preface
As a new generation of contemporary youth, should they be more or less able to make short videos?

Haha, what about the creators of contemporary we media~
When making videos, how much do you need some funny sounds? Or strange sounds? Music, etc~
How slow it is to download one by one, let's use python to realize batch download today~
Environment / module / objective
1. Target
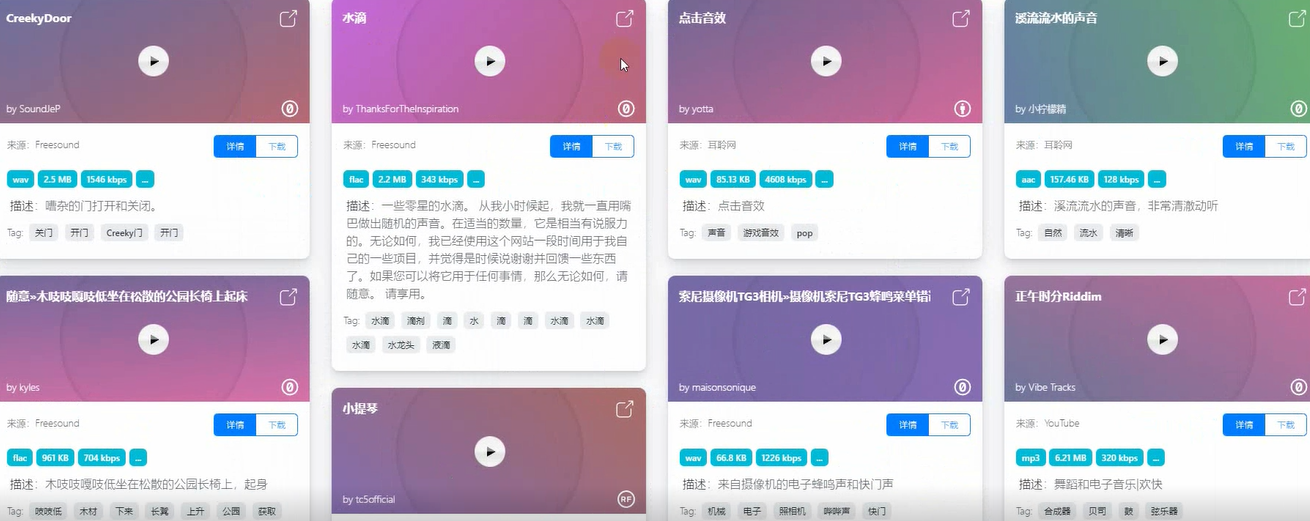
2. Development environment
Brothers, if you just learn Python, don't install some other software, just install these two~
Python environment Pycharm editor
3. Module
These two modules are mainly used this time
requests # Data request module re # regular expression module
Process explanation
This time I write the process in detail, which Xiaobai can understand. After reading it, you remember Sanlian. Give me some motivation to create, hehe~

First, we open the website and right-click to select check
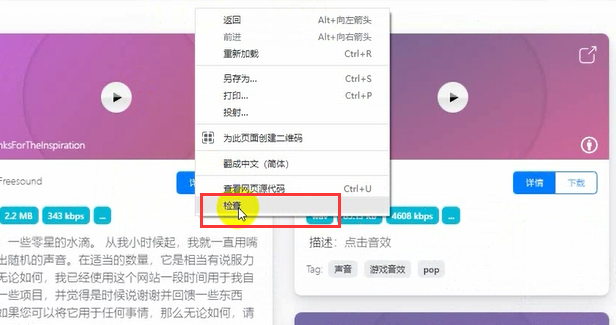 Select network, refresh the page, slide down, and a page-4 and page-5 will appear.
Select network, refresh the page, slide down, and a page-4 and page-5 will appear.
