1.Zookeeper learning notes
1.1 overview
Zookeeper is an open source distributed Apache project that provides coordination services for distributed frameworks.
Zookeeper's working mechanism:
From the perspective of design pattern: it is a distributed service management framework designed based on observer pattern. It is responsible for storing and managing the data everyone cares about, and then receiving the registration of observers. Once the state of these data changes, Zookeeper will be responsible for notifying which observers have registered on Zookeeper to respond accordingly.
1.2. Features
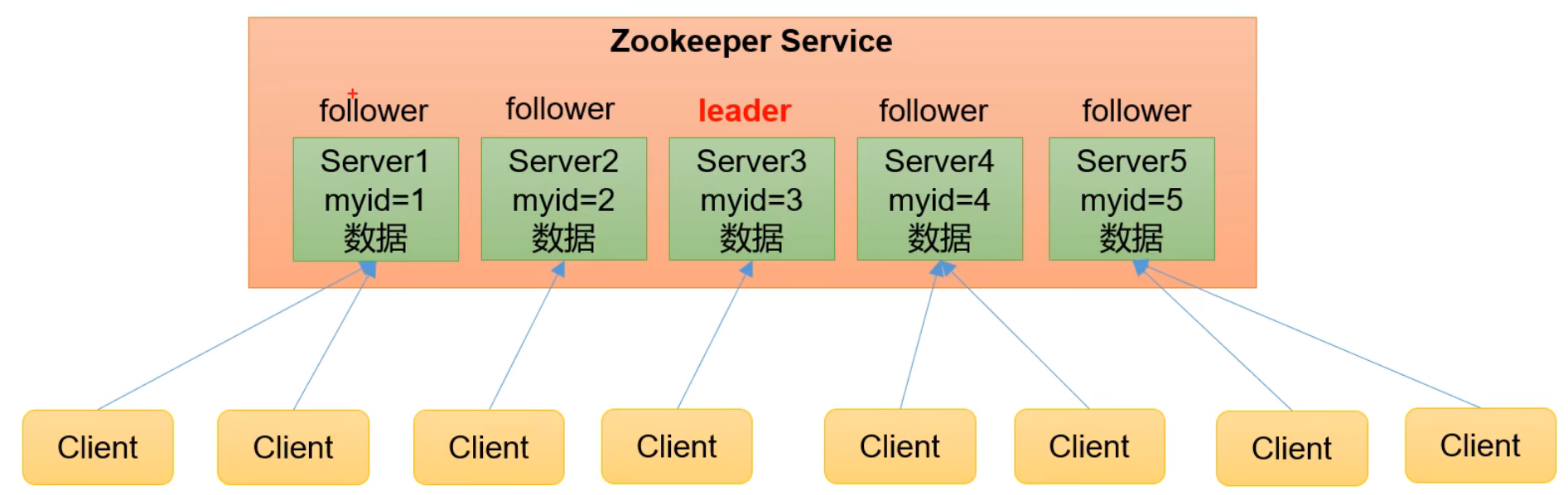
1) A cluster composed of one Leader and multiple followers.
2) . as long as more than half of the nodes in the cluster survive, the Zookeeper cluster can serve normally, so Zookeeper is suitable for installing an odd number of servers.
3) Global data consistency: each Server saves a copy of the same data. No matter which Server the Client connects to, the data is consistent.
4) . update request execution in sequence: update requests from the same Cilent are executed in sequence according to their sending order.
5) . atomicity of data update: data update in turn will either succeed or fail.
6) Real time: Cilent can read the latest data within a certain time range.
1.3 data structure
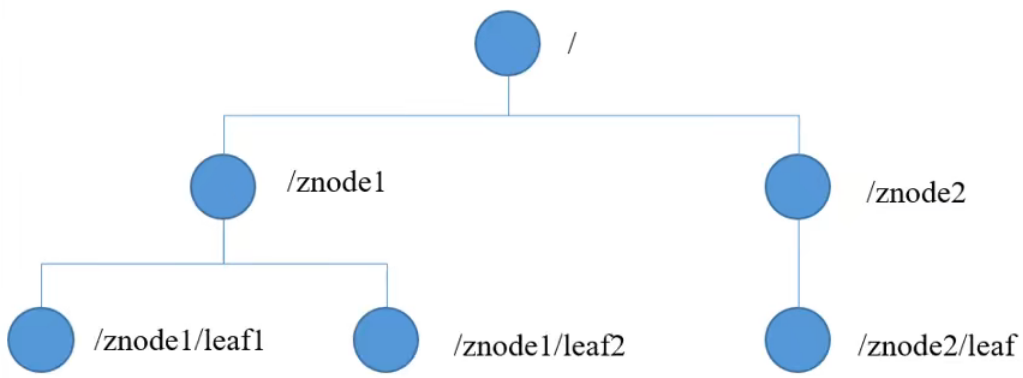
The structure of Zookeeper data model is very similar to that of Unix file system. The whole can be regarded as a tree. Each node is called a ZNode. By default, each ZNode can store 1MB of data, and each ZNode can be uniquely identified through its path.
1.4 application scenario
The services provided include: unified naming service (such as the relationship between domain name and IP), unified configuration management (the configuration information of all nodes is consistent), unified cluster management, dynamic uplink and downlink of server nodes, soft load balancing, etc.
1.5 download address
https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
1.6 local mode installation and configuration
1.6.1 Download
Upload the downloaded compressed package to the specified path of Linux

1.6.2. Unzip the file
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
1.6.3. Modify the unzipped folder name
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7

