Business scenario
- There are a lot of article information in the website. Use elastic search to do full-text retrieval
- According to the customer's feedback, the data added in the last two days has not been found on the front desk of the website (in order to prevent the index business from affecting the normal information maintenance business, the index operation is recorded in the thread pool, executed by asynchronous threads, stored in the index error record table in case of error, and processed by scheduled tasks, so the customer can't perceive the error of the index library temporarily)
- After the development check, it is found that there are errors in index writing, adding, updating and deleting, but the query is OK
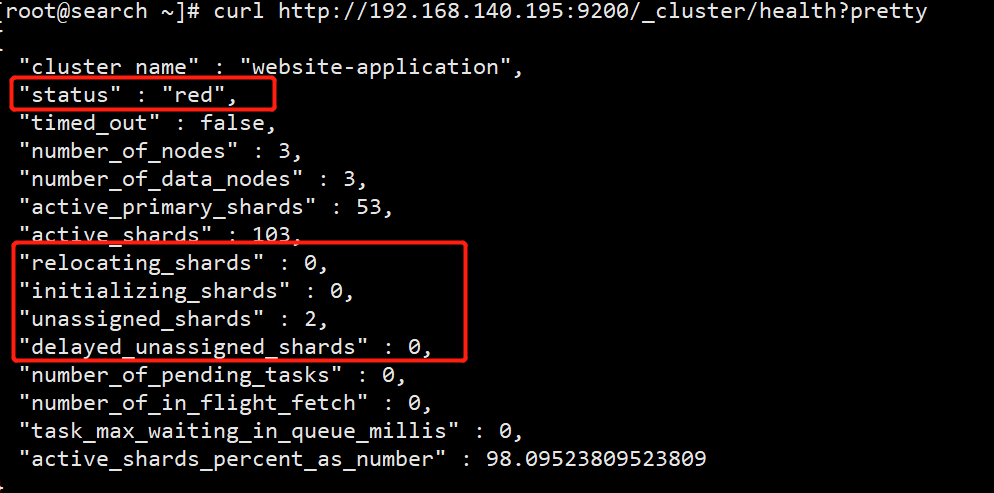
- The development informs the operation and maintenance department to restart the elasticsearch cluster service. After the restart, the index library becomes RED and cannot be restored to GREEN
- The operation and maintenance has been restarted several times. There are always two partitions that cannot be allocated, and the cluster cannot be restored to GREEN
- After checking, it is found that two fragments have been unassigned, and the successful fragments cannot be reproduced after reroute
- reroute can refer to my last elasticsearch blog: After elasticsearch restarts, the unassigned index fails to be re fragmented, and YELLO and RED resume processing
View the reason for fragmentation failure
- Since I was the first to introduce and use elasticsearch in the company, I was contacted when the O & M couldn't handle it
- For the RED status of the cluster, you need to check the specific reasons for the fragmentation failure, which index and which fragmentation
- First, check the cluster status curl http://localhost:9200/_cluster/health?pretty
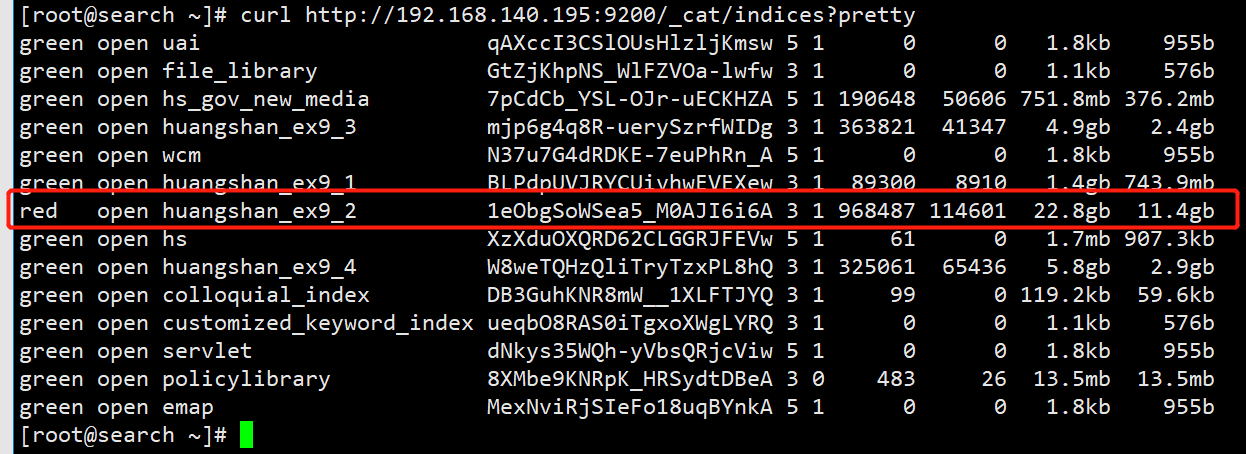
- Then check the index health status curl http://localhost:9200/_cat/indices?pretty
- Finally, check the specific reasons for fragmentation failure curl http://localhost:9200/_cluster/allocation/explain?pretty
{
"index" : "huangshan_ex9_2",
"shard" : 1,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "CLUSTER_RECOVERED",
"at" : "2022-03-03T15:00:56.648Z",
"last_allocation_status" : "no_valid_shard_copy"
},
"can_allocate" : "no_valid_shard_copy",
"allocate_explanation" : "cannot allocate because all found copies of the shard are either stale or corrupt",
"node_allocation_decisions" : [
{
"node_id" : "0KQXu9ETSW6C28XwdFiVKQ",
"node_name" : "node-2-master-40-4-9200",
"transport_address" : "192.168.140.156:9300",
"node_decision" : "no",
"store" : {
"in_sync" : false,
"allocation_id" : "jlBieBfuSyutS7xUIMd_EA",
"store_exception" : {
"type" : "file_not_found_exception",
"reason" : "no segments* file found in SimpleFSDirectory@/home/es/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index lockFactory=org.apache.lucene.store.NativeFSLockFactory@bdd7e5b: files: [write.lock]"
}
}
},
{
"node_id" : "DJ-qZio2TwGQT8xNM9tmlQ",
"node_name" : "node-1-master-40-3-9200",
"transport_address" : "192.168.140.195:9300",
"node_decision" : "no",
"store" : {
"in_sync" : true,
"allocation_id" : "cgVuWaTHTiu7clJznlVgAw",
"store_exception" : {
"type" : "corrupt_index_exception",
"reason" : "failed engine (reason: [recovery]) (resource=preexisting_corruption)",
"caused_by" : {
"type" : "i_o_exception",
"reason" : "failed engine (reason: [recovery])",
"caused_by" : {
"type" : "corrupt_index_exception",
