Multithreading application
- Multithreading
-
- 1. What is a thread?
-
- 1.1 basic concept of task scheduling
- 1.2 basic relationship between process and thread
- 1.3 basic relationship between multithreading and multi-core
- 2. Why use multithreading?
-
- 2.1. Application of concurrent scenarios
-
- 2.1.1 I/O bound
-
- 2.1.1.1 application of single karyotype
- 2.1.2 CPU intensive program (CPU bound)
-
- 2.1.2.1 single karyotype
- 2.1.2.2 multikaryotype (parallel)
- 2.2. Is the more threads the better
-
- 2.2.1 how many threads are suitable for CPU intensive programs?
- 2.2.2 how many threads are appropriate for I/O-Intensive programs?
- 2.2.3 can the problem be solved by increasing the number of CPU cores?
- 3. What is a thread pool
-
- 3.1 background
- 3.2 definition
- 3.3 application scenario
- 3.4 implementation of simple thread pool
- reference resources
Multithreading
1. What is a thread?
1.1 basic concept of task scheduling
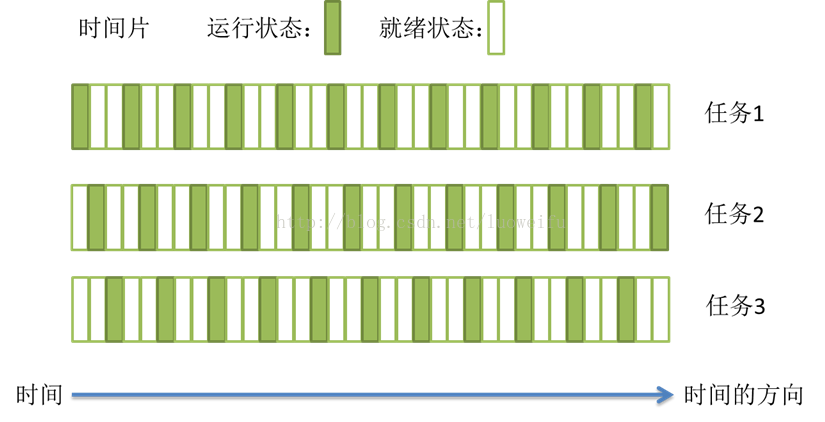
- The task scheduling of most operating systems (such as Windows and Linux) adopts the preemptive scheduling mode of time slice rotation;
- A short period of time when a task is executed is called a time slice, and the state when the task is executing is called running state.
- After a task is executed for a short period of time, it is forced to suspend to execute the next task, and each task is executed in turn.
- After a task is executed for a period of time, it is forced to pause to execute the next task. The suspended task is in a ready state and waits for the arrival of the next time slice that belongs to it. In this way, each task can be executed. Because the execution efficiency of CPU is very high and the time slice is very short, switching between tasks quickly gives the impression that multiple tasks are "carried out at the same time", which is what we call concurrency.
- Concurrency: multiple tasks are executed at the same time
1.2 basic relationship between process and thread
A simple explanation of process and thread
With the development of computer, the requirement of CPU is higher and higher, and the difference between processes** Switching overhead **Larger. So thread was invented. Thread is a single sequential control process in program execution, the smallest unit of program execution flow, and the basic unit of processor scheduling and dispatching. A process can have one or more threads, and each thread shares the memory space of the program (that is, the memory space of the process)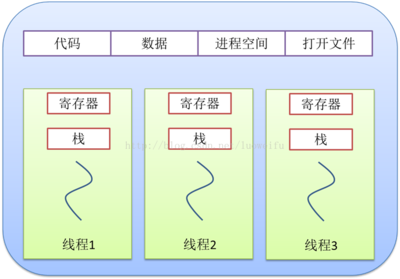
- All threads in a process share not only global variables, but also process instructions, most data, open files (such as description words), signal handlers and signal processing, current working directory, user ID and group ID.
- Each thread has its own thread ID, register set (including program counter and stack pointer), stack (used to store local variables and return address), error, signal mask and priority.
1.3 basic relationship between multithreading and multi-core
1. Multi core processor:
- Integrate multiple computing cores on a processor to improve computing power, that is, there are multiple processing cores for real parallel computing, and each processing core corresponds to a kernel thread.
- Kernel Thread (KLT) is a thread directly supported by the operating system kernel. This thread is switched by the kernel. The kernel schedules the thread through the operation scheduler and is responsible for mapping the task of the thread to each processor.
- Generally, a processing core corresponds to one kernel thread. For example, a single core processor corresponds to one kernel thread, a dual core processor corresponds to two kernel threads, and a four core processor corresponds to four kernel threads.
2. Hyper threading technology
Using special hardware instructions, a physical chip is simulated into two logic processing cores, so that a single processor can use thread level parallel computing, which is compatible with multi-threaded operating system and software, reduces the idle time of CPU and improves the operation efficiency of CPU. This hyper threading technology (such as dual core four threads) is determined by the processor hardware
3. User thread (LWP):
- Generally, programs do not directly use kernel threads, but use a high-level interface of kernel threads - Lightweight Process (LWP). Lightweight Process is what we usually call thread (we call it user thread here).
