Hello, dear friends, Yien is seeing you again. Unlike the general introduction articles on the Internet, which only stay at the level of "how to use", this article understands gradle from the perspective of source code.

Of course, if you haven't read my previous article "If you don't understand gradle after reading this article, you'd better delete me" , I suggest you take a look first. Many knowledge points of this article will be expanded on the basis of the previous article.
This article will be more in-depth and will take some brains and energy to understand. It is suggested to follow my writing ideas step by step. This article will be long. It takes about half an hour to read. Reading this article will understand:
- gradle build Lifecycle
- gradle Extension and Plugin
- gradle dependent implementation, Configuration
gradle build Lifecycle
We also talked about the concept of Lifecycle when we talked about Project in the last article. In this article, we will briefly talk about it as an introduction.
As stated on the official website, the gradle construction process consists of three stages:
Initialization phase: in this phase, Settings Gradle is the protagonist. Gradle will put Settings The configuration in gradle is delegated to the Settings class. It is mainly responsible for determining which modules need to participate in the construction, and then initializing their delegate object Project according to the Settings of these modules. Note that Project objects are generated during the initialization phase.
Configuration phase: the Task of configuration phase is to execute the build under each Project Gradle, complete the configuration of the Project object, and construct the Task dependency graph taskexitiongraph to execute the Task according to the dependency in the execution phase.
Execution phase: the execution phase will call gradle taskname according to the dependency relationship according to the Task entered on the command line.
It is worth mentioning that we can monitor and process the project construction phase in a variety of ways. as
// The following is the method of Project afterEvaluate(closure),afterEvaluate(action) beforeEvaluate(closure),beforeEvaluate(action) // The following is the lifecycle callback provided by gradle afterProject(closure),afterProject(action) beforeProject(closure),beforeProject(action) buildFinished(closure),buildFinished(action) projectsEvaluated(closure),projectsEvaluated(action) projectsLoaded(closure),projectsLoaded(action) settingsEvaluated(closure),settingsEvaluated(action) addBuildListener(buildListener) addListener(listener) addProjectEvaluationListener(listener) // Task also has this method afterTask(Closure closure) beforeTask(Closure closure) //Call after task is ready whenReady(Closure closure)
So how can we use this build process? We can monitor or dynamically control the construction and execution of project s and tasks as needed. For example, in order to speed up compilation, we remove some test tasks. It can be written like this
gradle.taskGraph.whenReady {
tasks.each { task ->
if (task.name.contains("Test")) {
task.enabled = false
} else if (task.name == "mockableAndroidJar") {
task.enabled = false
}
}
}
Extension and Plugin
Extension and Plugin are often mentioned in our daily development. In the last article, we talked about build All closures in gradle have a Delegate proxy. The proxy object can accept the parameters in the closure and pass them to itself for use. What is the proxy? In fact, it is the extension we want to talk about here.
- Generally speaking, Extension is actually an ordinary java bean. It stores some parameters. The use needs to be created with the help of ExtensionContainer. Take a chestnut
// First define an entity class
public class Message {
String message = "empty"
String greeter = "none"
}
// Next, use project in the gradle file Extensions (that is, ExtensionContainer). def extension = project.extensions.create("cyMessage", Message) / / write another task to verify the project task('sendMessage') { doLast { println "${extension.message} from ${extension.greeter}" println project. cyMessage. message + "from ${extension.greeter}" } }
- After Plugin plug-in talks about extension, we may be confused. Because we're building These operations added by JavaBeans and extension are not seen in gradle, so where is the code written? At this time, we will introduce the concept of Plugin, which is what you can see
apply plugin 'com.android.application'
This thing. This is the plug-in of Android Application. Android related extensions are defined in this plug-in. Some students may not understand the plug-in very well and why they need it. In fact, you can think about it. Gradle is just a general construction tool. There may be various applications on its upper layer, such as java, Android and even Hongmeng in the future. Then these applications will certainly have different extensions to gradle, and they certainly can't put these extensions directly in gradle. Therefore, adding plug-ins at the upper level is a good choice. You can choose whatever plug-ins you need. There are three common plug-ins in Android Development:
apply plugin 'com.android.application' // AppPlugin can only be referenced by the main module apply plugin 'com.android.library' // LibraryPlugin, a common android module reference apply plugin 'java' // Reference of java module
Other knowledge of plug-ins is not the focus of this article. There are many articles on this aspect on the Internet. You can learn by yourself. Based on our current knowledge, we are going to explore gradle's deeper knowledge.
