NoSQL getting started overview
MySQL database application history
The beautiful era of stand-alone MySQL
In the 1990s, the number of visits to a website was generally small, which could be easily handled with a single database. At that time, there were more static pages and less dynamic interactive websites.
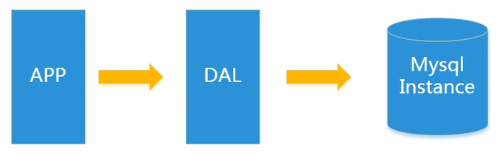
DAL: abbreviation of database access, namely Data Access Layer
Under the above architecture, let's take a look at the bottleneck of database storage?
- The total size of the data volume when one machine cannot fit
- Data index (B+ Tree) when the memory of a machine cannot fit
- The number of accesses (mixed reading and writing) cannot be borne by one instance
Memcached + MySQL + vertical split
Later, with the increase of visits, almost most websites using MySQL architecture had performance problems on the database. Web programs no longer only focus on functions, but also pursue performance. Programmers began to use caching technology to alleviate the pressure of the database and optimize the structure and index of the database. At first, file caching is popular to relieve the pressure on the database, but when the traffic continues to increase, multiple web machines cannot share through file caching, and a large number of small file caches also bring high IO pressure. At this time, Memcached naturally becomes a very fashionable technical product.
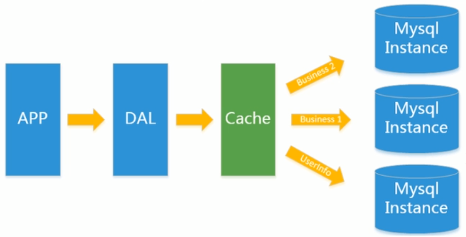
MySQL master-slave read-write separation
As the writing pressure of the database increases, Memcached can only alleviate the reading pressure of the database. Reading and writing are concentrated on one database, which makes the database overburdened. Most websites begin to use master-slave replication technology to achieve the separation of reading and writing, so as to improve the reading and writing performance and the scalability of the database. The master slave mode of MySQL became the standard configuration of the website at this time.
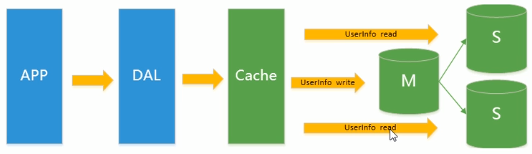
Separate tables and databases + horizontal splitting + MySQL Cluster
On the basis of Memcached cache, master-slave replication and read-write separation of MySQL, at this time, the write pressure of MySQL master database begins to appear bottleneck, and the amount of data continues to soar. Due to the use of table lock by MyISAM, serious lock problems will occur in high concurrency. A large number of high concurrency MySQL applications begin to use InnoDB engine to replace MyISAM.
At the same time, it has become popular to use sub tables and sub databases to alleviate the writing pressure and the expansion of database growth. At this time, sub database and sub table has become a hot technology, which is not only a hot issue in the interview, but also a hot technical issue discussed in the industry. That is, at this time, MySQL launched a table partition that is not very stable, which also brings hope to companies with average technical strength. Although MySQL has launched MySQL Cluster Cluster, its performance can not meet the requirements of the Internet, but it only provides a great guarantee for high reliability.
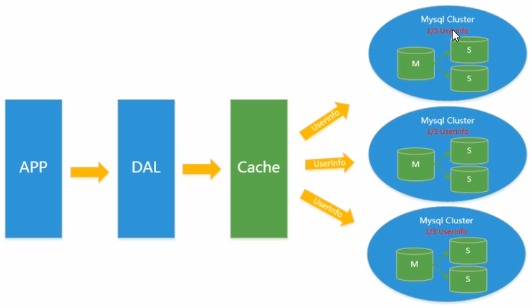
Scalability bottleneck of MySQL
Mysql database also often stores some large text fields, resulting in very large database tables. When doing database recovery, it is very slow and it is not easy to recover the database quickly. For example, 10 million 4KB files are close to 40GB. If you can save these data from mysql, MySQL will become very small. Relational database is very powerful, but it can not cope with all application scenarios. Under the pressure of MySQL, developers need to face up to the difficulty of changing the structure of MySQL.
What's it like today?
Basic concepts of NoSQL
Why use NoSQL
Today, we can easily access and capture data through third-party platforms (such as Google and Facebook). Users' personal information, social networks, geographical location, user generated data and user operation logs have multiplied. If we want to mine these user data, MySQL database is no longer suitable for these applications. The development of NoSQL database can handle these large data well.
What is NoSQL
NoSQL(Not Only SQL) means not only SQL, but also non relational database.
What can NoSQL do
Easy to expand
There are many kinds of NoSQL databases, but one common feature is to remove the relational characteristics of relational databases. There is no relationship between the data, so it is very easy to expand. It also brings expandable capabilities at the level of architecture.
Large amount of data and high performance
NoSQL databases have very high read and write performance, especially in large amounts of data. This is due to its irrelevance and the simple structure of the database.
Generally, MySQL uses Query Cache, and the Cache fails every time the table is updated. It is a kind of large-grained Cache, which is aimed at web2.0 0 is an application with frequent interaction, and the Cache performance is not high.
The NoSQL Cache is a record level Cache, which is a fine-grained Cache, so NoSQL has much higher performance at this level.
Diverse and flexible data types
NoSQL can store customized data formats at any time without establishing fields for the data to be stored in advance.
In the relational database, adding and deleting fields is a very troublesome thing. If it is a table with a very large amount of data, adding fields is a nightmare.
Traditional RDBMS VS NOSQL
RDBMS
- Highly organized structured data
- Structured query Fable (SQL)
- Data and relationships are stored in separate tables
- Data manipulation fable
- Strict consistency
- Basic transaction
NoSQL
- Represents more than just SQL
- No life query fable
- There are no predefined patterns
- Key value pair storage, column storage, document storage, graphic database
- Final consistency, not ACID attribute
- Unstructured and unpredictable data
- CAP theorem
- High performance, high availability and scalability
What is NoSQL
- Redis
- Memcached
- MongDB
How to use it?
- Key - Value
- Cache
- Persistence
3V + 3 high
3V in the era of big data
- Massive Volume
- Diversity
- Real time Velocity
3 high Internet demand
- High concurrency
- High extensibility
- High performance
Introduction to current NoSQL application scenarios
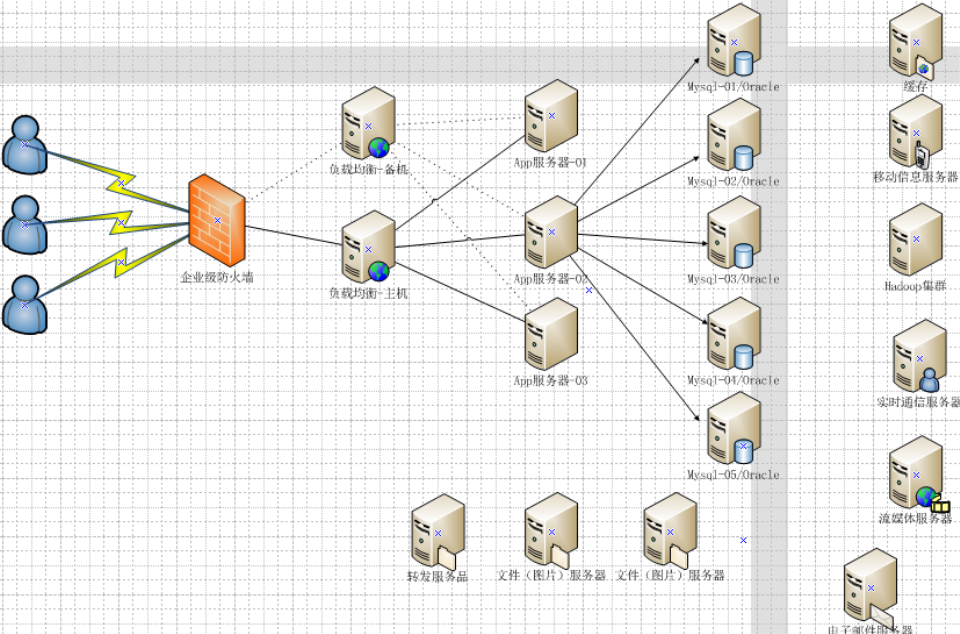
How to store the commodity information of Alibaba Chinese station
Architecture development process
-
Evolution process (up to the fourth generation)
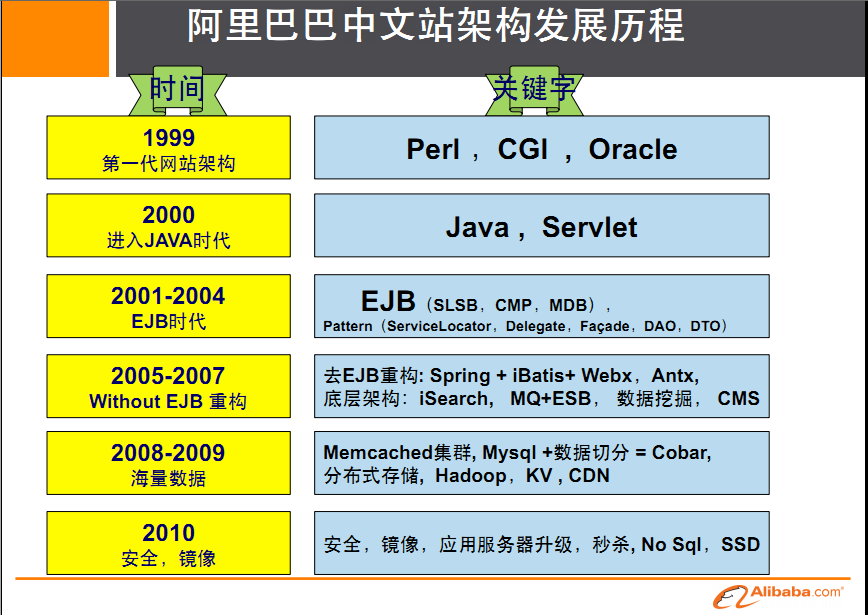
-
What problems does the fourth generation website mainly solve

-
Fifth generation architecture mission

-
Related to us, the storage of multiple data source types uses different databases for different data
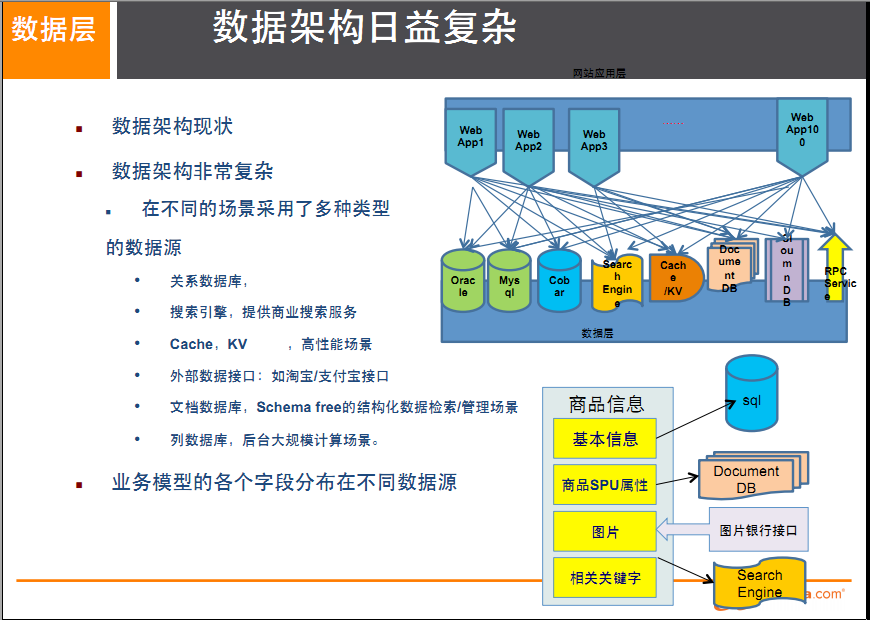
For the storage scheme of commodity information, take the home page of Alibaba Chinese website as an example
-
Basic information of goods
Name, price, date of manufacture, manufacturer, etc.
For relational database, mysql/oracle, Taobao is currently de oracle. The MySQL used in the package has been transformed by ourselves, not the MySQL we usually use.
Why go to IOE (in the process of IT construction, remove IBM minicomputers and Oracle database primary EMC storage devices) in short, you can not be constrained by these things.
-
Product description, details and evaluation information (multi text)
MongDB document database
-
Pictures of goods
Distributed file system (Taobao's own TFS, Google's GFS, Hadoop's HDFS)
-
Keywords of goods
Taobao's own ISearch
-
Hot spots and high-frequency information of commodities (such as chocolate on Valentine's day)
In memory database (Redis, Tair, Memcache)
-
Commodity trading, price calculation and integral accumulation
Alipay and external third party payment interface
Difficulties and solutions of large-scale Internet Applications (big data, high concurrency and diverse data types)
difficulty
- Data type diversity
- Data source diversity and change reconstruction
- Data source transformation and data service platform does not need large-scale reconstruction
terms of settlement
-
EAI
-
USDL unified data platform service layer
-
What is it?

-
What does it look like?