- Since each lightweight process is supported by a kernel thread, there can be a lightweight process only if the kernel thread is supported first. The first mock exam is the first mock exam, the three to one model, the many to many model. ( reference resources)
1, the first mock exam model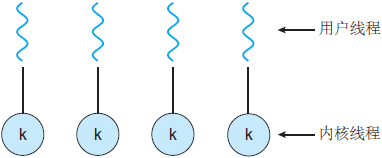
2, the first mock exam model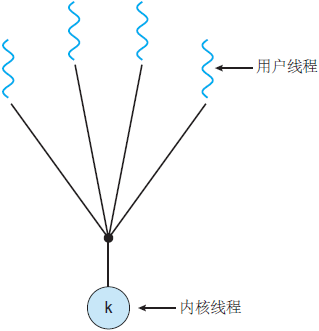
3. Many to many model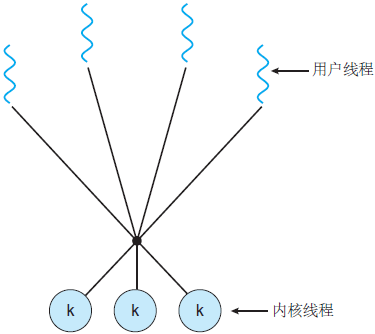
2. Why use multithreading?
The reason for choosing multithreading is the word "fast". Using multithreading is to maximize the running speed of the program by setting the correct number of threads in the right scenario.
- Make full use of CPU and I/O utilization
- A reasonable scenario + a reasonable number of threads} can improve the operation efficiency.
For example:
Multithreading is used for stacking processing, just like a large mound. One bulldozer is very slow, so 10 bulldozers can handle it together. Of course, the speed is faster. However, due to the limitation of location, if there are 20 bulldozers, they will avoid each other, rub each other and crowd each other. Instead, it is not as good as 10. Therefore, multithreading processing, The proper number of threads can improve efficiency.
The specific reasons focus on the following two levels:
- 1. Compared with processes, multithreading is a very cost-effective, fast switching and more "frugal" multitasking operation mode.
- Under the Linux system, starting a new process must allocate its independent address space and establish many data tables to maintain its code segments, stack segments and data segments, which is an "expensive" multitasking mode of work.
- Multiple threads running in a process use the same address space and share most of the data with each other. The space spent on starting a thread is far less than that spent on starting a process,
- Moreover, the time required for threads to switch to each other is far less than that required for processes to switch.
- 2. Convenient communication mechanism.
- For different processes, they have independent data space. Data transmission can only be carried out through communication. This method is not only time-consuming, but also very inconvenient.
- Threads are not. Because threads in the same process share data space, the data of one thread can be directly used by other threads, which is not only fast, but also convenient.
- Of course, data sharing also brings some other problems. Some variables cannot be modified by two threads at the same time, and the data declared as static in some subroutines is more likely to bring a disastrous blow to multithreaded programs. These are the most important points to pay attention to when writing multithreaded programs.
2.1. Application of concurrent scenarios
- 1. Common browsers, web services (now written web middleware helps you complete thread control), web processing requests, and various special servers (such as game servers)
- 2. servlet multithreading
- 3. FTP download, multi thread operation file
- 4. Multithreading used in database
- 5. Distributed computing
- 6, tomcat, tomcat uses multithreading, hundreds of clients access the same WEB application. After tomcat access, the subsequent processing is thrown to a new thread. The new thread finally calls our servlet program, such as doGet or dpPost.
- 7. Background tasks: such as sending emails to a large number of users (above 100W) regularly; Regularly update the configuration file and task scheduling (such as quartz), and some monitoring are used for regular information collection
- 8. Automatic job processing: such as regular backup of logs and database
- 9. Asynchronous processing: such as microblogging and logging
- 10. Asynchronous processing of pages: such as checking a large amount of data (there are 100000 mobile phone numbers, check which are existing users)
- 11. Data analysis of database (too much data to be analyzed), data migration
- 12. For multi-step task processing, threads with different numbers and characteristics can be selected for collaborative processing according to the characteristics of steps. The segmentation of multi tasks is completed by dividing one main thread into multiple threads
...
2.1.1 I/O bound
1. Definition
Frequent network transmission, reading hard disk and other io devices, etc
- Tasks involving network and disk IO are IO intensive tasks
2. Characteristics
This kind of task is characterized by low CPU consumption, and most of the time of the task is waiting for IO operation to complete (because the speed of IO is much lower than that of CPU and memory). For IO intensive tasks, the more tasks, the higher CPU efficiency, but there is also a limit.