gradle dependency implementation
Up to now, we have basically passed the processes related to gradle construction in these two articles. But there is a very important component that we didn't analyze. Is dependent management. As we mentioned in the previous article, dependency management is a very important feature of gradle, which is convenient for code reuse. So this part is devoted to how dependency management is realized.
First, let's look at the basic code
dependencies {
implementation fileTree(include: ['*.jar'], dir: 'libs')
implementation 'com.android.support:appcompat-v7:26.1.0'
api 'com.android.support:appcompat-v7:26.1.0'
implementation project(':test')
androidTestImplementation 'com.android.support.test:runner:1.0.1'
annotationProcessor 'com.jakewharton:butterknife-compiler:8.4.0'
}
We can see that there are generally three types of third-party libraries. The first is binary files, and fileTree points to all jar files in this folder. The second is the string coordinate form of the third-party library, and the third is the form of project. Of course, we will also know that there are differences between implementation and api references in the code. The dependency of implementation cannot be passed, but the api can.
In our previous research and development, we may not consider the deep-seated reasons for these three types of third-party libraries and two reference methods. When we look for the implementation, API and other related methods in the DependencyHandler according to the proxy mode mentioned in the previous article, we find that these methods do not seem to be defined, so what's the matter? If there is no definition, can you define a reference method at will? With questions, let's look down
1. Reading posture
First of all, let's introduce the way to read the gradle source code. I tried many ways, found that Android studio is the most comfortable to read, and then found a way. You can build a demo of gradle, and then build a module, except build Delete everything except gradle. Then copy the following code in. So you can see the source code
apply plugin 'java'
dependencies {
implementation gradleApi()
implementation 'com.android.tools.build:gradle:3.5.0' // Fill in your gradle version
}
2. Source code analysis
2.1 methodmissing
First, let's introduce a feature of groovy language: Method missing. You can refer to the official website. In short, when we define a methodmissing method in a class in advance. Then, when a method that has not been defined before is called on the object of this class, the method will fall back to the methodmissing method defined by it.
class GORM {
def dynamicMethods = [...] // an array of dynamic methods that use regex
def methodMissing(String name, args) {
def method = dynamicMethods.find { it.match(name) }
if(method) {
GORM.metaClass."$name" = { Object[] varArgs ->
method.invoke(delegate, name, varArgs)
}
return method.invoke(delegate,name, args)
} else throw new MissingMethodException(name, delegate, args)
}
}
assert new GORM().methodA(1) == resultA
As shown in the figure, when we call methodA, because the method is not defined, we will go to the methodmissing method, and pass the name of the method methodA and its parameters to methodmissing, so that if methodA is defined in the dynamic method, the method can be executed. This is how methodmissing works.
Why is this mechanism needed? I understand this is for scalability. dependencies is the function of gradle itself. It cannot completely summarize the possible reference methods of all upper-level applications. Each plug-in may add references. In order to be extensible, this feature of methodmissing must be adopted and these references must be handled by the plug-in. For example, Android's implementation, API, annotation processor, etc.
2.2 Configuration
Before going to the following explanation, let's first understand some knowledge of Configuration.
According to the official website:
Every dependency declared for a Gradle project applies to a specific
scope. For example some dependencies should be used for compiling
source code whereas others only need to be available at runtime.
Gradle represents the scope of a dependency with the help of a
Configuration. Every configuration can be identified by a unique name.
In other words, Configuration defines different ranges of dependencies during compilation and run time. Each Configuration has a name to distinguish it. For example, implementation and testRuntime are two common dependencies of android.