1.6.4. Modify configuration
1.6.4.1. First enter the conf directory
cd conf
1.6.4.2. Modify Zoo_ sample. The name of CFG is zoo cfg
mv sample.cfg zoo.cfg
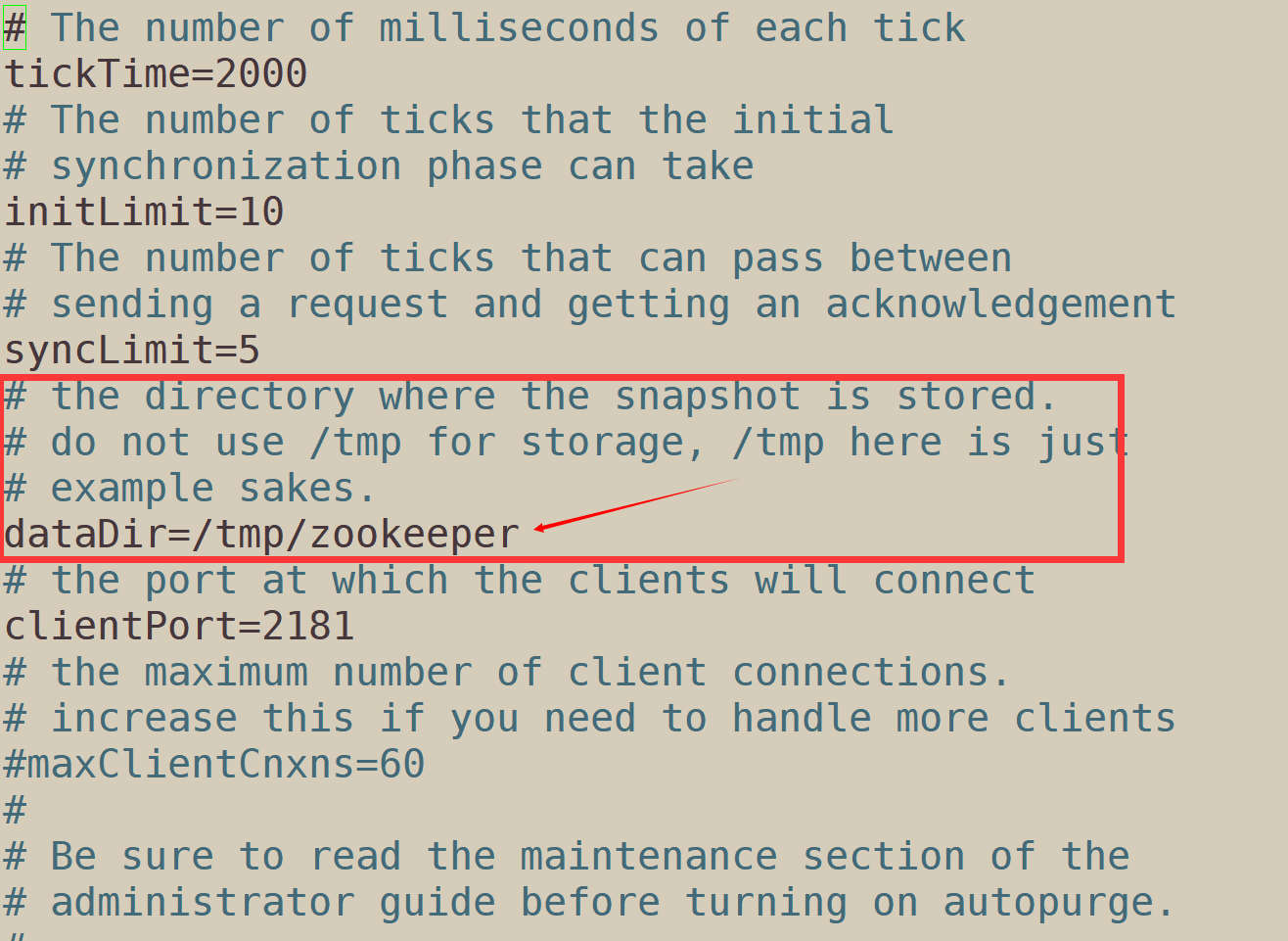
1.6.4.3 use vim to edit this file and modify the data storage path of zookeeper
vim zoo.cfg
The default storage path of data is / tmp/zookeeper, / tmp is the temporary file storage path of linux. The file data in the tmp directory will be automatically cleared after a month, so the purpose of changing the path is to prevent zk data from being automatically cleared by the system.
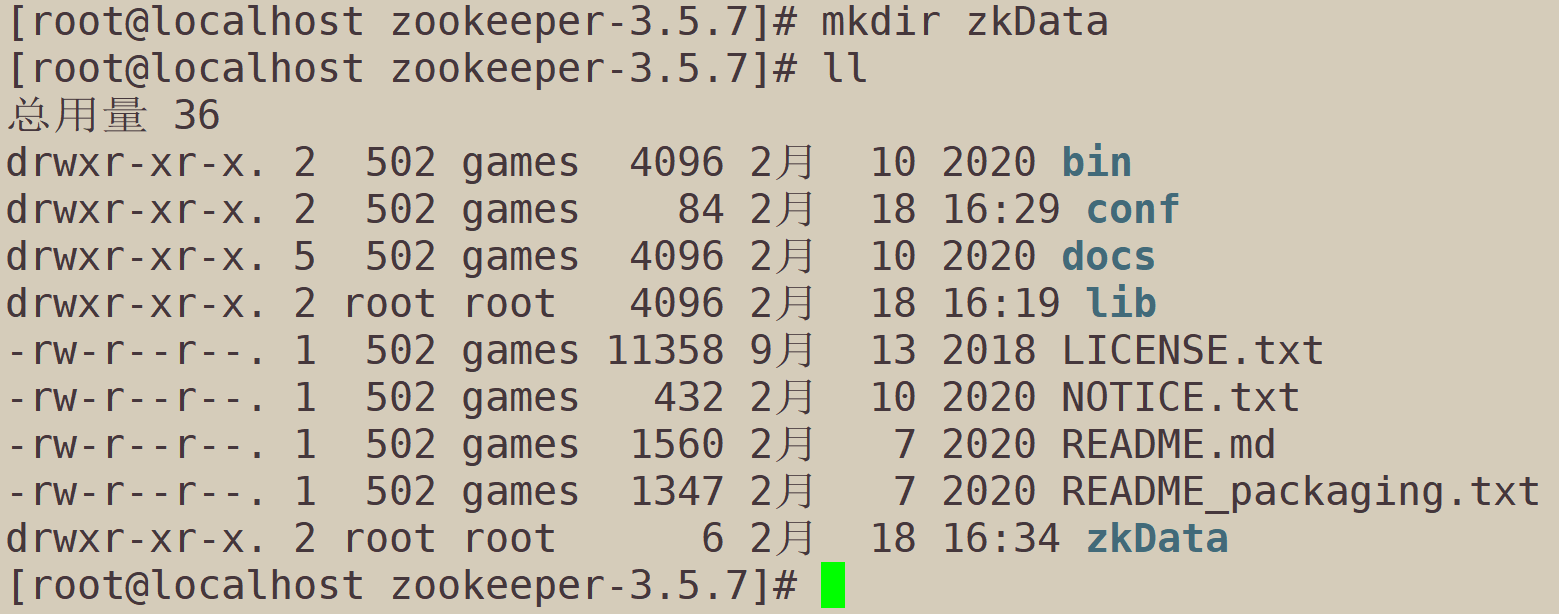
The data stored in the newly created directory of zoee6.4.zoeeper
mkdir zkData
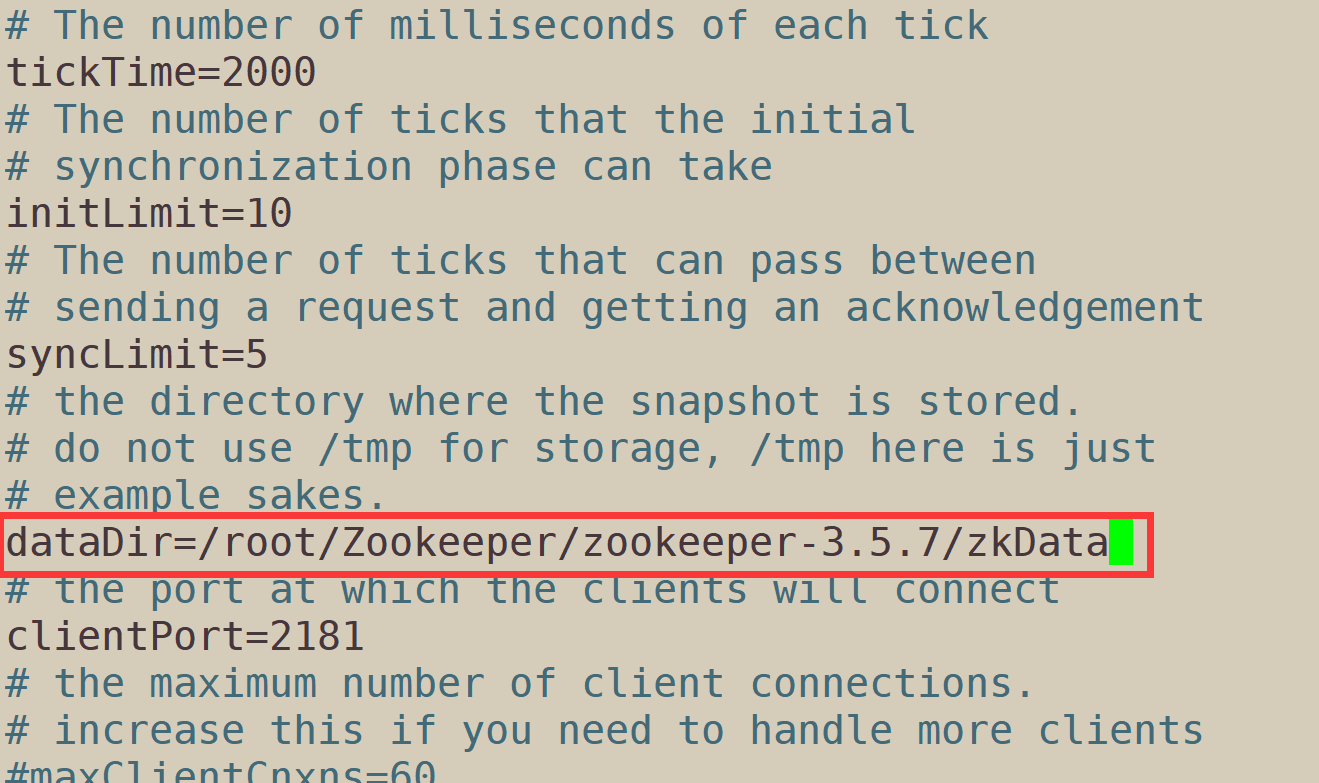
1.6.4.5. Go back to the configuration file and modify the storage path
1.6.5 description of configuration parameters
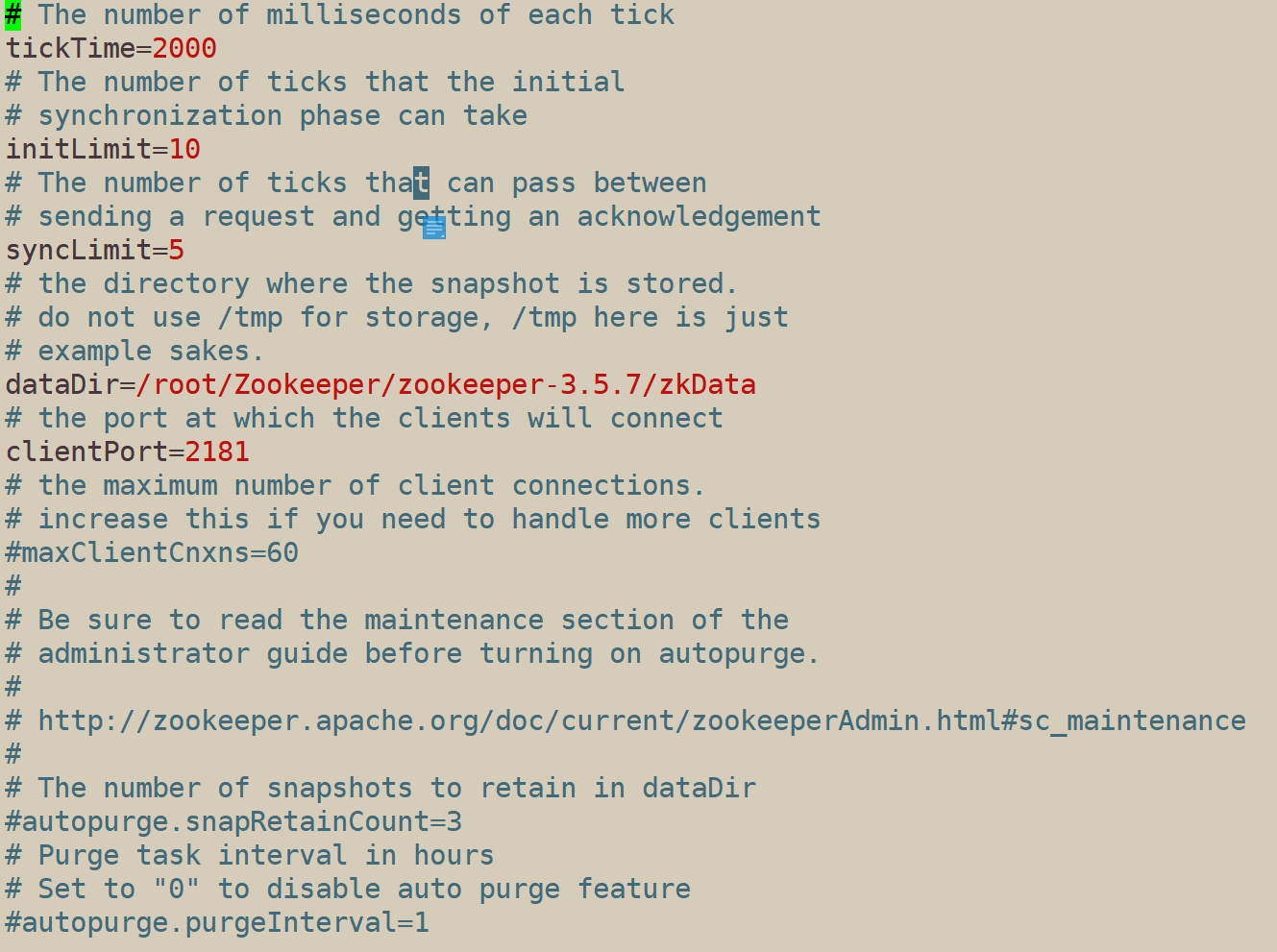
tickTime=2000: Communication heartbeat time Zookeeper server and client heartbeat time, in milliseconds
initLimit=10: LF (short for leader follower) initial communication time limit (i.e. no connection is established after 10 heartbeat times, i.e. 20 seconds, i.e. this communication fails)
syncLimit=5: LF synchronous communication time limit (the heartbeat time of service communication with established connection cannot exceed 5 heartbeat times, i.e. 10 seconds. If it exceeds, it indicates that the communication is abnormal)
dataDir: the path to save Zookeeper data. Generally, the default is tmp directory, but it is easy to be deleted regularly by linux, so it is necessary to create a new storage directory
clientPort = 2181: client port number, which is generally not modified
1.7 local startup
To start zookeeper, you need to start the server first and then the client.
**Note: * * after Zookeeper is deployed, the version after 3.5 will automatically occupy port 8080 The project integrating Zookeeper needs to modify the configuration file and change the server port. Otherwise, zk server will not start.
1.7.1. Server startup:
**Note: * * when the server starts, it needs to add start to start the zookeeper service
Add status to query the zookeeper status
Add stop to stop the zookeeper service

Use the jps command to check whether the startup is successful. After that, the zk process will appear