2.1.1.1 application of single karyotype
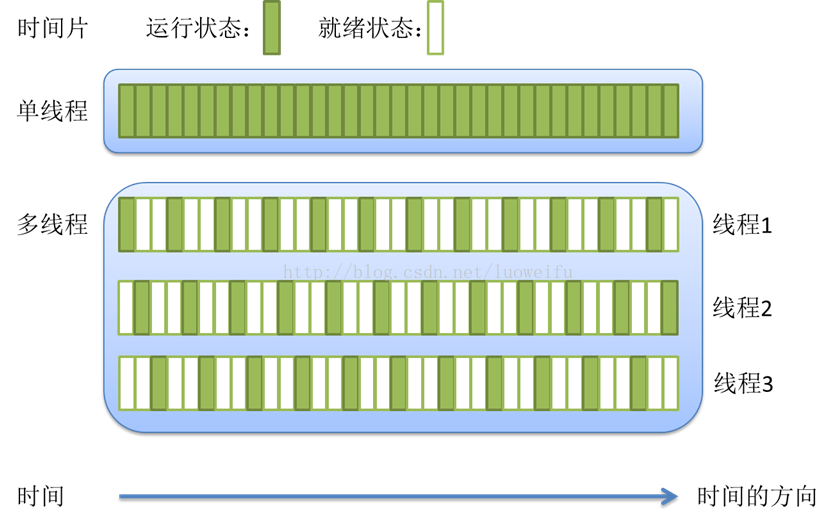
During I/O operations, the CPU is idle, so we should maximize the use of the CPU and not make it idle.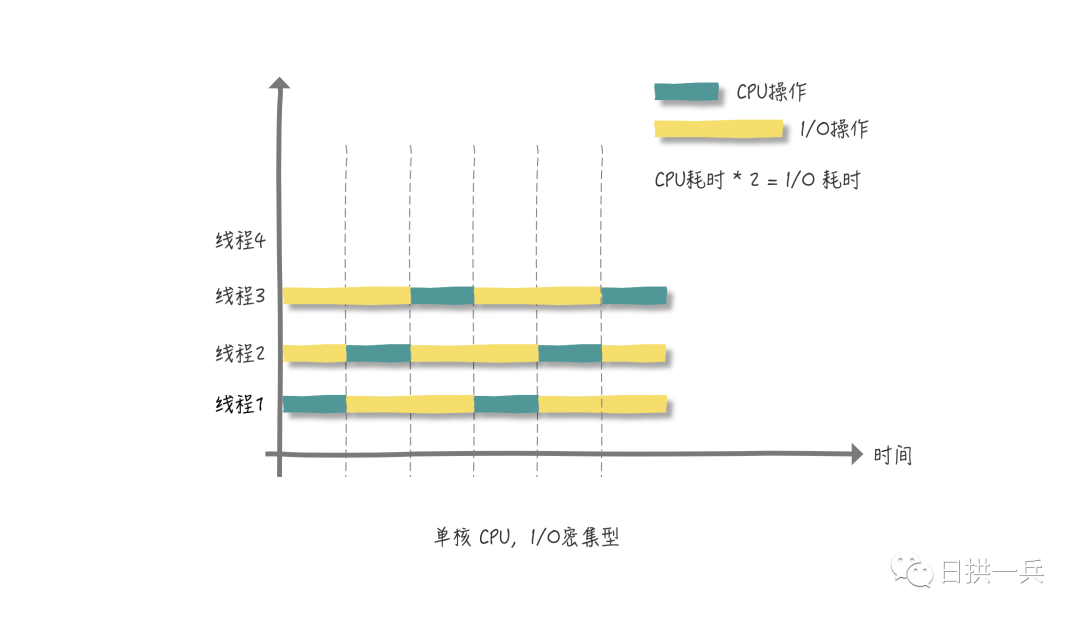
As can be seen from the above figure, each thread executes the same length of CPU time and I/O time. If you draw more cycles in the above figure, the CPU operation time is fixed, and change the I/O operation time to three times the CPU time, you will find that the CPU is free again. At this time, you can continue to maximize the utilization of CPU by creating a new thread 4.
2.1.2 CPU intensive program (CPU bound)
1. Definition
- Most of the program systems are doing calculation, logic judgment and circulation, which leads to high cpu occupancy, which is called computing intensive;
- For example, a program that calculates the PI to less than 1000 decimal places and spends most of its time in the calculation of trigonometric functions and open radicals is a program that belongs to CPU bound.
2. Characteristics
- Generally speaking, the CPU utilization rate of CPU bound programs is quite high. This may be because the task itself does not need to access the I/O device, or because the program is a multi-threaded implementation, which shields the time waiting for I/O.
- Just like your brain is a CPU, you are already doing your homework in one mind. Multithreading requires you to write your homework, then type the code immediately, then look at a picture in P, then watch a video, and then switch back to your homework. In the process, you still need to switch (put away your homework, take out the computer, turn on VS...) then your homework may be written to the failing course... Multithreading is not suitable at this time.
