background
Recently, the function of data export is being done. Since batch export is supported and the exported files are up to 3GB, it is decided to compress when exporting the final results
first day
java compression, emmm The first thought is java util. Zip the following APIs, directly to the code:
/**
* Batch compressed file v1 0
*
* @param fileNames List of file names to be compressed (including relative paths)
* @param zipOutName Compressed file name
**/
public static void batchZipFiles(List<String> fileNames, String zipOutName) {
//Set read data cache size
byte[] buffer = new byte[4096];
ZipOutputStream zipOut = null;
try {
zipOut = new ZipOutputStream(new FileOutputStream(zipOutName));
for (String fileName : fileNames) {
File inputFile = new File(fileName);
if (inputFile.exists()) {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(inputFile));
//Write the file into zip and package the file
zipOut.putNextEntry(new ZipEntry(inputFile.getName()));
//The method of writing files is the same as above
int size = 0;
//Set read data cache size
while ((size = bis.read(buffer)) >= 0) {
zipOut.write(buffer, 0, size);
}
//Close input / output stream
zipOut.closeEntry();
bis.close();
}
}
} catch (Exception e) {
log.error("batchZipFiles error:sourceFileNames:" + JSONObject.toJSONString(fileNames), e);
} finally {
if (null != zipOut) {
try {
zipOut.close();
} catch (Exception e) {
log.error("batchZipFiles error:sourceFileNames:" + JSONObject.toJSONString(fileNames), e);
}
}
}
}
Copy codeFirstly, BufferedInputStream is used to read the contents of the file, and the putNextEntry method of ZipOutputStream compresses and writes each file. Finally, write all the compressed files into the final zipOutName file. Because BufferedInputStream is used to buffer the input stream, the reading and writing of files are obtained from the cache (memory), that is, the corresponding byte array in the code. Compared with ordinary FileInputStream, it improves the efficiency. But not enough! The time consuming is as follows:
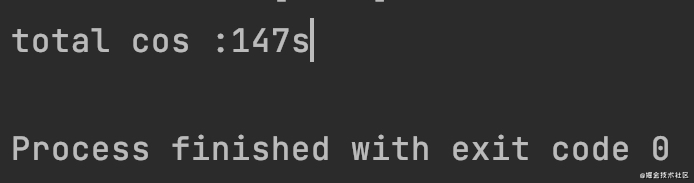
Compress three 3.5GB files
the second day
Thinking of NIO, the traditional IO is called BIO (the code above), which is synchronously blocked, and the reading and writing are in one thread. NIO is synchronous and non blocking. Its core is channel, buffer and selector. In fact, the reason why NIO is more efficient than BIO in intensive computing is that NIO is multiplexed and uses fewer threads to do more things. Compared with BIO, NIO greatly reduces thread switching and resource loss caused by competition. There are not many BB S. The above code:
/**
* Batch compressed file v2 0
*
* @param fileNames List of file names to be compressed (including relative paths)
* @param zipOutName Compressed file name
**/
public static void batchZipFiles(List<String> fileNames, String zipOutName) throws Exception {
ZipOutputStream zipOutputStream = null;
WritableByteChannel writableByteChannel = null;
ByteBuffer buffer = ByteBuffer.allocate(2048);
try {
zipOutputStream = new ZipOutputStream(new FileOutputStream(zipOutName));
writableByteChannel = Channels.newChannel(zipOutputStream);
for (String sourceFile : fileNames) {
File source = new File(sourceFile);
zipOutputStream.putNextEntry(new ZipEntry(source.getName()));
