🔥 Medical microscopic image recognition of Mycobacterium tuberculosis based on paddedetection
this project uses PP-yolov2 to detect conjugated bacteria in sputum, so as to realize anomaly detection.
Title reproduced from AI Studio
Title item link https://aistudio.baidu.com/aistudio/projectdetail/3503450
I believe you will gain something after reading this project
Watch first and then praise, and form a habit
folk collection, brilliant life

1, Project background
Tuberculosis (TB) is a chronic zoonosis caused by Mycobacterium tuberculosis. It is not affected by age, gender, race, occupation, and area. Tuberculosis and tuberculosis are the most common organs and organs in many organs of the human body. Tuberculosis is not only a public health problem, but also a social and economic problem, which poses a great threat to the public health of human beings.
1. although coloring treatment can make Mycobacterium tuberculosis appear in microscopic medical images, doctors can detect tuberculosis in the image to assist in the diagnosis of tuberculosis. 🎯
2. but by constructing an accurate target detection model, the intelligent system can be used to assist doctors in the detection work, and can be applied to the current medical testing products to meet the real needs of TB detection. 🎯
3. Realize AI + medical and empower the industry. 🎯
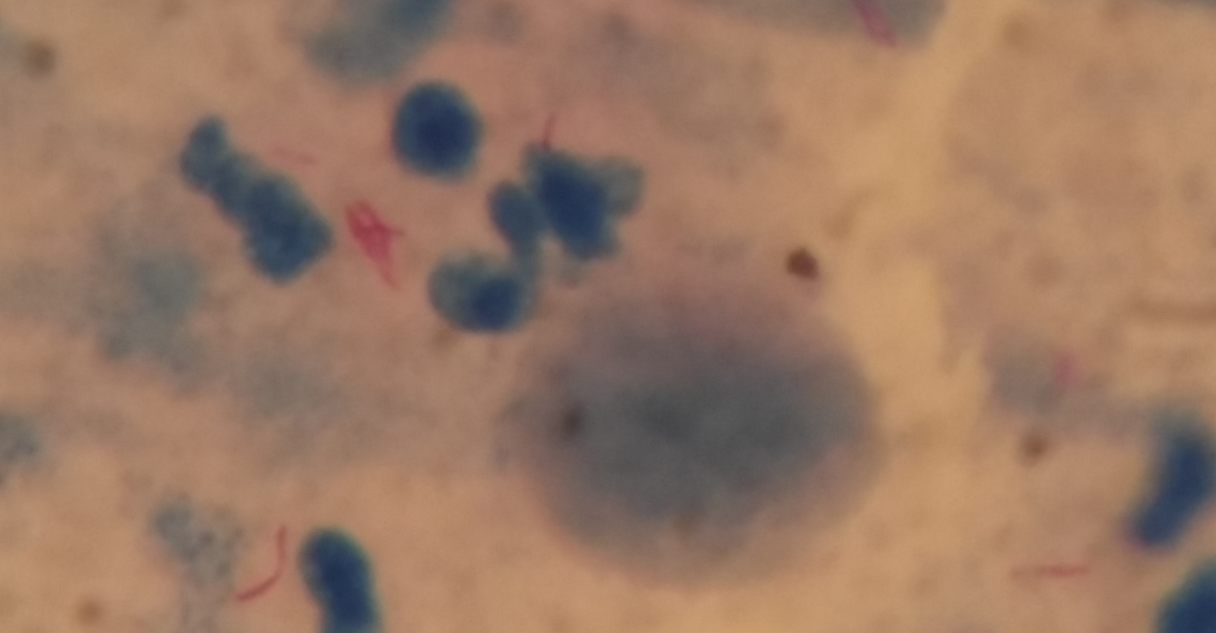
2, Data introduction
Data description
the data set is all related to tuberculosis and is taken from sputum samples. It contains 1265 sputum images and a bounding box of 3734 bacteria. The XML file contains the bounding box details of the image.
Data source: AI Research and Automated Laboratory Diagnostics
# 1. Load dataset !unzip /home/aistudio/data/data83968/Tuberculosis6208.zip -d ./Dataset
Three. Selection and development of models
use paddedetection and PP yolov2 algorithm
1. Introduction
compared with PP-YOLO released in 20 years, the accuracy of v2 version on coco 2017 test dev has increased by 3.6 percentage points, from 45.9% to 49.5%; Under the input size of 640 * 640, the FPS reaches 68.9FPS. PP-YOLOv2 at the same speed, the accuracy exceeds YOLOv5!