2.1.2.1 single karyotype
If we want to calculate , 1 + 2 + The sum of 10 billion} is obviously a CPU intensive program
Under the [single core] CPU, if we create four threads to calculate in segments, that is:
- Thread 1 computing [125 million)
- ... and so on
- Thread 4 computing [7.5 billion, 10 billion]
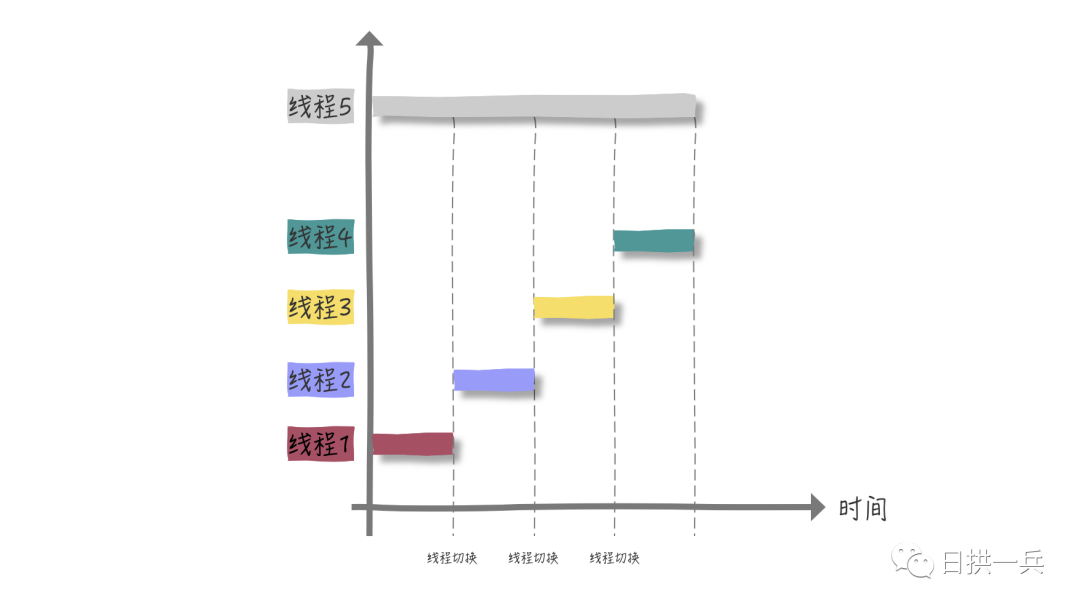
Since it is a single core CPU, all threads are waiting for CPU time slice. Ideally, the total execution time of four threads is equal to that of one thread 5 alone. In fact, we also ignore the overhead of context switching of four threads.
2.1.2.2 multikaryotype (parallel)
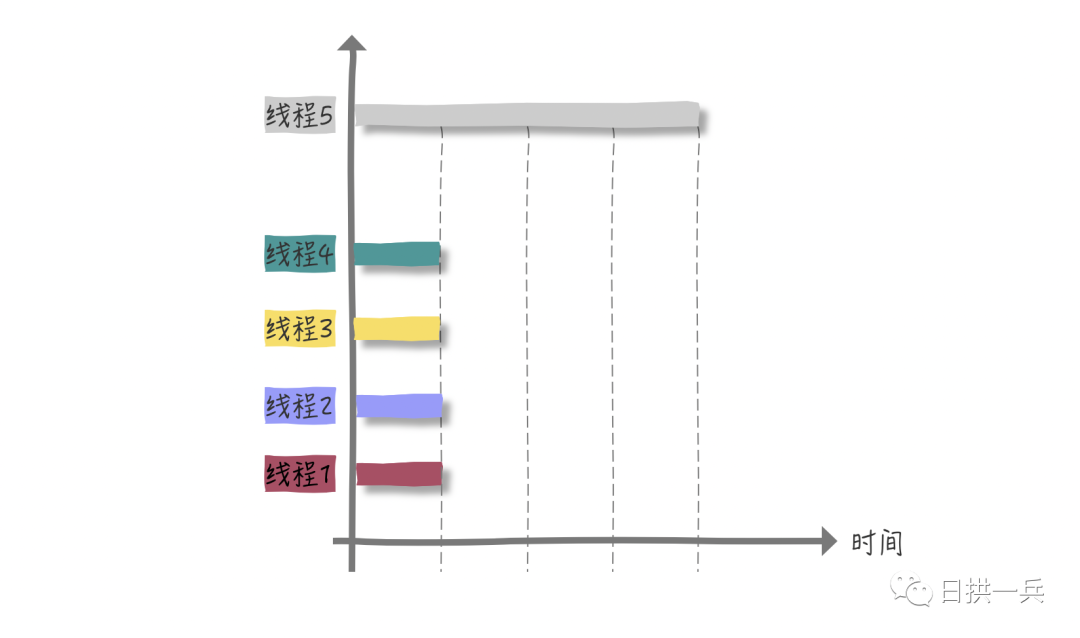
Each thread has a CPU to run. There is no waiting for CPU time slice, and there is no overhead of thread switching. In theory, the efficiency has been increased by four times.
2.2. Is the more threads the better
2.2.1 how many threads are suitable for CPU intensive programs?
Some students have found that for CPU intensive, theoretically, the number of threads = CPU cores (logic) is OK, but in fact, the number is generally set to CPU cores (logic) + 1. Why?
The actual combat of Java Concurrent Programming says:
Computing (CPU) - intensive threads happen to be suspended at a certain time due to a page error or other reasons, and there happens to be an "extra" thread, which can ensure that the CPU cycle will not interrupt in this case.
Therefore, for CPU intensive programs, the number of CPU cores (logic) + 1 thread number is the reason for the better empirical value
2.2.2 how many threads are appropriate for I/O-Intensive programs?