"reason" : "checksum failed (hardware problem?) : expected=1c1tkg8 actual=g89llu (resource=name [_eg4z.cfs], length [295346024], checksum [1c1tkg8], writtenBy [6.6.0]) (resource=VerifyingIndexOutput(_eg4z.cfs))"
}
}
}
}
},
{
"node_id" : "Pdb_sRtlQ7Gnx6kQ3QQIfg",
"node_name" : "node-3-master-40-5-9200",
"transport_address" : "192.168.140.188:9300",
"node_decision" : "no",
"store" : {
"in_sync" : false,
"allocation_id" : "WhnSlN6YQU61efSeQ-DTJQ"
}
}
]
}
Start search
- It can be found that the index is Huangshan_ ex9_ Partition allocation of 2 failed. The failure reason is no_valid_shard_copy, I took it to search. I didn't find anything useful, so I had to change the keyword to continue the search. The specific reason depends on the caused below_ by
- When I saw the two error messages, it was the first time I encountered them. I had a headache. I took them and translated them. As a result, the words "stay or corrupt" and "I" appeared_ o_ exception,hardware problem?, Fragment damage, io abnormality, hardware problem?
- There is no other way, but to continue the search according to these keywords according to the reasons for the segmentation error
- An error message is no segments* file found in SimpleFSDirectory@/home/es/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index lockFactory=org.apache.lucene.store.NativeFSLockFactory@bdd7e5b: files: [write.lock], said that the file could not be found. At first, I went to the server and found that the file was there. I was very confused. I went to see the next error (shit, I read the wrong server and looked at the folder of another node. If I read it correctly, I would find that the file does not exist, and the problem may be solved)
- Take the keyword no segments* file found to search. I found a lot of codes related to Lucene, which has little to do with the failure of elasticsearch. It's of no use to me
Relevant results
- Another slice error is checksum failed (hardware problem?): expected=1c1tkg8 actual=g89llu (resource=name [_eg4z.cfs], length [295346024], checksum [1c1tkg8], writtenBy [6.6.0]) (resource=VerifyingIndexOutput(_eg4z.cfs))
- Change another keyword to checksum failed (hardware problem?) Continue search
- I searched a bunch of articles on the Internet and found two articles in the elastic search Chinese community The index shard suddenly crashes and goes offline. The shard cannot be reallocated,Elasticsearch cannot write data. checksum failed (hardware problem?) , which is very similar to my error reporting and phenomenon
- However, these two posts did not give specific solutions. Some said that the hard disk was bad and some said it was not a hard disk problem. I went to the operation and maintenance department and checked that there was no bad disk. Of course, the solution is also given. The index is deleted and rebuilt, but my index stores more than a dozen G data, and the reconstruction cost is a little high
- Continue the search and find an article in CSDN Fix corrupted index in Elasticsearch , this article is also more suitable for my error reporting. It is also more detailed and reliable. In its article, there is also a post in the official discussion area Corrupted elastic index . Now that he has given a detailed method, he plans to try it according to his plan
- Execute the find command at each node of the cluster, and sure enough, the conflict file is found at the error reporting node 195
cd /usr/local/elasticsearch/elasticsearch-5.5.2/data