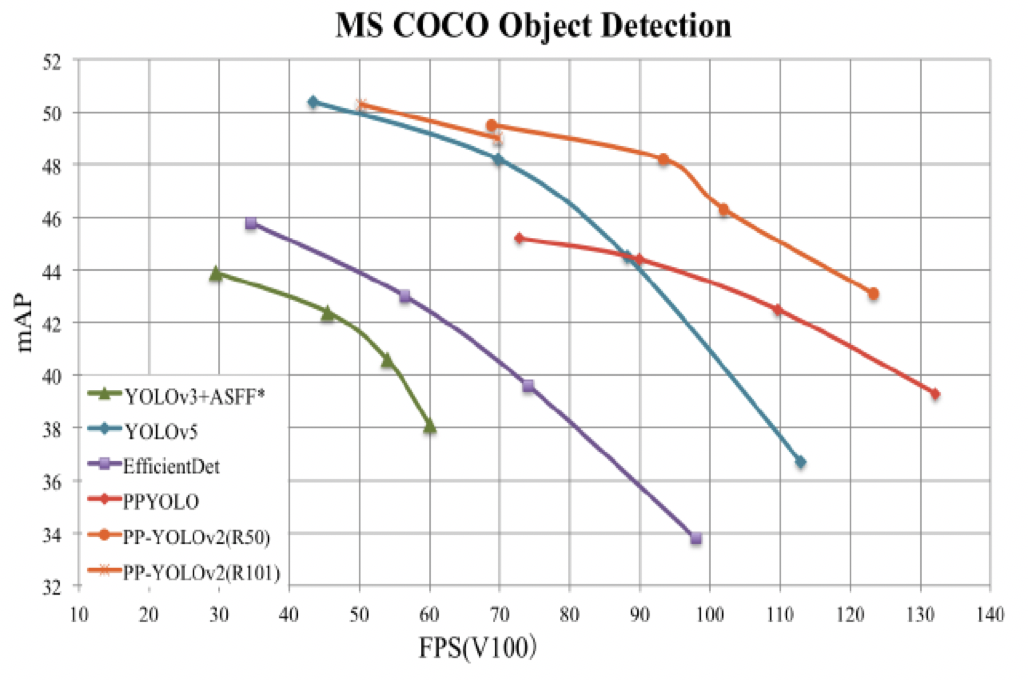
2. Model library
PP-YOLO model library
| Model | GPU number | images/GPU | backbone | input shape | Box APval | Box APtest | V100 FP32(FPS) | V100 TensorRT FP16(FPS) | download | config |
|---|---|---|---|---|---|---|---|---|---|---|
| PP-YOLO | 8 | 24 | ResNet50vd | 608 | 44.8 | 45.2 | 72.9 | 155.6 | model | config |
| PP-YOLO | 8 | 24 | ResNet50vd | 512 | 43.9 | 44.4 | 89.9 | 188.4 | model | config |
| PP-YOLO | 8 | 24 | ResNet50vd | 416 | 42.1 | 42.5 | 109.1 | 215.4 | model | config |
| PP-YOLO | 8 | 24 | ResNet50vd | 320 | 38.9 | 39.3 | 132.2 | 242.2 | model | config |
| PP-YOLO_2x | 8 | 24 | ResNet50vd | 608 | 45.3 | 45.9 | 72.9 | 155.6 | model | config |
| PP-YOLO_2x | 8 | 24 | ResNet50vd | 512 | 44.4 | 45.0 | 89.9 | 188.4 | model | config |
| PP-YOLO_2x | 8 | 24 | ResNet50vd | 416 | 42.7 | 43.2 | 109.1 | 215.4 | model | config |
| PP-YOLO_2x | 8 | 24 | ResNet50vd | 320 | 39.5 | 40.1 | 132.2 | 242.2 | model | config |
| PP-YOLO | 4 | 32 | ResNet18vd | 512 | 29.2 | 29.5 | 357.1 | 657.9 | model | config |
| PP-YOLO | 4 | 32 | ResNet18vd | 416 | 28.6 | 28.9 | 409.8 | 719.4 | model | config |
| PP-YOLO | 4 | 32 | ResNet18vd | 320 | 26.2 | 26.4 | 480.7 | 763.4 | model | config |
| PP-YOLOv2 | 8 | 12 | ResNet50vd | 640 | 49.1 | 49.5 | 68.9 | 106.5 | model | config |
| PP-YOLOv2 | 8 | 12 | ResNet101vd | 640 | 49.7 | 50.3 | 49.5 | 87.0 | model | config |
be careful:
- PP-YOLO model uses train2017 in COCO data set as training set, val2017 and test dev2017 as test set, and Box APtest is the evaluation result of mAP(IoU=0.5:0.95).