Optimal number of threads = (1/CPU utilization) = 1 + (I/O time consumption / CPU time consumption)
This is the optimal number of threads for a CPU core. If there are multiple cores, the optimal number of threads for I/O-Intensive programs is:
Optimal number of threads = number of CPU cores * (1/CPU utilization) = number of CPU cores * (1 + (I/O time / CPU time))
To calculate I/O-Intensive programs, you need to know the CPU utilization. If I don't know these, how can I give an initial value?
According to the above formula, if it is almost all I/O time-consuming, you can say 2N (N=CPU core number) in pure theory. Of course, there are also 2N + 1 (I guess this 1 is also backup)
2.2.3 can the problem be solved by increasing the number of CPU cores?
The theoretical number of threads is calculated, but the actual number of CPU cores is not enough, which will bring the overhead of thread context switching. Therefore, the next step is to increase the number of CPU cores. Can we solve the problem by blindly increasing the number of CPU cores?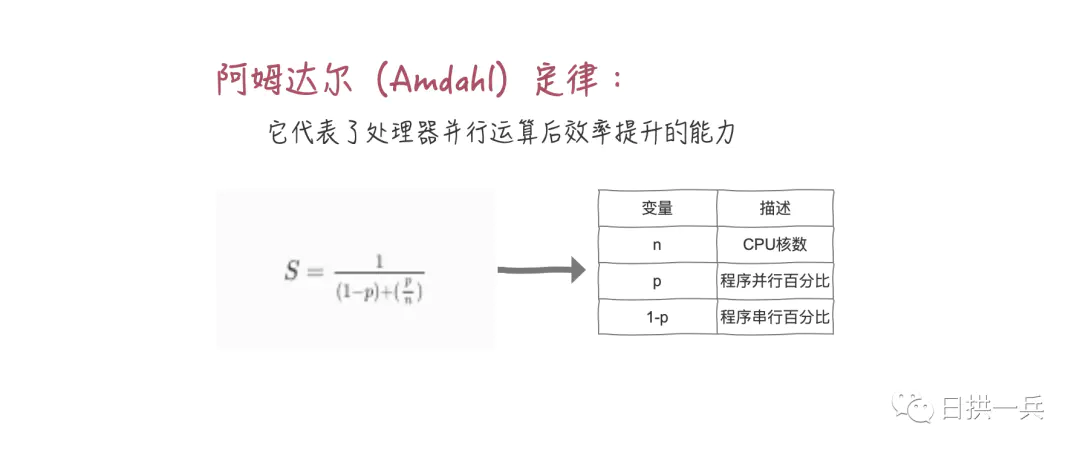

This conclusion tells us that if our serial rate is 5%, no matter what technology we use, the maximum performance can only be improved by 20 times.
How to understand the serial percentage simply and roughly (in fact, this result can be obtained through tools)? Take a look at a small Tips:
Tips: critical areas are serial and non critical areas are parallel. The time of executing the critical area with a single thread / the time of executing the critical area with a single thread (critical area + non critical area) is the serial percentage
3. What is Thread pool
3.1 background
In the traditional multithreading scheme, the server model we adopt is to create a new thread once the request is received, and the thread will execute the task. After the task is executed, the thread exits. This is the * * create immediately, destroy immediately * * strategy. Although the time of creating a thread has been greatly shortened compared with that of creating a process, if the task submitted to the thread has a short execution time and the execution times are extremely frequent, the server will be in the state of constantly creating and destroying threads.
We divide the thread execution process in the traditional scheme into three processes: T1, T2 and T3.
- T1: thread creation time
- T2: thread execution time, including thread synchronization, etc
- T3: thread destruction time
Then we can see that the proportion of the overhead of the thread itself is (T1+T3) / (T1+T2+T3). If the thread execution time is very short, this ratio may account for about 20% - 50% of the overhead. If the task execution time is very frequent, this cost can not be ignored.
Therefore, the emergence of thread pool is aimed at reducing the overhead brought by thread pool itself.
3.2 definition
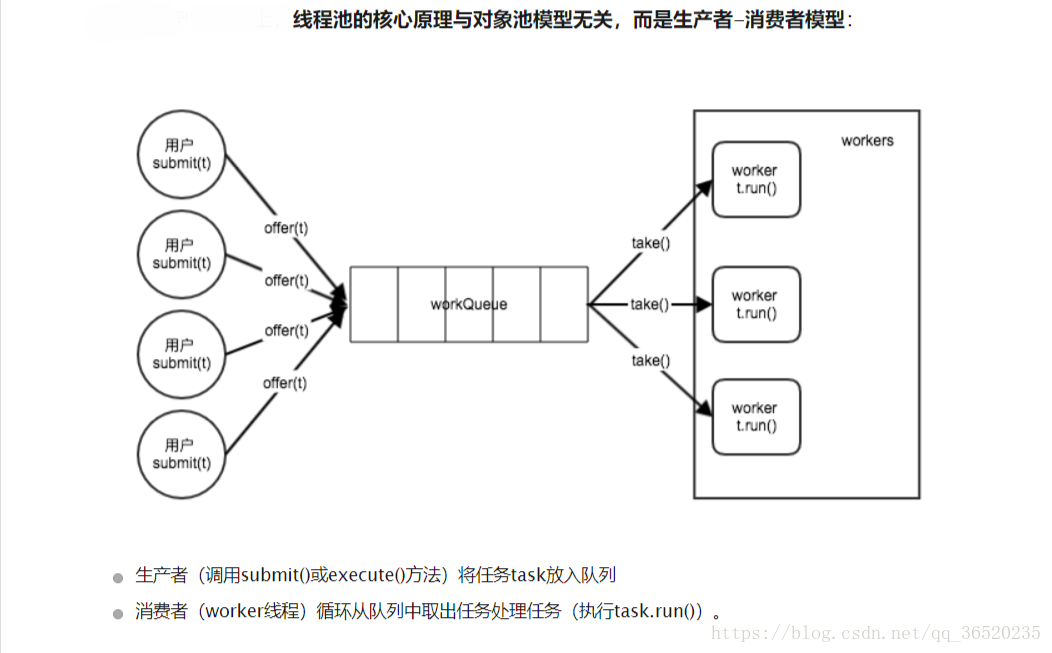
- 1. The thread pool adopts the pre creation technology. After the application starts, a certain number of threads (N1) will be created immediately and put into the idle queue. These threads are in the Suspended state and do not consume CPU, but occupy small memory space.
