brief introduction
The architecture with microservices does not represent good performance, but the architecture using microservices must require good performance. This sentence is not contradictory. The contradiction is that many people think that microservice architecture represents high concurrency, but it is not. We have the theory of "written micro service" and "actual micro service". For example, a large number of people on the Internet teach to change the timeout of httpConnection or FeignClient to 30 seconds so that it won't time out? What kind of micro service do you want? What exactly does microservice solve?
Most people forget what the essence of microservices is to solve.
There are six seconds for Internet applications at the To C end, that is, the opening and loading process of a small program / APP application is more than six seconds. It is certain that new users will not use it again. Four seconds is the average level. Generally, large manufacturers load the page for one second.
You should know that if any "query" page is opened for one second, there may be thousands or tens of thousands of APIs in the whole station. Sometimes a page needs to be combined through dozens of APIs. Therefore, the requirement of our Internet community for APIs in the system is that "when one API needs to be in the case of 10000 level concurrency at the front end + the data volume of tens of millions of data in each single table of the system, the response time is within 100 milliseconds".
This is the origin of the one second theory.
- To C-end interface is loaded for 1 second;
- Any micro service (instant response class) should be within 100 milliseconds
This is because there will be many calls such as outreach, callback, map, distribution and payment in your application. They will cause "cascading avalanche" to our applications.
In order to avoid the avalanche of complex system, it is necessary to "fuse, limit current, rise and fall" in time. This is the essence of microservices.
If you have used the microservice architecture and actually find that there is always timeout here, many people blindly prolong the connection time and think it will be solved.
Such people account for more than 90% (according to industry statistics).
Therefore, the use of microservices means that the level of skills required for development is higher. Anything that can improve 100 milliseconds is worth doing.
In the microservice architecture, a philosophy is particularly emphasized: "don't do it with good and small, and suddenly do it with evil and small".
Redis writes a lot of data in the for loop
Usually, we often encounter the need to write thousands or tens of thousands of data into Redis at one time. In Internet application scenarios, we often plug millions or tens of millions of data into Redis, such as Redis Bloom.
The classic way of writing is as follows:
@Test
public void testForLoopAddSingleString() throws Exception {
long startTime = System.currentTimeMillis();
String redisValue = "";
for (int i = 0; i < 10000; i++) {
StringBuilder redisKey = new StringBuilder();
redisKey.append("key_").append(i);
redisValue = String.valueOf(i);
redisTemplate.opsForValue().set(redisKey.toString(), redisValue);
}
long endTime = System.currentTimeMillis();
long costTime = endTime - startTime;
logger.info(">>>>>>test batch add into redis by using normal for loop spent->" + costTime);
}
After operation, the following outputs are obtained:

Come on man, this is only 10000 pieces of data. It takes 4.7 seconds to insert Redis.
I use a server that I have been using to simulate tens of millions of data. The performance of this server is several times better than that of the company's production server. It takes 4.7 seconds to insert 10000 pieces of data into such a server. In production, we also include the network overhead of reading, storing and writing Redis. In fact, it will only be slower. This efficiency is intolerable.
Enhanced version writing - Redis Piepeline writing
We don't need to add any third-party packages to Redis's "write operation". We bring a "permanently valid" write accelerator with the following code:
@Test
public void testPipelineAddSingleString() throws Exception {
RedisSerializer<String> keySerializer = (RedisSerializer<String>)redisTemplate.getKeySerializer();
RedisSerializer<Object> valueSerializer = (RedisSerializer<Object>)redisTemplate.getValueSerializer();
long startTime = System.currentTimeMillis();
redisTemplate.executePipelined((RedisCallback<Object>)pipeLine -> {
try {
String redisValue = "";
for (int i = 0; i < 10000; i++) {
StringBuilder redisKey = new StringBuilder();
redisKey.append("key_").append(i);
redisValue = String.valueOf(i);
pipeLine.setEx(keySerializer.serialize(redisKey.toString()), 10,
valueSerializer.serialize(redisValue));
}
} catch (Exception e) {
logger.error(">>>>>>test batch add into redis by using pipeline for loop error: " + e.getMessage(), e);
}
return null;
});
long endTime = System.currentTimeMillis();
long costTime = endTime - startTime;
logger.info(">>>>>>test batch add into redis by using pipeline for loop spent->" + costTime);
}Let's look at this way of writing. You can think that this way of writing is the same as when the update table set field=value nested in the for loop becomes a combined batchUpdate. Take a look at the difference in efficiency brought by this way of writing:

Oh My God. . . There is a little difference in writing.
