This article is shared from Huawei cloud community< Paging query for large data volume performance optimization >, by JavaEdge.
Paging query is required to turn the page of posts, and paging query is also required to search products. When there are tens of millions or hundreds of millions of data, how can we quickly pull the full amount of data?
For example:
- Large businesses pull the number of orders of tens of millions of levels per month to their independent ISV for financial statistics
- Big v with millions of fans, push messages to all fans
case
Common mistakes
SELECT * FROM table where kid = 1342 and type = 1 order id asc limit 149420,20;
Typical sorting + paging query:
order by col limit N,OFFSET M
When MySQL executes this kind of SQL: scan N rows first, and then get M rows.
The larger the N, MySQL needs to scan more data to locate the specific n rows, which will consume a lot of I/O cost and time cost.
Why is the above SQL writing method slow to scan data?
- t is an index organization table, key idx_kid_type(kid,type)
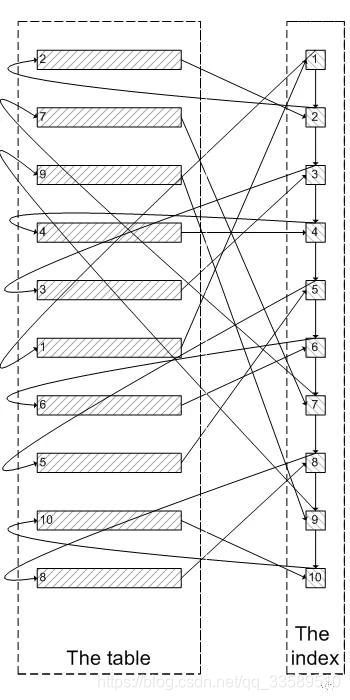
There are many lines in the record with kid=3 and type=1. Let's take lines 9 and 10.
select * from t where kid =3 and type=1 order by id desc 8,2;
For Innodb, according to idx_kid_type the primary key contained in the secondary index to find the corresponding row.
For millions of records, the index size may be almost the same as the data size. The number of indexes in the cache in memory is limited, and the secondary index and data leaf nodes are not stored in the same physical block. The relatively unordered mapping relationship between the secondary index and the primary key will also bring a large number of random I/O requests. The greater the N, the more it needs to traverse a large number of index pages and data leaves, The longer it takes.
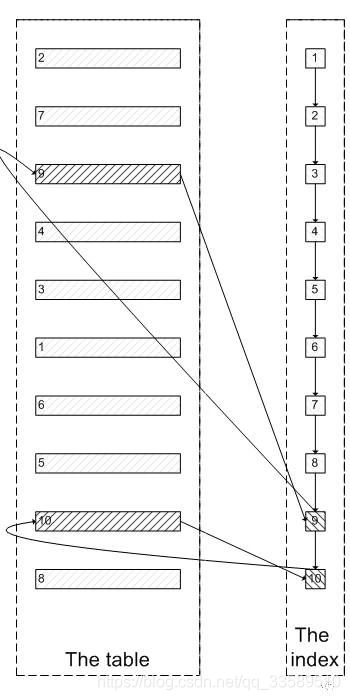
Since the above large paging query takes a long time, is it really necessary to completely traverse the "invalid data"?
If required:
limit 8,2
Skip the traversal of the first 8 rows of irrelevant data pages and directly locate rows 9 and 10 through the index. Is this faster?
This is the core idea of delayed Association: return the required primary key by using the overlay index query, and then associate the original table with the required data according to the primary key, instead of obtaining the primary key through the secondary index, and then traverse the data page through the primary key.
Through the above analysis, we can get the reasons for the slow speed of large page query through conventional methods, and know the specific methods to improve large page query.
General paging query
Simple limit clause. The limit clause is declared as follows:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
The limit clause is used to specify the number of records returned by the select statement. Note:
- Offset specifies the offset of the first return record line, which is 0 by default
The offset of the initial record line is 0, not 1 - Rows specifies the maximum number of returned record rows
Rows is - 1, which means to retrieve all record rows from an offset to the end of the recordset.
If only one parameter is given: it indicates the maximum number of record lines returned.
example:
select * from orders_history where type=8 limit 1000,10;
From orders_history table query offset: 10 pieces of data after the beginning of 1000, i.e. 1001 to 1010 pieces of data (1001 < = ID < = 1010).
