 MB 7.6 kB/s
[?25hRequirement already satisfied: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1)
Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.16.0)
Requirement already satisfied: numpy>=1.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.19.5)
Requirement already satisfied: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3)
Requirement already satisfied: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Installing collected packages: paddlenlp
Attempting uninstall: paddlenlp
Found existing installation: paddlenlp 2.1.1
Uninstalling paddlenlp-2.1.1:
Successfully uninstalled paddlenlp-2.1.1
Successfully installed paddlenlp-2.2.4
Collecting paddleslim
Downloading paddleslim-2.2.2-py3-none-any.whl (311 kB)
|████████████████████████████████| 311 kB 19 kB/s
[?25hRequirement already satisfied: pillow in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (8.2.0)
Requirement already satisfied: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (5.1.2)
Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (4.27.0)
Requirement already satisfied: pyzmq in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (22.3.0)
Requirement already satisfied: opencv-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (4.1.1.26)
Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (2.2.3)
Requirement already satisfied: numpy>=1.7.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (1.19.5)
Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (0.10.0)
Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (2019.3)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (3.0.7)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (1.1.0)
Requirement already satisfied: six>=1.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (1.16.0)
Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (2.8.2)
Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->paddleslim) (56.2.0)
Installing collected packages: paddleslim
Successfully installed paddleslim-2.2.2
After the environment is ready, we will introduce how to use the downstream task data to fine tune, further compress and reason deployment on the imported PP minilm.
2, Fine tuning
PP minilm is a 6-layer pre training model. Like other pre training models, call from_ After importing the PP minilm model with the pre trained () interface, you can perform fine tuning on your own dataset.
from paddlenlp.transformers import PPMiniLMModel, PPMiniLMForSequenceClassification
model = PPMiniLMModel.from_pretrained('ppminilm-6l-768h')
model = PPMiniLMForSequenceClassification.from_pretrained('ppminilm-6l-768h') # Used to classify tasks
This tutorial has provided a model trained on the clusc2020 dataset, which is located in '/ data/data124999/'. Readers can also refer to PaddleNLP The fine-tuning process in the document is trained on its own data.
After the model is trained on the downstream task, it can be directly used for deployment and can be used PaddleNLP Export the corresponding deployment model using the model export script provided in Prediction script Make predictions. However, we suggest further tailoring and quantification of the model, so as to get a model with faster reasoning speed.
3, Cutting
The cutting in PP minilm draws lessons from DynaBERT-Dynamic BERT with Adaptive Width and Depth The essence of the idea of adaptive cutting of medium width is knowledge distillation. Students who don't know much about distillation of knowledge can go back to the tutorial Practical lesson 12 of "NLP punch in camp": miniaturization and deployment of pre training model Learn.
Use dyna batch as the largest training model in the original network, and let the students use it as the largest training model in the original network. It should be added that the parameters among multiple sub models are shared.
Among them, based on the width experiment, the search space is composed of a width_mult_list, such as width_mult_list=[0.5, 0.75] indicates that the search space contains two sub models with the original width of 0.5 and 0.75. "Adaptive" in the title refers to that during the training process, we can train sub models under multiple clipping ratios at the same time, and finally select the model whose size and accuracy best meet our needs according to the evaluation results between different models.
Before training, the neurons in Head and FFN need to be ranked in importance, and then the neuron parameters in Head and FFN need to be rearranged according to the importance score. The purpose of this is to make more important parameters appear in more subnetworks and avoid being cut off. Before each training, when selecting different models, they will be cut according to different proportions, as shown in the following figure:
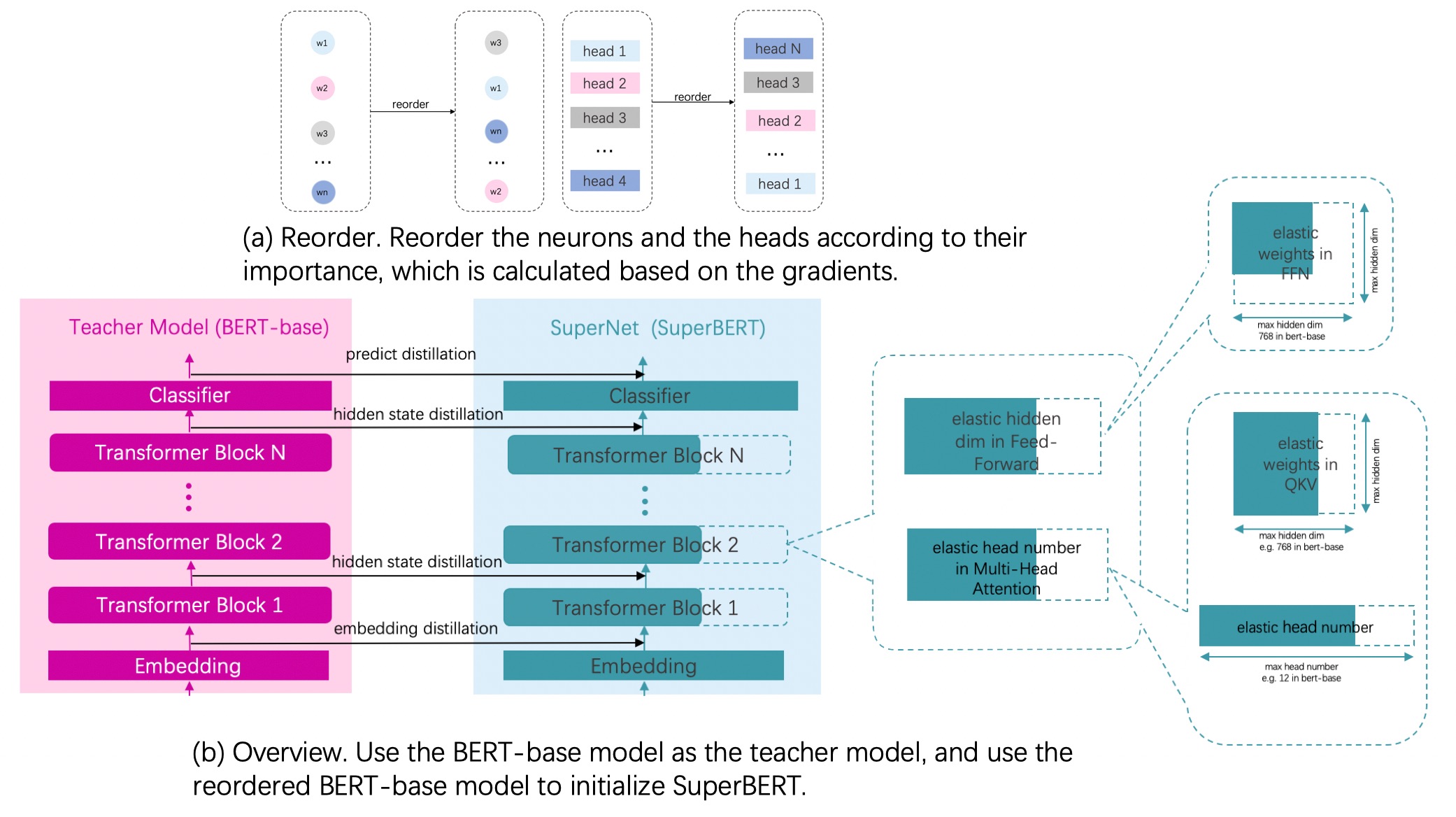
This is the basic principle of clipping. In order to show the clipping steps more clearly, the data processing part has been written in the file data In py, because this part of data processing is very close to other tasks, it will not be described in detail here. After fork ing the project, you can view and edit this part of the code by starting the project.
Data preparation before tailoring training
Data processing and other parts are reflected in the file data in this tutorial Py. In the following content, we can focus on the cutting process.
paddle.set_device('gpu')
set_seed(2022)
task_name = 'cluewsc2020'
model_type = 'ppminilm'
model_name_or_path = './data/data124999/'
train_ds = load_dataset('clue', task_name, splits='train')
train_data_loader = ...
from data import *
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/funnel/modeling.py:30: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable [01-28 15:17:47 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported 100%|██████████| 275/275 [00:00<00:00, 5732.91it/s]
Distillation configuration in cutting
Step 1: import the model of PP minilm after fine tuning on the task, which is our original model. At the same time, the model is also a teacher model.
from paddlenlp.transformers import PPMiniLMForSequenceClassification
# Use a dict to save the parameters of the original PP minilm
model = PPMiniLMForSequenceClassification.from_pretrained(
model_name_or_path, num_classes=num_labels)
origin_weights = model.state_dict()
# Define teacher model
teacher_model = PPMiniLMForSequenceClassification.from_pretrained(
model_name_or_path, num_classes=num_labels)
W0128 15:17:49.254159 236 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0128 15:17:49.259351 236 device_context.cc:465] device: 0, cuDNN Version: 7.6. [2022-01-28 15:17:55,106] [ INFO] - Loaded parameters from ./data/data124999/model_state.pdparams [2022-01-28 15:17:56,419] [ INFO] - Loaded parameters from ./data/data124999/model_state.pdparams
Step 2: transform the original model into a hypernetwork.
The hypernetwork here refers to a network including all search spaces. And use the parameters of the original network to initialize the super network parameters.
from paddleslim.nas.ofa import utils
from paddleslim.nas.ofa.convert_super import Convert, supernet
sp_config = supernet(expand_ratio=[1.0])
model = Convert(sp_config).convert(model)
# Initialize the hypernetwork using the parameters saved in dict
utils.set_state_dict(model, origin_weights)
del origin_weights
super_sd = paddle.load(
os.path.join(model_name_or_path, 'model_state.pdparams'))
model.set_state_dict(super_sd)
Step 3: configure distillation related parameters
Here, write the configuration required for distillation into a dict default_distill_config, and use this dict to initialize a paddleslim's DistillConfig object distill_config
from paddleslim.nas.ofa import DistillConfig
mapping_layers = ['ppminilm.embeddings']
for idx in range(model.ppminilm.config['num_hidden_layers']):
mapping_layers.append('ppminilm.encoder.layers.{}'.format(idx))
default_distill_config = {
'lambda_distill': 0.1,
'teacher_model': teacher_model,
'mapping_layers': mapping_layers,
}
distill_config = DistillConfig(**default_distill_config)
Step 4: configure hypernetwork training
Using the OFA interface provided by paddleslim, initialize an OFA with the super network model we transformed above_ model. This ofa_model is what we need for distillation training later. At the same time, we need to pass in the DistillConfig instance we generated above_ config. Because we only cut and search the width, we need to search the elastic_ The order parameter can be passed in ['width '].
ofa_ The model actually includes super network and teacher network. For example, the student network has the parameter 'model ppminilm. embeddings. word_ embeddings. fn. Weight 'corresponds to the parameter' ofa 'of the teacher network_ teacher_ model. model. ppminilm. embeddings. word_ embeddings. weight'
from paddleslim.nas.ofa import OFA
ofa_model = OFA(model,
distill_config=distill_config,
elastic_order=['width'])
Step 5: calculate the importance of neurons in Head and FFN, and reorder the order of parameters.
Before starting distillation training, it is also necessary to reorder the neurons in Head and FFN according to their importance, so that more important neurons can appear in more sub models and reduce the possibility of them being cut off.