1.7.2 client startup:
**Note: * * start is not required for client startup

After the client is started successfully, it will connect to the server. Enter ls / to view the current zookeeper node

Use quit to exit the interface.
1.8 cluster installation and configuration
Having the foundation of Hadoop will be much more convenient. I built it in an ordinary way without learning
1.8.1 cluster planning
Three linux systems are deployed with zookeeper server.
1.8.2. Configure server number
Create a zkData folder in the zookeeper directory of each host
Create a myid file in the zkData directory of each host
Edit the file in each host and give a number value in the file. For example, host 1 gives 1, host 2 gives 2, and so on.
**Note: * * the given number cannot have spaces up, down, left and right.
1.8.3. Configure zoo Cfg file
Zoo. In each host Add to cfg file
################Cluster###########
server.1=192.168.1.19:2888:3888
server.2=192.168.1.32:2888:3888
server.3=192.168.1.33:2888:3888
Note: the format is server [number in myid file] = [host IP]: [port where Leader and Follower exchange data]: [communication port when Leader is re elected]
zk according to the number of server s configured in this part, judge the number of services in the cluster and assist in the election of leaders.
1.8.4 run zookeeper service of each host
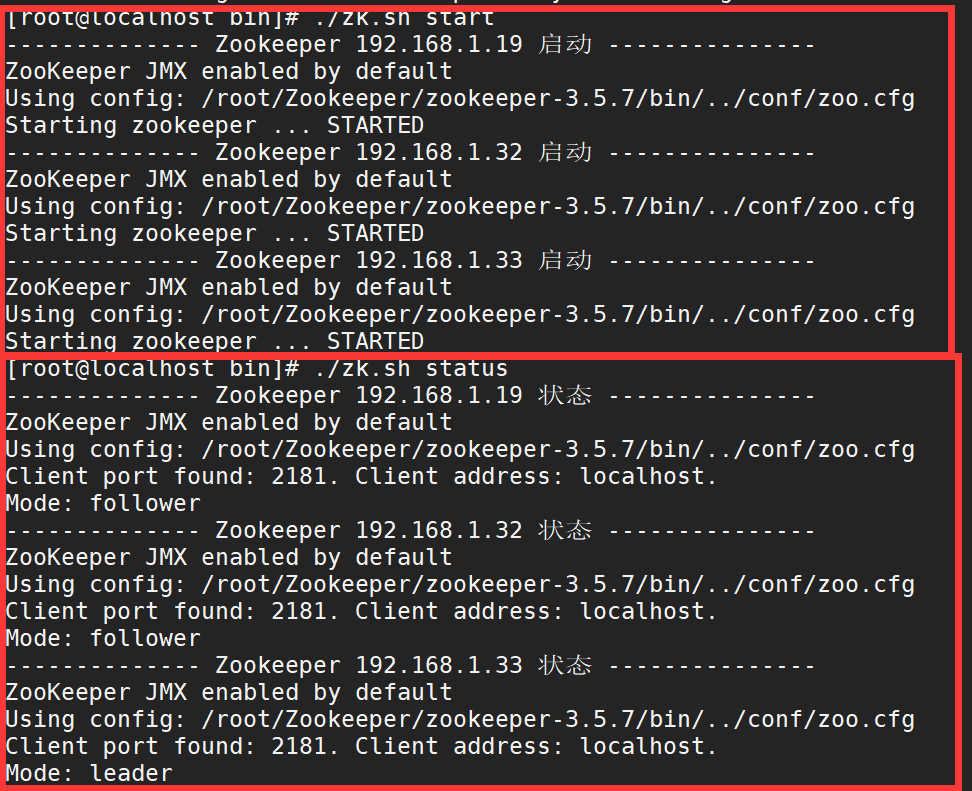
bin/zkServer.sh start run Zookeeper

Query startup and cluster status:
bin/zkServer.sh status view running status

If this happens, it means that the first zk service is started. One of the features of zk is that more than half of the services in zk cluster are unavailable, which will lead to the unavailability of the whole cluster.
Therefore, continue to start the zk services of other hosts.
After startup, check the zk status of each host as follows:
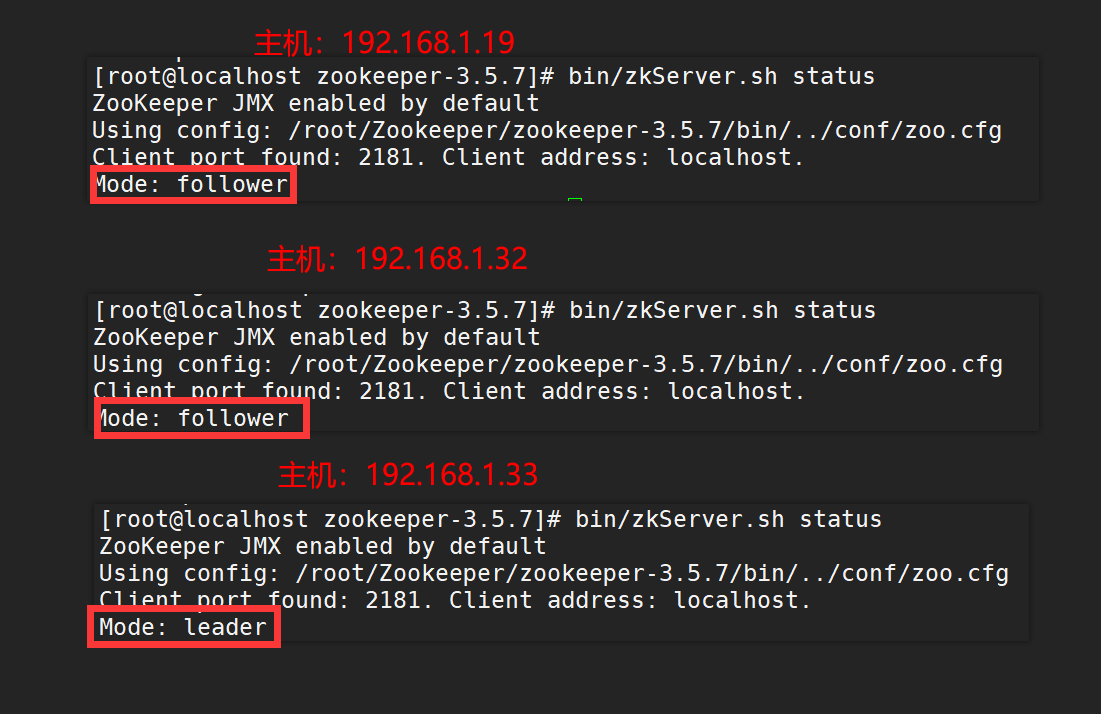
**Note: * * you'd better turn off the firewall before that.
This indicates that zk cluster has run successfully. After starting two machines, a leader has been elected, and the zk service to be started again can only be follower.
1.9 cluster concept and use
1.9.1 several concepts in Cluster:
**SID: * * server ID, which is used to uniquely identify the machines in a ZK cluster. Each machine cannot be repeated, and is consistent with myid.
**ZXID: * * transaction ID. ZXID is a transaction ID used to identify a change in server status. At a certain time, the ZXID value of each machine in the cluster may not be exactly the same, which is related to the processing logic of ZK server for client "update request".
**Epoch: * * code of each leader's tenure. When there is no leader, the logical clock value in the same voting process is the same. After each vote, the data will be increased.
1.9.2 when there are five zk servers, the zk election mechanism is started for the first time:
**1) * * server 1 starts and initiates an election. Server 1 votes for itself. At this time, server 1 has one vote, which is less than half (3 votes). The election cannot be completed, and server 1 remains in the state of LOOKING;
**2) * * server 2 starts up and initiates another election. Server 1 and server 2 have their own vote and exchange vote information. At this time, server 1 finds that the myid of server 2 is larger than that of server 1, and changes the vote to recommend server 2. At this time, server 1 has 0 votes and server 2 has 2 votes. Without more than half of the results, the election cannot be completed, Server 1 and server 2 remain in the state of LOOKING
**3) , * * server 3 starts and initiates an election. At this time, server 1 and server 2 will change the vote to server 3. At this time, the voting results: server 1 has 0 votes, server 2 has 0 votes, and server 3 has 3 votes. At this time, more than half of the votes of server 3 have been elected as Leader, server 1 and 2 change the status to FOLLOWING, and server 3 change the status to LEADING.
**4) * * server 4 starts and initiates an election. At this time, servers 1, 2 and 3 are no longer in the voting state and will not change the vote information. Result of exchange of ballot information: server 3 has 3 votes and server 4 has 1 vote. At this time, server 4 obeys the majority, changes the vote information to server 3, and changes the status to FOLLOWING;
**5) , * * like server 4, once a Leader is elected in the cluster, the following ones will become followers
1.9.3 when there are five zk servers, the zk election mechanism is not started for the first time
1) . when one of the following two situations occurs to a server in ZK cluster, it will start to enter the Leader election
- Server initialization start
- Unable to maintain connection with the Leader while the server is running
2) . when a machine enters the Leader election process, the current cluster may also be in two situations:
-
A Leader already exists in the cluster
When the machine tries to elect a Leader when there is already a Leader, it will be informed of the Leader information of the current server. For the machine, it only needs to establish a connection with the Leader machine and synchronize the status.
-
The Leader does not exist in the cluster
ZK service that can work can elect leaders according to the rules: ① elect the big one; ② If the eoch is the same, the election transaction id is larger (ZXID); ③ If the transaction id is the same, select the one with the larger server id (SID)
For example, suppose Zookeeper has 5 servers, SID is 1, 2, 3, 4, 5, ZXID is 8, 8, 8, 7, 7, and the server with SID is Leader. At this time, 3 and 5 fail. When Leader is selected according to the election rules, No. 1 (1, 8, 1), No. 2 (1, 8, 2) and No. 4 (1, 7, 4) are selected as Leader, and server 2 is finally elected as Leader.
1.9.4 ZK cluster start stop script
When there are many zk servers, such as 100, it is very boring to start and stop one by one, so the script of one click start and stop is very necessary.
1.9.4.1 script without password free login:
Before using, you need to install sshpass
On Linux system, use yum install sshpass to install
#!/bin/bash
case $1 in
"start"){
for i in 192.168.1.19 192.168.1.32 192.168.1.33
do
echo -------------- Zookeeper $i start-up ---------------
sshpass -p password ssh -o StrictHostKeyChecking=no $i "/root/Zookeeper/zookeeper-3.5.7/bin/zkServer.sh start"
done
}
;;
"stop"){
for i in 192.168.1.19 192.168.1.32 192.168.1.33
do
echo -------------- Zookeeper $i stop it ---------------
sshpass -p password ssh -o StrictHostKeyChecking=no $i "/root/Zookeeper/zookeeper-3.5.7/bin/zkServer.sh stop"
done
}
;;
"status"){
for i in 192.168.1.19 192.168.1.32 192.168.1.33
do
echo -------------- Zookeeper $i state ---------------
sshpass -p password ssh -o StrictHostKeyChecking=no $i "/root/Zookeeper/zookeeper-3.5.7/bin/zkServer.sh status"
done
}
;;
esac
1.9.4.2 script of password free login is set:
#!/bin/bash
case $1 in
"start"){
for i in 192.168.1.19 192.168.1.32 192.168.1.33
do
echo ----------------Zookeeper $i start-up ---------------------
ssh $i "/root/Zookeeper/zookeeper-3.5.7/bin/zkServer.sh start"
done
}
;;
"stop"){
for i in 192.168.1.19 192.168.1.32 192.168.1.33
do
echo ----------------Zookeeper $i stop it ---------------------
ssh $i "/root/Zookeeper/zookeeper-3.5.7/bin/zkServer.sh stop"
done
}
;;
"status"){
for i in 192.168.1.19 192.168.1.32 192.168.1.33
do
echo ----------------Zookeeper $i state ---------------------
ssh $i "/root/Zookeeper/zookeeper-3.5.7/bin/zkServer.sh status"
done
}
;;
esac
be careful:
1) . name the above script ZK SH is placed in the / home/zk/bin directory
2) Use Chmod 777 ZK SH modify the script permissions
3) . use jpsall to view multiple hadoop processes
4) , use zk The SH start command can start zk services of multiple hosts
5) , use zk The SH stop command stops zk services of multiple hosts
6) , use zk The SH status command allows you to view the status of zk services on multiple hosts, including role types
1.9.4.3 possible problems in the above script * *:**
1),JAVA_HOME setup problem
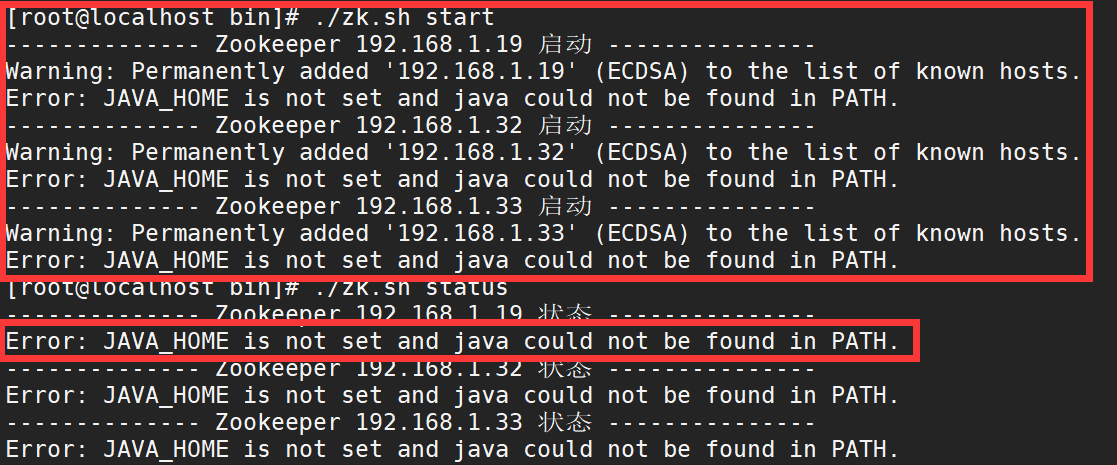
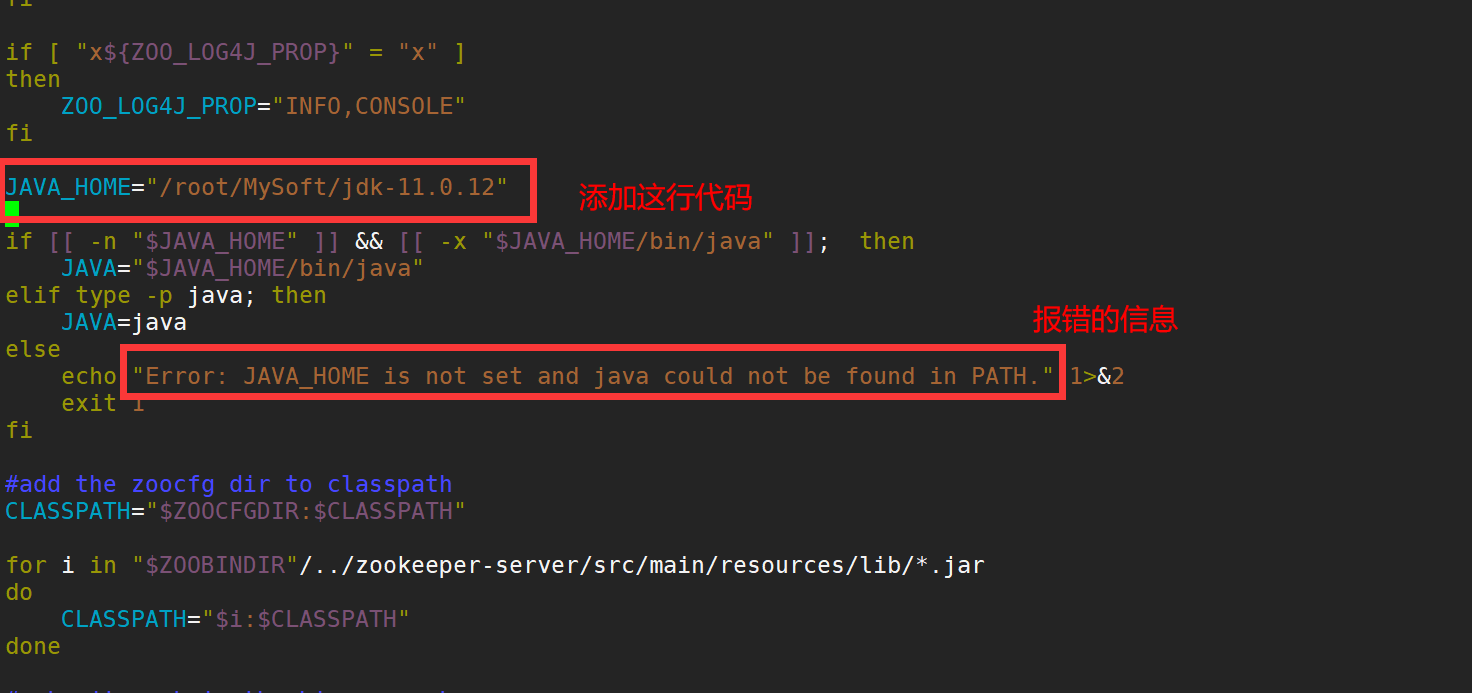
terms of settlement:
- 1. Use s witch java to obtain the Java installation path