- In the training process of PP-YOLO model, 8 GPUs are used, and the batch size of each GPU is 24 for training. If the above configuration is not used for the number of training GPUs and batch size, please refer to FAQ Adjust the learning rate and the number of iterations.
- PP-YOLO model reasoning speed test adopts single card V100, batch size=1, CUDA 10.2, CUDNN 7.5.1 and TensorRT 5.1.2.
- The reasoning speed test data of PP-YOLO model FP32 is tools / export_ model. After the PY script exports the model, use deploy / Python / infer -- run in py script_ The benchmark parameter uses the Paddle prediction library for reasoning speed benchmark test results, and the tested data are data that do not include data preprocessing and model output post-processing (NMS) (and YOLOv4(AlexyAB) The test method is consistent).
- The speed test of TensorRT FP16 removes Yolo compared with FP32_ The box (bbox decoding) part is time-consuming, that is, it does not include data preprocessing, bbox decoding and NMS (and YOLOv4(AlexyAB) The test method is consistent).
After comprehensive analysis, I chose to use PP-YOLOv2 + ResNet50vd
3. Algorithm implementation based on paddedetection code
This project uses the paddedetection suite. The download address is:
github: https://github.com/PaddlePaddle/PaddleDetection
# Download PaddleDetection !git clone https://gitee.com/paddlepaddle/PaddleDetection.git
3.1 configuring data sets
since the annotation files and pictures provided in the dataset are mixed, we classify them.
The following two methods are provided:
# Method 1:
import os
# Create a layer directory
os.mkdir("Dataset/JPEGImages")
os.makedirs("Dataset/Annotations")
import os
import shutil
# create folder
path_xml = "Dataset/tuberculosis-phonecamera"
filelist = os.listdir(path_xml)
path1 = "Dataset/tuberculosis-phonecamera"
path2 = "Dataset/JPEGImages/"
path3 = "Dataset/Annotations/"
for files in filelist:
filename1 = os.path.splitext(files)[1] # Read file suffix
filename0 = os.path.splitext(files)[0] #Read file name
# print(filename1)
m = filename1 == '.jpg'
# print(m)
if m :
full_path = os.path.join(path1, files)
despath = path2 + filename0+'.jpg' #. jpg is your file type, that is, the suffix
shutil.move(full_path, despath)
else :
full_path = os.path.join(path1, files)
despath = path3 + filename0 + '.xml' # . jpg is your file type, that is, the suffix