- For Head, we are Q in SelfAttention_ proj,k_proj,v_proj,out_proj by width_mult_list (0.75 here). The following figure is the visualization of the exported graph after clipping, which can be seen q_proj. The shape of weight has changed from (768, 768) to (768, 576)
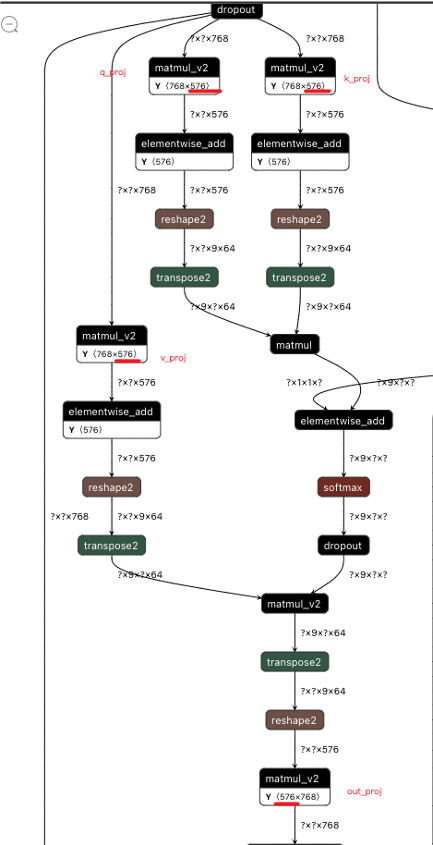
Cropped HEAD diagram
- For FFN neurons, we cut linear1 and linear2 in EncoderLayer in equal proportion (the ratio is 0.75). The following figure is the visualization of the exported graph after clipping.
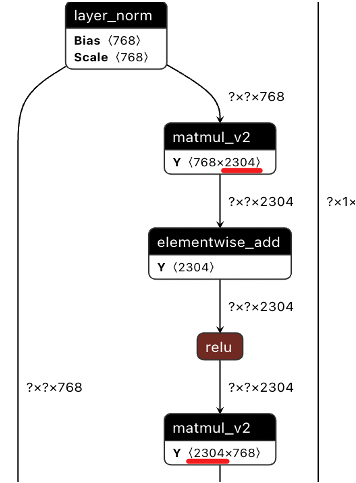
Cropped FFN graph
Here, we use compute_ neuron_ head_ The importance API calculates the importance of neurons. And call reorder_neuron_head, rearrange the model parameters according to the importance of neurons.
from paddleslim.nas.ofa.utils import nlp_utils
# Calculating the importance of neurons
head_importance, neuron_importance = nlp_utils.compute_neuron_head_importance(
task_name,
ofa_model.model,
dev_data_loader,
loss_fct=paddle.nn.loss.CrossEntropyLoss(
) if train_ds.label_list else paddle.nn.loss.MSELoss(),
num_layers=model.ppminilm.config['num_hidden_layers'],
num_heads=model.ppminilm.config['num_attention_heads'])
# Reassemble the order of parameters
reorder_neuron_head(ofa_model.model, head_importance, neuron_importance)
Step 6: define the optimizer and evaluator used in distillation training. The optimizer used in distillation training is AdamW and uses paddle nn. Clipgradbyglobalnorm for gradient clipping. The evaluator is' Accuracy '.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# Define optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
beta1=0.9,
beta2=0.999,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params,
grad_clip=nn.ClipGradByGlobalNorm(max_grad_norm))
# Define evaluator
metric = Accuracy()
Tailoring training
In this step, the training of clipping will be carried out. The search space defined here has only a single model [0.75]. After clipping training, the accuracy can be guaranteed on most classification data sets of CLUE.
It can be found that the training of cutting is almost the same as the ordinary distillation process, ofa_ The model contains the teacher model and the current sub model. Call calc_distill_loss() can calculate the mean square error loss between the output of EncoderLayer of student model and teacher model, and calculate the cross entropy loss with the logits of student model and teacher model_ Logit to balance the weights. Then the student model updates the parameters by back propagation according to loss. If width_ mult_ If the list has multiple scales, only the parameters of the current sub model are updated each time, and the parameters of all sub models are shared.
width_mult_list = [0.75]
lambda_logit = 1.0
logging_steps = 100
save_steps = 100
output_dir = './pruned_models/CLUEWSC2020/0.75/best_model'
global_step = 0
best_res = 0.0
num_train_epochs = 50
tic_train = time.time()
for epoch in range(num_train_epochs):
# Set the current epoch and task
ofa_model.set_epoch(epoch)
ofa_model.set_task('width')
for step, batch in enumerate(train_data_loader):
global_step += 1
input_ids, segment_ids, labels = batch
for width_mult in width_mult_list:
# For each width_mult is traversed and the current width is used_ Mult sets the current training sub network in the super network and trains the current sub network
net_config = utils.dynabert_config(ofa_model, width_mult)
ofa_model.set_net_config(net_config)
# Calculate the forward direction of the student model and the teacher model at the same time
logits, teacher_logits = ofa_model(
input_ids, segment_ids, attention_mask=[None, None])
# Calculate the loss of middle layer
rep_loss = ofa_model.calc_distill_loss()
# Using logits of student model and teacher model to calculate cross entropy loss
logit_loss = soft_cross_entropy(logits, teacher_logits.detach())