-
mapping

-
API

-
Hotspot cache
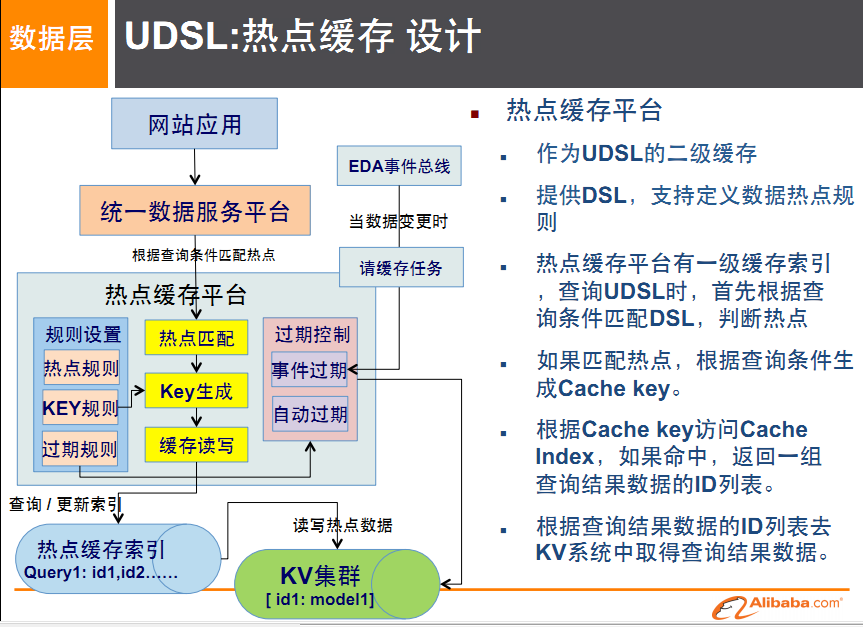
-
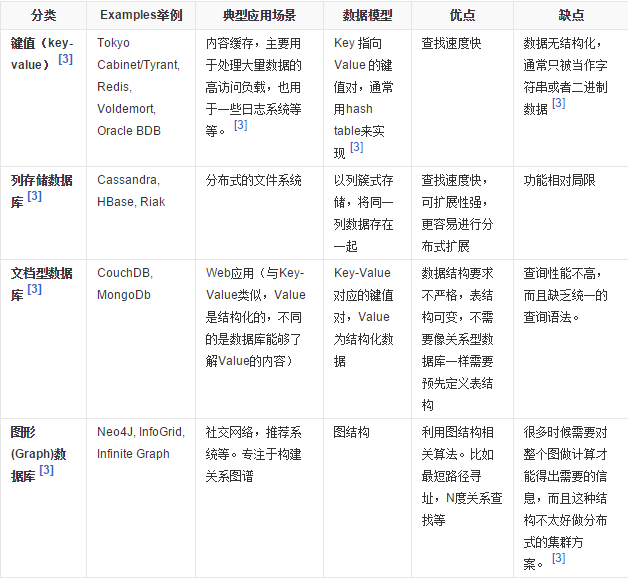
Four categories of NoSQL database
KV
- Sina: BerkeleyDB + Redis
- Meituan: redis + tail
- Alibaba, baidu: memcache + Redis
Document database (more bson formats)
-
CouchDB
-
MongDB
MongDB is a distributed file storage database. Written by C + + fable, it aims to provide scalable high-performance data storage solutions for WEB applications.
MongDB is a product between relational database and non relational database. It is the most functional and relational database among non relational databases.
Column storage database
- HBase
- Cassandra
- distributed file system
Graph relational database
It does not put graphics, but relationships, such as circle of friends, social networks and advertising recommendation system.
Social networks, recommendation systems. Focus on building the relationship map.
Neo4j,InfoGrid
Comparison of the four
Distributed database CAP principle
What are the traditional ACID
A (Atomicity): all operations in a transaction are either completed or not done. The condition for a successful transaction is that all operations in the transaction are successful. As long as one operation fails, the whole transaction fails and needs to be rolled back.
C (Consistency): the database should always be in a consistent state, and the operation of transactions will not change the original Consistency constraints of the database.
I (Isolation) independence: the so-called independence means that concurrent transactions will not affect each other. If the data to be accessed by a transaction is being modified by another transaction, as long as the other transaction is not committed, the data it accesses will not be affected by the uncommitted transaction.
D (Durability): persistence means that once a transaction is committed, its changes will be permanently saved in the database, and will not be lost even in case of downtime.
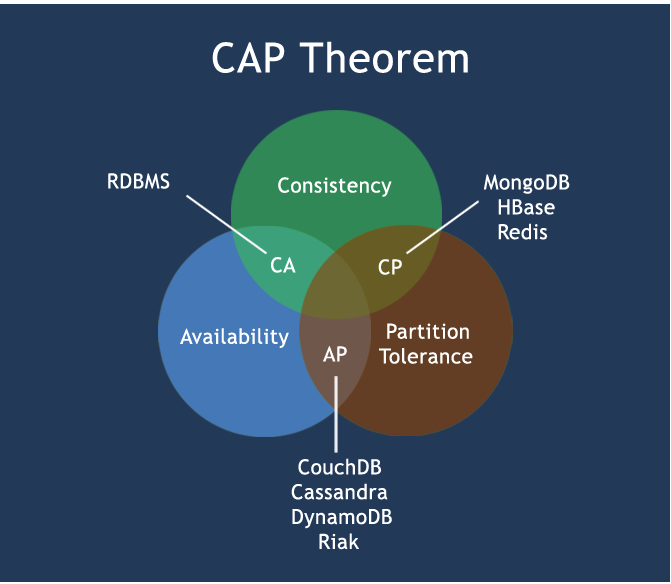
CAP
- C: Consistency (strong consistency)
- A: Availability
- P: Partition tolerance
CAP theory means that in distributed storage system, only the above two points can be considered at most.
Because the current network hardware will certainly have problems such as delay and packet loss, partition tolerance is what we must achieve. Therefore, we can only trade off between consistency and availability. No NoSQL system can guarantee these three points at the same time.
- CA traditional Oracle Database
- AP most website architecture choices
- CP Redis,MongoDB
Choice between consistency and availability
- Most web applications don't need strong consistency. Therefore, sacrificing C for P is the direction of distributed database products at present
- Database transaction consistency requirements: many web real-time systems do not require strict database transactions, and the requirements for read consistency are very low. In some cases, the requirements for write consistency are not high, allowing the realization of final consistency.
Classic CAP graph
The core of CAP theory is that a distributed system can not meet the three requirements of consistency, availability and partition fault tolerance at the same time. At most, it can only meet two requirements at the same time.
Therefore, according to the CAP principle, NoSQL database is divided into three categories that meet the CA principle, CP principle and AP principle:
- CA - single point cluster, a system that meets consistency and availability, is usually less powerful in scalability quotient.
- CP - a system that meets consistency and partition tolerance. Generally, the performance is not particularly high
- AP - a system that meets the requirements of availability and partition tolerance. It usually has lower requirements for consistency 202
BASE
BASE is a solution to reduce the availability caused by the problems caused by the strong consistency of relational database.
BASE is actually the abbreviation of the following three terms:
- Basically available
- Soft state
- Finally consistent
Its idea is to make the system relax the requirements for a certain time in exchange for the improvement of the overall scalability and performance of the system. Due to the requirements of regional distribution and high performance, it is impossible for Wangwang, a large system, to use distributed transactions to complete these indicators. In order to obtain these indicators, we must use another way to complete them. Here, BASE is the way to solve this problem.
Introduction to distributed + cluster
- Distributed: different service modules are deployed on different servers. They communicate and call each other through RPC/RMI to provide external services and intra group cooperation.
- Cluster: the same service module is deployed on different servers, and unified scheduling is carried out through distributed scheduling software to provide external services and access.
Basic concepts of Redis
definition
SQL / NOC is one of the most high-performance distributed database servers, which is also called NOC / NOC. It is also called NOC / NOC, which is a database with free memory structure.
Compared with other key value cache products, Redis has the following three characteristics
- Redis supports data persistence. It can save the data in memory on disk and load it again when restarting
- It not only supports simple key value data, but also provides the storage of list, set, zset, hash and other data structures
- Support data backup, that is, data backup in master slave mode
What can I do
- Memory storage and persistence: redis supports asynchronous writing of data in memory to the hard disk without affecting the continuous service
- The operation of getting the latest N data. For example, you can put the ID of the latest 10 comments in the List collection of Redis
- Simulate functions like HttpSession that need to set the expiration time
- Publish and subscribe message system
- Timer, counter
How do you play?
- Data type, basic operation and configuration
- Persistence and assignment, RDB/AOF
- Transaction control
- Assignment (master-slave relationship)
Redis usage
redis Basics
redis file introduction
Redis server redis server
Redis cli redis command line client
Redis benchmark redis performance test tool
Redis check AOF file repair tool
Redis check dump RDB file checking tool
Directory address of redis on mac
/usr/local/Cellar/redis/6.2.1/bin
redis. Location of conf redis configuration file
/usr/local/etc
Start redis
./redis-server
Stop redis
redis-cli shutdown
Enter redis
redis-cli
Miscellaneous startup knowledge after startup
-
Single process
Single process model to handle client requests. The response to read-write events is achieved by wrapping the epoll function. The actual processing speed of Redis completely depends on the execution efficiency of the main process.
Epoll is an improved epoll in the Linux kernel to deal with a large number of file descriptors. It is an enhanced version of the multiplexed IO interface select/poll under Linux. It can significantly improve the system CPU utilization when the program is only a small amount active in a large number of concurrent connections.