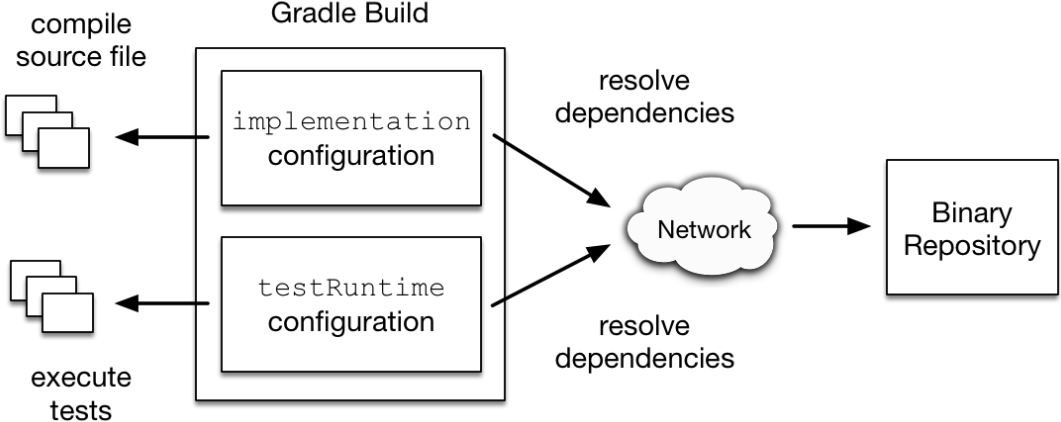
2.3 identification of dependencies
gradle uses the MethodMixIn interface to implement the capability of methodmissing.
// MethodMixIn
public interface MethodMixIn {
MethodAccess getAdditionalMethods();
}
public interface MethodAccess {
/**
* Returns true when this object is known to have a method with the given name that accepts the given arguments.
*
* <p>Note that not every method is known. Some methods may require an attempt invoke it in order for them to be discovered.</p>
*/
boolean hasMethod(String name, Object... arguments);
/*
* Invokes the method with the given name and arguments.
*/
DynamicInvokeResult tryInvokeMethod(String name, Object... arguments);
}
You can see that the methodmissing here is mainly to return a MethodAccess when the method cannot be found. In MethodAccess, you can judge whether it exists and execute the method dynamically.
Next, let's look at the implementation class DefaultDependencyHandler of DependencyHandler. This class implements the MethodMixIn interface and returns a DynamicAddDependencyMethods object.
// DefaultDependencyHandler.java
public DefaultDependencyHandler(...) {
...
this.dynamicMethods = new DynamicAddDependencyMethods(configurationContainer, new DefaultDependencyHandler.DirectDependencyAdder());
}
public MethodAccess getAdditionalMethods() {
return this.dynamicMethods;
}
So it actually returns a dynamic adddependencymethods to judge. Then there is no doubt that we should judge and execute specific methods in this class. Next, let's look at how it is handled in this class.
DynamicAddDependencyMethods(ConfigurationContainer configurationContainer, DynamicAddDependencyMethods.DependencyAdder dependencyAdder) {
this.configurationContainer = configurationContainer;
this.dependencyAdder = dependencyAdder;
}
public boolean hasMethod(String name, Object... arguments) {
return arguments.length != 0 && this.configurationContainer.findByName(name) != null;
}
public DynamicInvokeResult tryInvokeMethod(String name, Object... arguments) {
if (arguments.length == 0) {
return DynamicInvokeResult.notFound();
} else {
Configuration configuration = (Configuration)this.configurationContainer.findByName(name);
if (configuration == null) {
return DynamicInvokeResult.notFound();
} else {
List<?> normalizedArgs = CollectionUtils.flattenCollections(arguments);
if (normalizedArgs.size() == 2 && normalizedArgs.get(1) instanceof Closure) {
return DynamicInvokeResult.found(this.dependencyAdder.add(configuration, normalizedArgs.get(0), (Closure)normalizedArgs.get(1)));
} else if (normalizedArgs.size() == 1) {
return DynamicInvokeResult.found(this.dependencyAdder.add(configuration, normalizedArgs.get(0), (Closure)null));
} else {
Iterator var5 = normalizedArgs.iterator();
while(var5.hasNext()) {
Object arg = var5.next();
this.dependencyAdder.add(configuration, arg, (Closure)null);
}
return DynamicInvokeResult.found();
}
}
}
}
You can see two key points of this class:
1. Judge whether Configuration exists: judge whether this method exists through the externally passed in ConfigurationContainer** In this way, we can think that this ConfigurationContainer must be imported by each platform Plugin, and must be defined before it can be used** For example, android adds implementation, api and so on. If you want to check the initialization and Configuration of Configuration in gradle source code, you can check the class VariantDependencies.
