2021 the first Hehuang cup data Lake algorithm competition in Qinghai Province - vehicle multi-attribute recognition track preliminary baseline (Unofficial)
Link from AI Studio project https://aistudio.baidu.com/aistudio/projectdetail/3511579
1, Event background
At present, China's digital economy is developing by leaps and bounds, and remarkable achievements have been made in many fields. In social development, we also pay more attention to the development of digital economy, so that it can more effectively promote social development. At the same time, the research results of artificial intelligence also show that computers have the ability to surpass humans in some aspects. Of course, the core issue of the development of digital economy is still to better link human society and data, deal with the coordinated development of science and technology and society, and hold this tournament in order to better and faster improve the quality of social development and solve some practical problems in social development.
Adhering to the concept of fairness, openness and innovation, the competition aims to build a good resource sharing platform through the competition, focus on Qinghai, find and cultivate big data technical talents nationwide, improve the data scientific thinking, practical ability and cooperation ability of big data talents in the whole society, and stimulate the exploration spirit of talents, Enhance the innovative application of big data technology in the industrialization of digital economy in Qinghai Province, and further promote the production, study and research of big data in Qinghai.
2, Event task
The increasing popularity of vehicles leads to increasingly serious traffic problems. Intelligent transportation system comes into being. Combined with the development of artificial intelligence technology, vehicle identification management has become an important part of intelligent transportation system. Aiming at the problem of vehicle identification management, the "vehicle multi-attribute identification" competition was held to provide a basis for traffic, public security and other departments to deal with road traffic events.
In this competition, players are expected to use a large number of vehicle pictures under surveillance video to train relevant models, so as to solve the three problems of vehicle type recognition, vehicle driving direction recognition and vehicle body color recognition.
The preliminary competition adopts A/B list and provides training data set for contestants to train algorithm model; Provide test data sets for contestants to submit evaluation results and participate in ranking. During the preliminary competition, the contestant shall identify the type of vehicle in the picture and submit the results according to the format specification.
3, Review rules

sample data
The preliminary training data set is divided into two parts: pictures and labels, of which the pictures are jpg format, label is csv format. The tag data contains two parts, namely "id" and "type", where "id" is a string type, corresponding to the picture name; "Type" is a string type, corresponding to the type of vehicle in the picture. In the preliminary stage, there are four types: car, suv, van and truck.
Example:

!unzip -oq /home/aistudio/work/testA.zip !unzip -oq /home/aistudio/work/train.zip
Data EDA
Exploratory Data Analysis (EDA) refers to a data analysis method that analyzes and explores the existing data (original data) and explores the structure and law of data by means of drawing, tabulation, equation fitting, calculation of characteristic quantity and so on. Generally speaking, when we first come into contact with data, we often have no clue and don't know how to start. At this time, Exploratory Data Analysis is very effective.
For image classification tasks, we usually first count the number of each category and view the data distribution of the training set. Through the analysis of data distribution, the problem-solving ideas are formed. (insight into the nature of data is important.)
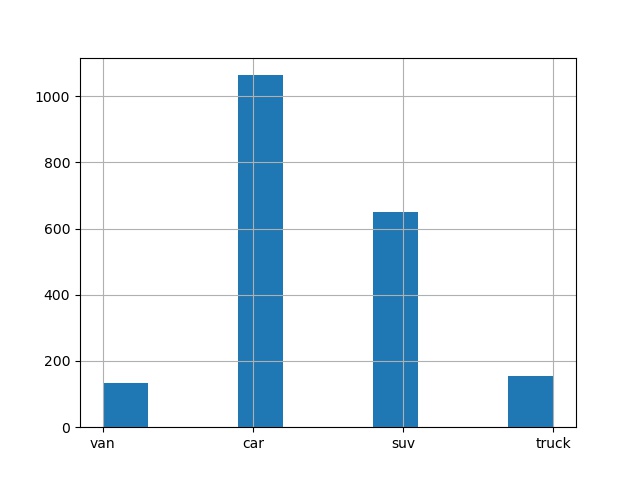
baseline build
Data preprocessing
Through the above data EDA, it is found that the categories are unbalanced,