-
There are 16 databases by default. Similar to the array, the subscript starts from zero. The zero library is used by default initially, which can be configured in the configuration file
-
The select command switches the database
-
dbsize view the number of key s in the current database
-
Flush DB empties the current library
-
Flush empty all libraries
-
Unified password management, 16 libraries are the same password, either all OK or none can be connected
-
Redis indexes start from zero
-
The default port number is 6379, which can be found in redis.com Modify in conf
-
Where can I get redis common data type operation commands
Redis common commands
key keyword
-
key *: view all keys in the current library
-
Exists is the name of the key, which determines whether a key exists
eg : exists hello
Existence return: (integer) 1
No return: (integer) 0
-
move key db moves the key of the current database to the given database db
Name of move key db database serial number eg: move hello 15
-
expire key name seconds: sets the expiration time for a given key
-
ttl key to see how many seconds the key has expired, - 1 means it will never expire, - 2 means it has expired
-
type key to see what type of key you have
-
del key deletes a key when it exists
String
-
set key value sets the value of the specified key
-
get key gets the value of the specified key
-
getset key value sets the value of the given key to value and returns the old value of the key. If it does not exist, it returns nil
-
mget key1 [key2...] gets the values of all (one or more) given keys
-
Setnx key valueset the value of key only when the key does not exist
-
stelen key value returns the length of the string value stored by the key
-
Mesh key value [key value] set one or more key value pairs at the same time
-
mesetnx key value [key value] set one or more key value pairs at the same time if and only if all given keys do not exist
-
The addition and subtraction of incr/decr/incrby/decrby numbers is supported only when the string is a number
eg:
Incr li: the value corresponding to key(li) is fixed plus one
decr li: the value corresponding to key(li) is fixed minus one
incrby li 5: the value corresponding to key(li) is fixed plus 5
decrby li 5: the value corresponding to key(li) is fixed minus 5
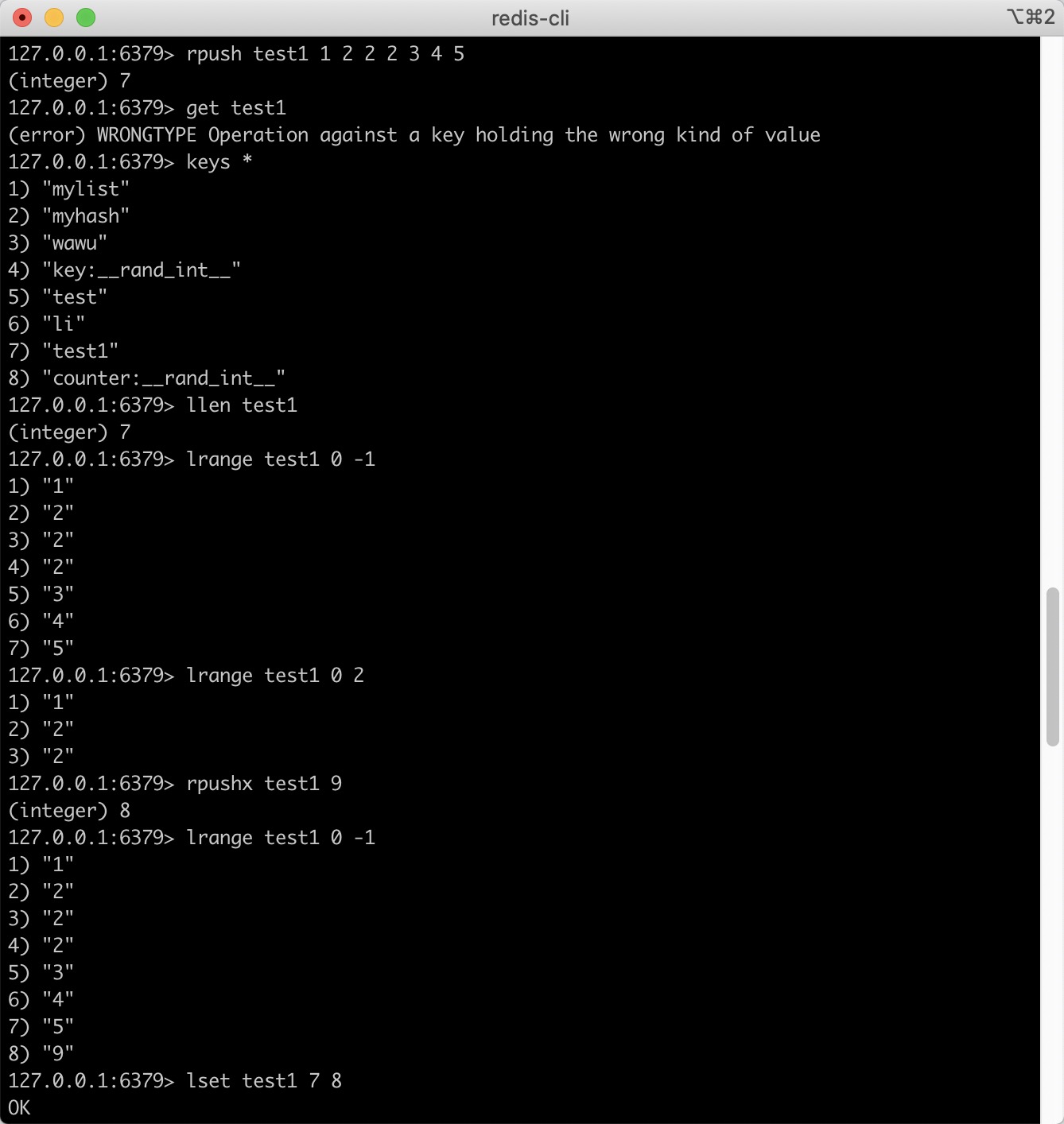
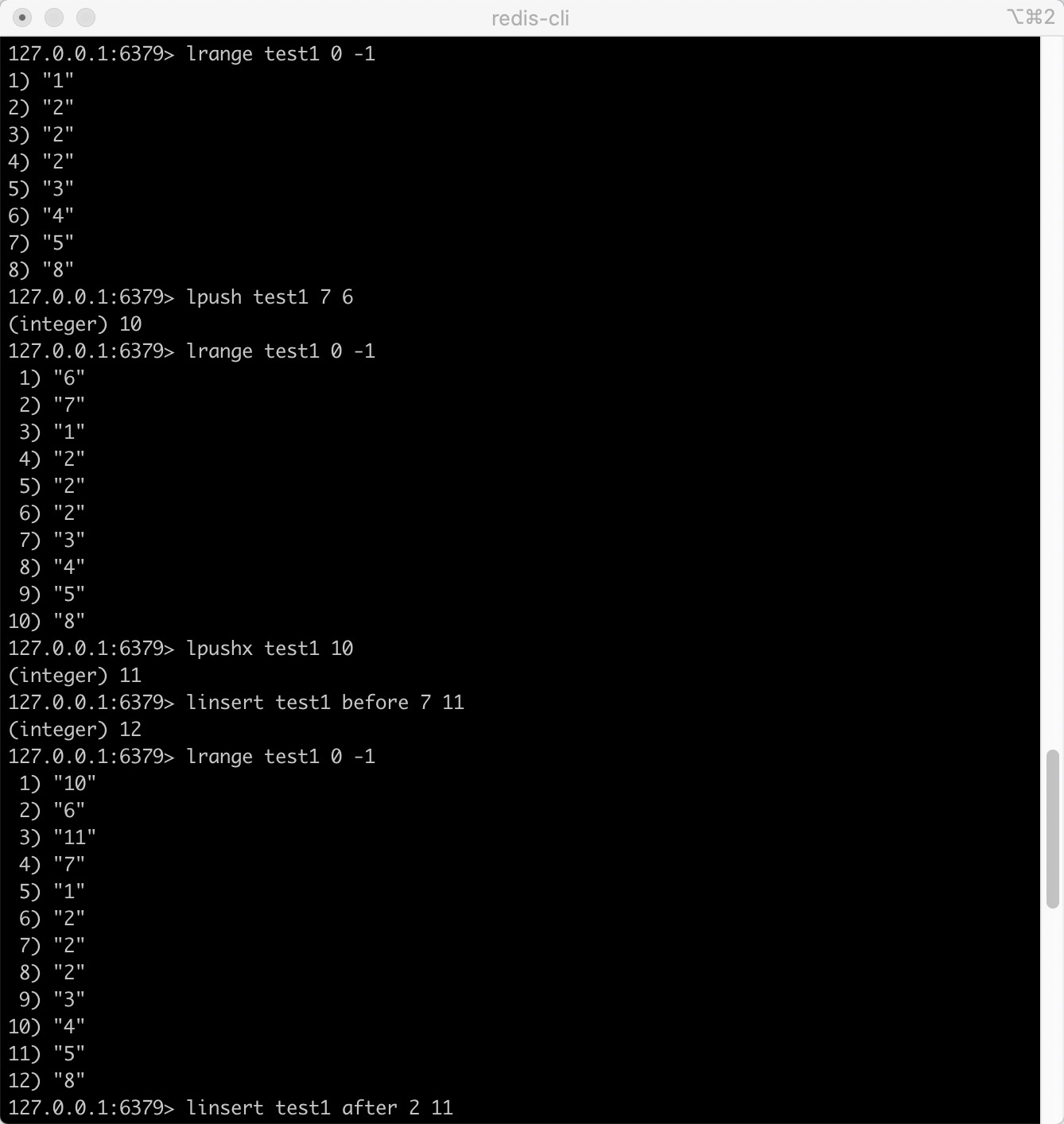
List
Set value
- rpush key value1 [value2] adds one or more values to the list
- rpushx key value adds a value to an existing list
- lset key index value sets the value of the list element through the index
- lpush key value1 [value2] inserts one or more values into the list header
- lpushx key value inserts a value into the header of an existing list
- linsert key before/alter pivot value inserts an element before or after a list element
Get value
-
lpop key moves out and gets the first element of the list
-
rpop key moves out of the last element in the list, and the return value is the moved out element
-
lindex key index gets the elements in the list through the index
-
blpop key1 [key2] timeout removes and obtains the first element of the list. If there is no element in the list, the list will be blocked until the waiting timeout or pop-up element is found
-
brpop key1 [key2] timeout moves out and gets the last element of the list. If there is no element in the list, the list will be blocked until the waiting timeout or pop-up element is found
-
lrange key start stop gets the elements within the specified range of the list
-
Len key to get the length of the list
Example test
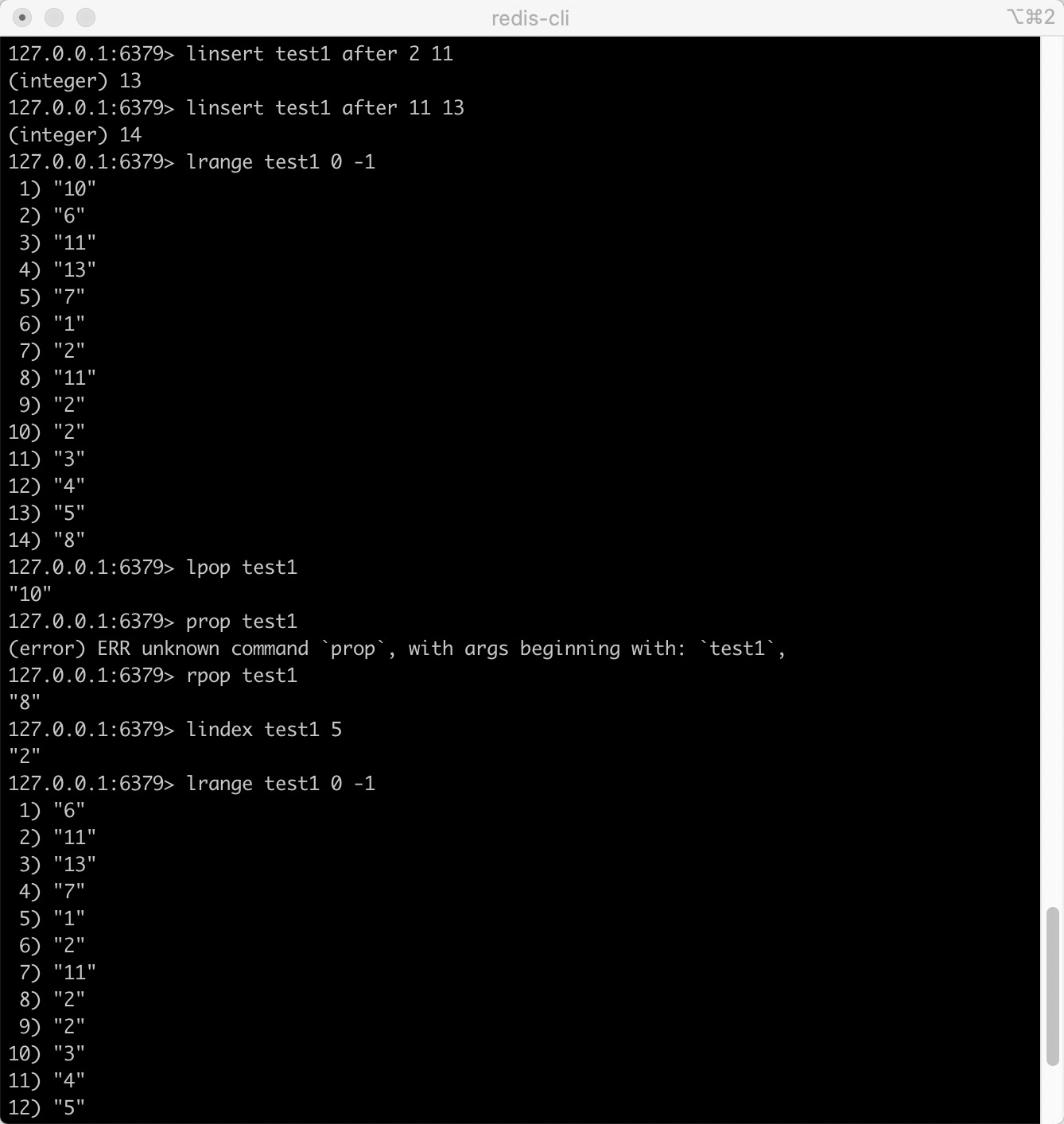

Set
- sadd key member1 [member2] adds one or more members to the collection
- scard key gets the number of members of the collection
- sismember key member determines whether the member element is a member of the set key
- smembers key returns all members in the collection
- spop key moves out and returns a random element in the collection
- srandmemeber key [count] gets one or more random numbers in the set
- srem key member1 [member2] moves one or more members out of the collection
Use example
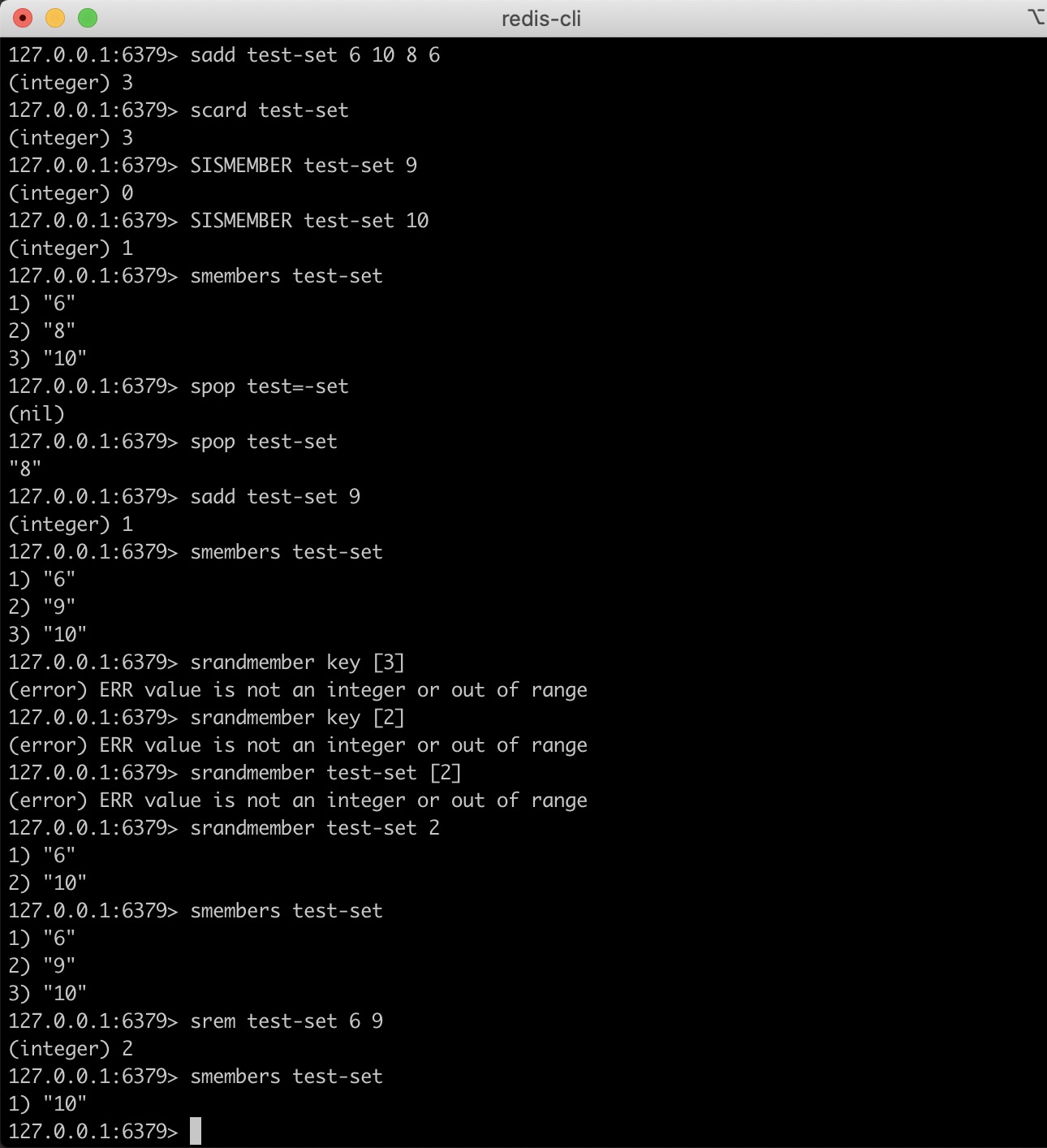
Hash
K mode remains unchanged, but V is a key value pair
Common commands:
- hdel key field1 [field2] Deletes one or more hash table fields
- hexists key field: check whether the specified field exists in the hash table key
- hget key field gets the value of the field specified in the hash table
- hgetall key gets all fields and values of the specified key in the hash table
- hkeys key gets the fields in all hash tables
- hlen key gets the number of fields in the hash table
- hmget key field1 [field2] get the values of all the given fields
- hmset key field1 value1 [field2 value2] set multiple field value pairs to the hash table key at the same time
- hset key field value sets the value of the field in the hash table key to value
- hsetnx key field value sets the value of the hash table field only when the field field does not exist
- hvals key gets all the values in the hash table
Usage example:
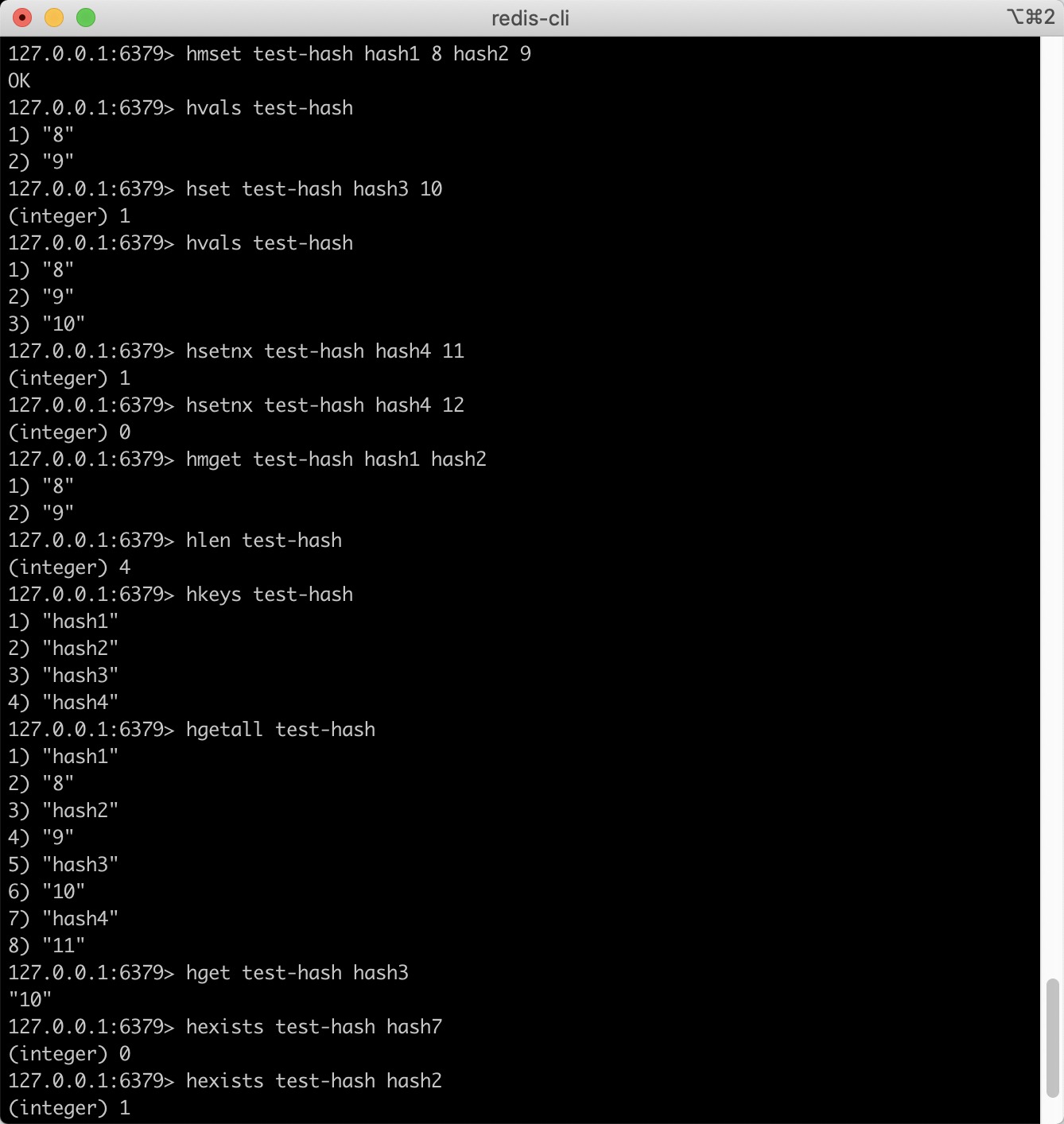

ZSet
If necessary, expand and do not understand for the time being
Redis profile
# redis start command # ./redis-server /path/to/redis.conf # The number of bytes corresponding to the redis unit. The unit is not case sensitive # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes # # Include indicates that redis can include configuration files of other redis ################################## INCLUDES ################################### # include /path/to/local.conf # include /path/to/other.conf #Load the module at startup. If the server cannot load the module, this configuration will be ignored. Multiple loadmodule s can be used. ################################## MODULES ##################################### # # loadmodule /path/to/my_module.so # loadmodule /path/to/other_module.so # Bind network interface to listen for client connection ################################## NETWORK ##################################### # # Examples: # # bind 192.168.1.100 10.0.0.1 # bind 127.0.0.1 ::1 # # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES # JUST COMMENT THE FOLLOWING LINE. # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ bind 127.0.0.1 # Default port number 6379 port 6379 # TCP listen() backlog. # # tcp-backlog 511 # Close the connection after a client is idle for N seconds (0 to disable) timeout 0 # TCP keepalive. # # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence # of communication. This is useful for two reasons: # # 1) Detect dead peers. # 2) Take the connection alive from the point of view of network # equipment in the middle. # # On Linux, the specified value (in seconds) is the period used to send ACKs. # Note that to close the connection the double of the time is needed. # On other kernels the period depends on the kernel configuration. # # A reasonable value for this option is 300 seconds, which is the new # Redis default starting with Redis 3.2.1. tcp-keepalive 300 ################################# GENERAL ##################################### # Daemon: daemon # Specifies whether redis should be started as a daemon thread # When set to yes, it means that the daemon mode is turned on. In this mode, redis will run in the background and write the process pid number to redis The conf option is in the file set by pidfile. At this time, redis will always run unless you manually kill the process # When set to no, the current interface will enter the redis command line interface. Forced exit or closing connection tools (putty,xshell, etc.) will cause the redis process to exit. daemonize yes #Redis daemon can be managed through upstart and systemd #Options: # supervised no - no supervised interaction # supervised upstart - starts the signal by placing Redis in SIGSTOP mode # supervised systemd - signal systemd writes READY = 1 to $NOTIFY_SOCKET # supervised auto - detects that the upstart or systemd method is based on UPSTART_JOB or NOTIFY_SOCKET environment variable # Note: these supervision methods only signal "process is ready." # They do not enable continuous liveness pings back to your supervisor. supervised no # Configure the PID file path. When redis runs as a daemon, the PID will be written to / var / run / redis_ In 6379.pid pidfile /var/run/redis_6379.pid # Define log level # The parameters are as follows: # debug (a lot of information, useful for development/testing) # verbose (many rarely useful info, but not a mess like the debug level) # notice (moderately verbose, what you want in production probably) # warning (only very important / critical messages are logged) loglevel notice # Output log, the default is standard output, that is, output to the screen # output for logging but daemonize, logs will be sent to /dev/null logfile "" # Set logging. If you want to record it to the system log, change it to yes # syslog-enabled no # Set the ID of the system log # syslog-ident redis # Specify system log settings Must be USER or between LOCAL0-LOCAL7. It's local, not loca + 10 # syslog-facility local0 # The number of databases. The default is 16 databases 16 # Whether to always display logo always-show-logo yes #Snapshot configuration ################################ SNAPSHOTTING ################################ # #Save data to disk: # # save <seconds> <changes> # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # # Save data to disk when a key changes in 15 minutes # after 900 sec (15 min) if at least 1 key changed # # Save data to disk when 10 key s change in 5 minutes # after 300 sec (5 min) if at least 10 keys changed # # Save data to disk when 10000 key s change in one minute # after 60 sec if at least 10000 keys changed # # Note: you can disable saving completely by commenting out all "save" lines. # # You can also delete all previously configured saves. # By adding a save instruction with a single empty string parameter # like in the following example: # # save "" save 900 1 save 300 10 save 60 10000 # Do you want to continue working after persistent errors occur stop-writes-on-bgsave-error yes # Whether to verify rdb files, # It is more conducive to file fault tolerance, but there will be about 10% performance loss when saving rdb files, # So if you want high performance, you can turn off the configuration rdbcompression yes # rdb files are compressed using LZF compression algorithm, # yes: compression, but it requires some cpu consumption. # No: no compression. More disk space is required rdbchecksum yes # DB file name dbfilename dump.rdb # Working directory # DB will write in this directory and specify the file name using the "dbfilename" configuration instruction above dir ./ #Master slave replication configuration ################################# REPLICATION ################################# # Master slave replication. Use slaveof as a redis instance to back up another redis server # # 1) Redis replication is asynchronous, but you can configure a master to # stop accepting writes if it appears to be not connected with at least # a given number of slaves. # 2) Redis slaves are able to perform a partial resynchronization with the # master if the replication link is lost for a relatively small amount of # time. You may want to configure the replication backlog size (see the next # sections of this file) with a sensible value depending on your needs. # 3) Replication is automatic and does not need user intervention. After a # network partition slaves automatically try to reconnect to masters # and resynchronize with them. # # slaveof <masterip> <masterport> # Configure the password of the master so that you can authenticate after connecting to the master # masterauth <master-password> # When the slave node loses connection or replication is in progress, the slave node has two operation modes: # # yes: continue to respond to the client's request # no: any request other than INFO and SLAVEOF commands will return an error # slave-serve-stale-data yes # Is the slave server read-only slave-read-only yes #At present, redis replication provides two methods, disk and socket. #If the new slave is connected or the reconnected slave cannot be partially synchronized, full synchronization will be performed and the master will generate rdb files. # There are two ways: # Disk backed: the master creates a new process, saves the rdb file to the disk, and then passes the rdb file on the disk to the slave. # Diskless: the master creates a new process and directly sends the rdb file to the slave in the form of socket disk Way, when a rdb In the process of saving, multiple slave Can share this rdb Documents. socket One by one slave Sequential replication. It is recommended when the disk speed is slow and the network speed is fast socket mode # With slow disks and fast (large bandwidth) networks, diskless replication # works better. repl-diskless-sync no # When socket replication is enabled, the delay time of socket replication is set to 0, which means it is