# The final loss is the sum of the losses caused by the middle layer loss + logits.
loss = rep_loss + lambda_logit * logit_loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % logging_steps == 0:
logger.info(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s"
% (global_step, epoch, step, loss,
logging_steps / (time.time() - tic_train)))
tic_train = time.time()
if global_step % save_steps == 0 or global_step == num_training_steps:
tic_eval = time.time()
evaluate(teacher_model, metric, dev_data_loader, width_mult=100)
print("eval done total : %s s" % (time.time() - tic_eval))
# Sub networks of different widths are evaluated
for idx, width_mult in enumerate(width_mult_list):
net_config = utils.dynabert_config(ofa_model, width_mult)
ofa_model.set_net_config(net_config)
tic_eval = time.time()
res = evaluate(ofa_model, metric, dev_data_loader,
width_mult)
print("eval done total : %s s" % (time.time() - tic_eval))
if best_res < res:
output_dir = output_dir
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
best_res = res
if global_step >= num_training_steps:
break
if global_step >= num_training_steps:
break
print("best_res: ", best_res)
[2022-01-28 15:18:08,169] [ INFO] - global step 100, epoch: 1, batch: 21, loss: 0.105064, speed: 14.88 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.5741927623748779 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7455508708953857 s [2022-01-28 15:18:16,804] [ INFO] - global step 200, epoch: 2, batch: 43, loss: 0.305842, speed: 11.60 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.43573880195617676 s width_mult: 0.75, acc: 0.819078947368421, eval done total : 0.6900777816772461 s [2022-01-28 15:18:25,356] [ INFO] - global step 300, epoch: 3, batch: 65, loss: 0.331153, speed: 11.71 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.48416948318481445 s width_mult: 0.75, acc: 0.8125, eval done total : 0.6980392932891846 s [2022-01-28 15:18:33,080] [ INFO] - global step 400, epoch: 5, batch: 9, loss: 0.043065, speed: 12.96 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4365711212158203 s width_mult: 0.75, acc: 0.8256578947368421, eval done total : 0.697986364364624 s [2022-01-28 15:18:41,518] [ INFO] - global step 500, epoch: 6, batch: 31, loss: 0.037226, speed: 11.87 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4355888366699219 s width_mult: 0.75, acc: 0.8125, eval done total : 0.6854457855224609 s [2022-01-28 15:18:49,361] [ INFO] - global step 600, epoch: 7, batch: 53, loss: 0.040827, speed: 12.77 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4369015693664551 s width_mult: 0.75, acc: 0.7763157894736842, eval done total : 0.7017619609832764 s [2022-01-28 15:18:57,307] [ INFO] - global step 700, epoch: 8, batch: 75, loss: 0.037858, speed: 12.60 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44539570808410645 s width_mult: 0.75, acc: 0.7993421052631579, eval done total : 0.7165935039520264 s [2022-01-28 15:19:05,209] [ INFO] - global step 800, epoch: 10, batch: 19, loss: 0.034154, speed: 12.67 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.443023681640625 s width_mult: 0.75, acc: 0.7894736842105263, eval done total : 0.6999709606170654 s [2022-01-28 15:19:13,000] [ INFO] - global step 900, epoch: 11, batch: 41, loss: 0.037347, speed: 12.85 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.43897581100463867 s width_mult: 0.75, acc: 0.7861842105263158, eval done total : 0.7127141952514648 s [2022-01-28 15:19:20,796] [ INFO] - global step 1000, epoch: 12, batch: 63, loss: 0.031297, speed: 12.84 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44092798233032227 s width_mult: 0.75, acc: 0.7960526315789473, eval done total : 0.697458028793335 s [2022-01-28 15:19:28,672] [ INFO] - global step 1100, epoch: 14, batch: 7, loss: 0.034092, speed: 12.71 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4513673782348633 s width_mult: 0.75, acc: 0.7993421052631579, eval done total : 0.7105143070220947 s [2022-01-28 15:19:36,614] [ INFO] - global step 1200, epoch: 15, batch: 29, loss: 0.032366, speed: 12.61 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4504852294921875 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7143106460571289 s [2022-01-28 15:19:44,787] [ INFO] - global step 1300, epoch: 16, batch: 51, loss: 0.031708, speed: 12.25 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4466538429260254 s width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.7035527229309082 s [2022-01-28 15:19:52,710] [ INFO] - global step 1400, epoch: 17, batch: 73, loss: 0.033588, speed: 12.64 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44365739822387695 s width_mult: 0.75, acc: 0.805921052631579, eval done total : 0.773322582244873 s [2022-01-28 15:20:01,197] [ INFO] - global step 1500, epoch: 19, batch: 17, loss: 0.031626, speed: 11.80 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.45194482803344727 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7937252521514893 s [2022-01-28 15:20:09,254] [ INFO] - global step 1600, epoch: 20, batch: 39, loss: 0.032826, speed: 12.43 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44441723823547363 s width_mult: 0.75, acc: 0.7927631578947368, eval done total : 0.7097764015197754 s [2022-01-28 15:20:17,078] [ INFO] - global step 1700, epoch: 21, batch: 61, loss: 0.029700, speed: 12.81 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4427919387817383 s width_mult: 0.75, acc: 0.8092105263157895, eval done total : 0.7078409194946289 s [2022-01-28 15:20:24,921] [ INFO] - global step 1800, epoch: 23, batch: 5, loss: 0.031197, speed: 12.77 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4403066635131836 s width_mult: 0.75, acc: 0.805921052631579, eval done total : 0.7044663429260254 s [2022-01-28 15:20:33,194] [ INFO] - global step 1900, epoch: 24, batch: 27, loss: 0.031075, speed: 12.11 