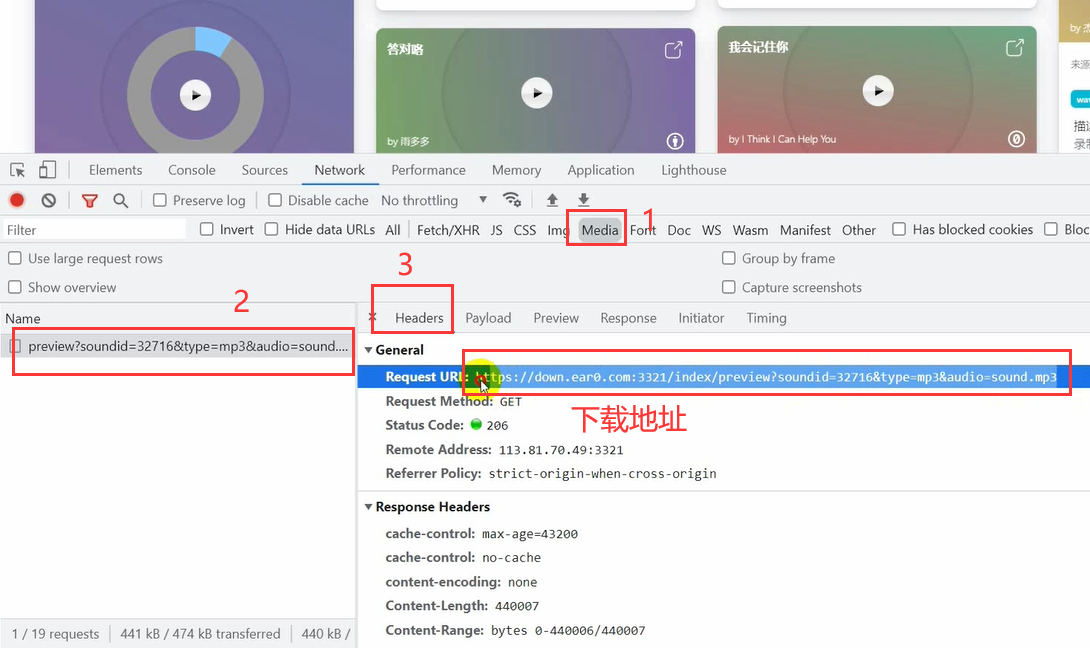
 A lot of data on these two pages are directly available here. We can find one and click play, and then click media. There will be an audio file in the headers, which is the download address I marked.
A lot of data on these two pages are directly available here. We can find one and click play, and then click media. There will be an audio file in the headers, which is the download address I marked.
 It can be played or downloaded directly
It can be played or downloaded directly
 What if you want to get this address?
What if you want to get this address?
We directly copy this string of numbers, such as 32716, and then click the search box in the upper left corner to search.
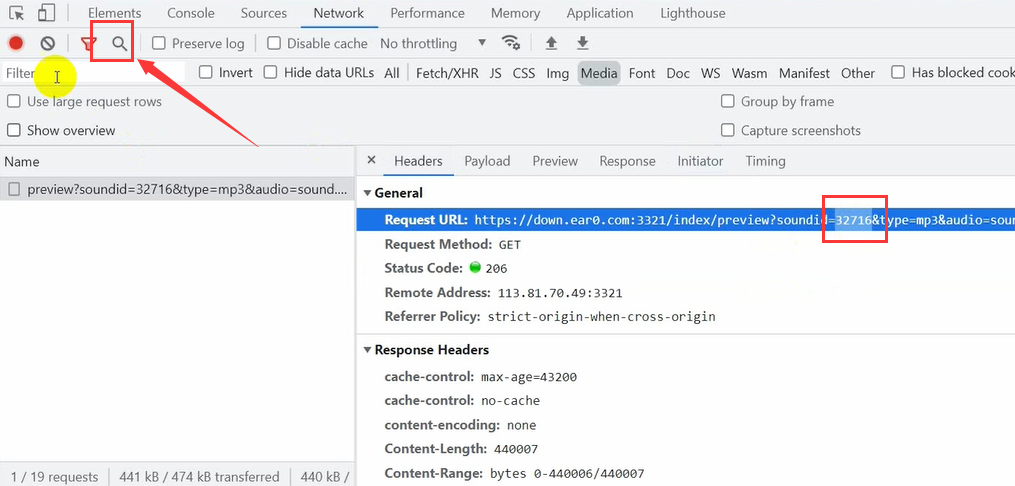 After searching, we can see the audio link address on page-5.
After searching, we can see the audio link address on page-5.