disabled. The default value is 5 repl-diskless-sync-delay 5 # The default value is 10 seconds # repl-ping-slave-period 10 # The following option sets the replication timeout for: # # 1) Bulk transfer I/O during SYNC, from the point of view of slave. # 2) Master timeout from the point of view of slaves (data, pings). # 3) Slave timeout from the point of view of masters (REPLCONF ACK pings). # # It is important to make sure that this value is greater than the value # specified for repl-ping-slave-period otherwise a timeout will be detected # every time there is low traffic between the master and the slave. #Replication connection timeout # repl-timeout 60 #Whether to prohibit copying the tcp nodelay parameter of the tcp link. yes or no can be passed. The default is No #That is, tcp nodelay is used. If yes is set in the master to disable tcp nodelay setting, #When copying data to the slave, it will reduce the number of packets and smaller network bandwidth. #However, this may also lead to data delay. By default, we recommend a smaller delay, #However, in the case of a large amount of data transmission, it is recommended to select yes repl-disable-tcp-nodelay no # Set the replication backlog size. #Save the copied command. #When the slave node is disconnected for a period of time, the master node will collect data to the backlog buffer, #Therefore, when a slave node wants to reconnect, it usually does not need to be fully resynchronized, #But partial resynchronization is enough, just by passing part of the data when the connection is disconnected. The default is 1mb # # repl-backlog-size 1mb # When the master node no longer contacts the slave node, the backlog is released # # repl-backlog-ttl 3600 # When the master is unavailable, Sentinel will select a master according to the priority of the slave. # The slave with the lowest priority is selected as the master. If it is set to 0, it will never be elected # # By default the priority is 100. slave-priority 100 # When the number of healthy slave is less than N, matser prohibits writing # min-slaves-to-write 3 # A slave with a delay of less than min slaves Max lag seconds is considered a healthy slave # min-slaves-max-lag 10 # # Setting one or the other to 0 disables the feature. # # By default min-slaves-to-write is set to 0 (feature disabled) and # min-slaves-max-lag is set to 10. # A Redis master is able to list the address and port of the attached # slaves in different ways. For example the "INFO replication" section # offers this information, which is used, among other tools, by # Redis Sentinel in order to discover slave instances. # Another place where this info is available is in the output of the # "ROLE" command of a master. # # The listed IP and address normally reported by a slave is obtained # in the following way: # # IP: The address is auto detected by checking the peer address # of the socket used by the slave to connect with the master. # # Port: The port is communicated by the slave during the replication # handshake, and is normally the port that the slave is using to # list for connections. # # However when port forwarding or Network Address Translation (NAT) is # used, the slave may be actually reachable via different IP and port # pairs. The following two options can be used by a slave in order to # report to its master a specific set of IP and port, so that both INFO # and ROLE will report those values. # # There is no need to use both the options if you need to override just # the port or the IP address. # # slave-announce-ip 5.5.5.5 # slave-announce-port 1234 # security ################################## SECURITY ################################### # Require clients to issue AUTH <PASSWORD> before processing any other # commands. This might be useful in environments in which you do not trust # others with access to the host running redis-server. # # This should stay commented out for backward compatibility and because most # people do not need auth (e.g. they run their own servers). # # Warning: since Redis is pretty fast an outside user can try up to # 150k passwords per second against a good box. This means that you should # use a very strong password otherwise it will be very easy to break. # # Set redis connection password # requirepass foobared # Command renaming. # # It is possible to change the name of dangerous commands in a shared # environment. For instance the CONFIG command may be renamed into something # hard to guess so that it will still be available for internal-use tools # but not available for general clients. # # Example: # # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 # # It is also possible to completely kill a command by renaming it into # an empty string: # Rename the command. For safety reasons, you can rename some important and dangerous commands. # When you rename a command to an empty string, you cancel the command. # rename-command CONFIG "" # # Please note that changing the name of commands that are logged into the # AOF file or transmitted to slaves may cause problems. #client ################################### CLIENTS #################################### # Set the maximum number of client connections # maxclients 10000 # memory management ############################## MEMORY MANAGEMENT ################################ # Specify the maximum memory limit of Redis. When Redis starts, it will load data into memory. After reaching the maximum memory, Redis will first try to clear the expired or about to expire keys # After this method is processed, the maximum memory setting is still reached, and the write operation can no longer be carried out, but the read operation can still be carried out. Redis's new vm mechanism, # The Key will be stored in memory and the Value will be stored in the swap area # # maxmemory <bytes> # When the memory usage reaches the maximum, redis uses the following clearing strategy: # # volatile-lru -> Evict using approximated LRU among the keys with an expire set. # allkeys-lru -> Evict any key using approximated LRU. # volatile-lfu -> Evict using approximated LFU among the keys with an expire set. # allkeys-lfu -> Evict any key using approximated LFU. # volatile-random -> Remove a random key among the ones with an expire set. # allkeys-random -> Remove a random key, any key. # volatile-ttl -> Remove the key with the nearest expire time (minor TTL) # noeviction -> Don't evict anything, just return an error on write operations. # # LRU means Least Recently Used # LFU means Least Frequently Used # # Both LRU, LFU and volatile-ttl are implemented using approximated # randomized algorithms. # # Note: with any of the above policies, Redis will return an error on write # operations, when there are no suitable keys for eviction. # # At the date of writing these commands are: set setnx setex append # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby # getset mset msetnx exec sort # # The default is: # # maxmemory-policy noeviction # LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated # algorithms (in order to save memory), so you can tune it for speed or # accuracy. For default Redis will check five keys and pick the one that was # used less recently, you can change the sample size using the following # configuration directive. # # The default of 5 produces good enough results. 10 Approximates very closely # true LRU but costs more CPU. 3 is faster but not very accurate. # # maxmemory-samples 5 # When deleting an object, it is only a logical deletion, and then the object is thrown to the background, so that the background thread can execute the real destruct to avoid blocking due to the excessive volume of the object ############################# LAZY FREEING #################################### # Redis has two primitives to delete keys. One is called DEL and is a blocking # deletion of the object. It means that the server stops processing new commands # in order to reclaim all the memory associated with an object in a synchronous # way. If the key deleted is associated with a small object, the time needed # in order to execute the DEL command is very small and comparable to most other # O(1) or O(log_N) commands in Redis. However if the key is associated with an # aggregated value containing millions of elements, the server can block for # a long time (even seconds) in order to complete the operation. # # For the above reasons Redis also offers non blocking deletion primitives # such as UNLINK (non blocking DEL) and the ASYNC option of FLUSHALL and # FLUSHDB commands, in order to reclaim memory in background. Those commands # are executed in constant time. Another thread will incrementally free the # object in the background as fast as possible. # # DEL, UNLINK and ASYNC option of FLUSHALL and FLUSHDB are user-controlled. # It's up to the design of the application to understand when it is a good # idea to use one or the other. However the Redis server sometimes has to # delete keys or flush the whole database as a side effect of other operations. # Specifically Redis deletes objects independently of a user call in the # following scenarios: # # 1) On eviction, because of the maxmemory and maxmemory policy configurations, # in order to make room for new data, without going over the specified # memory limit. # 2) Because of expire: when a key with an associated time to live (see the # EXPIRE command) must be deleted from memory. # 3) Because of a side effect of a command that stores data on a key that may # already exist. For example the RENAME command may delete the old key # content when it is replaced with another one. Similarly SUNIONSTORE # or SORT with STORE option may delete existing keys. The SET command # itself removes any old content of the specified key in order to replace # it with the specified string. # 4) During replication, when a slave performs a full resynchronization with # its master, the content of the whole database is removed in order to # load the RDB file just transfered. # # In all the above cases the default is to delete objects in a blocking way, # like if DEL was called. However you can configure each case specifically # in order to instead release memory in a non-blocking way like if UNLINK # was called, using the following configuration directives: # Slave lazy flush: the option to clear the data after the slave receives the RDB file # Lazy free lazy eviction: full memory eviction option # Lazy free lazy expire: option to delete expired key s # Lazyfree lazy server del: internal deletion options. For example, when renaming oldkey and newkey, if the newkey exists, the newkey needs to be deleted lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no slave-lazy-flush no ############################## APPEND ONLY MODE ############################### #By default, redis uses rdb persistence, #This approach is sufficient in many applications. #However, if redis goes down halfway, it may cause several minutes of data loss, #Persist according to the save policy. Append Only File is another persistence method, #Can provide better persistence features. #Redis will write the data written each time to appendonly after receiving Aof files, #At each startup, Redis will first read the data of this file into memory and ignore the RDB file first appendonly no # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # The fsync() call tells the Operating System to actually write data on disk # instead of waiting for more data in the output buffer. Some OS will really flush # data on disk, some other OS will just try to do it ASAP. # # Redis supports three different modes: # # no: don't fsync, just let the OS flush the data when it wants. Faster. # always: fsync after every write to the append only log. Slow, Safest. # everysec: fsync only one time every second. Compromise. # # The default is "everysec", as that's usually the right compromise between # speed and data safety. It's up to you to understand if you can relax this to # "no" that will let the operating system flush the output buffer when # it wants, for better performances (but if you can live with the idea of # some data loss consider the default persistence mode that's snapshotting), # or on the contrary, use "always" that's very slow but a bit safer than # everysec. # # More details please check the following article: # http://antirez.com/post/redis-persistence-demystified.html # # If unsure, use "everysec". # no means that fsync is not executed. The operating system ensures that the data is synchronized to the disk, and the speed is the fastest. # always means that fsync is executed for each write to ensure data synchronization to disk. # everysec means that fsync is executed every second, which may result in the loss of this 1s data # appendfsync always appendfsync everysec # appendfsync no # When aof rewrites or writes rdb files, a lot of IO will be executed, #At this time, for aof modes of everysec and always, executing fsync will cause blocking for a long time, #The no appendfsync on rewrite field is set to no by default, #For applications with high delay requirements, this field can be set to yes, otherwise it can be set to no, #This is a safer choice for persistence features. #Set to yes to indicate that new write operations are not fsync during rewriting and are temporarily stored in memory. Write again after rewriting is completed, #The default value is no, and yes is recommended. The default fsync policy for Linux is 30 seconds. 