2. Execution method: the real execution method will be judged according to the parameters, such as the reference form of a common parameter and the form of a parameter + a closure, such as
compile('com.zhyea:ar4j:1.0') {
exclude module: 'cglib' //by artifact name
}
This type of reference. When this reference method (hereinafter referred to as Configuration) is found in the ConfigurationContainer, a DynamicInvokeResult will be returned. We'll look at the specific functions of this class later. We'll look at them first. They all made one
this.dependencyAdder.add(configuration, arg, (Closure)null);
What does this operation do? If we continue to follow, we will find that the doAdd method of DefaultDependencyHandler is actually called.
// DefaultDependencyHandler.java
private class DirectDependencyAdder implements DependencyAdder<Dependency> {
private DirectDependencyAdder() {
}
public Dependency add(Configuration configuration, Object dependencyNotation, @Nullable Closure configureAction) {
return DefaultDependencyHandler.this.doAdd(configuration, dependencyNotation, configureAction);
}
}
private Dependency doAdd(Configuration configuration, Object dependencyNotation, Closure configureClosure) {
if (dependencyNotation instanceof Configuration) {
Configuration other = (Configuration)dependencyNotation;
if (!this.configurationContainer.contains(other)) {
throw new UnsupportedOperationException("Currently you can only declare dependencies on configurations from the same project.");
} else {
configuration.extendsFrom(new Configuration[]{
other
});
return null;
}
} else {
Dependency dependency = this.create(dependencyNotation, configureClosure);
configuration.getDependencies().add(dependency);
return dependency;
}
}
As you can see, we will first judge whether the dependencyNotation is configuration. If it exists, let the current configuration inherit the dependencyNotation, that is, all dependencies added to the dependencyNotation will be added to the configuration.
Some friends here may wonder why they have to judge dependency notification? This is mainly to deal with nesting. For example, reference of implementation project(path: 'projectA', configuration: 'configuration'). If you are interested, please check the collectionutils Flattencollections (arguments) method.
To sum up, this process is to use gradle's MethodMixIn interface to transfer all undefined reference methods to getAdditionalMethods method, judge whether Configuration exists in this method, and generate Dependency if it exists.
2.4 creation of dependency
You can see that at the end of the above process, DefaultDependencyHandler calls the Create method to create a Dependency. Let's continue to analyze the process of creating a Dependency.
// DefaultDependencyHandler.java
public Dependency create(Object dependencyNotation, Closure configureClosure) {
Dependency dependency = this.dependencyFactory.createDependency(dependencyNotation);
return (Dependency)ConfigureUtil.configure(configureClosure, dependency);
}
// DefaultDependencyFactory.java
public Dependency createDependency(Object dependencyNotation) {
Dependency dependency = (Dependency)this.dependencyNotationParser.parseNotation(dependencyNotation);
this.injectServices(dependency);
return dependency;
}
You can see that the dependency notation parser is finally called to parse the dependency notation. The dependencynotionparser here is actually the dependencynotionparser class.