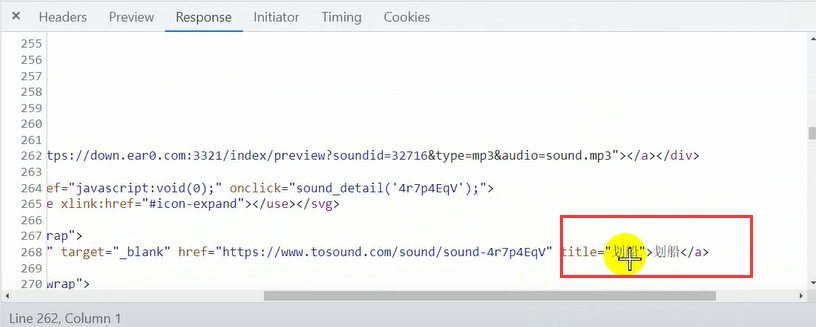
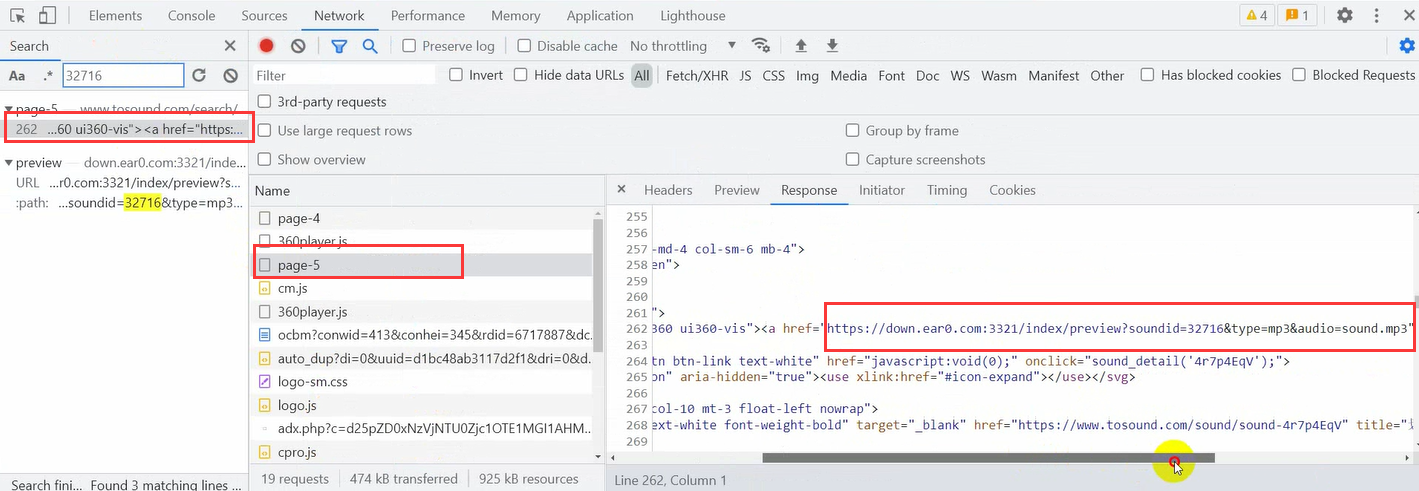 Audio titles can also be found here
Audio titles can also be found here
Then we click headers and send the request directly to the url address.
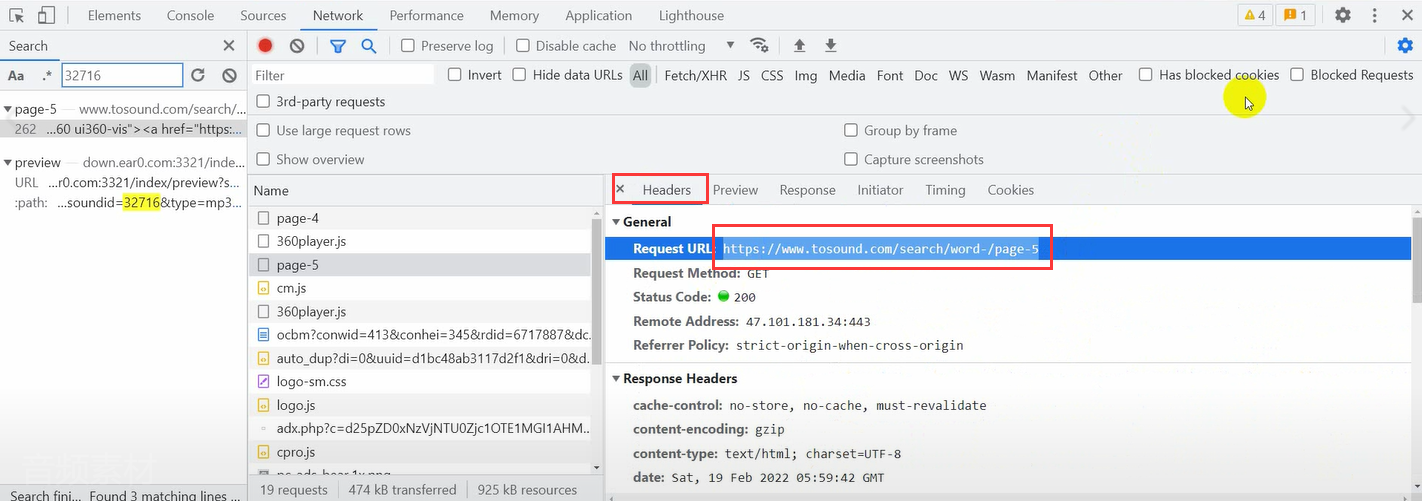
First, import the requests module
import requests
The url is just the link
url = 'https://Manually replace / search/word-/page-5 '
Then we add a header to disguise it