30 seconds of data may be lost no-appendfsync-on-rewrite no # When the current aof file size exceeds the percentage of the aof file size rewritten last time, #That is, when the aof file grows to a certain size, Redis can call bgrewrite aof to rewrite the log file. #When the current AOF file size is twice the size of the AOF file obtained from the last log rewrite (set to 100), #Automatically start a new log rewrite process auto-aof-rewrite-percentage 100 #Set the minimum aof file size that can be rewritten to avoid rewriting when the agreed percentage is reached but the size is still very small auto-aof-rewrite-min-size 64mb #Can redis load truncated AOF files at startup aof-load-truncated yes # Redis 4.0 adds RDB-AOF mixed persistence format, which is an optional function, # After this function is enabled, the file generated by AOF rewriting will contain both RDB format content and AOF format content, # The content in RDB format is used to record the existing data, while the memory in AOF format is used to record the recently changed data, # In this way, Redis can have the advantages of RDB persistence and AOF persistence at the same time - it can not only quickly generate rewritten files, but also quickly load data in case of problems aof-use-rdb-preamble no ################################ LUA SCRIPTING ############################### # Max execution time of a Lua script in milliseconds. # # If the maximum execution time is reached Redis will log that a script is # still in execution after the maximum allowed time and will start to # reply to queries with an error. # # When a long running script exceeds the maximum execution time only the # SCRIPT KILL and SHUTDOWN NOSAVE commands are available. The first can be # used to stop a script that did not yet called write commands. The second # is the only way to shut down the server in the case a write command was # already issued by the script but the user doesn't want to wait for the natural # termination of the script. # # Set it to 0 or a negative value for unlimited execution without warnings. lua-time-limit 5000 #Cluster settings ################################ REDIS CLUSTER ############################### # # ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ # WARNING EXPERIMENTAL: Redis Cluster is considered to be stable code, however # in order to mark it as "mature" we need to wait for a non trivial percentage # of users to deploy it in production. # ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ # # Normal Redis instances can't be part of a Redis Cluster; only nodes that are # started as cluster nodes can. In order to start a Redis instance as a # Cluster mode is not enabled by default # cluster-enabled yes # Every cluster node has a cluster configuration file. This file is not # intended to be edited by hand. It is created and updated by Redis nodes. # Every Redis Cluster node requires a different cluster configuration file. # Make sure that instances running in the same system do not have # overlapping cluster configuration file names. # The name of the cluster configuration file. Each node has a cluster related configuration file to persist the cluster information # cluster-config-file nodes-6379.conf # Cluster node timeout is the amount of milliseconds a node must be unreachable # for it to be considered in failure state. # Most other internal time limits are multiple of the node timeout. # Timeout for node interconnection # cluster-node-timeout 15000 # A slave of a failing master will avoid to start a failover if its data # looks too old. # # There is no simple way for a slave to actually have an exact measure of # its "data age", so the following two checks are performed: # # 1) If there are multiple slaves able to failover, they exchange messages # in order to try to give an advantage to the slave with the best # replication offset (more data from the master processed). # Slaves will try to get their rank by offset, and apply to the start # of the failover a delay proportional to their rank. # # 2) Every single slave computes the time of the last interaction with # its master. This can be the last ping or command received (if the master # is still in the "connected" state), or the time that elapsed since the # disconnection with the master (if the replication link is currently down). # If the last interaction is too old, the slave will not try to failover # at all. # # The point "2" can be tuned by user. Specifically a slave will not perform # the failover if, since the last interaction with the master, the time # elapsed is greater than: # # (node-timeout * slave-validity-factor) + repl-ping-slave-period # # So for example if node-timeout is 30 seconds, and the slave-validity-factor # is 10, and assuming a default repl-ping-slave-period of 10 seconds, the # slave will not try to failover if it was not able to talk with the master # for longer than 310 seconds. # # A large slave-validity-factor may allow slaves with too old data to failover # a master, while a too small value may prevent the cluster from being able to # elect a slave at all. # # For maximum availability, it is possible to set the slave-validity-factor # to a value of 0, which means, that slaves will always try to failover the # master regardless of the last time they interacted with the master. # (However they'll always try to apply a delay proportional to their # offset rank). # # Zero is the only value able to guarantee that when all the partitions heal # the cluster will always be able to continue. # It is used to judge whether the disconnection time between slave node and master is too long # cluster-slave-validity-factor 10 # Cluster slaves are able to migrate to orphaned masters, that are masters # that are left without working slaves. This improves the cluster ability # to resist to failures as otherwise an orphaned master can't be failed over # in case of failure if it has no working slaves. # # Slaves migrate to orphaned masters only if there are still at least a # given number of other working slaves for their old master. This number # is the "migration barrier". A migration barrier of 1 means that a slave # will migrate only if there is at least 1 other working slave for its master # and so forth. It usually reflects the number of slaves you want for every # master in your cluster. # # Default is 1 (slaves migrate only if their masters remain with at least # one slave). To disable migration just set it to a very large value. # A value of 0 can be set but is useful only for debugging and dangerous # in production. # # cluster-migration-barrier 1 # By default Redis Cluster nodes stop accepting queries if they detect there # is at least an hash slot uncovered (no available node is serving it). # This way if the cluster is partially down (for example a range of hash slots # are no longer covered) all the cluster becomes, eventually, unavailable. # It automatically returns available as soon as all the slots are covered again. # # However sometimes you want the subset of the cluster which is working, # to continue to accept queries for the part of the key space that is still # covered. In order to do so, just set the cluster-require-full-coverage # option to no. # # cluster-require-full-coverage yes # In order to setup your cluster make sure to read the documentation # available at http://redis.io web site. #Cluster Docker/NAT support ########################## CLUSTER DOCKER/NAT support ######################## # In certain deployments, Redis Cluster nodes address discovery fails, because # addresses are NAT-ted or because ports are forwarded (the typical case is # Docker and other containers). # # In order to make Redis Cluster working in such environments, a static # configuration where each node knows its public address is needed. The # following two options are used for this scope, and are: # # * cluster-announce-ip # * cluster-announce-port # * cluster-announce-bus-port # # Each instruct the node about its address, client port, and cluster message # bus port. The information is then published in the header of the bus packets # so that other nodes will be able to correctly map the address of the node # publishing the information. # # If the above options are not used, the normal Redis Cluster auto-detection # will be used instead. # # Note that when remapped, the bus port may not be at the fixed offset of # clients port + 10000, so you can specify any port and bus-port depending # on how they get remapped. If the bus-port is not set, a fixed offset of # 10000 will be used as usually. # # Example: # # cluster-announce-ip 10.1.1.5 # cluster-announce-port 6379 # cluster-announce-bus-port 6380 # Slow log ################################## SLOW LOG ################################### # The Redis Slow Log is a system to log queries that exceeded a specified # execution time. The execution time does not include the I/O operations # like talking with the client, sending the reply and so forth, # but just the time needed to actually execute the command (this is the only # stage of command execution where the thread is blocked and can not serve # other requests in the meantime). # # You can configure the slow log with two parameters: one tells Redis # what is the execution time, in microseconds, to exceed in order for the # command to get logged, and the other parameter is the length of the # slow log. When a new command is logged the oldest one is removed from the # queue of logged commands. # The following time is expressed in microseconds, so 1000000 is equivalent # to one second. Note that a negative number disables the slow log, while # a value of zero forces the logging of every command. # Record queries with query time greater than 10000 microseconds slowlog-log-slower-than 10000 # There is no limit to this length. Just be aware that it will consume memory. # You can reclaim memory used by the slow log with SLOWLOG RESET. # Save 128 logs slowlog-max-len 128 # Delay monitoring ################################ LATENCY MONITOR ############################## # The Redis latency monitoring subsystem samples different operations # at runtime in order to collect data related to possible sources of # latency of a Redis instance. # # Via the LATENCY command this information is available to the user that can # print graphs and obtain reports. # # The system only logs operations that were performed in a time equal or # greater than the amount of milliseconds specified via the # latency-monitor-threshold configuration directive. When its value is set # to zero, the latency monitor is turned off. # # By default latency monitoring is disabled since it is mostly not needed # if you don't have latency issues, and collecting data has a performance # impact, that while very small, can be measured under big load. Latency # monitoring can easily be enabled at runtime using the command # "CONFIG SET latency-monitor-threshold <milliseconds>" if needed. # The redis delay monitoring system will sample some operations during operation in order to collect the data sources that may lead to the delay. # Through the degree command, you can print some drawings and obtain some reports to facilitate monitoring # This system only records the operation whose execution time is greater than or equal to the predetermined time (milliseconds), # The scheduled time is specified through the latency monitor threshold configuration, # When set to 0, the monitoring system is stopped latency-monitor-threshold 0 #Event notification ############################# EVENT NOTIFICATION ############################## # Redis can notify Pub/Sub clients about events happening in the key space. # This feature is documented at http://redis.io/topics/notifications # # For instance if keyspace events notification is enabled, and a client # performs a DEL operation on key "foo" stored in the Database 0, two # messages will be published via Pub/Sub: # # PUBLISH __keyspace@0__:foo del # PUBLISH __keyevent@0__:del foo # # It is possible to select the events that Redis will notify among a set # of classes. Every class is identified by a single character: # # K Keyspace events, published with __keyspace@<db>__ prefix. # E Keyevent events, published with __keyevent@<db>__ prefix. # g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, ... # $ String commands # l List commands # s Set commands # h Hash commands # z Sorted set commands # x Expired events (events generated every time a key expires) # e Evicted events (events