I hope to take notes to record what I have learned, and I hope it can help the same beginner. I also hope that the big guys can help correct the error ~ infringement legislation and deletion.
catalogue
1, Network structure analysis of NNLM
2, Code implementation of NNLM
1, Network structure analysis of NNLM
Neural network language model NNLM is a probabilistic language model, which calculates each parameter in the probabilistic language model through neural network.
The model is shown in the figure
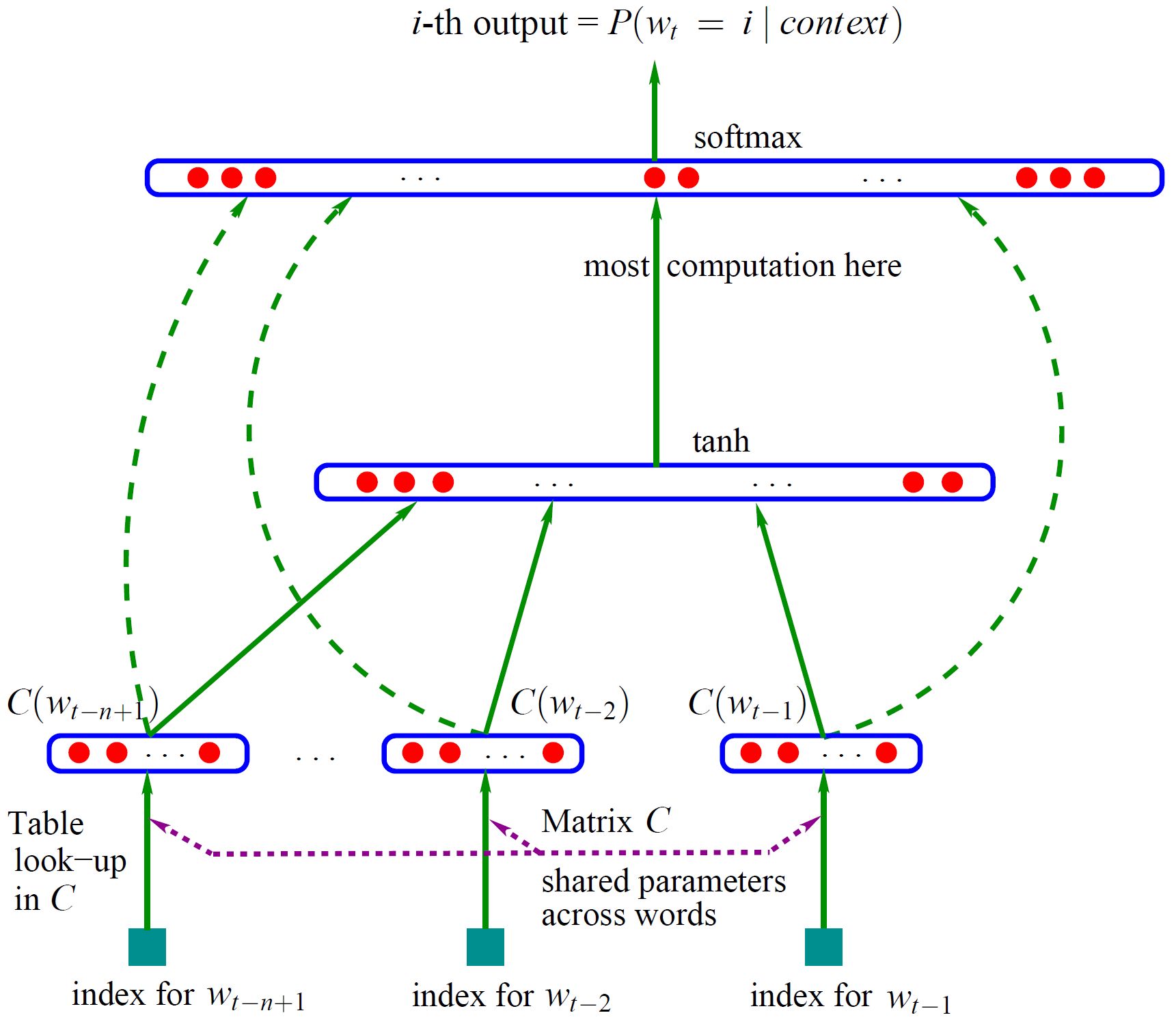
Model input: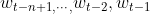 , that is, enter yes
, that is, enter yes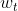 First n-1 words of
First n-1 words of
Model output: predict the next word based on the known n - 1 word
Above:
The word vector representation of the corpus: matrix C - the size is | V| * m, V represents the total number of words in the corpus, and M is the dimension of the word vector
C(w) refers to the word vector corresponding to W, that is, take a line corresponding to w in C
🌳 The first layer of the network (i.e. input layer):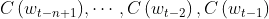 These n - 1 vectors are spliced together to form a vector x of m * (n - 1)
These n - 1 vectors are spliced together to form a vector x of m * (n - 1)
🌳 The second layer of the network (i.e. hidden layer): first, it is calculated by using a fully connected layer: d + Hx (d represents the offset, H represents the weight of the corresponding vector). After passing through the full connection layer, the tanh activation function is used for activation.