# Import required libraries
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import paddle.nn as nn
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
# Read data
train_images = pd.read_csv('train_sorted1.csv')
train_images = shuffle(train_images)
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
housing_cat=train_images["label"]
housing_cat_encoded=encoder.fit_transform(housing_cat)
train_images["label"]=pd.DataFrame(housing_cat_encoded)
# print(train_images)
# labelshuffling
def labelShuffling(dataFrame, groupByName = 'label'):
groupDataFrame = dataFrame.groupby(by=[groupByName])
labels = groupDataFrame.size()
print("length of label is ", len(labels))
maxNum = max(labels)
lst = pd.DataFrame()
for i in range(len(labels)):
print("Processing label :", i)
tmpGroupBy = groupDataFrame.get_group(i)
createdShuffleLabels = np.random.permutation(np.array(range(maxNum))) % labels[i]
print("Num of the label is : ", labels[i])
lst=lst.append(tmpGroupBy.iloc[createdShuffleLabels], ignore_index=True)
print("Done")
# lst.to_csv('test1.csv', index=False)
return lst
# Divide training set and check set
all_size = len(train_images)
# print(all_size)
train_size = int(all_size * 0.8)
train_image_list = train_images[:train_size]
val_image_list = train_images[train_size:]
df = train_image_list
# print(df)
df = labelShuffling(train_image_list)
df = shuffle(df)
train_image_path_list = df['image'].values
label_list = df['label'].values
label_list = paddle.to_tensor(label_list, dtype='int64')
train_label_list = paddle.nn.functional.one_hot(label_list, num_classes=4)
val_image_path_list = val_image_list['image'].values
val_label_list = val_image_list['label'].values
val_label_list = paddle.to_tensor(val_label_list, dtype='int64')
val_label_list = paddle.nn.functional.one_hot(val_label_list, num_classes=4)
# Define data preprocessing
data_transforms = T.Compose([
T.Resize(size=(256, 256)),
T.RandomHorizontalFlip(0.5),
T.RandomVerticalFlip(0.5),
T.RandomRotation(30),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0, 0, 0], # normalization
std=[255, 255, 255],
to_rgb=True)
])
length of label is 4 Processing label : 0 Num of the label is : 1448 Done Processing label : 1 Num of the label is : 587 Done Processing label : 2 Num of the label is : 140 Done Processing label : 3 Num of the label is : 149 Done W0224 22:03:39.271940 5640 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0224 22:03:39.275599 5640 device_context.cc:465] device: 0, cuDNN Version: 7.6.
# Build Dataset
class MyDataset(paddle.io.Dataset):
"""
Step 1: inherit paddle.io.Dataset class
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
Step 2: implement the constructor, define the data reading method, and divide the training and test data sets
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
# Reading csv library with pandas
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list
if mode == 'train':
# Read train_images data
for img,la in zip(self.train_images, self.train_label):
self.img.append('train/train/'+img)
self.label.append(la)
else:
# Read test_images data
for img,la in zip(self.test_images, self.test_label):
self.img.append('train/train/'+img)
self.label.append(la)
def load_img(self, image_path):
# In actual use, you can use the pilot related library to read pictures. Here, let's simulate the data first
image = Image.open(image_path).convert('RGB')
return image
def __getitem__(self, index):
"""
Step 3: Implement__getitem__Method, defining and specifying index How to obtain data and return a single piece of data (training data, corresponding label)
"""
image = self.load_img(self.img[index])
label = self.label[index]
# label = paddle.to_tensor(label)
return data_transforms(image), paddle.nn.functional.label_smooth(label)
def __len__(self):
"""
Step 4: Implement__len__Method to return the total number of data sets
"""
return len(self.img)
#train_loader train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train') train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0) #val_loader val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test') val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)
model training