generated when a key is evicted for maxmemory) # A Alias for g$lshzxe, so that the "AKE" string means all the events. # # The "notify-keyspace-events" takes as argument a string that is composed # of zero or multiple characters. The empty string means that notifications # are disabled. # # Example: to enable list and generic events, from the point of view of the # event name, use: # # notify-keyspace-events Elg # # Example 2: to get the stream of the expired keys subscribing to channel # name __keyevent@0__:expired use: # # notify-keyspace-events Ex # # By default all notifications are disabled because most users don't need # this feature and the feature has some overhead. Note that if you don't # specify at least one of K or E, no events will be delivered. notify-keyspace-events "" # Advanced configuration ############################### ADVANCED CONFIG ############################### # Hashes are encoded using a memory efficient data structure when they have a # small number of entries, and the biggest entry does not exceed a given # threshold. These thresholds can be configured using the following directives. # When the total number of elements in the hashtable is set to not exceed the set number, the hashtable is stored in the way of zipmap to save memory hash-max-ziplist-entries 512 # When the length of key and value in hashtable is less than the set value, use zipmap to store hashtable to save memory hash-max-ziplist-value 64 # Lists are also encoded in a special way to save a lot of space. # The number of entries allowed per internal list node can be specified # as a fixed maximum size or a maximum number of elements. # For a fixed maximum size, use -5 through -1, meaning: # -5: max size: 64 Kb <-- not recommended for normal workloads # -4: max size: 32 Kb <-- not recommended # -3: max size: 16 Kb <-- probably not recommended # -2: max size: 8 Kb <-- good # -1: max size: 4 Kb <-- good # Positive numbers mean store up to _exactly_ that number of elements # per list node. # The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size), # but if your use case is unique, adjust the settings as necessary. list-max-ziplist-size -2 # Lists may also be compressed. # Compress depth is the number of quicklist ziplist nodes from *each* side of # the list to *exclude* from compression. The head and tail of the list # are always uncompressed for fast push/pop operations. Settings are: # 0: disable all list compression # 1: depth 1 means "don't start compressing until after 1 node into the list, # going from either the head or tail" # So: [head]->node->node->...->node->[tail] # [head], [tail] will always be uncompressed; inner nodes will compress. # 2: [head]->[next]->node->node->...->node->[prev]->[tail] # 2 here means: don't compress head or head->next or tail->prev or tail, # but compress all nodes between them. # 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail] # etc. list-compress-depth 0 # Sets have a special encoding in just one case: when a set is composed # of just strings that happen to be integers in radix 10 in the range # of 64 bit signed integers. # The following configuration setting sets the limit in the size of the # set in order to use this special memory saving encoding. set-max-intset-entries 512 # Similarly to hashes and lists, sorted sets are also specially encoded in # order to save a lot of space. This encoding is only used when the length and # elements of a sorted set are below the following limits: zset-max-ziplist-entries 128 zset-max-ziplist-value 64 # HyperLogLog sparse representation bytes limit. The limit includes the # 16 bytes header. When an HyperLogLog using the sparse representation crosses # this limit, it is converted into the dense representation. # # A value greater than 16000 is totally useless, since at that point the # dense representation is more memory efficient. # # The suggested value is ~ 3000 in order to have the benefits of # the space efficient encoding without slowing down too much PFADD, # which is O(N) with the sparse encoding. The value can be raised to # ~ 10000 when CPU is not a concern, but space is, and the data set is # composed of many HyperLogLogs with cardinality in the 0 - 15000 range. hll-sparse-max-bytes 3000 # Active rehashing uses 1 millisecond every 100 milliseconds of CPU time in # order to help rehashing the main Redis hash table (the one mapping top-level # keys to values). The hash table implementation Redis uses (see dict.c) # performs a lazy rehashing: the more operation you run into a hash table # that is rehashing, the more rehashing "steps" are performed, so if the # server is idle the rehashing is never complete and some more memory is used # by the hash table. # # The default is to use this millisecond 10 times every second in order to # actively rehash the main dictionaries, freeing memory when possible. # # If unsure: # use "activerehashing no" if you have hard latency requirements and it is # not a good thing in your environment that Redis can reply from time to time # to queries with 2 milliseconds delay. # # use "activerehashing yes" if you don't have such hard requirements but # want to free memory asap when possible. activerehashing yes # The client output buffer limits can be used to force disconnection of clients # that are not reading data from the server fast enough for some reason (a # common reason is that a Pub/Sub client can't consume messages as fast as the # publisher can produce them). # # The limit can be set differently for the three different classes of clients: # # normal -> normal clients including MONITOR clients # slave -> slave clients # pubsub -> clients subscribed to at least one pubsub channel or pattern # # The syntax of every client-output-buffer-limit directive is the following: # # client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds> # # A client is immediately disconnected once the hard limit is reached, or if # the soft limit is reached and remains reached for the specified number of # seconds (continuously). # So for instance if the hard limit is 32 megabytes and the soft limit is # 16 megabytes / 10 seconds, the client will get disconnected immediately # if the size of the output buffers reach 32 megabytes, but will also get # disconnected if the client reaches 16 megabytes and continuously overcomes # the limit for 10 seconds. # # By default normal clients are not limited because they don't receive data # without asking (in a push way), but just after a request, so only # asynchronous clients may create a scenario where data is requested faster # than it can read. # # Instead there is a default limit for pubsub and slave clients, since # subscribers and slaves receive data in a push fashion. # # Both the hard or the soft limit can be disabled by setting them to zero. client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 # Redis calls an internal function to perform many background tasks, like # closing connections of clients in timeout, purging expired keys that are # never requested, and so forth. # # Not all tasks are performed with the same frequency, but Redis checks for # tasks to perform according to the specified "hz" value. # # By default "hz" is set to 10. Raising the value will use more CPU when # Redis is idle, but at the same time will make Redis more responsive when # there are many keys expiring at the same time, and timeouts may be # handled with more precision. # # The range is between 1 and 500, however a value over 100 is usually not # a good idea. Most users should use the default of 10 and raise this up to # 100 only in environments where very low latency is required. # Frequency of background tasks performed by Redis server hz 10 # When a child rewrites the AOF file, if the following option is enabled # the file will be fsync-ed every 32 MB of data generated. This is useful # in order to commit the file to the disk more incrementally and avoid # big latency spikes. # When a child node rewrites an AOF file, if the following options are enabled, the file will be synchronized every 32M of data generated aof-rewrite-incremental-fsync yes # Redis LFU eviction (see maxmemory setting) can be tuned. However it is a good # idea to start with the default settings and only change them after investigating # how to improve the performances and how the keys LFU change over time, which # is possible to inspect via the OBJECT FREQ command. # # There are two tunable parameters in the Redis LFU implementation: the # counter logarithm factor and the counter decay time. It is important to # understand what the two parameters mean before changing them. # # The LFU counter is just 8 bits per key, it's maximum value is 255, so Redis # uses a probabilistic increment with logarithmic behavior. Given the value # of the old counter, when a key is accessed, the counter is incremented in # this way: # # 1. A random number R between 0 and 1 is extracted. # 2. A probability P is calculated as 1/(old_value*lfu_log_factor+1). # 3. The counter is incremented only if R < P. # # The default lfu-log-factor is 10. This is a table of how the frequency # counter changes with a different number of accesses with different # logarithmic factors: # # +--------+------------+------------+------------+------------+------------+ # | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits | # +--------+------------+------------+------------+------------+------------+ # | 0 | 104 | 255 | 255 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 1 | 18 | 49 | 255 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 10 | 10 | 18 | 142 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 100 | 8 | 11 | 49 | 143 | 255 | # +--------+------------+------------+------------+------------+------------+ # # NOTE: The above table was obtained by running the following commands: # # redis-benchmark -n 1000000 incr foo # redis-cli object freq foo # # NOTE 2: The counter initial value is 5 in order to give new objects a chance # to accumulate hits. # # The counter decay time is the time, in minutes, that must elapse in order # for the key counter to be divided by two (or decremented if it has a value # less <= 10). # # The default value for the lfu-decay-time is 1. A Special value of 0 means to # decay the counter every time it happens to be scanned. # # lfu-log-factor 10 # lfu-decay-time 1 # Defragmentation ########################### ACTIVE DEFRAGMENTATION ####################### # # WARNING THIS FEATURE IS EXPERIMENTAL. However it was stress tested # even in production and manually tested by multiple engineers for some # time. # # What is active defragmentation? # ------------------------------- # # Active (online) defragmentation allows a Redis server to compact the # spaces left between small allocations and deallocations of data in memory, # thus allowing to reclaim back memory. # # Fragmentation is a natural process that happens with every allocator (but # less so with Jemalloc, fortunately) and certain workloads. Normally a server # restart is needed in order to lower the fragmentation, or at least to flush # away all the data and create it again. However thanks to this feature # implemented by Oran Agra for Redis 4.0 this process can happen at runtime # in an "hot" way, while the server is running. # # Basically when the fragmentation is over a certain level (see the # configuration options below) Redis will start to create new copies of the # values in contiguous memory regions by exploiting certain specific Jemalloc # features (in order to understand if an allocation is causing fragmentation # and to allocate it in a better place), and at the same time, will release the # old copies of the data. This process, repeated incrementally for all the keys # will cause the fragmentation to drop back to normal values. # # Important things to understand: # # 1. This feature is disabled by default, and only works if you compiled Redis # to use the copy of Jemalloc we ship with the source code of Redis. # This is the default with Linux builds. # # 2. You never need to enable this feature if you don't have fragmentation # issues. # # 3. Once you experience fragmentation, you can enable this feature when # needed with the command "CONFIG SET activedefrag yes". # # The configuration parameters are able to fine tune the behavior of the # defragmentation process. If you are not sure about what they mean it is # a good idea to leave the defaults untouched. # Enabled active defragmentation # activedefrag yes # Minimum amount of fragmentation waste to start active defrag # active-defrag-ignore-bytes 100mb # Minimum percentage of fragmentation to start active defrag # active-defrag-threshold-lower 10 # Maximum percentage of fragmentation at which we use maximum effort # active-defrag-threshold-upper 100 # Minimal effort for defrag in CPU percentage # active-defrag-cycle-min 25 # Maximal effort for defrag in CPU percentage # active-defrag-cycle-max 75
Redis persistence
RDB(Redis DataBase)
What is it?