🌳 The third layer of the network (i.e. output layer): This is also a fully connected layer in essence. There are V nodes in total. Each output node yi (where ^ I is the index) represents the log probability of the next word I. finally, the output yi is normalized by using the softmax activation function.
🌳 The whole is:
y = softmax[log(U * tanh( d + Hx ) + Wx + b)]
Of which:
U is the matrix of | V | * h, which is the parameter from the hidden layer to the output layer;
W is a matrix of | V | * (n - 1) * m, which is mainly a linear transformation in which the data results of the input layer are also put into the output layer for calculation, which is called a direct edge (if a direct edge is not required, let W = 0)
2, Code implementation of NNLM
Contents of the file to be processed (1.txt)
I have a pen.I love this pen.I have an apple.I love eating apples.
You have a book.
🎈 First import the required libraries
import torch import torch.nn as nn import torch.optim as optim
🎈 Then process the data of the file and turn it into a list divided by sentences
path = "1.txt"
f = open(path, 'r', encoding= 'utf-8', errors= 'ignore')
text = []
piece = ''
for line in f:
for uchar in line:
if uchar == '\n':
continue
if uchar == '.' or uchar == '?' or uchar == '!':
text.append(piece)
piece = ''
else:
piece = piece + ucharThe text in this case is:
['I have a pen', 'I love this pen', 'I have an apple', 'I love eating apples', 'You have a book']
🎈 Put forward the words in the sentence and remove the repetition
word_list = " ".join(text).split() word_list = list(set(word_list))
🎈 Index words
word_dict = {w:i for i, w in enumerate(word_list)} #Word index
number_dict = {i:w for i, w in enumerate(word_list)} #Index - words🎈 Some parameter settings
nlen = len(word_dict) #Get dictionary length step = len(text[0].split())-1 #Step size, that is, use the first few words to predict the next word (here is to predict what the last word is) hidden = 2#Parameter amount of hidden layer (i.e. number of nodes) m = 2#Dimension of embedded word vector
🎈 Network design
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(num_embeddings = nlen, embedding_dim = m) # Thesaurus
#nn.Embedding: when a number is given, the embedding layer can return the embedding vector corresponding to the number. The embedding vector reflects the semantic relationship between the symbols represented by each number. That is, the input is a numbered list and the output is a list of corresponding symbol embedded vectors.
#index is (0,nlen-1)
self.H = nn.Parameter(torch.randn(step * m, hidden).type(torch.FloatTensor)) # Enter layer to hidden layer weights
self.d = nn.Parameter(torch.randn(hidden).type(torch.FloatTensor)) # Offset of hidden layer
#nn.Parameter: as NN Use of trainable parameters in module
#torch.randn: tensor used to generate random numbers. These random numbers meet the standard normal distribution (0 ~ 1)
self.U = nn.Parameter(torch.randn(hidden, nlen).type(torch.FloatTensor)) # Hide layer to output layer weights
self.W = nn.Parameter(torch.randn(step * m, nlen).type(torch.FloatTensor)) # Weight from input layer to output layer
self.b = nn.Parameter(torch.randn(nlen).type(torch.FloatTensor)) # Offset of output layer
def forward(self, input):
'''
input: [batchsize, n_steps]
x: [batchsize, n_steps*m]
hidden_layer: [batchsize, n_hidden]
output: [batchsize, num_words]
'''
x = self.C(input) # Get the word list of a batch word vector
x = x.view(-1, step * m)
hidden_out = torch.tanh(torch.mm(x, self.H) + self.d) # Get hidden layer output
#torch.mm(a, b) is the multiplication of matrix A and matrix B
output = torch.mm(x, self.W) + torch.mm(hidden_out, self.U) + self.b # Get output layer
return output🎈 Process the input of the network
def make_batch(text):
'''
input_batch:a set batch Middle front steps Index of words
target_batch:a set batch Index of words to be predicted in each sentence
This is to predict what the last word of the sentence is
'''
input_batch = []
target_batch = []
for piece in text:
word = piece.split()
input = [word_dict[w] for w in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(input)
target_batch.append(target)
return torch.LongTensor(input_batch), torch.LongTensor(target_batch)call
input_batch, target_batch = make_batch(text)
🎈 train
model = NNLM()
criterion = nn.CrossEntropyLoss() # Use cross entry as the loss function
optimizer = optim.Adam(model.parameters(), lr = 0.001) # Using Adam as optimizer
for epoch in range(2000):
optimizer.zero_grad()# Gradient clearing
output = model(input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print("Epoch:{}".format(epoch+1), "Loss:{:.3f}".format(loss))
# Back propagation
loss.backward()
# Update weight parameters
optimizer.step()🎈 Output setting: first obtain the predicted index, and then combine the output
#Retrieve the index of the forecast predict = model(input_batch).data.max(1, keepdim=True)[1] print([t.split()[:step] for t in text], '->', [number_dict[n.item()] for n in predict.squeeze()]) #The first part is to take out the words of the sentence to be predicted; The latter part is to extract the words corresponding to the prediction index
🎈 Output results
[['I', 'have', 'a'], ['I', 'love', 'this'], ['I', 'have', 'an'], ['I', 'love', 'eating'], ['You', 'have', 'a']] -> ['pen', 'pen', 'apple', 'apples', 'book']
Welcome to criticize and correct in the comment area. Thank you~