shutil.move(full_path, despath)
# Move files to PaddlDetection
os.makedirs("PaddleDetection/dataset/data")
shutil.move('Dataset/Annotations','PaddleDetection/dataset/data')
shutil.move('Dataset/JPEGImages','PaddleDetection/dataset/data')
# Method 2: # create folder !mkdir /home/aistudio/PaddleDetection/data/ !mkdir /home/aistudio/PaddleDetection/data/JPEGImages/ !mkdir /home/aistudio/PaddleDetection/data/Annotations/ # Move two files separately !mv ../tuberculosis-phonecamera/*.jpg /home/aistudio/PaddleDetection/data/JPEGImages/ !mv ../tuberculosis-phonecamera/*.xml /home/aistudio/PaddleDetection/data/Annotations/
3.2 divide training set and verification set
Two methods are also provided:
1. Direct partitioning using PaddleX
! paddlex --split_dataset --format VOC --dataset_dir file path -- val_ value 0.2 --test_ Value 0.1 (remember to modify the file path)
2. See the demonstration below
import os
import random
# Number of categories
file_saved = [] # Save data
random.seed(2022) # Set random number seed
# voc data path problem
# Root directory information, subdirectory information, files_img -- file name under this folder
for _, _, files_img in os.walk('PaddleDetection/dataset/data/JPEGImages'):
random.shuffle(files_img)
for _, _, files_xml in os.walk('PaddleDetection/dataset/data/Annotations'):
# indexs = 0
# 1.jpg
# 1.xml
for i in range(len(files_img)): # Traverse image files -- one by one
for j in range(len(files_xml)):
# xml file matching the prefix name of the picture
# Is the prefix consistent
if files_img[i][:-4] == files_xml[j][:-4]:
# Relative path of picture + space + relative path of label file + '\ n'
# jpeg, img -- join -> jpeg/img
# JPEGImages/files_img[i]
file_maked = os.path.join('JPEGImages', files_img[i]) + ' ' + os.path.join('Annotations', files_xml[j]) + '\n'
file_saved.append(file_maked) # Each category is placed in the corresponding cache space
break
# example: relative path of picture + space + relative path of label file + '\ n'
# Division of training set
# The training set accounts for 80% of the data
# Validation set / evaluation data set: 1-80% = 20%
Train_percent = 0.8
# train.txt save
with open('PaddleDetection/dataset/data/train.txt', 'w') as f:
# int(Train_percent * len(file_saved))
# final_index = int(len(file_saved)*Train_percent) - 1
f.writelines(file_saved[:int(len(file_saved)*Train_percent)]) # Write multiline data
