1, NN Functional and NN Module
Earlier, we introduced the structure operation of Pytorch's tensor and some common API s in mathematical operation.
Using these tensor API s, we can construct neural network related components (such as activation function, model layer, loss function).
Most of the functional components related to Pytorch and neural network are encapsulated in torch NN module.
Most of these functional components are implemented in both function form and class form.
Where NN Functional (generally renamed f after introduction) has the function implementation of various functional components. For example:
(activate function)
- F.relu
- F.sigmoid
- F.tanh
- F.softmax
(model layer)
- F.linear
- F.conv2d
- F.max_pool2d
- F.dropout2d
- F.embedding
(loss function)
- F.binary_cross_entropy
- F.mse_loss
- F.cross_entropy
In order to facilitate the management of parameters, we usually inherit nn Module is converted into the implementation form of class and directly encapsulated in nn module. For example:
(activate function)
- nn.ReLU
- nn.Sigmoid
- nn.Tanh
- nn.Softmax
(model layer)
- nn.Linear
- nn.Conv2d
- nn.MaxPool2d
- nn.Dropout2d
- nn.Embedding
(loss function)
- nn.BCELoss
- nn.MSELoss
- nn.CrossEntropyLoss
Actually NN In addition to managing various parameters referenced by module, module can also manage its referenced sub modules, which is very powerful.
2, Use NN Module to manage parameters
In pytoch, the parameters of the model need to be trained by the optimizer. Therefore, the parameter is usually set to requires_ Grad = tensor of true.
At the same time, there are often many parameters in a model. It is not easy to manage these parameters manually.
Pytoch generally uses NN as the parameter Parameter and NN Module to manage all parameters under its structure.
import torch from torch import nn import torch.nn.functional as F from matplotlib import pyplot as plt
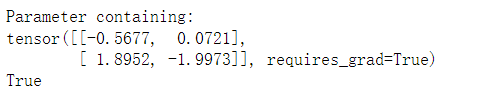
# nn.Parameter has requirements_ Grad = true attribute w = nn.Parameter(torch.randn(2,2)) print(w) print(w.requires_grad)
# nn.ParameterList can add multiple NN The parameter forms a list params_list = nn.ParameterList([nn.Parameter(torch.rand(8,i)) for i in range(1,3)]) print(params_list) print(params_list[0].requires_grad)

# nn.ParameterDict can convert multiple NN Parameter forms a dictionary
params_dict = nn.ParameterDict({"a":nn.Parameter(torch.rand(2,2)),
"b":nn.Parameter(torch.zeros(2))})
print(params_dict)
print(params_dict["a"].requires_grad)

# They can be managed using the Module
# module.parameters() returns a generator, including all parameters under its structure
module = nn.Module()
module.w = w
module.params_list = params_list
module.params_dict = params_dict
num_param = 0
for param in module.parameters():
print(param,"\n")
num_param = num_param + 1
print("number of Parameters =",num_param)

#In practice, generally through inheritance NN Module to build the module class, and put all the parts containing the parameters to be learned in the constructor.
#The following example is NN in pytoch Simplified version of linear's source code
#You can see that it puts the parameters to be learned in__ init__ In the constructor, the F.linear function is invoked in forward to realize the computation logic.
class Linear(nn.Module):
__constants__ = ['in_features', 'out_features']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
3, Use NN Module to manage sub modules
Generally, we seldom use NN directly Parameter is used to define parameters to build the model, but the model is constructed by assembling some common model layers.
These model layers are also inherited from NN The object of module itself also includes parameters and belongs to the sub module of the module we want to define.
nn.Module provides some methods to manage these sub modules.
children() method: returns the generator, including all sub modules under the module.
named_children() method: return a generator, including all sub modules under the module and their names.
modules() method: returns a generator, including all modules at all levels under the module, including the module itself.
named_modules() method: return a generator, including all modules at all levels under the module and their names, including the module itself.
Where chidren() method and named_ The children () method is widely used.
modules() method and named_ The modules() method is rarely used, and its functions can be through multiple named methods_ The nested use implementation of children ().
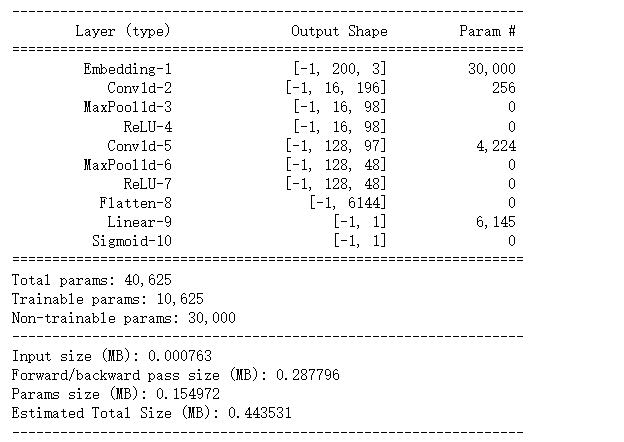
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.embedding = nn.Embedding(num_embeddings = 10000,embedding_dim = 3,padding_idx = 1)
self.conv = nn.Sequential()
self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))
self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_1",nn.ReLU())
self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))
self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_2",nn.ReLU())
self.dense = nn.Sequential()
self.dense.add_module("flatten",nn.Flatten())
self.dense.add_module("linear",nn.Linear(6144,1))
self.dense.add_module("sigmoid",nn.Sigmoid())
def forward(self,x):
x = self.embedding(x).transpose(1,2)
x = self.conv(x)
y = self.dense(x)
return y
net = Net()
i = 0
for child in net.children():
i+=1
print(child,"\n")
print("child number",i)

i = 0
for name,child in net.named_children():
i+=1
print(name,":",child,"\n")
print("child number",i)

i = 0
for module in net.modules():
i+=1
print(module)
print("module number:",i)

Let's go through named_ The children method finds the embedding layer and sets its parameters to untrainable (equivalent to freezing the embedding layer).
children_dict = {name:module for name,module in net.named_children()}
print(children_dict)
embedding = children_dict["embedding"]
embedding.requires_grad_(False) #Freeze its parameters

#It can be seen that the parameters of the first layer can no longer be trained.
for param in embedding.parameters():
print(param.requires_grad)
print(param.numel())
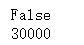
from torchkeras import summary summary(net,input_shape = (200,),input_dtype = torch.LongTensor) # Increase in the number of untrained parameters