- 2. When the task arrives, the buffer pool selects an idle thread and passes the task into this thread to run.
- 3. When N1 threads are processing tasks, the buffer pool automatically creates a certain number of new threads to process more tasks.
- 4. After the task is executed, the thread does not exit, but continues to stay in the pool waiting for the next task.
- 5. When the system is relatively idle, most threads are always suspended, and the thread pool automatically destroys some threads and reclaims system resources.
3.3 application scenario
- (1) The task processing time in the unit is frequent and short
- (2) It requires high real-time performance. If a thread is created after receiving a task, it may not meet the real-time requirements, so the thread pool must be used for pre creation.
- (3) We must often face high emergencies, such as Web server. If there is football broadcasting, the server will have a huge impact. At this time, if the traditional method is adopted, a large number of threads must be generated and destroyed. At this time, using dynamic thread pool can avoid this situation.
3.4 implementation of simple thread pool
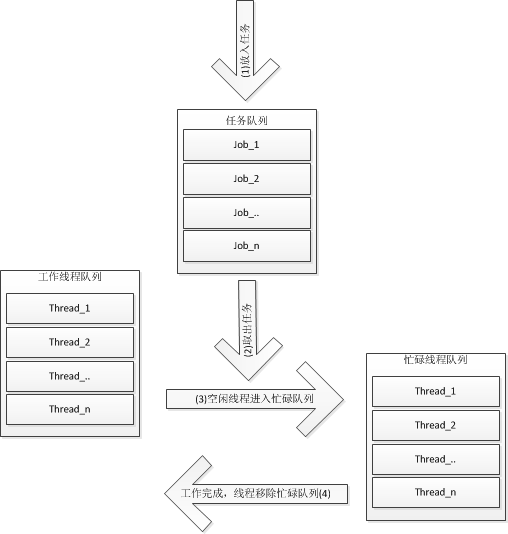
Based on the producer consumer model, we can get that the thread pool is roughly composed of the following parts:
1. Producer: generate a task and add it to the task queue (addTask);
2. task queue: container for storing tasks
3. Consumer: take out tasks from the task queue for consumption (threadRoutine).
4. Because it involves task queue and resource competition, mutual exclusion is adopted here( mutex )And condition_variable Complete the mutual exclusion of resources and the communication task of threads
The specific execution logic is as follows: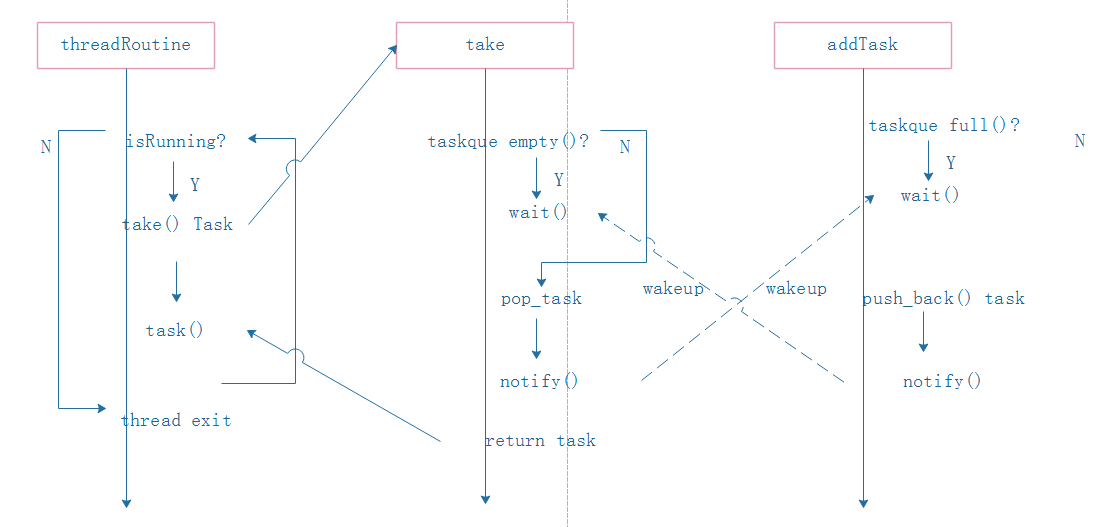
1. Encapsulation of thread pool structure ThreadPool h
#ifndef MYTHREADPOOL_THREADPOOL_H
#define MYTHREADPOOL_THREADPOOL_H
//Thread pool header file
#include "condition.h"
//Encapsulates the task object to be executed by the object in the thread pool
typedef struct task
{
void *(*run)(void *args); //Function pointer, task to be executed
void *arg; //parameter
struct task *next; //Next task in the task queue
}task_t;
//The following is the thread pool structure
typedef struct threadpool_data
{
condition_mutex ready; //State quantity
task_t *first; //The first task in the task queue
task_t *last; //The last task in the task queue
int counter; //Number of threads in thread pool
int idle; //Number of idle threads in the thread pool
int max_threads; //Maximum number of threads in thread pool
int quit; //Exit flag
}threadpool_t;
class threadpool
{
public:
threadpool(int threads);
~threadpool();
//Thread pool initialization
void threadpool_init(int threads);
//Add tasks to the thread pool
void threadpool_add_task(void *(*run)(void *arg), void *arg);
//Destroy thread pool
void threadpool_destroy();
private:
threadpool_t workers;
};
#endif //MYTHREADPOOL_THREADPOOL_H
2. Thread pool implements ThreadPool cpp:
#include "threadpool.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <time.h>
//Created thread execution
static void *thread_routine(void *arg)
{
struct timespec abstime;
int timeout;//Timeout flag bit
printf("thread %d is starting\n",pthread_self());
threadpool_t *pool = (threadpool_t *)arg;
while(1)
{
timeout = 0;
//Locking is required before accessing the thread pool
pool->ready.condition_lock();
//free
pool->idle++;
//Waiting for a task to arrive in the queue or receiving a thread pool destruction notification
while(pool->first == NULL && !pool->quit)