from res2net import Res2Net50_vd_26w_4s
# Model encapsulation
model_res = Res2Net50_vd_26w_4s(class_dim=4)
model = paddle.Model(model_res)
# Define optimizer
# scheduler = paddle.optimizer.lr.LinearWarmup(
# learning_rate=0.5, warmup_steps=20, start_lr=0, end_lr=0.5, verbose=True)
# optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
optim = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model.parameters())
# Configuration model
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(soft_label=True),
Accuracy()
)
model.load('Res2Net50_vd_26w_4s_pretrained.pdparams',skip_mismatch=True)
# Model training and evaluation
model.fit(train_loader,
val_loader,
log_freq=1,
epochs=15,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/15 step 181/181 [==============================] - loss: 1.3492 - acc: 0.3267 - 231ms/step Eval begin... step 9/9 [==============================] - loss: 1.3039 - acc: 0.2548 - 154ms/step Eval samples: 259 Epoch 2/15 step 181/181 [==============================] - loss: 1.1146 - acc: 0.4498 - 228ms/step Eval begin... step 9/9 [==============================] - loss: 1.5971 - acc: 0.3205 - 153ms/step Eval samples: 259 Epoch 3/15 step 181/181 [==============================] - loss: 0.8872 - acc: 0.5568 - 229ms/step Eval begin... step 9/9 [==============================] - loss: 1.7063 - acc: 0.3591 - 146ms/step Eval samples: 259 Epoch 4/15 step 181/181 [==============================] - loss: 0.9437 - acc: 0.6499 - 229ms/step Eval begin... step 9/9 [==============================] - loss: 1.4568 - acc: 0.2394 - 144ms/step Eval samples: 259 Epoch 5/15 step 181/181 [==============================] - loss: 0.8166 - acc: 0.7210 - 227ms/step Eval begin... step 9/9 [==============================] - loss: 0.8642 - acc: 0.4324 - 148ms/step Eval samples: 259 Epoch 6/15 step 181/181 [==============================] - loss: 0.7758 - acc: 0.7629 - 227ms/step Eval begin... step 9/9 [==============================] - loss: 0.8764 - acc: 0.4981 - 148ms/step Eval samples: 259 Epoch 7/15 step 181/181 [==============================] - loss: 0.6554 - acc: 0.7987 - 226ms/step Eval begin... step 9/9 [==============================] - loss: 1.0617 - acc: 0.3050 - 146ms/step Eval samples: 259 Epoch 8/15 step 181/181 [==============================] - loss: 0.6482 - acc: 0.8358 - 230ms/step Eval begin... step 9/9 [==============================] - loss: 2.0823 - acc: 0.3745 - 149ms/step Eval samples: 259 Epoch 9/15 step 181/181 [==============================] - loss: 0.6632 - acc: 0.8524 - 231ms/step Eval begin... step 9/9 [==============================] - loss: 1.5684 - acc: 0.4363 - 146ms/step Eval samples: 259 Epoch 10/15 step 181/181 [==============================] - loss: 0.6055 - acc: 0.8726 - 228ms/step Eval begin... step 9/9 [==============================] - loss: 1.1803 - acc: 0.4479 - 149ms/step Eval samples: 259 Epoch 11/15 step 181/181 [==============================] - loss: 0.5604 - acc: 0.8955 - 228ms/step Eval begin... step 9/9 [==============================] - loss: 2.5635 - acc: 0.4942 - 147ms/step Eval samples: 259 Epoch 12/15 step 181/181 [==============================] - loss: 0.5882 - acc: 0.9054 - 227ms/step Eval begin... step 9/9 [==============================] - loss: 1.1620 - acc: 0.5135 - 146ms/step Eval samples: 259 Epoch 13/15 step 181/181 [==============================] - loss: 0.5160 - acc: 0.9187 - 226ms/step Eval begin... step 9/9 [==============================] - loss: 2.2730 - acc: 0.5560 - 146ms/step Eval samples: 259 Epoch 14/15 step 181/181 [==============================] - loss: 0.4833 - acc: 0.9330 - 228ms/step Eval begin... step 9/9 [==============================] - loss: 0.7435 - acc: 0.4942 - 144ms/step Eval samples: 259 Epoch 15/15 step 181/181 [==============================] - loss: 0.4185 - acc: 0.9408 - 227ms/step Eval begin... step 9/9 [==============================] - loss: 1.3306 - acc: 0.5521 - 149ms/step Eval samples: 259
# Save model parameters
# model.save('Hapi_MyCNN') # save for training
model.save('Hapi_MyCNN1', False) # save for inference
View F1 score
Here you can view the performance of the model on the validation set according to the review rules.