- 2. Edit zkenv. In zk's bin directory SH, add JAVA_HOME variable value:
2) . an error is reported when one is not started successfully
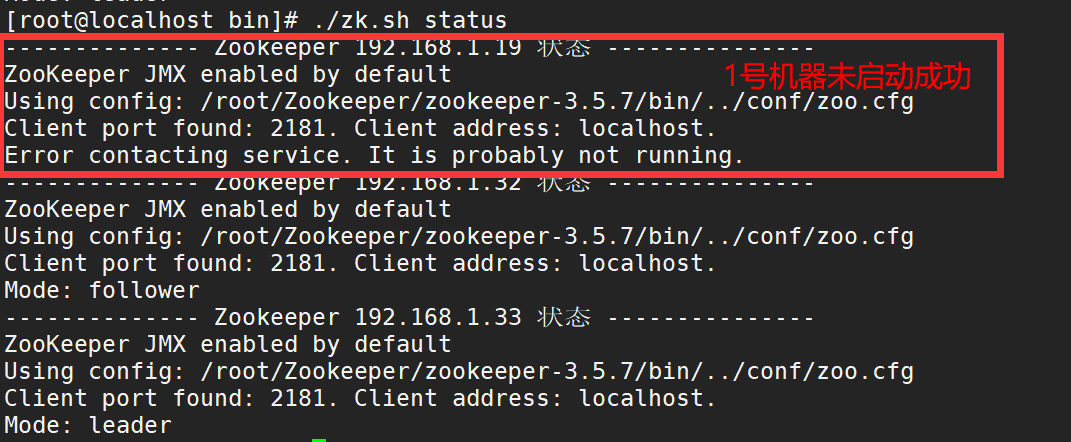
The reason is that the machine that failed to start did not turn off the firewall. If you turn off the firewall, you can restart successfully.
1.9.4.4 after successful startup
1.10. Client command line learning
1.10.1. Connect to the designated zk server
When using the client to connect to zk server, localhost is shown above
./bin/zkCli. After executing the SH command, the following screenshot is obtained