print('train.txt Has Writed {0} records!'.format(len(file_saved[:int(len(file_saved)*Train_percent)])))
# eval.txt save
with open('PaddleDetection/dataset/data/eval.txt', 'w') as f:
# final_index + 1 == int(len(file_saved)*Train_percent)
f.writelines(file_saved[int(len(file_saved)*Train_percent):])
print('eval.txt Has Writed {0} records!'.format(len(file_saved[int(len(file_saved)*Train_percent):])))
3.3 modify source code and configuration file
New label_list.txt
after division, we already have eval Txt and train Txt, we also need our label file. By analyzing the data set, we need to identify only one type of TBbacillus binding bacteria, so we create a new label_list.txt add label

def text_create(name, msg):
desktop_path = "PaddleDetection/dataset/data/" # The storage path of the newly created txt file
full_path = desktop_path + name + '.txt'
file = open(full_path, 'w')
file.write(msg) # msg is the TBbacillus below!
file.close() # Remember to close the file
text_create('label_list', 'TBbacillus')
Modify the source file and configure the model
open the file in this directory and change it to picture style paddedetection / configurations / ppyolo / ppyolov2_ r50vd_ dcn_ voc. yml
snapshot_epoch saves rounds and cycles for iteration rounds and parameters, which should be determined according to your specific sample number. You can keep the default value first (because it is only an example, I write it as 5 for convenience)
epoch training batch
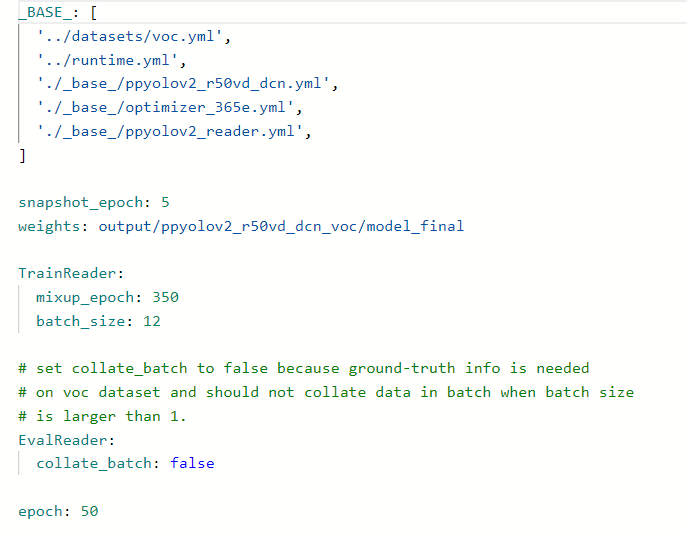
after that, modify the following directory file paddedetection / configurations / datasets / VOC yml
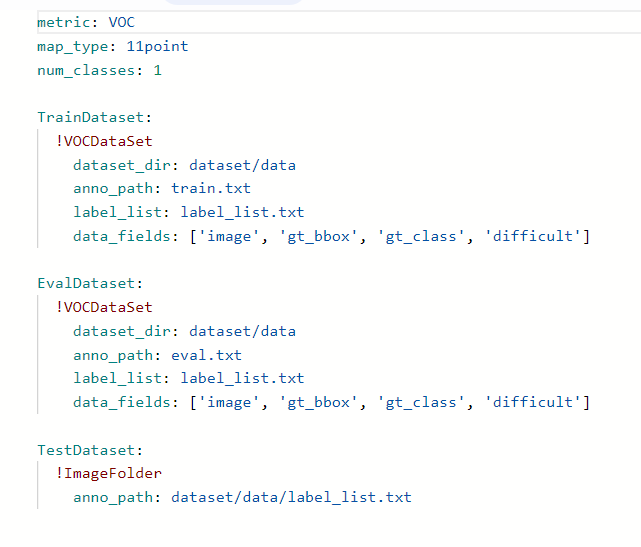
modify the path to the previously stored training set, verification set and label path
🎯 Error prone warning
during training, I found that there was no size keyword in the tag file (that is, there was no size of the original image), so I passed the following test:
import cv2
img = cv2.imread('PaddleDetection/dataset/data/JPEGImages/tuberculosis-phone-0002.jpg')
h,w,c = img.shape
print(h)
print(w)
print(c)
through the above code, I tested many pictures and found that the pictures in the dataset are of this size: width = 1632,height = 1224,depth = 3, so paddedetection / ppdet / data / source / VOC Py modify under this directory And give an initial value
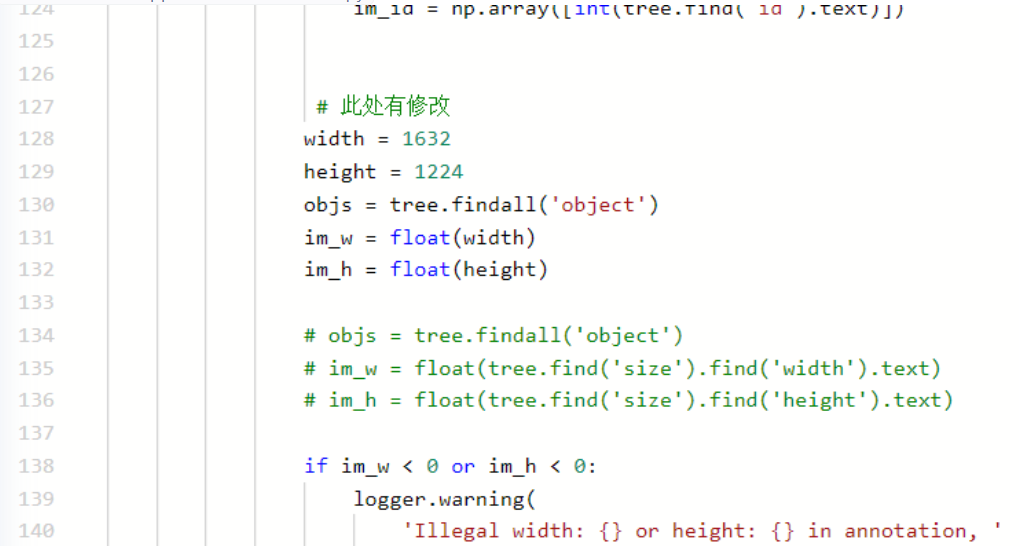
4. Model training