-
Writes the collective snapshot of data in memory to disk within the specified time interval
-
The jargon is Snapshot snapshot, which reads the Snapshot file directly into memory during recovery
-
Write to disk principle
Redis will separately create (fork) a sub process for persistence. It will first write the data to a temporary file. When the persistence process is over (all the new changes in the time interval are saved), redis will use this temporary file to replace the last persistent file.
In the whole process, the main process does not perform any IO operations, which ensures extremely high performance.
Fork
Fork is used to copy a process that is the same as the current process. The values of all data (variables, environment variables, program counters, etc.) of the new process are consistent with those of the original process, but it is a brand-new process and serves as a sub process of the original process.
-
RDB saves dump RDB file. The file name can be through dbfilename dump RDB configuration
Trigger RDB snapshot
-
Execute the command save or bgsave
- Save: when saving, just save and block everything else
- bgsave: Redis will perform snapshot operations asynchronously in the background, and the snapshot can also respond to client requests. You can obtain the time of the last successful snapshot execution through the lastsave command
-
Executing the flush command will also produce dump RDB file, but it is empty and meaningless
-
redis.conf's save {seconds} {changes} configuration saves data to disk
-
save 900 1
Save data to disk when a key changes in 15 minutes
-
save 300 10
Save data to disk when 10 key s change in 5 minutes
-
save 60 10000
Save data to disk when 10000 key s change in one minute
-
How to restore
- Move the backup file (dump.rdb) to the redis installation directory and start the service
- CONFIG GET dir get directory
Advantages and disadvantages
advantage
- Suitable for large-scale data recovery
- The requirements for data integrity and consistency are not high
inferiority
- Make a backup at a certain time interval. If redis fails unexpectedly, all modifications after the last snapshot will be lost
- When forking, the data in the memory is cloned, and the roughly twice expansion needs to be considered
- When the data set is relatively large, the process of fork will be very time-consuming, which may cause Redis to fail to respond to client requests in some milliseconds
How to stop
Method to dynamically stop all RDB saving rules: redis cli config set save ""
AOF(Append Only File)
definition
-
Each write operation is recorded in the form of log, and all instructions executed by Redis are recorded (read operation is not recorded)
-
It is only allowed to append files and cannot overwrite files. Redis will read the file and rebuild the data at the beginning of startup (if redis restarts, it will execute the write instruction from front to back according to the contents of the log file to complete the data recovery)
-
The file name for saving the log is appendix AOP can modify the file name through the appendfilename parameter
AOF startup / repair / recovery
Normal recovery
- Start: set yes to modify the default appendonly no to yes
- Copy a copy of the aof file with data and save it to the corresponding directory (config get dir)
- Restore: restart redis and reload
Abnormal recovery
- appendonly yes
- Back up the bad AOF file
- Repair: redis check AOF -- fix
- Restore: restart redis and reload
rewrite
Definition: AOF adopts the method of file addition, and the file will become larger and larger. In order to avoid this situation, a rewriting mechanism is added. When the size of AOF file exceeds the set threshold, Redis will start the compressed content of AOF file and only retain the minimum instruction set that can recover data.
Rewriting principle: when the AOF file continues to grow and is too large, it will fork a new process to rewrite the file, traverse the data in the memory of the new process, and each record has a Set statement.
The operation of rewriting AOF file does not read the old AOF file, but rewrites a new AOF file with the contents of the database in the whole memory by command.
The size of the AOF file triggered by the Redis mechanism is twice the size of the AOF file triggered last time, and the size of the AOF file triggered by the Redis mechanism is larger than the size of the AOF file last time
Advantages and disadvantages
Advantages:
- Synchronization per modification: appendfsync always synchronization persistence. Every time a data change occurs, it will be immediately recorded to the disk. The performance is poor, but the data integrity is good
- Synchronization per second: appendfsync everysec asynchronous operation, recording every second. If the machine goes down within one second, data will be lost
- Out of Sync: appendfsync no is out of sync
inferiority
- For the data of the same dataset, AOF files are much larger than rdb files, and the recovery speed is slower than rdb files
- The efficiency of aof is slower than rdb, the efficiency of synchronization strategy per second is better, and the asynchronous efficiency is the same as rdb
- The file operation command is easy to understand and the file is easy to analyze
Redis transaction
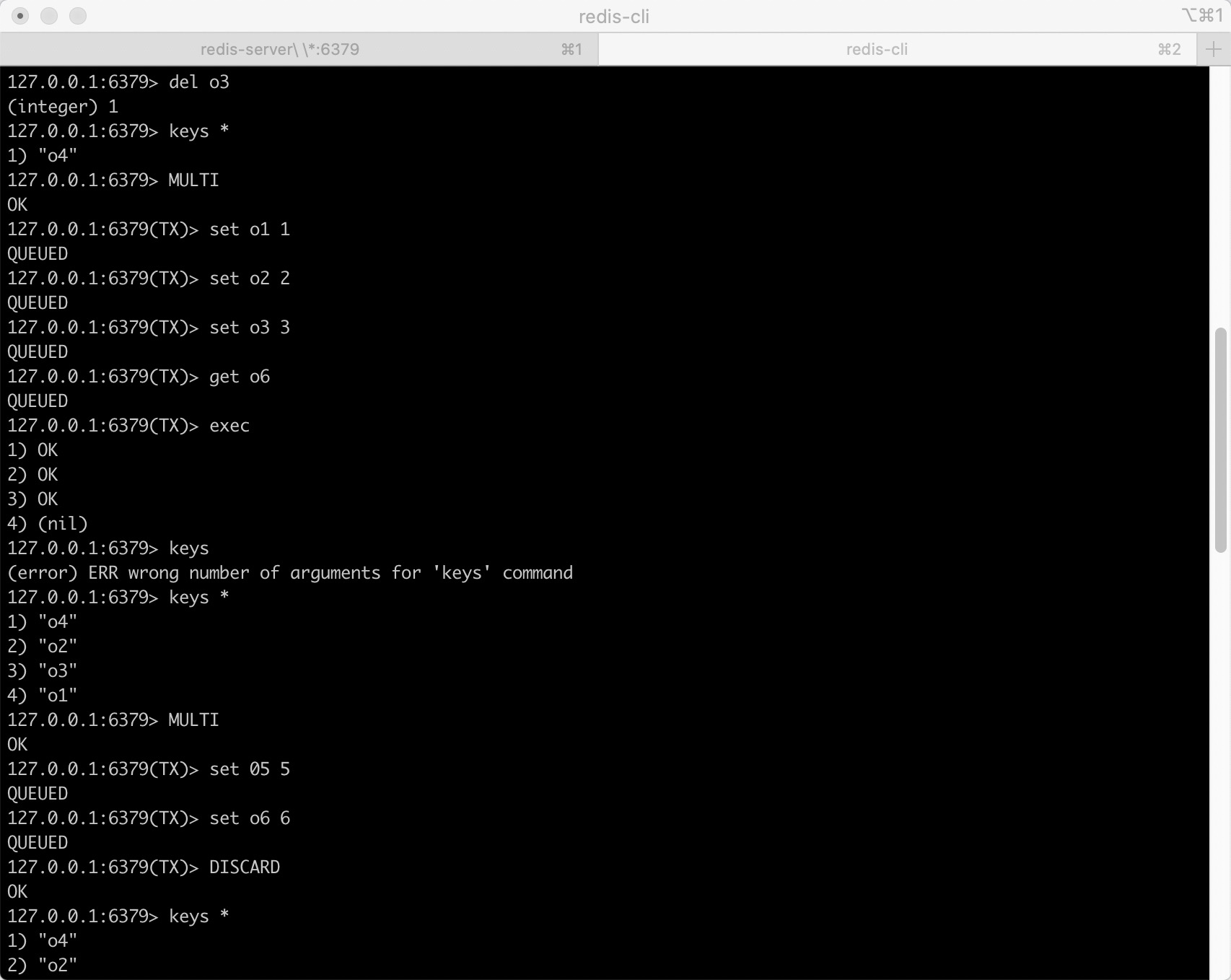
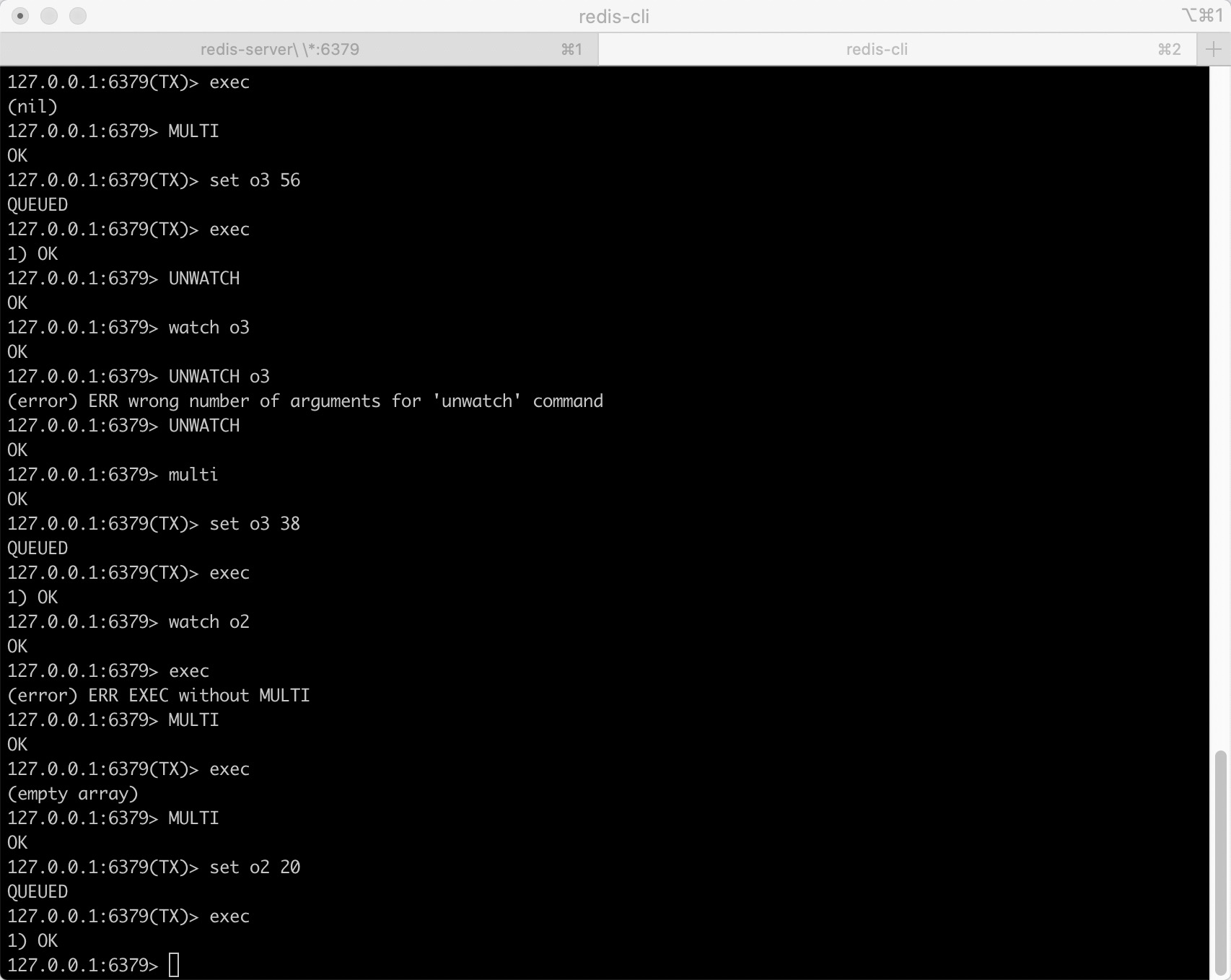
Definition: multiple commands can be executed at one time, which is essentially a set of commands. All commands in a transaction will be serialized and executed serially in sequence without being inserted by other commands. No stuffing is allowed.
characteristic
- A transaction is a separate isolation operation: all commands in the transaction are serialized and executed sequentially. During the execution of the transaction, it will not be interrupted by the command request sent by other clients
- A transaction is an atomic operation: all commands in a transaction are executed or none are executed
- The exec command is responsible for triggering and executing all commands in the transaction:
- If an error or disconnection occurs before exec is executed, all commands in the transaction will not be executed
- If the command has been added to the execution queue, the execution error will only affect the result of a single command, and the subsequent commands can still be executed normally
Main command
multi
Mark the beginning of a transaction block
discard
Cancel the transaction and abort all commands in the transaction block.
exec
Execute commands within all transaction blocks
When exec is called, no matter whether the transaction is successfully executed or not, the monitoring of all keys will be cancelled, that is, the watch command will be invalid as long as exec is executed.
watch
The exec command needs to be executed conditionally: the transaction can only be executed on the premise that all monitored keys have not been modified. If this precondition cannot be met, the transaction will not be executed.
unwatch
Cancel the monitoring of all key s by the watch command.
