catalogue
Code:
import requests
from bs4 import BeautifulSoup
import re
def getHTML(url):
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56"
}
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
#print(r.request.headers)
r.encoding =r.apparent_encoding
return r.text
except:
return "raise an exception."
def gettitele(str1):
# title = str1.find_all("h4")
detials = str1.select('h4')[0].text
title_len = len(str1.select('h4'))#Get Title Length
#print(title_len)
#print(str1.select('h4')[19].text)
#print(detials)
title= {}
for i in range(0, title_len):
title[i]=str1.select('h4')[i].text
return title
def geturl(str1):
url= str1.select(".mainContent")#Find nearest box
url=str(url)
url=BeautifulSoup(url, 'html.parser')
#ans=url.find_all("href")
#url=url.select("a")
num = 0
for i in range(len(url.select("a"))):#Traverse all a Tags
# print(url.select("a")[i])
str2=str(url.select("a")[i])#Find a tag
str2 = BeautifulSoup(str2, 'html.parser')
str2 = str2.find("a")
str2=str2.get("href") #Get link properties
str2=str(str2)
#pattern = re.compile(str2)
#print(pattern)
ans=re.findall(r".*csdn.*",str2)
# print(ans)
if (len(ans)!=0):
num+=1
print(ans,num)
url="https://blog.csdn.net/kilig_CSM?type=blog"
html=getHTML(url)
#print(getHTML(url))
str1 = BeautifulSoup(html, 'html.parser')
title=gettitele(str1)
num=0
for i in range(len(title)):
num += 1
print(title[i],num)
geturl(str1)
#print(title)
Summary:
Crawling a web page is very simple. You only need to disguise the crawler's head and send a request to the server. In this program, getHTML is implemented by constructor Page analysis is relatively troublesome
By viewing the page code, it is found that the title of all problems or articles on the page are < H4 > tags