The records in the data table are sorted by primary key (id) by default. The above result is equivalent to:
select * from orders_history where type=8 order by id limit 10000,10;
The three query times are:
3040 ms 3063 ms 3018 ms
For this query method, the following tests the impact of query records on time:
select * from orders_history where type=8 limit 10000,1; select * from orders_history where type=8 limit 10000,10; select * from orders_history where type=8 limit 10000,100; select * from orders_history where type=8 limit 10000,1000; select * from orders_history where type=8 limit 10000,10000;
Time of the third query:
Query 1 record: 3072 ms 3092ms 3002ms Query 10 records: 3081 ms 3077ms 3032ms Query 100 records: 3118 ms 3200ms 3128ms Query 1000 records: 3412 ms 3468ms 3394ms Query 10000 records: 3749 ms 3802ms 3696ms
When the number of query records is less than 100, there is basically no gap in query time. With the increasing number of query records, more time is consumed.
Test for query offset:
select * from orders_history where type=8 limit 100,100; select * from orders_history where type=8 limit 1000,100; select * from orders_history where type=8 limit 10000,100; select * from orders_history where type=8 limit 100000,100; select * from orders_history where type=8 limit 1000000,100;
The three query times are as follows:
Query 100 offset: 25 ms 24ms 24ms Query 1000 offset: 78 ms 76ms 77ms Query 10000 offset: 3092 ms 3212ms 3128ms Query offset: 3878 ms 3812ms 3798ms Query 1000000 offset: 14608 ms 14062ms 14700ms
With the increase of query offset, especially after the query offset is greater than 100000, the query time increases sharply.
This paging query method will start scanning from the first record of the DB, so the later the query speed is, the slower the query speed is, and the more data is queried, the slower the total query speed will be.
optimization
- Add cache and search at the front end to reduce the query operation to the database
For example, a large number of goods can be put into the search, and the data can be displayed in the way of waterfall flow - Optimize how SQL accesses data
Directly and quickly navigate to the data row to access. It is recommended to use the "delayed Association" method to optimize sorting operations. What is "delayed Association": use the overlay index query to return the required primary key, and then associate the original table according to the primary key to obtain the required data. - Use the bookmark method to record the latest / largest id value of the last query, and trace back the M-line records
Delayed Association
Before optimization
explain SELECT id, cu_id, name, info, biz_type, gmt_create, gmt_modified,start_time, end_time, market_type, back_leaf_category,item_status,picuture_url FROM relation where biz_type ='0' AND end_time >='2014-05-29' ORDER BY id asc LIMIT 149420 ,20; +----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+ | id | select_type | table | type | possible_keys | key | key\_len | ref | rows | Extra | +----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+ | 1 | SIMPLE | relation | range | ind\_endtime | ind\_endtime | 9 | NULL | 349622 | Using where; Using filesort | +----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+
Execution time:
20 rows in set (1.05 sec)
After optimization:
explain SELECT a.* FROM relation a, (select id from relation where biz_type ='0' AND end\_time >='2014-05-29' ORDER BY id asc LIMIT 149420 ,20 ) b where a.id=b.id; +----+-------------+-------------+--------+---------------+---------+---------+------+--------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------------+--------+---------------+---------+---------+------+--------+-------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 20 | | | 1 | PRIMARY | a | eq_ref | PRIMARY | PRIMARY | 8 | b.id | 1 | | | 2 | DERIVED | relation | index | ind_endtime | PRIMARY | 8 | NULL | 733552 | | +----+-------------+-------------+--------+---------------+---------+---------+------+--------+-------+
Execution time:
20 rows in set (0.36 sec)
The optimized execution time is 1 / 3 of the original.
bookmark
First, get the maximum id and minimum id of the qualified record (the default id is the primary key)
select max(id) as maxid ,min(id) as minid from t where kid=2333 and type=1;
Traverse according to the id that is greater than the minimum value or less than the maximum value.
select xx,xx from t where kid=2333 and type=1 and id >=min_id order by id asc limit 100; select xx,xx from t where kid=2333 and type=1 and id <=max_id order by id desc limit 100;
case
When delayed association cannot meet the requirements of query speed
SELECT a.id as id, client_id, admin_id, kdt_id, type, token, created_time, update_time, is_valid, version FROM t1 a, (SELECT id FROM t1 WHERE 1 and client_id = 'xxx' and is_valid = '1' order by kdt_id asc limit 267100,100 ) b WHERE a.id = b.id; 100 rows in set (0.51 sec)
It is definitely a qualitative leap to reduce the delay associated query data to 510ms and the solution based on bookmark mode to less than 10ms.