FileChannel fileChannel = new FileInputStream(sourceFile).getChannel();
while (fileChannel.read(buffer) != -1) {
//Update cache location
buffer.flip();
while (buffer.hasRemaining()) {
writableByteChannel.write(buffer);
}
buffer.rewind();
}
fileChannel.close();
}
} catch (Exception e) {
log.error("batchZipFiles error fileNames:" + JSONObject.toJSONString(fileNames), e);
} finally {
zipOutputStream.close();
writableByteChannel.close();
buffer.clear();
}
}
Copy codeOr use Java For the api under NiO package, first use channels The newchannel () method creates a write channel from the zipOutputStream output stream, and directly uses FileInputStream. When reading the contents of the file Getchannel(), get the read channel of the current file, and then read the file content from the read channel through ByteBuffer (buffer) and write it into the writableByteChannel write channel. Be sure to reverse the buffer Flip(), otherwise the read content is the last content of the file when byte=0. Compared with the above speed, this method is shown in the following figure: 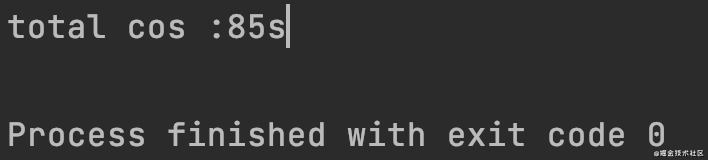
Compress three 3.5GB files
on the third day
Continue to optimize. I heard that the way to use memory mapped files is faster! What are you waiting for? Let me try! Code:
/**
* Batch compressed file v3 0
*
* @param fileNames List of file names to be compressed (including relative paths)
* @param zipOutName Compressed file name
**/
public static void batchZipFiles(List<String> fileNames, String zipOutName) {
ZipOutputStream zipOutputStream = null;
WritableByteChannel writableByteChannel = null;
MappedByteBuffer mappedByteBuffer = null;
try {
zipOutputStream = new ZipOutputStream(new FileOutputStream(zipOutName));
writableByteChannel = Channels.newChannel(zipOutputStream);
for (String sourceFile : fileNames) {
File source = new File(sourceFile);
long fileSize = source.length();
zipOutputStream.putNextEntry(new ZipEntry(source.getName()));
int count = (int) Math.ceil((double) fileSize / Integer.MAX_VALUE);
long pre = 0;
long read = Integer.MAX_VALUE;
//Since the file size of one mapping cannot exceed 2GB, it is mapped in stages
for (int i = 0; i < count; i++) {
if (fileSize - pre < Integer.MAX_VALUE) {
read = fileSize - pre;
}
mappedByteBuffer = new RandomAccessFile(source, "r").getChannel()
.map(FileChannel.MapMode.READ_ONLY, pre, read);
writableByteChannel.write(mappedByteBuffer);
pre += read;
}
//Release resources
Method m = FileChannelImpl.class.getDeclaredMethod("unmap", MappedByteBuffer.class);
m.setAccessible(true);
m.invoke(FileChannelImpl.class, mappedByteBuffer);
mappedByteBuffer.clear();
}
} catch (Exception e) {
log.error("zipMoreFile error fileNames:" + JSONObject.toJSONString(fileNames), e);
} finally {
try {
if (null != zipOutputStream) {
zipOutputStream.close();
}
if (null != writableByteChannel) {
writableByteChannel.close();
}
if (null != mappedByteBuffer) {
mappedByteBuffer.clear();
}
} catch (Exception e) {
log.error("zipMoreFile error fileNames:" + JSONObject.toJSONString(fileNames), e);
}
}
}
Copy codeHere are two pits:
1. Use mappedbytebuffer Map file, if the file is too large and exceeds integer An error will be reported at max (about 2GB):
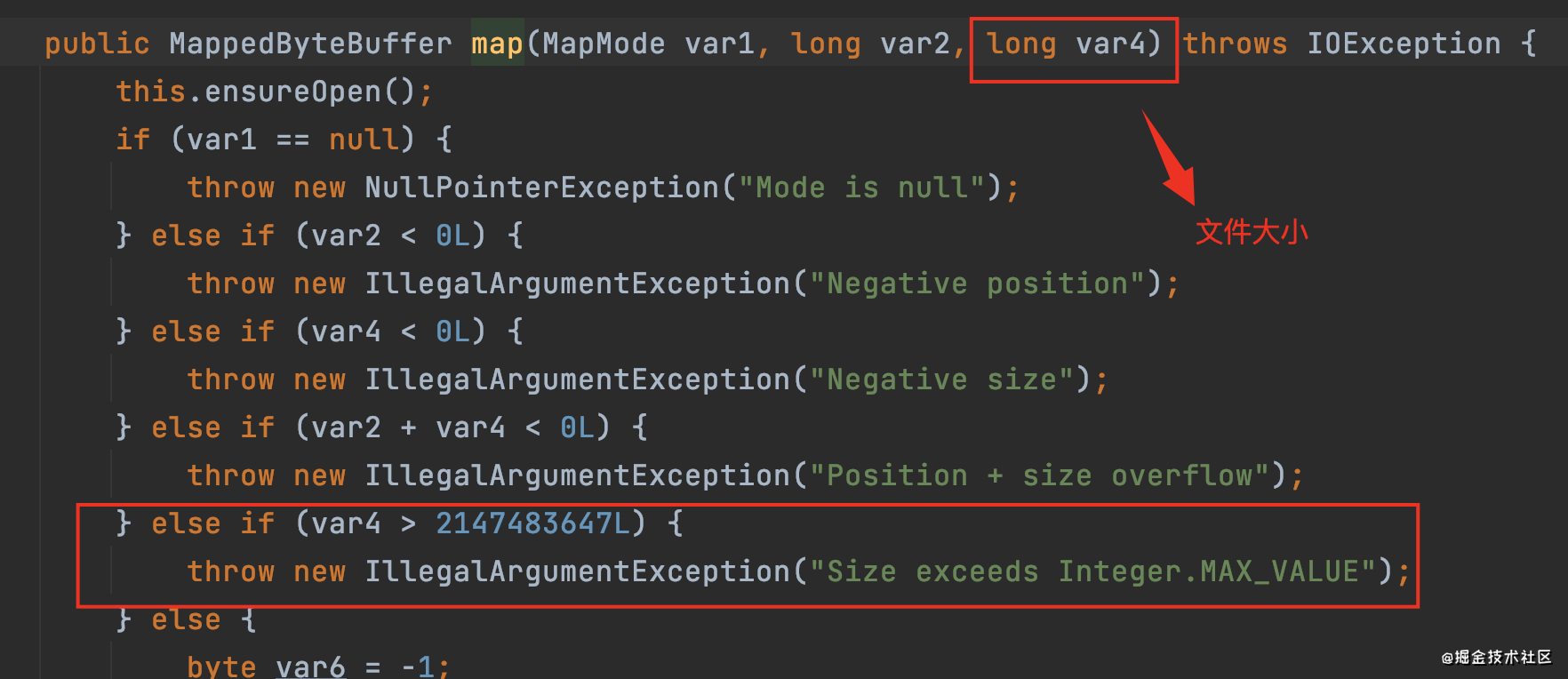 Therefore, you need to map the file to be written into memory file in several times.