public class DependencyNotationParser {
public static NotationParser<Object, Dependency> parser(Instantiator instantiator, DefaultProjectDependencyFactory dependencyFactory, ClassPathRegistry classPathRegistry, FileLookup fileLookup, RuntimeShadedJarFactory runtimeShadedJarFactory, CurrentGradleInstallation currentGradleInstallation, Interner<String> stringInterner) {
return NotationParserBuilder.toType(Dependency.class)
.fromCharSequence(new DependencyStringNotationConverter(instantiator, DefaultExternalModuleDependency.class, stringInterner))
.converter(new DependencyMapNotationConverter(instantiator, DefaultExternalModuleDependency.class))
.fromType(FileCollection.class, new DependencyFilesNotationConverter(instantiator))
.fromType(Project.class, new DependencyProjectNotationConverter(dependencyFactory))
.fromType(ClassPathNotation.class, new DependencyClassPathNotationConverter(instantiator, classPathRegistry, fileLookup.getFileResolver(), runtimeShadedJarFactory, currentGradleInstallation))
.invalidNotationMessage("Comprehensive documentation on dependency notations is available in DSL reference for DependencyHandler type.").toComposite();
}
}
From there, we can see three classes: FileCollection, Project and ClassPathNotation. Does it feel that they correspond to our three forms of tripartite library resources? In fact, the analysis of these three resource forms is carried out with these three classes. DependencyNotationParser integrates these converters into a comprehensive converter. Among them,
- DependencyFilesNotationConverter resolves FileCollection into self resolving dependency, that is, the form of implementation fileTree(include: ['*. jar'], dir: 'libs').
- DependencyProjectNotationConverter resolves Project to ProjectDependency. (i.e. Project a)
- DependencyClassPathNotationConverter converts ClassPathNotation to SelfResolvingDependency. That is, implementation 'xxx'.
These three methods are specific analysis methods. You can read the source code by yourself, which is not the focus of this paper. Therefore, except that Project will be resolved to Project dependency, all others are self resolving dependency. In fact, ProjectDependency is a subclass of SelfResolvingDependency. Their relationship can be seen from the code comments of self resolving dependency.
2.5 ProjectDependency
Next, let's talk about Project dependency A common Project reference is as follows:
implementation project(':projectA')
We already know that the implementation here is an extension added by the plug-in, not included in gradle. What about project? This is what gradle comes with. delegate is the project method of DependencyHandler.
// DefaultDependencyHandler.java
public Dependency project(Map<String, ?> notation) {
return this.dependencyFactory.createProjectDependencyFromMap(this.projectFinder, notation);
}
// DefaultDependencyFactory.java
public ProjectDependency createProjectDependencyFromMap(ProjectFinder projectFinder, Map<? extends String, ? extends Object> map) {
return this.projectDependencyFactory.createFromMap(projectFinder, map);
}
// ProjectDependencyFactory.java
public ProjectDependency createFromMap(ProjectFinder projectFinder, Map<? extends String, ?> map) {
return (ProjectDependency)NotationParserBuilder.toType(ProjectDependency.class).converter(new ProjectDependencyFactory.ProjectDependencyMapNotationConverter(projectFinder, this.factory)).toComposite().parseNotation(map);
}
// ProjectDependencyMapNotationConverter.java
protected ProjectDependency parseMap(@MapKey("path") String path, @Optional @MapKey("configuration") String configuration) {
return this.factory.create(this.projectFinder.getProject(path), configuration);
}
// DefaultProjectDependencyFactory.java
public ProjectDependency create(ProjectInternal project, String configuration) {
DefaultProjectDependency projectDependency = (DefaultProjectDependency)this.instantiator.newInstance(DefaultProjectDependency.class, new Object[]{project, configuration, this.projectAccessListener, this.buildProjectDependencies});
projectDependency.setAttributesFactory(this.attributesFactory);
projectDependency.setCapabilityNotationParser(this.capabilityNotationParser);
return projectDependency;
}
We can see that the incoming project is finally passed to the ProjectDependencyMapNotationConverter. First find the project, and then create the ProjectDependency object through the factory. Of course, considering the influence of Configuration, a DefaultProjectDependency is finally generated. This is the generation process of project dependency.