If you need to display the ip address of zk server, you can use
./bin/zkCli.sh -server [ip address]: [port number 2181] use this command to connect to the specified ZK server
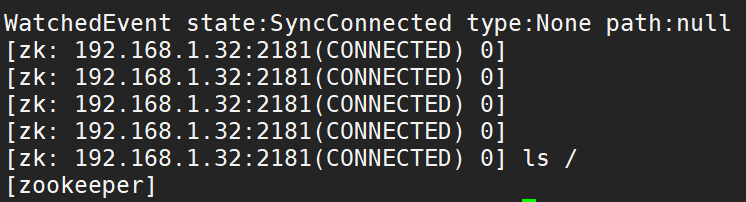
1.10.1. ls command
ls -s [path] command to view the information of the specified path
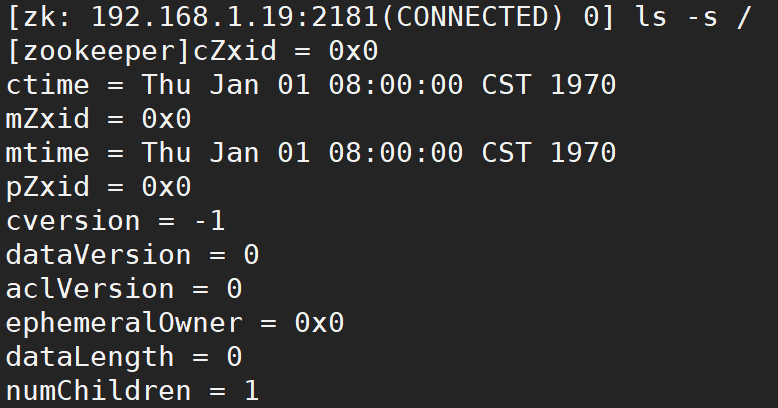
Information item description:
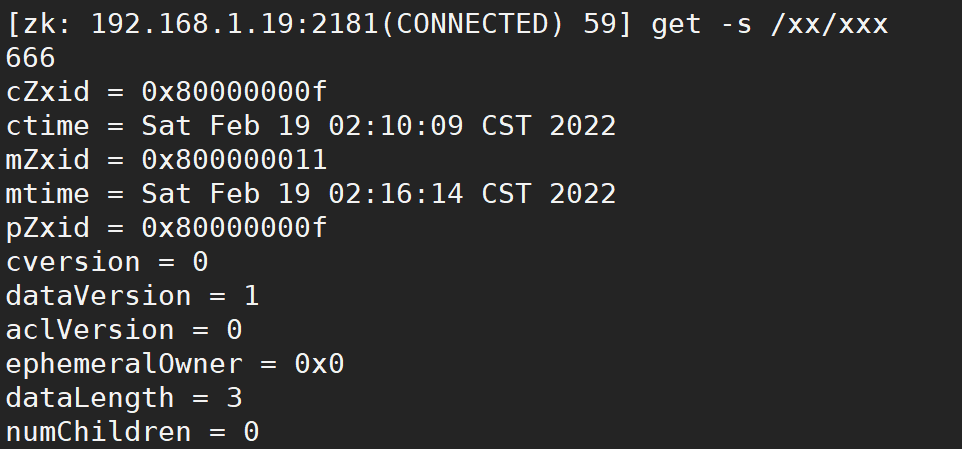
**cZxid: * * create the transaction zxid of the node. Each time the ZK state is modified, a ZK transaction id will be generated. The transaction id is the total order of all modifications in ZK. Each modification will have a unique zxid. If zxid1 is less than zxid2,
**ctime: * * the number of milliseconds that znode was created, counting from 1970
**mZxid: * * znode last updated transaction zxid
**mtime: * * the last modified milliseconds of znode, calculated from 1970
**pZxid: * * znode last updated child node zxid
**cversion: * * child node change number, znode child node modification times
**dataVersion: * * znode data change number
**aclVersion: * * znode change number of access control list
**Ephemeral0owner: * * if it is a temporary node, this is the session id of the znode owner. If it is not a temporary node, the value is 0
**dataLenth: * * data length of znode
**numChildren: * * number of znode child nodes
Carry parameters -w:
It is used to create a listener and listen to the changes of the specified node
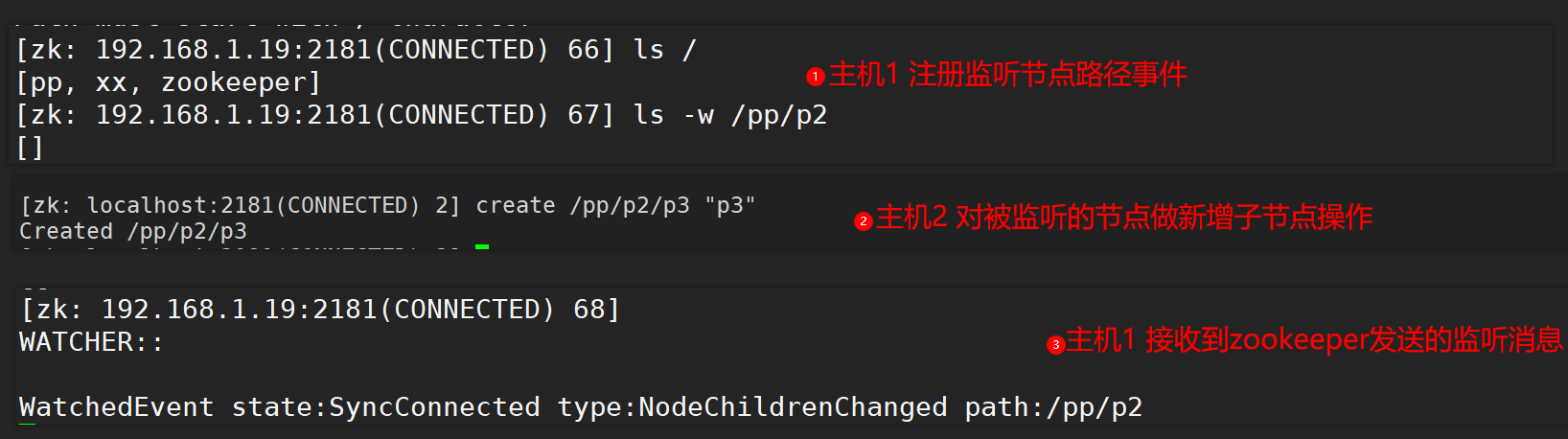
Note: the monitoring notification will only be sent once, that is, when the child node of the monitoring node is changed again, the notification will not be received. If you want to receive the notification again, you must register the monitoring event again.
1.10.2. get command
Used to get the value of the node under the specified path
get [node path]
For example:

get parameters:
Carry - s parameter:
Carry -w parameters:
Used to create a listener and specify the change of the value of the listening node
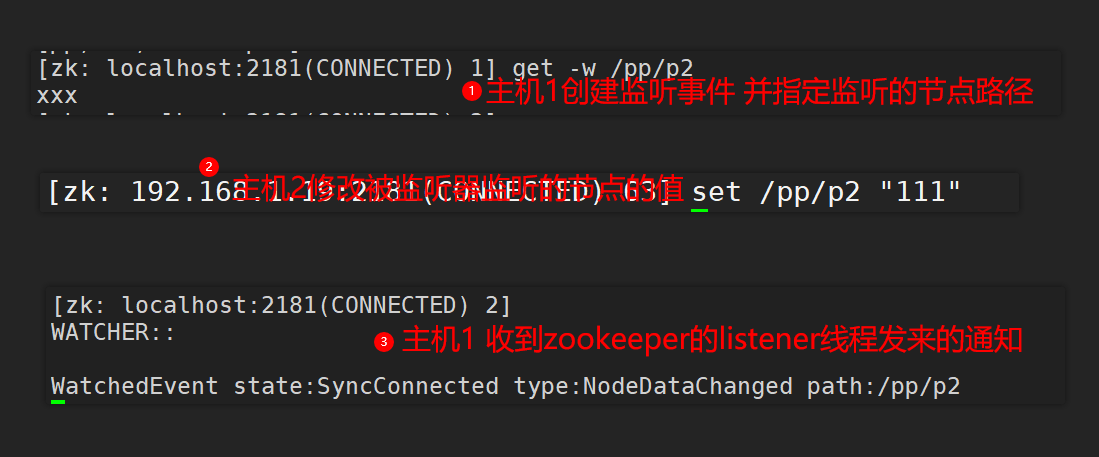
Note: the monitoring notification will only be sent once, that is, when the value of / pp/p2 is modified again, the notification will not be received. If you want to receive the notification again, you must register the monitoring event again.
1.10.3. delete command
Deletes the node of the specified node path
delete [node path]
For example:

**Note: * * if there are nodes under a node, you can use the deleteall command to delete recursively
1.10.4 set command
Used to modify the value of the node in the specified node path
set [node path] [new node value]
For example:
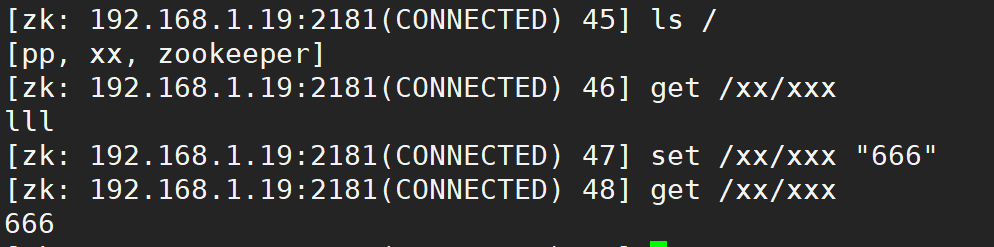
1.10.5. create command
Used to create nodes
create [node path] [node data]
For example:
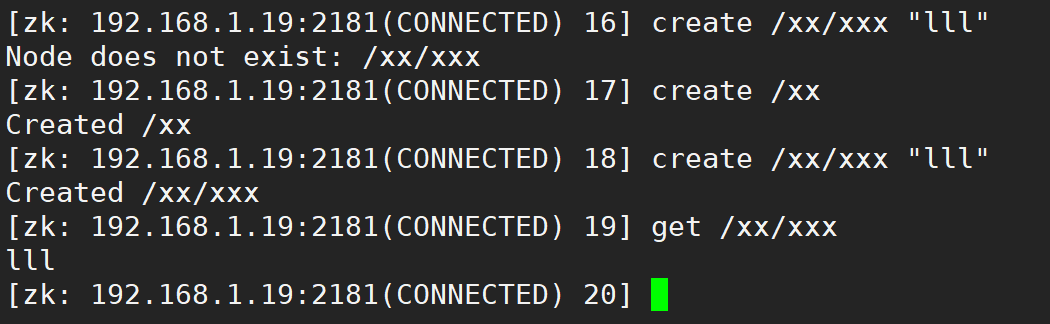
be careful:
If no parameters are carried during creation, the generated node is a persistent node
If the parameter - s is carried during creation, the generated node is a persistent node with sequence number, and the node with sequence number will not be repeated
If the parameter - e is carried during creation, the generated node is a temporary node. After disconnection, the data will be deleted.
If the parameter - e -s is carried during creation, the generated node is a temporary node with serial number. The node with serial number will not be repeated, but it will still be deleted after disconnection.
1.10.6. quit command
Exit client
1.10.7 node type
Node types include: persistent and temporary
Persistent: after the client and server are disconnected, the created node is not deleted.
-
**Persistent directory node: * * the node still exists after the client is disconnected from zk.
-
**Persistent sequence number directory node: * * after the client is disconnected from zk, the node still exists, but zk gives the sequence number to the node name.
Temporary: after the client and server are disconnected, the created node will be deleted by itself.
-
**Temporary directory node: * * this node is deleted after the client is disconnected from zk.
-
Temporary sequence number directory node: after the client is disconnected from zk, the node is deleted, but zk gives the sequence number to the node name.
**Note: * * when creating a znode, set the sequence ID, and a value will be appended to the name of the znode. In the case of sequence number, a word increment counter is maintained by the parent node.
**Note: * * in a distributed system, the sequence number can be used to globally sort all times, so that the client can infer the sequence of events through the sequence number.
1.10.8 listener
**Function of listener: * * it is used to ensure that zk can quickly respond to any change of any data to the application listening to the node.
Listener principle:
1) First, there must be a main thread
2) . in the main thread, create a zookeeper client. At this time, two threads will be created, one for network communication and the other for listener
3) . send the registered listening event to zookeeper through the connect thread to tell zookeeper which node or nodes the client needs to listen for
4) . in the list of registered listeners in zookeeper, add the registered listening events to the list
5) . zookeeper will send this message to the listener thread if it listens to the change of node data or path
6) The process() method is called inside the listener thread to inform the client of the message
For specific operations, please refer to the case under 2.11 client API.
1.11 client API
Case 1: use the client to operate the Zookeeper cluster, create nodes and write data
Maven builder, POM file is as follows
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.aliang</groupId>
<artifactId>ZookeeperDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
<dependencies>
<!-- Zookeeper Dependent package-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
<!--Junit Dependent package-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
</dependencies>
</project>
The Java operation code is as follows:
package com.aliang.zk;
import org.apache.zookeeper.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class ZKClient {
String ip = "192.168.1.19:2181,192.168.1.32:2181,192.168.1.33:2181";
int ms = 20000; // Note: the default is 15 seconds. If the error message of no connection is reported, please increase the value
ZooKeeper zk ;
@Before
public void init() throws IOException, InterruptedException {
zk = new ZooKeeper(ip, ms, null);
}
@Test
public void createNode() throws InterruptedException, KeeperException {
/**
* create Method: parameter 1: node path, parameter 2: node value, parameter 3: node permission, parameter 4: node type
* Parameter 3: from zoodefs Ids. Specify a permission in this class. Commonly used are:
* *OPEN_ACL_UNSAFE-->Indicates that this is a fully open ACL
* *CREATOR_ALL_ACL-->Indicates that this ACL grants all permissions to the creator identity
* *READ_ACL_UNSAFE-->Indicates that this ACL gives anyone read-only permission
* AUTH_IDS-->Indicates that this ID can only be used to set ACL. It will be replaced by the ID verified by the client.
* ANYONE_ID_UNSAFE-->Indicates that this ID represents anyone.
* Parameter 4: specify a node type from the CreateMode class. Commonly used are:
* *PERSISTENT-->Node persistence type
* *PERSISTENT_SEQUENTIAL-->Persistent node type with sequence number
* *EPHEMERAL-->Temporary node type
* *EPHEMERAL_SEQUENTIAL-->Temporary node type with sequence number
*/
String s = zk.create("/JavaTestCreate2", "testString2".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(s); //Output / JavaTestCreate
}
}
Test results:
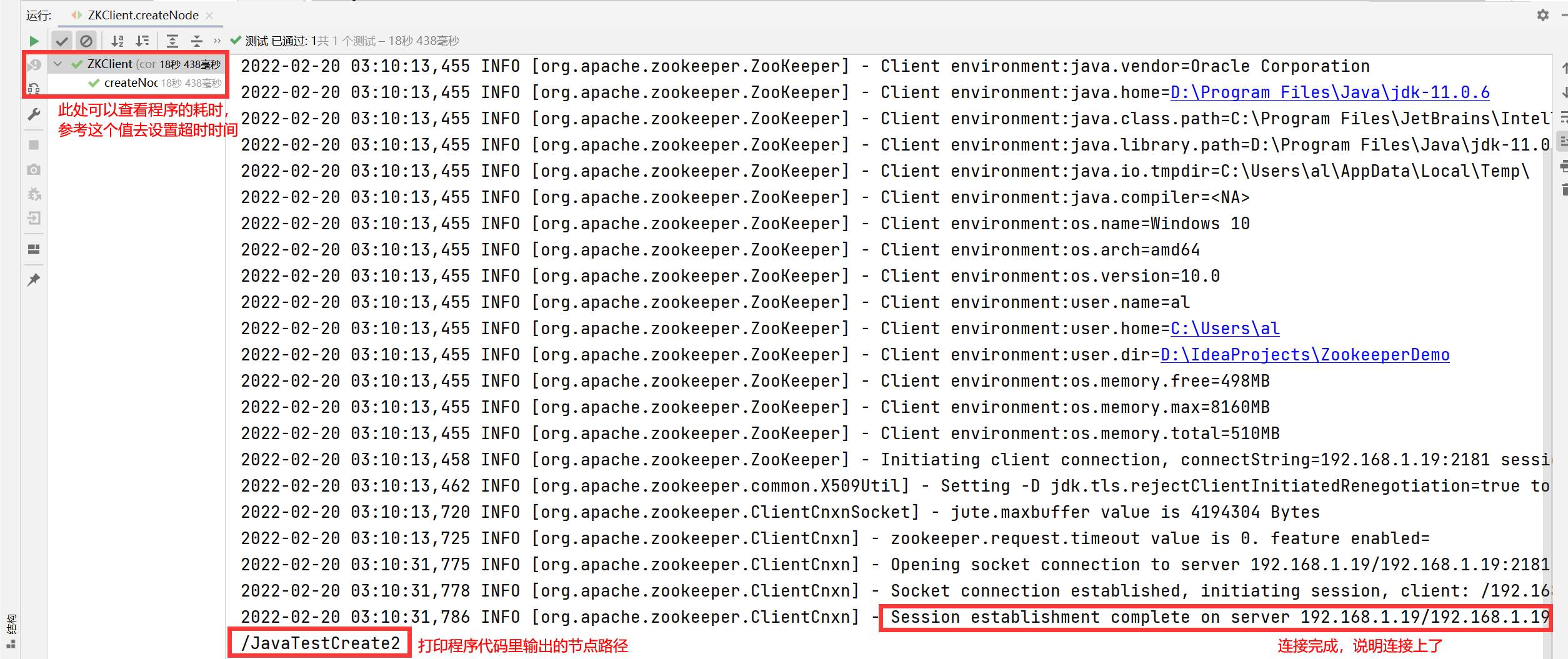
Check in Zookeeper to see if the new is successful:

Case 2: obtaining child nodes
The POM document still adopts case 1, which will not be repeated here.
The java code is as follows:
package com.aliang.zk;
import org.apache.zookeeper.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
public class ZKClient {
String ip = "192.168.1.19:2181,192.168.1.32:2181,192.168.1.33:2181";
int ms = 20000;
ZooKeeper zk ;
@Before
public void init() throws IOException, InterruptedException {
zk = new ZooKeeper(ip, ms, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
/**
* Gets the data of the specified node
*/
@Test
public void getChild() throws InterruptedException, KeeperException {
/**
* getChildren Method parameters,
* Parameter 1: node path to be obtained,
* Parameter 2: it can be a Boolean value or a new Watcher() object,
* When Boolean values are used, the Watcher object specified during initialization will be automatically used,
* Or create a Watcher in this location
*/
List<String> children = zk.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
}
}
Test results:
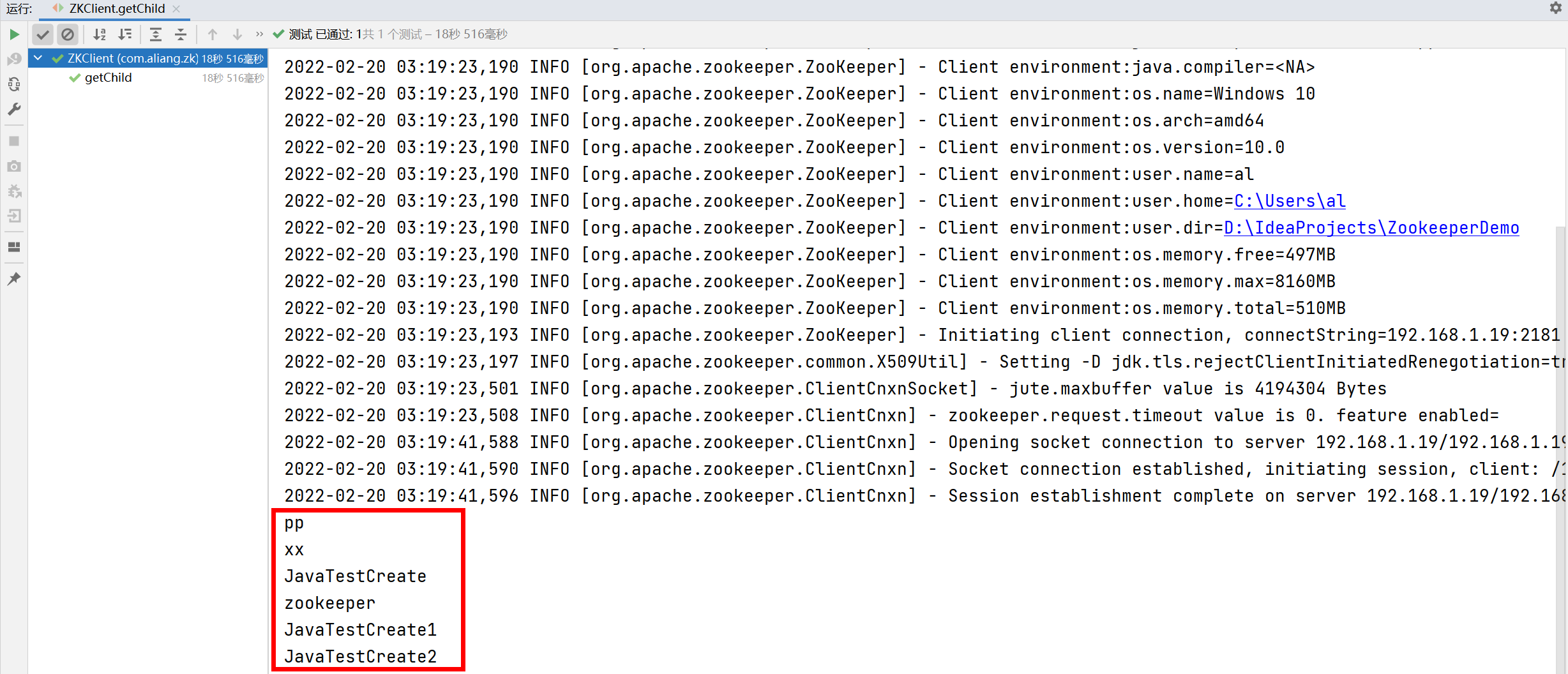
Case 3: monitor the changes of the specified node
Use of listener Watcher
The POM document still adopts case 1, which will not be repeated here.
The Java code is as follows:
package com.aliang.zk;
import org.apache.zookeeper.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
public class ZKClient {
String ip = "192.168.1.19:2181,192.168.1.32:2181,192.168.1.33:2181";
int ms = 200000;
ZooKeeper zk ;
@Before
public void init() throws IOException, InterruptedException {
zk = new ZooKeeper(ip, ms, new Watcher() {
/**
*Write listening events that need to be registered
*/
@Override
public void process(WatchedEvent event) {
/**
* The rewritten process method is used to register listening events. It listens for the changes of the "/" node. This method will be executed every time the monitored node changes,
* The premise is thread. In getChild() sleep(Integer.MAX_VALUE); It's long enough. The program isn't over yet.
*/
List<String> children = null;
try {
children = zk.getChildren("/", true);
System.out.println("#####################");
for (String child : children) {
System.out.println(child);
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* Gets the data of the specified node
*/
@Test
public void getChild() throws InterruptedException, KeeperException {
List<String> children = zk.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
// It is used to sleep the current thread. Otherwise, when the listening node changes, the program has ended, and the notification message sent by zookeeper cannot be obtained
Thread.sleep(Integer.MAX_VALUE);
}
}
Test results:
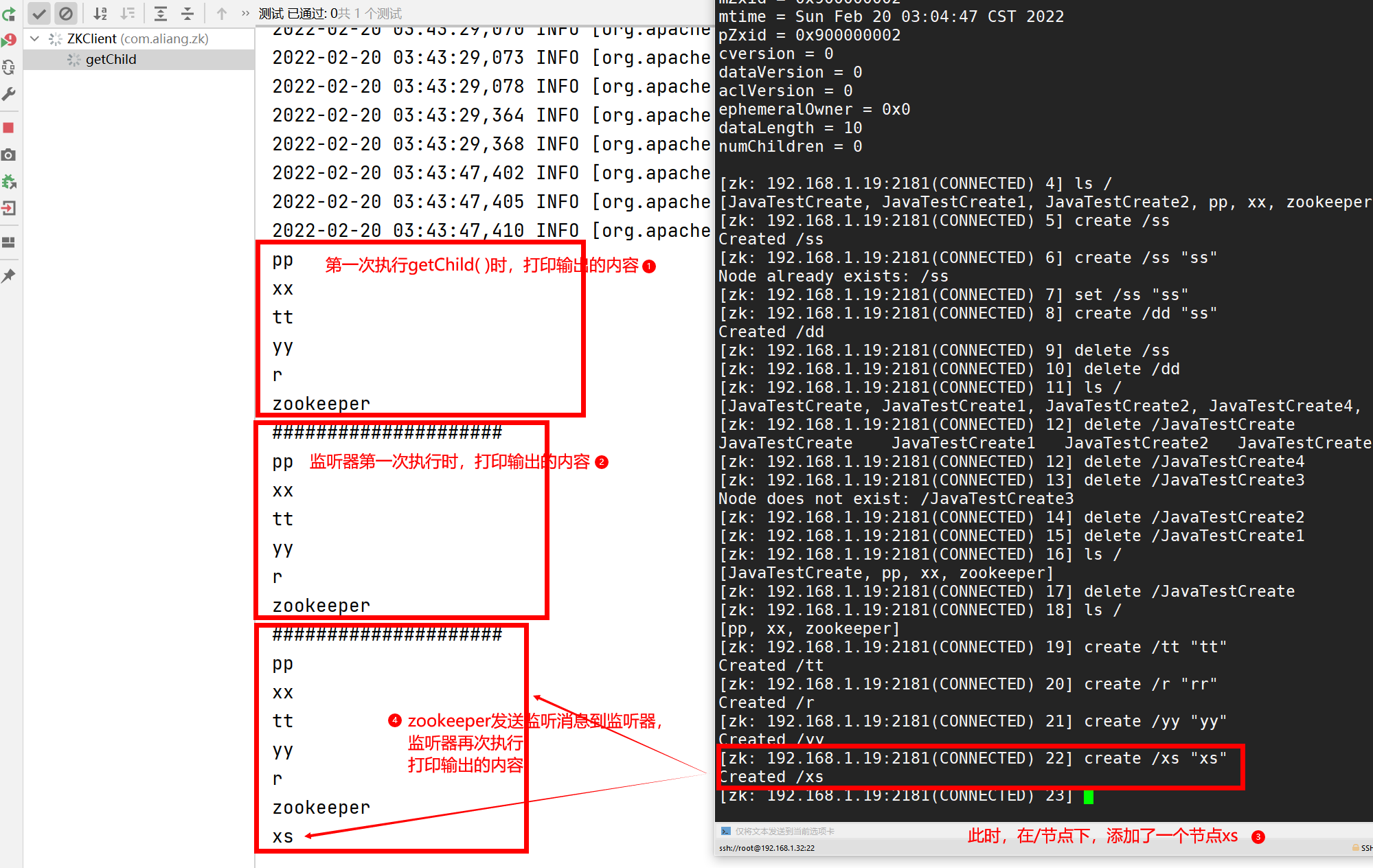
Case 4: judge whether the specified node exists
java code:
package com.aliang.zk;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
public class ZKClient {
String ip = "192.168.1.19:2181,192.168.1.32:2181,192.168.1.33:2181";
int ms = 200000;
ZooKeeper zk ;
@Before
public void init() throws IOException, InterruptedException {
zk = new ZooKeeper(ip, ms, null);
}
/**
* Judge whether the specified node exists
*/
@Test
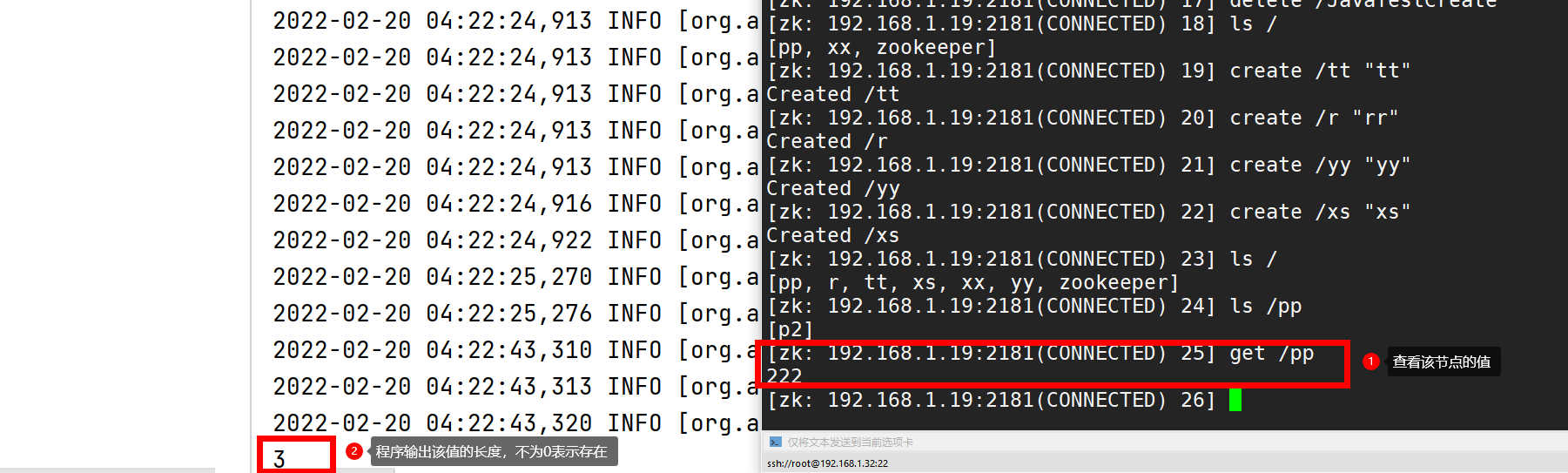
public void isExist() throws InterruptedException, KeeperException {
Stat exists = zk.exists("/pp", false); // false indicates that the listener is not used
System.out.println(exists.getDataLength());
}
}
Test results:
1.12 data writing principle
Scenario 1: three zookeeper servers, and the client initiates a write operation to the zookeeper to the leader server
-
The client sends a write request to the leader
-
The leader starts writing to the znode node
-
The leader notifies the first follower server of the data to be written
-
The first follower server, after writing, returns an ack confirmation packet to the leader, indicating that the writing has been completed
-
According to the number of ack packets received, the leader determines whether the zk server (including leader and follower) that has performed the write operation has reached half (2) of the cluster. When it has reached half (2), it returns the ack packet to the client, indicating that the write operation has been completed. This has the advantage of high efficiency. It does not need to wait for all followers to write. As long as it is more than half, the client can be notified
-
The leader continues to notify other follower servers to write data
-
When the other follower server finishes writing, it sends an ack confirmation packet to inform the leader that the writing has been completed
-
So far, the write operation of the client is completed
Scenario 2: three zookeeper servers, and the client initiates a write operation to the zookeeper server
- The client sends a write request to the follower
- The follower forwards the request to the leader and asks the leader to arrange it
- The leader starts writing to the znode node
- The leader starts to notify the first follower server of the data to be written
- The first follower server, after writing, returns an ack confirmation packet to the leader, indicating that the writing has been completed
- According to the number of ack packets received, the leader determines whether the zk server (including leader and follower) that has performed the write operation has reached half (2) of the cluster. When it reaches the number, it returns the ack packet to the follower server that has received the write request, indicating that the write operation has been completed and can respond to the client
- The leader continues to notify other follower servers to write data
- When the other follower server finishes writing, it sends an ack confirmation packet to inform the leader that the writing has been completed
- So far, the write operation of the client is completed
1.13. Server dynamic online and offline case study
The purpose of this case is to consolidate the learning of temporary nodes and listeners.
- Run zk cluster
- Write the logic code of the client
- Client connection zk cluster (new zookeeper(IP,TimeOut,Watcher))
- The client adds a listening event, listens to the changes of the specified node, and prints out the node name (zk.getChildren(NodePath,Watcher))
- Write the logical code of the server
- Server connection zk cluster (new zookeeper(IP,TimeOut,Watcher))
- The server creates a temporary node with serial number under the specified node. The simulation service goes online. After the program is executed, the temporary node is deleted and the simulation service goes offline (zkClient.create(NodeName,NodeValue,ACLType.NodeType))
- The client receives the listener message returned by zk, executes the listening event again, prints out the node name, and displays the changes of the node content under the currently monitored node
- When you go online, you add nodes, and when you go offline, you delete nodes
The server code can be tested by entering different host names on the command line. Take a single example here
package com.aliang.zk.Case1_OnlineStatusChange;
import org.apache.zookeeper.*;
import java.io.IOException;
public class Zk_Provider {
String ip = "192.168.1.19:2181,192.168.1.34:2181,192.168.1.33:2181";
int ms = 200000;
ZooKeeper zk ;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
//1. Get zk connection
Zk_Provider provider = new Zk_Provider();
provider.getConnect();
//2. Register service to zk server
provider.regist(args[0]); // Pass the hostname parameter of the command line into the method
///3. Start business logic
provider.service();
}
private void service() throws InterruptedException {
Thread.sleep(Integer.MAX_VALUE);
}
/**
* Used to register services to zk server
* @param hostName Service name
*/
private void regist(String hostName) throws InterruptedException, KeeperException {
//1. Create a node to indicate that the service is online and used for consumer subscription
zk.create("/servers/"+hostName,hostName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("Mainframe["+hostName+"]Online!");
}
private void getConnect() throws IOException {
zk = new ZooKeeper(ip, ms, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
}
Consumer code:
package com.aliang.zk.Case1_OnlineStatusChange;
import org.apache.zookeeper.*;
import java.io.IOException;
import java.util.List;
public class Zk_Consumer {
String ip = "192.168.1.19:2181,192.168.1.34:2181,192.168.1.33:2181";
int ms = 200000;
ZooKeeper zk ;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
//1. Get zk connection
Zk_Consumer provider = new Zk_Consumer();
provider.getConnect();
//2. Subscribe to the specified node
provider.distribute();
///3. Start business logic
provider.service();
}
private void service() throws InterruptedException {
Thread.sleep(Integer.MAX_VALUE);
}
/**
* Used to get the child nodes under the specified node
*/
private void distribute() throws InterruptedException, KeeperException {
//1. Gets the node list under the specified node
zk.getChildren("/servers", true);
}
private void getConnect() throws IOException {
zk = new ZooKeeper(ip, ms, new Watcher() {
@Override
public void process(WatchedEvent event) {
// Register an event that listens to the specified node
List<String> children = null;
try {
children = zk.getChildren("/servers", true);
if (children.size()!=0){
System.out.println("********Current child node list of the monitored node********");
for (String child : children) {
System.out.println("child:["+child+"]");
}
System.out.println("**************************************");
}else{
System.out.println("Status code:"+event.getState()+",Indicates that all services have been offline...");
}
}else{
System.out.println("The child nodes of the monitored node have been cleared");
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
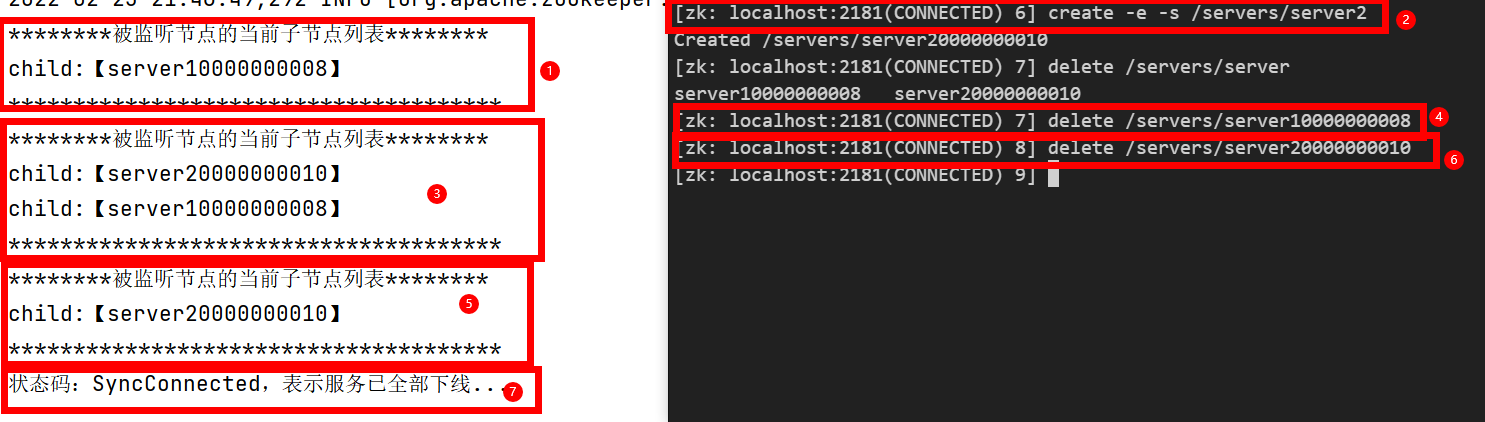
Test 1: child nodes of the current zk / servers node