SELECT * FROM t1 where client_id='xxxxx' and is_valid=1 and id<47399727 order by id desc LIMIT 100; 100 rows in set (0.00 sec)
Summary
Locate the data directly to the starting point of the primary key according to the way of locating the data of the primary key, and then filter the required data.
It is relatively faster than delayed correlation, and there are less secondary index scans when looking up data. However, there is no silver bullet in the optimization method, such as:
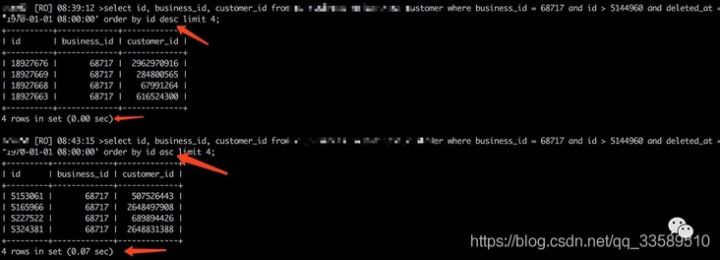
The difference between the results of order by id desc and order by asc is 70ms, and the production case has a limit of 100, with a difference of 1.3s. Why?
There are other optimization methods. For example, ICP can also speed up the large page query when using all the index columns of the combined index for overlay index scanning.
Subquery optimization
First locate the id of the offset position, and then query it later. It is suitable for the scenario of id increment:
select * from orders_history where type=8 limit 100000,1; select id from orders_history where type=8 limit 100000,1; select * from orders_history where type=8 and id>=(select id from orders_history where type=8 limit 100000,1) limit 100; select * from orders_history where type=8 limit 100000,100;
The query time of the four statements is as follows:
Sentence 1: 3674 ms Sentence 2: 1315 ms Clause 3: 1327 ms Clause 4: 3710 ms
- Select id: 3 times faster than select id: v
- 2 V.S 3: the speed difference is small
- 3 V.S 4: thanks to the increase in the speed of select id, the query speed of 3 is three times faster
Compared with the original general query method, this method will be several times faster.
Use id qualification optimization
Assuming that the id of the data table increases continuously, the range of the query id can be calculated according to the number of pages and records queried. You can use id between and:
select * from order_history where c = 2 and id between 1000000 and 1000100 limit 100;
Query time:
15ms 12ms 9ms
This can greatly optimize the query speed, which can be completed in tens of milliseconds.
The limitation is that it can only be used when the id is explicitly known.
Another way of writing:
select * from order_history where id >= 1000001 limit 100;
You can also use in, which is often used to query when multiple tables are associated. You can use the id set of other table queries to query:
select *
from order_history
where id in
(select order_id from trade_2 where goods = 'pen')
limit 100;cursor
It doesn't belong to query optimization anymore. I'll mention it here.
For the problem of using id to limit the optimization, the id needs to be continuously increased. However, in some scenarios, such as when using the history table or when there is a data loss problem, you can consider using the temporarily stored table to record the id of the page and using the id of the page for in query. This can greatly improve the speed of traditional paging query, especially when the amount of data is tens of millions.
id of the data table
Generally, when creating tables in DB, the id increment field is forced to be added to each table to facilitate query.
There is a large amount of data such as order library, which is generally divided into database and table. At this time, it is not recommended to use the id of the database as the unique id, but should use the distributed high concurrency unique id generator, and use another field in the data table to store this unique id.
First use the range to query the location ID (or index), and then use the index to locate the data, which can improve the query speed several times. That is, select id first, and then select *.
reference resources
- https://segmentfault.com/a/1190000038856674
Click follow to learn about Huawei's new cloud technology for the first time~