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.46996545791625977 s width_mult: 0.75, acc: 0.8092105263157895, eval done total : 0.7440495491027832 s [2022-01-28 15:20:41,574] [ INFO] - global step 2000, epoch: 25, batch: 49, loss: 0.030019, speed: 11.95 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4463233947753906 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7100734710693359 s [2022-01-28 15:20:49,539] [ INFO] - global step 2100, epoch: 26, batch: 71, loss: 0.032354, speed: 12.57 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.45970797538757324 s width_mult: 0.75, acc: 0.805921052631579, eval done total : 0.7155802249908447 s [2022-01-28 15:20:57,579] [ INFO] - global step 2200, epoch: 28, batch: 15, loss: 0.034274, speed: 12.45 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44640588760375977 s width_mult: 0.75, acc: 0.8125, eval done total : 0.7163288593292236 s [2022-01-28 15:21:05,496] [ INFO] - global step 2300, epoch: 29, batch: 37, loss: 0.032193, speed: 12.65 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44902658462524414 s width_mult: 0.75, acc: 0.8125, eval done total : 0.7374258041381836 s [2022-01-28 15:21:13,560] [ INFO] - global step 2400, epoch: 30, batch: 59, loss: 0.029288, speed: 12.41 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44863224029541016 s width_mult: 0.75, acc: 0.8125, eval done total : 0.7201321125030518 s [2022-01-28 15:21:21,654] [ INFO] - global step 2500, epoch: 32, batch: 3, loss: 0.029359, speed: 12.37 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44440150260925293 s width_mult: 0.75, acc: 0.8092105263157895, eval done total : 0.7205178737640381 s [2022-01-28 15:21:29,797] [ INFO] - global step 2600, epoch: 33, batch: 25, loss: 0.480859, speed: 12.30 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.47400641441345215 s width_mult: 0.75, acc: 0.8026315789473685, eval done total : 0.9264335632324219 s [2022-01-28 15:21:38,327] [ INFO] - global step 2700, epoch: 34, batch: 47, loss: 0.030747, speed: 11.74 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.48304057121276855 s width_mult: 0.75, acc: 0.8289473684210527, eval done total : 0.7780828475952148 s [2022-01-28 15:21:47,228] [ INFO] - global step 2800, epoch: 35, batch: 69, loss: 0.034642, speed: 11.25 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4455270767211914 s width_mult: 0.75, acc: 0.8256578947368421, eval done total : 0.7098217010498047 s [2022-01-28 15:21:55,208] [ INFO] - global step 2900, epoch: 37, batch: 13, loss: 0.032040, speed: 12.55 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4510841369628906 s width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.7204141616821289 s [2022-01-28 15:22:03,325] [ INFO] - global step 3000, epoch: 38, batch: 35, loss: 0.030037, speed: 12.34 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.5255749225616455 s width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.77712082862854 s [2022-01-28 15:22:11,855] [ INFO] - global step 3100, epoch: 39, batch: 57, loss: 0.029965, speed: 11.74 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44854116439819336 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7175805568695068 s [2022-01-28 15:22:20,477] [ INFO] - global step 3200, epoch: 41, batch: 1, loss: 0.028272, speed: 11.61 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4660167694091797 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7658946514129639 s [2022-01-28 15:22:29,449] [ INFO] - global step 3300, epoch: 42, batch: 23, loss: 0.032405, speed: 11.15 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4678215980529785 s width_mult: 0.75, acc: 0.819078947368421, eval done total : 0.7498805522918701 s [2022-01-28 15:22:38,056] [ INFO] - global step 3400, epoch: 43, batch: 45, loss: 0.029382, speed: 11.64 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4404871463775635 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.6975588798522949 s [2022-01-28 15:22:46,052] [ INFO] - global step 3500, epoch: 44, batch: 67, loss: 0.029915, speed: 12.52 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4386465549468994 s width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.6895158290863037 s [2022-01-28 15:22:53,911] [ INFO] - global step 3600, epoch: 46, batch: 11, loss: 0.030097, speed: 12.75 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.43879246711730957 s width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.6866724491119385 s [2022-01-28 15:23:01,544] [ INFO] - global step 3700, epoch: 47, batch: 33, loss: 0.027487, speed: 13.12 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4383969306945801 s width_mult: 0.75, acc: 0.819078947368421, eval done total : 0.6880450248718262 s [2022-01-28 15:23:09,187] [ INFO] - global step 3800, epoch: 48, batch: 55, loss: 0.031854, speed: 13.11 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4406898021697998 s width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.6892104148864746 s [2022-01-28 15:23:16,862] [ INFO] - global step 3900, epoch: 49, batch: 77, loss: 0.029160, speed: 13.03 step/s width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44138550758361816 s width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.7905969619750977 s best_res: 0.8289473684210527
Export clipping model
After the training of clipping model, we need to load the best model saved before and export it to the static graph model. For model export, we use ofa_ The export method in model is implemented. The main parameters are as follows:
- origin_model: an instance of the original model.
- Config: the configuration of the submodel to be exported. Via ofa get_ current_ Config () or other special configurations, such as paddleslim nas. ofa. utils. dynabert_ config(width_mult).
- input_shapes: all imported shape s.
- input_dtypes: all input dtype s.