4745 MS VS 564 MS, I'll call it 600 ms, but how much is it? Think about it.
The following also gives the corresponding batch writing Redis writing method of simple Hash structure
We want to insert such a structure into Hash
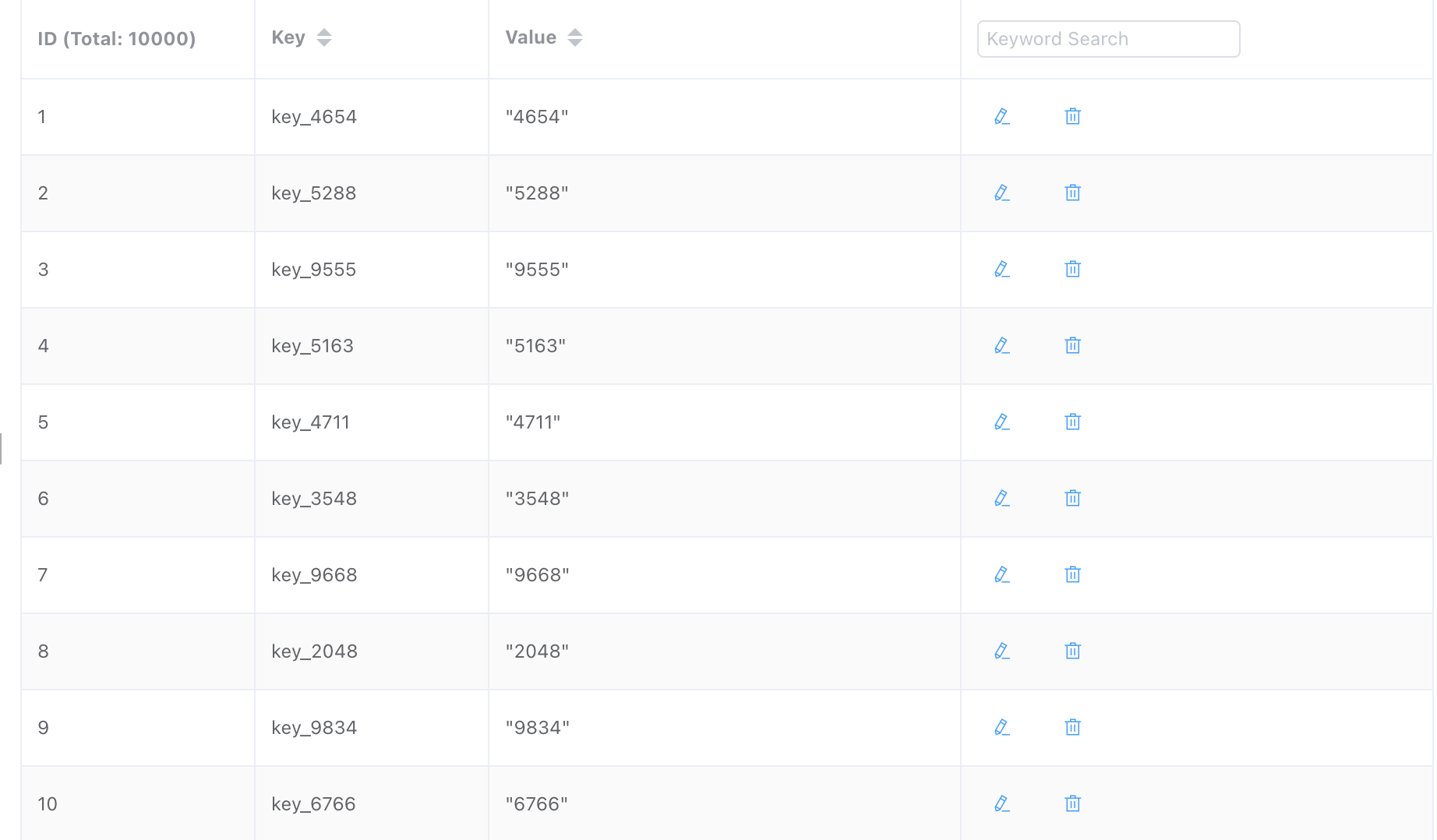
@Test
public void testPipelineAddHash() throws Exception {
RedisSerializer<String> keySerializer = (RedisSerializer<String>)redisTemplate.getKeySerializer();
RedisSerializer<Object> valueSerializer = (RedisSerializer<Object>)redisTemplate.getValueSerializer();
long startTime = System.currentTimeMillis();
String hashKey = "pipeline_hash_key";
redisTemplate.executePipelined((RedisCallback<Object>)pipeLine -> {
try {
String redisValue = "";
for (int i = 0; i < 10000; i++) {
StringBuilder redisKey = new StringBuilder();
redisKey.append("key_").append(i);
redisValue = String.valueOf(i);
pipeLine.hSet(keySerializer.serialize(hashKey), keySerializer.serialize(redisKey.toString()),
valueSerializer.serialize(redisValue));
}
} catch (Exception e) {
logger.error(">>>>>>testPipelineAddHash by using pipeline for loop error: " + e.getMessage(), e);
}
return null;
});
long endTime = System.currentTimeMillis();
long costTime = endTime - startTime;
logger.info(">>>>>>testPipelineAddHash by using pipeline for loop spent->" + costTime);
}
It took only about 500 milliseconds.
How to batch insert complex type Hash into Redis
As follows, 10000 JavaBean s exist in Redis in Hash structure.
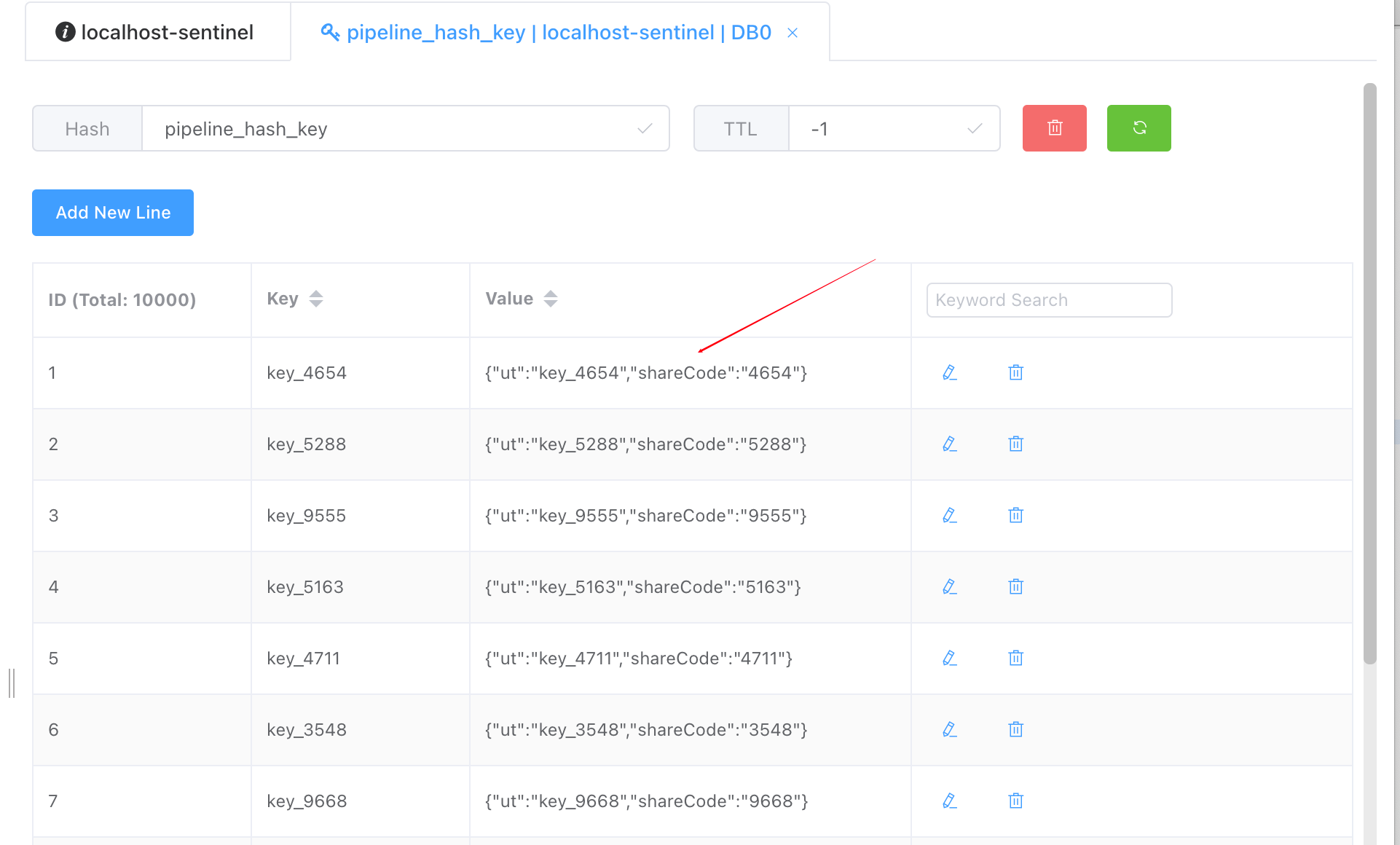