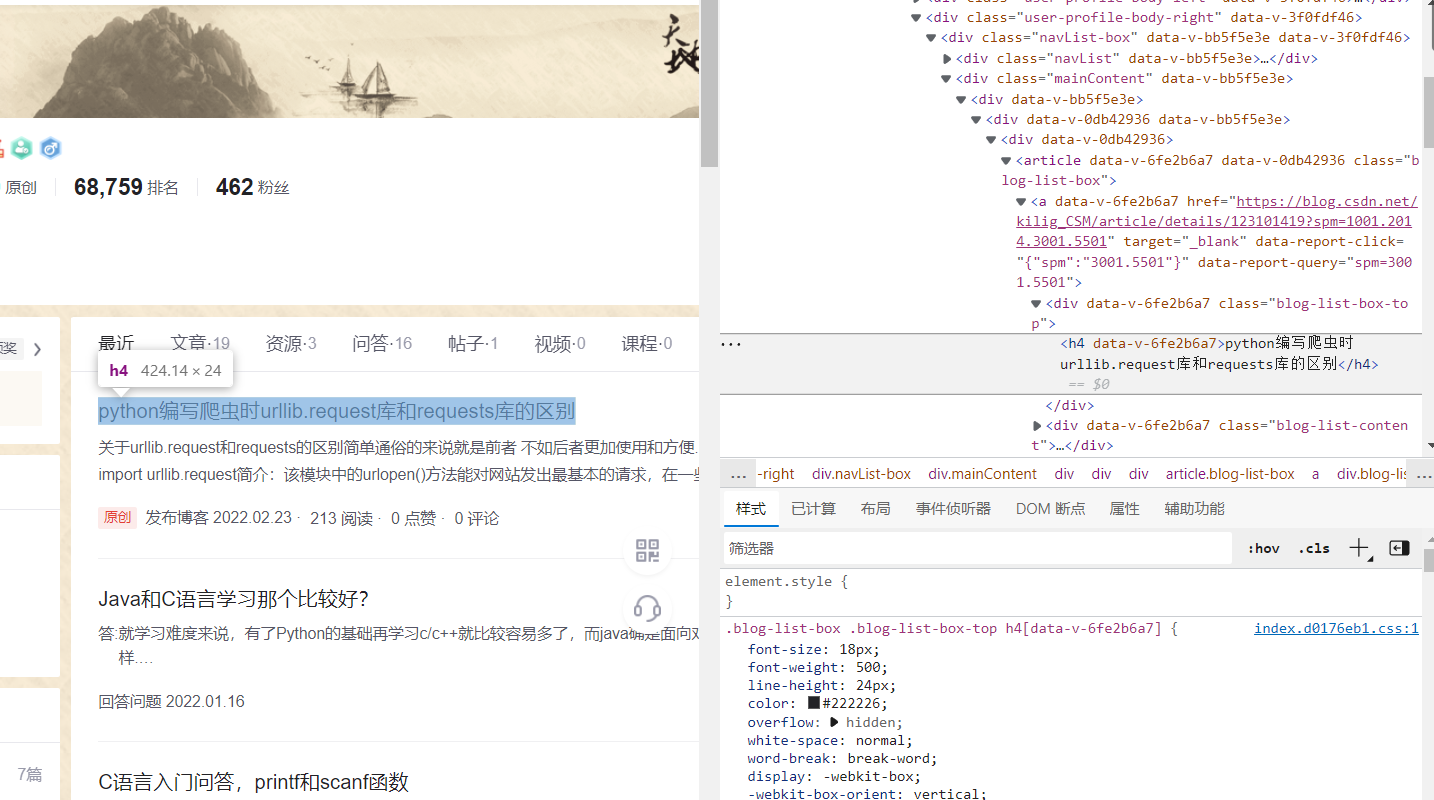
So we can directly find the h4 tag, and the link is stored in the href attribute in the < a > tag. However, direct search will find many other links, such as opening vip It is found that all links of the page are stored in the < a > tag, but we only need the links corresponding to the recent articles or problems. By looking at the page code, we find that all relevant tags of the "recent" column box exist as sub tags in the div tag with the attribute of mainContent
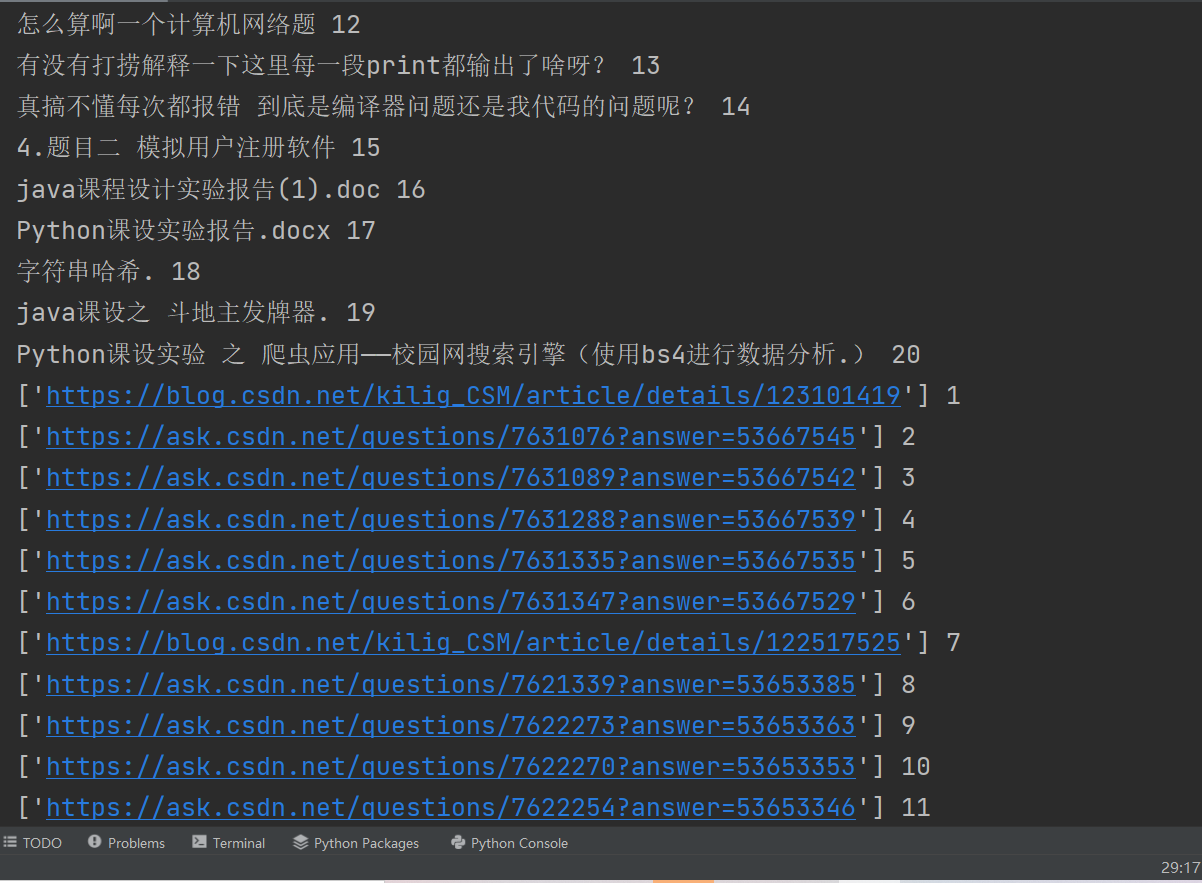
So let's find mainContent first
Then go to the a tag in his sub tag and get the href attribute
However, it should be noted that if you recently answered someone else's question and put a link in your answer
Then follow the method just now to find links, there will be more links than titles The reason is that the link in your answer will be placed in the tag of the answer, and the attribute of the most sub tag a will appear instead of in the text
At this time, the link can be washed out through regular expression You only need to find all links related to. csdn
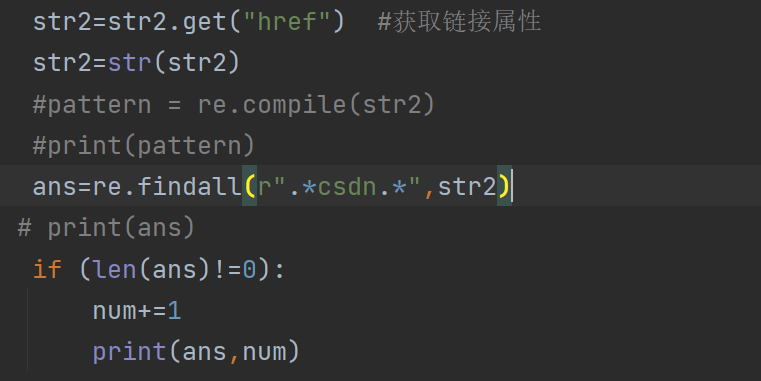 Of course, there is a bug in this method. For example, put a csdn related link in the answer, so you can't wash away the link Because bloggers compare dishes and are still learning about reptiles, they haven't found a better way. If you have a better way, please be sure to comment
Of course, there is a bug in this method. For example, put a csdn related link in the answer, so you can't wash away the link Because bloggers compare dishes and are still learning about reptiles, they haven't found a better way. If you have a better way, please be sure to comment