Article catalogue
- preface
- 1, Analyze the composition of Taobao URL
- 2, View the web source code and extract information with re library
- 3: Function filling
- 4: Main function filling
- 5: Complete code
preface
This paper simply uses python's requests library and re regular expression to crawl Taobao's commodity information (commodity name, commodity price, production region, and sales volume), and finally uses xlsxwriter library to put the information into Excel. The final rendering is as follows:
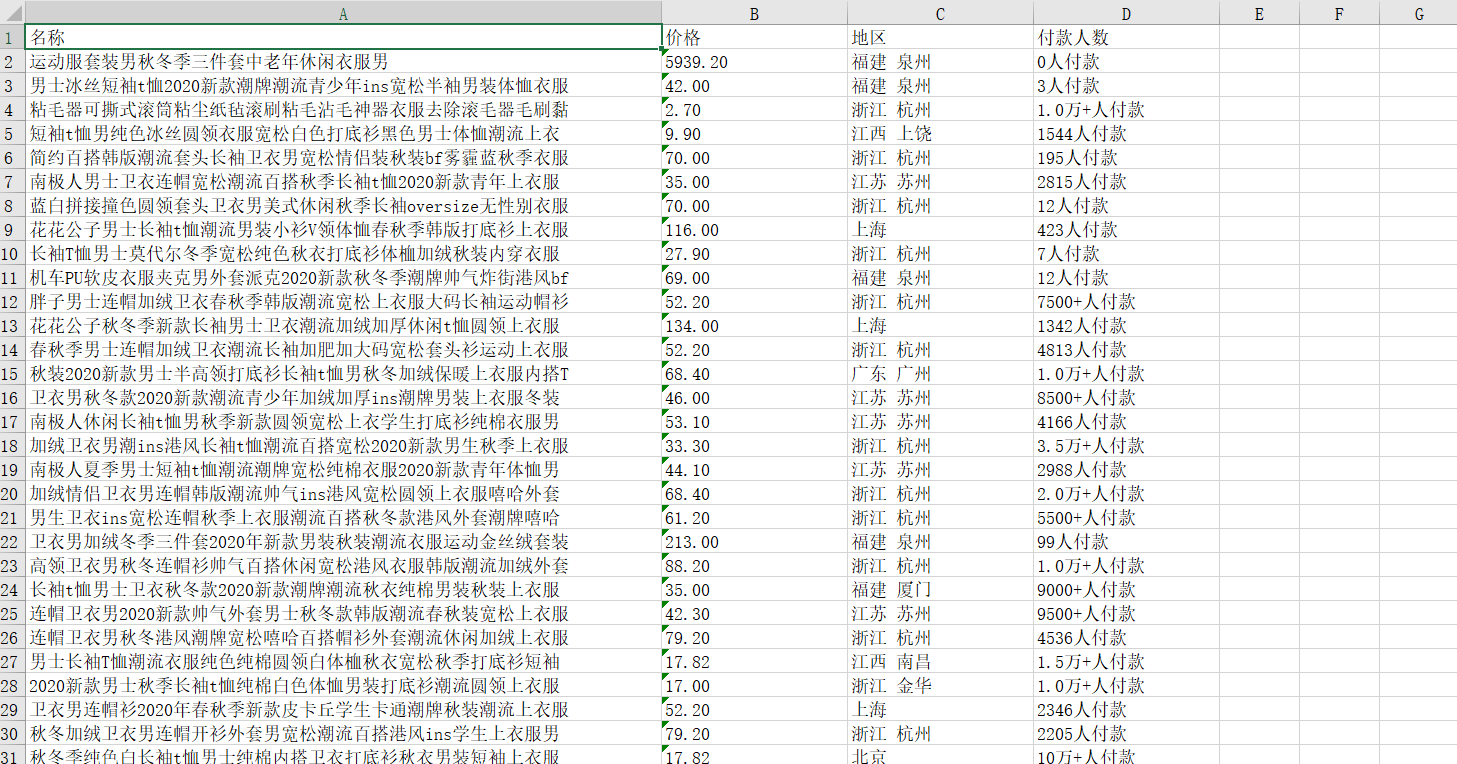
Tip: the following is the main content of this article
1, Analyze the composition of Taobao URL
1. Our first requirement is to enter the product name and return the corresponding information
So we choose a random commodity here to observe its URL. Here we choose a schoolbag. Open the web page and we can see that its URL is:
https://s.taobao.com/searchq=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306
We may not see anything from this url alone, but we can see some clues from the figure

We found that the parameter after q is the name of the item we want to get
2. Our second requirement is to crawl the page number of the product according to the input number
So let's take a look at the composition of the URL s in the next few pages
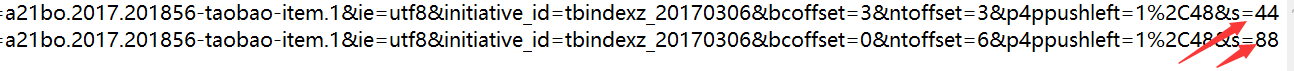
From this, we can conclude that the pagination is based on the value of the last s = (44 (Pages - 1))
2, View the web source code and extract information with re library
1. Check the source code