Test 2: start the server and start registering a node
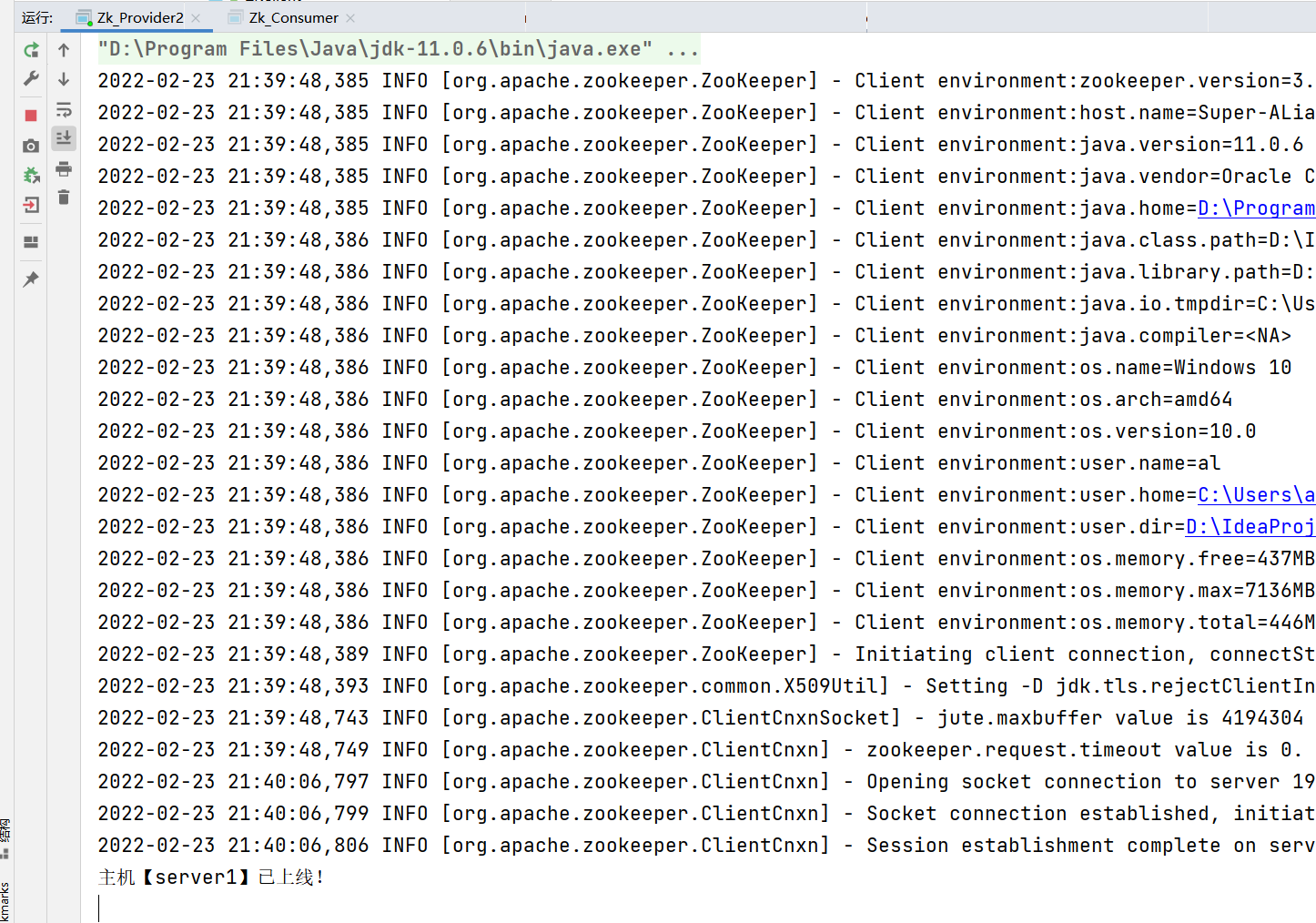

Test 3: start the online and offline of the consumer monitoring node
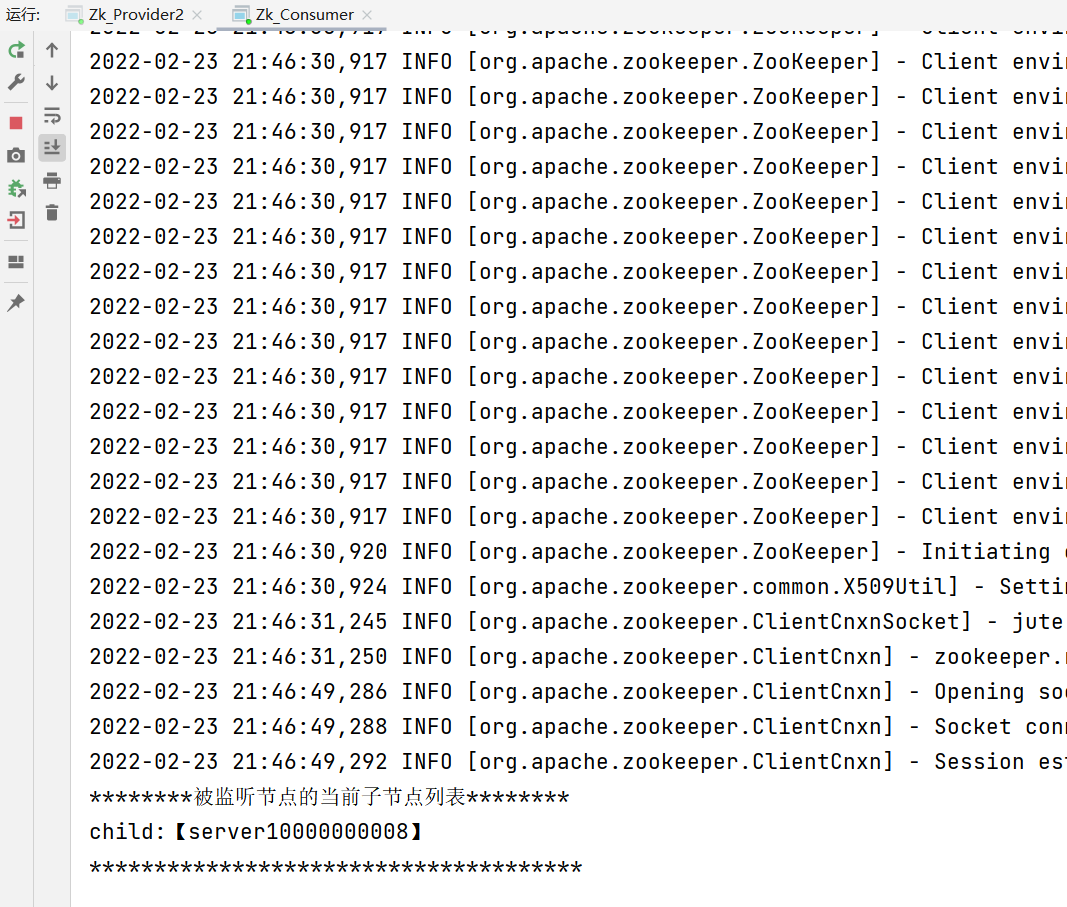
Test 4: register another server and view the print information of the consumer

Test 5: service offline