@Test
public void testPipelineAddHashBean() throws Exception {
RedisSerializer<String> keySerializer = (RedisSerializer<String>)redisTemplate.getKeySerializer();
Jackson2JsonRedisSerializer jacksonSerial = new Jackson2JsonRedisSerializer<>(Object.class);
long startTime = System.currentTimeMillis();
String hashKey = "pipeline_hash_key";
redisTemplate.executePipelined((RedisCallback<Object>)pipeLine -> {
try {
String redisValue = "";
for (int i = 0; i < 10000; i++) {
StringBuilder redisKey = new StringBuilder();
redisKey.append("key_").append(i);
redisValue = String.valueOf(i);
UserBean user = new UserBean();
user.setUt(redisKey.toString());
user.setShareCode(redisValue);
pipeLine.hSet(keySerializer.serialize(hashKey), keySerializer.serialize(redisKey.toString()),
jacksonSerial.serialize(user));
}
} catch (Exception e) {
logger.error(">>>>>>testPipelineAddHash by using pipeline for loop error: " + e.getMessage(), e);
}
return null;
});
long endTime = System.currentTimeMillis();
long costTime = endTime - startTime;
logger.info(">>>>>>testPipelineAddHash by using pipeline for loop spent->" + costTime);
}
About 400 milliseconds (sometimes 600 milliseconds, sometimes 400 milliseconds, mostly within 400 milliseconds)
Pipeline like writing method in Redis Bloom filter
Similarly, if the amount of values fed into the Redis Bloom filter is larger, the faster the feeding, the shorter the "black window period" during Bloom interception, which is more beneficial to the system. Therefore, it also has the same good method of batch writing, as shown in the following code:
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper Cannot be empty");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
BitFieldSubCommands commands = BitFieldSubCommands.create();// Using the merge writing method, it is assumed that 100000 pieces of data take 12 seconds for a for
for (int i : offset) {
commands = commands.set(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(i).to(1);// Merge bit
}
redisTemplate.opsForValue().bitField(key, commands);// Write redis again
}100000 data in 45 seconds

If the traditional writing method is used, such as the following code, it is the traditional writing method
public <T> void addByBloomFilterSingleFor(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper Cannot be empty");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}100000 data in 455 seconds

Summary
Think back to the last article I wrote in Micro service design guidance - use cloud native micro services to solve the "cascade avalanche" and efficiency between systems caused by traditional massive batch running
An example mentioned in: when you upload 30000 small files of 10K and 20K each to a hundred online disks, it takes several hours to package these 30000 small files into a zip, upload them at one time, and upload them in a few minutes.
This is the fatal efficiency improvement caused by saving steps in network I/O reading and writing.