Here are some information we need
2.re database extraction information
If you don't understand the re library, you can see the re summary I just wrote
Portal!!!!!!!!!!!!!!!.
a = re.findall(r'"raw_title":"(.*?)"', html)
b = re.findall(r'"view_price":"(.*?)"', html)
c = re.findall(r'"item_loc":"(.*?)"', html)
d = re.findall(r'"view_sales":"(.*?)"', html)
3: Function filling
Here I have written three functions. The first function is to get the html page. The code is as follows:
def GetHtml(url):
r = requests.get(url,headers =headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
The second URL code used to obtain the web page is as follows:
def Geturls(q, x):
url = "https://s.taobao.com/search?q=" + q + "&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm"
"=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 "
urls = []
urls.append(url)
if x == 1:
return urls
for i in range(1, x ):
url = "https://s.taobao.com/search?q="+ q + "&commend=all&ssid=s5-e&search_type=item"
"&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306"
"&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=" + str(
i * 44)
urls.append(url)
return urls
The third one is used to obtain the commodity information we need and write it into Excel. The code is as follows:
def GetxxintoExcel(html):
global count#Define a global variable count to fill in the following excel table
a = re.findall(r'"raw_title":"(.*?)"', html)#(.*?) Match any character
b = re.findall(r'"view_price":"(.*?)"', html)
c = re.findall(r'"item_loc":"(.*?)"', html)
d = re.findall(r'"view_sales":"(.*?)"', html)
x = []
for i in range(len(a)):
try:
x.append((a[i],b[i],c[i],d[i]))#Put the obtained information into a new list
except IndexError:
break
i = 0
for i in range(len(x)):
worksheet.write(count + i + 1, 0, x[i][0])#worksheet. The write method is used to write data. The first number is the row position, the second number is the column, and the third is the written data information.
worksheet.write(count + i + 1, 1, x[i][1])
worksheet.write(count + i + 1, 2, x[i][2])
worksheet.write(count + i + 1, 3, x[i][3])
count = count +len(x) #The number of lines to be written next time is the length of this time + 1
return print("Completed")
4: Main function filling
if __name__ == "__main__":
count = 0
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
,"cookie":""#Cookies are unique to everyone. Because of the anti crawling mechanism, if you crawl too fast, you may have to refresh your Cookie s later.
}
q = input("Import goods")
x = int(input("How many pages do you want to crawl"))
urls = Geturls(q,x)
workbook = xlsxwriter.Workbook(q+".xlsx")
worksheet = workbook.add_worksheet()
worksheet.set_column('A:A', 70)
worksheet.set_column('B:B', 20)
worksheet.set_column('C:C', 20)
worksheet.set_column('D:D', 20)
worksheet.write('A1', 'name')
worksheet.write('B1', 'Price')
worksheet.write('C1', 'region')
worksheet.write('D1', 'Number of payers')
for url in urls:
html = GetHtml(url)
s = GetxxintoExcel(html.text)
time.sleep(5)
workbook.close()#Do not open excel before the end of the program. The excel table is in the current directory
5: Complete code
import re
import requests
import xlsxwriter
import time
def GetxxintoExcel(html):
global count
a = re.findall(r'"raw_title":"(.*?)"', html)
b = re.findall(r'"view_price":"(.*?)"', html)
c = re.findall(r'"item_loc":"(.*?)"', html)
d = re.findall(r'"view_sales":"(.*?)"', html)
x = []
for i in range(len(a)):
try:
x.append((a[i],b[i],c[i],d[i]))
except IndexError:
break
i = 0
for i in range(len(x)):
worksheet.write(count + i + 1, 0, x[i][0])
worksheet.write(count + i + 1, 1, x[i][1])
worksheet.write(count + i + 1, 2, x[i][2])
worksheet.write(count + i + 1, 3, x[i][3])
count = count +len(x)
return print("Completed")
def Geturls(q, x):
url = "https://s.taobao.com/search?q=" + q + "&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm"
"=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 "
urls = []
urls.append(url)
if x == 1:
return urls
for i in range(1, x ):
url = "https://s.taobao.com/search?q="+ q + "&commend=all&ssid=s5-e&search_type=item"
"&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306"
"&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=" + str(
i * 44)
urls.append(url)
return urls
def GetHtml(url):
r = requests.get(url,headers =headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
if __name__ == "__main__":
count = 0
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
,"cookie":""
}
q = input("Import goods")
x = int(input("How many pages do you want to crawl"))
urls = Geturls(q,x)
workbook = xlsxwriter.Workbook(q+".xlsx")
worksheet = workbook.add_worksheet()
worksheet.set_column('A:A', 70)
worksheet.set_column('B:B', 20)
worksheet.set_column('C:C', 20)
worksheet.set_column('D:D', 20)
worksheet.write('A1', 'name')
worksheet.write('B1', 'Price')
worksheet.write('C1', 'region')
worksheet.write('D1', 'Number of payers')
xx = []
for url in urls:
html = GetHtml(url)
s = GetxxintoExcel(html.text)
time.sleep(5)
workbook.close()
Finally, I thought it was OK

New article: Actual combat of python crawler -- crawl the cat's eye movie TOP100 and import it into excel