Therefore, you need to map the file to be written into memory file in several times.
2. There is a bug here. After the file is mapped to memory, the memory will not be released even if the mapped ByteBuffer is clear ed after writing. At this time, it needs to be released manually. See the above code for details.
Look at the speed!
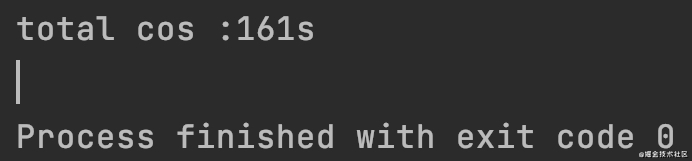
Compress three 3.5GB files
There must be something wrong with my opening method. Why is it the slowest.. Is the file too big? My machine memory is too small? I still have a problem with it. Let me think about it.. I hope to discuss it in the message area.
the forth day
I wonder if the bulk compression of files is so slow because it is serial. Wouldn't it be faster if it was changed to multi-threaded parallelism? Do as you say. I originally wanted to write it myself. Later, I checked the data on google and found that Apache Commons is ready-made. I decided not to repeat the wheel and put the code on it:
/**
* Batch compressed file v4 0
*
* @param fileNames List of file names to be compressed (including relative paths)
* @param zipOutName Compressed file name
**/
public static void compressFileList(String zipOutName, List<String> fileNameList) throws IOException, ExecutionException, InterruptedException {
ThreadFactory factory = new ThreadFactoryBuilder().setNameFormat("compressFileList-pool-").build();
ExecutorService executor = new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(20), factory);
ParallelScatterZipCreator parallelScatterZipCreator = new ParallelScatterZipCreator(executor);
OutputStream outputStream = new FileOutputStream(zipOutName);
ZipArchiveOutputStream zipArchiveOutputStream = new ZipArchiveOutputStream(outputStream);
zipArchiveOutputStream.setEncoding("UTF-8");
for (String fileName : fileNameList) {
File inFile = new File(fileName);
final InputStreamSupplier inputStreamSupplier = () -> {
try {
return new FileInputStream(inFile);
} catch (FileNotFoundException e) {
e.printStackTrace();
return new NullInputStream(0);
}
};
ZipArchiveEntry zipArchiveEntry = new ZipArchiveEntry(inFile.getName());
zipArchiveEntry.setMethod(ZipArchiveEntry.DEFLATED);
zipArchiveEntry.setSize(inFile.length());
zipArchiveEntry.setUnixMode(UnixStat.FILE_FLAG | 436);
parallelScatterZipCreator.addArchiveEntry(zipArchiveEntry, inputStreamSupplier);
}
parallelScatterZipCreator.writeTo(zipArchiveOutputStream);
zipArchiveOutputStream.close();
outputStream.close();
log.info("ParallelCompressUtil->ParallelCompressUtil-> info:{}", JSONObject.toJSONString(parallelScatterZipCreator.getStatisticsMessage()));
}
Copy codeLook at the results first:
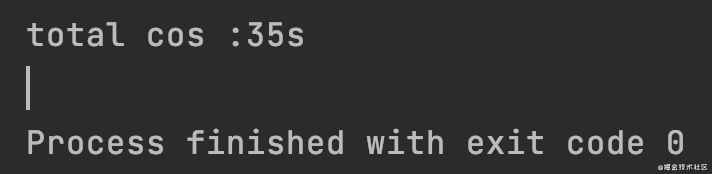
Compress three 3.5GB files
Sure enough, it's still fast!
As for the implementation principle, we are going to record a special article later to deepen our understanding!
Author: tiny orange
Link: https://juejin.cn/post/6949355730814107661
Source: Nuggets
The copyright belongs to the author. For commercial reprint, please contact the author for authorization. For non-commercial reprint, please indicate the source.