!pip install patta
import os, time
import matplotlib.pyplot as plt
import paddle
from PIL import Image
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score,classification_report
import patta as tta
use_gpu = True
model_file_path="Hapi_MyCNN1"
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
model = paddle.jit.load(model_file_path)
model = tta.ClassificationTTAWrapper(model, tta.aliases.ten_crop_transform(224,224))
model.eval() #Training mode
def load_image(img_path):
'''
Prediction picture preprocessing
'''
img = Image.open(img_path).convert('RGB')
#resize
img = img.resize((256, 256), Image.BILINEAR) #Image.BILINEAR interpolation
img = np.array(img).astype('float32')
# HWC to CHW
img = img.transpose((2, 0, 1))
#Normalize
img = img / 255 #Pixel value normalization
return img
def infer_img(path, model):
'''
model prediction
'''
#Preprocess the prediction picture
infer_imgs = []
infer_imgs.append(load_image(path))
infer_imgs = np.array(infer_imgs)
label_pre = []
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data = dy_x_data[np.newaxis,:, : ,:]
img = paddle.to_tensor(dy_x_data)
out = model(img)
lab = np.argmax(out.numpy()) #argmax(): returns the maximum number of indexes
label_pre.append(int(lab))
return label_pre
img_list = val_image_path_list
pre_list = []
for i in range(len(img_list)):
pre_list.append(infer_img(path='train/train/' + img_list[i], model=model)[0])
img = pd.DataFrame(img_list)
img = img.rename(columns = {0:"image_id"})
img['category_id'] = pre_list
base_score = f1_score(val_image_list['label'].values, img['category_id'].values, average='macro')
clc_report = classification_report(val_image_list['label'].values, img['category_id'].values)
print(base_score)
print(clc_report)
0.20938058534405718
precision recall f1-score support
0 0.61 0.80 0.69 162
1 0.21 0.11 0.15 62
2 0.00 0.00 0.00 24
3 0.00 0.00 0.00 11
accuracy 0.53 259
macro avg 0.20 0.23 0.21 259
weighted avg 0.43 0.53 0.47 259
model prediction
import os, time
import matplotlib.pyplot as plt
import paddle
from PIL import Image
import numpy as np
import patta as tta
import pandas as pd
use_gpu = True
# model_file_path="Hapi_MyCNN"
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
model = paddle.jit.load('/home/aistudio/Hapi_MyCNN1')
model = tta.ClassificationTTAWrapper(model, tta.aliases.ten_crop_transform(224,224))
model.eval() #Training mode
def load_image(img_path):
'''
Prediction picture preprocessing
'''
img = Image.open(img_path).convert('RGB')
#resize
img = img.resize((256, 256), Image.BILINEAR) #Image.BILINEAR interpolation
img = np.array(img).astype('float32')
# HWC to CHW
img = img.transpose((2, 0, 1))
#Normalize
img = img / 255 #Pixel value normalization
return img
def infer_img(path, model):
'''
model prediction
'''
#Preprocess the prediction picture
label_pre = []
labeled_img = []
data = load_image(path)
dy_x_data = np.array(data).astype('float32')
dy_x_data = dy_x_data[np.newaxis,:, : ,:]
img = paddle.to_tensor(dy_x_data)
out = model(img)
res = paddle.nn.functional.softmax(out)[0] # If softmax is already included in the model, this line of code is not needed.
lab = np.argmax(out.numpy()) #argmax(): returns the maximum number of indexes
if res[lab].numpy()[0] >= 0.95:
label_pre.append(int(lab))
labeled_img.append(path)
return label_pre
img_list = os.listdir('testA/')
img_list.sort()
img_list.sort(key=lambda x: int((x[:-4]).split('_')[-1])) ##File names are sorted by number
pre_list = []
labeled_img_list = []
for i in range(len(img_list)):
data = load_image(img_path='testA/' + img_list[i])
dy_x_data = np.array(data).astype('float32')
dy_x_data = dy_x_data[np.newaxis,:, : ,:]
img = paddle.to_tensor(dy_x_data)
out = model(img)
res = paddle.nn.functional.softmax(out)[0] # If softmax is already included in the model, this line of code is not needed.
lab = np.argmax(out.numpy()) #argmax(): returns the maximum number of indexes
pre_list.append(int(lab))
labeled_img_list.append(img_list[i])
encoder.inverse_transform
img = pd.DataFrame(labeled_img_list)
img = img.rename(columns = {0:"id"})
img['type'] = encoder.inverse_transform(pre_list)
():Returns the maximum number of indexes
pre_list.append(int(lab))
labeled_img_list.append(img_list[i])
encoder.inverse_transform
img = pd.DataFrame(labeled_img_list)
img = img.rename(columns = {0:"id"})
img['type'] = encoder.inverse_transform(pre_list)
img.to_csv('result.csv', index=False)
# len(labeled_img_list)
# len(pre_list)
# import pandas as pd
# df1 = pd.read_csv('train_sorted1.csv')
# df2 = pd.read_csv('result.csv')
# result = pd.concat([df1, df2], axis=0)
# result.to_csv('train_sorted2.csv', index=False)
Submit results