2.6 embodiment of dependence
You can see here that you have understood different dependency resolution methods, but you may still not understand what dependency is. In fact, the dependency library does not rely on the source code of the third-party library, but the product of the third-party library, which is generated through A series of Task execution. In other words, if projectA depends on projectB, then A has the ownership of B's products. We will introduce the products later. First, let's know what support Configuration has for the product. When we look at the code of Configuration, we can find that it inherits the FileCollection interface, and the FileCollection inherits the Buildable interface. What's the use of this interface? It's very useful. First look at the official website

Buildable represents the product of many Task object generation. There is only one way in it.
public interface Buildable {
TaskDependency getBuildDependencies();
}
Let's look at the implementation of DefaultProjectDependency.
// DefaultProjectDependency.java
public TaskDependencyInternal getBuildDependencies() {
return new DefaultProjectDependency.TaskDependencyImpl();
}
private class TaskDependencyImpl extends AbstractTaskDependency {
private TaskDependencyImpl() {
}
public void visitDependencies(TaskDependencyResolveContext context) {
if (DefaultProjectDependency.this.buildProjectDependencies) {
DefaultProjectDependency.this.projectAccessListener.beforeResolvingProjectDependency(DefaultProjectDependency.this.dependencyProject);
Configuration configuration = DefaultProjectDependency.this.findProjectConfiguration();
context.add(configuration);
context.add(configuration.getAllArtifacts());
}
}
}
public Configuration findProjectConfiguration() {
ConfigurationContainer dependencyConfigurations = this.getDependencyProject().getConfigurations();
String declaredConfiguration = this.getTargetConfiguration();
Configuration selectedConfiguration = dependencyConfigurations.getByName((String)GUtil.elvis(declaredConfiguration, "default"));
if (!selectedConfiguration.isCanBeConsumed()) {
throw new ConfigurationNotConsumableException(this.dependencyProject.getDisplayName(), selectedConfiguration.getName());
} else {
return selectedConfiguration;
}
}
We can see that in fact, when resolving each dependency, if the Configuration declared in the ConfigurationContainer is specified, such as implementation, api, etc., then this Configuration will be returned, otherwise default will be returned. After getting this Configuration, I did this operation
context.add(configuration); context.add(configuration.getAllArtifacts());
The context here is a TaskDependencyResolveContext. Its add method can add objects that can contribute tasks to the result, such as Task, TaskDependencies, Buildable, etc. these types can contribute tasks to the results (we mentioned earlier that the products are generated by tasks).
Here, context refers to configuration and configuration Getallartifacts() is added as Buildable. The difference is configuration Getallartifacts() gets the DefaultPublishArtifactSet object. Next, let's see how the DefaultPublishArtifactSet implements the Buildable method.
public TaskDependency getBuildDependencies() {
return this.builtBy; // The builtBy here is the following ArtifactsTaskDependency object
}
private class ArtifactsTaskDependency extends AbstractTaskDependency {
private ArtifactsTaskDependency() {
}
public void visitDependencies(TaskDependencyResolveContext context) {
Iterator var2 = DefaultPublishArtifactSet.this.iterator();
while(var2.hasNext()) {
PublishArtifact publishArtifact = (PublishArtifact)var2.next();
context.add(publishArtifact);
}
}
}
We found that as expected, the name of the DefaultPublishArtifactSet is the same as that of the DefaultPublishArtifactSet. The PublishArtifact objects contained in it are put into the context one by one as a set.
2.7 summary
In this section, we analyze the differences between different dependency methods, tell you what Configuration is and how dependency works. In this way, we can better know why in daily development. To sum up, that is
- implementation is resolved into different configurations by the plug-in through the method missing mechanism, so it should be predefined.
- Our different dependency declarations will be converted by different Parser converters. Project dependencies will be converted into project dependencies, and the rest will be resolved into self resolving dependencies.
- project dependency is ultimately the dependency of Task and product artifact.
So what is the relationship between Task and product? This involves a deeper level. This article is limited in length. Let's analyze it in the next article.
summary
This article is mainly introduced from Extension and Plugin. It mainly explains the principle and analysis mechanism of gradle dependency, and then throws a question: how are product Artifacts related to dependency? We'll answer this question later in the next article "an article goes deep into gradle (Part 2): Artifacts"