- load_weights_from_supernet: whether to import parameters from the Supernet. Default: False.
import paddle.fluid.core as core
width_mult = 0.75
static_sub_model='pruning/pruned_models/CLUEWSC2020/0.75/sub_static/float'
sub_model_output_dir='pruning/pruned_models/CLUEWSC2020/0.75/sub'
# Right ofa_ Set the properties of model so that it can directly export the deployment model
ofa_model = enable_ofa_export(ofa_model)
sd = paddle.load(os.path.join(output_dir, "model_state.pdparams"))
origin_model = PPMiniLMForSequenceClassification.from_pretrained(output_dir)
ofa_model.model.set_state_dict(sd)
best_config = utils.dynabert_config(ofa_model, width_mult)
# Call the export interface of ofa to export the model
origin_model_new = ofa_model.export(
best_config,
input_shapes=[1],
input_dtypes=core.VarDesc.VarType.STRINGS,
origin_model=origin_model)
for name, sublayer in origin_model_new.named_sublayers():
if isinstance(sublayer, paddle.nn.MultiHeadAttention):
sublayer.num_heads = int(width_mult * sublayer.num_heads)
origin_model_new.to_static(static_sub_model)
[2022-01-28 15:23:19,764] [ INFO] - Loaded parameters from ./pruned_models/CLUEWSC2020/0.75/best_model/model_state.pdparams 2022-01-28 15:23:20,090-INFO: Start to get pruned params, please wait... 2022-01-28 15:23:20,539-INFO: Start to get pruned model, please wait... [2022-01-28 15:23:24,986] [ INFO] - Already save the static model to the path pruning/pruned_models/CLUEWSC2020/0.75/sub_static/float
4, Quantification
Quantitative introduction
Quantitative purpose: use INT8 to replace Float32 storage, reduce model volume, reduce model storage space, reduce memory bandwidth requirements, and speed up reasoning.
The quantization in PaddleSlim adopts the method of linear mapping, as shown in the following two figures:
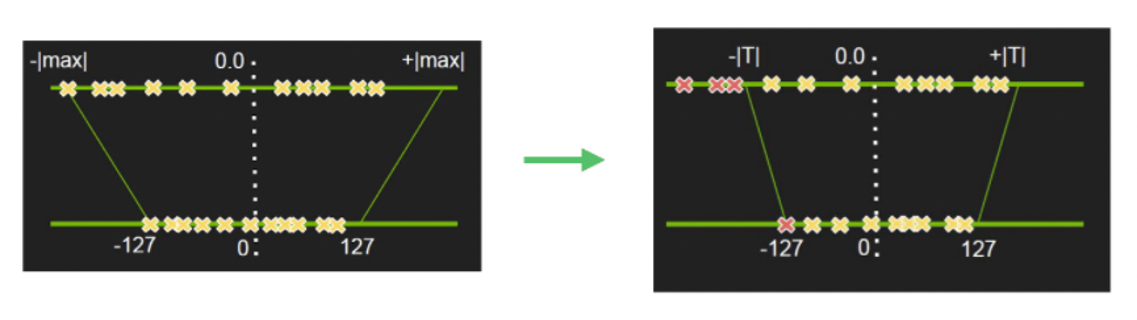
quantification
As shown in the left figure, if | max| = 5, then scale = 127 / 5 = 25.4, then float value 3.0 will be mapped to int(25.4 * 3) = int(76.2) = 76. Therefore, we can see that the core of quantization is to calculate the quantization scale factor.
Quantitative method after training in PP minilm
PP minilm adopts the quantization method after training (static off-line quantization method), that is, the quantization model can be quickly obtained by using only a small amount of calibration data to calculate the quantization factor without training. Generally, the maximum absolute value, mean square error loss and KL divergence loss are used to calculate the quantization Scale factor. In PaddleSlim, mse, avg and ABS are generally used_ Max, hist and other methods quantify the activation of Tensor and channel_wise_abs_max quantifies the weight Tensor.
This step requires a trained prediction (static graph) model. In the last step, we have exported the static graph model.
After training, we can directly use the offline quantization API PaddleSlim provided by PaddleSlim quant. quant_ post_ Static is implemented, and the number of 4 and 8 calibration sets is used to calibrate matmul and matmul_v2 operator for quantization.
Next, for quant_ post_ The parameters in the static API are briefly introduced. Including batch_size is determined by data_loader embodiment.
- quantizable_op_type: the op type to be quantified. For PP minilm, BERT, ERNIE and other models, you can pass in ['matmul ','matmul_v2'], and the default value is ['conv2d ',' depthwise_conv2d ','mul']
- weight_quantize_type: quantification method of weight Tensor, with 'abs_max 'and' channel_wise_abs_max 'two types. Generally speaking, the latter is better. The default value is' channel'_ wise_ abs_max'.
- algo: the method of obtaining scale, which can be 'hist', 'mse' and 'ABS'_ Max ',' KL ', etc
- weight_bits: the number of quantized bits. Here is the quantization of 8 bit s
- data_loader: the pad that generates calibration data io. Dataloader object or a Python Generator.
- hist_percent: when using the 'hist' method, the percentage of the histogram and the average value of the histogram when the statistical quantity reaches 0.9999 * the total number are used as the threshold. Default: 0.9999
- batch_ Num: if it is not None, the number of calibration data is batch_size * batch_nums; If it is None, use all the data generated by the Generator as calibration data.