{
//Otherwise, the thread blocks and waits
printf("thread %d is waiting\n",pthread_self());
//Get the current time from and add the waiting time to set the timeout sleep time of the thread
clock_gettime(CLOCK_REALTIME, &abstime);
abstime.tv_sec += 2;
int status;
status = pool->ready.condition_timedwait(&abstime);//This function will unlock and allow other threads to access it. When it is awakened, it will lock it
if(status == ETIMEDOUT)
{
printf("thread %d wait timed out\n",pthread_self());
timeout = 1;
break;
}
}
pool->idle--;
if(pool->first != NULL)
{
//Take out the task at the top of the waiting queue, remove the task, and execute the task
task_t *t = pool->first;
pool->first = t->next;
//Since task execution takes time, unlock it first to allow other threads to access the thread pool
pool->ready.condition_unlock();
//Perform tasks
t->run(t->arg);
//Free memory after executing tasks
free(t);
//Re lock
pool->ready.condition_lock();
}
//Exit thread pool
if(pool->quit && pool->first == NULL)
{
pool->counter--;//Number of threads currently working - 1
//If there are no threads in the thread pool, notify the waiting thread (main thread) that all tasks have been completed
if(pool->counter == 0)
{
pool->ready.condition_signal();
}
pool->ready.condition_unlock();
break;
}
//Timeout, jump out of destruction thread
if(timeout == 1)
{
pool->counter--;//Number of threads currently working - 1
pool->ready.condition_unlock();
break;
}
pool->ready.condition_unlock();
}
printf("thread %d is exiting\n", pthread_self());
return NULL;
}
threadpool::threadpool(int threads)
{
threadpool_init(threads);
}
threadpool::~threadpool()
{
threadpool_destroy();
}
//Thread pool initialization
void threadpool::threadpool_init(int threads)
{
workers.ready.condition_init();
workers.first = NULL;
workers.last =NULL;
workers.counter =0;
workers.idle =0;
workers.max_threads = threads;
workers.quit =0;
}
//Add a task to the thread pool
void threadpool::threadpool_add_task(void *(*run)(void *arg), void *arg)
{
//Generate a new task
task_t *newtask = (task_t *)malloc(sizeof(task_t));
newtask->run = run;
newtask->arg = arg;
newtask->next=NULL;//The newly added task is placed at the end of the queue
//The state of the thread pool is shared by multiple threads and needs to be locked before operation
workers.ready.condition_lock();
if(workers.first == NULL)//First task join
{
workers.first = newtask;
}
else
{
workers.last->next = newtask;
}
workers.last = newtask; //The end of the queue points to the newly added thread
//There are idle threads in the thread pool. Wake up
if(workers.idle > 0)
{
workers.ready.condition_signal();
}
//The number of threads in the current thread pool does not reach the set maximum. Create a new thread
else if(workers.counter < workers.max_threads)
{
pthread_t tid;
pthread_create(&tid, NULL, thread_routine, &workers);
workers.counter++;
}
//End, visit
workers.ready.condition_unlock();
}
//Thread pool destruction
void threadpool::threadpool_destroy()
{
//If destruction has been called, return directly
if(workers.quit)
{
return;
}
//Lock
workers.ready.condition_lock();
//Set destroy flag to 1
workers.quit = 1;
//The number of threads in the thread pool is greater than 0
if(workers.counter > 0)
{
//For waiting threads, send a signal to wake up
if(workers.idle > 0)
{
workers.ready.condition_broadcast();
}
//The thread that is executing the task, waiting for them to finish the task
while(workers.counter)
{
workers.ready.condition_wait();
}
}
workers.ready.condition_unlock();
workers.ready.condition_destroy();