Usage example:
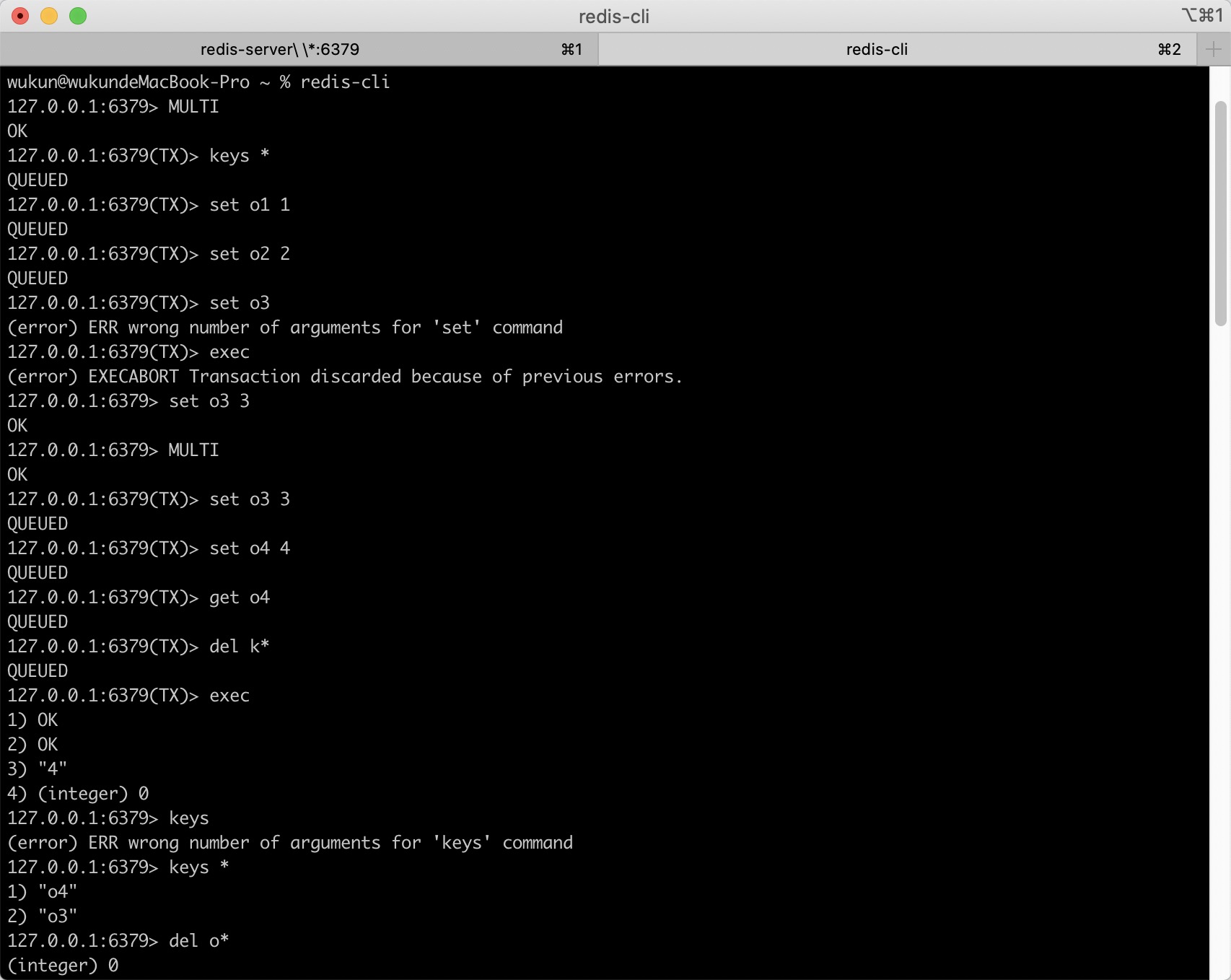

Redis master-Slave replication (Master Master / Slave)
definition
After the host database is updated, it is automatically synchronized to the standby machine according to the configuration and policy.
Master mainly writes, Slave mainly reads.
Main function
- Read write separation
- Disaster recovery backup
Use process
Preparation - configuration
-
Slave database not master database
-
Slave library configuration command: slaveof Primary Library IP Primary Library port
Every time you disconnect from the master, you need to reconnect unless you configure redis Conf file (REPLICATION)
info replication: command to view current library information
-
Detailed operation of modifying configuration file
- Copy multiple redis Conf file
- Enable daemon yes
- pid file name
- Specify port
- log file name
- dump.rdb name
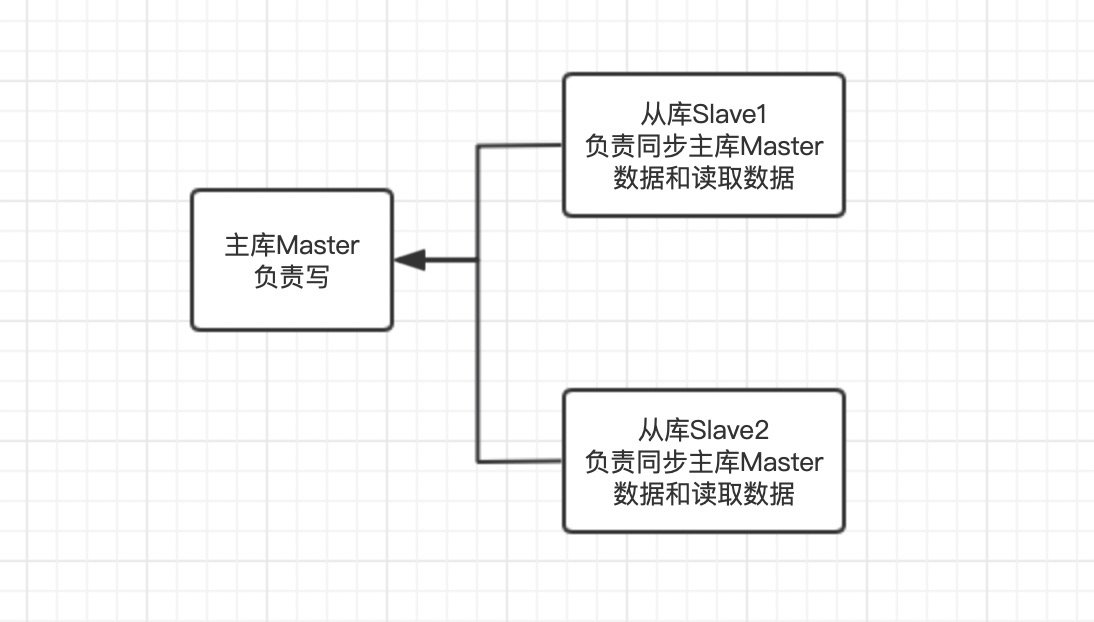
Three common modes
One Master and two servants: one Master and two slaves. There is no relationship between the two slaves
From generation to generation: the previous slave can be the master of the next slave. The slave can also receive connection and synchronization requests from other slaves. Then the slave is the next master in the chain, which can effectively reduce the write pressure of the master.
Intermediate change direction: the previous data will be cleared and the latest copy will be re established; After the original master shutdown, you can set up another save as the host
Sentinel mode: it can monitor whether the host fails in the background. If it fails, it will automatically convert from the library to the main library according to the voting
How do you play?
- Adjust the structure, 6379 with 6380 and 6381
- Create a sentinel Conf file, the name must not be wrong
- Configure sentinels and fill in the contents
- 127.0 monitor1.0 monitor1
- The last number 1 above indicates that after the host hangs up, the slave votes to see who will take over as the host and become the host after the number of votes
- Start sentinel redis sentinel / sentinel conf
- Normal master-slave demonstration
- The original master is hung up
- Vote for a new election
- Restart the master-slave operation and check the info replication
Question: if the previously suspended master restarts, will there be a double master conflict? No, the original master becomes slave
Replication principle
- After the slave is successfully started and connected to the master, it will send a sync command
- After receiving the command, the master starts the background save process and collects all the commands received to modify the dataset. After the background process is executed, the master will transfer the whole data file to the slave to complete a complete synchronization
- Full copy: after receiving the database file data, the slave service saves it and loads it into memory
- Incremental replication: the Master continues to transmit all new collected modification commands to the slave to complete synchronization
- However, as long as the master is reconnected, a full synchronization (full replication) will be performed automatically
Disadvantages of master-slave replication
Replication delay: since all write operations are performed on the master first and then synchronously updated to the slave, there is a certain delay in synchronizing from the master to the slave machine. When the system is very busy, the delay problem becomes more serious, and the increase in the number of slave machines will also make this problem more serious.
Master-slave problem demonstration
-
The entry point question is whether slave1 and slave2 are copied from scratch or from the entry point? For example, from k4, can the previous k1, k2 and k3 be copied?
Copy from scratch; 123 can also be copied
-
Can the slave write? Can set?
The slave cannot write or set
-
What happens after the host shuts down? Is the slave up or standing by
Slave or standby in place (one master and two slave mode, other modes can set up another host)
-
After the host comes back, can the host add new records and the slave copy smoothly?
can
-
What happens after one of the slaves goes down? According to the original, can it keep up with the big army?
Can't keep up. Every time you disconnect from the master, you need to reconnect, unless you configure redis Conf file
Redis class
Main classes: JedisPool, JedisPool
JedisPool configuration parameters:
-
maxActive: controls how many jedis instances can be allocated to a pool through pool Getresource(); If the value is - 1, it means there is no limit; If the pool has been allocated maxActive jedis instances, the status of the pool is exhausted.
-
maxIdle: controls the maximum number of jedis instances in idle status in a pool;
-
whenExhaustedAction
Indicates the action to be taken by the pool when all jedis instances in the pool are allocated; There are three by default.
- WHEN_ EXHAUSTED_ Fail -- > indicates that NoSuchElementException is thrown directly when there is no jedis instance;
- WHEN_ EXHAUSTED_ Block -- > indicates that it is blocked, or JedisConnectionException is thrown when maxWait is reached;
- WHEN_ EXHAUSTED_ Grow -- > means to create a new jedis instance, that is, the set maxActive is useless;
-
maxWait: indicates the maximum waiting time when a jedis instance is browsed. If it exceeds the waiting time, the JedisConnectionException will be thrown directly;
-
Testonmirror: whether to check the connection availability (ping()) when obtaining a jedis instance; If true, all the jedis instances are available;
-
Teston return: Returns whether to check the connection availability (ping()) when a jedis instance is given to the pool;
-
Testwhiteidle: if true, it means that an idle object monitor thread scans the idle object. If validate fails, the object will be drop ped from the pool; This item is meaningful only when timebetween evictionrunsmillis is greater than 0;
-
Timebetween evictionrunsmillis: indicates the number of milliseconds to sleep between two scans of idle object monitor;
-
numTestsPerEvictionRun: indicates the maximum number of objects scanned each time by the idle object monitor;
-
Minevictabidletimemillis: indicates the shortest time an object stays in the idle state at least before it can be scanned and expelled by the idle object monitor; This item is meaningful only when timebetween evictionrunsmillis is greater than 0;
-
softMinEvictableIdleTimeMillis: Based on minEvictableIdleTimeMillis, at least minIdle objects have been added and are already in the pool. If - 1, evicted does not evict any objects based on idle time. If minEvictableIdleTimeMillis > 0, this setting is meaningless and only meaningful when timebetween evictionrunsmillis is greater than 0;
-
lifo: default is used when borrowObject returns an object_ lifo (last in first out, i.e. the most frequently used queue similar to cache). If False, it indicates FIFO queue;
Reference material
https://my.oschina.net/jallenkwong/blog/4411044
https://www.bilibili.com/video/BV1oW411u75R