Continue to share dry goods in Excel, MySQL and Python. Poke the official account link stamp. The beauty of data analysis and statistics Pay attention to this official account with a little bit of things. You can also obtain four original documents: Python automation office manual, Excel PivotTable complete manual, python basic query manual and Mysql basic query manual
Yesterday, I published an article for you, which was deeply loved by you.
Strike while the iron is hot, Mr. Huang will explain the 16Pandas function again today. It's really easy to use!
This article introduces
Do you have such a feeling that why the data in your hand is always messy?

As a data analyst, data cleaning is an essential link. Sometimes because the data is too messy, it often takes us a lot of time to deal with it. Therefore, mastering more data cleaning methods will increase your ability by 100 times.
Based on this, this paper describes the super easy-to-use str vectorization string function in Pandas. After learning it, I instantly feel that my data cleaning ability has been improved.

1 data set, 16 Pandas functions
The data set is carefully fabricated by Mr. Huang just to help you learn knowledge. The data sets are as follows:
import pandas as pd
df ={'full name':[' Classmate Huang','Huang Zhizun','Huang Laoxie ','Da Mei Chen','Sun Shangxiang'],
'English name':['Huang tong_xue','huang zhi_zun','Huang Lao_xie','Chen Da_mei','sun shang_xiang'],
'Gender':['male','women','men','female','male'],
'ID':['463895200003128433','429475199912122345','420934199110102311','431085200005230122','420953199509082345'],
'height':['mid:175_good','low:165_bad','low:159_bad','high:180_verygood','low:172_bad'],
'Home address':['Guangshui, Hubei','Xinyang, Henan','Guangxi Guilin','Hubei Xiaogan','Guangzhou, Guangdong'],
'Telephone number':['13434813546','19748672895','16728613064','14561586431','19384683910'],
'income':['1.1 ten thousand','8.5 thousand','0.9 ten thousand','6.5 thousand','2.0 ten thousand']}
df = pd.DataFrame(df)
df
The results are as follows:
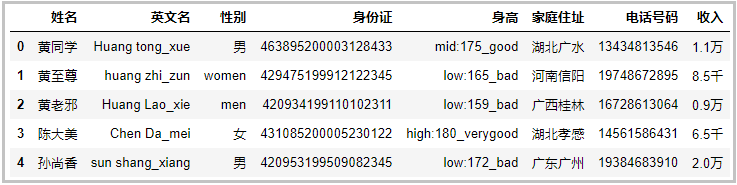
Observing the above data, the data set is chaotic. Next, we will use 16 Pandas to clean the above data.
① cat function: used for string splicing
df["full name"].str.cat(df["Home address"],sep='-'*3)
The results are as follows:

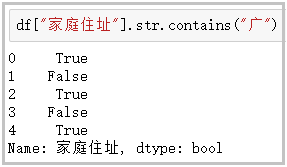
② Contains: determines whether a string contains a given character
df["Home address"].str.contains("wide")
The results are as follows:
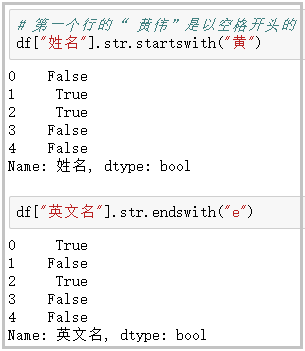
③ Startswitch / endswitch: judge whether a string starts / ends with
# "Huang Wei" in the first line begins with a space
df["full name"].str.startswith("yellow")
df["English name"].str.endswith("e")
The results are as follows:
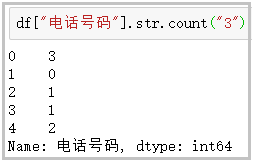
④ count: counts the number of occurrences of a given character in the string
df["Telephone number"].str.count("3")
The results are as follows:
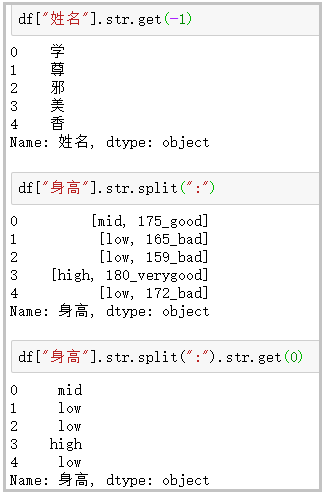
⑤ get: gets the string at the specified location
df["full name"].str.get(-1)
df["height"].str.split(":")
df["height"].str.split(":").str.get(0)
The results are as follows:
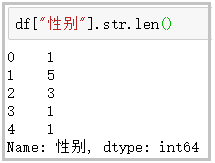
⑥ len: calculate string length
df["Gender"].str.len()
The results are as follows:
⑦ upper/lower: English case conversion
df["English name"].str.upper() df["English name"].str.lower()
The results are as follows:

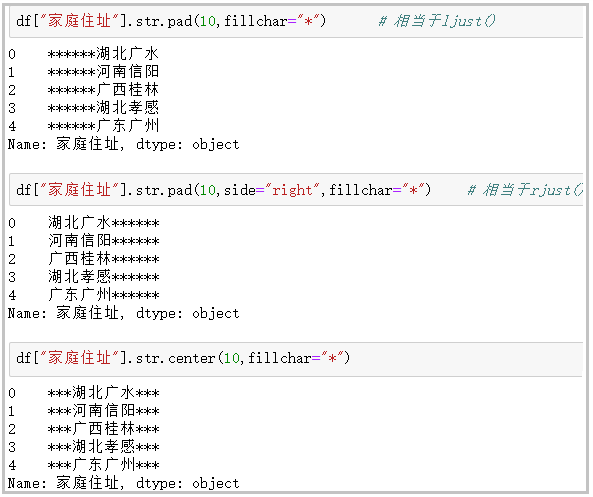
⑧ pad+side parameter / center: add the given character to the left, right or left and right sides of the string
df["Home address"].str.pad(10,fillchar="*") # Equivalent to ljust() df["Home address"].str.pad(10,side="right",fillchar="*") # Equivalent to rjust() df["Home address"].str.center(10,fillchar="*")
The results are as follows:
⑨ Repeat: repeat the string several times
df["Gender"].str.repeat(3)
The results are as follows:

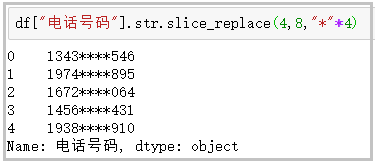
⑩ slice_replace: replaces the character at the specified position with the given string
df["Telephone number"].str.slice_replace(4,8,"*"*4)
The results are as follows:
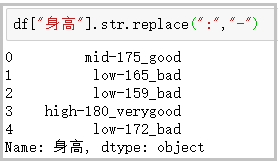
⑪ Replace: replace the character at the specified position with the given string
df["height"].str.replace(":","-")
The results are as follows:
⑫ Replace: replace the character at the specified position with the given string (accept regular expression)
- The regular expression is passed into replace to make it easy to use;
- Regardless of whether the following case is useful or not, you just need to know how easy it is to use regular data cleaning;
df["income"].str.replace("\d+\.\d+","regular")
The results are as follows:

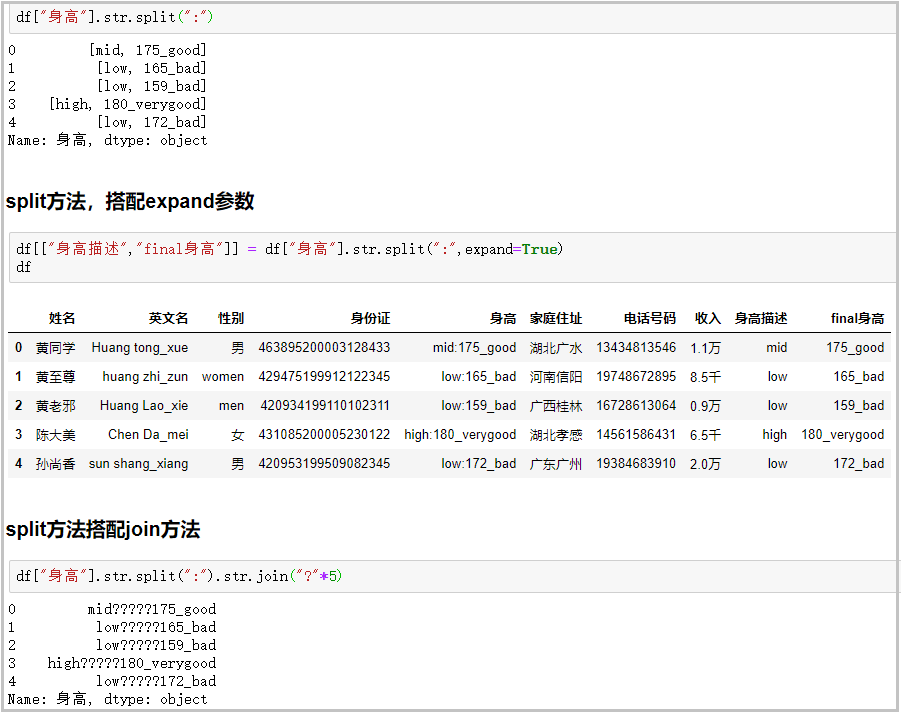
⑬ split method + expand parameter: with the join method, the function is very powerful
# Common usage
df["height"].str.split(":")
# split method with expand parameter
df[["Height description","final height"]] = df["height"].str.split(":",expand=True)
df
# split method with join method
df["height"].str.split(":").str.join("?"*5)
The results are as follows:
⑭ strip/rstrip/lstrip: remove blank characters and line breaks
df["full name"].str.len() df["full name"] = df["full name"].str.strip() df["full name"].str.len()
The results are as follows:

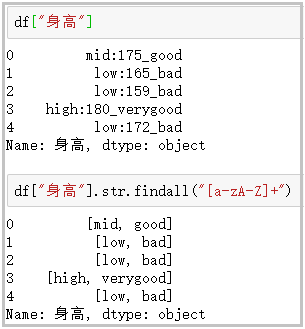
⑮ findall: use regular expressions to match strings and return a list of search results
- findall uses regular expressions to clean data. It's really fragrant!
df["height"]
df["height"].str.findall("[a-zA-Z]+")
The results are as follows:
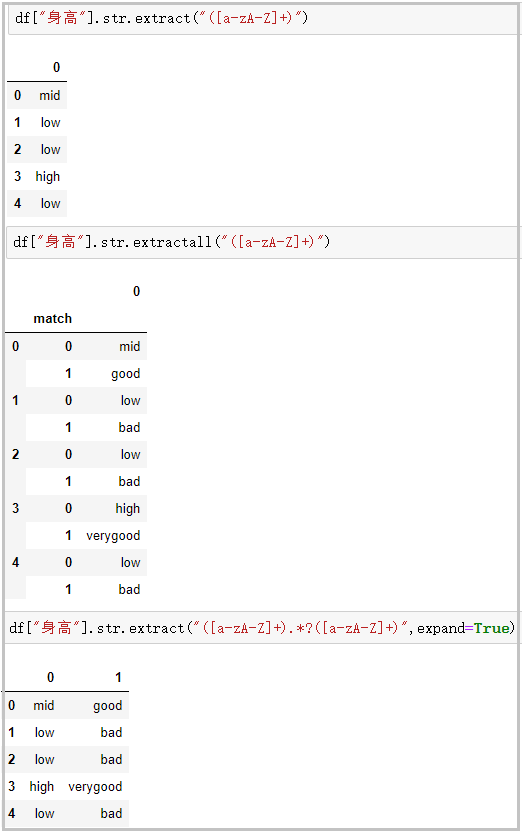
⑯ extract/extractall: accept regular expressions and extract matching strings (be sure to add parentheses)
df["height"].str.extract("([a-zA-Z]+)")
# Extract the composite index from extractall
df["height"].str.extractall("([a-zA-Z]+)")
# extract with expand parameter
df["height"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True)
The results are as follows:
Today's article, Mr. Huang will tell you here. I hope it can be helpful to you.