# Download paddedetection dependency Library %cd /home/aistudio/PaddleDetection/ !pip install -r requirements.txt
# Because he prompted me to update pip, I updated it To update it !/opt/conda/envs/python35-paddle120-env/bin/python -m pip install --use --upgrade pip
!python setup.py install
# Model training and configure GPU training import os os.environ['CUDA_VISIBLE_DEVICES'] = '0' %cd /home/aistudio/PaddleDetection/ # !CUDA_VISIBLE_DEVICES=0 !python tools/train.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml --use_vdl=True --vdl_log_dir="./output"
5. Data model visualization
After setting the following
We can view the parameters during our training
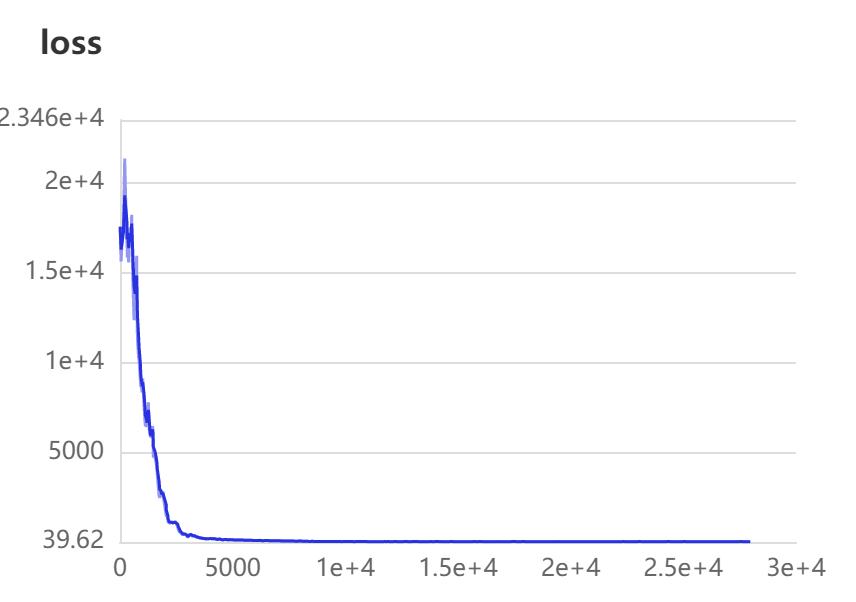
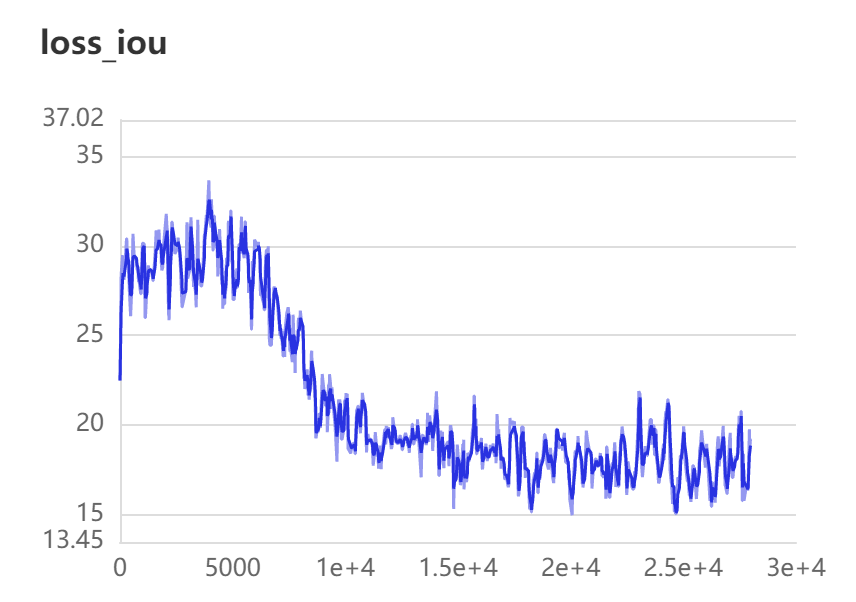
6. Model evaluation
Because the training time is too long, I only conducted a short training. The final best is this file. We can test its accuracy through the following code
!python -u tools/eval.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml
7. Prediction model
!python tools/infer.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml\ --infer_img=/home/aistudio/PaddleDetection/dataset/data/JPEGImages/tuberculosis-phone-0641.jpg \ -o weights=/home/aistudio/PaddleDetection/output/ppyolov2_r50vd_dcn_voc/model_final.pdparams
Here are the effects we detected


summary
at present, there are still many aspects of the project that can be optimized. You are welcome to ask questions and suggestions
This project has been open source in Github and Gitee. You are welcome to praise it
Github link: https://github.com/Yao-BH/PaddleDetection-TBbacillus
Gitee link: https://gitee.com/yao-bohao/PaddleDetection-TBbacillus
1. Be sure to improve and learn the project in combination with the source code
2. There are not too many data sets in this project. You can add more data and modify relevant parameters later, so the accuracy will be better
3. At the same time, I also thank the boss for his help, so that I can solve problems faster. 🔥🔥🔥
Introduction to the author
Yao Bohao, a 2020 undergraduate majoring in data science and big data technology
I am also a little white running on the road of deep learning. I also hope that some of my experience in stepping on the pit can be of some help to you.
Head of Baidu PaddlePaddle pilot group
Internet + provincial Silver Award, second prize of northwest division of China University computer competition, etc