Here, just copy the contents of user agent under headers directly
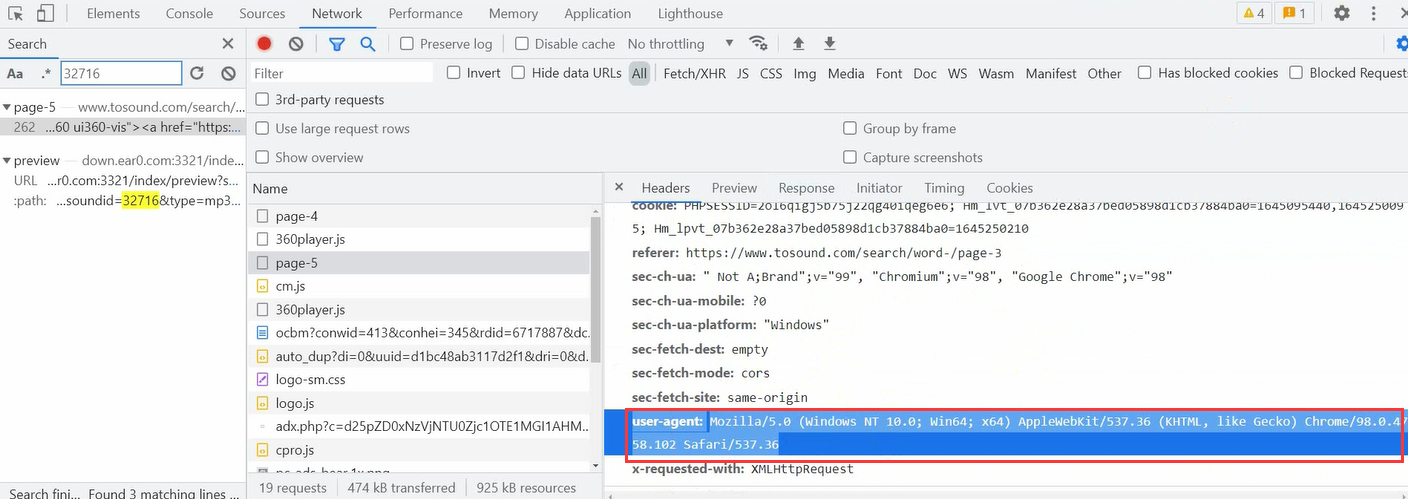 Remember to put quotation marks
Remember to put quotation marks
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
Then send the request, print it and see the result
response = requests.get(url=url, headers=headers) print(response.text)
There are too many printed contents. We directly search MP3 on it and locate it accurately. Its title is in the link below the MP3 file.