find ./ -name corrupted_*
./nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index/corrupted_Beh13uEIS-KDHWd2Cw1Gtg
Try to repair
Try to resolve the conflict
- Try to recover the conflict first according to the blog
- Note: during data recovery, if there is a write, it may lead to an error. Close the index first and then operate
## To lib directory
cd /usr/local/elasticsearch/elasticsearch-5.5.2/lib
## Execute restore command
java -cp lucene-core*.jar -ea:org.apache.lucene... org.apache.lucene.index.CheckIndex /usr/local/elasticsearch/elasticsearch-5.5.2/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index -verbose -exorcise
- There is No problem between my execution results and CSDN's little brother's blog, which shows that there is no conflict at all and it is not affected by this problem
Delete conflict file
- No matter whether the recovery is successful or not, you decide to delete the conflicting files, and you may lose a small part of the data
cd /usr/local/elasticsearch/elasticsearch-5.5.2/data
find ./ -name corrupted_*
cd ./nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index/
## Change your name
mv corrupted_Beh13uEIS-KDHWd2Cw1Gtg corrupted_Beh13uEIS-KDHWd2Cw1Gtg.bak
## Or delete
rm -rf corrupted_Beh13uEIS-KDHWd2Cw1Gtg
Active redistribution
- According to the solution in the blog, I should be able to return to normal at this time, but I found it still couldn't work after I started
- Try to execute the reroute command, but it still fails. The original error is reported, but I have deleted the conflict file
curl -XPOST 'http://192.168.140.195:9200/_cluster/reroute?retry_failed=true'
Final settlement
- Since it's not a conflict problem, it's another problem. Continue to look back at the error information of the first segment
- Then go to the corresponding location on the server / home / ES / data / nodes / 0 / indices / 1eobgsowsea5_ M0aji6a / 1 / index looked at it and I wiped it. There was really no segments * file, only a write lock
- In that case, it shows that this is an empty partition. I decided to delete it. Anyway, the cluster will be re partitioned. Deleting it will not have any bad impact
- To be on the safe side, temporarily use the move command to change the folder name, and roll back in case of serious errors. Before operation, close the elasticsearch cluster
- The screenshot is as follows. Since it is after operation, you can only see 1_bak, you can see that there are only index and_ In the state folder and index, there is only write lock
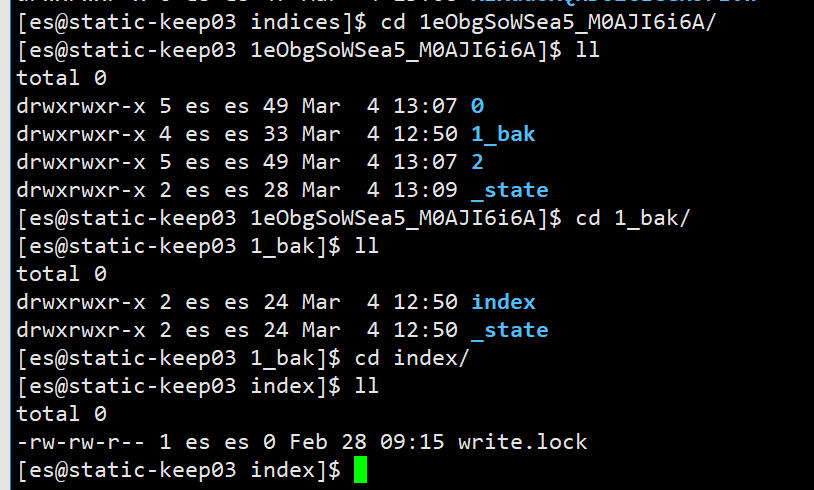
- Then, start each node of the cluster and it will be fine.
summary
- Conflicting file corrupted_* The creation time of the index was generated one morning a few days ago, and the subsequent writing of the index should have made an error. Asked about operation and maintenance and development, but they didn't do any special operations. The specific reason for the error is still unknown
- corrupted appears later_* You can try to restore and delete according to the above method to solve the problem
- For the index folder without segments * file, the creation time is the time of restarting the cluster. It may be that after restarting, the new partition failed due to the last error, resulting in the locking of the new partition. Segments * cannot be generated, and only write Lock folder
- In case of similar error reporting, delete the error reporting fragment without data