import paddleslim
algo = 'hist'
input_dir = os.path.dirname(static_sub_model)
quantize_model_path = os.path.join(task_name + '_quant_models', algo, "int8")
save_model_filename = 'int8.pdmodel'
save_params_filename = 'int8.pdiparams'
input_model_filename = 'float.pdmodel'
input_param_filename = 'float.pdiparams'
# It needs to be completed in the static graph mode, and the dynamic graph mode is switched to the static graph mode
paddle.enable_static()
place = paddle.set_device("gpu")
exe = paddle.static.Executor(place)
# Call the interface to directly realize offline quantization in one step
paddleslim.quant.quant_post_static(
exe,
input_dir,
quantize_model_path,
save_model_filename=save_model_filename,
save_params_filename=save_params_filename,
algo=algo,
hist_percent=0.9999,
data_loader=batch_generator,
model_filename=input_model_filename,
params_filename=input_param_filename,
quantizable_op_type=['matmul', 'matmul_v2'],
weight_bits=8,
weight_quantize_type='channel_wise_abs_max',
batch_nums=1, )
algo = 'hist'
input_dir = os.path.dirname(static_sub_model)
quantize_model_path = os.path.join(task_name + '_quant_models', algo)
save_model_filename = 'int8.pdmodel'
save_params_filename = 'int8.pdiparams'
input_model_filename = 'float.pdmodel'
input_param_filename = 'float.pdiparams'
# It needs to be completed in the static graph mode, and the dynamic graph mode is switched to the static graph mode
paddle.enable_static()
place = paddle.set_device("gpu")
exe = paddle.static.Executor(place)
# Call the interface to directly realize offline quantization in one step
paddleslim.quant.quant_post_static(
exe,
input_dir,
quantize_model_path,
save_model_filename=save_model_filename,
save_params_filename=save_params_filename,
algo=algo,
hist_percent=0.9999,
data_loader=batch_generator,
model_filename=input_model_filename,
params_filename=input_param_filename,
quantizable_op_type=['matmul', 'matmul_v2'],
weight_bits=8,
weight_quantize_type='channel_wise_abs_max',
batch_nums=1, )
Fri Jan 28 15:23:24-INFO: Load model and set data loader ... Fri Jan 28 15:23:25-INFO: Collect quantized variable names ... Fri Jan 28 15:23:25-INFO: Preparation stage ... Fri Jan 28 15:23:25-INFO: Run batch: 0 Fri Jan 28 15:23:25-INFO: Finish preparation stage, all batch:1 Fri Jan 28 15:23:25-INFO: Sampling stage ... Fri Jan 28 15:23:28-INFO: Run batch: 0 Fri Jan 28 15:23:28-INFO: Finish sampling stage, all batch: 1 Fri Jan 28 15:23:28-INFO: Calculate hist threshold ... Fri Jan 28 15:23:29-INFO: Update the program ... Fri Jan 28 15:23:33-INFO: The quantized model is saved in cluewsc2020_quant_models/hist/int8 Fri Jan 28 15:23:33-INFO: Load model and set data loader ... Fri Jan 28 15:23:33-INFO: Collect quantized variable names ... Fri Jan 28 15:23:33-INFO: Preparation stage ... Fri Jan 28 15:23:33-INFO: Run batch: 0 Fri Jan 28 15:23:33-INFO: Finish preparation stage, all batch:1 Fri Jan 28 15:23:33-INFO: Sampling stage ... Fri Jan 28 15:23:36-INFO: Run batch: 0 Fri Jan 28 15:23:36-INFO: Finish sampling stage, all batch: 1 Fri Jan 28 15:23:36-INFO: Calculate hist threshold ... Fri Jan 28 15:23:37-INFO: Update the program ... Fri Jan 28 15:23:41-INFO: The quantized model is saved in cluewsc2020_quant_models/hist
5, Forecast
Forecast deployment with the help of PaddlePaddle installation package Paddle Inference Make predictions.
For more obvious acceleration effect, it is recommended to test on NVIDA Tensor Core GPU (such as T4, A10 and A100). If you test on the V series GPU card, because it does not support Int8 Tensor Core, the acceleration effect will not reach the effect in the top table of this tutorial.
After the quantification in the previous step, we have obtained the static graph model, and we can use the cushion influence for predictive deployment. Paddle Inference is the original reasoning Library of the propeller, which acts on the server and cloud and provides high-performance reasoning ability.
Paddle Inference uses predictor to predict. Predictor is a high-performance prediction engine. Through the analysis of calculation diagram,
Complete a series of optimization of the calculation diagram (such as OP fusion, memory / video memory optimization, MKLDNN, TensorRT and other low-level acceleration library support, etc.),
It can greatly improve the prediction performance. In addition, Paddle Inference provides multi language API s such as Python, C + +, GO, etc., which can be selected according to the needs of the actual environment. In order to obtain higher reasoning performance, it is recommended to install and use the prediction library with TensorRT for prediction. Limited by the Paddle version in this tutorial environment, here we only demonstrate the prediction without TensorRT prediction library. You can Paddle Inference Download the reference library in the environment and match it with your own Source code in project Perform TensorRT prediction:
To develop a Python prediction program using paste inference, you only need the following steps:
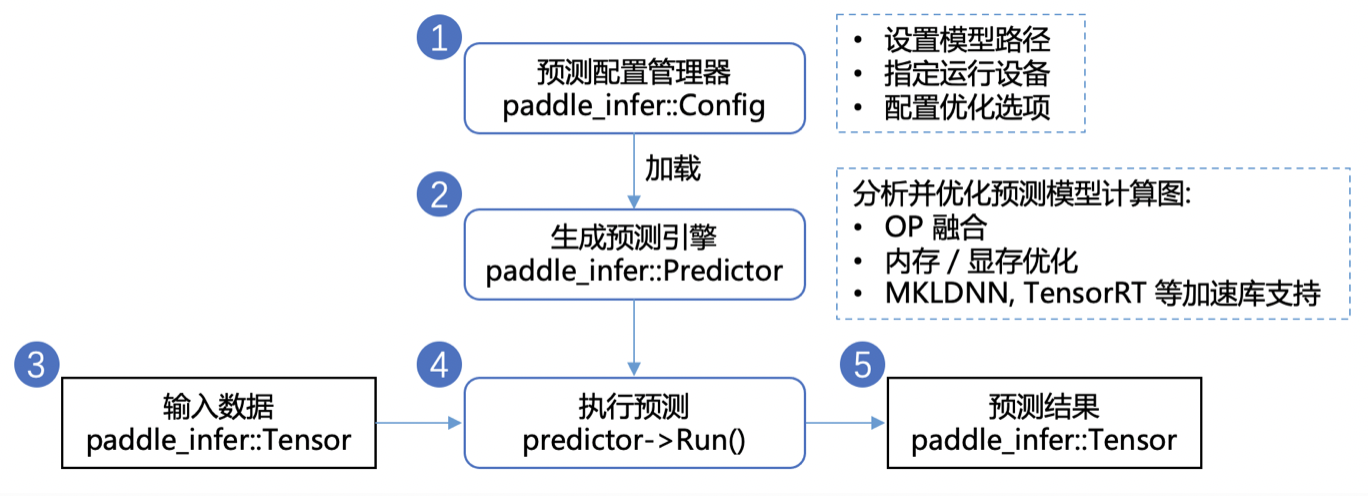
from paddle import inference
use_trt = True
collect_shape = True
batch_size = 32
# 1. Create configuration object and set prediction model path
config = inference.Config(os.path.join(quantize_model_path, save_model_filename), os.path.join(quantize_model_path, save_params_filename))
# Enable GPU for prediction - initialize GPU video memory 100M, Deivce_ID is 0
config.enable_use_gpu(100, 0)
# 2. Create an inference engine according to the configuration content
predictor = inference.create_predictor(config)
# 3. Set input data
# Get input handle
input_handles = [
predictor.get_input_handle(name)
for name in predictor.get_input_names()
]
# Get input data
dev_ds = load_dataset("clue", task_name, splits="dev")
trans_func = partial(
convert_example, label_list=dev_ds.label_list, is_test=False)
dev_ds = dev_ds.map(trans_func, lazy=True)
data = [[dev_ds[0]['sentence']]]
# Set input data
for input_field, input_handle in zip(data, input_handles):
print(input_field)
input_handle.copy_from_cpu(input_field)
# 4. Execute forecast
predictor.run()
# 5. Obtain prediction results
# Get output handle
output_handles = [
predictor.get_output_handle(name)
for name in predictor.get_output_names()
]
# Get prediction result from output handle
output = [output_handle.copy_to_cpu() for output_handle in output_handles]
print(output)
W0128 15:23:41.411352 236 analysis_predictor.cc:795] The one-time configuration of analysis predictor failed, which may be due to native predictor called first and its configurations taken effect. [1m[35m--- Running analysis [ir_graph_build_pass][0m [1m[35m--- Running analysis [ir_graph_clean_pass][0m [1m[35m--- Running analysis [ir_analysis_pass][0m [32m--- Running IR pass [is_test_pass][0m [32m--- Running IR pass [simplify_with_basic_ops_pass][0m [32m--- Running IR pass [conv_affine_channel_fuse_pass][0m [32m--- Running IR pass [conv_eltwiseadd_affine_channel_fuse_pass][0m [32m--- Running IR pass [conv_bn_fuse_pass][0m [32m--- Running IR pass [conv_eltwiseadd_bn_fuse_pass][0m [32m--- Running IR pass [embedding_eltwise_layernorm_fuse_pass][0m I0128 15:23:41.686870 236 fuse_pass_base.cc:57] --- detected 1 subgraphs [32m--- Running IR pass [multihead_matmul_fuse_pass_v2][0m [32m--- Running IR pass [squeeze2_matmul_fuse_pass][0m [32m--- Running IR pass [reshape2_matmul_fuse_pass][0m [32m--- Running IR pass [flatten2_matmul_fuse_pass][0m [32m--- Running IR pass [map_matmul_v2_to_mul_pass][0m I0128 15:23:41.696921 236 fuse_pass_base.cc:57] --- detected 38 subgraphs [32m--- Running IR pass [map_matmul_v2_to_matmul_pass][0m I0128 15:23:41.698750 236 fuse_pass_base.cc:57] --- detected 6 subgraphs [32m--- Running IR pass [map_matmul_to_mul_pass][0m [32m--- Running IR pass [fc_fuse_pass][0m [32m--- Running IR pass [fc_elementwise_layernorm_fuse_pass][0m [32m--- Running IR pass [conv_elementwise_add_act_fuse_pass][0m [32m--- Running IR pass [conv_elementwise_add2_act_fuse_pass][0m [32m--- Running IR pass [conv_elementwise_add_fuse_pass][0m [32m--- Running IR pass [transpose_flatten_concat_fuse_pass][0m [32m--- Running IR pass [runtime_context_cache_pass][0m [1m[35m--- Running analysis [ir_params_sync_among_devices_pass][0m I0128 15:23:41.722019 236 ir_params_sync_among_devices_pass.cc:45] Sync params from CPU to GPU [1m[35m--- Running analysis [adjust_cudnn_workspace_size_pass][0m [1m[35m--- Running analysis [inference_op_replace_pass][0m [1m[35m--- Running analysis [ir_graph_to_program_pass][0m I0128 15:23:42.005632 236 analysis_predictor.cc:714] ======= optimize end ======= I0128 15:23:42.015040 236 naive_executor.cc:98] --- skip [feed], feed -> text I0128 15:23:42.019754 236 naive_executor.cc:98] --- skip [linear_151.tmp_1], fetch -> fetch ['Some of these“_Foreigners_"Standing among the public, like standing out of the crowd, he made no secret of his sense of superiority.[they]Behind the extraordinary nail dish basin, although the number is very few, it is particularly eye-catching.'] [array([[ 3.7948644, -4.1197 ]], dtype=float32)]
The source code of this project is all open source PaddleNLP Yes.
If it helps you, welcome ⭐ ️ star ⭐ Collect it. It's not easy to lose it! Link directions: https://github.com/PaddlePaddle/PaddleNLP

Join Wechat exchange group and learn together
Add a small assistant wechat, reply to "NLP", and immediately join the PaddleNLP technology exchange group to exchange NLP technology together!