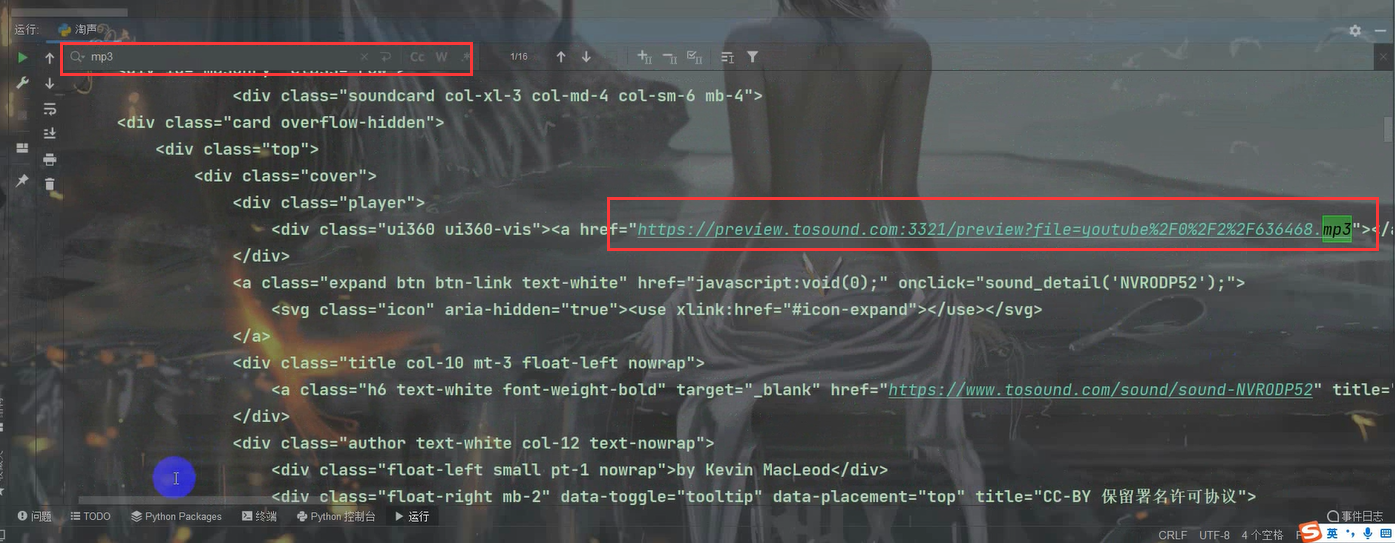 Then we copy it, use regular to match the content in the middle, and the url in the middle is (. *?) Replace.
Then we copy it, use regular to match the content in the middle, and the url in the middle is (. *?) Replace.
Import the re module first
import re
Just copied that content,. *? Enclose in parentheses.
From response Text, and play is used for the matched content_ url_ The list variable receives.
play_url_list = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>', response.text)
Then print it to see if it matches
print(play_url_list)
You can see that the mp3 file is directly matched, which is included in a list.
 Then we also need its title and name, and copy the same.
Then we also need its title and name, and copy the same. Still the same operation, replace the url and name with. *?
Still the same operation, replace the url and name with. *?
From response Text, and name is used for the matched content_ The list variable receives.
name_list = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?</a>', response.text)
Print it
print(name_list)
You can see the name and these data have been obtained.
 Traverse it, package the obtained data together, and then extract it one by one to obtain its binary data content, and use MP3_ Accept the variable content
Traverse it, package the obtained data together, and then extract it one by one to obtain its binary data content, and use MP3_ Accept the variable content
for play_url, name in zip(play_url_list, name_list):
mp3_content = requests.get(url=play_url, headers=headers).content
Then save it directly, with open, give it the name of a folder, add the name, and add mp3 suffix, save mode = wb, use the variable f.write to receive mp3_content
with open('Sound effect\\' + name + '.mp3', mode='wb') as f:
f.write(mp3_content)
We didn't create a folder automatically here, so we need to create a folder manually and write in your name.
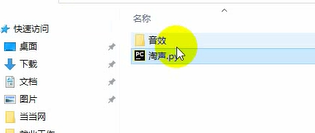
Then we print it and see the results.
print(name)
 The relevant data content is saved in the folder you created
The relevant data content is saved in the folder you created
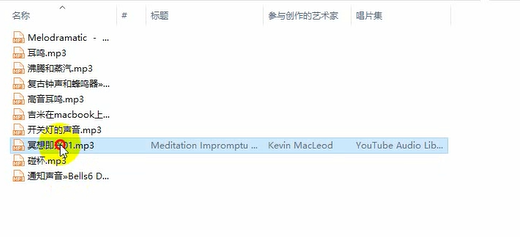
Note: all URLs should be replaced manually. I'll delete them here, otherwise they will be killed by mistake
All codes
import requests
import re
url = 'https://Here you can replace / search/word-/page-5 '
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
play_url_list = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>', response.text)
name_list = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?</a>', response.text)
print(play_url_list)
print(name_list)
for play_url, name in zip(play_url_list, name_list):
mp3_content = requests.get(url=play_url, headers=headers).content
with open('Sound effect\\' + name + '.mp3', mode='wb') as f:
f.write(mp3_content)
print(name)
Brothers, that's all for today's sharing. Slip away~
Remember to praise the collection and give me motivation~