}
3. The class of thread synchronization encapsulates condition h: Mutually exclusive and conditional variables
#ifndef MYTHREADPOOL_CONDITION_H
#define MYTHREADPOOL_CONDITION_H
#include <pthread.h>
//Encapsulates a mutex and condition variable as a state
typedef struct condition
{
pthread_mutex_t pmutex;
pthread_cond_t pcond;
}condition_t;
class condition_mutex
{
public:
condition_mutex();
~condition_mutex();
//Operation function on state
int condition_init();//initialization
int condition_lock();//Lock
int condition_unlock();//Unlock
int condition_wait();//wait for
int condition_timedwait(const struct timespec *abstime);//Timeout wait
int condition_signal();//Wake up a sleep thread
int condition_broadcast();//Wake up all sleep threads
int condition_destroy();//Destroy
private:
condition_t c_mutex;
};
#endif //MYTHREADPOOL_CONDITION_H
4. Specifically implement condition cpp:
#include "condition.h"
condition_mutex::condition_mutex()
{
condition_init();
}
condition_mutex::~condition_mutex()
{
condition_destroy();
}
//initialization
int condition_mutex::condition_init()
{
int status;
if((status = pthread_mutex_init(&c_mutex.pmutex, NULL)))
return status;
if((status = pthread_cond_init(&c_mutex.pcond, NULL)))
return status;
return 0;
}
//Lock
int condition_mutex::condition_lock()
{
return pthread_mutex_lock(&c_mutex.pmutex);
}
//Unlock
int condition_mutex::condition_unlock()
{
return pthread_mutex_unlock(&c_mutex.pmutex);
}
//wait for
int condition_mutex::condition_wait()
{
return pthread_cond_wait(&c_mutex.pcond,&c_mutex.pmutex);
}
//Fixed time waiting
int condition_mutex::condition_timedwait(const struct timespec *abstime)
{
return pthread_cond_timedwait(&c_mutex.pcond,&c_mutex.pmutex, abstime);
}
//Wake up a sleep thread
int condition_mutex::condition_signal()
{
return pthread_cond_signal(&c_mutex.pcond);
}
//Wake up all sleep threads
int condition_mutex::condition_broadcast()
{
return pthread_cond_broadcast(&c_mutex.pcond);
}
//release
int condition_mutex::condition_destroy()
{
int status;
if((status = pthread_mutex_destroy(&c_mutex.pmutex)))
return status;
if((status = pthread_cond_destroy(&c_mutex.pcond)))
return status;
return 0;
}
5. Experimental test main cpp
#include "threadpool.h"
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
void* mytask1(void *arg)
{
printf("thread %d is working on task %d\n", pthread_self(), *(int*)arg);
sleep(1);
free(arg);
return NULL;
}
void* mytask2(void *arg)
{
printf("thread %d is working on task %d\n", pthread_self(), *(int*)arg);
sleep(10);
free(arg);
return NULL;
}
//Test code
int main(void)
{
//Initialize thread pool, up to three threads
threadpool pool(3);
int i;
//Create ten tasks
for(i=0; i < 10; i++)
{
if(i == 5)
{
sleep(5);//Deliberately pause for 5 seconds and the test thread times out
}
int *arg = (int *)malloc(sizeof(int));
*arg = i;
if (i%2 == 0)
{
pool.threadpool_add_task(mytask1, arg);//Perform task 1 even
}
else
{
pool.threadpool_add_task(mytask2, arg);//Odd execution task 2
}
}
return 0;
}
g++ main.cpp condition.cpp threadpool.cpp -o main -lpthread
./main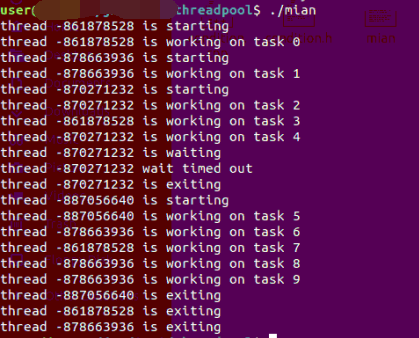
reference resources
1,https://kb.cnblogs.com/page/531409/
2,https://www.cnblogs.com/gguozhenqian/archive/2011/11/16/2251521.html
3,https://www.zhihu.com/question/343831397/answer/810660079?utm_source=wechat_session&utm_medium=social&utm_oi=963890703886180352
4,https://www.jianshu.com/p/f30ee2346f9f
5,https://www.cnblogs.com/cpper-kaixuan/p/3640485.html
6,https://www.cnblogs.com/ailumiyana/p/9402761.html
7,https://www.cnblogs.com/yangang92/p/5485868.html